可观测性差距:为什么你的监控策略还没准备好应对即将到来的变化
摘要:随着系统架构从单体应用转向微服务和Kubernetes,可观测性差距日益凸显。传统监控工具难以应对指数级增长的复杂性,采样数据会丢失关键信号。OpenTelemetry通过供应商中立性和标准化元数据解决了基础问题,而关联技术(如traceID)和wide-events数据结构能实现跨信号的无缝调查。AI驱动的分析利用丰富上下文可大幅缩短故障诊断时间。建议优先评估日志质量、采用OpenTele
作者:来自 Elastic David Hope

任何去过伦敦的人都知道地铁里会有“Mind the gap”的广播,但我们监控和可观测性策略中出现的差距怎么办呢?我以前也经历过这种辛苦,运行过一个分布式系统,一切运作得很顺畅。我的告警是可管理的,仪表板清晰明了,当出现问题时,我通常能在合理的时间内找到原因。
快进 3 - 5 年,情况发生了变化,我们引入了 Kubernetes,采用了微服务,也许现在你甚至加入了一些 AI 驱动的功能。突然间,你被遥测数据淹没,告警疲劳感真实存在,在分布式架构中关联问题变得压力山大。
你正在经历我称之为“可观测性差距”的情况 —— 系统复杂性飞速增长,而我们的监控成熟度却缓慢落后。今天,我们将探讨这个差距存在的原因、推动它扩大的因素,以及最重要的,如何使用现代可观测性实践来弥合它。
复杂性的火箭已经发射离开了发射台
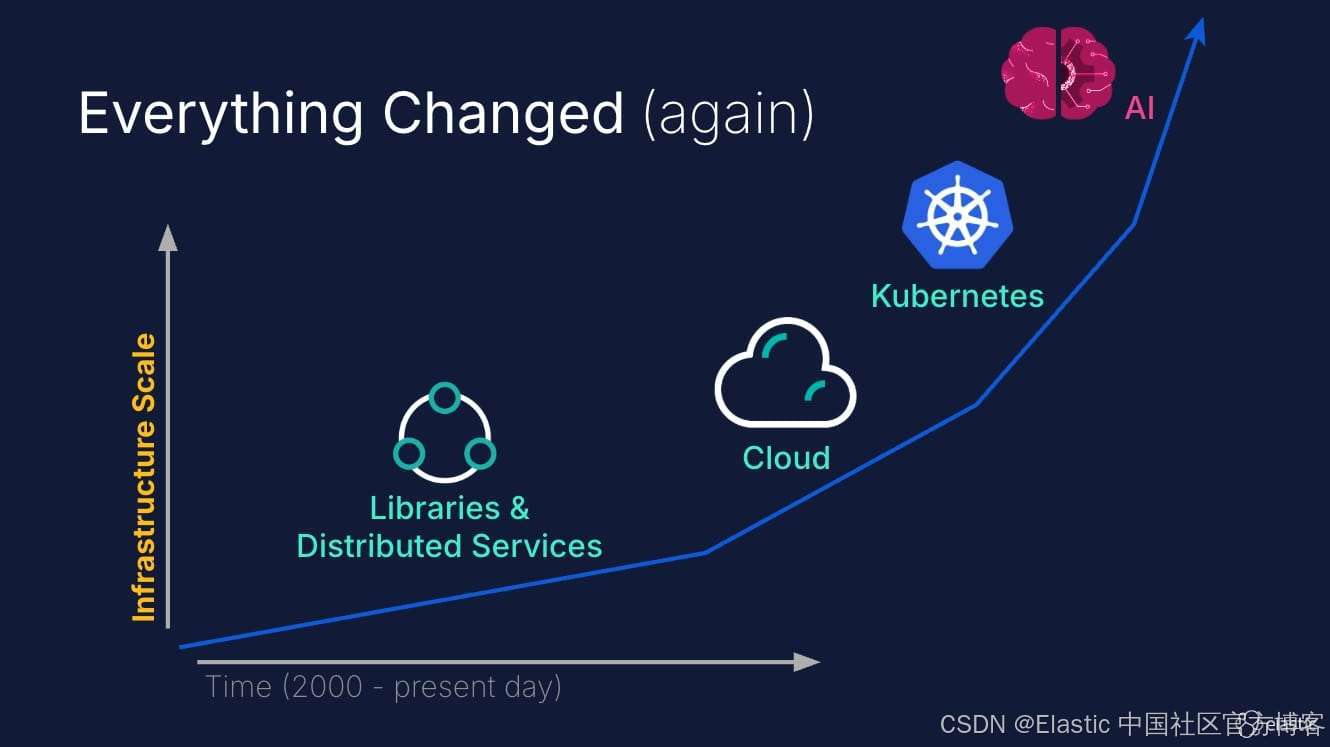
让我们坦率地面对现实。我们的基础设施规模和复杂性并不是线性增长,而是指数级增长。我们已经从运行在物理服务器上的单体应用,发展到管理数百个微服务的容器编排平台,现在 AI 算法甚至开始自主做出扩展决策。
这一趋势没有放缓的迹象。随着 AI 辅助编码加快开发周期,以及像 Kubernetes 这样的智能编排系统向预测性扩展发展,我们面对的基础设施不仅复杂,而且是动态复杂的。
