9.1【A】同构与异构,应用面对的各种墙,CXL图片与cxl.mem,为什么AI训练需要高带宽,HBM
摘要:本文探讨了异构内存系统的必要性及其技术实现,重点分析了CXL协议在内存共享和缓存一致性方面的优势。传统同构DRAM内存面临带宽、能耗、成本和灵活性等瓶颈,而异构系统通过整合HBM、CXL DRAM、PMEM等多种内存技术,为不同应用场景提供定制化解决方案。研究指出,CXL协议通过硬件级缓存一致性支持,使内存资源池化成为可能,特别适合AI训练等需要高带宽的场景。文章还解析了HBM通过3D堆叠和
build/X86/gem5.opt -d "output/fs_stream_dram" configs/example/gem5_library/x86-cxl-run.py --test_cmd stream_dram.sh --cpu_type TIMING --num_cpus 48

三级缓存结构
缓存层次结构:使用了三级缓存,其中L1和L2是每个核心私有的,L3是共享的。这种结构在现代多核处理器中很常见,有助于减少内存访问延迟
•三级缓存架构:
- •私有L1:指令/数据分离缓存(32kB/48kB),保障核心独享低延迟访问
- •私有L2:2MB大容量中间缓存,降低L3访问频率
- •共享L3:96MB末级缓存(LLC),采用MESI协议维护一致性
内存系统:主内存和CXL内存分别配置。CXL设备在这里被模拟为附加的内存节点,通过CXL协议连接。在NUMA系统中,CXL内存会作为一个额外的NUMA节点出现
什么是所谓同构
- •技术同构: 绝大多数计算机系统,从手机到数据中心服务器,其主内存(Main Memory)几乎清一色地由DRAM 技术构成。你可能有一根、两根或更多内存条,但它们都是同样的技术、同样的接口(如DDR4/DDR5)、同样的访问特性(延迟、带宽、持久性)。
- •架构同构: 从处理器的视角看,所有内存单元通过一个统一的、对称的内存访问接口 连接。无论是NUMA(非统一内存访问)架构还是UMA(统一内存访问)架构,其呈现给软件(操作系统、应用程序)的抽象视图都是一块连续的、字节可寻址的线性地址空间,背后的物理介质是单一的DRAM。
应用面对的各种墙——需求灵活性
a. 内存墙 / 带宽墙:
CPU核心数遵循摩尔定律增长(如64核、128核),但DRAM的带宽和延迟改善速度远落后于此。更多核心在争抢有限的内存带宽,导致许多应用处于“内存饥饿”状态,CPU计算单元空闲,等待数据从内存到来。这在数据密集型应用(如AI训练、大数据分析、科学计算)中尤为致命。
b. 能耗墙:
DRAM是系统中最主要的能耗源之一。服务器农场中,内存功耗可占总功耗的30%-40%。然而,对于许多不需要低延迟访问全部数据的应用(如冷数据存储、后台任务),始终让所有DRAM保持供电是巨大的能源浪费。
c. 成本墙 / 容量墙:
随着数据集爆炸式增长(TB甚至PB级),单纯地通过增加DRAM来扩容成本极其高昂。我们希望以更低的成本获得更大的内存容量,即使其性能稍逊。
d. 应用多样性墙:
不同的工作负载对内存的需求截然不同:
- •AI训练/GPU计算: 极度渴求高带宽。HBM的带宽是DDR5的5-10倍。
- •大数据内存数据库(如Redis): 需要大容量 和低成本,对延迟不那么敏感。
- •持久化内存(如日志、内存文件系统): 需要非易失性,希望数据在掉电后不丢失。
- •安全应用: 需要内存加密和即时销毁能力。
“灵活性”的需求由此诞生: 我们能否为不同的任务、不同的数据,动态地分配不同类型的内存资源,从而实现性能、容量、成本、能耗的最佳权衡?而不是像现在这样,对所有数据都使用昂贵、高耗能、带宽受限的DRAM。
异构的理念
异构内存系统正是为了提供这种灵活性而提出的解决方案。其核心思想是:在单一计算机系统中集成多种具有不同特性(速度、容量、成本、持久性)的内存技术,并通过硬件和软件协同管理,让数据智能地驻留在最合适的介质上。
- •高带宽内存: HBM - 通过2.5D/3D堆叠提供极致带宽,但容量小、成本高。适用于GPU和AI加速器。
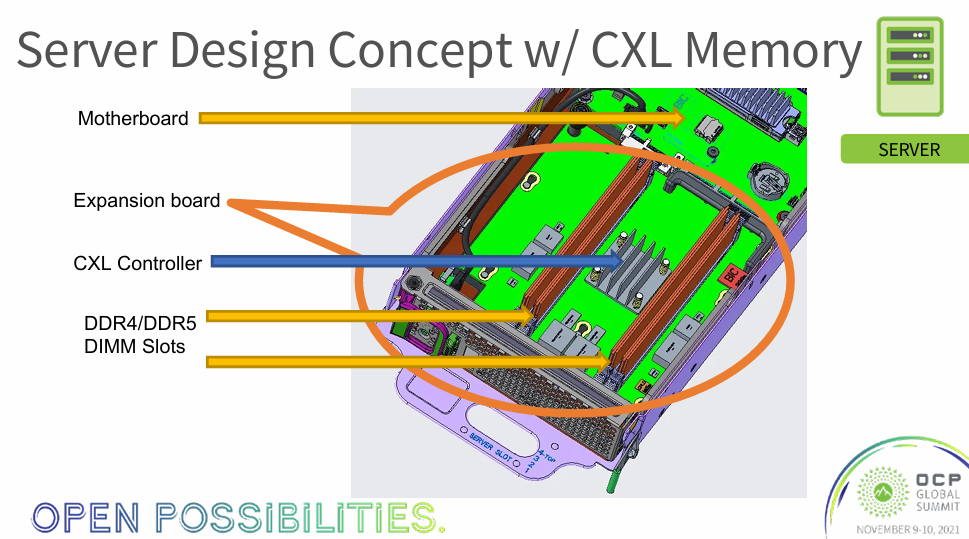
- •大容量内存: CXL DRAM - 通过CXL协议扩展出的内存池,可提供远超主板插槽限制的容量。
- •持久性内存: PMEM(傲腾)/MRAM/ReRAM - 像DRAM一样字节可寻址,但掉电后数据不丢失,读写速度介于DRAM和SSD之间。
- •低成本内存: 甚至可以考虑将NVMe SSD 通过软件或硬件技术(如CXL)视为一种慢速、大容量的“内存”扩展。

