【大模型】KG+LLM:知识增强的核心技术栈与创新实践全景图——揭秘下一代理解与生成任务的核心驱动力与落地挑战。
本文探讨了知识增强在大语言模型中的重要性与实践路径。首先分析了知识的本质及其结构性、因果性和应用性特征,指出知识增强可解决大模型在事实一致性、时效性和因果推理方面的不足。随后详细介绍了知识嵌入技术及其在问答系统、文本摘要等任务中的具体应用,并提出了控制事实一致性的四大技术路径。文章还总结了六种典型的知识增强模型创新方案,包括K-BERT、CoKE等代表性方法。最后指出知识增强是提升大模型可信度和推
给AI注入“灵魂”:知识增强才是大模型构建世界观的基石。一份从理论到实践的完整链条,深度理解LLM背后的智慧之源。
Part 1
概述:什么是“知识”?
为何要“增强”?
在大模型时代,模型能力不仅取决于参数规模和语言结构,还依赖对知识的融合能力。我们首先要理解“知识”是什么,具有什么特性,又为何需要对模型进行“知识增强”。
知识的本质与关键属性
-
知识是人类对世界的总结,可用于指导行为、解释现象、预测结果。
-
与数据或信息相比,知识具备更强的结构性、因果性与应用性。
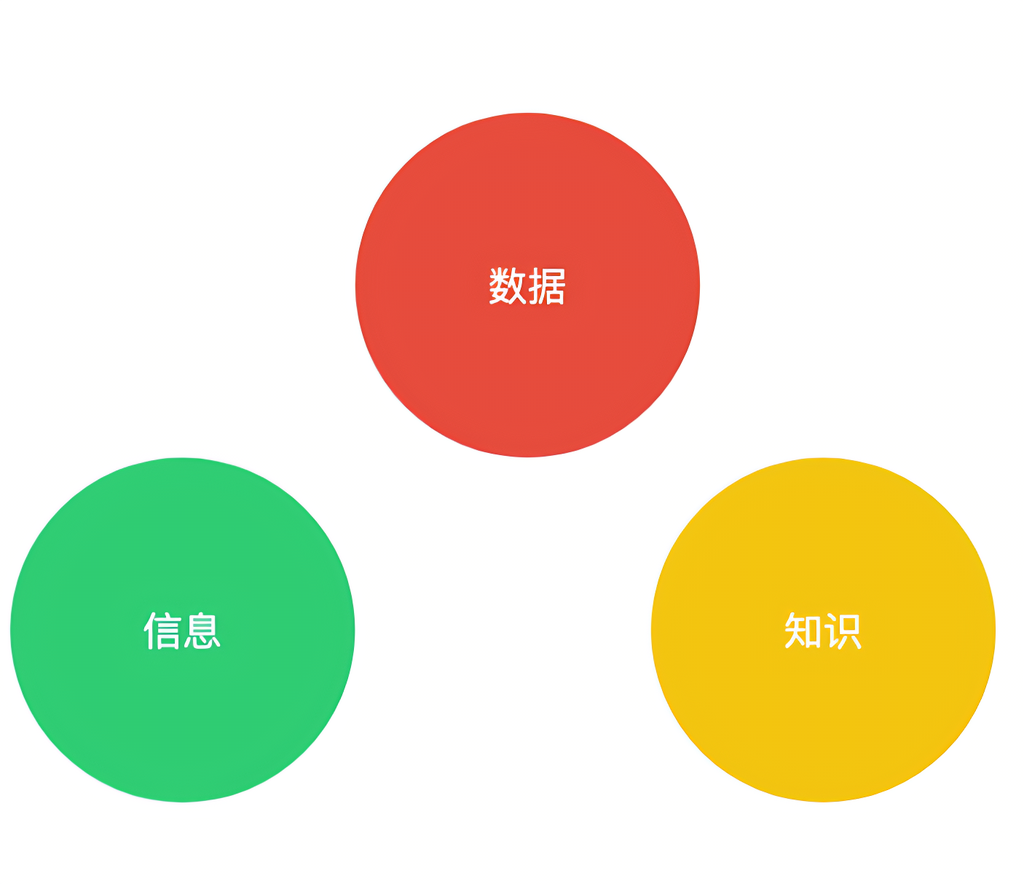
三大核心属性:
-
客观性:能反映客观规律,经验证真。
-
系统性:知识之间有内在联系,构成网络。
-
可传递性:可以通过语言、经验传授与共享。
知识的分类视角
-
按内容划分:
-
-
事实性知识(Know-What):如“巴黎是法国首都”;
-
原理性知识(Know-Why):如“水因温度升高会蒸发”;
-
技能性知识(Know-How):如“如何搭建神经网络”。
-
按形式划分:
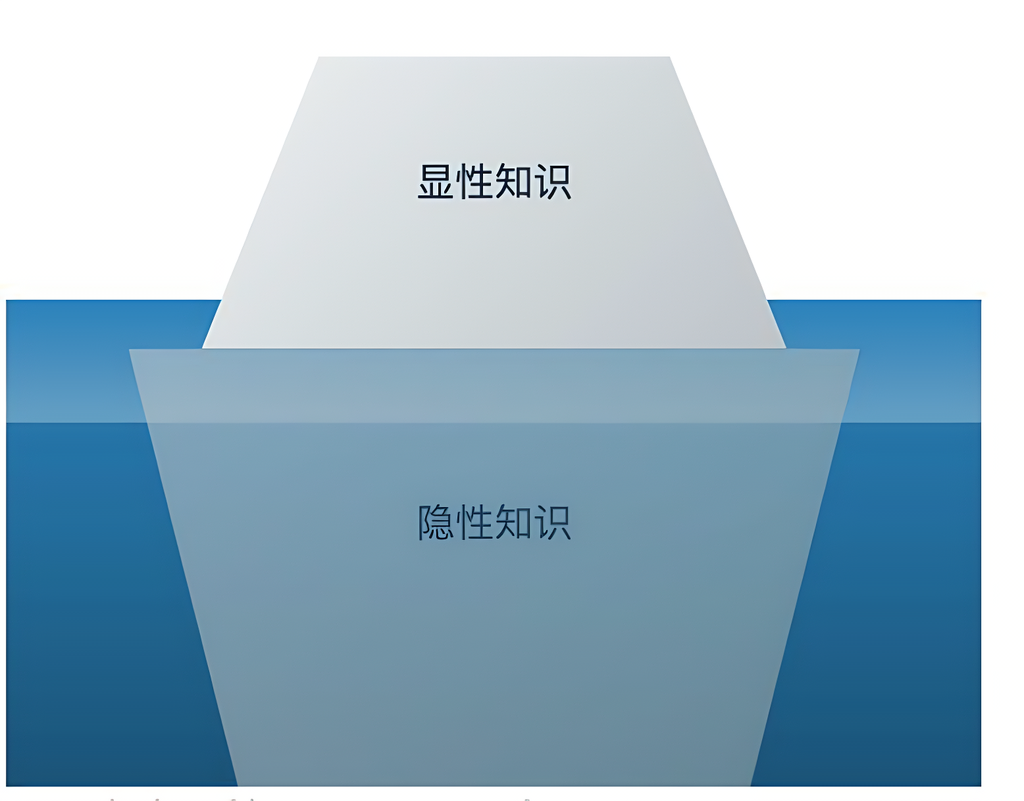
-
显性知识(Explicit):如课本、文档;
-
隐性知识(Tacit):如经验、直觉。
为什么大模型需要知识增强?
