大模型微调之LORA原理
大模型微调LORA的原理
目录
1.问题背景
问题-1:大模型通常包含数十亿甚至数百亿个参数,对其进行微调需要大量的计算资源和存储空间。
问题-2:在微调过程中,直接修改预训练模型的所有参数可能会破坏模型的原始性能。
问题-3:存储和部署微调后的大模型需要大量存储空间,尤其是当需要在多个应用场景中部署不同微调版本时。
问题-4:许多微调方法会增加推理阶段的计算延迟,影响模型的实时性应用。
2.解决措施
LORA(Low-Rank Adaptation)通过引入低秩矩阵分解,在减少计算资源和存储需求的同时,保持了预训练模型的初始性能,稳定了微调过程,并降低了存储和部署成本。它特别适用于大规模模型的微调,在资源有限的环境中具有显著的优势。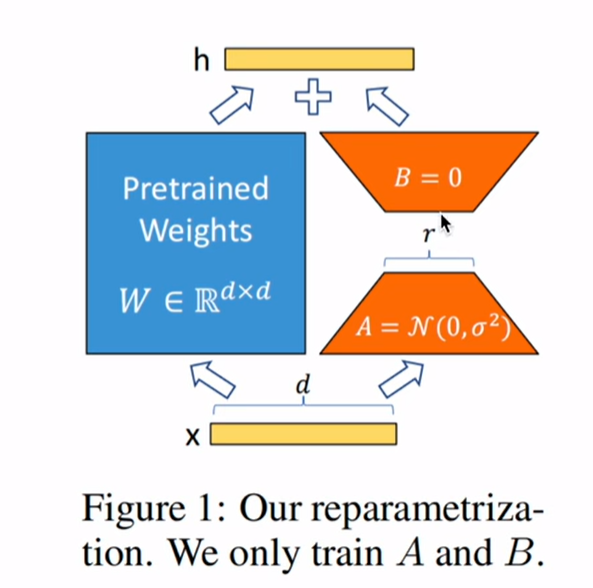
3.LORA 优势
- 存储与计算效率 :通过低秩适应(LORA),可以显著减少所需存储的参数数量,并减少计算需求
- 适应性与灵活性:LORA方法允许模型通过只- 替换少量特定的矩阵A和B来快速适应新任务,显着提高任务切换。的效率。
- 训练与部署效率:LORA的简单线性设计允许在不引入推理延迟的情况下,与冻结的权重结合使用,从而提高部署时的操作效率。
4. LORA原理
4.1 为什么需要低秩分解?
1.现代预训练模型虽然是过参数化的,但在微调时参数更新主要集中在一个低维子空间中。
2.参数更新 △W 可以在低维度中进行优化,高维参数空间中的大部分参数在微调前后几乎没有变化。
3.低秩分解使参数优化更高效,但如果参数更新实际上在高维子空间中发生,可能会导致重要信息遗漏和LORA方法失效。
4.2 LORA算法原理
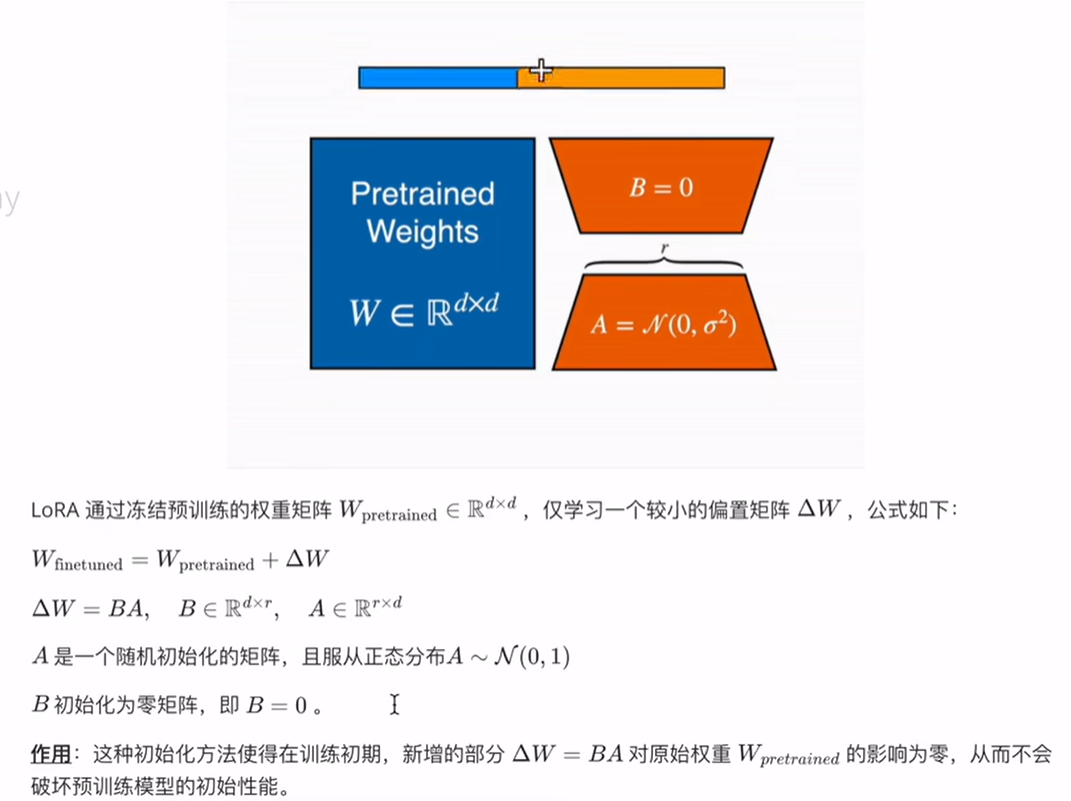

LORA的训练参数量一般不会超过1%
知识补充
问-1:为什么初始化参数使用正态分布?