CXL

CXL access via loads/stores is a game changer as it allows memory to remain statically preallocated while physically being located in a shared pool.”
这句话的意思是:通过load/store指令(即CPU的常规内存访问指令)来访问CXL设备,这一能力是颠覆性的。因为它使得内存在软件视角上可以保持静态预分配(地址固定),而其物理位置实际上可以位于一个被多个计算单元共享的资源池中。
这彻底打破了“内存必须物理上紧挨着CPU”的传统束缚。
cxl.mem协议可能的访存步骤

缓存一致性:
- •这是CXL相比其他方案最核心的优势。CXL协议包含缓存一致性的原生支持。
- •如果某个CPU核缓存了位于CXL内存中的数据,当另一个设备(如另一个CPU或加速器)要修改该数据时,CXL协议(通过Snooping或Directory-based机制)会自动发起无效化 操作,使那个CPU核的缓存行失效。
- •这确保了所有参与者看到的内存视图是一致的,完全由硬件自动完成,软件无需干预。这是RDMA等方案无法提供的。
可能的异构研究方向

为什么AI训练,GPU需要高带宽


就是说,需要高带宽来喂给计算单元,才能保证并行计算中,计算单元没有被闲置

因此,想要提升训练速度,最直接有效的方法就是提升内存带宽。计算能力(TFLOPS)再高,如果没有足够的数据喂给它,也是徒劳。
HBM
传统架构的问题: 传统的GPU使用GDDR内存,通过PCB板上的导线与GPU芯片连接。导线长度长、数量有限,带宽和功耗成为瓶颈。
- 1.堆叠: 将多个DRAM晶粒(Dies)在垂直方向上堆叠起来,通过硅通孔进行互联,大大缩短了Die-to-Die的通信距离。
- 2.宽接口: 每个HBM堆栈与GPU基片(Interposer)通过一个极其宽的并行接口连接(通常是1024-bit或2048-bit per stack)。多个堆栈组合,总位宽可达4096-bit甚至8192-bit。带宽 = 频率 × 位宽,巨大的位宽带来了带宽的飞跃。
- 3.先进封装: GPU芯片和HBM堆栈共同放置在一个硅中介层上。中介层提供了数倍于传统PCB的布线密度和更短的互连距离,确保了高速信号传输的完整性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)