-
传统语言模型训练依赖海量文本,但缺乏对“事实一致性”“时效性”“因果推理”的控制;
-
面对多跳推理、专业问答、开放场景生成任务时容易产生幻觉(hallucination);
-
知识增强是解决上述问题的关键手段,提升模型的推理性、解释性、可信度。
Part 2
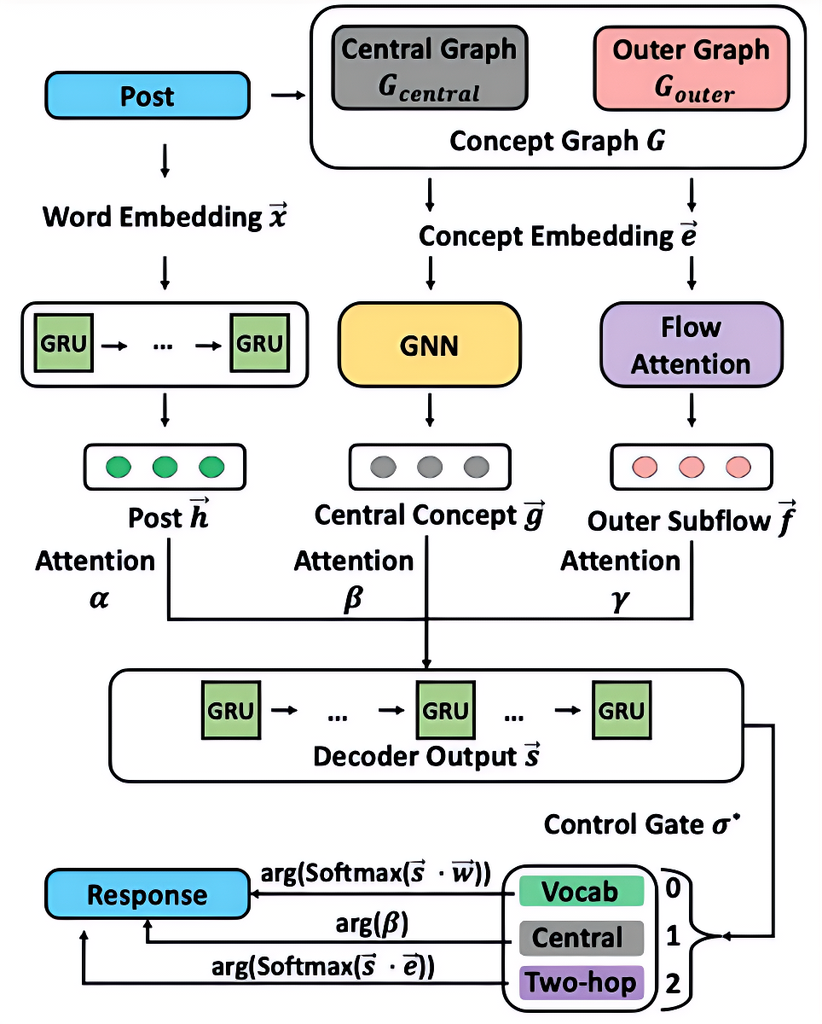
知识嵌入:
在生成任务中的路径与落地方式
知识嵌入(Knowledge Embedding)是知识增强的第一步,它指的是:将知识图谱、实体关系等转换成稠密向量,使得语言模型能够识别、理解和使用它们。
核心概念回顾
什么是“知识嵌入”?
-
把人类知识(如“华盛顿→是→美国首都”)转为计算可用的向量表示。
核心价值:
-
打破传统符号逻辑对模型的限制;
-
实现语言与知识的语义融合计算;
-
提升模型对“关系”、“事实”及“背景”的理解能力。
主要技术:
-
早期方法:Word2Vec、GloVe(只捕捉词共现)
-
现代方法:BERT(上下文嵌入)+ 知识图谱(TransE等)
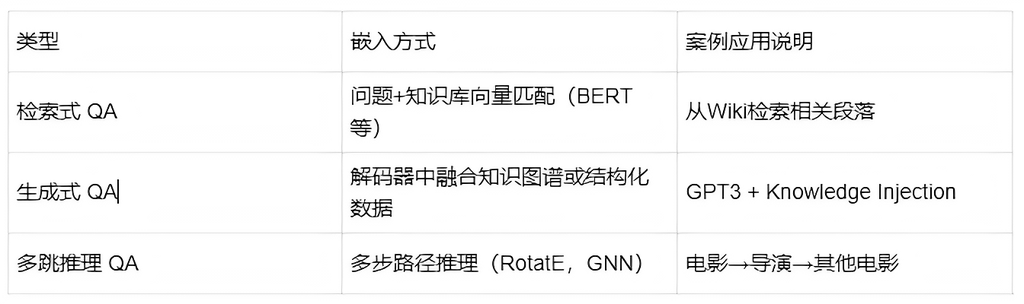
多类型自然语言任务中的知识嵌入实践
问答系统(QA)

问答任务中,模型不仅要识别问题意图,还要从知识源中找到最匹配的事实信息。
-
需要弥合“问题-答案之间的知识缺口”(Question-Answer Gap)。
-
常用知识源:Wikipedia(上下文)、Wikidata(结构)、Wiktionary(定义)
示例:
问题:“在1895年之前,夏威夷属于谁的统治?”
