GWM:面向机器人操作的可扩展高斯世界模型
25年8月来自清华、BIGAI 和南洋理工的论文"GWM: Towards Scalable Gaussian World Models for Robotic Manipulation"。由于现实世界交互效率低下,在已学习的世界模型中训练机器人策略正成为一种趋势。现有的基于图像世界模型和策略已取得一定成效,但缺乏鲁棒的几何信息,即使基于互联网规模的视频源进行预训练,也需要对三维世界有一致的空间和
25年8月来自清华、BIGAI 和南洋理工的论文"GWM: Towards Scalable Gaussian World Models for Robotic Manipulation"。
由于现实世界交互效率低下,在已学习的世界模型中训练机器人策略正成为一种趋势。现有的基于图像世界模型和策略已取得一定成效,但缺乏鲁棒的几何信息,即使基于互联网规模的视频源进行预训练,也需要对三维世界有一致的空间和物理理解。为此,本文提出一种用于机器人操作的世界模型分支——高斯世界模型 (GWM),它通过推断机器人动作影响下高斯基元的传播来重建未来状态。其核心是一个潜扩散 Transformer (DiT) 与三维变分自编码器相结合,通过高斯分层实现细粒度的场景级未来状态重建。GWM 不仅可以通过自监督的未来预测训练增强模仿学习智体的视觉表征,还可以作为支持基于模型强化学习的神经模拟器。模拟和现实世界的实验都表明,GWM 可以根据不同的机器人动作准确预测未来场景,并且可以进一步用于训练以令人印象深刻的优势超越最先进技术的策略,展示 3D 世界模型的初始数据扩展潜力。
高斯世界模型 (GWM) 是一种 3D 世界模型,它将 3D-GS 与用于机器人操作的高容量生成式模型相结合。具体而言,该方法将前馈 3D-GS 重建与扩散 transformer (DiT) 的最新进展相结合,从而能够通过以当前观测和机器人动作为条件的高斯渲染进行细粒度的未来场景重建。为了实现实时训练和推理,其设计一个 3D 高斯变分自编码器 (VAE) 来从 3D 高斯中提取潜表示,从而使基于扩散的世界模型能够在紧凑的潜空间中高效运行。通过这种设计,证明 GWM 增强视觉表征学习,提高其作为模仿学习的视觉编码器作用,同时还可作为基于模型的强化学习 (RL) 强大神经模拟器。
GWM 如图所示:
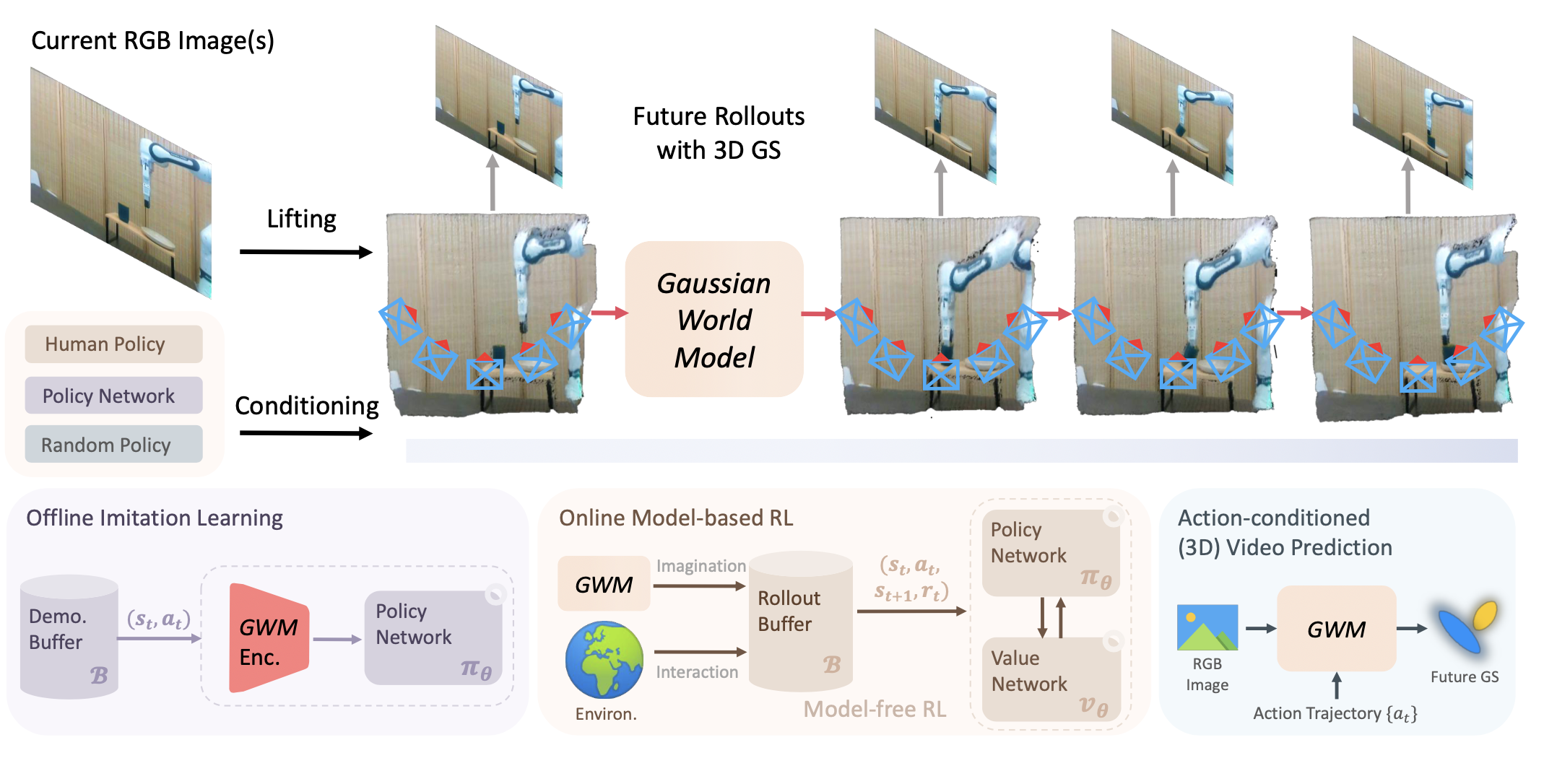