与此同时,我们的可观测性工具呢?还停留在过去,它们设计的世界是你能精确知道有多少台服务器,并能通过交叉对比时间戳手动关联日志和指标。
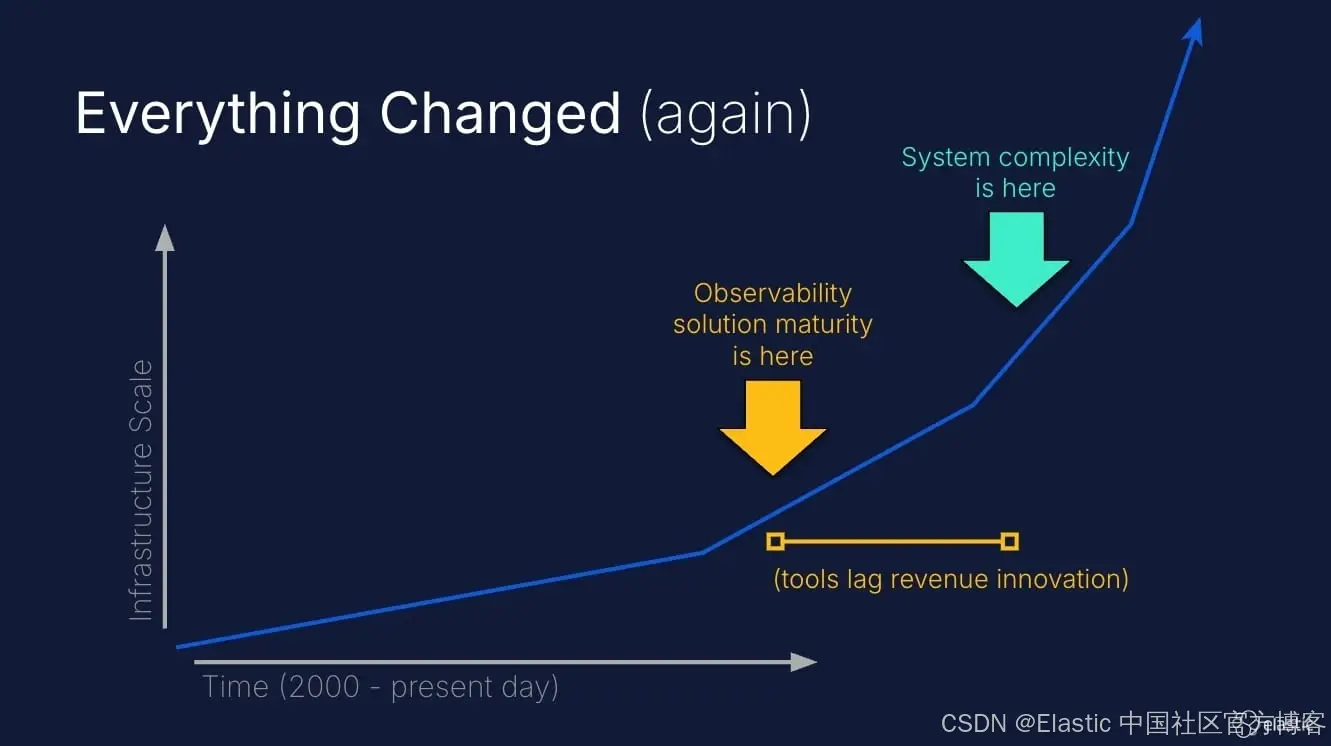
遥测数据的爆炸(以及为什么采样不是解决方案)
团队在扩展时首先注意到的一件事是,他们的可观测性开销增长速度超过基础设施成本。直觉反应通常是开始对数据进行采样、下采样指标、对 trace 进行头采样、去重日志。虽然这些技术有其作用,但它们从根本上与我们发展的方向背道而驰。
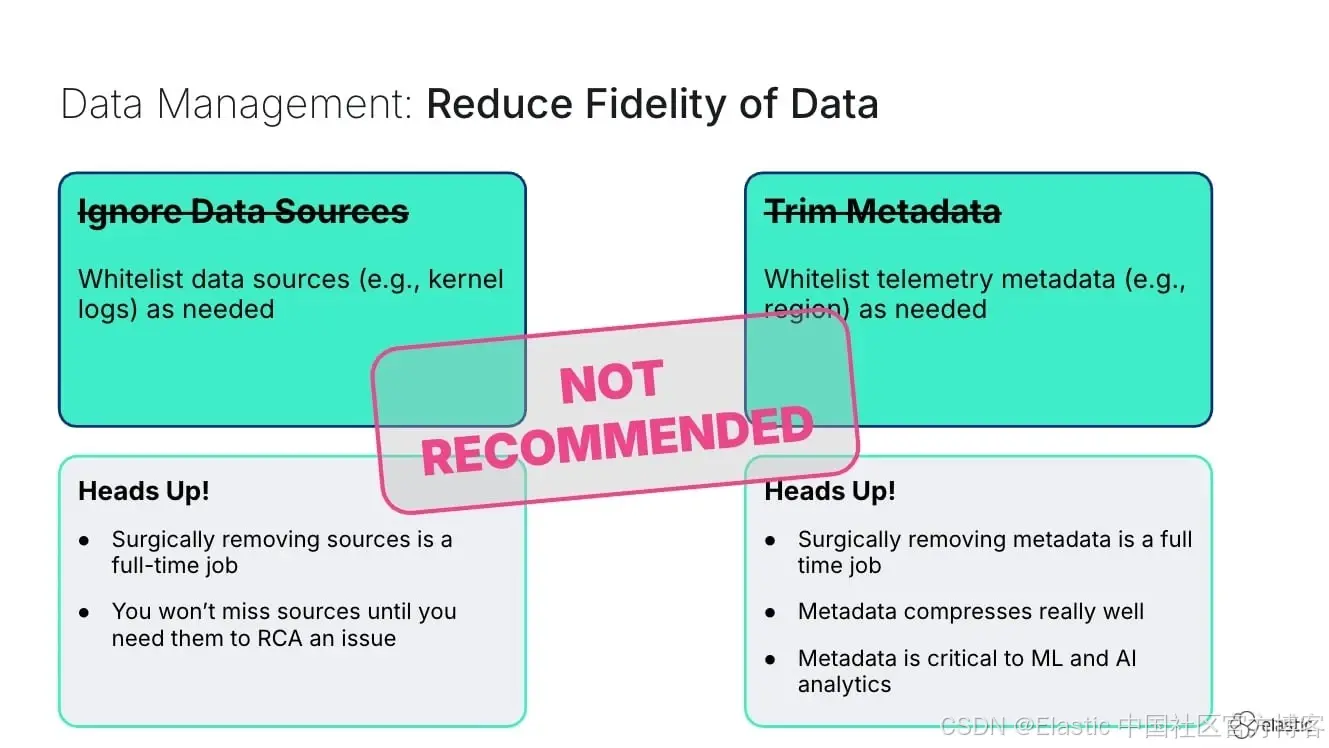
问题在于:ML 和 AI 系统依赖丰富的上下文数据。当你把 “噪音” 采样丢弃时,往往也丢掉了那些能够帮助你理解系统行为模式或预测故障的重要信号。与其问“我们如何收集更少的数据?”,更好的问题是 “我们如何以更具成本效益的方式存储和处理所有这些数据?”
