【python and AI】爬虫的使用 And 人脸识别系统
本文内容只要介绍爬虫的使用和下载、python的类和对象、函数等相关知识,人脸识别系统的基础知识。
一、前言
🔍在现实生活中我们只有不断的做某件事才可能作成某件事,例如:不断学习才有可能考上985或者211,或者说只有不断的赚钱才能买得上小米SUV7;在计算机方面我们使用条件循环语言来描述这一情况,所以我们说计算机语言是用来在计算机上描述世界的。
二、条件循环语句
a = 9
if a > 0:
print(a)
else:
print(0)📖解析:如果 a > 0,就执行语句:print(a),否则执行语句:print(0),我们要注意一下的书写格式,当然读过大学特别是学过计算机语言C++的都知道python的条件循环语句和C语言是有点区别的。
a = 10
if a > 0:
print(0)
elif a > 9:
print(9)
elif a < -1:
print(-1)这是个连续判断语句,只要符合其中一个条件就会执行对应的语句,如果都不符合可以加上一个语句else:,注意如果有两个及以上的条件符合就会执行最近的语句(就近原则),因为编译器是从上往下执行的。
while循环:
a = 1
while a <= 10:
print(a)
a += 1
print(a)1
2
3
4
5
6
7
8
9
10
11📖解析:只要满足条件 a<=10 就可以执行循环语句,当 a=11 时,不满足循环语句的条件所以跳出循环语句。
for循环:
#a=0,只要 a < 3 就可以进入循环语句
for a in range(3):
print(a)
print("...............")
#i = 1,只要 i < 4 就是可以进入循环
for i in range(1,4):
print(i)
print("...............")
#k = 1,只要 k < 10 就可以进入循环,2是步长,就是说每次执行完循环语句之后 k += 2
for k in range(1,10,2):
print(k)0
1
2
...............
1
2
3
...............
1
3
5
7
9📖解析:range是左闭右开的区间。
扩展:
for i in range(1,10):
print(i)
if i == 3:
break#跳出循环,不再执行循环语句
print("///////////////")
for k in range(1,10):
print(k)
if k == 7:
continue#继续执行语句1
2
3
///////////////
1
2
3
4
5
6
7
8
9三、函数
函数具体化为一个西瓜放进榨汁机里面,一定时间之后变成西瓜汁,而这段过程就是函数执行的过程,之后返回一个西瓜汁。
def add(a,b):
return a+b
def month(Month):
if Month == 2:
return 2
elif Month == 3:
return 3
else:
print("没有中")
return 0
ret = add(1,2)
print(ret)
ret2 = month(2)
print(ret2)3
2✍解析:上面的例子大家要注意书写格式。
缩进很重要:函数内的代码必须缩进(通常是4个空格)
函数名不能有空格:用下划线代替空格,如say_hello
先定义,后调用:必须先定义函数,才能调用它
参数可选:有些函数不需要参数
return可选:如果不需要返回值,可以不写return
四、类和对象
✍类相当于是一个房子的设计图纸,而对象就是根据对象实例化出来的房子。那么python的类和对象的语法格式是什么呢?我们来看一下:
格式:
class 类名:
# 类属性
属性名 = 值
# 初始化⽅法(构造⽅法),构造方法只能有一个,self是默认的
def __init__(self, 参数1, 参数2, ...):
self.实例属性1 = 参数1
self.实例属性2 = 参数2
# 实例⽅法
def ⽅法名(self, 参数1, 参数2, ...):
# ⽅法体
return 返回值
# 类⽅法
@classmethod
def 类⽅法名(cls, 参数1, 参数2, ...):
# ⽅法体
return 返回值
# 静态⽅法
@staticmethod
def 静态⽅法名(参数1, 参数2, ...):
# ⽅法体
return 返回值#类
