Dify学习(二)
MCP 是一套规则,它让 AI 模型可以安全、方便地使用外部工具和数据,从而极大地扩展了 AI 的能力边界。作为使用者:你将来可以通过一个简单的界面,一键添加由 MCP 提供的各种强大工具(如操作 Excel、发送邮件、查询股票等)到你的 AI 助手中。作为开发者:如果你有独特的需求,可以为自己或公司编写自定义的 MCP Server,然后在 Dify 中无缝集成,打造出真正强大和专属的 AI 应
8. 集成MCP服务实现文案创作
MCP介绍
MCP:Model Context Protocol(模型上下文协议)。
简单来说,MCP 是一个标准化的“沟通桥梁”协议,它让 AI 应用(如 Dify 中构建的助手)能够安全、高效地访问和使用外部的工具、数据源和计算资源。
你可以把它理解成 AI 世界的 USB 协议 或 应用商店。
- 就像 USB 协议:定义了键盘、鼠标、U盘等外部设备如何与电脑主机通信。MCP 定义了外部工具和数据如何与 AI 模型“对话”。
- 就像应用商店:为手机提供了各种各样的 App 来扩展功能。MCP 为 AI 模型提供了各种各样的“工具App”来扩展其能力。
为什么需要 MCP?它解决了什么问题?
在没有 MCP 之前,如果你想让你基于大模型的 AI 助手能做一些特定的事,比如:
- 查询公司内部的数据库
- 操作 GitHub 仓库
- 控制家里的智能电器
- 访问特定的 API
开发者需要为每一个功能编写大量的、定制化的代码来连接和调试。这个过程非常繁琐、容易出错,且难以复用。
MCP 的出现,就是为了将“工具本身的功能”和“AI 如何使用这个工具”分离开来,实现标准化。
MCP 的核心工作原理
MCP 主要包含三个核心概念,它们之间的协作关系可以用下图清晰地展示:
其工作流程遵循严格的客户端-服务器架构,如下图所示,展示了从发起到执行的完整过程:
通过这种设计,MCP 成功地将 AI 模型与外部工具解耦,使得能力的扩展变得标准、安全和高效。
MCP 在 Dify 中的巨大价值
Dify 是一个用于构建和运营 AI 应用的平台。MCP 与 Dify 的结合是天作之合,它为 Dify 带来了前所未有的能力:
-
极致的功能扩展:你不再受限于 Dify 官方内置的几种工具。你可以通过 MCP 为你的 AI 助手接入任何你能想到的工具。