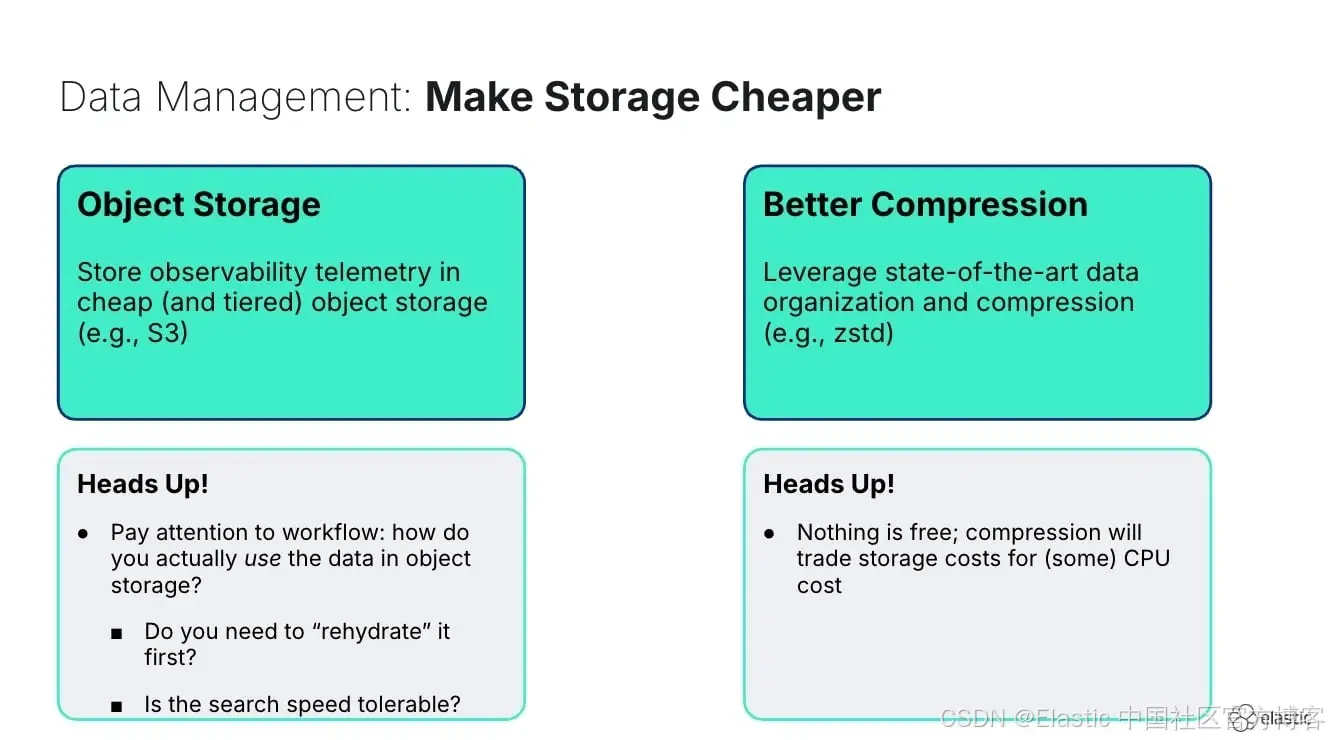
现代存储架构,特别是那些利用对象存储和 ZStandard 等高级压缩技术的架构,可以实现极高的性价比。关键在于把相关数据组织在一起,并快速转移到更便宜的存储层。这样的方法让你既能保留完整的数据保真度,又不会花费过高。
当然,这里需要平衡,并不是所有应用程序都相同,因此第一步你应该查看所有最关键的流程和应用,确保它们拥有最丰富的遥测数据。不要为了降低开销而对所有数据进行粗暴采样,当精确方法才是最优选择时。
OpenTelemetry (OTel):所有其他工具的基础
如果要在我的职业生涯中选择对可观测性最具变革性的单一改变,那就是 OpenTelemetry。不是因为它概念上炫酷或革命性,而是因为它解决了困扰我们多年的根本问题。
在 OTel 出现之前,给应用程序添加监控意味着供应商锁定。想从供应商 A 换到供应商 B?祝你好运,要重新在整个代码库中添加监控。想把相同的遥测数据发送到多个后端?希望你喜欢维护多个代理配置。
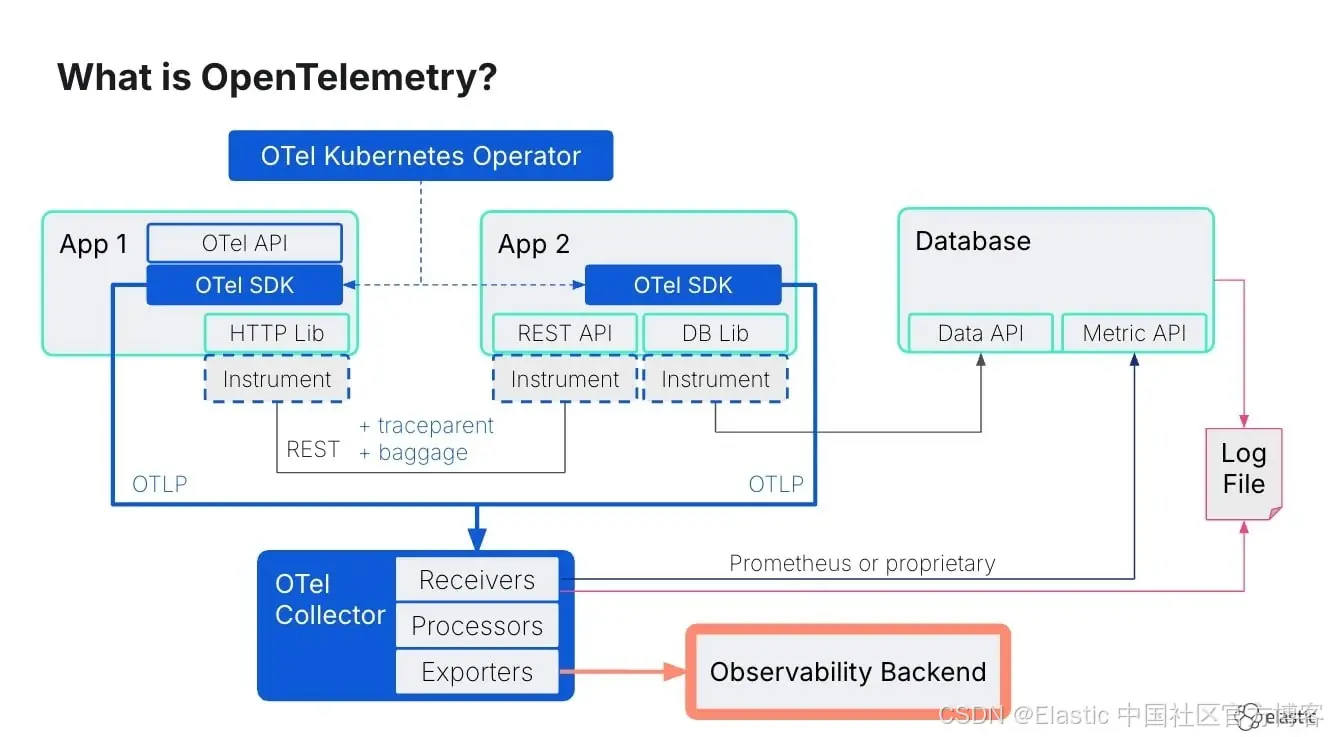
OpenTelemetry 完全改变了现状。原因有三:
- 供应商中立性:你的监控代码变得可移植。同一个 OTEL SDK 可以将数据发送到任何兼容的后端。
- OpenTelemetry 语义约定:所有遥测数据(日志、指标、追踪、性能分析、宽事件)共享通用元数据,如服务名称、资源属性和追踪上下文。
- 自动化监控:对于大多数流行语言和框架,你可以在不改动代码的情况下获得丰富的遥测数据。
OTEL 还使手动监控变得非常有价值且付出最小。比如在认证服务中添加一行代码:
baggage.set_baggage("customer.id", "alice123")
意味着客户 ID 会自动在每个下游服务调用、每次数据库查询、每条日志消息中流动。这样,你就可以在整个分布式系统中按客户 ID 搜索所有遥测数据。
发展趋势很明确:几年内,OTel 将像 Kubernetes 今天一样普及且无感知。运行时会默认包含它,云服务提供商会在边缘提供 OTel 收集器,框架将预装监控。
关联性:让一切衔接的秘诀

你收到一个高延迟的告警。你查看指标仪表板,95 百分位确实在飙升。切换到追踪系统,你能看到一些慢请求。再跳到日志系统,发现同一时间段有一些错误信息。现在有趣的部分来了:搞清楚哪些日志对应哪些追踪,它们是否与触发告警的指标相关。
