RAG技术实战:从文档分块到混合检索的全面优化指南|大模型原理
文章深入探讨了RAG技术的实现细节与优化策略,指出RAG常被视为黑盒导致问题定位困难。文章从文档分块、索引增强、编码、混合检索到重排序等关键环节进行了详细解析,强调需结合具体场景对各模块进行调优,以提升召回率与精确率的平衡。文章倡导从快速使用走向深度优化的实践路径,帮助开发者更好地诊断问题、找到可优化节点,做出更合理的迭代设计。
简介
文章深入探讨了RAG技术的实现细节与优化策略,指出RAG常被视为黑盒导致问题定位困难。文章从文档分块、索引增强、编码、混合检索到重排序等关键环节进行了详细解析,强调需结合具体场景对各模块进行调优,以提升召回率与精确率的平衡。文章倡导从快速使用走向深度优化的实践路径,帮助开发者更好地诊断问题、找到可优化节点,做出更合理的迭代设计。

阿里妹导读
本文深入探讨了RAG(Retrieval Augmented Generation)技术的实现细节与优化策略,指出在AI应用开发中,RAG常被视为黑盒导致问题定位困难。文章从文档分块(Chunking)、索引增强(语义增强与反向HyDE)、编码(Embedding)、混合检索(Hybrid Search)到重排序(Re-Ranking)等关键环节进行了详细解析,强调需结合具体场景对各模块进行调优,以提升召回率与精确率的平衡,并倡导从快速使用走向深度优化的实践路径。
写在前面
随着AI应用开发的普及,RAG成了一个家喻户晓的词,非常朴实且出镜率极高,不过在平时也会经常听到一些声音,“RAG效果不好,可能需要微调模型”,“xxx上的RAG产品不好用,召回不精准”,“我需要更强大的RAG工具,不然这个效果很难提升”等等,首先可以肯定,光从上述一些话术中不能说明大家对于RAG的实践和结论是有问题的,但是当进一步沟通的时候,比较多的case中会发现比较那回答出“为什么你觉得RAG不好用?”,“有实际case吗?比如什么样的query召回了什么样的知识?”,“我们的文档是怎么组织的?如何编写的?有做一些结构和分块上的处理吗?”。
日常我们会比较多的把RAG当成一个黑盒,输入是我们沉淀的文档,输出可能是整个AI应用反馈的最终结果(如下图所示),这样的方式下,我们可能可以收获一定的初期收益,但是当要持续优化或者扩展使用场景的时候,可能会缺乏评估和应对的方式,比较难去定位问题,因此也不太能说清楚当下链路的诉求,最后所对应的action也可能会偏离比较大。
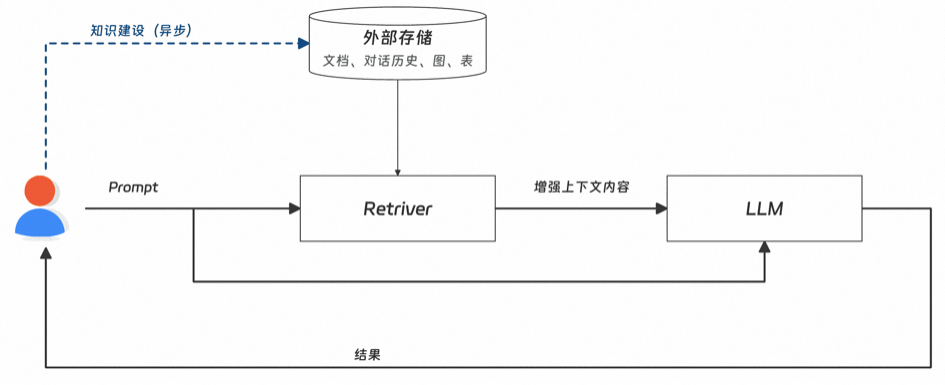
Fig1.RAG链路图-粗粒度版,有缺失
