Leveraging Segment Anything Model for Source-Free Domain Adaptation via Dual Feature Guided Auto-Pro
本文提出了一种创新方法DFG,将Segment Anything Model(SAM)引入无源源域自适应(SFDA)医学图像分割任务。通过双特征引导(目标模型和MedSAM特征)的自动提示搜索框架,解决了传统SFDA方法伪标签不准确和SAM需人工交互的问题。实验表明,DFG在跨模态腹部MRI/CT分割和前列腺MRI分割任务中,Dice系数显著优于现有方法(如腹部CT→MRI任务达84.9%)。该方
本文发表于IEEE Transactions on Medical Imaging,该期刊在医学影像领域处于顶尖水平,具有高影响力、严格审稿和高认可度等特征。中科院分区中位于 1 区,属于 Top 期刊;JCR 分区为 Q1 区 ,在多个小类学科如计算机跨学科应用、生物医学工程等也均处于 Q1 区,这表明该期刊在所属领域具有较高的学术地位。
一、论文核心背景与问题
1. 研究领域与痛点
本文聚焦医学图像分割中的无源源域自适应(SFDA) 问题。在临床场景中,深度学习模型常因扫描设备、成像协议差异产生“域偏移”——即基于源域数据(如CT图像)训练的模型,直接应用于目标域数据(如MRI图像)时性能大幅下降。
传统SFDA旨在仅利用预训练的源模型和无标注的目标数据实现域自适应,核心优势是保护源域敏感数据隐私、降低数据传输成本。但现有方法存在关键局限:
- 仅依赖源模型和目标数据的有限知识,易受域偏移影响产生错误伪标签;
- 无法有效利用通用基础模型的泛化能力,性能提升受限。
2. 创新切入点:引入Segment Anything Model(SAM)
SAM是预训练的通用分割模型,在给定边界框、点等提示时,可对多模态、多领域图像实现高精度零样本分割(如医学领域的MedSAM)。但直接应用SAM存在挑战:
- SFDA要求“全自动自适应”,而SAM默认需人工交互提供提示,不符合任务目标;
- 现有SFDA方法生成的边界框提示精度不足(因域偏移导致),无法满足MedSAM对提示准确性的要求(框过大/过小均会严重降低分割性能,见图1(a)(b))。
二、核心方法:双特征引导自动提示(DFG)框架
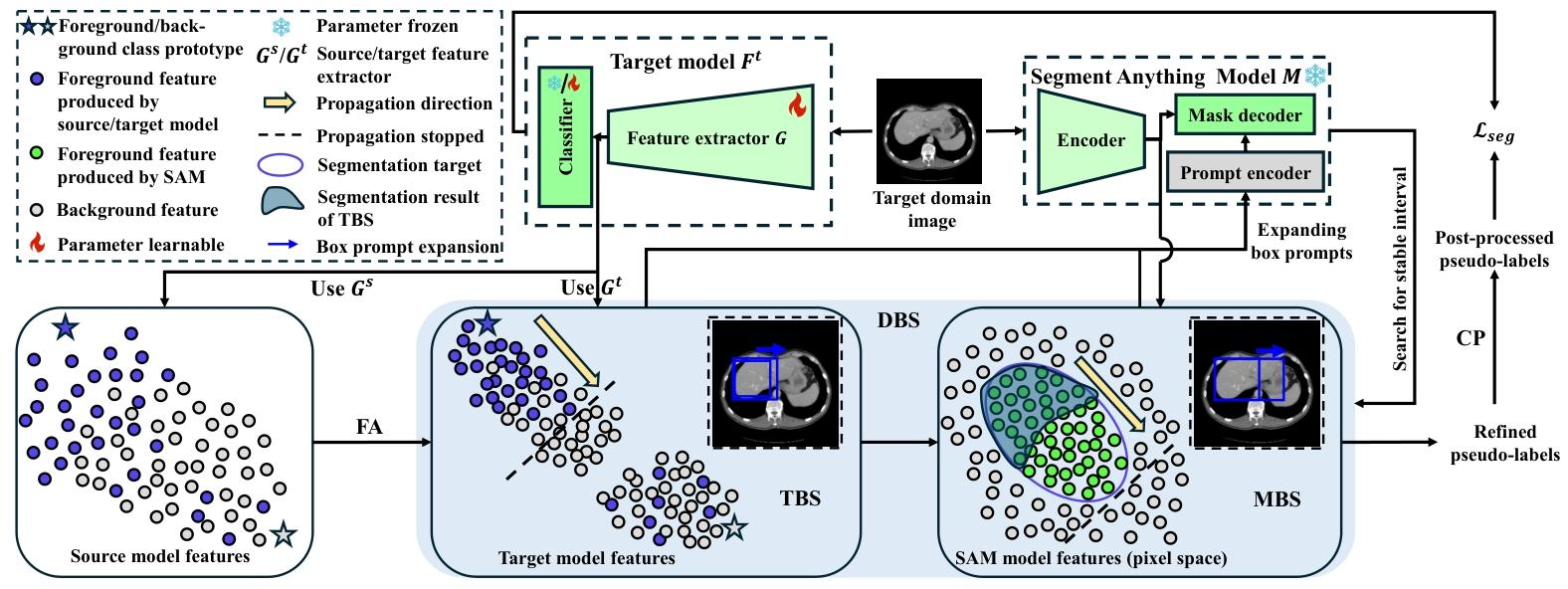
DFG框架通过“特征聚合→双特征引导提示搜索→连通性后处理”三阶段,实现SAM提示的全自动生成与伪标签优化,整体流程见图3。
1. 阶段1:特征聚合(FA)——为提示搜索打基础
目标
- 初步缓解域偏移,使源模型适应目标域;
- 构建“类内特征聚集、类间特征分离”的特征分布,为后续提示搜索提供结构支撑。
实现逻辑
- 初始化:将目标模型参数初始化为源模型参数,冻结源模型的分类器(分类器权重视为“类原型”);
- 损失设计:通过双项损失函数引导目标特征聚合:
- 第一项:最小化每个目标像素特征与类原型的距离,将特征拉向对应类原型,实现类内聚集;
- 第二项:确保每个类原型分配到足够多的目标特征,避免所有特征被拉向同一类(避免 trivial 解)。
关键输出