- 例如:为你公司内部开发的系统、一个特殊的数据库、一个硬件设备编写一个 MCP Server,然后就能在 Dify 工作流中像使用普通工具一样使用它。
-
增强的 RAG 能力:MCP 的 “Resources” 可以用来构建更强大的 RAG(检索增强生成)应用。你可以写一个 MCP Server 来连接:
- 公司内部的 Confluence、Jira、Notion。
- 你的 GitHub/GitLab 仓库。
- 任何支持 API 的数据源。
这样,你的 AI 助手就能实时读取这些最新信息来回答问题,而不是仅仅依赖一个静态的知识库。
-
安全性与隔离性:MCP Server 是独立的进程。这意味着:
- 更安全:AI 应用(Dify)本身不需要知道你的数据库密码或 API 密钥,这些敏感信息只保存在 MCP Server 端。
- 更稳定:一个工具的崩溃不会导致整个 AI 应用崩溃。
- 语言无关:你可以用任何语言(Python, JavaScript, Go, Java…)来编写 MCP Server,只要遵守协议即可。
-
生态与复用:MCP 正在形成一个活跃的开源生态。很多常用的工具(如 Web Browser、GitHub、SQL 数据库等)都已经有社区写好的 MCP Server。你可以在 Dify 中直接使用它们,无需重复造轮子。
总结
MCP 是一套规则,它让 AI 模型可以安全、方便地使用外部工具和数据,从而极大地扩展了 AI 的能力边界。
对于 Dify 用户来说:
- 作为使用者:你将来可以通过一个简单的界面,一键添加由 MCP 提供的各种强大工具(如操作 Excel、发送邮件、查询股票等)到你的 AI 助手中。
- 作为开发者:如果你有独特的需求,可以为自己或公司编写自定义的 MCP Server,然后在 Dify 中无缝集成,打造出真正强大和专属的 AI 应用。
以上来自deepseek
需要引入两个插件:MCP server、MCP SSE / StreamableHTTPMCP server里面设置schema
{
"name": "poem",
"description": "模仿输入的作者风格写诗歌",
"inputSchema": {
