大模型落地:从微调到企业级解决方案的完整路径
本文系统阐述了大模型落地应用的关键技术与实施路径。主要内容包括:1)模型微调方法(全参数/参数高效/指令微调)及LoRA代码示例;2)提示词工程的设计原则与思维链等高级技巧;3)多模态应用的技术架构与实现案例;4)企业级解决方案的架构设计、安全过滤和缓存策略;5)性能优化技术对比及vLLM高性能推理方案;6)智能客服系统落地案例。文章强调大模型落地需综合数据质量、系统架构和成本控制,并指出小型化模
随着人工智能技术的飞速发展,大语言模型(Large Language Models, LLMs)已成为推动自然语言处理、多模态理解与生成、智能决策系统等领域的核心驱动力。然而,将大模型成功“落地”到实际业务场景中,远不止是部署一个预训练模型那么简单。它涉及模型微调、提示词工程、多模态应用集成以及企业级系统架构设计等多个关键技术环节。本文将系统性地阐述大模型落地的完整路径,结合代码示例、流程图、Prompt设计、图表与可视化内容,帮助开发者和企业构建高效、可扩展、可维护的大模型应用体系。
一、大模型微调:从通用模型到领域专家
大模型在通用语料上训练后具备广泛的语言理解能力,但要服务于特定行业或任务(如医疗、金融、客服),必须进行微调(Fine-tuning)。微调通过在特定数据集上继续训练模型,使其适应特定任务的语义和表达方式。
1.1 微调方法分类
|
全参数微调(Full Fine-tuning) |
更新模型所有参数 |
数据量大,算力充足 |
|
参数高效微调(PEFT) |
仅更新少量参数,如LoRA、Adapter |
资源受限,快速迭代 |
|
指令微调(Instruction Tuning) |
使用指令-响应对训练,提升任务理解能力 |
多任务、对话系统 |
1.2 使用LoRA进行高效微调(代码示例)
LoRA(Low-Rank Adaptation)是一种参数高效微调技术,通过低秩矩阵分解引入可训练参数,显著减少训练开销。
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, get_peft_model
import torch
# 加载预训练模型
model_name = "meta-llama/Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
# 配置LoRA
lora_config = LoraConfig(
r=8, # 低秩维度
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # 注意力层中的特定模块
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 查看可训练参数比例