答案:“夏威夷王国”(Hawaiian Kingdom)
📌 三种知识支持路径:
-
Wikipedia 提供历史上下文;
-
Wiktionary 给出精确定义;
-
Wikidata 用结构化方式明确“结束时间=1895”。
文本摘要与翻译任务
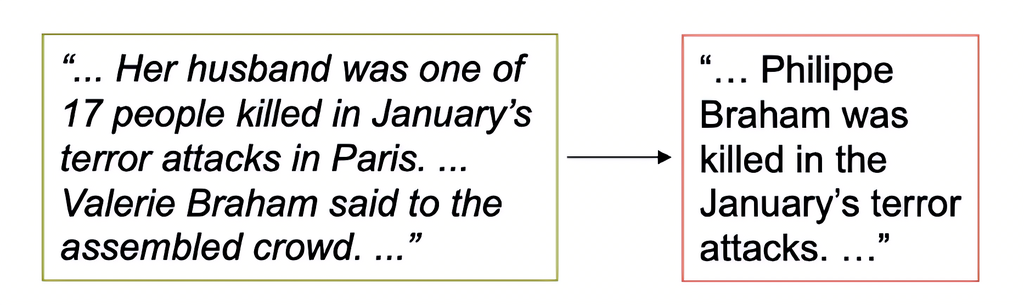
多用于确保生成内容与原文及背景知识的一致性。
-
通过嵌入知识控制生成摘要的客观性和重点覆盖性;
-
在翻译任务中补充上下文语义,防止文化误译。
创造性生成任务(故事生成、溯因推理)
如ROCStories等任务中,模型需要补充“事件之间的逻辑空隙”。
-
输入:火山喷发的场景 + 学生观看;
-
模型需结合“醋+小苏打=模拟喷发”知识;
-
输出:合理补足爆发结果,构建完整故事。
解释生成与反事实生成
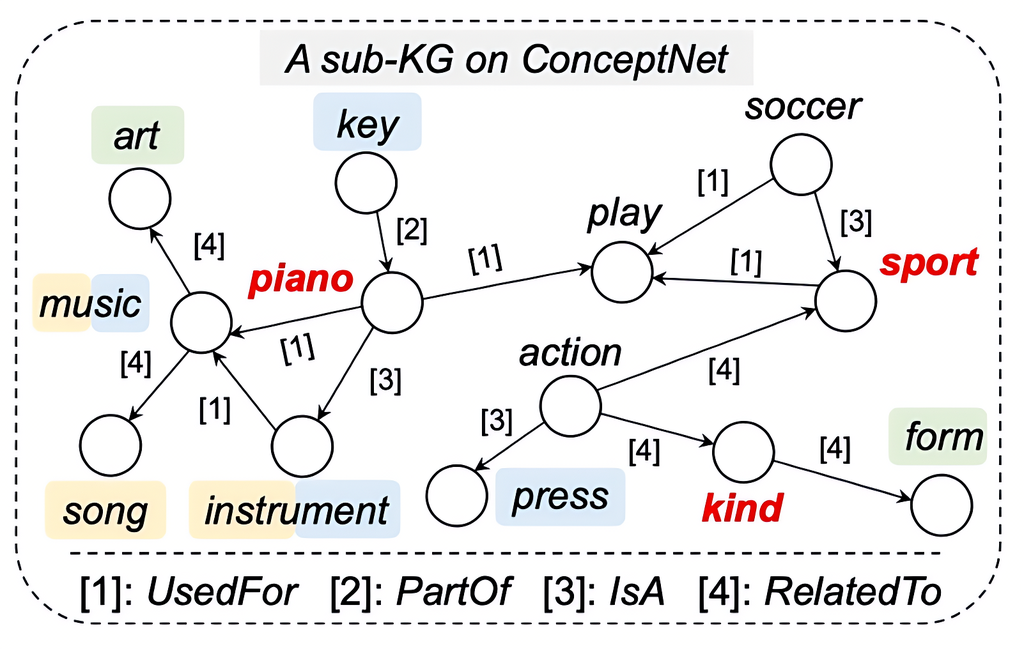
-
给出不合理说法:“钢琴是一种运动”;
-