class Student :
def __init__(self,name,age,color):#初始化,构造函数
self.name = name
self.age = age
self.color = color
def secure_class(self):#得到年级
print(self.age,end='')#end=''是取消自动换行
print("年级")
#对象
student1 = Student("张三",8,"黑色")
student1.secure_class()
print(student1.age)
print(student1.color)
print(student1.name)8年级
8
黑色
张三访问对象当中的成员:
1、使用对象的引用+点号来访问对象当中的属性
2、使用对象的引用+点号来访问对象当中的方法(行为)
3、self这个参数是必须要有的,在传参的时候可以不显示进行传递
4、类方法和静态方法我们暂且不涉及,这里不深入讲解
1、构造方法的特点:
名字为__init__:如Baby类的构造方法名是__init__
自动调用:在secure("张三",1,8)时自动执行。
构造函数:不能同时存在多个
2、默认构造方法:
如果类中没有定义任何构造方法,会默认提供一个无参构造方法
五、列表
可以将Python中的列表通俗地理解为⼀排储物柜或⼀条有序的盒⼦序列。每个储物柜(列表元素)可以存放⼀件物品(数据),且所有储物柜的格⼦大小相同(数据类型⼀致),并通过编号 (索引)快速找到对应位置。
list1 = ["abc","def","gh"]
list2 = [1,2,3,4,5,6]
list3 = ["hello",2,3,4]
#列表中存储的数据类型可以不一样
#感觉跟那个C语言的数组差不多
#访问列表元素
print("lise1[0]:",list1[0])#访问下标为0的元素即:"abc"
print("list2[2]:",list2[2])#访问下标为2的元素即:3lise1[0]: abc
list2[2]: 3访问超出范围的话会报错:
print(list1[4])IndexError: list index out of range根据范围来访问列表:
print(list1[1:3])#访问下标1到2的元素,[1:3]左闭右开相当于(1,3]
['def', 'gh']✍注意:可以超出范围内的元素访问,这时候访问的是最多的访问的数据。
print(list1[1:100])#访问下标1到2的元素,[1:100]左闭右开相当于(1,100]
['def', 'gh']用循环来访问:
list1 = ["abc","def","gh"]
list2 = [1,2,3,4,5,6]
list3 = ["hello",2,3,4]
for index in list1:
print(index,end=" ")abc def gh list1 = ["abc","def","gh"]
list2 = [1,2,3,4,5,6]
list3 = ["hello",2,3,4]
for word in range(len(list2)):#len是计算list2列表的元素个数
print(list2[word],end=" ")1 2 3 4 5 6列表的更新:
list1 = ["abc","def","gh"]
list2 = [1,2,3,4,5,6]
list3 = ["hello",2,3,4]
list2.append(10)#尾插
for word in range(len(list2)):#len是计算list2列表的元素个数
print(list2[word],end=" ")1 2 3 4 5 6 10 列表的删除:
list1 = ["abc","def","gh"]
list2 = [1,2,3,4,5,6]
list3 = ["hello",2,3,4]
list2.append(10)#尾插
del list2[2]#删除下标为2的元素
for word in range(len(list2)):#len是计算list2列表的元素个数
print(list2[word],end=" ")1 2 4 5 6 10六、爬虫
爬虫是一种能自动从互联网网页上抓取、提取所需数据(如文字、图片、表格等)的程序或工具,本质是模拟人类浏览网页并收集信息的自动化过程。
✍那么使用爬虫的步骤(示例):
