美团开源5600亿参数LongCat-Flash大模型,零计算机制让AI效率提升5倍!
美团开源5600亿参数LongCat-Flash大模型,采用革命性"零计算"专家机制,动态激活仅18.6B-31.3B参数,性能直逼DeepSeek V3.1。推理速度超100 TPS,成本仅0.7美元/百万token,在Agent工具使用等任务中表现优异。MIT协议开源,开发者可自由使用,是学习大模型架构优化的绝佳案例。
简介
美团开源5600亿参数LongCat-Flash大模型,采用革命性"零计算"专家机制,动态激活仅18.6B-31.3B参数,性能直逼DeepSeek V3.1。推理速度超100 TPS,成本仅0.7美元/百万token,在Agent工具使用等任务中表现优异。MIT协议开源,开发者可自由使用,是学习大模型架构优化的绝佳案例。
刚刚,美团正式开源了他们的龙猫大模型LongCat-Flash-Chat——一个拥有5600亿参数的混合专家(MoE)模型,性能直逼DeepSeek V3.1和Qwen-3-235B-2507!
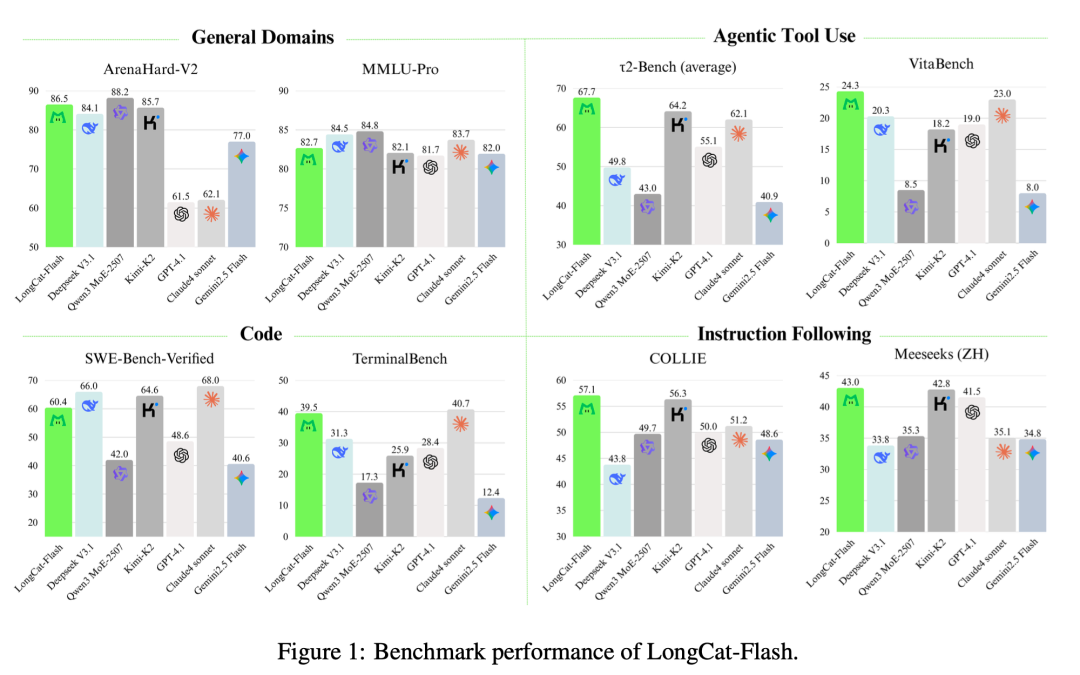
LongCat-Flash在四大核心领域的基准测试表现,绿色柱状图显示其在Agent工具使用等关键任务中的领先优势
最关键的创新——一个叫做"零计算"专家机制的黑科技,重新定义了AI算力效率。
Can you imagine?一个模型有560B参数,但每次推理只需要激活平均27B参数,推理速度超过100 TPS,成本仅0.7美元/百万token。这不是魔法,这是工程的艺术,是新的技术平权!