模型需基于常识生成多个合理解释,如“钢琴是一种用于演奏的乐器”;
-
此类任务要求模型理解“语义空隙”并生成自然解释。
响应生成任务(开放域对话)
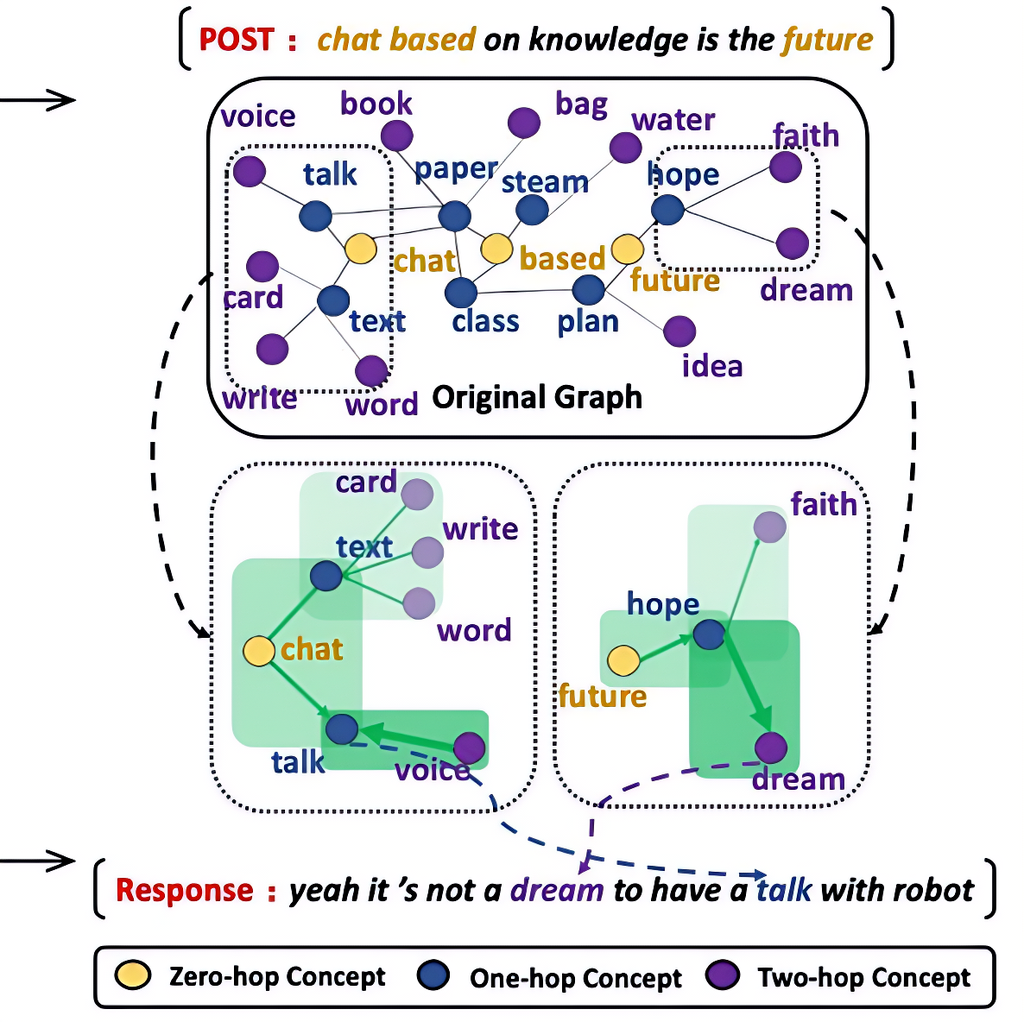
-
输入:“knowledge-based dialogue is the future”;
-
输出:“yes, talking to robots is no longer a dream.”
模型构建方式:
-
构建语义图(如“talk”与“chat”相关);
-
多跳推理获得关联词(如“dream”);
-
最终生成逻辑自然、知识一致的对话内容。
不同类型问答任务的知识嵌入方式对比

Part 3
事实一致性控制:
生成任务中的内容可信度保障
大模型在生成自然语言时,可能会出现“看起来合理但实际上错误”的内容,这被称为“幻觉”(hallucination)。因此,为了保障语言生成任务的可靠性,“事实一致性控制”成为知识增强中不可忽视的重要环节。
为什么生成任务容易产生“幻觉”?