"title": "poem",
"type": "object",
"properties": {
"author": {
"title": "author",
"description": "作者",
"type": "string"
}
},
"required": [
"author"
]
}
}
点击保存后,可以获取到mcp-server
获取到https://xxx.ai-plugin.io/sse,然后
放到MCP SSE / StreamableHTTP的里面:
{
"server_name": {
"url": "https://xxx.ai-plugin.io/sse",
"headers": {},
"timeout": 50,
"sse_read_timeout": 50
}
}
配置做完后,建一个agent,关键词:调用 mcp 工具回答用户问题,先获取工具列表,再选中可用的工具,最后返回工具结果中的诗歌原文及解析,然后引入MCP SSE / StreamableHTTP的两个插件,即可
MCP这个例子,没有搞成功
老报错:
调用工具时出现错误,错误信息为 “Arguments must be a valid JSON string: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)”。这意味着传递给 mcp_sse_call_tool 函数的参数 arguments 不是一个有效的JSON字符串。请检查参数格式是否正确。通常,需要将参数表示为一个正确格式的JSON字符串,例如 {“author”: “李白”}。请确保参数在传递时遵循正确的JSON语法。如果问题仍然存在,请提供更多上下文信息,以便进一步排查
按着视频一步一步做的,连续看了两遍,都一样,但是就是报错。网上查了资料,没解决。先放一放
9. 生成PPT
这个就比较简单了,直接用一个PPT插件即可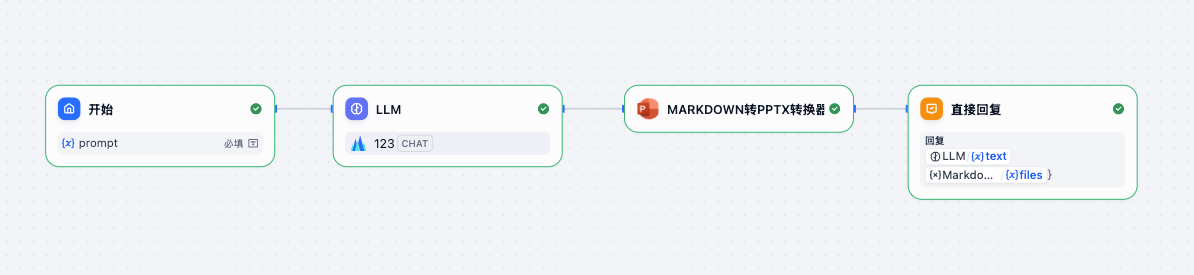

10. Dify整合Ollama访问本地大模型
Docker Desktop 可以用来管理Dify,也就是,部署到本地,而不是用Dify里面的cloud
一、安装Docker Desktop
