构建AI智能体:二十一、精准检索“翻译官”:qwen-turbo在RAG Query改写中的最佳实践
因为用户的自然提问方式与知识库的客观组织方式天生存在不可调和的差异。如果不进行改写,直接将原始查询用于检索,就如同让一个不懂检索的人自己去漫无目的地查字典,结果往往是找不到、找错了或找到的没法用。Query 改写是保障 RAG 系统可靠性、准确性和可用性的“第一道防线”和“核心基础设施”。它通过一系列技术手段,将用户的意图“翻译”成检索器能高效理解的语言,从而确保后续步骤能在一个高质量的基础上进行
一、必不可少

回忆我们日常的场景中,有时候我们使用百度或Google,要得到一个问题的答案,似乎来来回回换了很多次问法,才得到了我们期望的答案,或者到最后都没有获取预期的结果,这是为什么呢?
这里存在一个核心矛盾,我们的“问法”和知识库的“存法”有着极大的差异,我们在提问过程中(Query)灵活、多变、口语化、不完整且没有标明依赖背景,比如会问“电脑卡死了咋办”、“LLM和AI有啥关系”等,知识库的存法都是固定、规范、目录、索引且自成体系的结构化内容,如果直接将两者匹配,就像是用独特的方言和普通话交流,对两者来说都可能是晦涩难懂,不一定是完全失败,但失败的概率会非常大,寻求问题的答案,自然是需要追求更大的成功率,所以对请求提问(Query)的改写是很有必要且必不可少的。
二、什么是Query改写
-
核心定义
Query 改写是指在 RAG 系统的检索阶段之前,对用户输入的原始查询(Query)进行一系列处理、扩展或重构的技术,旨在生成一个或多个对检索器(Retriever)更友好、更能匹配知识库中相关文档的“新查询”。
-
主要工作
把我们的“原始查询”,通过适合的方法加工翻译成知识库能听懂、能高效执行的“改写后的查询”。
三、为什么需要Query改写
由于每个人的不同的思维都会有独特的提问方式和术语,导致我们输入的原始查询会存在以下的一些偏差:
-
简短模糊: “如何解决这个问题?” -> “这个问题”指代不明。
-
缺乏上下文: 在多轮对话中,用户可能说“那上一个方法呢?”,缺乏指代。
-
表述不专业: 用户使用口语化或错误术语,而知识库使用规范术语。
-
信息缺失: 问题隐含了未明说的前提条件或意图。
-
语义鸿沟: 用户的问法和文档中的答法在表述上不一致。
如果直接将这样的原始查询扔给检索器(如向量数据库做相似性搜索),很可能检索到不相关或次相关的文档,导致后续的生成阶段(Generator)产生“胡言乱语”或答非所问的情况。
因此,Query 改写的终极目标是:提升检索召回率(Recall)和精确率(Precision),为答案生成奠定高质量的上下文基础。
四、Query不该写会有什么影响
如果不对 Query 做任何处理,直接扔给检索器(比如向量数据库做语义搜索),会出现一些问题:
1. 召回失败(Recall Failure):根本找不到答案
问题:用户问:“苹果股价咋样了?”(用了口语“咋样”和品牌“苹果”)
答案:知识库里的文档标题是:《Apple Inc. (AAPL) 2024年Q2财报与股价分析》。
偏差:虽然“苹果”和“Apple”语义相似,但“咋样”和“财报分析”的匹配度很低。检索器可能无法将这篇最相关的文档排到最前面,甚至完全找不到它。用户得到的结果是“未找到相关信息”或一个不相关的答案。
2. 精度失败(Precision Failure):找到错误的答案
问题:用户问:“Python怎么装?”(想安装Python语言环境)
答案:知识库里还有一篇文档叫《如何在Python中安装PyTorch包(Using Pip)》。
后果:检索器发现“Python”和“安装”这两个词都高度匹配,很可能将这篇关于“安装包”的文档错误地排在第一位。最终大模型根据这篇错误文档,开始教用户如何使用pip install,完全答非所问。
3. 上下文低效(Ineffective Context):找到的文档无法用于生成
问题:用户问:“总结一下Transformer的创新点。”
答案:知识库里最相关的是一篇50页的论文《Attention Is All You Need》。
偏差:检索器成功找对了文档!但它把整整50页的论文全部作为上下文扔给了大模型。最终大模型的输入长度有限,可能被迫截断后面的内容;同时,过多的无关信息也会干扰大模型的判断,导致它无法生成一个精炼、准确的总结。
五、怎么去做Query改写
1. 补充细节:把模糊的话变具体。
-
如果问:“上次说的那个事?”(啥事?)
