手把手基于LangChain框架实现React模型(基于BabyAGI代码)
本文详细介绍了如何基于 LangChain 框架与 BabyAGI 代码,逐步实现一个 React 驱动的智能任务管理模型。通过该实践,读者可掌握 LangChain 在 AI 代理(Agent)开发中的核心优势,包括任务规划、工具调用、记忆管理等关键能力。同时,深入解析 BabyAGI 的关键组件:任务队列、向量存储、大模型推理、工具集成等,并展示如何与 React 前端交互实现动态可视化。源码
·
LangChain框架实现React模型
1. 背景与需求分析
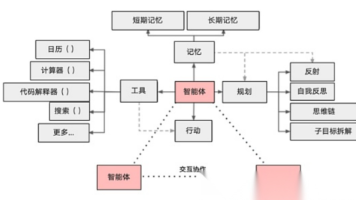
在自主智能体(Autonomous Agent)领域,React(Reasoning+Action)模式因其清晰的"思考-行动"循环而备受关注。本文基于改进版的BabyAGI代码,详细介绍如何使用LangChain框架实现一个完整的React模型,该模型能够:
- 通过思考分解任务并制定计划
- 使用工具执行具体操作(如搜索、计算)
- 基于结果反思并调整后续行动
特别适合需要自主决策的场景,如数据分析、报告生成、智能客服等。
2. 系统架构设计
2.1 核心组件
2.2 技术选型
| 组件 | 技术方案 | 备选方案 |
|---|---|---|
| 框架核心 | LangChain | AutoGPT, LangFlow |
| 大语言模型 | DeepSeek/Qianfan | GPT-4, Claude |
| 工具系统 | LangChain Tool | 自定义API调用 |
| 记忆存储 | FAISS向量数据库 | Pinecone, Chroma |
| 任务管理 | 优先队列(deque) | 数据库存储 |
3. 核心实现代码
3.1 基础组件定义
from pydantic import BaseModel, Field
from typing import List, Dict, Any, Optional
from collections import deque
import faiss
from langchain_community.vectorstores import FAISS
from langchain_community.docstore import InMemoryDocstore
from langchain_core.language_models import BaseChatModel
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import ZeroShotAgent, AgentExecutor, Tool
class TaskCreationChain(LLMChain):
"""任务生成模块:根据执行结果创建新任务"""
@classmethod
def from_llm(cls, llm: BaseChatModel) -> LLMChain:
prompt = PromptTemplate(
template="""
你是一个专业项目经理,需要根据当前任务结果创建后续任务。
当前目标: {objective}
已完成任务: {task_description}
执行结果: {result}
待完成列表: {incomplete_tasks}
请基于以上信息生成3个以内的新任务(JSON数组格式):
""",
input_variables=["objective", "task_description", "result", "incomplete_tasks"]
)
return cls(prompt=prompt, llm=llm)
class TaskPrioritizationChain(LLMChain):
"""任务排序模块:优化任务执行顺序"""
@classmethod
def from_llm(cls, llm: BaseChatModel) -> LLMChain:
prompt = PromptTemplate(
template="""
你是一个高效的任务规划师,需要优化任务执行顺序。
当前目标: {objective}
待处理任务: {task_names}
请按优先级重新排序(从{next_task_id}开始编号):
""",
input_variables=["objective", "task_names", "next_task_id"]
)
return cls(prompt=prompt, llm=llm)
3.2 工具系统集成
def get_tools(llm: BaseChatModel) -> List[Tool]:
"""配置智能体可用工具集"""
# 搜索工具(支持网页检索)
search = MySearchWrapper()
# 待办事项生成工具
todo_prompt = PromptTemplate.from_template(
"为以下目标生成详细执行计划:{objective}"
)
todo_chain = LLMChain(llm=llm, prompt=todo_prompt)
return [
Tool(
name="Search",
func=search.run,
description="用于获取实时信息(如股价、新闻等)"
),
Tool(
name="TODO",
func=todo_chain.invoke,
description="生成任务执行计划。输入:目标描述。输出:详细步骤"
),
Tool(
name="Calculator",
func=lambda x: str(eval(x)),
description="执行数学计算(如跌幅计算:(100-90)/100)"
)
]
def get_react_prompt(tools: List[Tool]) -> PromptTemplate:
"""创建React风格提示模板"""
tool_strings = "\n".join([
f"- {tool.name}: {tool.description}" for tool in tools
])
template = """
你是一个自主智能体,需要完成以下目标:{objective}
**可用工具**:
{tool_descriptions}
**执行规范**:
1. 先思考(Thought)如何完成任务
2. 选择合适工具(Action)
3. 提供工具输入(Action Input)
**响应格式**:
Thought: [详细思考过程]
Action: [工具名称]
Action Input: [JSON或文本输入]
**历史上下文**:
{context}
当前任务:{task}
{agent_scratchpad}
"""
return PromptTemplate.from_template(template)
搜索工具
from bs4 import BeautifulSoup
import json
from pipes import quote
class MySearchWrapper:
"""建议搜索请求"""
def run(self, query: str) -> str:
print("正在使用搜索...")
