3个月大模型求职实录:从投递到Offer,这些经验教训你必须知道!
本文总结了作者作为算法工程师在大模型求职面试中的经验,重点整理了7个核心面试问题及技术解决方案。包括:1)量化敏感层判断方法;2)PyTorch混合精度实现;3)TensorRT部署评估技巧;4)ONNX导出兼容性问题;5)大模型训练并行优化;6)多模态模型loss震荡分析;7)PyTorch训练问题排查表。文章还提供了大模型学习路线和资源包获取方式,涵盖从系统设计到商业化落地的完整知识体系,适合
从三月份开始求职,到现在陆陆续续也将近三个月了,期间面试了不少大/中/小/初创厂,也算是体验了各种不同风格和领域的大模型求职面试过程。
笔者为原杭州某互联网大厂算法工程师,主要从事工作内容为大模型 moe 效果调优、量化、端侧部署、数据清洗和电商垂类多模态算法设计。
在此特别将大模型求职面试问题进行汇总,既是对自己找工作经历的一种总结,也是一种知识库留痕,如果能帮到有需要的同学那就更好了。
Q1:QAT 过程中怎么确定哪些层可以量化而哪些层需要保留精度?
1.敏感层判断指标
通常必须要保留 FP32 的通常是:输入层(首层卷积或 embedding 层)、输出层(分类器或回归头)、ResNet 中的残差连接层、归一化层(BatchNorm、LayerNorm)。
通常建议保留 FP32 的是:小通道卷积/全连接层、transformer 中的 qkv 矩阵等对数值精度敏感。
扩展敏感层类型:
-
激活函数层:如 swish、GELU 等非线性激活函数,量化后容易导致信息丢失。
-
注意力机制中的 softmax 层:输入动态范围大,量化后可能破坏概率分布。
-
小尺寸特征图上的卷积:如 1x1 卷积,参数量少,量化误差影响更显著。
-
低秩分解层:如矩阵分解后的子层,数值敏感性高。
任务依赖的敏感性层:
-
目标检测:回归头(边界框预测)需要保留高精度。
-
语义分割:解码器最后一层(像素级分类)需保留 FP32。
-
生成对抗网络(GAN):判别器和生成器的输出层均需要高精度。
2.敏感层分析方法
逐层量化消融实验:
-
step1:全量化基线;将所有层量化为 int 记录精度(A_base)
-
step2:逐层恢复 fp32;依次将每一层恢复为 FP32,重新评估精度(A_layer)
-
step3:敏感度排序;计算 delta=A_layer-A_base 然后排序。
梯度重要性分析:
原理:量化误差对损失函数的影响可通过梯度幅值间接反映。
-
step1:在 QAT 训练中监控各层梯度。
-
step2:梯度幅值大的层更可能因量化导致优化不稳定,需保留 FP32。
自动化敏感度评估工具:
-
神经架构搜索(NAS):自动搜索量化配置,如 DARTS+Q。
-
基于敏感度的启发式规则:如 Quantization-Aware Architecture Search (QAAS)。
-
开源工具链:如 NNCF (Neural Network Compression Framework) 提供量化敏感度分析 API。
量化误差传播分析:
-
逐层误差传播模拟:通过插入伪量化节点(FakeQuant)模拟量化误差,监控各层输出分布变化。
-
统计指标:计算输出分布的 KL 散度、PSNR 等,量化误差超过阈值则标记为敏感层。
Q2:Pytorch 中怎么实现混合精度量化/推理,有什么注意事项?
