LangExtract如何解决LLM信息抽取痛点?精准定位、可审计性与长文档优化
langextract是一款专为解决LLM结构化输出难题而设计的Python库,通过"受控生成"机制确保稳定输出,采用字符级位置锚定实现精确溯源,并内置智能分块和并行处理策略以优化长文档处理。相比LangChain的通用框架,它专注于信息提取任务,提供更可靠的端到端解决方案,特别适合医疗、法律等高精度需求场景。
一、LangExtract是什么?
最近在开发过程中经常会用到大模型进行结构化输出或者结构化提取,如提取长文本信息,提取用户提问的查询条件生成结构化查询语句,提取规则生成结构化大纲等等,对比了不同的实现方案,发现一款LLM结构化提取的利器–langextract可以高效准确进行结构化提取生成。
大型语言模型的一个核心挑战始终存在:如何将自由、模糊的文本可靠、精准地转化为严谨、可用的结构化数据?这不仅仅是技术上的挑战,更是工程实践中的“最后一公里”难题。传统的做法,要么依赖于编写复杂的正则表达式进行多次校验等,但其维护成本高昂且难以应对多变文本;要么直接向LLM发出Prompt请求JSON格式输出,但这种方式常常因模型的概率性本质而产生格式不一致、字段缺失或内容“幻觉”等问题 。
Google推出的开源Python库langextract 应运而生。它并非又一个简单的LLM封装,而是一个专为解决这一“最后一公里”难题而生的专业级工具 。
二、为什么选择LangExtract?它与普通LLM输出的本质区别
传统的LLM结构化输出方法主要依赖于提示词工程,即通过在Prompt中明确要求模型以特定格式(如JSON)返回结果。这种方法在面对简单、短小的任务时尚可,但一旦处理大规模、多变或高风险领域的文本,其固有的缺陷便会暴露无遗。
2.1 传统方法的困境与langextract的破局
2.1.1 直接Prompt的不可靠性
问题根源:LLM的生成过程是基于概率的、非确定性的 。这意味着即使是同一个Prompt,模型在不同次调用时也可能返回略有差异的输出。在结构化数据提取的场景中,这种不确定性可能导致输出格式不一致、键值对缺失或类型错误,即所谓的格式“漂移” 。这种不稳定性使得下游系统无法可靠地解析和利用数据,为自动化工作流带来了巨大的障碍。 langextract通过其独特的“受控生成”机制,从根本上解决了这一问题。
LangExtract 的破局方法
-
受控生成: 通过 Pydantic Schema 预定义输出结构(如 JSON 格式),强制模型遵守字段类型、层级关系和键名规范。例如医疗场景中约束“剂量字段必须为字符串且包含单位”
-
示例驱动的模式约束: 提供高质量示例(ExampleData)作为“模板”,模型需严格模仿其结构输出。例如定义
{"medication": "药物名称", "dosage": "剂量"}后,模型无法擅自添加"dose"等未声明字段 -
输出围栏: 启用
fence_output=True参数,要求模型仅返回与示例结构完全匹配的内容,丢弃自由发挥的冗余信息
2.1.2 缺乏溯源的“黑盒”问题
问题根源:大多数LLM输出的结构化数据与原文脱离,数据来源不透明 。如果模型在提取过程中产生“幻觉”,凭空捏造了事实,或者对原文进行了不准确的释义和重述,用户很难追溯其来源,更无法进行人工验证 。这种“无中生有”的黑盒问题,在医疗、法律等对数据精确性要求极高的领域是无法接受的 。
LangExtract 的破局方法
-
字符级位置锚定 每项提取结果(如
"头孢唑啉")自动绑定原文中的精确字符区间(如start_pos=15, end_pos=19),通过char_interval属性实现 100% 可溯源 -
确定性文本对齐算法 采用 WordAligner 技术:先要求 LLM 返回原文片段(非改写),再通过模糊字符串匹配(如编辑距离算法)定位原文位置,避免基于 Embedding 的模糊定位误差
-
