一个 “小而美” 的方案,帮助你快速搭建个人 AI 知识库。
当下,RAG 技术已经非常成熟了,市面上的各种 AI 知识库产品也很丰富。在这个 AI 时代的浪潮下,如果你还用传统的笔记软件来管理个人知识,就有点显得了。不过,想要选到一款称心如意的知识库工具,似乎也不是那么简单。首先是数据隐私上的考虑,虽然现在很多在线 AI 平台似乎都支持了知识库上传的能力,但有些 “私密” 的知识我们可能不想上传到 “云端”。另外,虽然有很多大厂直接提供了非常全面的私有化部
当下,RAG 技术已经非常成熟了,市面上的各种 AI 知识库产品也很丰富。
在这个 AI 时代的浪潮下,如果你还用传统的笔记软件来管理个人知识,就有点显得 Out 了。
不过,想要选到一款称心如意的知识库工具,似乎也不是那么简单。
首先是数据隐私上的考虑,虽然现在很多在线 AI 平台似乎都支持了知识库上传的能力,但有些 “私密” 的知识我们可能不想上传到 “云端”。
另外,虽然有很多大厂直接提供了非常全面的私有化部署方案,但是动辄几万的费用让人望而却步。
那就只能从开源工具上下手了,作为个人的知识库管理工具,我希望使用一款 “小而美” 的产品,对于 RAGFlow、Dify 这样的企业级产品显然不太适合个人部署。
另外,现在大部分的知识库产品似乎只注重于 AI 检索 的体验,而忽略了知识本身的管理,很多情况下,上传上去的文档可能只能够在 RAG 检索中发挥作用,想回去翻一翻原文就有点困难了。
所以,虽然我一直在陆陆续使用一些知识库工具,但作为个人知识库来讲,我一直没找到一款称心如意的产品。
直到前段时间,我无意间刷到了这个 PandaWiki 品三国 的网站:
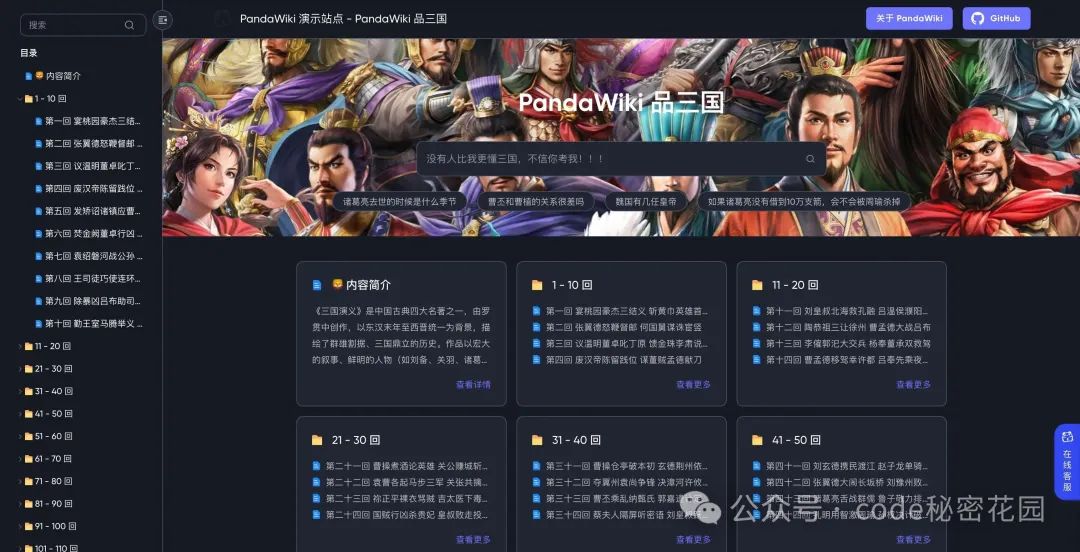
打开网站的第一眼,我就感觉到,这就是我期望的那种个人知识库的效果!
首先网站整体还是保留了传统文档知识库的风格,我还可以直接点击某篇文章,可以直接阅读文档的原文:
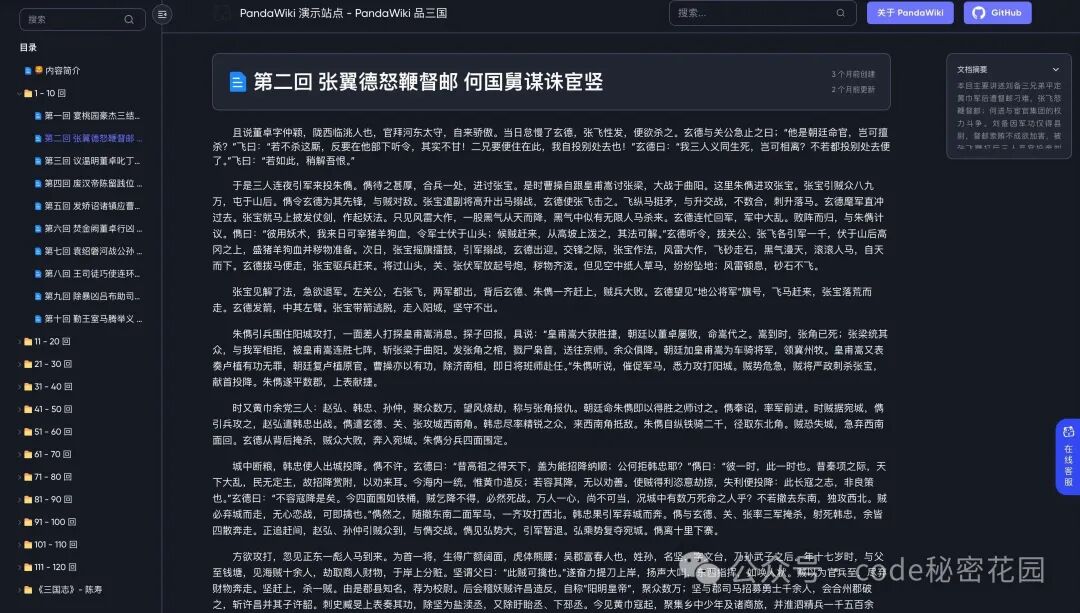
然后我直接尝试对文档中的知识发起一个问答,回答效果还是很不错的:
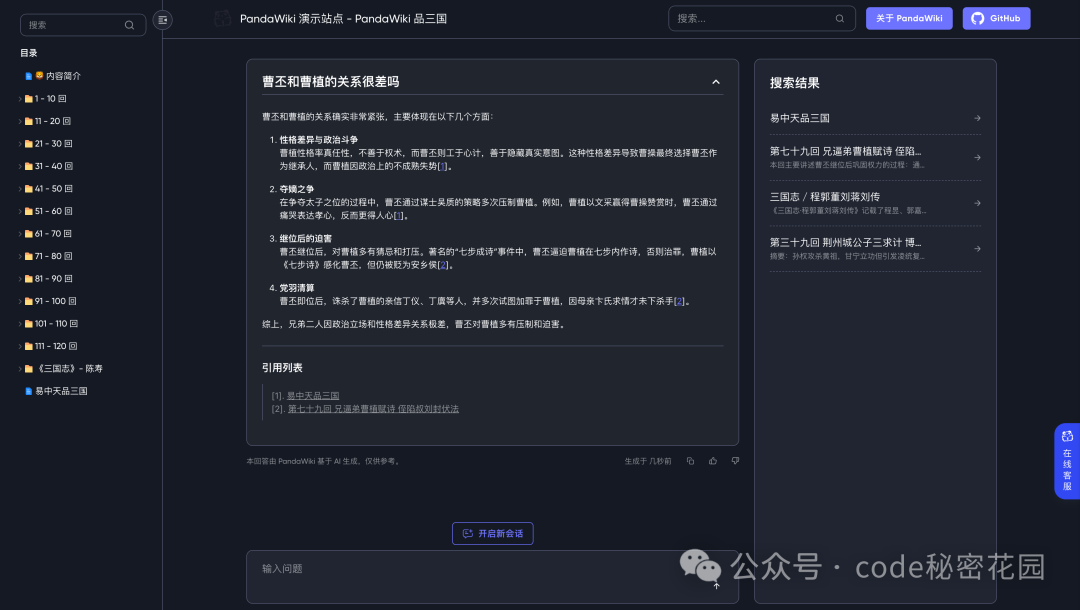
令我惊喜的是,这还是一款开源的产品:

于是我立马想自己也搭建一个,把最近整理的一些 AI 知识也导入进入,做一个个人 AI 知识库。
说干就干,下面我就带大家一起来从零搭建一下。
PandaWiki 的文档站也是用自己来搭建的,写的非常详细了:
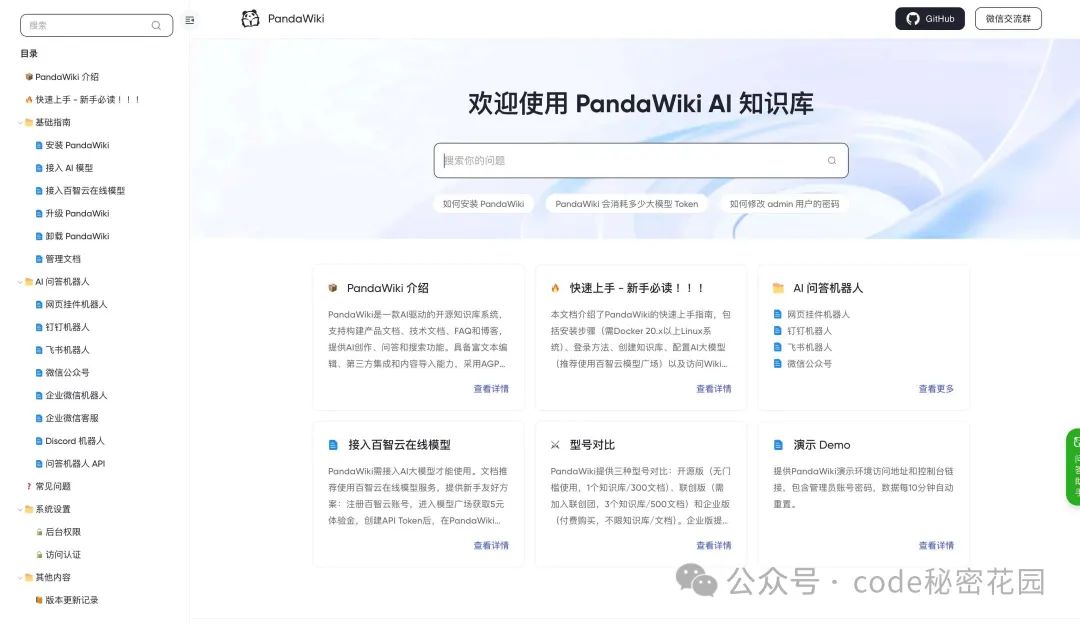
拿我们就直接问问怎么部署?