-
改写为:“关于上周三会议上讨论的预算增加方案。”(这下清楚了!)
2. 更换说法:把口语化的词换成知识库里正式的词。
-
如果问:“电脑卡死了咋办?”
-
改写为:“计算机响应缓慢故障排除的解决方案”(术语对齐,一找一个准)
3. 多角度提问:怕一种问法搜不到,就换几种方式都问问。
-
如果问:“这个 error 是啥意思?”
-
改写后则会同时问:“这个错误代码的含义”、“如何解决这个错误”、“这个错误的常见原因”(这样搜到的答案更全面!)
4. 猜你想要啥:根据你的问题,直接“脑补”出一段答案,然后用这段答案去匹配相似的文档。
-
如果问:“怎么泡茶好喝?”
-
改写会“脑补”出一段话:“要选择好水,控制水温,绿茶80度,红茶100度……”,然后用这段“脑补”的专业描述:去知识库找,更容易找到《茶艺入门》这种专业文档,而不是只匹配“泡茶”、“好喝”这种词。
通过Query改写,检索器能找到真正相关的文档,大模型才能更准确的分析得出让我们满意的答案。
如果没有这一步,就好比再厉害的厨师,用一堆错误的食材,也做不出好菜。所以,Query改写是确保RAG系统聪明好用的第一步,也是至关重要的一步。
六、Query改写的类型
以下改写类型都是结合 qwen-turbo-latest模型的Query改写演示:
1. 上下文依赖型
-
定义:用户的当前查询严重依赖之前的对话历史或未明说的上下文背景,孤立地看当前查询则无法理解其真实意图。
-
挑战:检索器看不到对话历史,直接检索会因信息缺失而失败。
-
改写策略:将关键的上下文信息显式地融入当前查询中,生成一个独立、完整的查询。
-
示例:对话历史:
用户:介绍一下苏轼。
AI:苏轼,字子瞻,号东坡居士,北宋著名文学家...
用户:他的词风呢?
原始查询:他的词风呢? (检索器无法理解“他”指谁)
改写后查询:苏轼的词风特点是什么?
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_context_dependent_query(self, current_query, conversation_history):
"""上下文依赖型Query改写"""
instruction = """
你是一个智能的查询优化助手。请分析用户的当前问题以及前序对话历史,判断当前问题是否依赖于上下文。
如果依赖,请将当前问题改写成一个独立的、包含所有必要上下文信息的完整问题。
如果不依赖,直接返回原问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例1: 上下文依赖型Query
print("示例1: 上下文依赖型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了'疯狂动物城'主题园区,这里有朱迪警官和尼克狐的互动体验。"
用户: "这个园区有什么游乐设施?"
AI: "'疯狂动物城'园区目前有疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店等设施。"
"""
current_query = "还有其他设施吗?"
print(f"对话历史: {conversation_history}")
print(f"当前查询: {current_query}")
result = rewriter.rewrite_context_dependent_query(current_query, conversation_history)
print(f"改写结果: {result}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例1: 上下文依赖型Query
对话历史:
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了'疯狂动物城'主题园区,这里有朱迪警官和尼克狐的互动体验。"
用户: "这个园区有什么游乐设施?"
AI: "'疯狂动物城'园区目前有疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店等设施。"
当前查询: 还有其他设施吗?