交互式可视化溯源 生成 HTML 报告,用户点击实体(如“药物剂量”)自动高亮对应原文位置,支持千级实体的快速人工复核
2.1.3. 长文档处理的效率与召回困境
问题根源:
-
上下文碎片化:传统LLM受限于上下文窗口长度(如4K-128K Token),处理百万级字符的长文档(如财报、小说)时需强制分块,导致跨块语义断裂。例如,关键信息若跨越两个分块边界,模型可能忽略其关联性,造成信息漏提•
-
单次扫描的召回率瓶颈:传统单轮抽取仅能捕捉局部信息,对分散在文档各处的“长尾实体”(如小说中次要人物、医疗报告中的罕见症状)召回率显著降低
langextract的破局方法:
-
多轮扫描机制:通过多次遍历文本(默认3轮),模型在不同“注意力焦点”下重读内容,显著提升关键信息的召回率。实验显示,3轮扫描可使长文档的实体召回率提升40%以上
-
智能分块与并行处理:动态分块时保留重叠缓冲区(
max_char_buffer参数),避免跨块信息割裂;结合max_workers参数启用并行处理,百万字符文档的处理时间可缩短至传统方法的1/3
2.2 langextract的核心优势
langextract的出现,为开发者提供了一个可靠的“生产级脚手架” ,其核心优势正是针对上述痛点而设计:
-
精确溯源:这是
langextract最引人注目的特性之一。每个提取的实体都精确标记其在原文中的字符偏移量 。这确保了每一项数据的可验证性和可审计性,从根本上杜绝了幻觉,并为后续的自动化验证和人工审核提供了强大的技术基础 。 -
稳定的结构化输出:
langextract通过“少样本学习”和“受控生成”技术,强制模型遵循预定义的Schema 。用户只需提供少量高质量的示例,langextract就能引导模型锁定在期望的输出格式上,极大地提升了输出的稳定性和可靠性,即使面对复杂的任务也能有效防止格式漂移 。 -
专为长文档而生:信息提取在面对长篇幅文档时,常常会遇到LLM因上下文窗口限制而出现的“召回率下降”问题,即所谓的“大海捞针”挑战 。
langextract采用了专门优化的长文本处理策略,包括智能分块、并行处理和多轮提取,有效处理百万Token级的长文本,确保高召回率 。 -
内置可视化工具:为了方便调试和验证,
langextract能够将提取结果一键生成交互式HTML报告 。用户可以在浏览器中直观地看到原文中被高亮标记的提取实体,以及其对应的结构化数据,这极大地简化了人工审核和质量控制的流程 。
三、LangChain与LangExtract结构化提取对比
LangChain提供了.with_structured_output()方法也提供了结构化输出的能力,该方法依赖于底层模型的原生支持(如OpenAI的JSON Mode或工具调用),如果模型不支持,则需要开发者手动使用输出解析器 。LangChain的强大之处在于其可组合性,但也可能引入额外的抽象层(如LCEL)和学习成本,这可能在处理某些特定任务时显得“过重”。langextract是专注于信息提取这一单一任务,并将其做到极致 。它提供了一套端到端的、高度优化的解决方案,将复杂的工程策略封装在库内部,开发者无需手动实现分块、并行等逻辑,只需关注提取任务本身。这种专注性使得 langextract在处理高复杂度的信息提取任务时,比通用框架更高效、更可靠。
| 特性 | LangChain |
langextract |
|---|---|---|
| 核心哲学 | 通用的LLM编排与应用开发框架 | 专业的、端到端的信息提取库 |
| 结构化输出机制 | 依赖底层模型原生功能(JSON Mode/工具调用)或手动输出解析器 | 依赖库内部的“受控生成”与少样本学习,模型无关性更强 |
| 长文档处理 | 需开发者手动实现分块、并行等逻辑 | 内置智能分块、并行处理、多轮提取等优化策略 |
| 输出可靠性 | 受模型非确定性影响,可能出现格式漂移 | 明确承诺“不漂移”,通过受控生成强制遵循预定模式 |
| 溯源与可验证性 | 默认不提供,需开发者自行实现 | 内置精确溯源,记录字符偏移量,确保数据可验证 |