形成满足“类内特征亲和性”的目标特征分布——同一类别的目标特征虽受域偏移影响,但仍保持较近距离(见图2(a)右侧)。
2. 阶段2:双特征引导边界框提示搜索(DBS)——精准定位提示
针对特征聚合后存在的“类内聚集特征”和“类内分散特征”两类情况,分别通过目标模型特征和MedSAM特征引导提示扩展。
子阶段2.1:目标模型特征引导搜索(TBS)——处理类内聚集特征
核心思路
利用“目标模型类内特征聚集”和“MedSAM输出在真实边界附近波动时趋于稳定”的特性,逐步扩展提示框,直至覆盖所有聚集特征。
步骤
- 初始像素选择:通过自适应阈值筛选目标模型中对某类预测置信度最高的像素集I0I_0I0(避免类别不平衡影响);
- 特征传播扩展:迭代扩展像素集IjI_jIj——仅添加“与当前IjI_jIj特征相似度高(余弦相似度>0.99)且空间相邻”的像素(确保扩展方向正确);
- 稳定区间检测:每次扩展后生成对应边界框提示,计算MedSAM输出的像素变化量ΔM\Delta_MΔM(前后两次输出的差异像素数)。当ΔM\Delta_MΔM小于阈值时,判定进入稳定区间,停止扩展(此时框已接近真实边界,见图1(d)(e))。
子阶段2.2:MedSAM特征引导搜索(MBS)——处理类内分散特征
核心思路
MedSAM虽无任务特定类别语义,但因预训练数据量大、泛化能力强,其特征具有更优的“类内亲和性”(见图2(b)),可用于补充覆盖TBS未捕捉到的分散特征。
步骤
- MedSAM特征原型计算:以TBS输出的像素集为基础,计算MedSAM特征的“类原型”和“特征离散度”;
- 特征传播扩展:迭代添加“与MedSAM类原型距离小于阈值(由离散度动态调整)且空间相邻”的像素,避免将背景像素误纳入;
- 稳定区间检测:同TBS,通过ΔM\Delta_MΔM判断稳定区间,确定最终提示框。
3. 阶段3:连通性后处理(CP)——优化伪标签
问题
目标模型可能对部分区域过度自信,导致DBS生成的伪标签包含较大假阳性区域(如将背景误分为前景器官)。
解决方案
利用“医学图像中器官具有连续性”的先验知识,仅保留每个前景类伪标签中最大连通组件,剔除孤立的假阳性区域。
最终训练
用后处理后的伪标签通过Dice损失训练目标模型,完成域自适应。
三、实验验证与核心结论
1. 实验设置
数据集
- 腹部数据集:BTCV(CT)、CHAOS(MRI)、CURVAS(CT),涵盖跨模态(MRI→CT、CT→MRI)自适应,分割器官包括肝脏、左右肾脏、脾脏;
- 前列腺数据集:NCI-ISBI(MRI,源域)、QUBIQ(MRI,目标域),2D分割任务。
对比方法
- 传统SFDA方法:DPL、AdaMI、UPL、FVP、ProtoContra;
- 基线方法:“ProtoContra + MedSAM”(直接用ProtoContra输出生成MedSAM提示,验证 naive 结合的局限性)。
评价指标
- Dice系数(越高越好):衡量分割区域重叠度;
- 平均对称表面距离(ASSD,越低越好):衡量分割边界与真实边界的接近程度。
2. 核心实验结果
结果1:DFG性能显著优于现有方法
