基于Q-Learning的无模型AI Agent学习效率提升研究
基于无模型方法的AI Agent能在未知环境中通过交互直接学习最优策略,具备更强的适应性和泛化性。通过引入经验回放、ε-贪婪策略等机制,可以显著提升决策效率。未来结合深度学习与元学习的无模型方法,将为人工智能的发展开辟新的路径。
·
基于Q-Learning的无模型AI Agent学习效率提升研究
1. 引言
人工智能(Artificial Intelligence, AI)的发展推动了智能体(Agent)在自动驾驶、金融交易、智能制造和机器人控制等领域的广泛应用。传统的基于模型的方法(Model-based Methods)往往依赖环境动态的精确建模,而在复杂、不确定或难以建模的环境下,效率和泛化能力受到限制。
因此,基于无模型方法(Model-free Methods)的AI Agent成为研究的重点,其核心思想是不需要显式环境模型,而是直接通过与环境交互学习最优决策策略。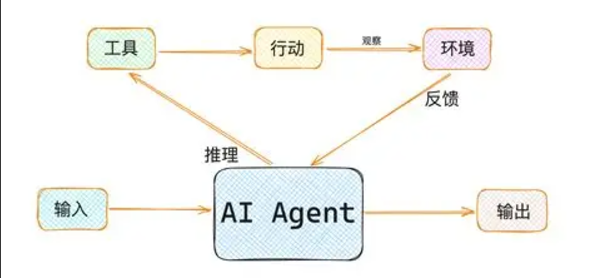
2. 无模型方法的核心思想
无模型方法的关键在于:
- 无需环境转移概率模型,直接通过交互数据更新策略。
- 依赖强化学习(Reinforcement Learning, RL)的框架,基于奖励信号优化决策。
- 典型方法包括 Q-Learning、SARSA、以及深度强化学习中的 Deep Q-Network (DQN)。
2.1 优势
- 通用性强:可应用于未知或复杂环境。
- 在线学习:能在动态环境中持续适应。
- 计算高效:避免了建模和推理的开销。
2.2 挑战
- 探索与利用的平衡(Exploration vs Exploitation)。
- 样本效率低:需要大量交互才能收敛。
- 稳定性与收敛性问题。
3. 高效决策机制设计
为了提升无模型AI Agent的决策效率,研究者们提出了多种优化机制:
3.1 经验回放(Experience Replay)
将交互经验存储在缓冲区中,随机采样进行训练,避免数据相关性过强。
3.2 ε-贪婪策略(ε-Greedy)
通过在随机探索和贪婪利用之间动态调整ε值,平衡探索与利用。
3.3 优势函数(Advantage Function)
在Actor-Critic框架下引入优势函数,提高策略更新效率。
4. 代码实战:基于Q-Learning的无模型AI Agent
下面我们以经典的 FrozenLake 环境(冰湖环境,OpenAI Gym 提供) 为例,演示无模型方法下AI Agent的高效决策过程。
import numpy as np
import gym
# 创建环境
env = gym.make("FrozenLake-v1", is_slippery=False) # 冰湖环境,非随机滑动
n_states = env.observation_space.n
n_actions = env.action_space.n
# 初始化Q表
Q_table = np.zeros((n_states, n_actions))
# 超参数
alpha = 0.8 # 学习率
gamma = 0.95 # 折扣因子
epsilon = 1.0 # 探索率
epsilon_min = 0.01
epsilon_decay = 0.995
episodes = 1000
# Q-Learning算法
for ep in range(episodes):
state = env.reset()[0]
done = False
while not done:
# ε-贪婪选择动作
if np.random.rand() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(Q_table[state, :])
# 执行动作
next_state, reward, done, _, _ = env.step(action)
# Q值更新
Q_table[state, action] += alpha * (
reward + gamma * np.max(Q_table[next_state, :]) - Q_table[state, action]
)
state = next_state
# 动态调整epsilon
if epsilon > epsilon_min:
epsilon *= epsilon_decay
# 测试训练好的Agent
state = env.reset()[0]
env.render()
done = False
total_reward = 0
while not done:
action = np.argmax(Q_table[state, :])
next_state, reward, done, _, _ = env.step(action)
env.render()
state = next_state
total_reward += reward
print("智能体总奖励:", total_reward)
4.1 代码分析
- Q表更新:智能体通过不断迭代更新
Q(s,a)。 - ε-贪婪策略:保证了训练初期充分探索环境,后期逐渐趋向利用已学得的最优策略。
- 最终效果:Agent能在冰湖环境中学会避免陷阱,找到通往目标的路径。
5. 未来展望
- 深度强化学习:结合神经网络逼近Q函数,提升大规模状态空间的学习能力。
- 元学习(Meta-Learning):提升Agent在多任务环境下的泛化性。
- 分层决策机制:通过宏观策略与微观动作的结合,提高决策效率。
6. 结论
基于无模型方法的AI Agent能在未知环境中通过交互直接学习最优策略,具备更强的适应性和泛化性。通过引入经验回放、ε-贪婪策略等机制,可以显著提升决策效率。未来结合深度学习与元学习的无模型方法,将为人工智能的发展开辟新的路径。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)