输出示例:
trainable params: 2,097,152 || all params: 7,100,000,000 || trainable%: 0.0295%
仅训练0.03%的参数即可实现良好性能,极大降低显存和计算成本。
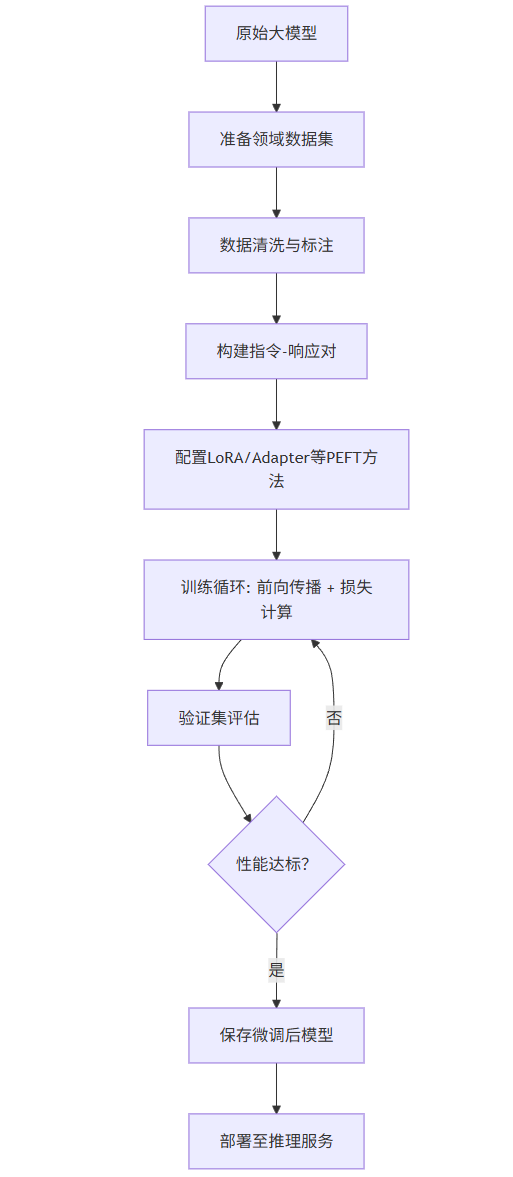
1.3 微调流程图(Mermaid)
graph TD
A[原始大模型] --> B[准备领域数据集]
B --> C[数据清洗与标注]
C --> D[构建指令-响应对]
D --> E[配置LoRA/Adapter等PEFT方法]
E --> F[训练循环: 前向传播 + 损失计算]
F --> G[验证集评估]
G --> H{性能达标?}
H -- 否 --> F
H -- 是 --> I[保存微调后模型]
I --> J[部署至推理服务]
二、提示词工程(Prompt Engineering):引导模型精准输出
即使不进行微调,通过精心设计的提示词(Prompt),也能显著提升大模型在特定任务上的表现。提示词工程是大模型落地中最灵活、成本最低的优化手段。
2.1 Prompt设计原则
- 明确任务:清晰说明输入输出格式
- 提供示例:Few-shot提示提升准确性
- 结构化指令:使用分步、条件判断等逻辑
- 约束输出格式:指定JSON、Markdown等结构
2.2 Prompt 示例:金融新闻情感分析
你是一个专业的金融分析师,请根据以下新闻内容判断其对市场情绪的影响。
要求:
1. 输出必须为JSON格式
2. 包含字段:sentiment(positive/negative/neutral)、confidence(0-1)、reason(简要解释)
新闻内容:
"美联储宣布将基准利率上调25个基点,以应对持续的通胀压力。"
请分析:
模型输出示例:
{
"sentiment": "negative",
"confidence": 0.85,
"reason": "加息通常抑制经济增长和股市表现,对市场情绪偏负面"
}
2.3 高级Prompt技巧:Chain-of-Thought(思维链)
通过引导模型“逐步思考”,提升复杂任务的准确性。
问题:小明有15个苹果,他每天吃2个,送朋友3个。多少天后他会吃完?
请按以下步骤思考:
1. 每天总共消耗多少个苹果?
2. 总苹果数除以每日消耗量是多少?
3. 如果不能整除,是否需要向上取整?
4. 给出最终答案。
回答:
问题:小明有15个苹果,他每天吃2个,送朋友3个。多少天后他会吃完?
请按以下步骤思考:
1. 每天总共消耗多少个苹果?
2. 总苹果数除以每日消耗量是多少?
3. 如果不能整除,是否需要向上取整?