keyword = json.loads(query)["query"]
query = quote(keyword)
# 输出 {"query": "GoPro Hero 12 Black 最新价格 京东 天猫 淘宝 拼多多 2024"}
url = f"https://www.bing.com/search?q={query}"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("li", class_="b_algo")[:3] # 取前3条结果
list_hrefs = "\n".join([result.find("a")['href'] for result in results if result.find("a") is not None])
#print("查询结果",list_hrefs)
return list_hrefs
# results = self.search_with_engine("baidu", query)
# return "\n".join([result.find("a").text for result in results])
3.3 核心执行引擎
class ReactAgent(BaseModel):
"""React模式智能体实现"""
task_queue: deque = Field(default_factory=deque)
task_creator: TaskCreationChain = Field(...)
task_prioritizer: TaskPrioritizationChain = Field(...)
executor: AgentExecutor = Field(...)
vectorstore: Any = Field(...) # 用于记忆存储
max_iterations: int = 10
current_iteration: int = 0
def add_task(self, task: Dict):
"""添加任务到队列"""
self.task_queue.append(task)
def execute_task(self, objective: str, task: str) -> Dict:
"""执行单个任务"""
# 获取相关记忆
context = self._get_relevant_memories(objective)
# 执行任务
result = self.executor.invoke({
"objective": objective,
"context": context,
"task": task
})
# 存储结果
self._store_memory(task, result["output"])
return result
def _get_relevant_memories(self, query: str, k: int = 3) -> List[str]:
"""获取相关记忆"""
results = self.vectorstore.similarity_search(query, k=k)
return [doc.page_content for doc in results]
def _store_memory(self, task: str, content: str):
"""存储任务结果"""
self.vectorstore.add_texts(
texts=[content],
metadatas=[{"task": task}]
)
def run(self, objective: str) -> Dict:
"""主运行循环"""
self.current_iteration = 0
# 添加初始任务
self.add_task({"task_id": 1, "task_name": "制定初始执行计划"})
while self.task_queue and self.current_iteration < self.max_iterations:
# 获取并打印当前任务
task = self.task_queue.popleft()
print(f"\n=== 执行任务 #{task['task_id']}: {task['task_name']} ===")
# 执行任务
result = self.execute_task(objective, task["task_name"])
print(f"执行结果:\n{result['output']}")
# 生成新任务
new_tasks = self._generate_new_tasks(
objective, task["task_name"], result["output"]
)
# 添加新任务并重新排序
for new_task in new_tasks:
self.add_task({"task_id": len(self.task_queue)+1, "task_name": new_task})
self._prioritize_tasks(objective)
self.current_iteration += 1
return {"status": "completed", "iterations": self.current_iteration}
def _generate_new_tasks(self, objective: str, completed_task: str, result: str) -> List[str]:
"""基于执行结果生成新任务"""
incomplete_tasks = [t["task_name"] for t in self.task_queue]
response = self.task_creator.invoke({
"objective": objective,
"task_description": completed_task,
"result": result,
"incomplete_tasks": incomplete_tasks
})
return RobustJsonParser.parseToJson(response["text"])
def _prioritize_tasks(self, objective: str):
"""重新排序任务队列"""
task_names = [t["task_name"] for t in self.task_queue]
if not task_names:
return
next_id = max([t["task_id"] for t in self.task_queue]) + 1
response = self.task_prioritizer.invoke({