下面想稍微深入探索下RAG链路和涉及的一些技术细节,希望可以给到实践中的小伙伴一些参考,从而可以更好的诊断问题、找到可优化的节点,做出更合理的迭代设计。
重新介绍下RAG
RAG核心的功能就是针对用户Query,补充和Query相关的且模型没有的信息,同时要在两个维度上做要求:1.召回率:能够找到最相关的信息;2.精确率:不相关的信息不要;RAG技术以及我们针对实践的设计,主要就是锚定这两个维度指标的提升去的,同时这两个指标在现实实践中是个权衡,需要找到一个相对适合的值,追求两者都很高,不太现实,或者说可能需要付出的代价不足以让我们这么去做。
RAG是RetrievalAugmentationGeneration三个词的缩写,代表了三个核心的行为Retrieve-检索、Augment-增强以及Generate-生成,同时在三个核心动作之外,还有一个embedding-编码,具体见下图:
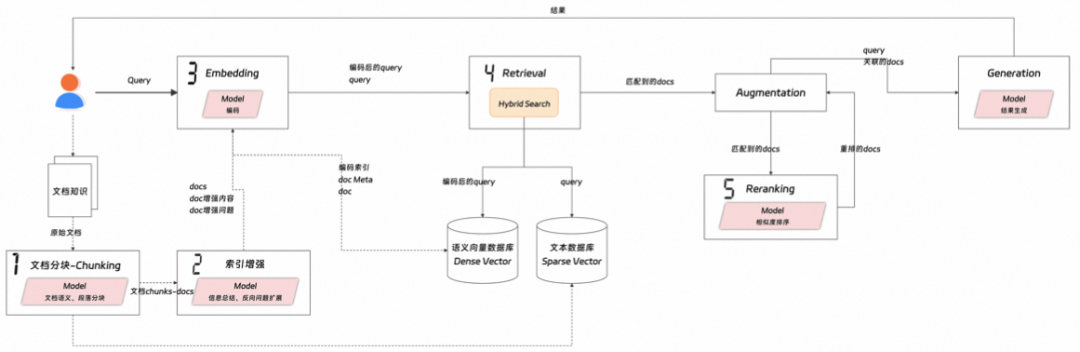
Fig2.RAG链路图-细粒度版
下面分别针对笔者觉得可能影响RAG实践中效果的一些技术点(图中标有编号的部分),做进一步的描述。
1. 文档分块-Chunking
所谓兵马未动粮草先行,要有一个好的检索结果,首先要从我们的知识文档的优化开始,我们实践中比较重视知识文档的内容沉淀,但是在一些文档结构组织,段落划分,以及一些知识点的内聚性和正交性上会涉及少一点。我们来看下一份文档在语义chunking(基础的按照token、字符、语句、段落切分大部分情况下效果都比较局限)下是被如何处理的。
# 设置本地数据保存目录
例子中是针对一篇论文做chunking,chunking会设置min_split_tokens(最小chunk的tokens数)和max_split_tokens(最大chunk的tokens数),chunking完之后的统计结果可见下面的图和表:
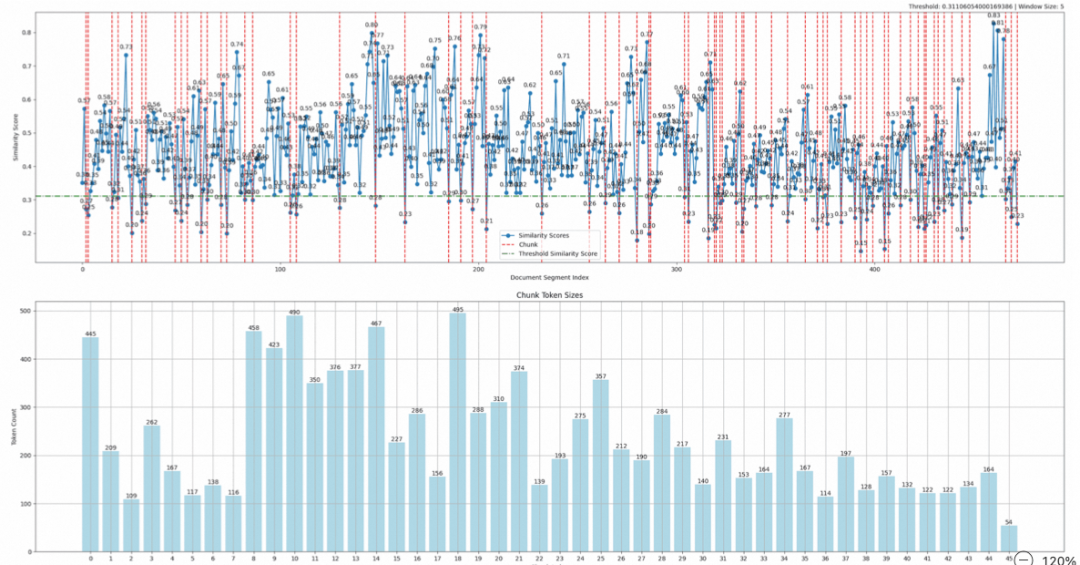
Chunking Statistics:
可以先看下统计的结果文字描述,简单做下解释:
- 整体Documents(可以简单理解为句子数,本部分设计的document都是该含义):474;
- 整体切分的文件块chunk:46个,其中41chunk的切分是基于相似度的阈值(可以理解为是按照语义正常划分出来的),有4个是因为达到了500tokens数量被切分的,还有最后1个chunk是到文章结尾了;
- 最大的chunk的token数495个,最小的chunk的token数54个,因为是lastchunk,所以会出现小于min_split_tokens的情况;