改写结果: 除了疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店之外,'疯狂动物城'园区还有其他游乐设施吗?2. 对比型
-
定义:用户意图是对两个或多个实体、概念进行对比、比较其异同或优劣。
-
挑战:直接检索可能只能找到分别描述单个实体的文档,而找不到直接的对比资料。
-
改写策略:在查询中显式添加“vs”、“与”、“区别”、“对比”、“优缺点”等比较性词汇。
-
示例:
原始查询:Transformer 和 RNN
改写后查询:Transformer 与 RNN 的区别和优缺点对比
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_comparative_query(self, query, context_info):
"""对比型Query改写"""
instruction = """
你是一个查询分析专家。请分析用户的输入和相关的对话上下文,识别出问题中需要进行比较的多个对象。
然后,将原始问题改写成一个更明确、更适合在知识库中检索的对比性查询。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史/上下文信息 ###
{context_info}
### 原始问题 ###
{query}
### 改写后的查询 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例2: 对比型Query
print("示例2: 对比型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了疯狂动物城主题园区,还有蜘蛛侠主题园区"
"""
current_query = "哪个游玩的时间比较长,比较有趣"
print(f"对话历史: {conversation_history}")
print(f"当前查询: {current_query}")
result = rewriter.rewrite_comparative_query(current_query, conversation_history)
print(f"改写结果: {result}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例2: 对比型Query
对话历史:
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了疯狂动物城主题园区,还有蜘蛛侠主题园区"
当前查询: 哪个游玩的时间比较长,比较有趣
改写结果: 哪个游玩时间更长、更有趣:上海迪士尼乐园的疯狂动物城主题园区和蜘蛛侠主题园区?3. 模糊指代型
-
定义:查询中使用了一些代词(这个、那个)、口语化词汇或省略语,导致所指不明。
-
挑战:知识库中的文档使用明确、规范的语言,无法匹配模糊的指代。
-
改写策略:根据对话历史或常识,将模糊指代替换为具体的实体名称或规范术语。
-
示例:
原始查询:你们那个新品什么时候上线? (“那个新品”指代不明)
改写后查询:智能手表产品 Galaxy Watch 7 的预计上市发布时间
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_ambiguous_reference_query(self, current_query, conversation_history):
"""模糊指代型Query改写"""
instruction = """
你是一个消除语言歧义的专家。请分析用户的当前问题和对话历史,找出问题中 "都"、"它"、"这个" 等模糊指代词具体指向的对象。
然后,将这些指代词替换为明确的对象名称,生成一个清晰、无歧义的新问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例3: 模糊指代型Query
print("示例3: 模糊指代型Query")
conversation_history = """
用户: "我想了解一下上海迪士尼乐园和香港迪士尼乐园的烟花表演。"
AI: "好的,上海迪士尼乐园和香港迪士尼乐园都有精彩的烟花表演。"
"""
current_query = "都什么时候开始?"
print(f"对话历史: {conversation_history}")
print(f"当前查询: {current_query}")
result = rewriter.rewrite_ambiguous_reference_query(current_query, conversation_history)
print(f"改写结果: {result}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例3: 模糊指代型Query
对话历史:
用户: "我想了解一下上海迪士尼乐园和香港迪士尼乐园的烟花表演。"
AI: "好的,上海迪士尼乐园和香港迪士尼乐园都有精彩的烟花表演。"
当前查询: 都什么时候开始?
