树莓派 5 上运行 Gemma3:270m 本地大模型体验
树莓派5成功运行轻量级大语言模型Gemma3:270m。通过Ollama框架在8GB内存的树莓派5上部署,模型运行速度约18 tokens/s,适合简单对话和语音助手场景。虽然处理复杂任务能力有限,但270M的小模型体积使其成为边缘计算的理想选择。文章详细介绍了从环境配置到systemd服务设置的完整流程,展示了在资源受限设备上运行AI模型的可能性,为DIY智能设备开发提供了新思路。
树莓派 5 上运行 Gemma3:270m 本地大模型体验
最近脑子里一直有个想法:树莓派 5 能不能直接跑大语言模型?
大模型确实很吃算力,但一些小模型其实已经可以在单板机上运行。于是我就尝试了一下 Gemma3:270m,结果发现:它真的可以跑起来!
环境准备
运行环境:
-
硬件:Raspberry Pi 5 (8GB RAM)
-
系统:Raspberry Pi OS (Bookworm 64-bit)
-
模型框架:Ollama
Ollama 在 ARM64 架构下也提供了预编译包,但是因为 Pi 上网络经常拉不下来大文件,我选择了在笔记本上下载好,再传到树莓派。
下载地址:
👉 ollama-linux-arm64.tgz
上传到树莓派之后解压安装:
sudo tar -C /usr -xzf ollama-linux-arm64.tgz
然后创建 ollama 用户并配置 service:
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