- 最后SimilarityChunkRatio是统计这次切分的chunk,89%的chunk是按照语义切分出来的(41/46);
SimilarityChunkRatio可以比较好的说明当前外部文档的chunking的结果,因为试想都是被max_split_tokens卡主划分的chunk,后续在语义检索的时候,结果也不会太好。实践中需要针对你的文档情况,调整split的token大小,在chunk的数量和相关性比例上达到一个平衡;除了chunk的大小,还有两个值需要关注:
- Threshold,就是所谓的相似度的下限,上面例子中threshold是0.31,该值越大,chunk内的相关性越好;
- WindowSize,是被用于计算的document的数量大小,默认是5,即每次是选择连续的5个document计算相似度,windowsize设置越大,上下文切分的相关性越好,但是同时chunking过程的计算量和耗时也更高,chunk大小相对要大;
这篇论文《Meta-Chunking: Learning Text Segmentation and Semantic Completion via Logical Perception》也给出了一个基于逻辑和语义的chunking的方法,有完整的效果评测,可参考;除了semantic Chunking之外,还有面向多模态数据文档类型的Modality-Specific Chunking(可以比较好的区分不同内容类型的文档块,并面向文本、表格、代码、图使用不同的chunking策略)和Agentic Chunking(让能力强的LLM阅读全文,判断给出切分策略),上述都是工具箱里面的工具,实践中需要结合自身的场景、知识现状、成本综合去权衡选择,并且面向效果进行调优或者切换更适合的方式。
2. 索引增强-Indexing
索引增强,这里介绍两种类型:1.语义增强;2.反向HyDE。
语义增强
语义增强就是将chunk和该chunk所在的文档内容(这里是整片论文)传给LLM,让LLM结合整个文档对这段chunk作个概述,然后把这个概述的信息append到chunk的内容中,从而增强在后续进行语义检索时的精确性。
DOCUMENT_CONTEXT_PROMPT = """
这里的LLM选择需要能力比较强的大模型,最好可以有promptcache功能,这样可以大大节省这一部的模型调用开销;同时也有一些做法是可以增加前后两个chunk的内容,对于整体文档比较长且前后文本关联度比较大的场景会有一些增强的效果。
反向HyDE