这种上下文切换的噩梦,恰恰是正确关联可以消除的。当你的遥测数据共享通用标识符时,例如日志中的 trace ID、一致的服务名称、同步的时间戳,甚至客户 ID,你就可以在不同信号类型之间无缝切换而不丢失上下文。
但关联不仅仅是技术便利。当你可以按 customer.id 搜索所有日志,并立即看到该客户在系统中的追踪和指标时,你会彻底改变支持和调试的方式。当你可以按部署版本过滤整个可观测性堆栈,并瞬间了解发布的影响时,你会改变对部署的思考方式。
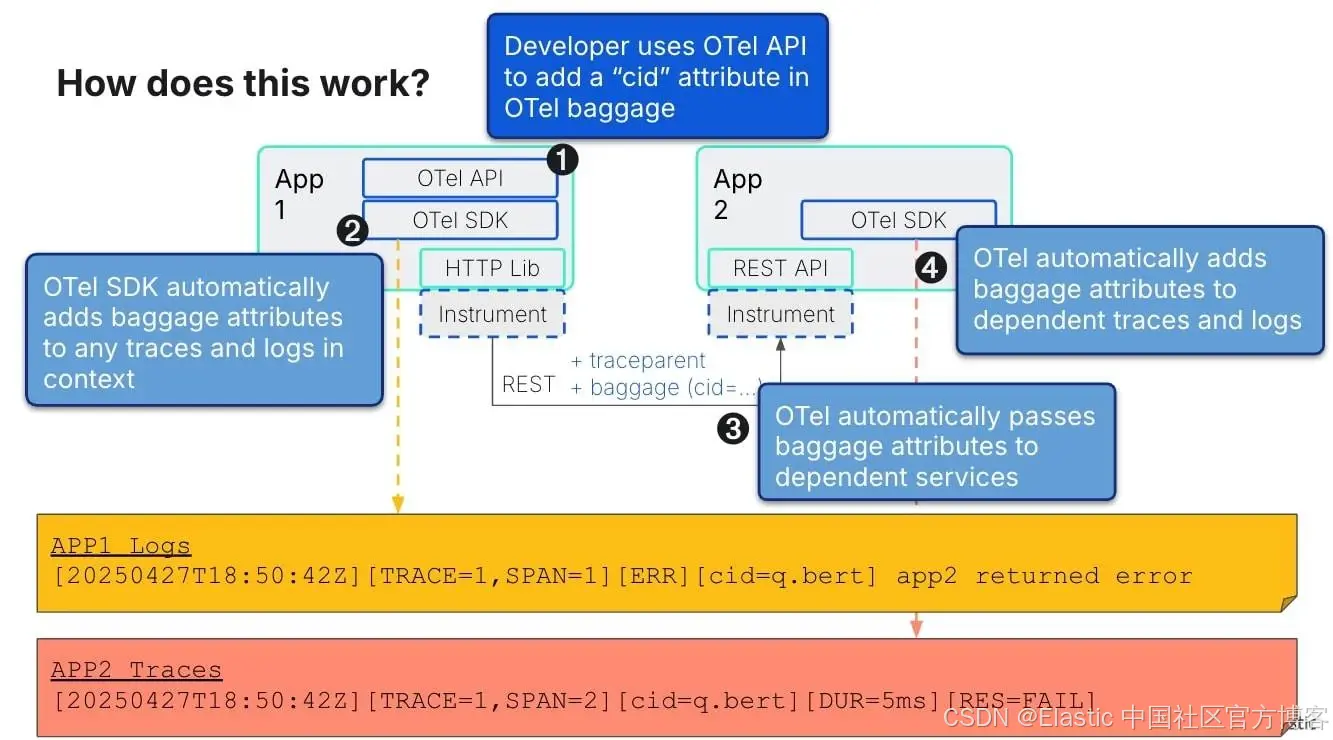
指标?没错,即使是指标也可以通过使用 OpenTelemetry exemplars 进行关联。例如,在 python 中,你可以这样开启 exemplars。
# Setup metrics with exemplars enabled
exemplar_filter = ExemplarFilter(trace_based=True)
exemplar_reservoir = ExemplarReservoir(
exemplar_filter=exemplar_filter,`
max_exemplars=5
)
这样就会将指标与正在发生的追踪关联,从而让一些指标与追踪相关联。
那么,为什么还要关联呢?