| 内置可视化 | 无原生支持 | 一键生成交互式HTML报告,用于快速审核与调试 |
| 生态兼容性 | 广泛集成各种LLM、外部工具和数据库 | 支持主流LLM(Gemini、GPT)及本地模型(Ollama) |
四、LangExtract技术原理
langextract的真正价值在于它作为一个“智能层” ,在LLM的语言理解能力之上,提供了必要的控制和脚手架 ,将一个概率性、非确定性的模型,转化为一个可靠、可信赖的结构化数据提取系统。其核心技术正是对LLM固有缺陷的工程化解决方案。
4.1:受控生成与少样本学习
LLM天生是为生成连贯、流畅的文本而设计的,而非精确的数据结构。langextract解决这一问题的核心机制是“受控生成” 。它通过在Prompt中提供一份高质量的 ExampleData(即“少样本”) ,能够精确地向LLM演示期望的输出格式和规则。
这种方法比简单的JSON Mode更具指导性。它不仅仅告诉LLM“要提取什么”,更重要的是,通过具体的示例告诉它“如何呈现”)。这是一种更高级的“Prompt Engineering”,将模糊的指令转化为精确的模式。通过这种方式,即使面对复杂的、从未见过的文本,模型也能锁定在预设的模式上,显著减少了错误和格式漂移 。
4.2:精确的源文本定位
在医疗、法律等高风险领域,每一项提取都必须可验证 。 langextract通过记录每个提取实体在原始文档中的精确字符偏移量(char_interval)实现了这一点 。
这项技术为何至关重要?首先,它提供了可信度。由于每个提取都必须有在原文中的“出处”,这从根本上杜绝了LLM凭空捏造事实的可能性,保证了数据的真实性和可靠性。其次,它提供了强大的调试与自动化能力。当提取结果不正确时,字符偏移量可以帮助开发者快速定位问题所在 。此外,它还为下游应用(如交互式UI)提供了强大的数据基础,例如在网页上高亮显示提取的内容 。
4.3:长文档的优化策略
“长文本召回率下降”是LLM的通病 。为了解决这一问题, langextract内置了三项高效的优化策略:
- 智能分块:
langextract并非简单地按字符数硬性切分文档,而是尊重句子、段落等自然边界进行分块,以确保每个分块都具有完整的语义上下文 。这种智能切分方式确保了相关信息不会被硬生生割裂,从而提高了提取的准确性。 - 并行处理:通过
max_workers参数,langextract可以并行处理多个文本分块,显著提升了处理大规模文档的吞吐量 。这使得处理长篇小说、法律文书或年度报告等大型文档成为可能。 - 多轮提取:该策略通过多次扫描文档,以不同的分块或提取策略进行处理,以提高实体的召回率 。例如,在“大海捞针”场景下,多轮提取能够显著提升召回率,
但值得注意的是:langextract在百万Token上下文基准测试中,其召回率比单次提取提高了12% 。多轮提取虽然提高了召回率,但也可能因重复处理Token而增加成本,这是需要根据具体任务进行权衡的工程决策 。
五、入门实践
5.1 依赖安装
requirements.txt
streamlit>=1.28
openai>=1.2
streamlit-feedback
langextract
其中streamlit依赖主要是用于后面做一个综合案例测试。
5.2 简单提取和溯源
5.2.1 测试代码
import langextract as lx
# 待提取文本
input_text = "Patient took 400 mg PO Ibuprofen q4h for two days."
# 提取提示词
prompt_description = "Extract medication information including medication name, dosage, route, frequency, and duration in the order they appear in the text."