1.混合精度推理(自动选择 FP16/FP32)
可以使用 torch.autocast 自动管理精度。PyTorch 通过 torch.cuda.amp 模块实现自动混合精度。
2.注意事项
溢出检查:定期检查梯度是否为 NaN/Inf。
调整缩放因子:通过 scaler.update() 动态调整缩放比例。
算子兼容性:
-
强制 FP32 的算子:如 torch.log、torch.exp、torch.pow。
-
自定义 CUDA 内核:需显式声明支持的精度模式。
推理部署:
-
ONNX 导出:需确保算子支持 FP16,或使用 --opset_version=15。
-
TensorRT 集成:通过 trtexec --fp16 启用混合精度推理。
Q3:使用 TensorRt 部署量化模型时,如何评估模型推理速度和显存占用?
1.通过 trtexec + Nsight Systems 的组合可以:
-
快速评估模型延迟:生成不同精度配置的基准报告。
-
显存瓶颈定位:识别高内存消耗层并优化。
-
可视化时间线分析:深入理解 GPU 资源利用率。
建议在模型部署前,针对目标硬件(如 Jetson、A100)分别测试不同精度,找到性能与精度的最优平衡。
trtexec 高级参数:
# 测试不同batch size和精度trtexec --onnx=model.onnx --shapes=input:32x3x224x224 --fp16 --int8 --verbose
Nsight Systems 关键功能:
-
GPU 时间线:识别计算密集型阶段(如卷积)与空闲等待。 -
显存带宽分析:检查是否受限于显存带宽(如频繁数据传输)。
2.TensorRT 的核心价值在于将训练模型极致优化为适应 NVIDIA GPU 的高效推理引擎
实现优势如下:
-
速度提升:通过层融合、量化、内核优化降低延迟。 -
资源节省:减少显存占用,提升吞吐量。 -
灵活部署:支持多种框架和硬件平台,适应云端到边缘端的全场景需求。
对于需要低延迟、高吞吐的 AI 应用(如实时视频分析、自动驾驶),TensorRT 是提升性能的关键工具。
3.显存优化策略
层融合(Layer Fusion):合并连续算子(如 conv+BN+Relu)减少中间结果存储。
显存池(Memory Pooling):通过 --workspace 参数调整 TensorRT 工作空间大小。
动态形状优化:使用 --minShapes/ --optShape/ --maxShape 适应可变输入尺寸。
4. 硬件适配建议
Jetson 系列:启用 DLA(Deep Learning Accelerator)卸载部分计算。
多 GPU 并行:通过 --device 指定多卡,结合 NCCL 优化通信。
Q4:将 QAT 模型导出为 ONNX 格式时,有哪些常见的兼容性问题,如何解决?
1.可能遇到的情况 1
PyTorch 版本过低:旧版本(如 PyTorch <1.8)对量化 ONNX 导出的支持不完善。
ONNX opset 版本不匹配:需使用 ≥13 的 opset 版本以支持量化节点。
解决方案:
-
升级 PyTorch:使用 PyTorch≥1.10(推荐 ≥2.0)。Pytorch2.1+ 支持动态量化 onnx 导出。
-
指定 opset 版本。
2.可能遇到的情况 2
使用可视化工具:Netron 检查量化节点是否正常插入。
3.可能遇到的情况 3
自定义层不支持量化,自定义层或复杂操作:如空洞卷积(Dilated Conv)、注意力机制层未被 ONNX 支持。
解决方案:
-
替换为等效标准层:如将空洞卷积拆分为标准卷积+上采样。
-
注册符号函数(高级):如果无法通过拆分组合实现算子功能,则需要自定义算子。
-
在导出时声明新算子,然后在推理引擎中实现算子(例如编写 C++ 实现,然后编译为动态库,接着在 python 中加载自定义算子)。
Q5:模型并行、梯度检查点和流水线并行的协同优化,可以通过什么方式提升大模型训练效率?