访问Docker官网,下载MAc适配的Docker Desktop
二、拉取Dify源代码
打开终端,执行git命令克隆Dify仓库
git clone https://github.com/langgenius/dify.git
或者,直接下载Dify的源码到本地
三、进入Docker目录并配置环境
进入dify/docker目录下,复制环境配置文件
cd dify/docker
cd .env.example .env
或者,进入到dify/docker文件夹下,将.env.example复制一份,然后改名字:.env
四、启动dify服务
docker compose up -d
遇到很多次网络错误,记得开🚀

五、打开Dify平台
打开浏览器,访问http://localhost/apps,进入Dify平台,填写账号登录
Ollama
Ollama用于部署大模型
下载对应的版本后,可以在命令行查看是否安装成功,以及安装的版本号:
ollama -v
可以看到:ollama version is 0.11.8
现在,就可以下载你想用的模型了
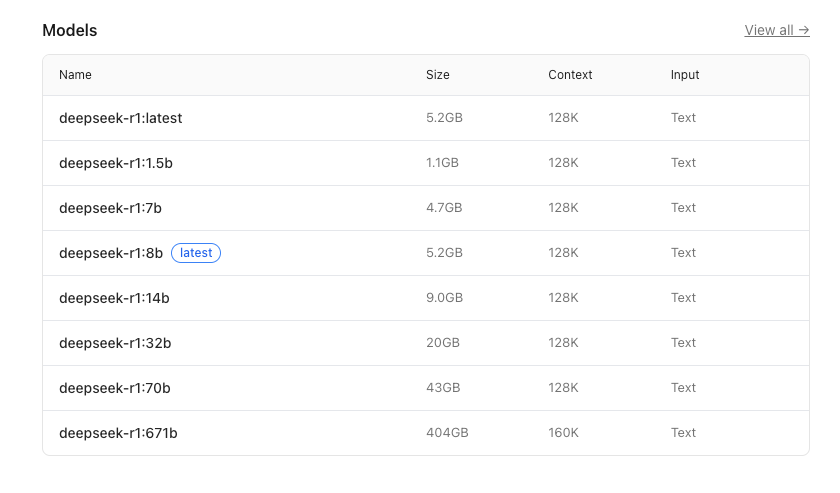
由于电脑配置不高,所以,选了1.5b的模型
在命令行执行:ollama run deepseek-r1:1.5b,下载即可

Ollama部署了本地模型,现在就可以在Docker里面,用自己的模型了
在设置Ollama的时候,老报错:
An error occurred during credentials validation: HTTPConnectionPool(host=‘192.168.66.89’, port=11434): Max retries exceeded with url: /api/chat (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x7f6253d8bd10>: Failed to establish a new connection: [Errno 111] Connection refused’))
需要在命令行执行:launchctl setenv OLLAMA_HOST "0.0.0.0"