# 定义提取few-shot样例
examples = [
lx.data.ExampleData(
text="Patient was given 250 mg IV Cefazolin TID for one week.",
extractions=[
lx.data.Extraction(extraction_class="dosage", extraction_text="250 mg"),
lx.data.Extraction(extraction_class="route", extraction_text="IV"),
lx.data.Extraction(extraction_class="medication", extraction_text="Cefazolin"),
lx.data.Extraction(extraction_class="frequency", extraction_text="TID"),
lx.data.Extraction(extraction_class="duration", extraction_text="for one week")
]
)
]
MODEL_CONFIG = {
"model_id": "gpt-4.1-mini", # 模型名称
"model_url": "https://xxx/v1", # 接口地址
"api_key": "sk-xxx", # api-key
"temperature": 0.7
}
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt_description,
examples=examples,
**MODEL_CONFIG
)
# 打印提取结果
print(f"Input: {input_text}\n")
print("Extracted entities:")
for entity in result.extractions:
position_info = ""
if entity.char_interval:
start, end = entity.char_interval.start_pos, entity.char_interval.end_pos
position_info = f" (pos: {start}-{end})"
print(f"• {entity.extraction_class.capitalize()}: {entity.extraction_text}{position_info}")
# 可视化结果
lx.io.save_annotated_documents([result], output_name="medical_ner_extraction.jsonl", output_dir=".")
# 生成可视化网页
html_content = lx.visualize("medical_ner_extraction.jsonl")
with open("medical_ner_visualization.html", "w", encoding="utf-8") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data) # For Jupyter/Colab
else:
f.write(html_content)
print("Interactive visualization saved to medical_ner_visualization.html")
5.2.2测试结果
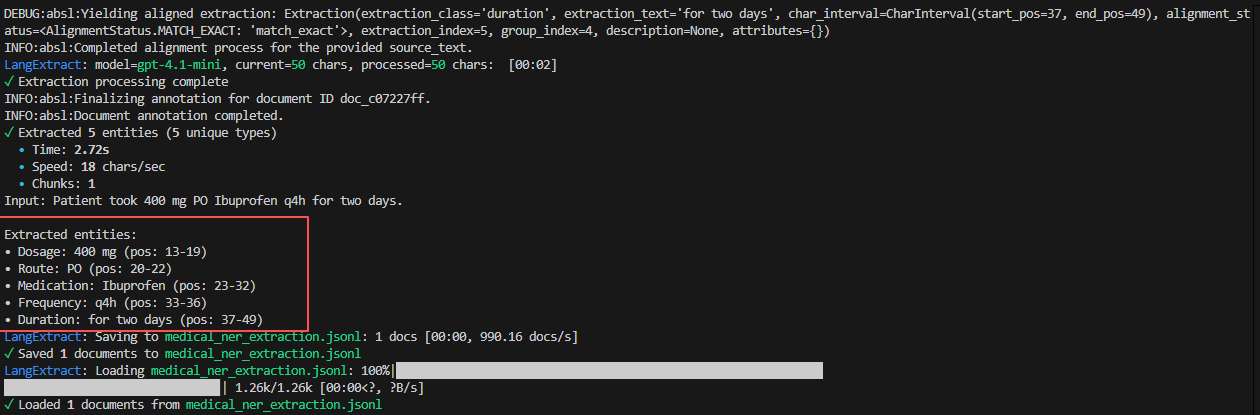