HyDE,Hypothetical Document Embeddings,是正向query检索增强的一种方式,即可以针对用户的query,生成一些假设的答案或者做query扩写,然后通过这些中间内容去做检索召回;反向HyDE的意思是针对chunk(可以视为answer),生成这块chunk可能的question,然后针对这些quetion进行索引构建,关联到具体的chunk内容;反向HyDE相比HyDE的优势是可以离线处理,不影响实时调用的rt。
Given the following text chunk, generate {n} different questions that this chunk would be a good answer to:
该方法比较适合这类问答型的知识,比如一些答疑内容,有明确的A和Q的,或者可以作为后面hybridsearch中的关键词扩写,提升后续混合检索的效果。
3. 编码-Embedding
Embedding大家应该都很熟悉,就是将输入的文本(多模态内容)转换成向量,主要过程包含文字到token的切分,然后每个token在词汇表中有对应的id,每个tokenid都会对应同等维度(不同embedding模型维度不同)的向量,可以看个简单的例子。
first_sentence = "直播分享会AI Living第一场"

编码之后是当前文本对应的tokens的tokenid列表,这里影响编码的原因有这些:
-
编码模型的语言问题,不同语言会有不同的分词和词汇表,比如例子中使用的这个编码模型all-MiniLM-L6-v2在处理中文的文本时候,就比较差,可以看到返回的id有好些100(不可识别的token),中文的处理可以找相应的中文embedding模型,但是不是所有语言都有对应的编码模型,因为语种太多,同时如果一些语种对应的数据语料太少,不足以训练这样的一个模型。
-
编码模型的词汇表大小,例子中的all-MiniLM-L6-v2的词汇表大小是30522,有些主流模型的词汇表大小基本都在5w以上,有些10w以上,词汇表小会导致一些词无法表示,只能用一个兜底tokenid来代替,会影响后续处理的效果;词汇表大能精准标识文本的输入,但是间接也会增加文本编码完之后的token大小。
-
编码模型的语义空间,不同的编码模型有自己的词汇表,以及自己对应的向量语义空间,向量语义空间的效果决定于该模型训练基于的数据集,目前用于文本编码的模型,基本都是现有世界知识的通用语义空间,偏日常、大众化的关联,如果我们需要在一个特定领域下,有一个特殊的语义空间,可能就需要找一个使用该领域下的数据训练的embedding模型,或者需要自己SFT一个,不然预期想要的效果和实际效果可能会有比较大的gap。(顺便说下图知识的问题,直接拿图片当知识,处理过程可能就是OCR的文本提取,或者是LLM对于图片的理解描述,但是这里的干扰会很大,比如中间过程的文本,是不是你期望的样子和描述的维度,这些都需要把握下,不然后续的检索召回肯定也是一团浆糊)