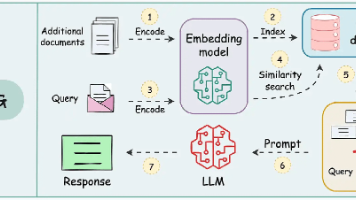
GWM 方法的整体流程如图所示。其中,构建一个高斯世界模型,用于推断由三维高斯基元表示的未来场景重建。具体而言,将现实世界视觉输入编码为潜三维高斯表示,并利用基于扩散的条件生成模型来学习给定机器人状态和动作的表示动态变化。GWM 可以灵活地集成到离线模仿学习和基于在线模型的强化学习中,以用于各种机器人操作任务。
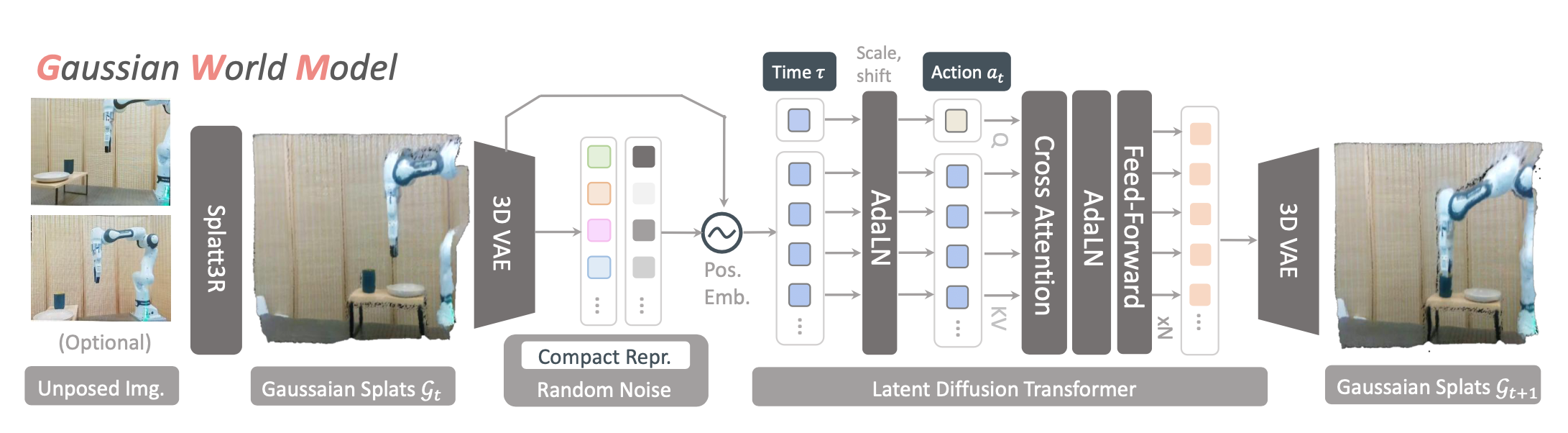
世界状态编码
前馈三维高斯分布。给定表示世界状态的单视图或双视图图像输入 I = {I},目标是首先将场景编码为三维高斯表示,以进行动态学习和预测。3D-GS 表示一个具有多个非结构化三维高斯核 G = {x_p, σ_p, Σ_p, C_p} 的三维场景,其中 x_p、σ_p、Σ_p 和 C_p 分别表示高斯函数的中心、不透明度、协方差矩阵和球谐系数。为了从给定视点获取每个像素的颜色,3D-GS 将 3D 高斯投影到图像平面并计算像素颜色。
由于原始 3D-GS 依赖于耗时的逐场景离线优化,采用可泛化的 3D-GS 来学习从图像到 3D 高斯的前馈映射,以加速该过程。具体而言,用 Splatt3R [70] 获取 3D 高斯世界状态 G。该模型首先使用立体重建模型 Mast3R [37] 从输入图像生成 3D 点图,然后使用附加的预测头根据这些点图预测每个 3D 高斯的参数。
3D 高斯 VAE。由于每个世界状态学习的 3D 高斯数量在不同场景和任务中可能存在显著差异,采用 3D 高斯 VAE (E_θ, D_θ) 将重建的 3D 高斯 G 编码为固定长度的 N 个潜嵌入 x。具体而言,先使用最远点采样 (FPS) 将重建的 3D 高斯 G 下采样为固定数量的 N 个高斯 GN:G_N = FPS(G)。接下来,用这些采样的高斯函数 G_N 作为查询,使用基于 L 层交叉注意机制的编码器 E_θ 将所有高斯函数 G 的信息聚合在潜嵌入 x 中。
对于潜编码 x,用基于镜像 transformer 的解码器 D_θ 在潜编码集内传播和聚合信息,并利用这些信息获得重构的高斯函数 Gˆ。
为了学习 3D 高斯 VAE (E_θ,D_θ),用重构高斯函数 Gˆ 和原始高斯函数 G 的中心之间 Chamfer 损失函数进行监督。还添加重构高斯函数 Gˆ 的渲染损失函数,以实现基于图像策略的高保真渲染。