改写结果: 上海迪士尼乐园和香港迪士尼乐园的烟花表演都什么时候开始?4. 多意图型
-
定义:一个查询中包含了多个独立的问题或意图。回答它需要从知识库中多个不同部分检索信息。
-
挑战:单一查询检索,可能只能匹配到其中一个意图的文档,导致回答不全。
-
改写策略:将复合查询分解成多个原子性的子查询,分别进行检索,最后再整合答案。
-
示例:
原始查询:请介绍公司的创始人背景以及目前的主要产品线。
改写后查询:
[公司名称] 创始人 背景 经历
[公司名称] 当前 主要产品线 有哪些
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_multi_intent_query(self, query):
"""多意图型Query改写 - 分解查询"""
instruction = """
你是一个任务分解机器人。请将用户的复杂问题分解成多个独立的、可以单独回答的简单问题。以JSON数组格式输出。
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始问题 ###
{query}
### 分解后的问题列表 ###
请以JSON数组格式输出,例如:["问题1", "问题2", "问题3"]
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return [response]
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例4: 多意图型Query
print("示例4: 多意图型Query")
query = "门票多少钱?需要提前预约吗?停车费怎么收?"
print(f"原始查询: {query}")
result = rewriter.rewrite_multi_intent_query(query)
print(f"分解结果: {result}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例4: 多意图型Query
原始查询: 门票多少钱?需要提前预约吗?停车费怎么收?
分解结果: ['门票多少钱?', '需要提前预约吗?', '停车费怎么收?']5. 反问型
-
定义:用户以反问或否定句的形式提出问题,但其真实意图是肯定性的。
-
挑战:检索器可能被反问的语气或否定词误导,去检索“为什么不”的原因,而不是如何做。
-
改写策略:识别出反问句背后的真实肯定性意图,并将其转换为中性的、正向的查询。
-
示例:
原始查询:难道就没有更快的方法了吗? (情绪化、否定)
改写后查询:提高 [某项任务] 执行速度的优化方法或高效技巧
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def rewrite_rhetorical_query(self, current_query, conversation_history):
"""反问型Query改写"""
instruction = """
你是一个沟通理解大师。请分析用户的反问或带有情绪的陈述,识别其背后真实的意图和问题。
然后,将这个反问改写成一个中立、客观、可以直接用于知识库检索的问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
return get_completion(prompt, self.model)
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例5: 反问型Query
print("示例5: 反问型Query")
conversation_history = """
用户: "你好,我想预订下周六上海迪士尼乐园的门票。"
AI: "正在为您查询... 查询到下周六的门票已经售罄。"
用户: "售罄是什么意思?我朋友上周去还能买到当天的票。"
"""
current_query = "这不会也要提前一个月预订吧?"
print(f"对话历史: {conversation_history}")
print(f"当前查询: {current_query}")
result = rewriter.rewrite_rhetorical_query(current_query, conversation_history)
print(f"改写结果: {result}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例5: 反问型Query
对话历史:
用户: "你好,我想预订下周六上海迪士尼乐园的门票。"
AI: "正在为您查询... 查询到下周六的门票已经售罄。"
用户: "售罄是什么意思?我朋友上周去还能买到当天的票。"
当前查询: 这不会也要提前一个月预订吧?
改写结果: 迪士尼乐园门票是否需要提前一个月预订?6. 总结
|
类型 |
核心特征 |
改写策略 |
|
上下文依赖型 |
依赖历史对话 |
补全上下文 |
|
对比型 |
比较两个事物 |
添加比较词 |
| 模糊指代型 |
使用代词、口语 |
替换为具体术语 |
|
多意图型 |
一个问题多部分 |
分解为子查询 |
|
反问型 |
否定、反问语气 |
转为正向意图 |
七、Query意图识别
-
定义:它指的是系统需要先理解用户查询的深层目的(是问定义、查步骤、要对比,还是故障排查)。
-
挑战:不同的意图需要不同的改写策略和检索优化(如添加过滤器)。
-
改写策略:首先对查询进行意图分类,然后根据分类结果应用特定的改写模板或策略。
-
示例1:
原始查询:Python list comprehension
意图识别:询问定义
改写策略:添加“是什么”、“介绍”、“概念”等词。
改写后查询:Python list comprehension 的概念是什么?
-
示例2:
原始查询:如何用 Python list comprehension 过滤数据?