你可能会想,这很棒,我能看到这是一个有用的策略。当你把指标、日志和追踪分散在不同系统中时,这尤其有用。然而,很快你会意识到,当你可以把所有数据合并到一个单一数据结构中时,关联就显得非常费力,可以完全避免。可观测性行业也认同这一点,最近推崇一种新信号类型叫做 wide-events。
Wide-events 实际上就是高度结构化的日志,其理念是将指标数据、追踪数据和日志数据全部放入同一个宽数据结构中,从而简化分析。想想看,如果有一个单一数据结构,你就可以非常快速地运行查询和聚合,而无需进行可能很昂贵的数据关联。
此外,你还提高了每条日志记录的信息密度,这对于 AI 应用尤其有利。AI 得到一个上下文丰富的数据集进行分析,延迟极低,一条记录就有足够的描述能力,能够快速找到问题根本原因,而无需在其他数据存储中挖掘并尝试理解它们的模式。
LLM 尤其喜欢上下文,如果你能在不让它们去寻找的情况下提供所需的全部上下文,你的调查时间会显著减少。
这不仅仅是为了让 SRE 的工作更轻松(虽然确实如此),更是为了创建 AI 和 ML 系统理解基础设施行为模式所需的丰富、互联的数据集。
AI 驱动的调查
如今的可观测性工具在解决告警疲劳和仪表板问题方面已经相当出色,这方面已经非常成熟。告警关联和其他技术大大减少了这些领域的噪音,更不用说重点是根据 SLO 而非纯技术指标触发告警。过去几年,SRE 的生活在这方面确实变得更好了。
告警只是拼图的一部分,而最新的 AI 技术,使用 LLM 和智能代理 AI,可以在另一个环节 —— 调查阶段 —— 节省大量时间。想想看,调查通常是在发生故障时拖延时间的主要环节,在压力下的认知负荷对 SRE 来说非常真实且压力很大。
好消息是,当我们通过关联、丰富数据、采用 wide-events 并以全保真存储数据,将数据整理好后,我们就有工具帮助我们加速调查。
LLM 可以利用所有这些丰富的数据进行非常强大的分析,从而缩短调查时间。我们来看一个例子。
假设我们有以下基础日志。我们提供给 LLM 的数据量有限,它唯一能判断的是数据库发生了故障。
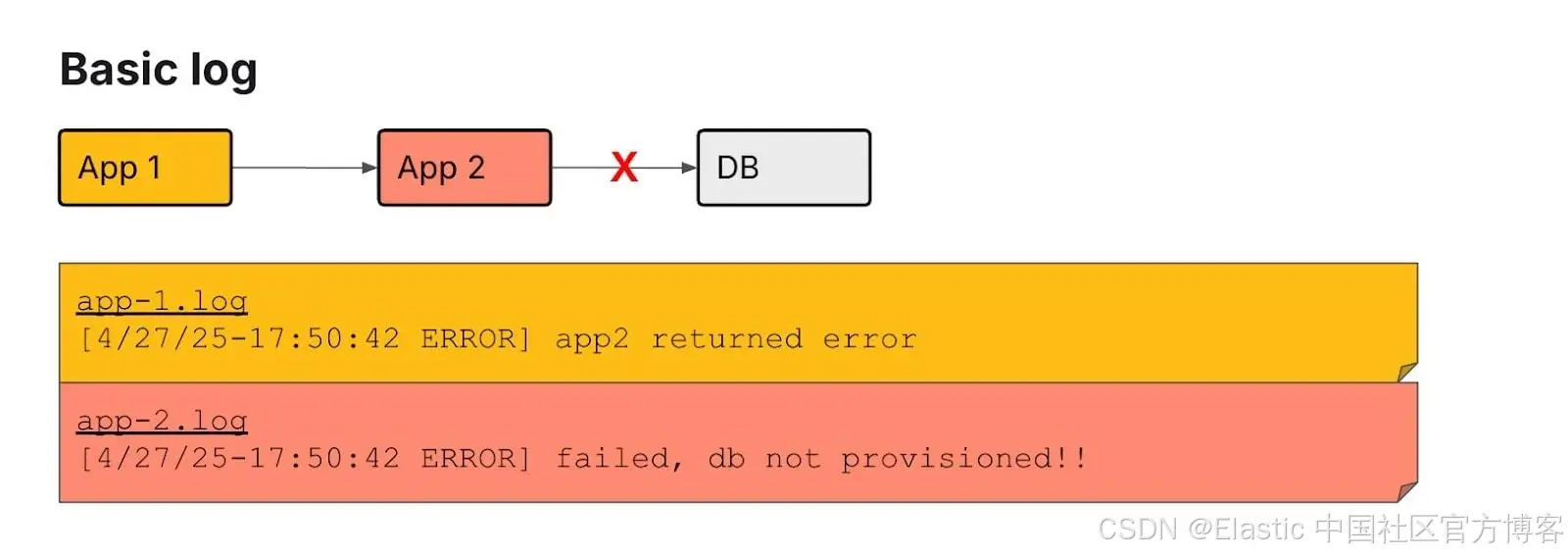
让我们看看使用 wide-event 后的情况,可以注意到已经有一些显著的好处。首先,我们只需查看来自单个节点的日志,即处理该请求的节点。我们不需要深入下游日志。这已经让 LLM 的工作更轻松;它不必去弄清楚如何关联多条日志、追踪和指标,当然,如果我们迫切需要查看下游系统,仍然可以使用关联 ID。

接下来,我们有了所有这些额外的丰富数据,LLM 可以用来推理发生了什么。LLM 在有上下文的情况下表现最佳,如果你能提供尽可能多的上下文,它们将更有效地减少调查时间。
| Field | How an LLM uses it |
|---|---|
|
trace_id ,parent_span_id |