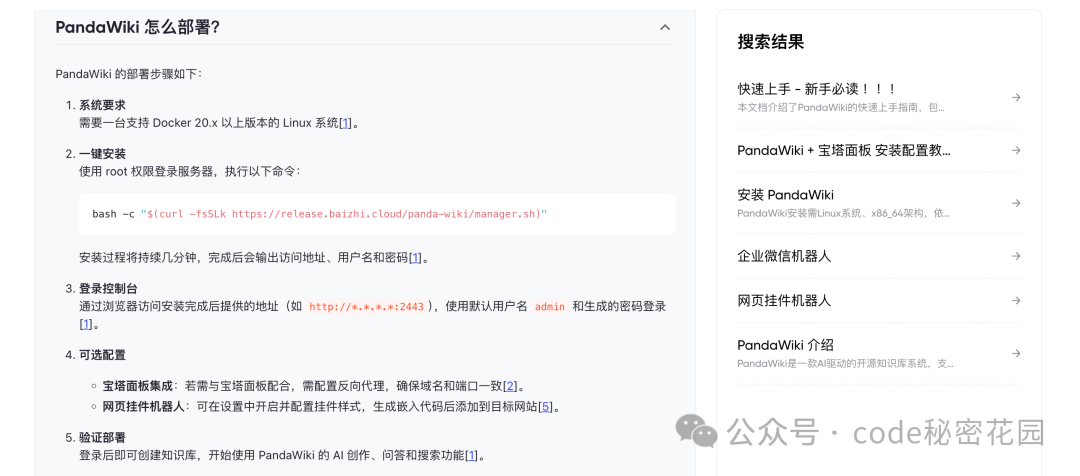
可以看到,官方提供的部署方式非常简单,只需要拥有一台 Linux 机器(没有服务器的话直接在自己的电脑上开个虚拟机就行),就可以用一个命令一键完成部署:
bash -c "$(curl -fsSLk https://release.baizhi.cloud/panda-wiki/manager.sh)"
我们直接输入这段命令:
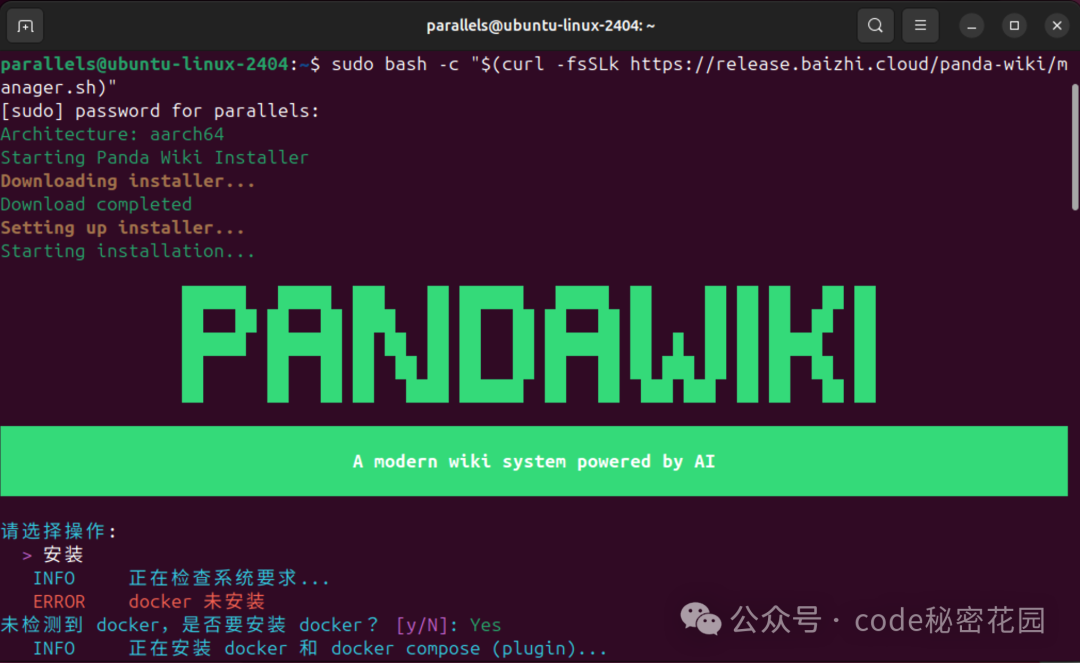
可以发现,其实脚本里面就是自动帮我们启动 Docker 镜像,它还能自动帮我们识别本地是否有 Docker 环境,如果没有会引导我们安装:
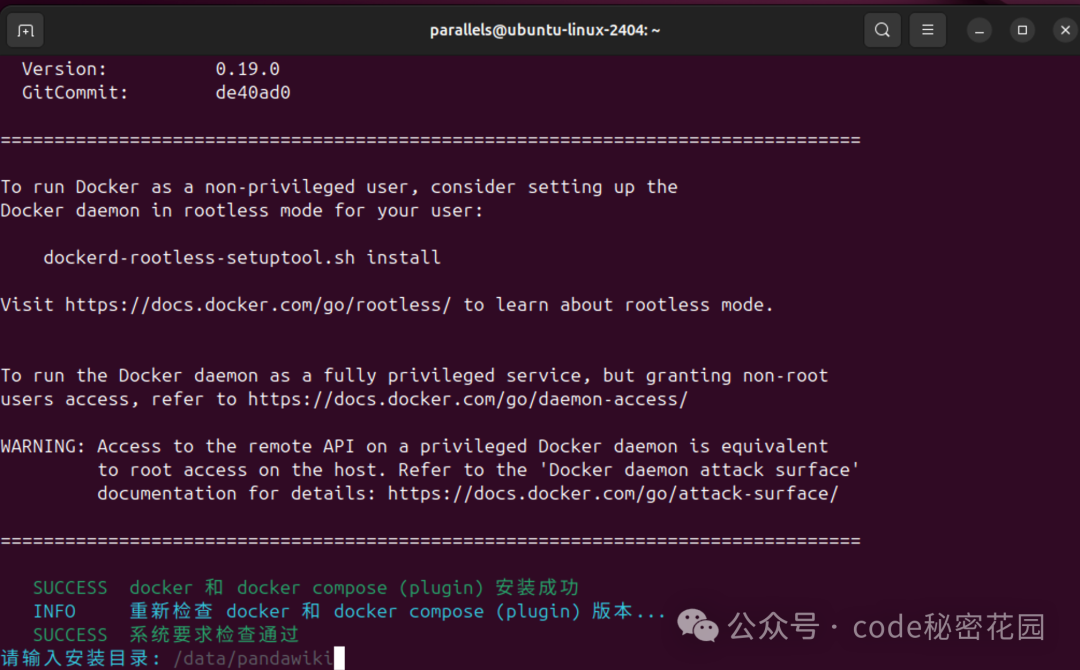
Docker 安装完成后,开始拉取 PandaWiki 的镜像:
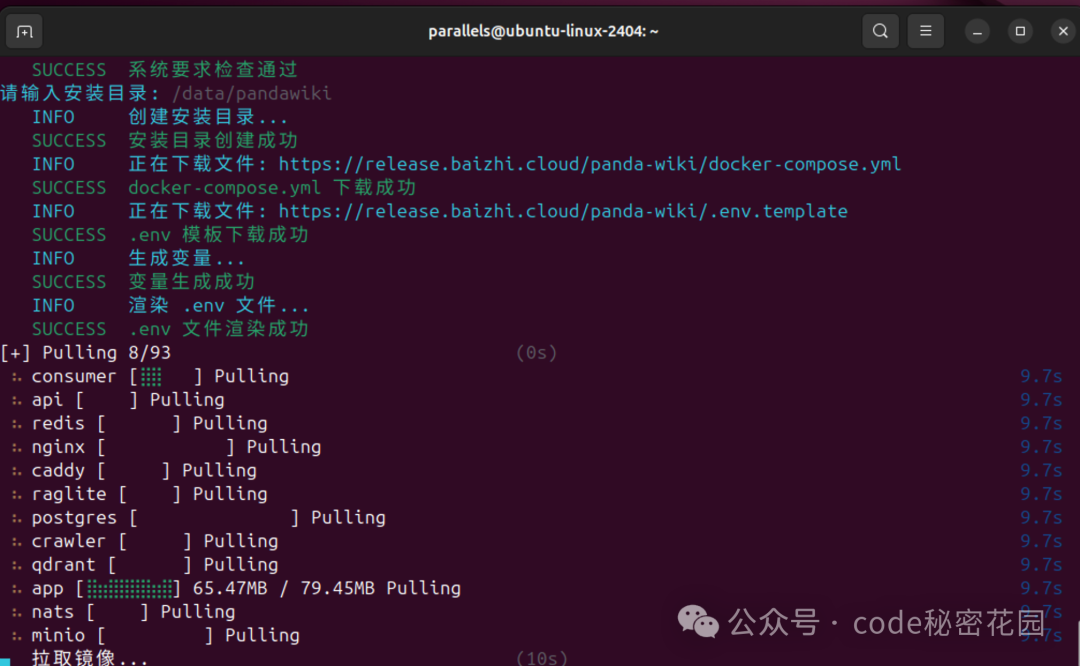