可以看到对应提取的entity 以及其对应在原文本的pos位置。
使用html网页进行可视化溯源:

5.3 综合测试场景
基于streamlit编写一个综合测试案例,覆盖基础提取,长文本提取,以及MQL 提取
5.3.1 测试代码
import streamlit as st
import langextract as lx
import textwrap
from langextract.data import ExampleData
import pandas as pd
import time
from langextract.data import Extraction
from langextract.data import ExampleData
MODEL_CONFIG = {
"model_id": "gpt-4.1-mini", # 模型名称
"model_url": "https://xxx/v1", # 接口地址
"api_key": "sk-xxx", # api-key
"temperature": 0.7
}
TEST_CASES = {
"基础提取测试": {
"prompt": textwrap.dedent("""\
提取人物、故事和关系,按出现顺序排列
使用原文文本,不进行改写或重叠"""),
"examples": [ExampleData(
text="江南烟雨朦胧,张无忌与赵敏并骑行至绿柳庄旧址。残垣断壁间,一柄断折的“武林至尊”旗斜插焦土,赵敏轻抚旗角冷笑:“当年六大派围剿光明顶,可曾想过今日?”话音未落,三枚透骨钉破空袭来!张无忌乾坤大挪移心随意动,钉头倏然转向,没入柳树三寸。阴影中走出玄冥二老,鹤笔翁森然道:“郡主娘娘,王爷念父女之情,命我等‘请’您回去。”鹿杖客却紧盯张无忌怀中凸起——那裹着屠龙刀碎片的布包,才是汝阳王府真正的目标",
extractions=[Extraction(
extraction_class="倚天屠龙记",
extraction_text="张无忌",
attributes=["张无忌是武林至尊"],
)]
)],
"input_text": "光剑影间,武当山道钟声穿透雨幕。宋青书率丐帮弟子围住众人,打狗棒直指张无忌:“弑叔之仇,武当逆徒当诛!”陈友谅阴笑捧出染血道袍,赫然是宋远桥的衣物。张无忌悲愤交加,九阳神功即将爆发时,杨逍弹指射落宋青书发簪:“蠢货!你怀中《武当心法》缺页,正是成昆模仿你笔迹所书!”一卷残册落地,末页画着玄冥二老向汝阳王密报的暗号——那图案竟与屠龙刀裂纹完全吻合"
},
"长文本提取": {
"prompt": "提取所有药物名称、剂量和给药途径,以及使用禁忌",
"examples": [ExampleData(
text="患者被给予250毫克静脉注射头孢唑啉",
extractions=[Extraction(
extraction_class="药品", extraction_text="头孢唑啉",
attributes={"dosage": "250毫克", "route": "静脉注射", "taboo":["禁止空腹", "不能喝酒"]},
)]
)],
"input_text": open("long_medical_report.txt", encoding="utf-8").read() # 假设存在长文本文件
},
"MQL提取": {
"prompt": "提取用户提问中可能涉及到的时间、指标、维度、过滤条件、分组聚合、粒度等用于分析数据的信息",
"examples": [ExampleData(
text="查询本年广州太古汇点A店铺的B和C款鞋子的每个月销售额",