配置 systemd 服务
在 /etc/systemd/system/ollama.service 新建 service 文件:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=multi-user.target
启动服务:
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollama
sudo systemctl status ollama
运行 Gemma3:270m
准备工作完成后,就可以直接拉取并运行模型了:
ollama run gemma3:270m
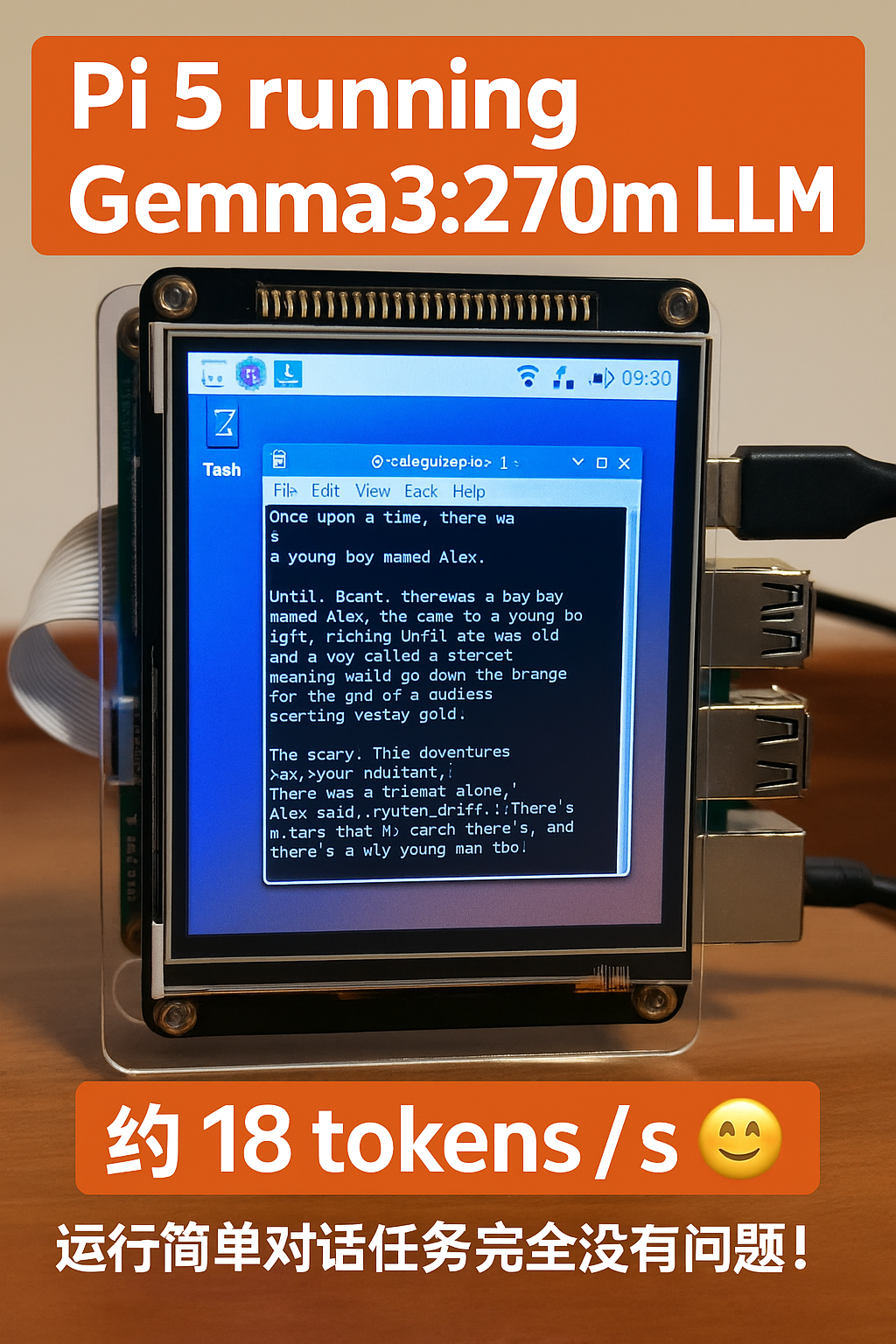
效果如下图:
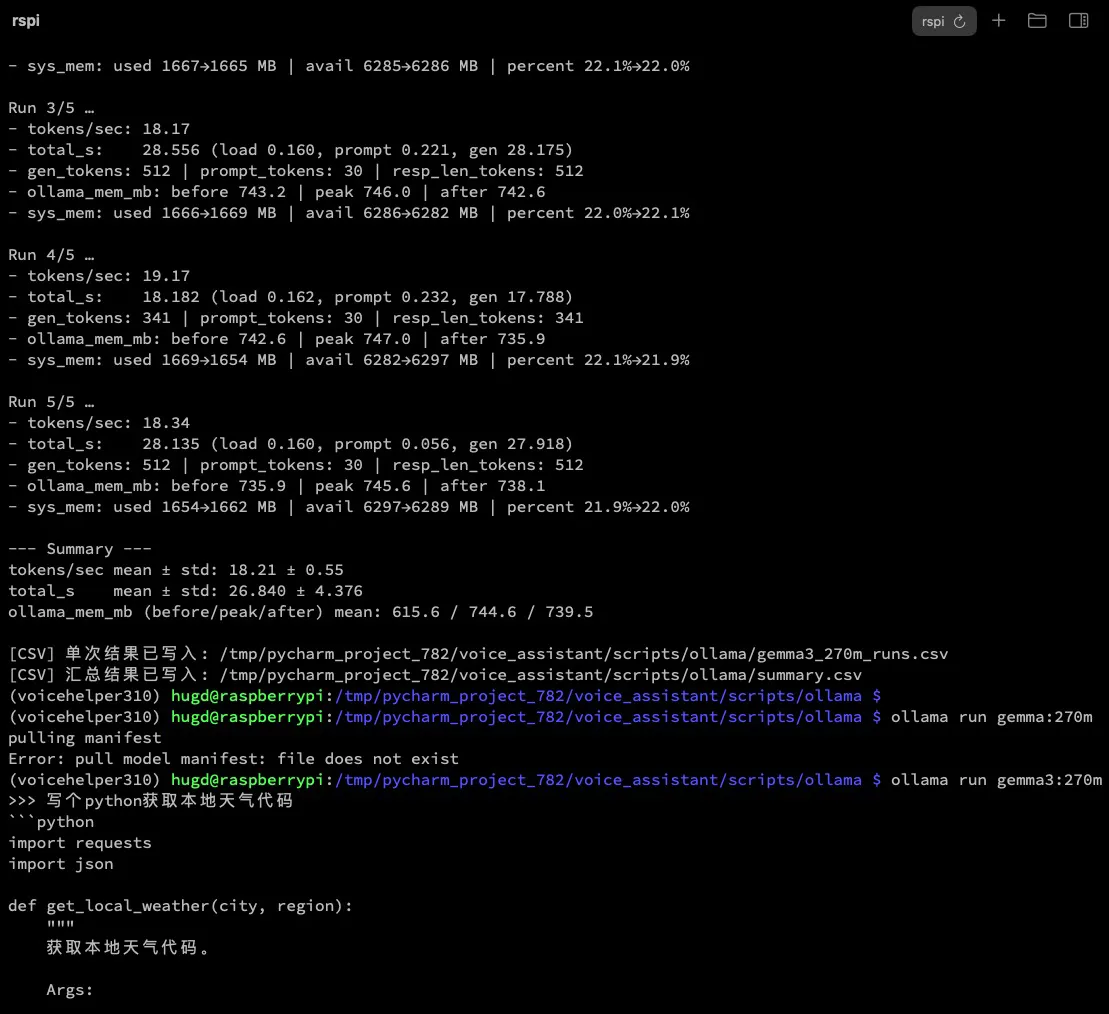
在 Raspberry Pi 5 上,Gemma3:270m 可以跑到 约 18 tokens/s,简单的对话完全没有问题。
使用体验与总结
-
优势:
-
模型小(270M),可以常驻内存
-
性能在树莓派上完全够用
-
简单对话、命令控制、语音助手类场景非常合适
-
-
不足:
-
模型能力有限,处理复杂问题会力不从心
-
树莓派的存储和内存还是有限,不适合跑大模型
-
✨ 总结一句:Gemma3:270m 非常适合作为 Raspberry Pi 上的轻量级本地大语言模型,尤其适合 DIY 语音助手、边缘计算等小场景。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)