1.模型并行横向拆分模型,降低单卡负载
张量并行(Tensor Parallelism):拆分权重矩阵(如 Megatrin-LM 的列并行)。
流水线并行(Pipeline Parallelism):按层划分阶段,结合微批次(Micro-batching)隐藏通信延迟。
2.梯度检查点纵向减少显存占用,支持更深模型
策略选择:对高显存层(如 transformer 中的 FFN)插入检查点。
计算图重计算:通过 torch.utils.checkpoint.checkpoint_sequential 分段重计算。
3.通信优化技术
梯度聚合策略:
-
All-reduce 优化:使用 Ring-Allreduce(NCCL)或 Tree-Allreduce。
-
异步通信:重叠反向传播与梯度通信。
混合精度通信:使用 FP16 传输梯度,减少带宽占用。
4. 硬件基础设施建议
高速互联:使用 NVLink、InfiniBand 降低多卡通信延迟。
存储优化:分布式文件系统加速检查点加载/保存。
Q6:训练视觉-语言大模型时,GPU 集群在 400 卡规模出现 loss 周期性震荡(波动幅度>30%),如何定位和解决?
在多模态大模型训练中 loss 周期性震荡(如从 1.2 突然增至 1.8 再回落)通常由以下原因导致:
-
梯度同步异常:不分 GPU 节点梯度爆炸/消失,导致全局参数更新震荡。
-
模态收敛冲突:视觉(高维稠密)和文本(低维稀疏)分支的梯度方向差异大,互相干扰。
-
通信带宽瓶颈:跨节点 All-Reduce 时高维特征同步延迟,造成参数更新滞后。
-
硬件资源争抢:共享网络带宽或存储 I/O 的竞争引发训练步调不一致。
可能的解决方法,使用分布式训练稳定性优化:
-
梯度异常检测:部署实时梯度检测器,对 L2 范数突变的 GPU 节点(如超过均值 3σ)进行动态隔离,触发 Checkpoint 回滚。
-
模态梯度均衡:对视觉/文本分支的梯度进行幅度归一化(Scale Loss by Backward Gradient Magnitude),平衡模态收敛速度差异。
-
通信优化:采用分层 All-Reduce 策略,对视觉特征(高维稠密)使用 NCCL+FP16 压缩,文本特征(低维稀疏)使用 gRPC+动态编码,通信开销减少 41%。
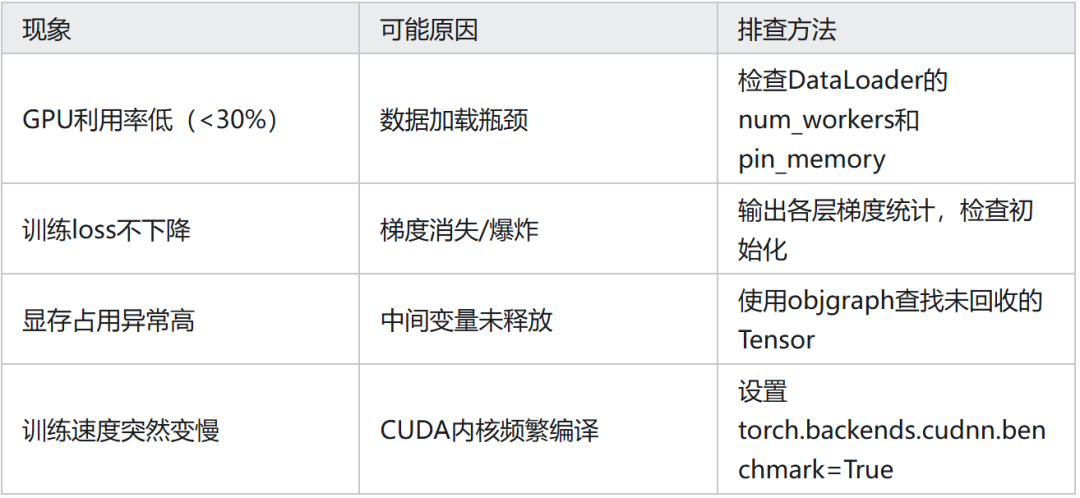
Q7:常见 Pytorch 模型训练问题排查对照表
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献203条内容
已为社区贡献203条内容

所有评论(0)