意图识别:询问操作方法
改写策略:添加“步骤”、“方法”、“示例”等词。
改写后查询:使用 Python list comprehension 过滤数据的步骤与示例
下图描绘了结合 qwen-turbo-latest 模型的Query改写智能决策流程:
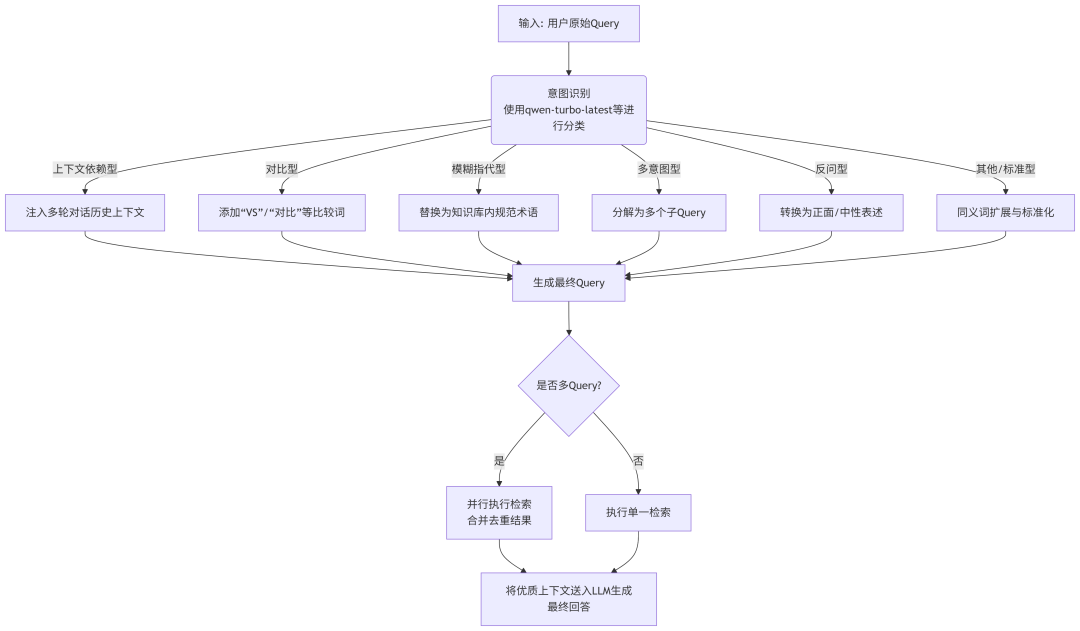
流程解读:
1. 入口:流程始于接收用户的原始Query。
2. 核心决策点(意图识别):首先使用 qwen-turbo-latest 等模型对Query进行意图分类。这是整个流程的“大脑”,决定了后续的改写策略。常见的意图类别包括:定义、操作、对比、故障排除等。
3. 策略分支:根据识别出的意图,进入不同的专用处理通道:
-
上下文依赖型:会查询对话历史,将缺失的上下文补全到当前Query中。
-
对比型:会显式地在Query中添加比较词汇。
-
模糊指代型:会调用一个术语表或另一个LLM调用,将模糊指代具体化。
-
多意图型:会被分解成多个独立的子Query,这是最关键的一步。
-
反问型:会进行“否定转肯定”的语义转换。
-
标准型:对于没有特殊意图的查询,进行基础的扩展和规范化。
4. 生成与检索:所有分支最终汇合,生成最终的一个或多个优化后的Query,送入检索器。
-
如果是多Query(如多意图型分解后),则会并行执行检索,并将结果合并、去重、重排,得到最全面的上下文。
-
如果是单一Query,则直接执行检索。
5. 出口:将检索到的优质上下文文档与原始Query一起,送给LLM(如 qwen-turbo-latest )生成最终准确、可靠的回答。
这个流程图展示了一个成熟RAG系统处理Query的完整逻辑链,其中意图识别是触发不同改写策略的开关,而 specialized 的改写策略是精准命中知识库内容的关键。
代码演示:
# Query改写使用示例
# 导入依赖库
import dashscope
import os
import json
# 从环境变量中获取 API Key
dashscope.api_key = os.getenv('DASHSCOPE_API_KEY')
# 基于 prompt 生成文本
def get_completion(prompt, model="qwen-turbo-latest"):
messages = [{"role": "user", "content": prompt}]
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message',
temperature=0,
)
return response.output.choices[0].message.content
# Query改写功能
class QueryRewriter:
def __init__(self, model="qwen-turbo-latest"):
self.model = model
def auto_rewrite_query(self, query, conversation_history="", context_info=""):
"""自动识别Query类型并进行改写"""
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,识别其属于以下哪种类型:
1. 上下文依赖型 - 包含"还有"、"其他"等需要上下文理解的词汇
2. 对比型 - 包含"哪个"、"比较"、"更"、"哪个更好"、"哪个更"等比较词汇
3. 模糊指代型 - 包含"它"、"他们"、"都"、"这个"等指代词
4. 多意图型 - 包含多个独立问题,用"、"或"?"分隔