Thread every hop together without parsing free-text |
|
status.code ,error.* |
Precise failure class; no NLP guess-work |
|
db.* |
Root-cause surface ("postgres isn't provisioned") |
|
user.id ,cloud.region |
Instant blast-radius queries |
|
deployment.version |
Correlation with new releases |
注意,我们没有去掉非结构化的错误信息,这仍然是有用的上下文!LLM 非常擅长处理非结构化文本,因此这段文本描述有助于它进一步理解问题。
大型语言模型在获取完整、上下文丰富的证据时表现最佳,这正是 wide-event 日志提供的内容。一次性投资于更丰富的日志,每一个下游 AI 工作流(摘要、异常检测、自然语言查询)都会变得更简单、更便宜、也更可靠。
面向未来的构建
展望未来,有三个趋势似乎不可避免:
-
OpenTelemetry 语义约定推动 wide-events:OTel 语义约定将像今天的日志一样成为标准,用于创建 wide-events。云提供商、运行时和框架将默认使用它。
-
利用 LLM 理解日志:提高数据丰富度以及让 LLM 自动增强现有日志的丰富度,将成为缩短调查时间的关键。
-
AI 将不可或缺:随着系统复杂性超过人类认知能力,AI 辅助将成为保持合理调查时间的必要手段。
现在开始构建面向未来的组织,通过采用 OpenTelemetry、投资更丰富的可观测性,并开始尝试 AI 辅助调试,在这些趋势加速时将获得显著优势。
下一步行动
如果你在自己的环境中面临可观测性差距,可以从这里开始:
-
评估你的日志:你的日志是否具有缩短调查时间所需的数据丰富度?LLM 能否提供额外上下文?
-
开始尝试 OpenTelemetry:即使不能立即迁移所有内容,为新服务添加 OTel 监控,并使用语义约定生成 wide-events,可以让你积累技术经验,并开始构建丰富的数据集。
-
添加高价值上下文:客户 ID、会话 ID、部署版本,甚至少量上下文元数据,都能显著提升调试能力。
-
超越存储成本考虑:不要简单采样数据,而是研究现代存储架构,使你能够以合理成本保存关键服务的所有数据。
复杂性的火箭已经发射离开发射台,而且不会减速。问题不在于你的可观测性策略是否需要演进,而在于你是主动演进还是被动应对。我知道哪种方式晚上睡得更安稳。
附加资源
原文:Pivoting Elastic's Data Ingestion to OpenTelemetry — Elastic Observability Labs

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)