稍等了几分钟,直接就安装完成了,它直接给出了一个内网可访问的地址以及外网可访问的地址,然后给生成了一个管理员登录的账号密码:
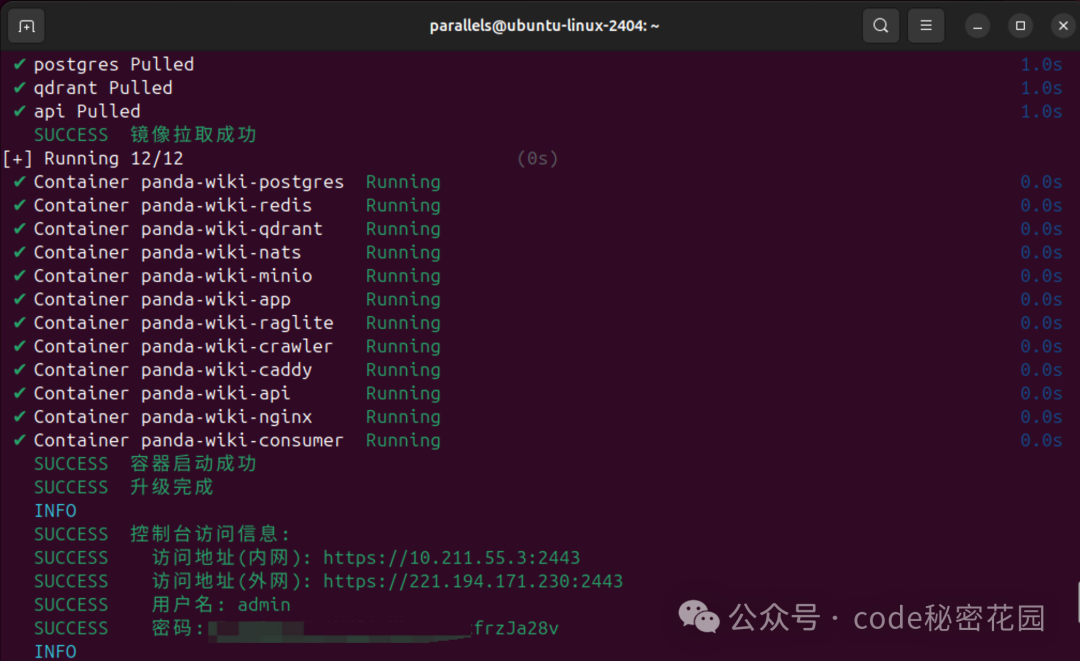
我们复制一下这个网址,支持到本地浏览器打开并完成登录。
登录成功后,首先系统提示我们配置模型:
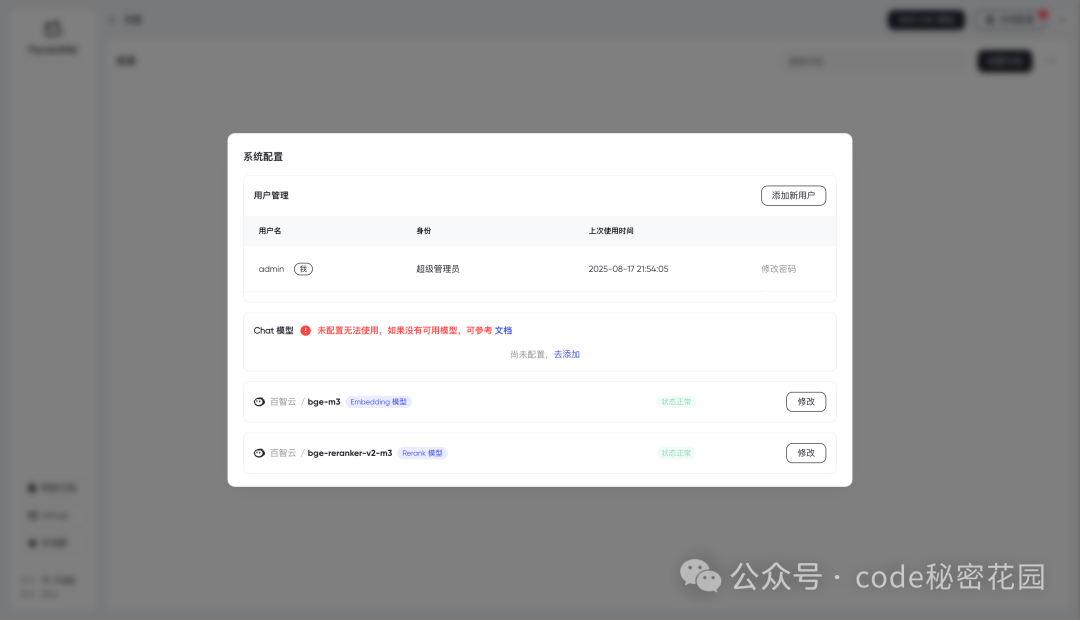
相信大家对 RAG 技术已经比较熟悉了,这里我们需要配置三个模型:
-
嵌入模型(Embedding Model):通过对文本的语义理解,将文字信息映射到向量空间中,使语义相似的文本在向量空间中的距离更近。例如,“如何预防感冒?” 和 “感冒的预防方法有哪些?” 会被转化为距离较近的向量,从而为后续的检索匹配提供基础。
-
重排模型(Reranker Model):基于文本与问题的语义相关性、信息完整性、准确性等深层特征,重新调整候选文本的顺序,过滤噪音信息(如无关内容、低质量回答),确保更相关的文本被优先送入生成模型。例如,在检索 “机器学习算法” 时,重排模型会将详细讲解算法原理的文档排在泛泛而谈的内容之前。