extractions=[Extraction(
extraction_class="condition", extraction_text="查询条件",
attributes={"time": "本年", "shop": "广州太古汇点A店铺", "goods": ["B", "C"], "metric": "销售额", "group": "月份"}
)]
)],
"input_text": "分析过去12个月内华南地区每个店铺的A、B、C款商品销售额和销售量,按月汇总,找出其中卖的最好的店铺和商品"
}
}
TEST_RESULTS = []
def run_extraction(test_case):
try:
start_time = time.time()
result = lx.extract(
text_or_documents=test_case["input_text"],
prompt_description=test_case["prompt"],
examples=test_case.get("examples", []),
**MODEL_CONFIG,
)
latency = time.time() - start_time
formatted_result = [{
"class": ex.extraction_class,
"text": ex.extraction_text,
#"position": f"{ex.char_interval.start_pos}-{ex.char_interval.end_pos}",
"attributes": ex.attributes
} for ex in result.extractions]
for entity in result.extractions:
position_info = ""
if entity.char_interval:
start, end = entity.char_interval.start_pos, entity.char_interval.end_pos
position_info = f" (pos: {start}-{end})"
print(f"• {entity.extraction_class.capitalize()}: {entity.extraction_text}{position_info}")
#st.subheader(f"测试结果: {test_name}")
st.markdown(f"**提取实体数**: {len(formatted_result)}")
# 交互式表格
df = pd.DataFrame(formatted_result)
st.dataframe(df, use_container_width=True)
highlighted_text = []
for ex in formatted_result:
highlighted_text.append(
f"`{ex['text']}` "
)
st.markdown("".join(highlighted_text), unsafe_allow_html=True)
return {
"success": True,
"result": formatted_result,
"latency": latency,
"count": len(formatted_result),
"extract_result": result,
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
def visualize_results(test_name, results):