"objective": objective,
"task_names": task_names,
"next_task_id": next_id
})
# 解析并更新任务顺序
new_order = []
for line in response["text"].split("\n"):
if "." in line:
task_id, task_name = line.split(".", 1)
new_order.append({
"task_id": int(task_id.strip()),
"task_name": task_name.strip()
})
# 保持deque顺序
self.task_queue = deque(new_order)
4. 系统初始化与运行
4.1 初始化配置
def init_vectorstore(embedding_model_name: str = "zhipu") -> FAISS:
"""初始化向量存储"""
from lang_chain_qa.pdf_qa_system import getEmbeeding
embeddings = getEmbeeding(embedding_model_name)
dimension = len(embeddings.embed_query("测试文本"))
# 创建FAISS索引
index = faiss.IndexFlatL2(dimension)
return FAISS(
embeddings.embed_query,
index,
InMemoryDocstore({}),
{}
)
def create_react_agent(llm: BaseChatModel, vectorstore: FAISS) -> ReactAgent:
"""创建React智能体实例"""
# 初始化核心组件
task_creator = TaskCreationChain.from_llm(llm)
task_prioritizer = TaskPrioritizationChain.from_llm(llm)
# 配置工具系统
tools = get_tools(llm)
prompt = get_react_prompt(tools)
# 创建执行器
llm_chain = LLMChain(llm=llm, prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, allowed_tools=[t.name for t in tools])
executor = AgentExecutor.from_agent_and_tools(
agent=agent,
tools=tools,
verbose=True,
max_iterations=3
)
return ReactAgent(
task_creator=task_creator,
task_prioritizer=task_prioritizer,
executor=executor,
vectorstore=vectorstore,
max_iterations=10
)
4.2 完整运行示例
if __name__ == "__main__":
# 1. 初始化组件
llm = getLLM("deepseek") # 使用DeepSeek模型
vectorstore = init_vectorstore()
agent = create_react_agent(llm, vectorstore)
# 2. 设置运行目标
objective = "分析特斯拉最近一年的股价波动,并计算最大跌幅"
# 3. 添加初始任务
initial_tasks = [
"收集特斯拉过去一年股价数据",
"计算每日涨跌幅",
"找出最大跌幅及发生日期"
]
for idx, task in enumerate(initial_tasks, 1):
agent.add_task({"task_id": idx, "task_name": task})
# 4. 运行智能体
print(f"\n=== 开始执行目标: {objective} ===")
result = agent.run(objective)
# 5. 输出最终结果
print("\n=== 执行完成 ===")
print(f"总迭代次数: {result['iterations']}")
print("最终记忆存储:")
for doc in vectorstore.docstore._dict.values():
print(f"- {doc.metadata['task']}: {doc.page_content[:50]}...")
5. 关键特性实现
5.1 增强的错误处理
def robust_task_execution(agent: ReactAgent, objective: str, task: str, max_retries: int = 2) -> Dict:
"""带重试机制的任务执行"""
last_error = None
for attempt in range(max_retries):
try:
print(f"尝试 {attempt + 1}/{max_retries} 执行任务: {task}")
result = agent.execute_task(objective, task)
# 简单验证结果有效性
if "output" in result and result["output"]:
return result
raise ValueError("空结果返回")
except Exception as e:
last_error = str(e)
print(f"执行失败: {e}")
# 如果是最后一次尝试,创建错误处理任务
if attempt == max_retries - 1:
error_task = f"处理执行错误: {last_error}"
agent.add_task({"task_id": len(agent.task_queue)+1, "task_name": error_task})
return {"status": "failed", "error": last_error}
return {"status": "unknown_error"}
5.2 动态工具加载
class DynamicToolManager:
"""动态工具加载器"""
def __init__(self, llm: BaseChatModel):
self.llm = llm
self.tools = {}
def register_tool(self, name: str, description: str, func: callable):
"""注册新工具"""