1、首先把爬虫的插件的安装下来;
♐注意:上面是我把Xpath下载到谷歌浏览器上作为个插件使用。具体方法请私信。
2、把插件Xpath固定到工具栏上。
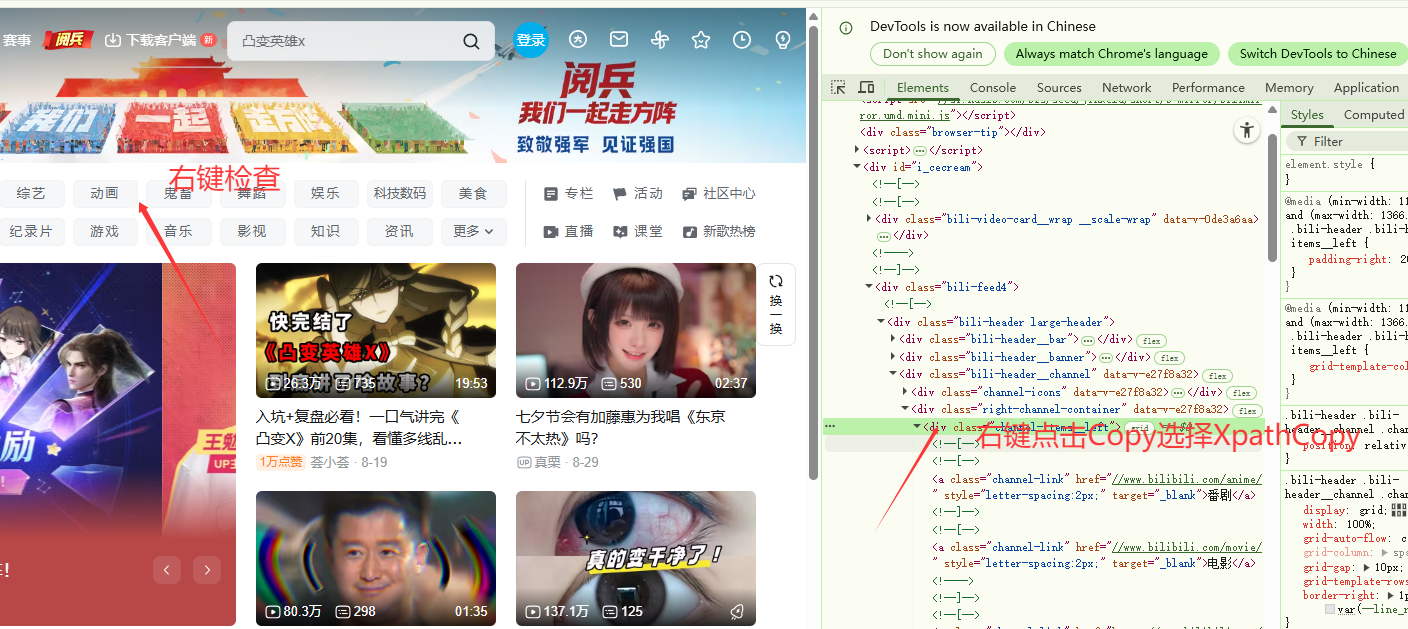
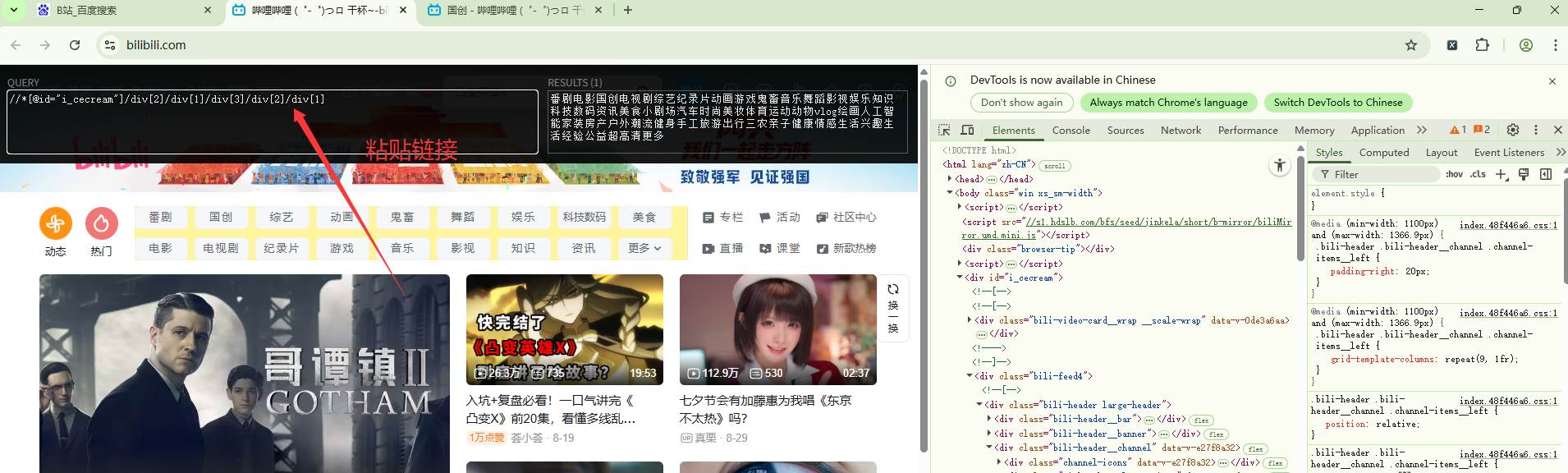
3、爬取B站的⾸⻚的标题和链接


pip install requests beautifulsoup4 lxml这个是在python执行。
4、爬虫业务分析:
1)请求指定网址内容。
2)返回指定网址内容。
3)接受返回指定网址内容后进行解析。
#//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[2]/div[1]/a
import requests
import lxml.html as lh
def main():
url = "https://www.bilibili.com/" # B站主⻚链接
# 使⽤ requests 获取⽹⻚内容,这⾥事实上是模拟正式浏览器,避免被⽹站屏蔽
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# response 中存储的就是 获取到的⽹⻚内容
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
# 使⽤ lxml 解析HTML
doc = lh.fromstring(response.text)
# 使⽤ XPath 解析视频标题
elements = doc.xpath("//*[@id =\"i_cecream\"]/div[2]/div[1]/div[3]/div[2]/div[1]/a")
# 打印视频标题
for element in elements:
# 获取标题 text_content来⾃这个库
title = element.text_content()
# 获取链接
link = element.get('href')
# 如果链接是相对路径,添加域名
if link and link.startswith("//"):
link = "https:" + link
print("标题:", title)
print("链接:", link)
print("-------------------")
if __name__ == "__main__":
main()标题: 番剧
链接: https://www.bilibili.com/anime/
-------------------
标题: 电影
链接: https://www.bilibili.com/movie/
-------------------
标题: 国创
链接: https://www.bilibili.com/guochuang/
-------------------
标题: 电视剧
链接: https://www.bilibili.com/tv/
-------------------
标题: 综艺
链接: https://www.bilibili.com/variety/
-------------------
标题: 纪录片
链接: https://www.bilibili.com/documentary/
-------------------
标题: 动画
链接: https://www.bilibili.com/c/douga/
-------------------
标题: 游戏
链接: https://www.bilibili.com/c/game/
-------------------
标题: 鬼畜
链接: https://www.bilibili.com/c/kichiku/
-------------------
标题: 音乐
链接: https://www.bilibili.com/c/music/
-------------------
标题: 舞蹈
链接: https://www.bilibili.com/c/dance/
-------------------
标题: 影视
链接: https://www.bilibili.com/c/cinephile/
-------------------🍁🍁请各位道友,敬请期待下文,完!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)