-
模型基于语言共现学习,不具备真实世界验证机制;
-
缺乏知识支撑,导致生成结果容易
自圆其说但与事实不符;
-
尤其是在多跳推理、领域问答等任务中,更易出错。
增强一致性的四大技术路径
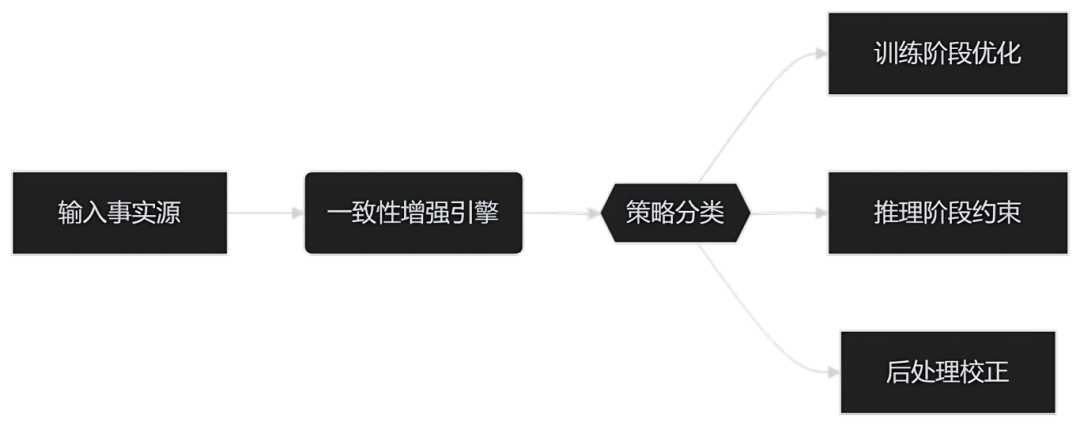
① 检索增强式控制(Retrieve-and-Generate)
-
先从外部知识库中检索事实依据,再引导模型进行生成;
-
代表方法:RAG(Retrieval-Augmented Generation);
-
示例流程:用户提问 → 检索维基段落 → 再进行回答生成。
② 结构约束控制(Structured Control)
-
在生成过程中嵌入结构化知识(如三元组、事件链);
-
有助于维持“事实主干不动摇”,在表述上做语言重写;
-
可用于生成新闻摘要、历史还原类内容。
③ 后处理一致性检测(Post-hoc Filtering)

-
在模型输出后,用额外模块验证是否“可信”;
-
如使用Fact-checker或判别器进行输出判别;
-
成本相对高,但可提升生成内容质量。
④ 多任务联合优化(Multi-task Learning)
-
在训练阶段引入额外监督信号(如事实分类任务);
-
让模型在学习语言生成的同时,学会“事实校准”。
Part 4
外部知识的接入方式与模型结构设计
将知识引入模型中,既要“进得去”,也要“用得好”。不同任务对知识接入方式要求不同,而不同结构也决定了模型的适应范围和表达能力。
四种典型知识接入方式
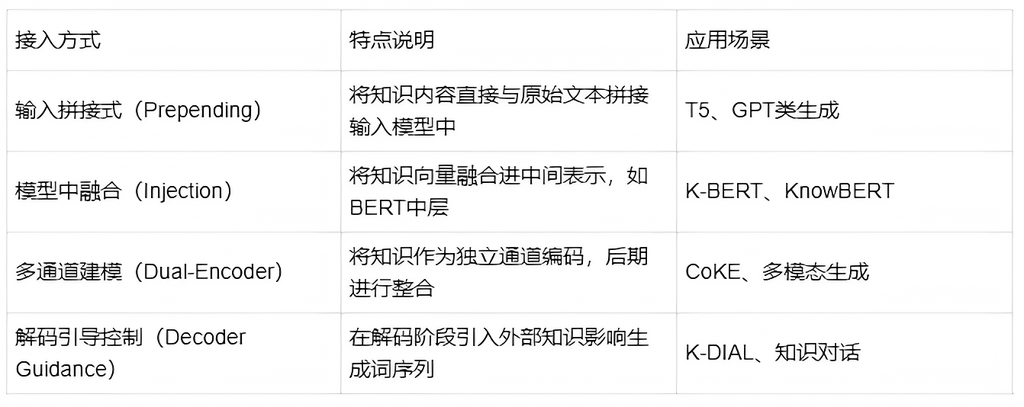
控制知识使用的三种策略
① 实体对齐机制(Entity Alignment)
-
将知识中提及的实体与文本内容进行“锚点式”匹配;
-
常见于任务:命名实体识别(NER)、属性抽取。
② 位置编码机制(Knowledge Position Embedding)
-
在嵌入时引入“位置信息”,让模型区分知识词与原文词;
-
如K-BERT中设置知识节点为特殊位置。
③ 显式监督策略(Explicit Label Supervision)
-
训练时对知识使用位置进行监督,引导模型合理融合;
-
适用于任务型模型(如QA、检索问答等)。
