【大模型测试】大模型AI中Transformer、TensorFlow、pytorch中相互之间的关系是什么,详细介绍
TensorFlow和PyTorch是两大主流深度学习框架,而Transformer是一种革命性的神经网络架构。两个框架都提供张量计算、自动微分等核心功能,但设计理念不同:PyTorch更灵活适合研究,TensorFlow对生产部署更友好。Transformer因其卓越的并行化能力和长距离依赖捕捉能力,成为大语言模型的基石。三者关系体现为:框架是实现架构的工具,开发者可以用任一框架实现Transf
所有机器学习从业者和学习者都会遇到的核心概念。作为一名大模型算法专家,我将为你清晰地梳理这三者的关系。
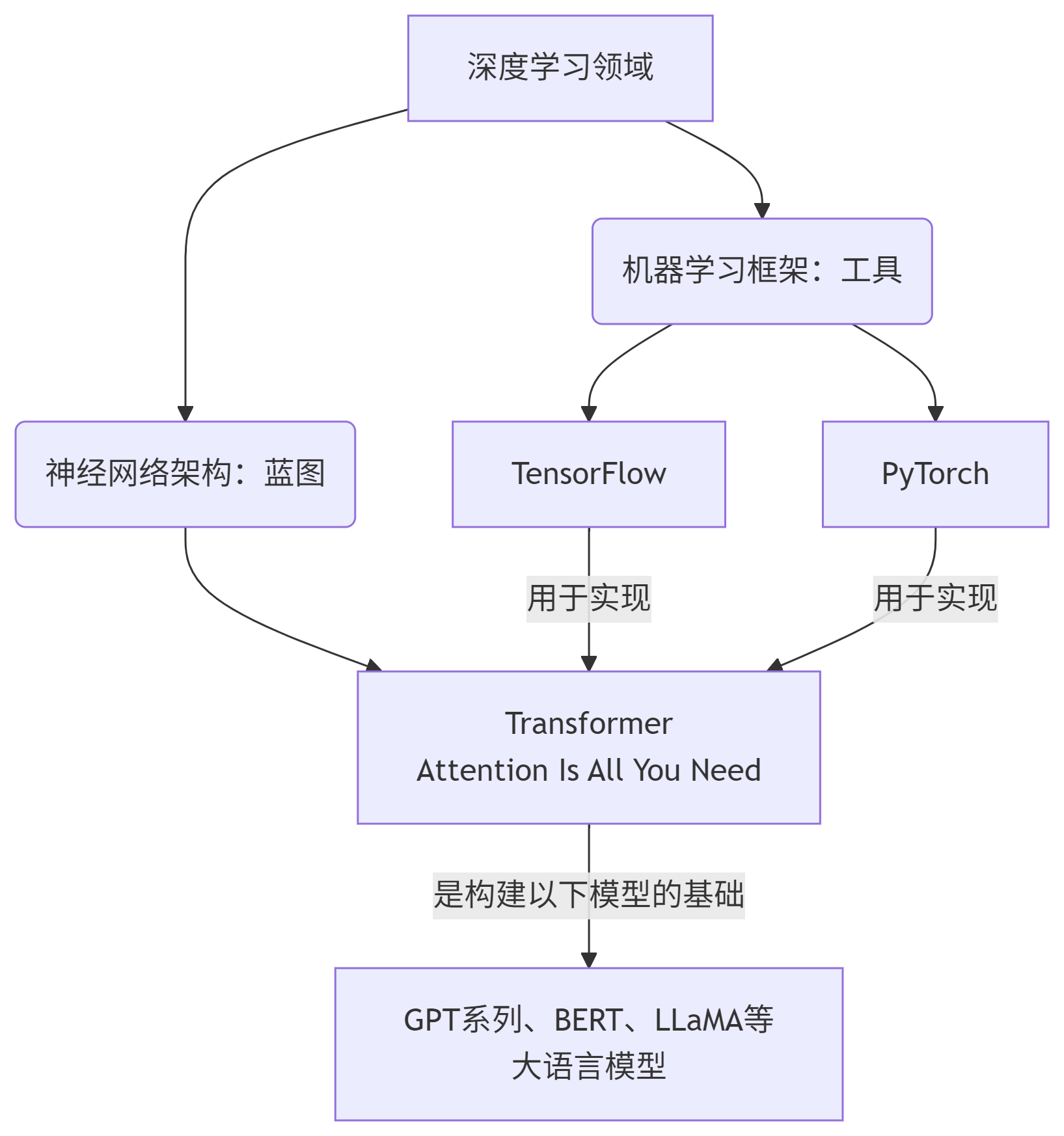
简单来说,这是一个 “两个基础框架” 和 “一个核心架构” 的关系。
-
TensorFlow 和 PyTorch 是机器学习框架,是工具,是平台。
-
Transformer 是一种神经网络架构,是模型设计,是蓝图。
它们之间的关系就像:
-
TensorFlow/PyTorch :像是 “厨房和整套厨具”。
-
Transformer :像是 “一道名菜(比如宫保鸡丁)的经典菜谱”。
你可以用 TensorFlow 这套厨具,也可以使用 PyTorch 那套厨具,来根据 Transformer 这个菜谱,做出美味的菜肴(即训练出强大的模型)。
详细分解
1. TensorFlow vs. PyTorch (框架之争)
这两者是当前最主流的深度学习开源框架。它们的核心目标是一致的:提供一套工具,让开发者能够更高效地定义、训练和部署机器学习模型。它们都提供:
-
张量计算:支持GPU加速的N维数组操作。
-
自动微分:自动计算梯度,这是训练神经网络的核心。
-
丰富的神经网络构建模块(层、损失函数、优化器等)。
-
庞大的生态系统(如可视化工具、部署方案)。
然而,它们在哲学和设计上有所不同:
| 特性 | PyTorch | TensorFlow (2.x) |
|---|---|---|
| 核心理念 | 命令式、Pythonic | 图执行、生产优先 |
| 学习曲线 | 平缓,更符合Python编程直觉 | 相对陡峭,但有Keras简化了入门 |
| 调试难度 | 非常容易(动态图,可直接调试) | 容易(Eager模式下与PyTorch类似) |
| 静态图 | 通过 torch.jit 等支持(可选) |
通过 @tf.function 支持(推荐) |
| 社区与研究 | 在学术界和研究领域占据绝对主流 | 在工业界和生产环境非常强大 |
| 部署 | 通过 TorchScript, TorchServe | 通过 SavedModel, TFLite, TF Serving (优势领域) |
| API | 更统一,主要由PyTorch团队维护 | 稍显复杂,有TF核心API和Keras高级API |
简单比喻:
-
PyTorch 像 Python:灵活、动态、易于学习和调试,非常适合研究和快速原型设计。
-
TensorFlow 像 Java:更严谨、对大规模部署和生产环境有更深层次的优化和支持。
现状:两者在不断趋同。TensorFlow 2.x 吸收了 PyTorch 的动态图优势,推出了 Eager Execution。PyTorch 也在不断增强其生产部署能力(如 TorchServe)。对于新手来说,两者都是绝佳的选择,PyTorch 目前在研究社区更受欢迎。
2. Transformer (架构之王)
Transformer 与上面两个框架完全不在一个维度。它是由 Google 团队在 2017 年的论文《Attention Is All You Need》中提出的一种神经网络架构。