pass
# Streamlit界面
def main():
st.title("LangExtract 功能测试")
st.markdown("## 测试用例选择")
test_case_name = st.selectbox("选择测试类型", list(TEST_CASES.keys()))
if st.button("开始测试"):
with st.spinner("正在执行测试..."):
test_config = TEST_CASES[test_case_name]
results = run_extraction(test_config)
if __name__ == "__main__":
main()
运行代码:
streamlit run test_extract.py
代码中的测试长文本:long_medical_report.txt
以下是一份符合国家药品说明书规范的中成药通用模板,包含必要要素和示例内容,总字数约500字:
药品说明书
药品名称
通用名称:板蓝根颗粒
商品名称:清热解毒颗粒
英文名称:Banlangen Granules
汉语拼音:Banlangen Keli
成份
每袋含:
• 板蓝根 10g
• 大青叶 5g
• 连翘 3g
• 薄荷脑 0.1g(辅料:蔗糖、糊精)
性状
本品为浅棕色至棕褐色的颗粒;味微苦、清凉。
适应症/功能主治
清热解毒,凉血利咽。用于肺胃热盛所致的咽喉肿痛、口咽干燥;急性扁桃体炎、腮腺炎见上述证候者。
规格
每袋装10g(相当于饮片15g)
用法用量
口服:一次1袋,一日3次,饭后温开水冲服。
疗程:急性症状建议连续服用不超过7天,慢性炎症需遵医嘱调整。
不良反应
1. 常见:轻度胃肠道不适(如腹胀、腹泻)
2. 偶见:皮疹、瘙痒等过敏反应
3. 罕见:头晕、恶心加重(停药可缓解)
禁忌
1. 对本品成分过敏者禁用
2. 风寒感冒(恶寒重、无汗)者不宜使用
3. 糖尿病患者慎用(含蔗糖辅料)
注意事项
1. 特殊人群:
• 孕妇慎用,需医师评估
• 哺乳期妇女建议暂停哺乳
• 儿童需按年龄调整剂量(3岁以下减半)
2. 药物相互作用:
• 与滋补性中药同服可能减弱疗效
• 避免与抗凝血药物(如华法林)联用
3. 其他:
• 忌烟酒及辛辣食物
• 服药3天症状无缓解应就医
药理作用
1. 抗菌抗病毒:抑制流感病毒、金黄色葡萄球菌等病原体
2. 抗炎消肿:降低炎症因子IL-6、TNF-α水平
3. 免疫调节:增强巨噬细胞吞噬功能
贮藏
密封,置阴凉干燥处(温度≤25℃),避免阳光直射。
包装
复合膜袋装,每盒10袋。
有效期
24个月
执行标准
《中国药典》2020年版一部
批准文号
国药准字Z2023XXXX
生产企业
企业名称:XX制药有限公司
生产地址:XX省XX市XX区XX路XX号
联系电话:400-XXX-XXXX
说明书修订日期
2025年08月
注意事项补充
• 儿童用药:需在成人监护下使用,防止误服过量
• 老年用药:肾功能不全者建议调整剂量
• 药物过量:超过推荐剂量3倍时需立即洗胃
参考依据
本说明书内容符合《药品管理法》《药品说明书和标签管理规定》要求,参考了同类中成药(如)的规范格式,并整合了药理研究数据及临床用药反馈。
---
该模板可根据具体药品特性调整,建议实际应用时补充毒理研究、临床试验数据等专业内容。
**药品名称**
通用名:复方氨酚烷胺胶囊
商品名:感康®
英文名:Compound Paracetamol and Amantadine Hydrochloride Capsules
**成分**
每粒含:
- 对乙酰氨基酚 250mg
- 盐酸金刚烷胺 100mg
- 人工牛黄 10mg