Part 5
知识增强模型的六大
创新路径与案例分析
随着知识增强技术的发展,学术界与工业界已构建出一系列具代表性的融合模型。它们从结构、机制、任务适配等角度对知识融合方式进行了多样化创新。
六种代表性知识增强路径
① K-BERT:结构控制的知识注入
-
构建知识树结构,插入实体关系,使用位置掩码控制传播;
-
核心优势:可控注入、结构明确;
-
应用:情感分析、分类任务、QA。
② CoKE:多通道建模的图谱融合
-
构建文本通道与知识图谱通道,分别建模、联合学习;
-
保留实体-关系结构,不打乱原文;
-
适合结构化推理类任务。
③ KnowBERT:软性融合与动态匹配
-
在中间层插入“知识融合层”,动态判断是否使用该知识;
-
使用注意力机制灵活控制知识注入;
-
应用于问答、实体识别等任务。
④ K-DIAL:解码阶段的知识控制
-
专为对话生成设计,解码器引入知识图谱中的实体与关系;
-
提高多轮对话中的上下文连贯性与事实准确性。
⑤ RAG / REALM:检索增强类大模型
-
整合检索模块与语言模型,动态查找相关知识;
-
RAG结构中,知识与问题拼接后统一编码;
-
特别适合问答、摘要等信息密集任务。
⑥ K-Adapter:模块化知识接入机制
-
插入式“知识适配器”模块,不改动主模型结构;
-
可扩展接入视觉知识、图谱知识等多模态内容;
-
具备灵活、可插拔、低成本的优势。
知识增强任务案例
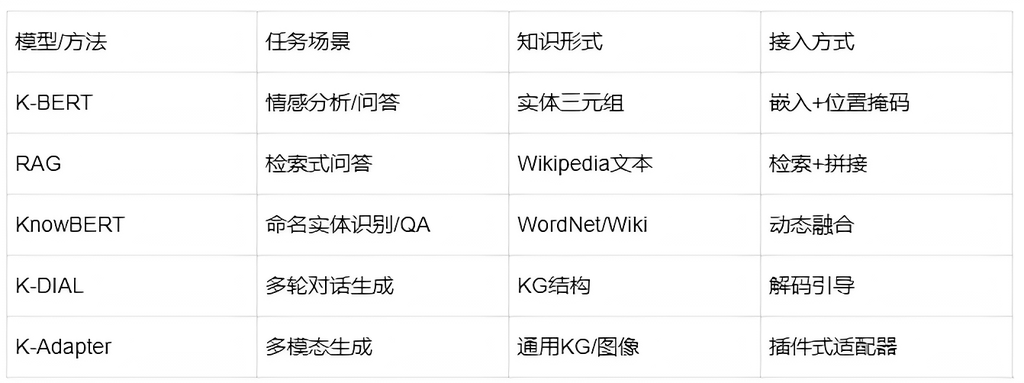
总结回顾:知识增强,为语言模型注入“常识、事实、推理力”
“让语言模型更有智慧”已成为AI发展的主线,而知识增强正是关键推手。
随着检索、图谱、外部工具等技术不断完善,未来的大模型将更加可信、可控、可解释。
-
语言模型的本质是对语言分布建模,但“事实”与“语义”往往超出语言范畴;
-
通过嵌入结构化知识、引入检索机制、设计控制解码器等手段,知识增强能够显著提升模型在问答、对话、生成等任务中的可靠性与推理力;
-
当前研究趋势正朝着“多模态融合”、“因果推理”、“可解释增强”发展,未来值得重点关注。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)