-
它是什么? 一种完全基于自注意力机制的模型设计,摒弃了之前主导NLP领域的循环神经网络(RNN)和卷积神经网络(CNN)。
-
它为什么重要? 它的并行化能力更强,训练效率远高于RNN,并且在捕捉长距离依赖关系上表现极其出色。
-
它带来了什么? Transformer 架构是当今所有大语言模型的基石。GPT 系列、BERT、T5、PaLM 等所有你听说过的强大模型,都是基于 Transformer 架构构建的。
3. 三者如何协同工作?
这就是最精彩的部分:框架是用来实现架构的工具。
-
你可以使用 TensorFlow 来实现 Transformer:
python
# 伪代码:使用 TensorFlow/Keras 定义 Transformer 中的自注意力层 import tensorflow as tf from tensorflow.keras.layers import Dense, Layer class SelfAttention(Layer): def __init__(self, d_model): super(SelfAttention, self).__init__() self.wq = Dense(d_model) self.wk = Dense(d_model) self.wv = Dense(d_model) def call(self, q, k, v, mask): # ... 实现自注意力的计算 ... return output -
你也可以使用 PyTorch 来实现完全相同的 Transformer:
python
# 伪代码:使用 PyTorch 定义相同的自注意力层 import torch.nn as nn class SelfAttention(nn.Module): def __init__(self, d_model): super(SelfAttention, self).__init__() self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) def forward(self, q, k, v, mask): # ... 实现完全相同的自注意力计算 ... return output -
预训练模型库:由于 Transformer 如此重要,社区出现了像 Hugging Face Transformers 这样的库。它提供了一个统一的API,让你可以无缝地在 TensorFlow 或 PyTorch 框架下加载、训练和使用预训练的 Transformer 模型(如BERT、GPT-2)。这进一步模糊了框架之间的界限,让研究者更关注模型本身而非框架细节。
总结与关系图
图表
给你的建议:
-
新手入门:如果你想快速上手、做研究、读论文并复现代码,从 PyTorch 开始 是目前社区更主流的选择。它的编程风格更受研究人员喜爱。
-
工业部署:如果你关注的是将模型部署到移动端、嵌入式设备或大规模服务器集群,TensorFlow 的生产工具链(如 TF Lite, TF Serving)仍然非常强大和成熟。
-
核心重点:不要过于纠结框架二选一。它们的核心概念(张量、自动求导、层/模块)是相通的。学好一个后,切换到另一个的成本并不高。你的核心竞争力应该是对机器学习理论、模型架构(如Transformer) 和问题解决能力的深度理解,而非对某个框架的精通。
-
实践路径:直接去学习 Transformer 架构的原理。然后尝试用你选择的框架(PyTorch推荐)从零开始实现一个简单的 Transformer 模型(比如用于机器翻译),这会让你对三者关系的理解达到新的高度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)