答-1:这样做的原因包括:
① 确保初始梯度的有效传播
正态分布初始化有助于在训练初期确保梯度有效传播,避免梯度消失或爆炸
② 提供足够的随机性:正态分布的随机初始化为模型提供了足够的随机性,从而能够探索更广泛的参数空间,增加了模型找到最优解的可能性。
③ 平衡训练初期的影响:正态分布初始化的值一般较小,结合B初始化为零矩阵,可以在训练初期确保新增的偏置矩阵对原始预训练权重的影响为零,从而避免破坏预训练模型的初始性能。
下图为正太分布图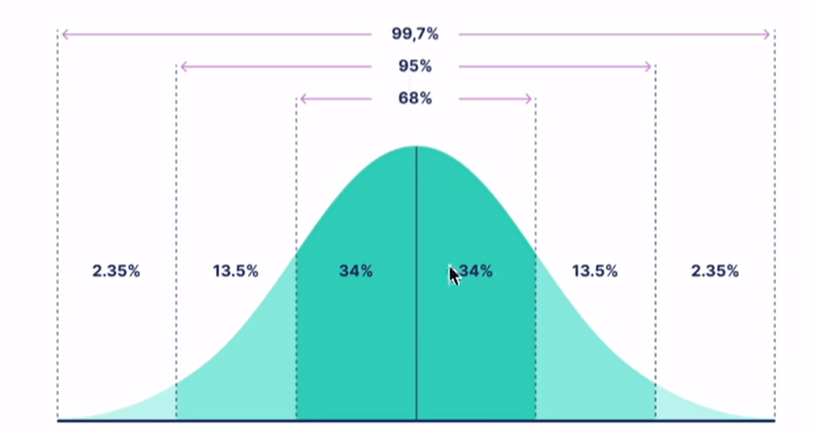
问-2:为什么 A初始化服从正态分布?而B初始化为零矩阵?
答-2:(1)如果B和A全部初始化为零矩阵,缺点是很容易导致梯度消失;
(2)如果B和A全部正态分布初始化,那么在模型训练开始时,就会容易得到一个过大的偏移值△W,从而引起太多噪声,导致难以收敛。
假设我们有一个预训练的权重矩阵 Wpretrained,其维度为 dxd,我们想应用LORA进行微调。
1.初始化 :
2.训练:
在训练过程中,仅更新 A和 B的值。
随着训练的进行,B的值逐渐变得非零。
3.微调权重计算:
4.3 选择哪些权重矩阵进行适配?
在有限参数预算下,应选择哪些权重矩阵进行适配以最大化下游任务性能?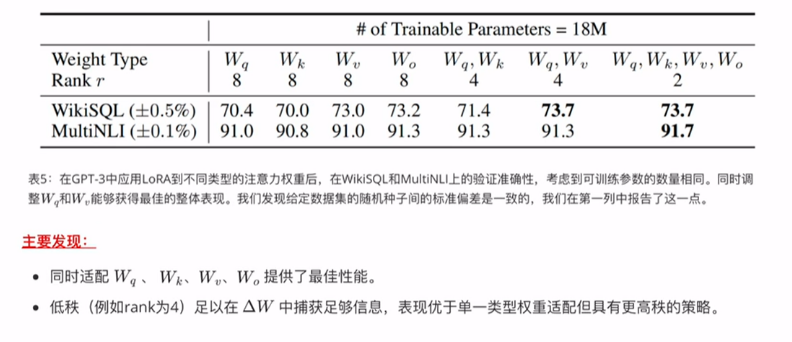
4.4 为什么 LoRA 在 Q, K,V,O 上有效?