5. 反问型 - 包含"不会"、"难道"等反问语气
说明:如果同时存在多意图型、模糊指代型,优先级为多意图型>模糊指代型
请返回JSON格式的结果:
{
"query_type": "查询类型",
"rewritten_query": "改写后的查询",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 上下文信息 ###
{context_info}
### 原始查询 ###
{query}
### 分析结果 ###
"""
response = get_completion(prompt, self.model)
try:
return json.loads(response)
except:
return {
"query_type": "未知类型",
"rewritten_query": query,
"confidence": 0.5
}
def main():
# 初始化Query改写器
rewriter = QueryRewriter()
print("=== Query改写功能使用示例(迪士尼主题乐园) ===\n")
# 示例6: 自动识别Query类型
print("示例6: 自动识别Query类型")
test_queries = [
"还有其他游乐项目吗?",
"哪个园区更好玩?",
"都适合小朋友吗?",
"有什么餐厅?价格怎么样?",
"这不会也要排队两小时吧?"
]
for i, query in enumerate(test_queries, 1):
print(f"测试查询 {i}: {query}")
result = rewriter.auto_rewrite_query(query)
print(f" 识别类型: {result['query_type']}")
print(f" 改写结果: {result['rewritten_query']}")
print(f" 置信度: {result['confidence']}\n")
if __name__ == "__main__":
main() 输出结果:
=== Query改写功能使用示例(迪士尼主题乐园) ===
示例6: 自动识别Query类型
测试查询 1: 还有其他游乐项目吗?
识别类型: 上下文依赖型
改写结果: 除了已知的游乐项目外,还有哪些其他游乐项目?
置信度: 0.95
测试查询 2: 哪个园区更好玩?
识别类型: 对比型
改写结果: 请比较各个园区的娱乐性,指出哪个更好玩。
置信度: 0.95
测试查询 3: 都适合小朋友吗?
识别类型: 模糊指代型
改写结果: 哪些产品或活动适合小朋友?
置信度: 0.95
测试查询 4: 有什么餐厅?价格怎么样?
识别类型: 多意图型
改写结果: 有哪些餐厅?这些餐厅的价格怎么样?
置信度: 0.95
测试查询 5: 这不会也要排队两小时吧?
识别类型: 反问型
改写结果: 这需要排队两小时吗?
置信度: 0.95八、总结
因为用户的自然提问方式与知识库的客观组织方式天生存在不可调和的差异。如果不进行改写,直接将原始查询用于检索,就如同让一个不懂检索的人自己去漫无目的地查字典,结果往往是找不到、找错了或找到的没法用。
Query 改写是保障 RAG 系统可靠性、准确性和可用性的“第一道防线”和“核心基础设施”。它通过一系列技术手段,将用户的意图“翻译”成检索器能高效理解的语言,从而确保后续步骤能在一个高质量的基础上进行。没有它,再强大的大模型也只会是“巧妇难为无米之炊”,甚至“做出一锅坏饭”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)