4. 检索-HybridSearch
HyBridSearch,混合搜索,本质上是结合了Term-based和Semantic-based两种模式的检索特性,通过融合两种形式的算法,来提升检索的准确性和相关性;HybridSearch结合了SparseVector(稀疏向量)相似度计算----关键词匹配和DenseVector稠密向量相似度计算----语义匹配,从而提升检索的效果,可见下图:
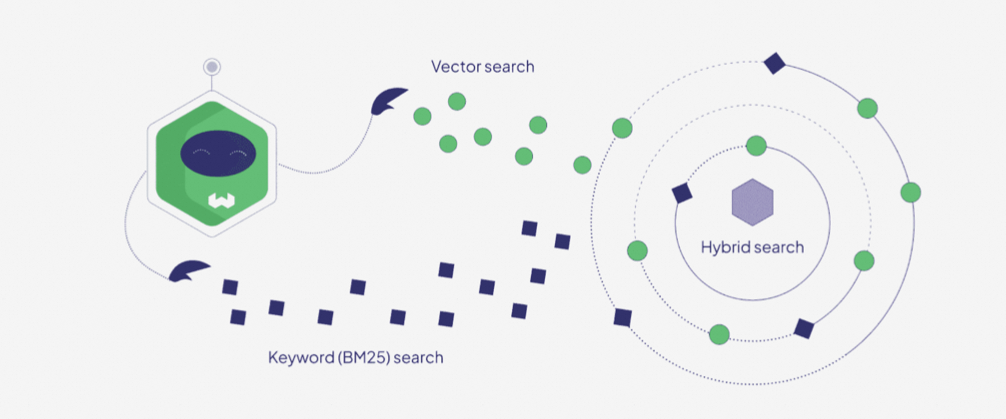
Sparse向量主要是通过BM25为代表的算法生成,BM25核心就是TF-IDF算法(词频-反向文档频率),返回是某个query相对每个文档编号的分数值(具体算法如下)。
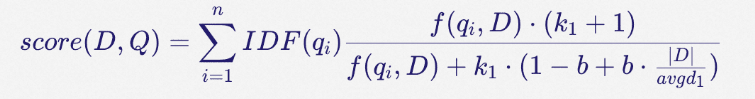
# Load the chunks
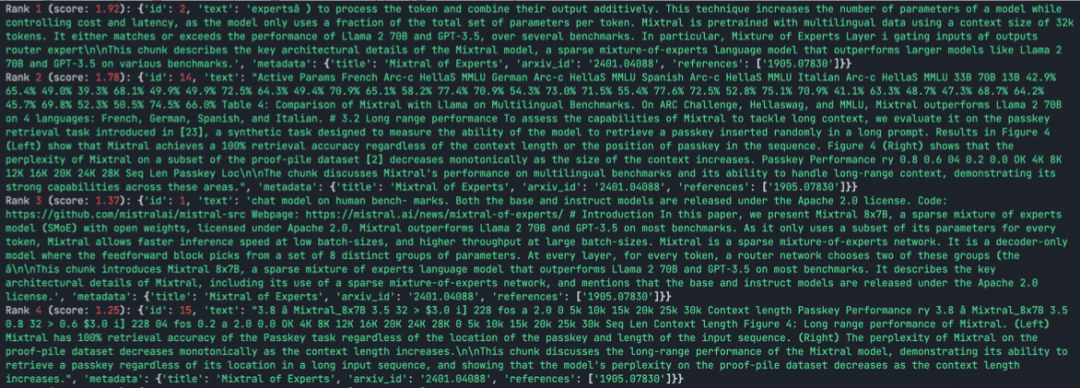
Dense向量主要是通过基于Transformer架构的embedding模型来进行编码生成,同时针对查询query,使用同样的embedding模型进行编码,然后再进行向量的相似度比对,找出最相似的n个结果。
#Dense Index
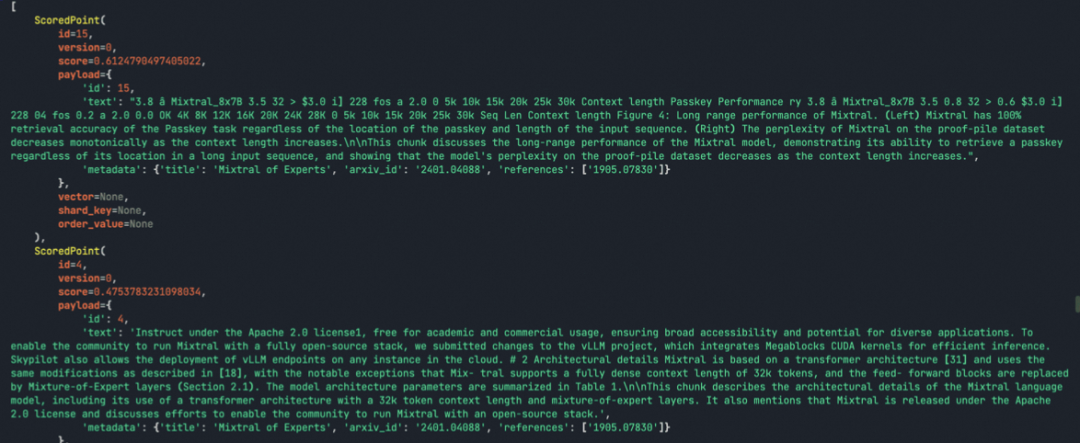
最后针对上述两种方式找出的chunk做综合筛选,这里可以有多种方式,比如比较常用的就是先分别对Sparse向量和Dense向量计算出来的topn个结果的分值做归一化,然后针对统一个Chunk,按照一定的权重(比如Sparse向量计算结果权重0.2,Dense向量计算结果权重0.8)计算一个最终分值,最后返回topn个chunk列表给到下个节点:
# Normalize the two types of scores

如果当前场景的检索需要兼顾关键词和语义的时候,可以考虑混合搜索(需要结合文档内容、chunking和关键字词构建等环节);相对于关键字词匹配检索,混合搜索可以降低查询编写的规范性(不一定要有特定的关键词出现)以及提升查询的容错性(可能会有拼写错误或者不恰当的描述);相对于语义相似检索,混合搜索可以增加一些领域专有信息的更精准匹配,提升检索结果的准确性。