LORA(Low-Rank Adaptation)在Transformer 模型的Q(Query)、K(Key)、V(Value)和O(Output)矩阵上有效果的原因可以归结为这些矩阵在注意力机制中的核心作用以及 LORA 方法在降低参数数量的同时保持或提升模型性能的能力。具体原因如下:
4.4.1 Self-Attention
- Q(Query)矩阵:用于生成查询向量,决定模型在注意力机制中对输入的关注程度。
- K(Key)矩阵:用于生成键向量,与查询向量计算相似度,帮助确定注意力分布。
- V(Value)矩阵:用于生成数值向量,实际传递注意力机制计算的输出
- O(Output)矩阵:用于将多头注意力的输出合并并映射回原始维度。
4.4.2 信息传播的关键路径
Q、K、V和O矩阵在信息传播和特征表示中起着关键作用:
- 查询与键的交互:Q 和K矩阵 的交互决定了注意力分布,影响模型对输入序列的不同部分的关注度。
- 数值的加权求和:V矩阵通过加权求和操作,将注意力分布转化为具体的输出。
- 多头输出的整合:O矩阵整合多头注意力的输出,提供最终的特征表示。
4.4.3 LORA 的低秩近似
LORA 通过将权重矩阵分解为两个低秩矩阵(例如 W ≈ BA),减少了参数数量,降低了计算和存储成本,同时保持模型性能:
- 参数压缩:Q、K、V 和 O矩阵通常包含大量参数,LORA 的低秩分解显著减少了需要优化的参数数量,
- 性能保持:低秩矩阵能够捕捉到原始矩阵的主要信息,确保模型性能不受显著影响。
4.5 LORA中的最优秩r的选择
作者探讨了不同秩,对模型性能的影响,并确定最小的有效秩,即“内在秩”。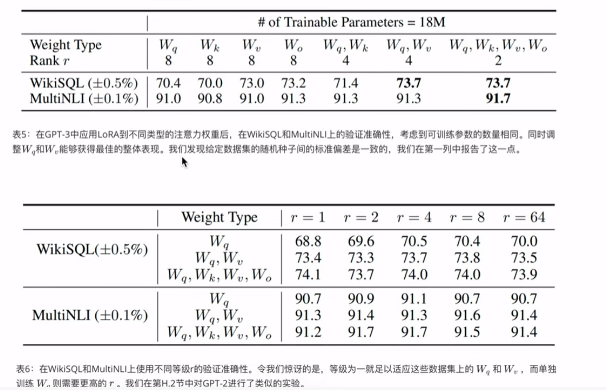
r的选取从上述实验结果看一般2和4效果比较好,当然这要根据实际场景尝试后决定
4.6 LORA可以应用到模型中的哪些层?
LoRA(Low-Rank Adaptation)可以插入到模型的多个地方,具体取决于需要微调的模型部分和任务要求。以下是一些常见的插入位置及其原因:
4.6.1 线性层(全连接层)
位置:
在深度神经网络的全连接层(LinearLayer)中,通常会使用线性变换 W十b。原因:
- 主要参数集中:全连接层通常包含大量参数,通过在这些层中应用LORA,可以显著减少需要微调的参数数。
量。 - 计算密集型:全连接层的计算量较大,通过低秩近似可以有效降低计算复杂度。
4.6.2 注意力层
位置:
在Transformer模型的多头自注意力(Multi-head Self-Attention)机制中,包括查询(Query)、键(Key)和值(Value)矩阵的线性投影部分。
原因:
- 关键功能组件:自注意力机制是Transformer模型的核心组件,对模型性能影响重大。对这些矩阵进行低秩近似可以显著影响模型的表达能力。
- 参数量大:这些投影矩阵包含大量参数,使用LORA可以减少参数数量,降低计算和存储需求
4.6.3 嵌入层
位置:
在NLP任务中,嵌入层用于将离散的词汇表映射到连续的向量空间。原因:
- 高维稀疏表示:嵌入层通常包含大量高维向量,通过LORA可以有效降低维度,减少计算量和内存占用。
- 提升训练效率:低秩分解可以俄嵌入层的训练更加高效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)