- 咖啡因 15mg
- 马来酸氯苯那敏 2mg
**性状**
本品为硬胶囊,内容物为白色至淡黄色颗粒
**适应症**
缓解普通感冒及流行性感冒引起的发热、头痛、四肢酸痛、打喷嚏、流鼻涕、鼻塞、咽痛等症状
**规格**
12粒/盒,铝塑泡罩包装
**用法用量**
口服。成人一次1粒,一日2次(早晚各一次)。疗程不超过5天。
特殊人群:
- 肝功能不全者:剂量减半
- 老年人(>65岁):首日1粒,后续0.5粒/次
- 儿童(6-12岁):0.5粒/次,每日不超过1粒
**不良反应**
1. **常见**(>1%):嗜睡、口干、恶心
2. **偶见**(0.1%-1%):皮疹、头晕、食欲减退
3. **罕见**(<0.1%):粒细胞减少、肝功能异常(AST/ALT升高)
**禁忌**
1. 严重肝肾功能不全者禁用
2. 对乙酰氨基酚过敏者禁用
3. 妊娠期及哺乳期妇女禁用
**注意事项**
- 用药期间避免驾驶或操作机械(易致嗜睡)
- 避免与含酒精饮料同服(增加肝毒性风险)
- 合并使用抗凝药(如华法林)需监测INR值
- 贮藏条件:密封,避光,25℃以下保存
**有效期**
24个月(生产日期见盒底:YYYYMMDD)
**生产企业**
吉林感康制药有限公司
批准文号:国药准字H20230821
**药品名称**
通用名:萘敏维滴眼液
商品名:亮视®
英文名:Naphazoline Hydrochloride and Chlorphenamine Maleate Eye Drops
**成分**
每毫升含:
- 盐酸萘甲唑啉 0.2mg
- 马来酸氯苯那敏 2mg
- 维生素B12 0.1mg
辅料:硼酸、硼砂、依地酸二钠
**性状**
淡红色澄明液体,开启后需15天内用完
**适应症**
缓解眼睛疲劳、结膜充血及过敏性结膜炎引起的眼痒
**规格**
10ml/支,PE塑料瓶装
**用法用量**
滴入眼睑内。一次1-2滴,一日3-4次。
特殊限制:
- 连续使用≤3天(避免反跳性充血)
- 儿童(3-12岁):每日总量≤4滴
**不良反应**
- **眼部**:短暂刺痛感(发生率15%)、瞳孔散大
- **全身**:高血压患者可能出现血压波动(收缩压↑≥10mmHg)
**禁忌**
1. 闭角型青光眼患者禁用
2. 甲状腺功能亢进者禁用
3. 3岁以下婴幼儿禁用
**注意事项**
- 糖尿病者慎用(可能干扰血糖监测)
- 避免与MAO抑制剂(如司来吉兰)联用
- 贮藏:2-8℃冷藏,避免冻结
**有效期**
18个月(开封后有效期15天)
**生产企业**
江苏亮视生物科技有限公司
批准文号:国药准字H20231205
5.3.2 运行结果

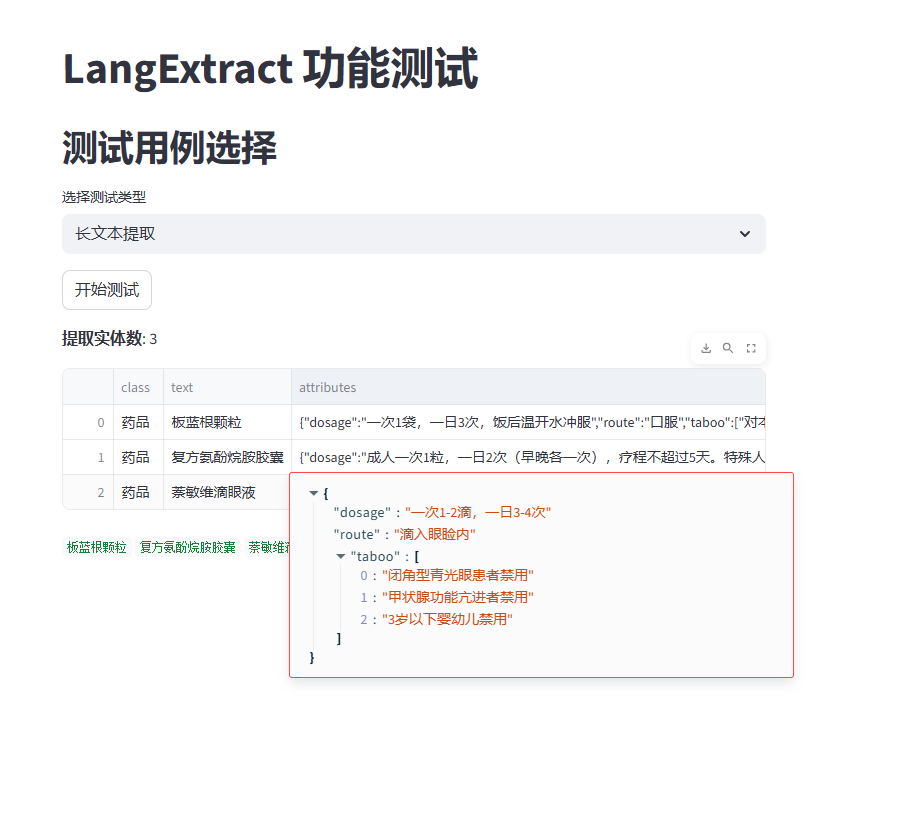
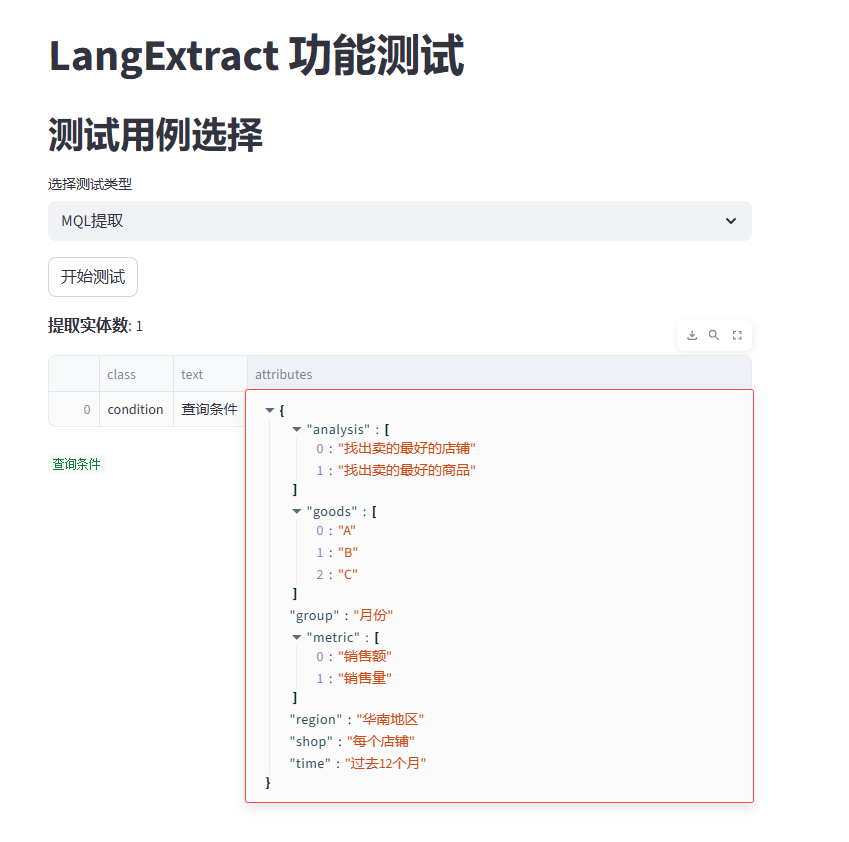
可以看到,在不同的场景下,LangExtract 的提取效果都是比较稳定的。
langextract的出现填补了LLM生态系统中的一个关键空白。它通过将复杂的工程策略(如智能分块、受控生成、并行处理)封装在一个简单、易用的库中,将LLM从一个“不可靠的文本生成器”提升为一个“可信赖的结构化数据提取引擎” 。它不试图成为一个包罗万象的框架,而是专注于将单一任务做到极致,这正是其能够提供生产级可靠性和性能的关键。
langextract将在企业知识库构建、智能文档处理、大规模数据分析、以及RAG系统元数据生成等领域展现出巨大潜力 。它代表了未来LLM工具发展的一个重要方向:从通用和抽象,走向专业、可靠和可信。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)