5. 重排-ReRanking
检索的优点是可以在海量的知识里面快速找到和用户query相关的内容块docs,但是检索所返回出来的docs,实际上可能部分和用户query关联度并不大,这个时候就需要通过re-rank这一步,对于检索返回出来的docs做关联度排序,最终选取最相关的topk个doc,做后续的上下文补充。
在RAG链路中,ReRanking的常用技术是Cross-Encoder(交叉编码器),本质一个Bert模型(Encode-only的transformer架构),计算query和每一个doc相关性,返回0~1之间的结果(1代表最相关),示意图和代码示例如下:
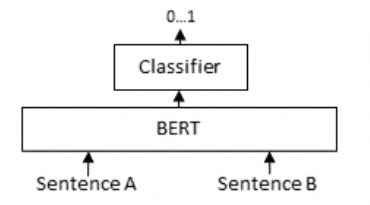
from sentence_transformers import CrossEncoder

最后进行排序,选择topk个结果补充到context中,然后调用模型拿最后的结果:
client = OpenAI(
结语
AI应用的开发实践进行得非常火热,现阶段可能更多的是对已有的一些基建平台、开发编排工具、现成的横向基础产品做整合使用,结合使用场景做链路设计。但是随着时间推移,还是需要慢慢深入到部分细节,往深水区慢慢前行,本文讲述的RAG只是AI架构中的一块,其他相关的技术,在对待方式上也雷同,都需要经历快速使用、技术细节了解、使用产品实现了解、应用中的设计实现迭代、面向效果的循环优化,快速上手有捷径,得益于比较好的基础设施建设,成本比较低,但是深入追寻效果,切实提升效率或幸福感,需要更深入的探寻,希望对读到这里的小伙伴有帮助。
参考资料
- https://weaviate.io/blog/hybrid-search-explained
- https://www.sbert.net/examples/sentence_transformer/applications/retrieve_rerank/README.html
- https://learning.oreilly.com/videos/advanced-rag/11122024VIDEOPAIML/
创意加速器:AI 绘画创作
本方案展示了如何利用自研的通义万相 AIGC 技术在 Web 服务中实现先进的图像生成。其中包括文本到图像、涂鸦转换、人像风格重塑以及人物写真创建等功能。这些能力可以加快艺术家和设计师的创作流程,提高创意效率。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献203条内容
已为社区贡献203条内容

所有评论(0)