4. 给出最终答案。
回答:
模型输出:
1. 每天消耗:2 + 3 = 5个苹果
2. 15 ÷ 5 = 3
3. 可以整除,无需取整
4. 答案:3天
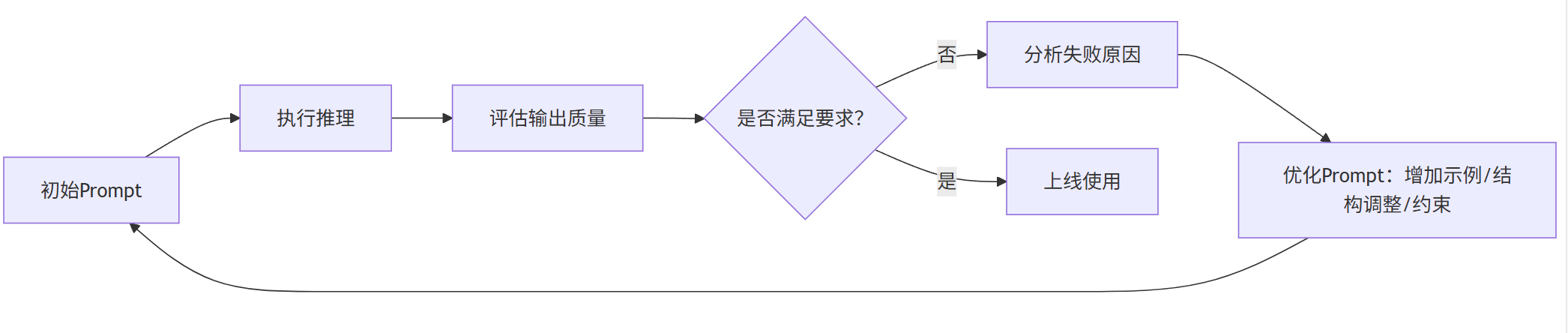
2.4 Prompt优化流程图
graph LR
P[初始Prompt] --> Q[执行推理]
Q --> R[评估输出质量]
R --> S{是否满足要求?}
S -- 否 --> T[分析失败原因]
T --> U[优化Prompt:增加示例/结构调整/约束]
U --> P
S -- 是 --> V[上线使用]
三、多模态应用:融合文本、图像、音频的智能系统
大模型正从纯文本向多模态(Multimodal)演进,能够理解图像、音频、视频并与文本联合处理,广泛应用于智能客服、内容生成、医疗影像分析等场景。
3.1 多模态模型架构
典型的多模态模型(如LLaVA、Flamingo)包含:
- 视觉编码器:如CLIP-ViT,将图像编码为向量
- 语言模型:如LLaMA、ChatGLM,处理文本
- 对齐模块:将图像向量注入语言模型的输入层
3.2 图像描述生成代码示例(LLaVA)
from transformers import AutoProcessor, LlavaForConditionalGeneration
from PIL import Image
import requests
# 加载模型
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)
processor = AutoProcessor.from_pretrained(model_id)
# 加载图像
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 构造Prompt
prompt = "USER: <image>\nDescribe this image in detail.\nASSISTANT:"
# 处理输入
inputs = processor(prompt, image, return_tensors="pt").to(model.device, torch.float16)
# 生成描述
output = model.generate(**inputs, max_new_tokens=200)
description = processor.decode(output[0], skip_special_tokens=True)
print(description)
输出示例:
ASSISTANT: The image shows two cats lounging on a couch. One cat is sitting upright with its tail curled around its body, while the other is lying down with its head resting on the arm of the couch. The room appears to be a living room with a window in the background.
3.3 多模态应用场景图表
pie
title 多模态应用领域分布
“智能客服” : 25
“内容生成” : 30
“医疗影像分析” : 15
“自动驾驶” : 10
“教育辅助” : 12
“其他” : 8
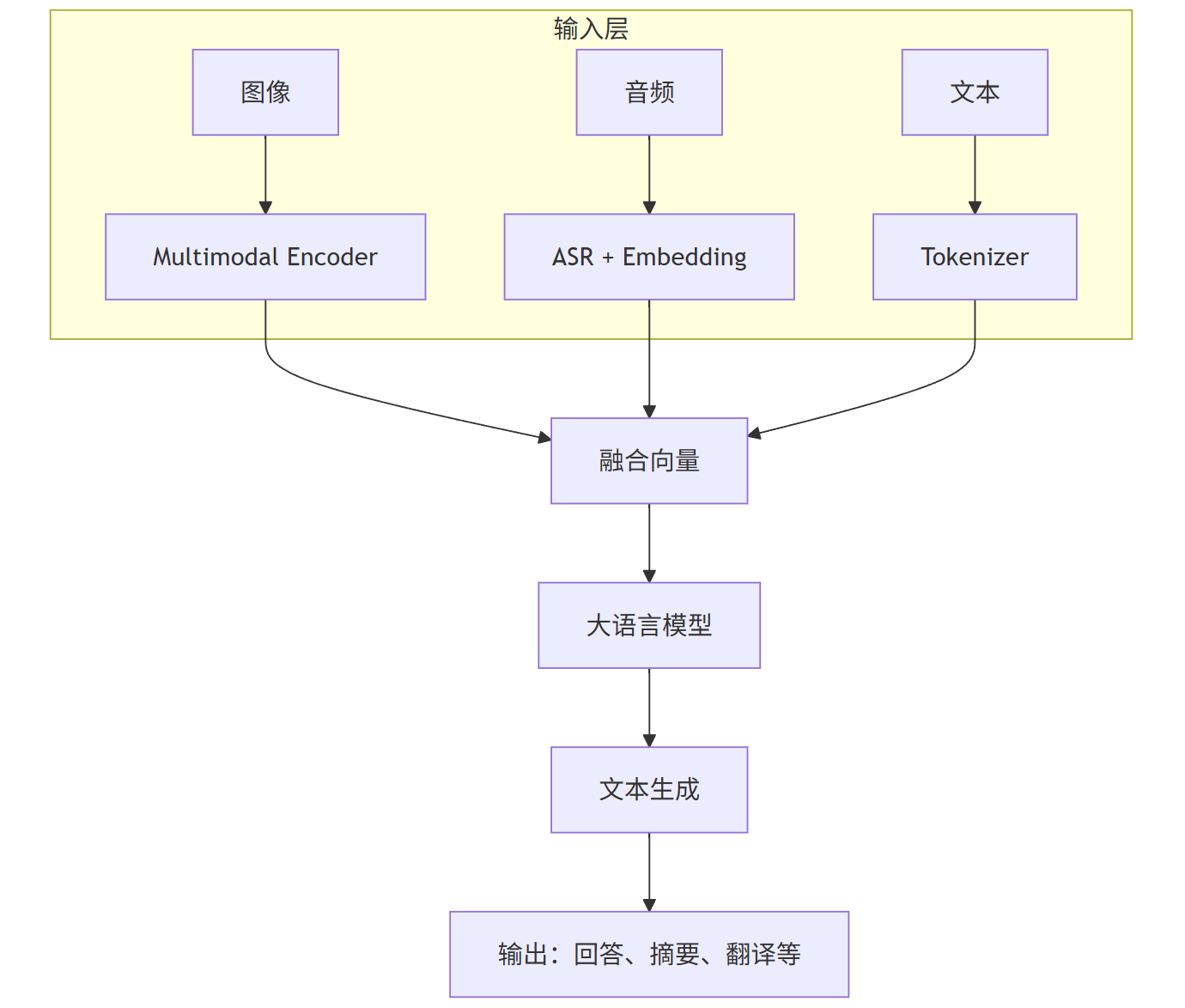
3.4 多模态系统架构图
graph TB
subgraph 输入层
A[图像] --> D[Multimodal Encoder]
B[音频] --> E[ASR + Embedding]
C[文本] --> F[Tokenizer]
end
D --> G[融合向量]
E --> G
F --> G
G --> H[大语言模型]
H --> I[文本生成]
I --> J[输出:回答、摘要、翻译等]
四、企业级大模型解决方案:可扩展、安全、可控的系统架构
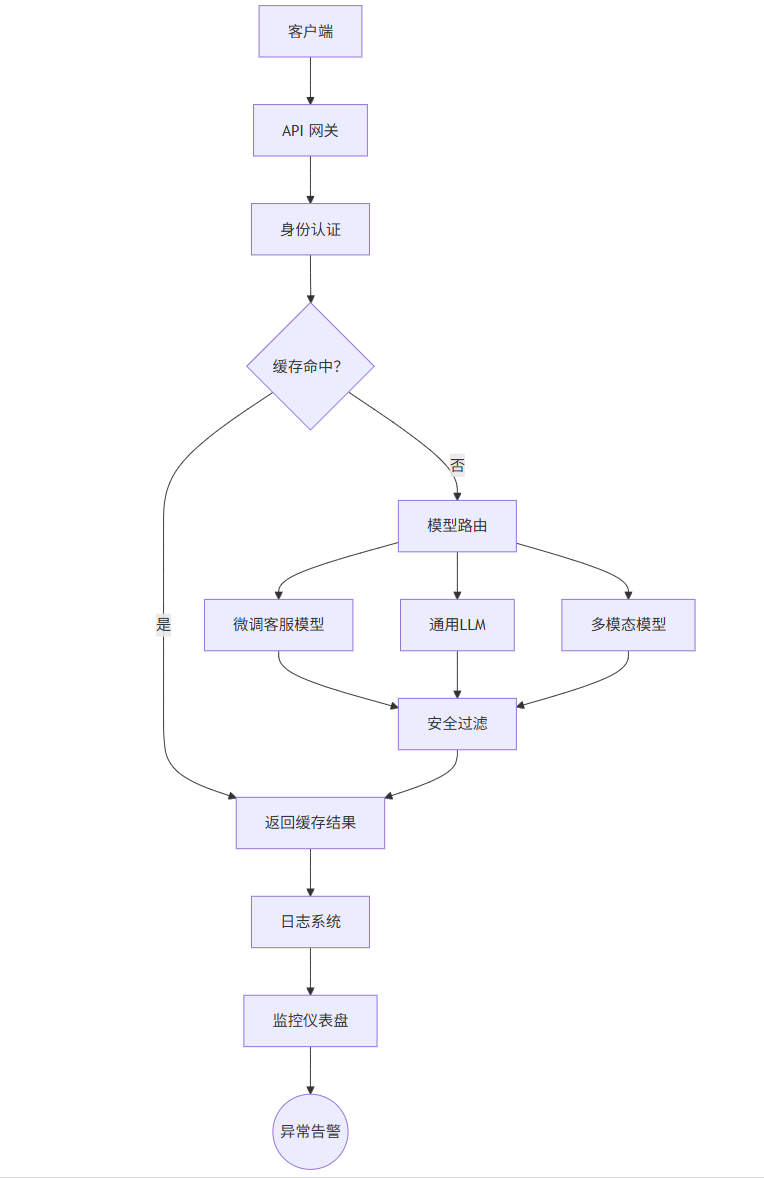
将大模型集成到企业系统中,需考虑性能、安全、监控、成本控制等非功能性需求。以下是典型的企业级架构设计。
4.1 企业级架构核心组件
|
模型网关(Model Gateway) |
统一API入口,负载均衡、鉴权 |
|
缓存层(Cache Layer) |
缓存高频请求,降低延迟与成本 |
|
监控系统(Monitoring) |
日志、延迟、错误率、Token消耗 |
|
安全过滤(Safety Filter) |
内容审核、PII脱敏、防越狱 |
|
模型编排(Orchestration) |
多模型路由、A/B测试、降级策略 |
4.2 企业级架构图(Mermaid)
4.3 缓存策略示例(Redis + LRU)
import redis
import hashlib
import json
r = redis.Redis(host='localhost', port=6379, db=0)
def get_cache_key(prompt, model_name):
key_str = f"{model_name}:{prompt}"
return hashlib.md5(key_str.encode()).hexdigest()
def cached_inference(prompt, model, model_name, ttl=3600):
cache_key = get_cache_key(prompt, model_name)
cached = r.get(cache_key)
if cached:
return json.loads(cached)
# 调用模型
result = model.generate(prompt)
# 存入缓存
r.setex(cache_key, ttl, json.dumps(result))
return result
缓存可降低30%-60%的推理成本,尤其适用于FAQ、固定模板类请求。
4.4 安全过滤模块(Prompt与输出审查)
import re
def is_sensitive_content(text):
patterns = [
r"password|token|api_key",
r"\d{3}-\d{2}-\d{4}", # SSN
r"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b", # Email
]
for pattern in patterns:
if re.search(pattern, text, re.IGNORECASE):
return True
return False
def safe_generate(prompt, model):
if is_sensitive_content(prompt):
return {"error": "输入包含敏感信息,已拦截"}
response = model.generate(prompt)
if is_sensitive_content(response):
return {"error": "输出包含敏感信息,已过滤"}
return {"response": response}
五、性能与成本优化策略
大模型推理成本高,需通过多种技术手段优化。
5.1 推理优化技术对比
|
模型量化(INT8/FP16) |
30% |
40% |
低 |
|
KV Cache 优化 |
50% |
- |
中 |
|
批处理(Batching) |
60% |
50% |
高 |
|
模型蒸馏 |
40% |
60% |
高 |
5.2 使用vLLM进行高性能推理
vLLM 是一个高效的LLM推理引擎,支持PagedAttention,显著提升吞吐量。
from vllm import LLM, SamplingParams
# 初始化LLM
llm = LLM(model="meta-llama/Llama-3-8B", tensor_parallel_size=2)
# 设置采样参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=200)
# 批量推理
prompts = [
"请写一封辞职信,语气正式。",
"解释量子计算的基本原理。",
"推荐三本适合初学者的Python书籍。"
]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(output.outputs[0].text)