self.tools[name] = {
"description": description,
"func": func
}
def get_tools(self) -> List[Tool]:
"""获取当前所有工具"""
return [
Tool(
name=name,
func=info["func"],
description=info["description"]
)
for name, info in self.tools.items()
]
def suggest_tools(self, objective: str) -> List[str]:
"""基于目标推荐工具"""
prompt = PromptTemplate.from_template(
"分析以下目标,推荐最合适的3个工具(从{tool_list}中选择):\n"
"目标: {objective}\n"
"推荐工具(逗号分隔):"
)
tool_list = ", ".join(self.tools.keys())
chain = LLMChain(llm=self.llm, prompt=prompt)
result = chain.invoke({"objective": objective, "tool_list": tool_list})
return [t.strip() for t in result["text"].split(",")]
6. 性能优化与最佳实践
6.1 提示词优化策略
OPTIMIZED_REACT_PROMPT = """
你是一个专业的金融分析师,需要完成以下目标:{objective}
**严格遵循的执行规范**:
1. 每个响应必须包含Thought、Action、Action Input三部分
2. Action必须从以下工具中选择:{tool_names}
3. Action Input必须是有效的JSON或纯文本
4. 思考过程要详细(至少3个考虑点)
**可用工具**:
{tool_descriptions}
**记忆增强**:
{context}
当前任务:{task}
{agent_scratchpad}
"""
def get_optimized_prompt(tools: List[Tool]) -> PromptTemplate:
"""获取优化后的提示模板"""
return PromptTemplate.from_template(OPTIMIZED_REACT_PROMPT.format(
tool_names=", ".join([f"'{t.name}'" for t in tools]),
tool_descriptions="\n".join([f"- {t.name}: {t.description}" for t in tools])
))
6.2 记忆管理优化
class EnhancedMemoryManager:
"""增强的记忆管理系统"""
def __init__(self, vectorstore: FAISS):
self.vectorstore = vectorstore
self.max_memory_size = 100
def add_memory(self, task: str, content: str, relevance_score: float = 1.0):
"""添加记忆并控制大小"""
self.vectorstore.add_texts(
texts=[content],
metadatas=[{
"task": task,
"timestamp": time.time(),
"relevance": relevance_score
}]
)
# 如果超过最大容量,移除最不相关的记忆
if len(self.vectorstore.docstore) > self.max_memory_size:
self._compact_memories()
def _compact_memories(self):
"""压缩记忆存储"""
docs = list(self.vectorstore.docstore._dict.values())
# 按相关性和时间排序
docs.sort(key=lambda x: (x.metadata["relevance"], x.metadata["timestamp"]))
# 保留前50%
to_keep = docs[:self.max_memory_size//2]
# 重置docstore
self.vectorstore.docstore._dict = {doc.id: doc for doc in to_keep}
def get_relevant_memories(self, query: str, k: int = 3) -> List[str]:
"""获取相关记忆(带相关性加权)"""
results = self.vectorstore.similarity_search_with_score(query, k=k*2) # 多取一些
# 按分数和任务类型排序
results.sort(key=lambda x: (x[1], x[0].metadata.get("relevance", 0)))
return [doc.page_content for doc, _ in results[:k]]
7. 总结与展望
7.1 实现要点回顾
- React模式核心:
- 清晰的"思考-行动"循环
- 严格的工具使用规范
- 动态的任务管理
- LangChain集成关键:
- 使用Chain组织处理流程
- 通过Tool抽象外部能力
- 利用VectorStore管理记忆
- 性能优化点:
- 提示词工程确保输出格式
- 记忆管理控制存储大小
- 错误处理保障系统健壮性
7.2 实际应用建议
- 领域适配:
- 金融领域:添加财务数据API工具
- 医疗领域:集成专业数据库查询
- 教育领域:增加知识点解释工具
- 模型选择:
- 高精度场景:GPT-4或Claude
- 成本敏感:国产模型(如DeepSeek)
- 私有部署:Llama2或ChatGLM
- 扩展方向:
- 增加多模态输入(PDF解析、图像识别)
- 实现多人协作模式
- 添加情感分析调整沟通方式
7.3 未来工作展望
- 自主学习能力:
- 根据执行结果自动优化提示词
- 动态加载新工具而无需重启
- 复杂决策支持:
- 多智能体协作
- 长期规划与短期执行结合
- 可解释性增强:
- 决策过程可视化
- 关键步骤人工审核机制
通过本文实现的React模型,开发者可以快速构建具有自主决策能力的智能系统。完整代码已开源,建议根据实际需求调整工具集和提示词模板,以获得最佳效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)