然后,再在配置Ollama处填入:http://host.docker.internal:11434保存即可
另外,模型名称 不要瞎填
之后,就可以在Dify里面,使用自己部署的Ollama模型了
另外,也可以分享出去,让别人使用。就跟其他大模型一样,拿到key就行
11. 基于Echarts插件打造可视化报表
Echarts,有很多可视化视图等
找到想要的图,然后复制里面的js代码,转换成python代码,然后调用即可,比较简单
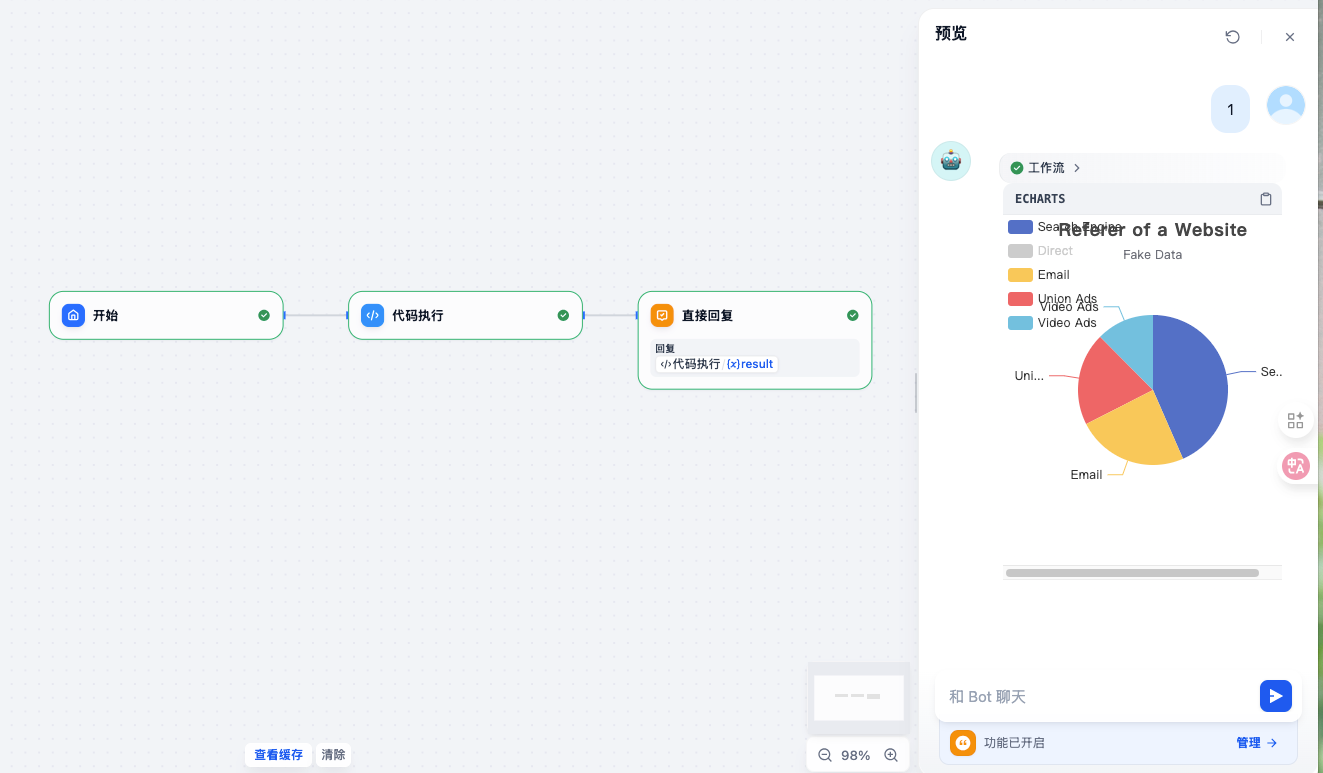
还有一种方法,直接使用插件:Echarts图表生成,也比较简单
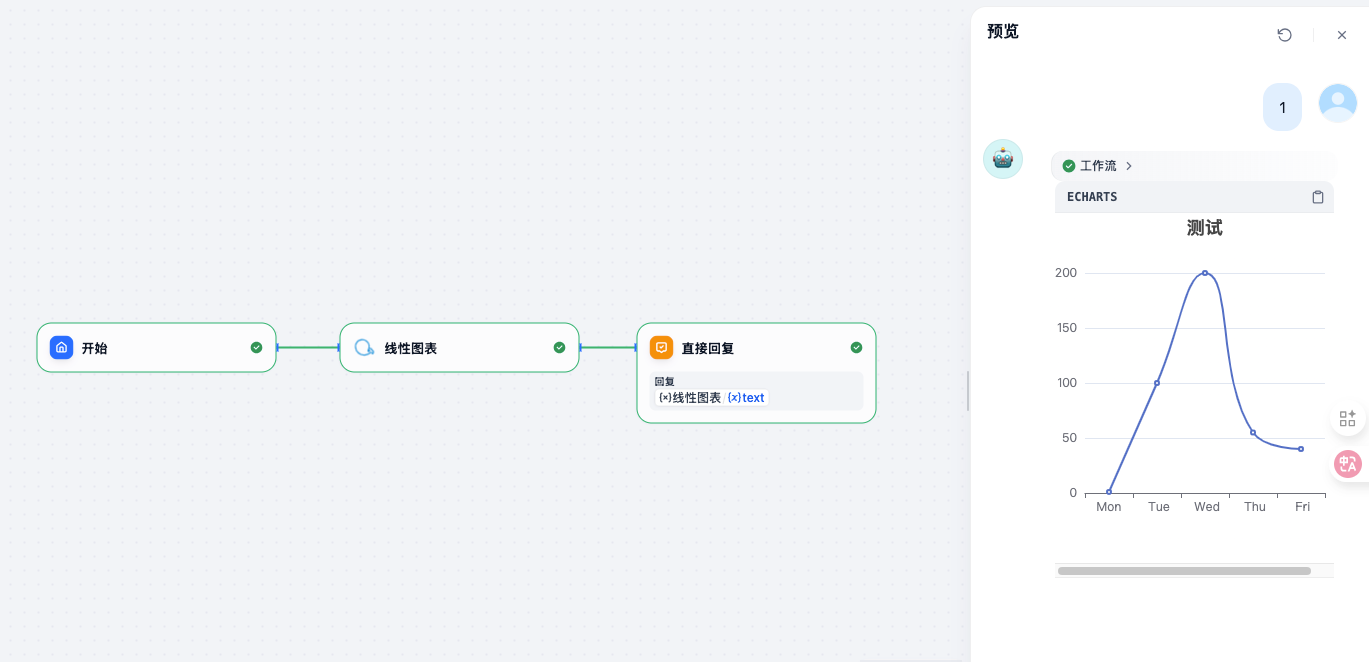
Excel输出图表
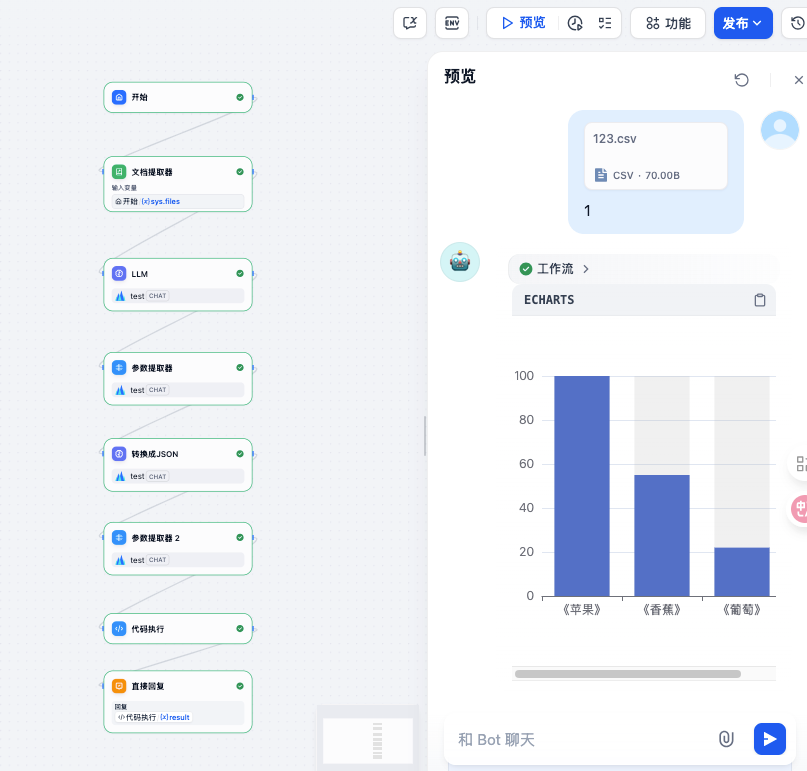
倒也还好,主要是几个步骤
首先要上传一个Excel文件:
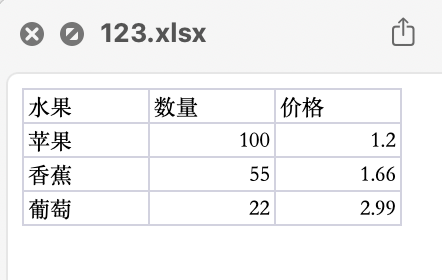
然后通过第一个LLM,提取数据,并且转换成csv格式
角色
你是一个数据整理的专家,擅长数据格式的整合和数据的转换
数据
{{#1756717165651.text#}}
任务
先从数据中提取出满足用户要求的数据 {{#sys.query#}} 然后把数据转换为 csv 格式
输出
把 csv 格式的数据输出
然后,提取参数(参数提取器)
然后,将csv格式转换成json数据
# 角色
你是一个csv格式数据转json数据的技术专家,擅长把csv转换为对应的json数据,
# 数据
{{#1756717327951.CSV_Data#}}这个数据只有两列
# 任务
把csv中的两列数据转换对应的json 数据
比如:
水果,数量,价格\n 苹果,10,50 \n 香蕉,12,38 \n 荔枝,15,60 \n 梨子,13,35
转换为:
{
"name":["《苹果》","《香蕉》","《荔枝》","《梨子》"]
"values":[10,12,15,13]
}
# 输出
把上面转换得到的json数据输出即可
然后,再提取,最后执行代码:
其中,代码执行的代码:
import json
import re
def main(jsonData: str) -> dict:
# 解析外层JSON数据
# data = json.loads(jsonData)
# query_str = data['query']
# 去除换行符和制表符
clean_str = re.sub(r'[\n\t]', '', jsonData)
# 去除转义的双引号(将\"替换为")
clean_str = re.sub(r'\\"', '"', clean_str)
# 提取name和values的值
name_pattern = r'"name":\s*\[(.*?)\]'
values_pattern = r'"values":\s*\[(.*?)\]'
name_match = re.search(name_pattern, clean_str)
values_match = re.search(values_pattern, clean_str)
names = []
if name_match:
names = re.findall(r'"([^"]*)"', name_match.group(1))
values = []
if values_match:
values = [float(num.strip()) for num in values_match.group(1).split(',')]
option = {
"xAxis": {
"type": 'category',
"data": names
},
"yAxis": {
"type": 'value'
},
"series": [
{
"data": values,
"type": 'bar',
"showBackground": True,
"backgroundStyle": {
"color": 'rgba(180, 180, 180, 0.2)'
}
}
]
}
# 生成输出文件
output = f'```echarts\n{json.dumps(option, ensure_ascii=False)}\n```'
return {
"result": output,
}
# 如果您想要直接运行这个脚本,可以添加以下代码
if __name__ == "__main__":
# 示例输入
sample_data = '{"name": ["A", "B", "C"], "values": [10, 20, 30]}'