在A100上,vLLM可实现每秒处理数百个请求,吞吐量是Hugging Face的3-5倍。
六、落地案例:智能客服系统
6.1 业务需求
某银行希望构建智能客服系统,支持:
- 自动回答常见问题(余额查询、转账流程)
- 处理用户上传的账单截图(多模态)
- 识别用户情绪并转接人工
- 符合金融数据安全规范
6.2 技术实现
graph LR
User[用户提问] --> TextQ{纯文本?}
TextQ -- 是 --> QA[微调客服模型回答]
TextQ -- 否 --> OCR[图像OCR提取文字]
OCR --> QA
QA --> Sentiment[情感分析模型]
Sentiment --> Alert{情绪负面?}
Alert -- 是 --> Transfer[转接人工]
Alert -- 否 --> Response[返回答案]
Response --> Cache[写入缓存]

6.3 Prompt 示例:账单查询
你是一个银行客服助手,请根据用户提供的账单信息回答问题。
账单信息:
- 交易时间:2024-05-15
- 金额:¥1,299.00
- 商户:Apple Store
- 类型:扣款
用户问题:这笔Apple Store的扣款是什么?
请用中文回答,语气友好。
输出:
您好,这笔¥1,299.00的扣款是您于2024年5月15日在Apple Store的消费记录,可能是购买应用、iCloud服务或设备。如有疑问,可登录App Store查看明细。
七、总结与未来展望
大模型落地是一个系统工程,需综合运用微调、提示词工程、多模态集成、企业级架构设计等技术。关键成功因素包括:
- 数据质量:高质量标注数据是微调的基础
- Prompt设计:低成本提升模型表现
- 系统架构:保障稳定性、安全性与可扩展性
- 成本控制:通过缓存、量化、批处理优化ROI
未来趋势:
- 小型化模型:如Phi-3、Gemma,适合边缘部署
- Agent系统:大模型自主调用工具、搜索、执行任务
- 持续学习:模型在线更新,适应新知识
大模型不仅是技术突破,更是企业智能化转型的核心引擎。通过科学的方法论与工程实践,任何组织都能构建属于自己的“AI大脑”。
附录:常用工具与框架
|
微调 |
Hugging Face Transformers, PEFT, DeepSpeed |
|
推理 |
vLLM, TensorRT-LLM, TGI |
|
多模态 |
LLaVA, BLIP-2, Whisper |
|
部署 |
FastAPI, Kubernetes, Prometheus |
|
安全 |
Guardrails, Rebuff, Custom Filters |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)