- 腹部数据集:在CT→MRI(BTCV→CHAOS)任务中,DFG平均Dice达84.9%,远超ProtoContra(74.4%)和“ProtoContra+MedSAM”(75.0%);ASSD降至1.99,仅为传统方法的1/3~1/5(见表1);
- 前列腺数据集:DFG的Dice达93.3%,接近全监督模型(94.4%),ASSD仅2.18,远低于ProtoContra的5.58(见表3)。
结果2:naive 结合SAM效果有限
直接用现有SFDA方法生成MedSAM提示(如“ProtoContra+MedSAM”),仅带来微小性能提升甚至性能下降(见表1中CT→MRI任务,ProtoContra的平均Dice从80.5%降至75.0%),证明DFG提示生成策略的必要性。
结果3:消融实验验证各组件有效性
- 仅FA:平均Dice达73.2%,证明特征聚合可初步缓解域偏移;
- FA+TBS:Dice提升至80.6%,验证目标模型特征引导的价值;
- FA+TBS+MBS:Dice进一步提升至82.9%,说明MedSAM特征可补充分散特征;
- 完整DFG(FA+TBS+MBS+CP):Dice达84.9%,ASSD显著降低,验证后处理对假阳性的抑制作用(见表4)。
结果4:优于SAM微调方案
用现有SFDA方法(ProtoContra)生成的伪标签微调SAM(如SAMed策略),平均Dice仅67.3%,甚至低于ProtoContra原性能(74.4%),证明“用DFG生成精准提示+冻结SAM”的方案优于“用低质量伪标签微调SAM”(见表6)。
四、关键结论与未来方向
1. 核心结论
- 创新价值:首次实现SAM在SFDA中的全自动应用,通过双特征引导提示生成,解决了“人工提示依赖”和“提示精度不足”两大痛点;
- 性能优势:DFG充分融合源模型的类别语义知识和SAM的通用分割能力,在跨模态、跨数据集医学图像分割任务中显著优于现有SFDA方法;
- 效率保障:MedSAM仅需一次编码器推理(提取图像嵌入后重复使用),提示搜索额外开销小,且训练参数仅为目标分割网络,计算成本可控(见表8)。
2. 局限性与未来方向
- 失败案例:对超大器官(特征变异性大)、MedSAM输出不稳定区域,提示搜索可能失效(见图7);
- 未来优化方向:
- 设计更鲁棒的稳定区间检测准则;
- 探索源模型与SAM知识的更深层次融合(如特征级融合);
- 适配轻量级MedSAM,进一步降低计算成本。
五、总结
本文的核心贡献在于打通了通用基础模型(SAM)与无源源域自适应的结合路径:通过DFG框架的特征聚合与双特征引导策略,实现了SAM提示的全自动、高精度生成,既保留了SFDA的隐私保护优势,又借助SAM的泛化能力突破了传统方法的性能瓶颈。实验结果验证了该方法在医学图像分割中的实用性,为跨机构模型共享、临床数据隐私保护提供了新的技术方案。https:// github.com/xmed-lab/DFG
Leveraging Segment Anything Model for Source-Free Domain Adaptation via Dual Feature Guided Auto-Prompting

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)