基于扩散的动态建模
利用时间 t 的编码世界状态嵌入 x_t 及其未来状态 x_t+1,目标是学习世界动态 p(x_t+1|x_≤t,a_≤t),其中 x_≤t 和 a_≤t 分别表示历史状态和动作。具体来说,利用基于扩散的动态模型,将动态学习转化为条件生成问题,以历史状态和动作 y_t = (x_≤t, a_≤t) 作为条件,从噪声中生成未来状态 x_t+1。
扩散公式。为了生成未来状态,从扩散过程的公式开始。具体来说,首先将噪声添加到真实未来状态 x0_t+1 = x_t+1,通过高斯扰动核获得带噪声的未来状态样本 xτ_t+1。此扩散过程,可以描述为随机微分方程 (SDE) [72] 的解。在此公式下,高斯扰动核的效果等同于设 f (x, τ ) = 0 且 g(τ ) = (2σ ̇ (τ )σ(τ ))1/2。为了从噪声中生成样本,可以使用逆-时间的随机微分方程 (SDE) [2] 进行逆向采样。由于得分函数可以由网络估计,通过最小化采样的未来状态 xˆ_t+10 = D_θ(xτ_t+1, y_t) 与真实未来状态 x0_t+1 之间的差异来学习条件去噪模型 D_θ。
使用 EDM 进行学习。如 [33] 中所述,直接学习去噪器 D_θ (xτ_t+1, y_t) 可能会受到噪声幅度变化等问题的影响。因此,遵循 [1] 并采用 EDM [33] 中的做法,改为使用预处理来学习网络 F_θ。这种转换的一个关键点在于,根据噪声调度 σ(τ) 自适应地混合信号和噪声,从而创建一个新的训练目标,以便更好地学习网络 F_θ。直观地讲,在高噪声水平(σ(τ) ≫ σ_data)下,cτ_skip → 0,网络主要学习预测干净信号。相反,在低噪声水平(σ(τ) → 0)下,cτ_skip → 1,目标变为噪声成分,从而阻止目标函数变得无关紧要。
实现。从技术上讲,用 DiT [60] 实现网络 F_θ。给定一系列实际世界状态潜嵌入 {x0_t = x_t},首先按照高斯扰动创建带有噪声 {xτ_t } 的潜嵌入。接下来,将噪声潜嵌入与旋转位置嵌入 (RoPE [73]) 连接起来,并将其作为输入传递给 DiT。就条件 y_t = (x0_≤t , a_≤t , cτ_noise ) 而言,时间嵌入由自适应层正则化 (AdaLN [61]) 进行调制,并且当前机器人动作作为 DiT 内交叉注意层的键和值,进行条件生成。为了所有注意机制的稳定性和效率,用具有可学习尺度的均方根归一化(RM-SNorm[92])来稳定处理空间表征的训练,同时将时间动作序列作为条件。