-
文本模型(生成模型,如 LLM):基于检索到的相关信息和用户问题,生成最终的回答。
RAG 通过嵌入模型将用户问题与知识库文本转化为语义向量并检索相关信息,经重排模型优化排序后,由文本模型结合检索结果生成准确且有依据的回答,实现 “检索增强生成” 的闭环。
这里我们发现,默认的嵌入模型和重排模型已经帮我们配置好了,这里应该是 “百智云” 给这个产品提供了赞助,默认提供了一些免费额度。不过嵌入模型和重排模型其实在整个 RAG 检索的过程中 Token 消耗量是非常小的,所以这里我们用默认的免费额度就可以用非常久了。
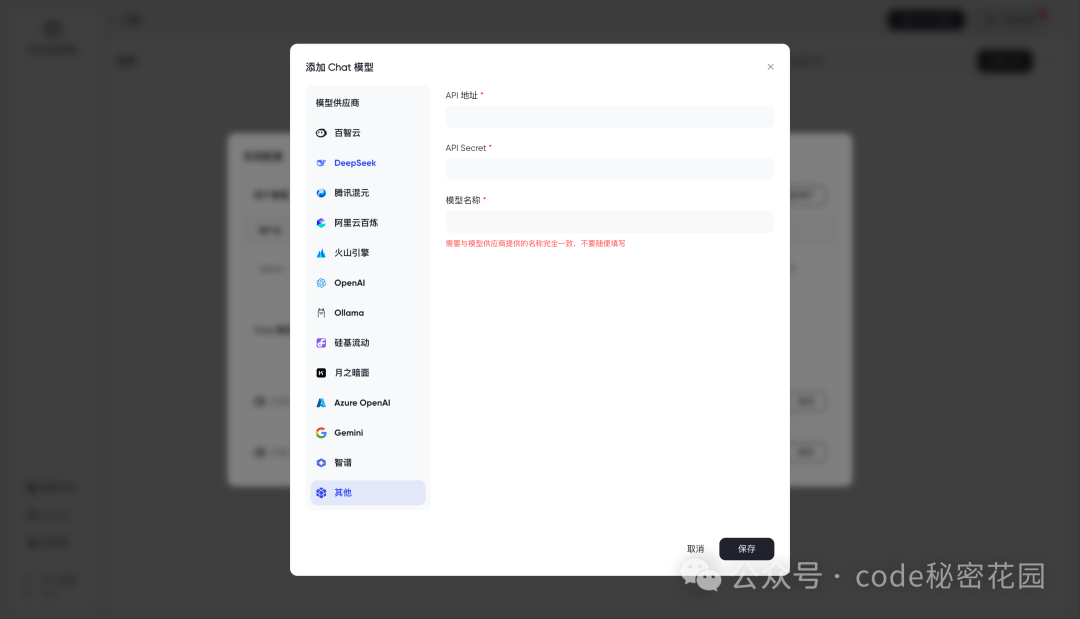
然后我门需要自己配置一个对话模型,可以看到它支持很多模型提供商,也可以自定义配置,所有兼容 OPEN AI 格式的 LLM API 都是可用的:
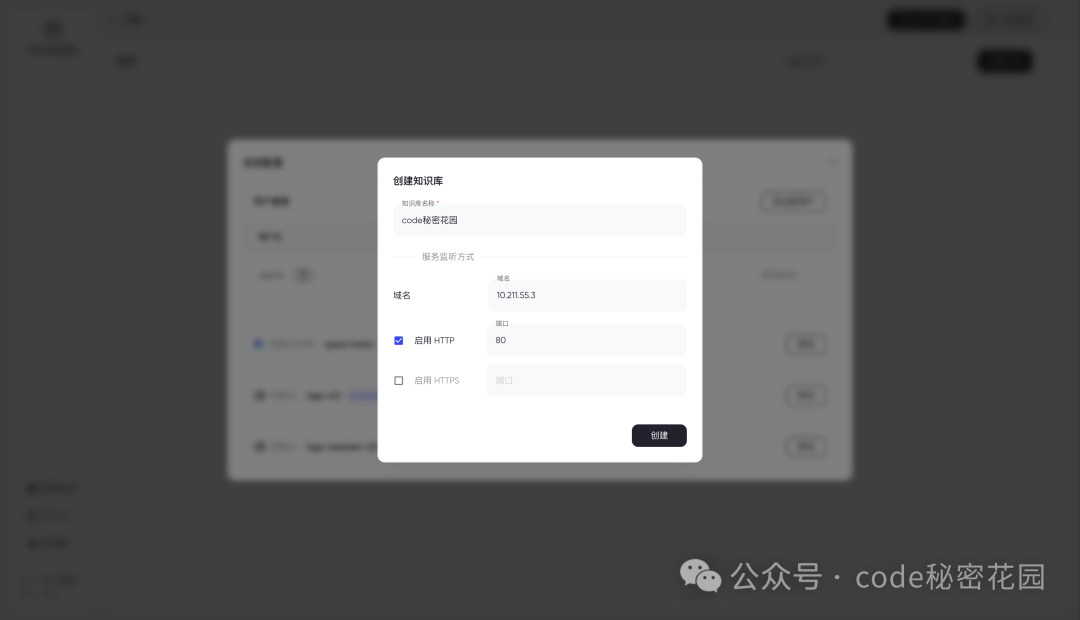
模型配置完成后,它提示我们创建一个知识库:
在 PandaWiki 中,“知识库” 就是一组文档的集合,PandaWiki 将会根据知识库中的文档,为不同的知识库分别创建 “Wiki 网站”。
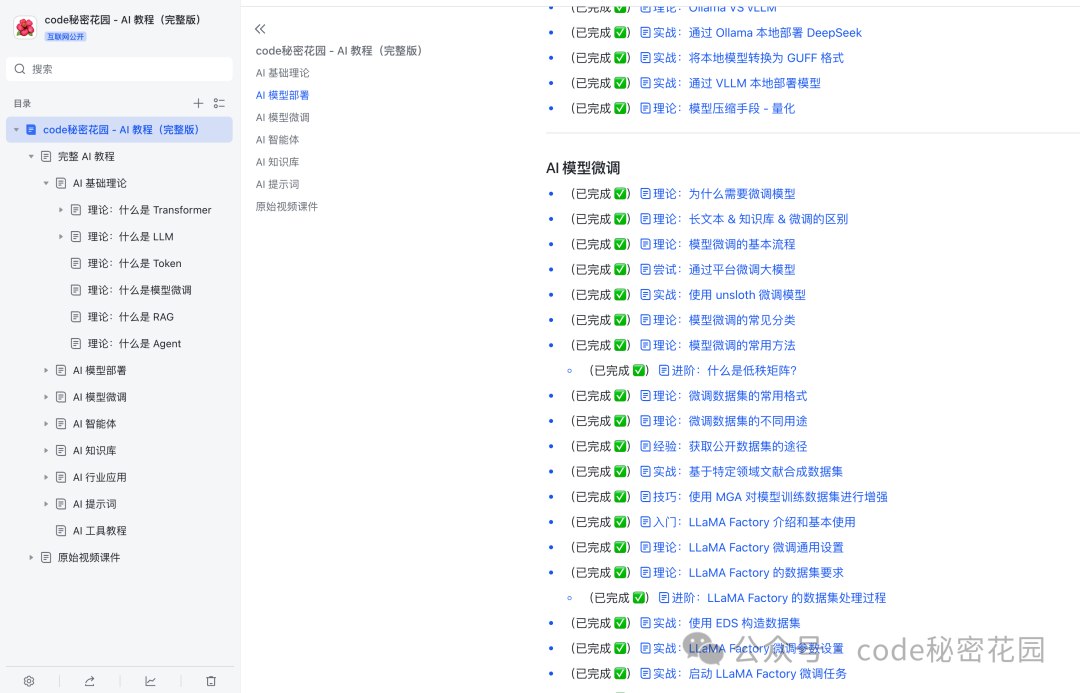
创建成功后,我们就得到了一个空白的知识库网站:
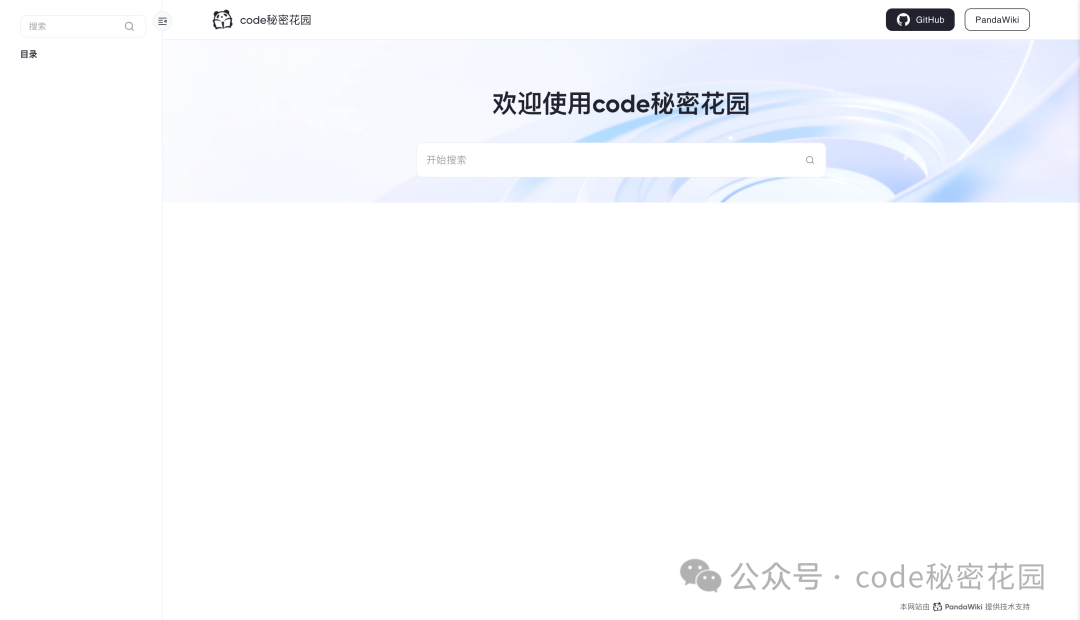
下面我们就可以添加文档了,当然就不需要每个文档再手动粘贴一遍了,这里它几乎支持了目前市面上所有主流的笔记软件的直接导入,还支持支持听过一个网页 URL 和 RSS 进行导入,还是非常方便的:
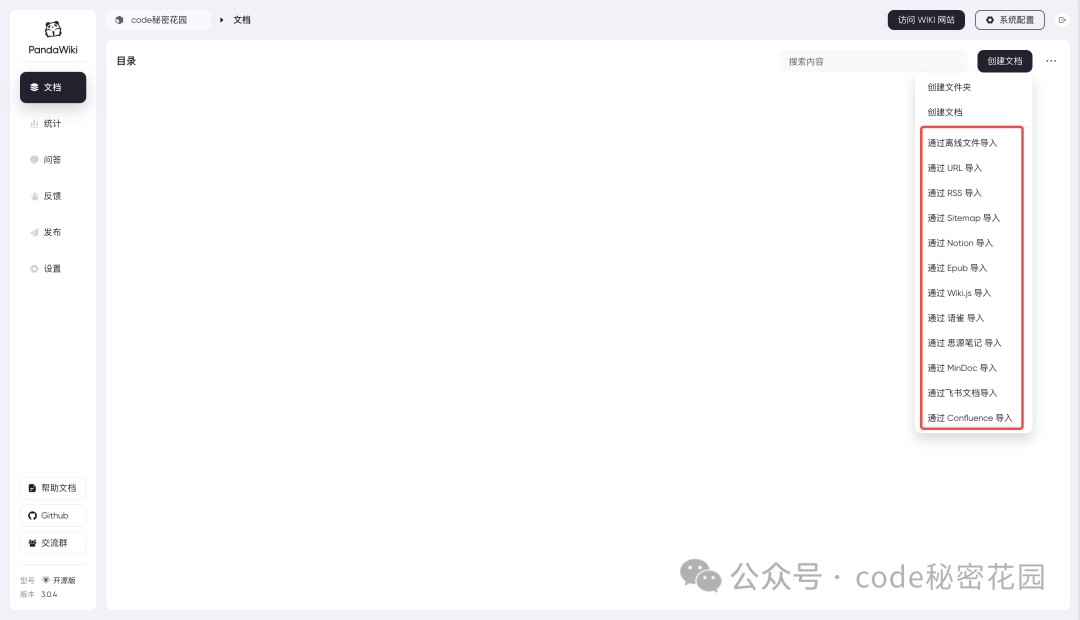
这里我准备先把我在飞书知识库中编写的 AI 教程导入进来试试:
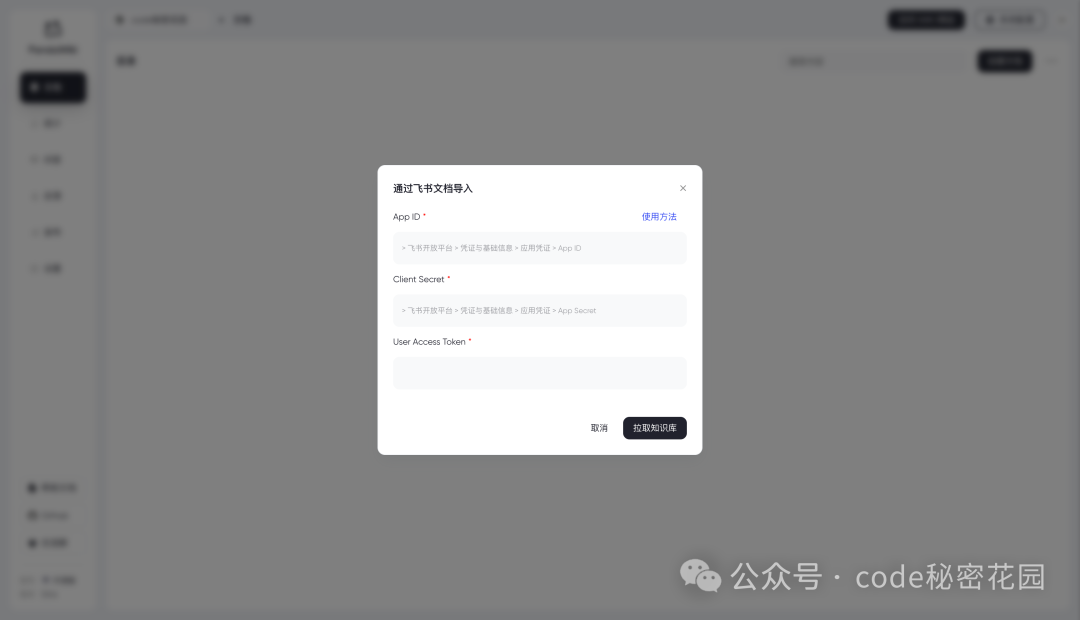
我们选择通过飞书文档导入:
我们还是直接在 PandaWiki 文档中进行提问:
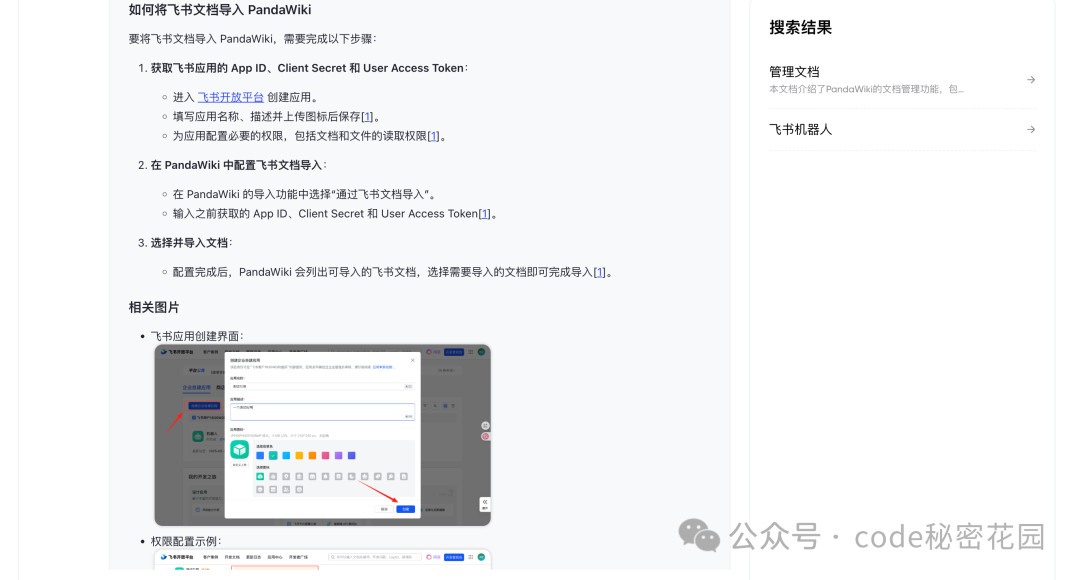
这里它会给出非常详细的配置指引,包括创建飞书机器人、配置机器人权限等等,过程我就直接省略了,大家直接根据文档操作就行了。
然后我们可以直接拉取到你在飞书文档上创建的所有文档:
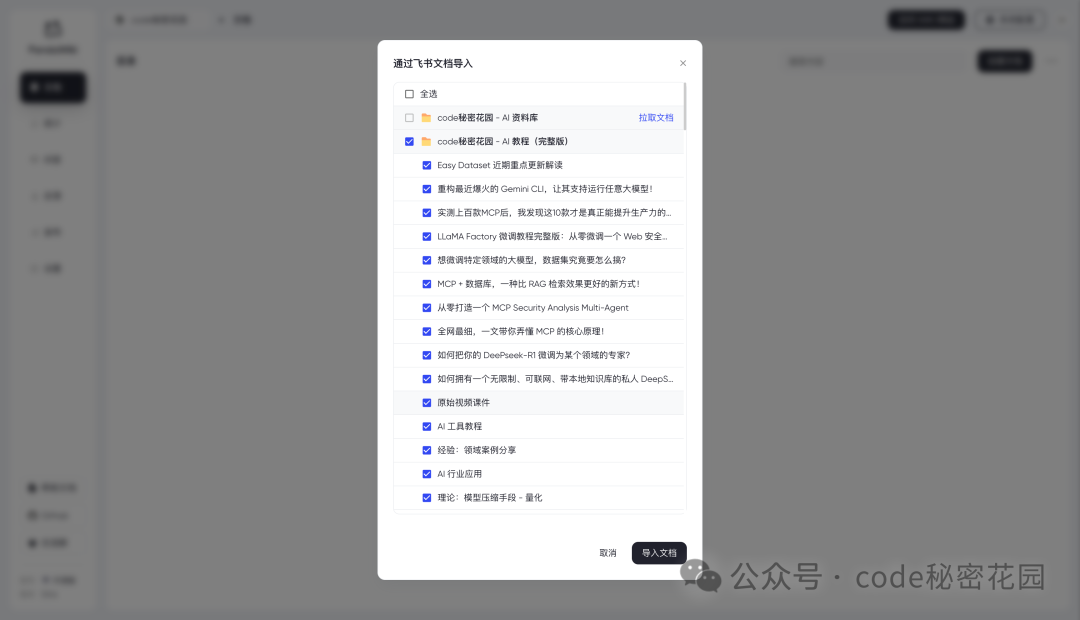
我们直接选择一批文档开始导入:
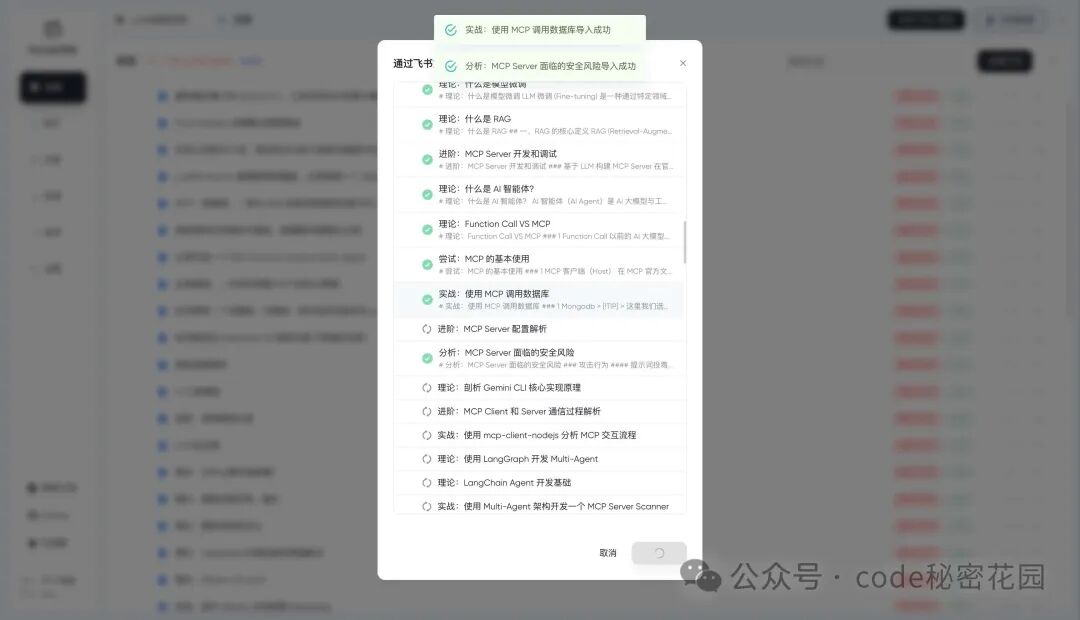
导入成功后,我们发现在后台多了一大批 “未发布” 的文档。
在 PandaWiki 中,所有新创建或新导入到文档必须经过发布才会在 Wiki 网站中可见,才会被 AI 学习到。文档在被修改以后会被标记为 “更新未发布”,此时需要重新发布,才会在 Wiki 网站中更新内容,否则只是后台的草稿状态。
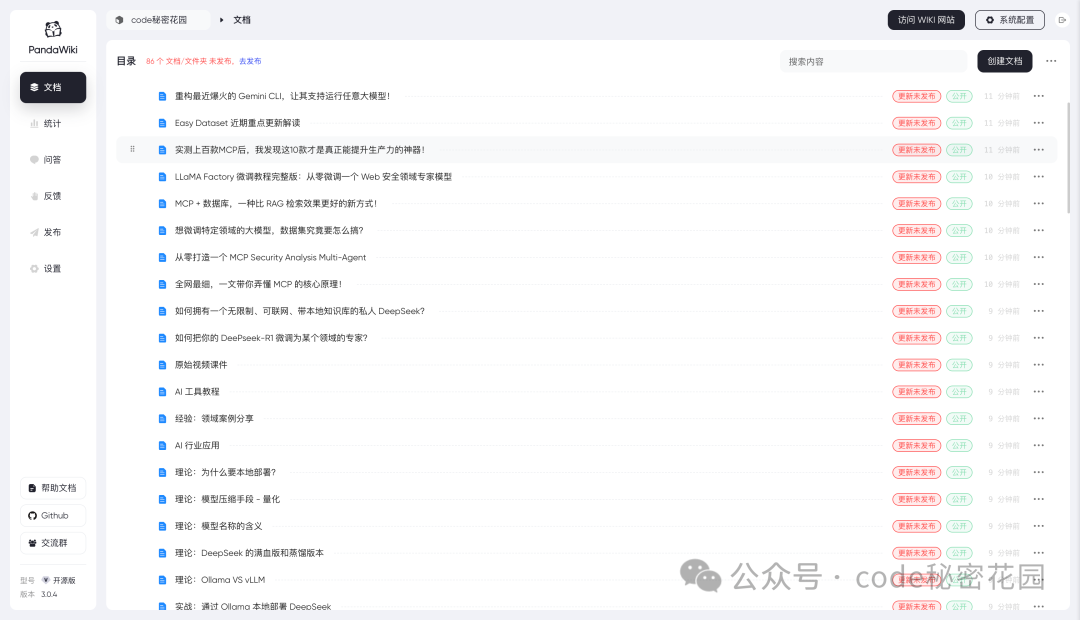
然后你可以对这些文档直接使用 AI 生成摘要:
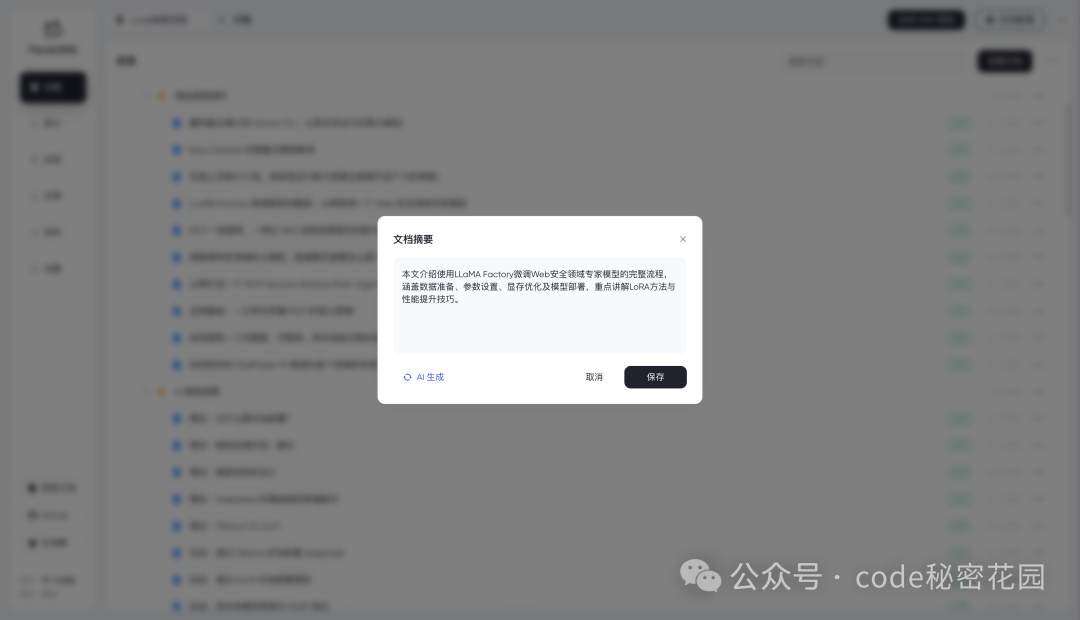