result = main(sample_data)
print(result["result"])
一键生成图文
首先,我们创建一个Agent,做一个输入文字就可以生成图片的功能
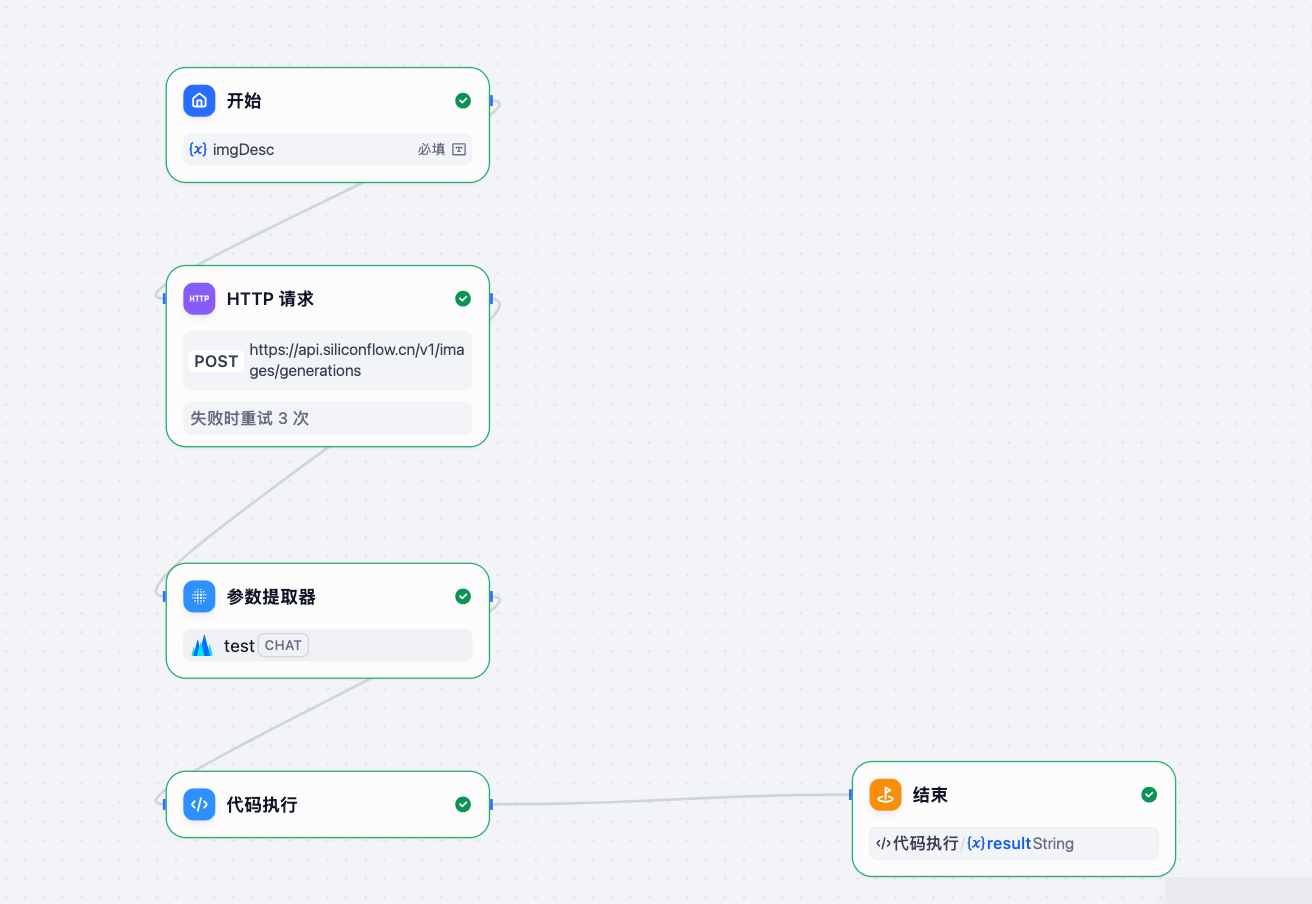
然后,使用硅基流动生成图片的API,文档地址
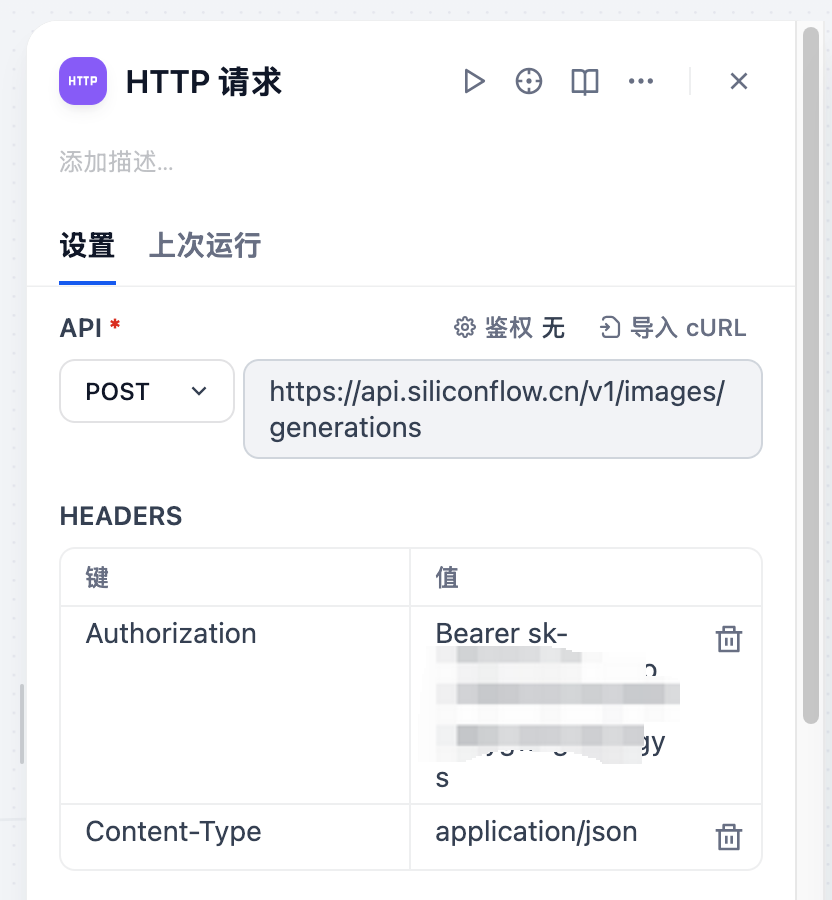
Authorization的value,直接使用 Bearer token即可
Body填入:
{
"model": "Kwai-Kolors/Kolors",
"prompt": "{{#1756733391329.imgDesc#}}",
"image_size": "1024x1024",
"batch_size": 1,
"num_inference_steps": 20,
"guidance_scale": 7.5
}
参数提取器: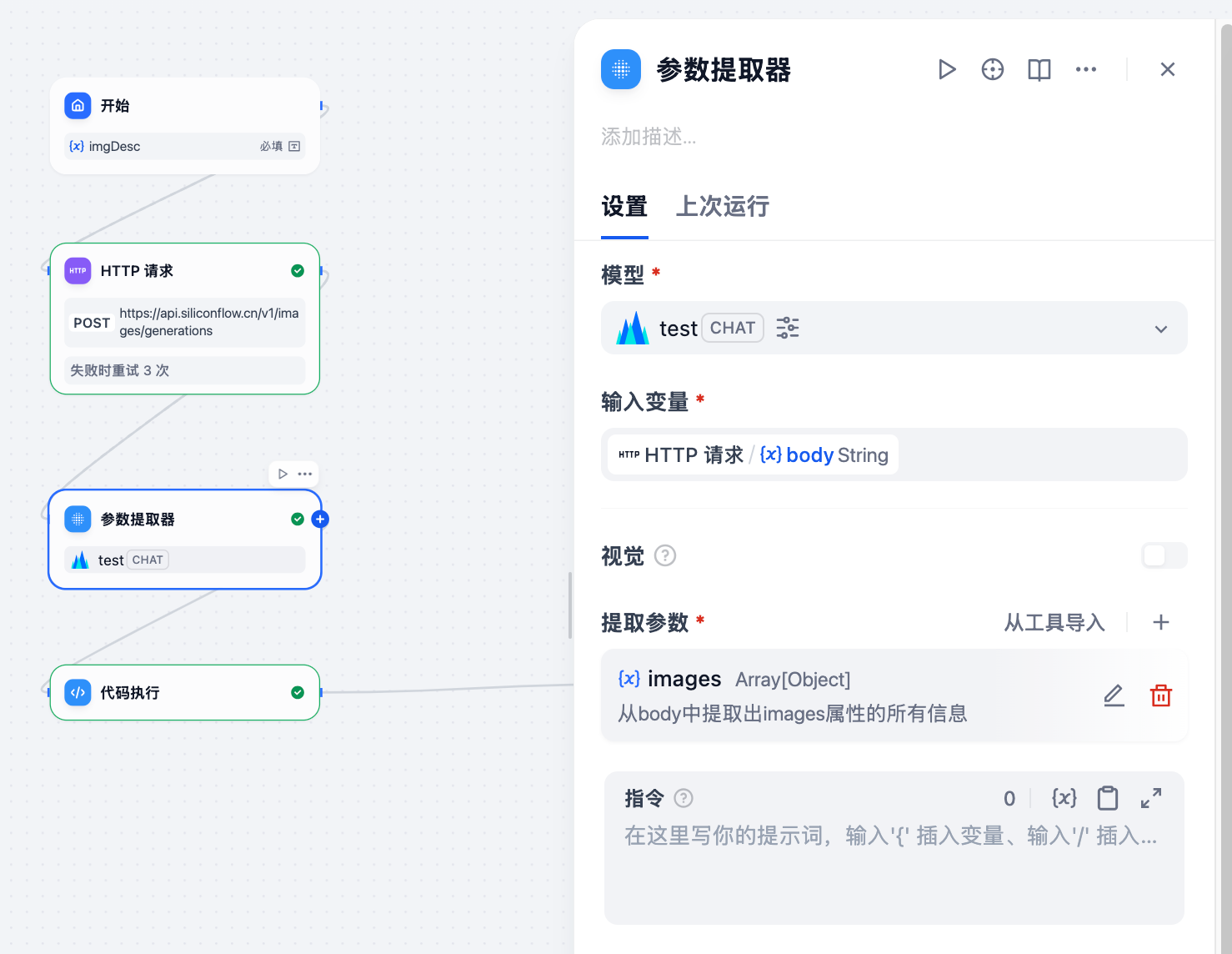
代码执行的地方:
from typing import Any, Union
def extract_url(value: Union[dict, list, str]) -> str:
"""递归提取的核心逻辑"""
if isinstance(value, str):
# 检查字符串是否以 http://、https:// 或 data:image 开头
if value.startswith(('http://', 'https://', 'data:image')):
return value
return ''
elif isinstance(value, dict):
# 优先检查单数形式字段(url、image、link、src)
for field in ['url', 'image', 'link', 'src']:
if field in value:
found = extract_url(value[field])
if found:
return found