用于策略学习的 GWM
用于强化学习的 GWM。其证明 GWM 可以无缝集成到现有的基于模型强化学习方法中。形式上,马尔可夫决策过程 (MDP) 由三元组 (S, A, p, r, γ, ρ_0) 定义。S 和 A 分别是状态和动作空间,γ 是折扣因子,r(s, a) 是奖励函数。基于模型的强化学习 [31] 的目标是学习一个策略 π,该策略 π 最大化折扣奖励的预期总和 π∗ = arg max_π E_π [sum(γtr_t)],同时使用策略部署构建动态模型 p_θ(s_t+1, r_t | s_t, a_t)。在算法 1 中提供基于模型 RL 策略学习的伪代码。在此公式下,在 GWM 上添加一个额外的奖励预测头,以参数化动态模型 p_θ(s_t+1, r_t|s_t, a_t)。为了提高在视觉操作任务中的表现,按照 [82] 中讨论的设计选择构建基础 RL 策略。

用于模仿学习的 GWM。在模仿学习中,用 GWM 作为更有效的编码器,为策略学习提供更好的特征。具体而言,用扩散过程中第一步去噪后的特征向量作为下游策略模型(如 BC-Transformer [59] 和扩散策略 [9])的输入。第一个去噪步,处理代表性空间信息以处理严重的噪声水平。在实现中,以连续的块来预测动作,以提高机器人控制的一致性。
环境。为了全面分析 GWM 的能力,在两个合成环境和一个真实环境中评估方法:(1)META-WORLD [90],一个用于学习机器人操作 RL 策略的合成环境;(2)ROBOCASA [59],一个大规模多尺度合成模仿学习基准,具有厨房环境中的各种机器人操作任务;(3)FRANKA-PNP,一个使用 Franka Emika FR3 机械臂的真实世界拾取和放置环境。
任务。设计四项任务来系统地评估各种测试环境中的 GWM:(1)动作条件场景预测评估 GWM 在世界建模和未来预测中的有效性;(2)基于 GWM 的模仿学习检查表示质量及其对基于模仿学习的机器人操作好处;(3)基于 GWM 的 RL 探索其基于模型强化学习的潜力; (4)真实世界任务部署评估 GWM 在真实世界机器人操作中的鲁棒性。
动作条件场景预测