我们也可以创建一些文件夹来将文档进行分类整理:
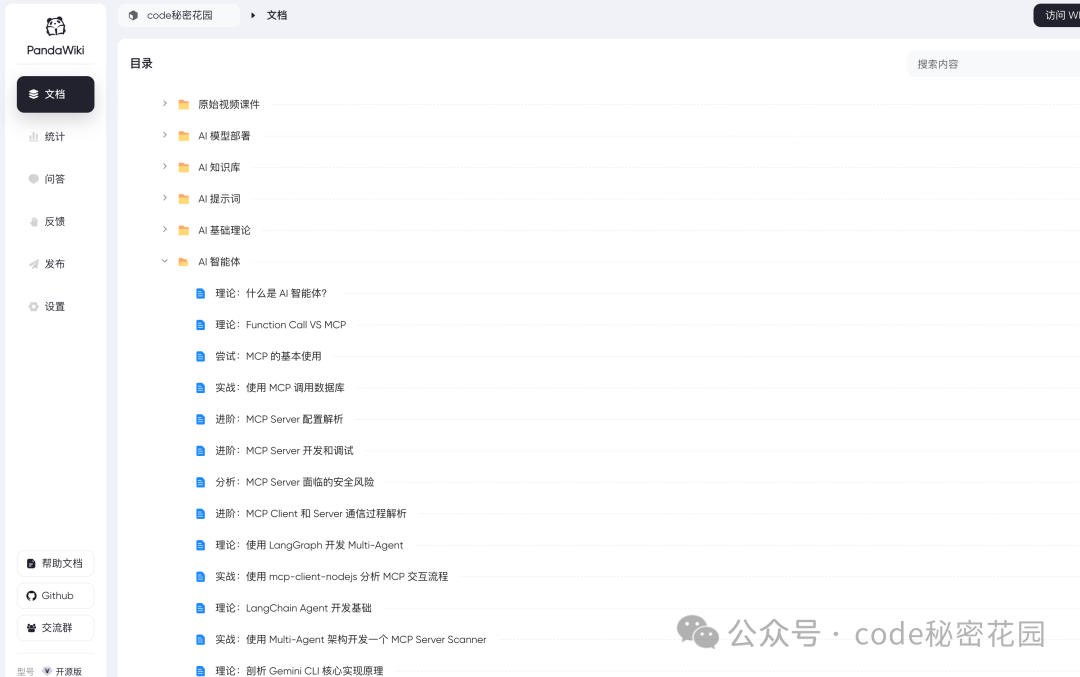
然后我们尝试一下发布这些文档:
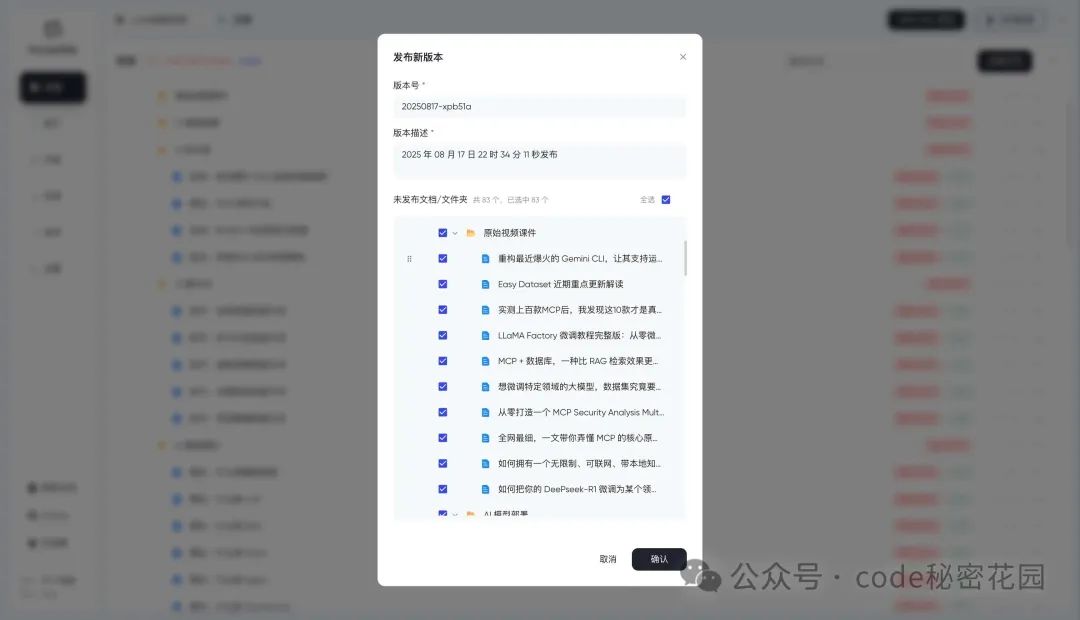
我们再刷新网站,你就直接得到了一个整理好的知识库:

在后台的设置部分,你可以做很多更细致的设置,比如首页的提示语、首页的文章卡片,背景图片,以及自定义 AI 提示词等等:
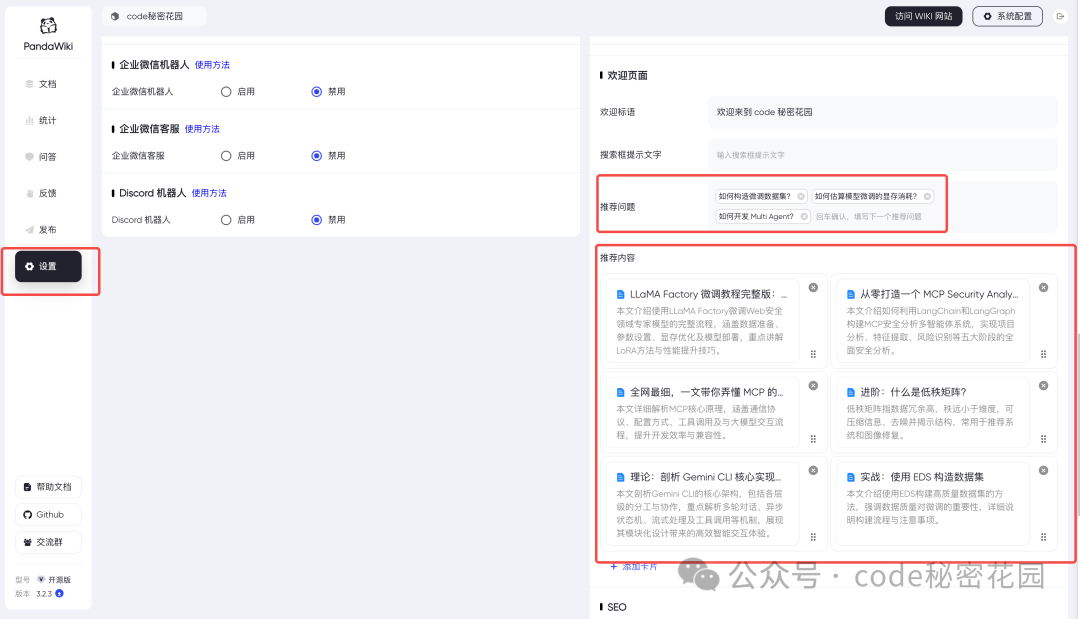
我们回到首页,效果非常不错,这很适合做个人博客,或者一些产品等文档站:
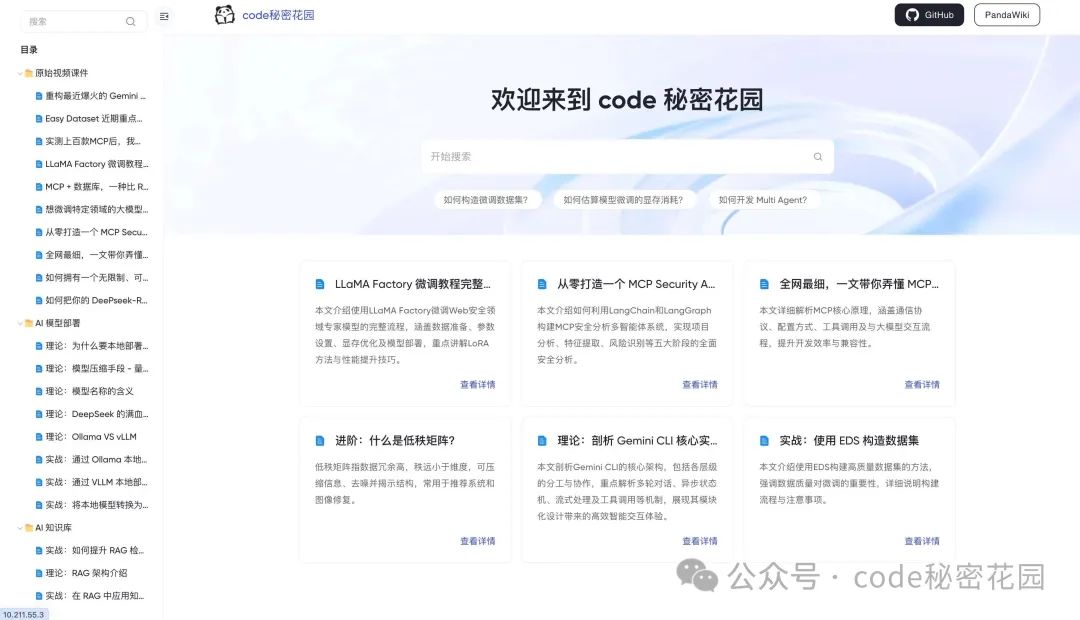
我们来尝试做一个提问,模型非常快速准确的给出了答案:
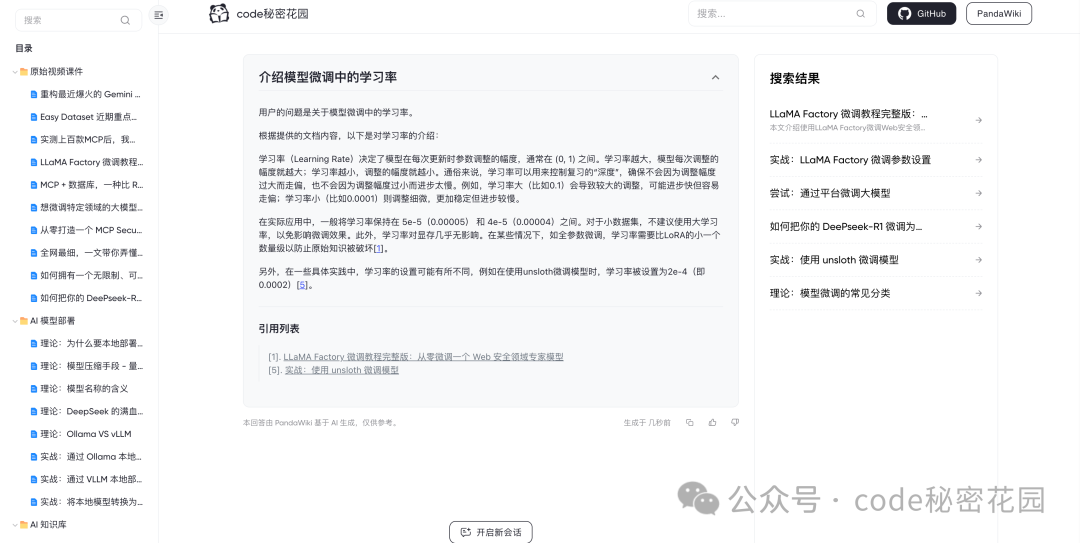
另外,PandaWiki 还支持上传和管理离线文件,咱家粉丝都知道,我经常会在星球中分享一些最新的 AI 资料文件,这些文档都很有价值,但是从知识管理的角度就不太友好了:

我们可以尝试把这些离线文件都导入到知识库,我们选择离线导入,可以发现它支持很多中格式:
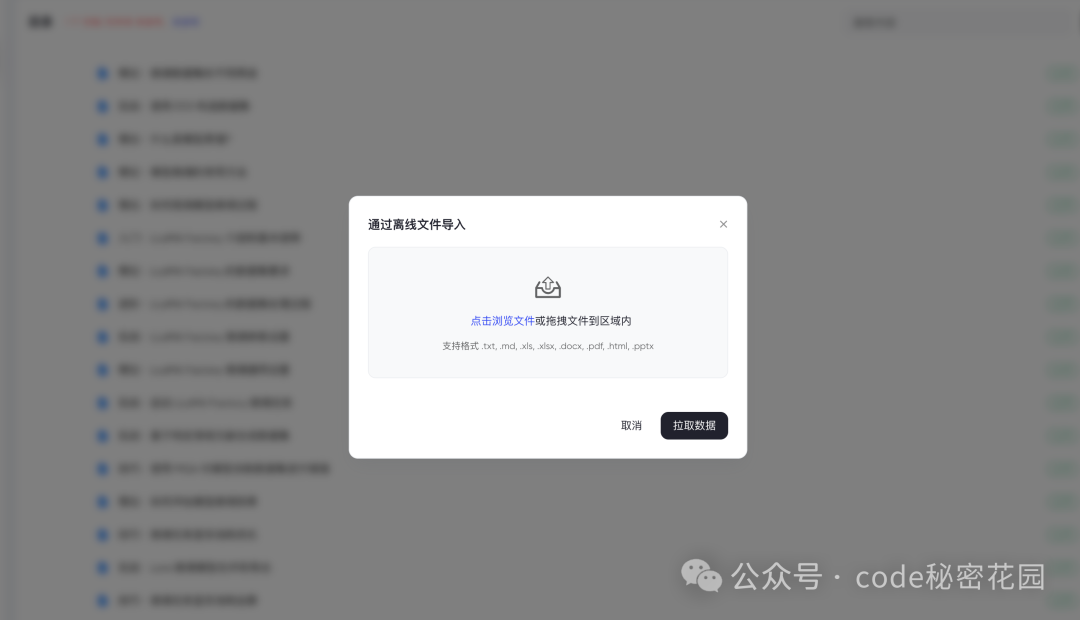
选择离线文档导入后,它会自动提取其中的内容:
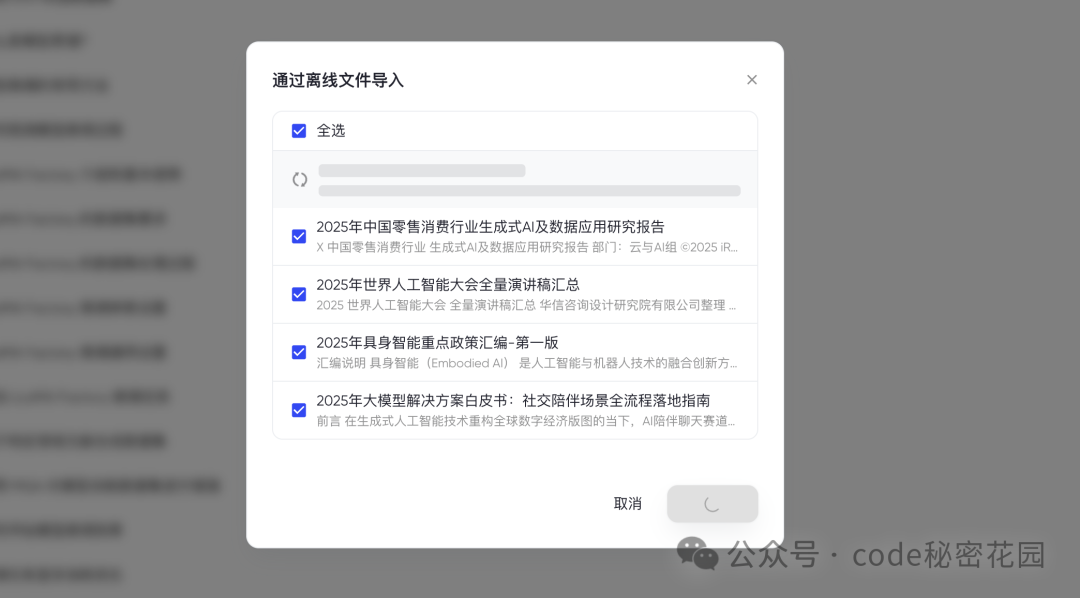
然后我们也可以直接对这些离线文档中的内容进行提问:
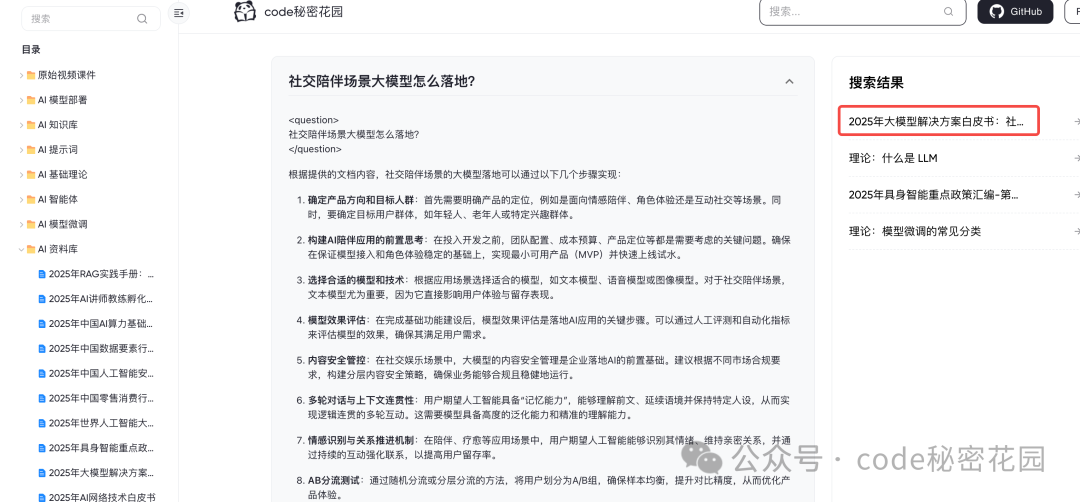
最后,我发现在后台设置中还支持非常快捷的搭建问答机器人的配置,包括网页挂件、飞书机器人、微信公众号等等等等:
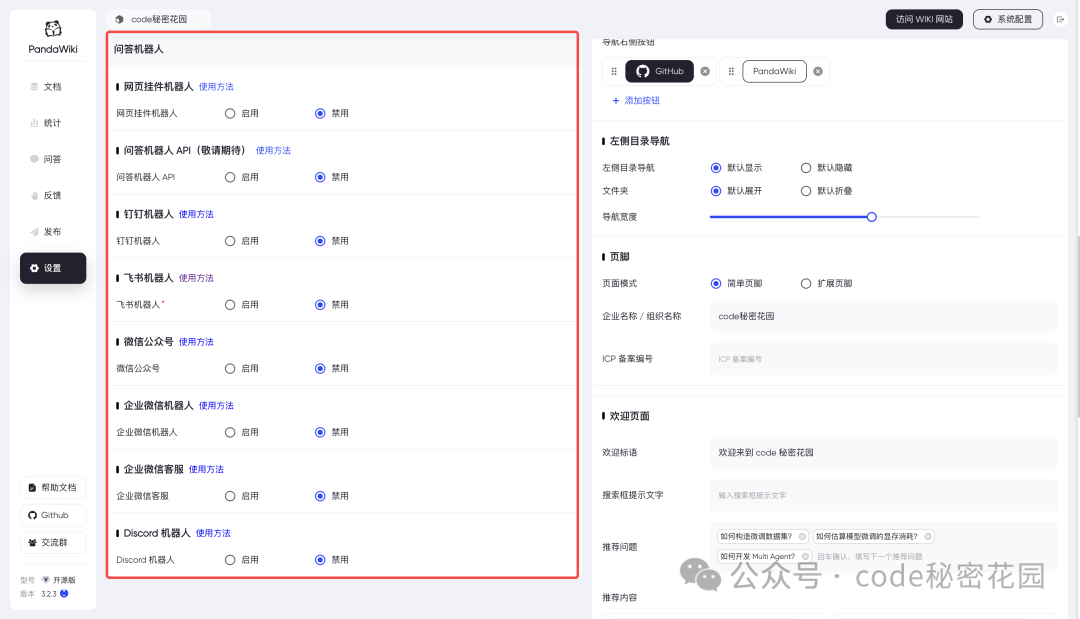
并且每一个都给出了非常详细的操作指引,对小白用户非常友好:
其他更强大的功能,就要靠大家自己去探索啦!
最后

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)