# 检查复数形式字段(urls、images、links、sources)
for list_field in ['urls', 'images', 'links', 'sources']:
list_value = value.get(list_field)
if isinstance(list_value, list):
found = extract_url(list_value)
if found:
return found
# 深度搜索字典的值
for v in value.values():
found = extract_url(v)
if found:
return found
elif isinstance(value, list):
# 遍历列表中的每个元素
for item in value:
found = extract_url(item)
if found:
return found
return ''
def main(data: Any) -> dict:
"""
从复杂数据结构中安全提取第一个URL(优化版)
:param data: 支持 dict/list/str 的任意嵌套数据结构
:return: 总是返回包含字符串类型结果的字典,找不到时结果为空字符串
"""
return {"result": extract_url(data)}
举例:一只老虎在跳舞
接下来,就可以做法朋友圈文案了: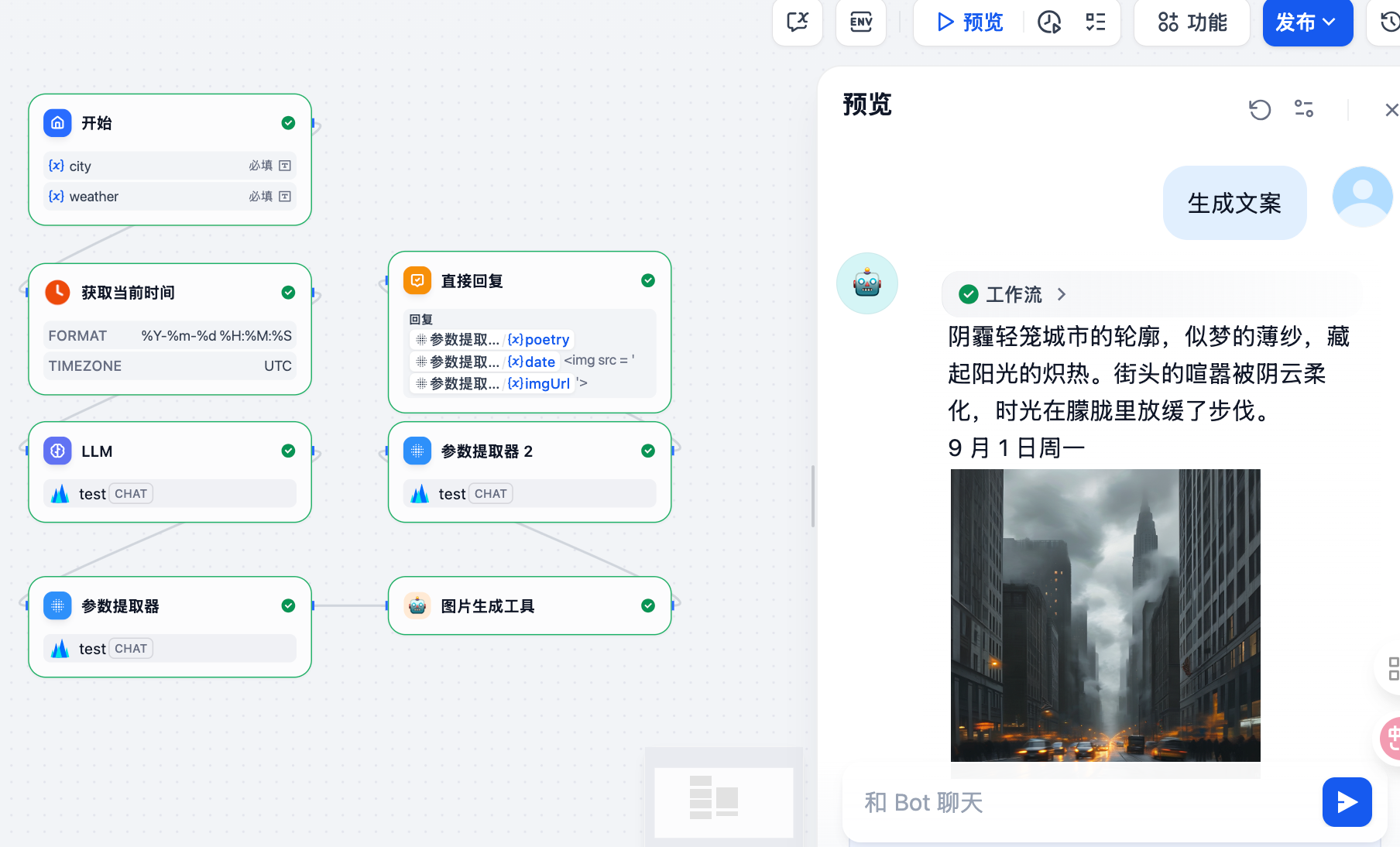
LLM参考提示词:
请根据 {{#sys.query#}} 和今天的天气情况 {{#1756736659044.weather#}}
写几句有诗意的散文诗,并且生成一段话描述这个场景的画面感。
诗词或者散文请富有文学性和哲理,诗句示例:
万千生命如画卷徐徐展开,恍若荷叶晨露,转瞬即逝。
诗词请保持输出两句话,不一定需要城市名称,但要突出城市或者当天的天气
请严格按照以下格式输出
{
"poetry":<输出散文诗>,
"img_des":< 输出描述诗词画面感的语句 >,
"date":< 今天的日期,格式示例:11 月 28 日周四 >
}
今天的日期是:{{#1756736688627.text#}}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)