实验设置。世界模型生成高保真且与动作对齐展开的能力对于有效的策略优化至关重要。为了评估这一能力,在所有考虑的真实和合成环境中的人类演示上训练 GWM,并通过将模型训练到从验证集中采样的未见动作轨迹上来评估未来的预测质量。为了进行定量评估,用常见的生成质量指标,包括用于测量时间一致性的FVD [76]、用于像素级精度的基于图像指标(包括PSNR [29])以及用于感知质量的SSIM [81]和LPIPS [95]。
基于GWM的模仿学习
实验设置。GWM可用于从图像观察中提取信息表征,这有望有益于模仿学习。在 ROBOCASA 上测试 GWM 的模仿学习有效性来验证这一特性。 ROBO-CASA 中的任务套件包含 24 个原子任务,并配有适用于厨房环境的相关语言指令,包括取放、打开和关闭等操作。每个任务都提供 50 个人类演示和 3000 个来自 MimicGen [55] 的生成演示。用这些演示训练 GWM,并将其作为状态编码传递给最先进的 BC-Transformer [59],以便对成功率指标进行定量比较。
基于 GWM 的强化学习
实验设置。在六个 Meta-World [90] 机器人操作任务上评估 GWM 的强化学习策略能力,这些任务的复杂度不断增加。实施一种受 MBPO [31] 启发的基于模型强化学习方法,使用 GWM 生成合成的展开,以增强 DrQ-v2 [88] Actor- Critics算法的重放缓冲区。采用最先进基于图像的世界模型 iVideoGPT [82] 作为强大的基准。为了公平比较,不对这两种方法进行预训练初始化。为了公平比较,所有比较方法都使用相同的上下文长度和视野,并且训练步数最多为 1 × 105。
真实世界部署
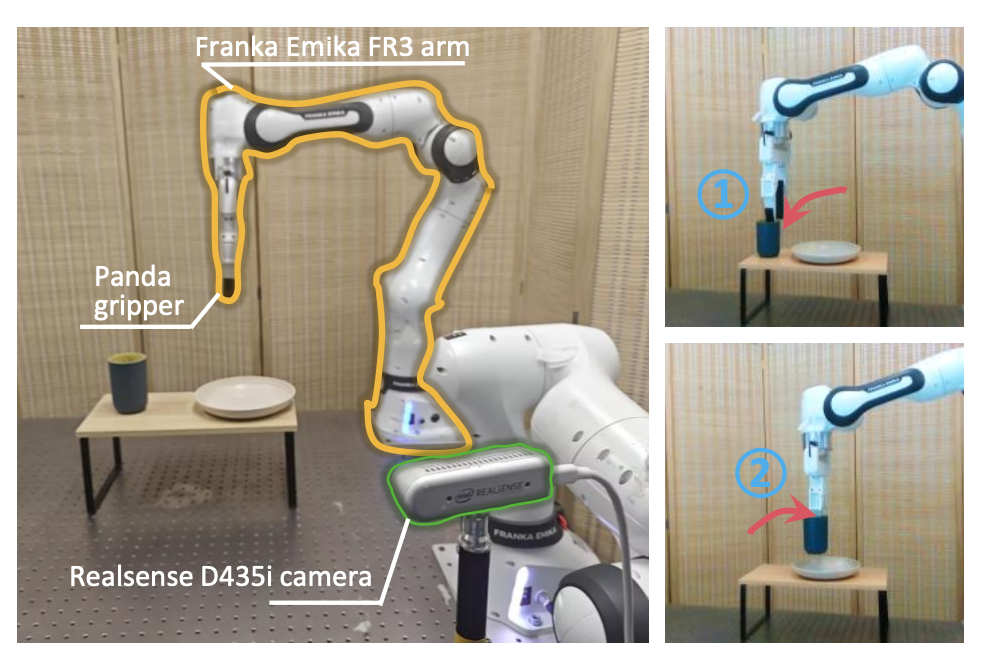
实验设置。部署一个 Franka Emika FR3 机械臂和一个 Panda 机械手进行真实机器人实验。专注于现实世界的任务:拿起一个彩色的杯子,并将其放在桌子上的盘子上。用 Mujoco AR 遥操作界面收集 30 个演示样本。还设置一个第三视角 Realsense D435i 摄像头,用于提供未摆拍的纯 RGB 图像以供观察。如图所示概述真实世界的任务设置。比较最先进的基于 RGB 的策略扩散策略 [9] 在有或没有 GWM 表示的情况下对任务成功率的表现,以进行定量分析。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)