🔬 技术架构深度解析:重新定义MoE效率
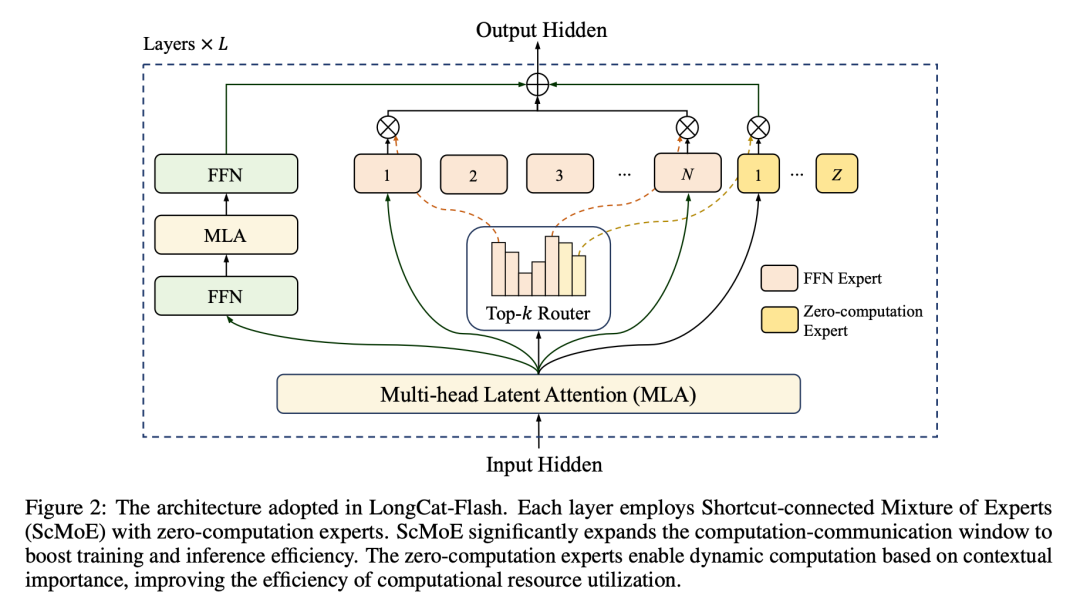
LongCat-Flash采用创新的ScMoE架构,每层集成512个FFN专家和256个零计算专家
一、核心参数与技术规格
让我们先来看看这个"庞然大物"的真实身材:
总参数量:5600亿(560B)
上下文长度:128K tokens
开源协议:MIT License
模型架构规格(基于官方技术报告):
模型层数:28层(不包括MTP层)
隐藏维度:6144维隐藏状态
注意力头数:64个头,每头维度128
专家配置:每层512个FFN专家 + 256个零计算专家
动态激活:每token激活12个专家,平均27B参数(18.6B~31.3B范围)
推理性能:100+ TPS,成本仅0.7美元/百万输出token
二、三大核心创新突破
1. “零计算"专家机制:AI界的"聪明懒人”
MLA注意力机制优化:
- KV压缩维度:512
- Query压缩维度:1536
- FFN中间维度:密集路径12288,每个专家2048
这些数字背后的含义?传统的大模型就像一个工厂,每次生产都要"全员上岗",所有参数都要参与计算。而LongCat-Flash就像一个聪明的调度员,根据任务难度动态分配"员工",简单任务派少数人,复杂任务才调动更多资源。
LongCat-Flash最具革命性的创新,就是这个"零计算"专家机制(Zero-computation Experts)。
模型可以智能判断输入内容的重要性。当遇到常见词汇、标点符号这些"简单任务"时,会分配给一个特殊的"零计算"专家——这个专家不进行任何复杂运算,直接返回输入,极大节省算力。
就像医院的智能分诊系统:发烧感冒挂普通门诊,疑难杂症才找专家。这种设计让模型在处理每个词元时,仅需动态激活186亿至313亿参数,实现了性能与效率的完美平衡。
2. ScMoE架构:高速公路的"快速通道"
在大规模MoE模型中,不同"专家"模块间的通信延迟往往是性能瓶颈。LongCat引入了快捷连接混合专家模型(Shortcut-connected MoE, ScMoE)。
这就像在高速公路上增加了快速通道,有效扩大了计算和通信的重叠窗口,让模型响应更快,吞吐量更高。
3. Agent优化训练:为"智能代理"而生
LongCat-Flash经历了精心设计的多阶段训练流程:大规模预训练→针对性提升推理和代码能力→专注对话和工具使用的后训练。
这种设计使其在执行需要调用工具、与环境交互的复杂Agent任务时表现出色,这也是它与其他模型的关键差异化优势。
三、 性能基准测试:与顶级模型正面PK
01. 官方评估结果
在各项权威基准测试中,LongCat-Flash展现出了非常强劲且极具竞争力的性能。以下是来自GitHub官方仓库的完整对比数据:
| 测试领域 | 具体基准 | DeepSeek V3.1 | Claude4 Sonnet | LongCat-Flash |
|---|---|---|---|---|
| 通用能力 | MMLU | 90.96 | 91.75 | 89.71 |
| ArenaHard-V2 | 84.10 | 62.10 | 86.50 | |
| 指令遵循 | IFEval | 86.69 | 88.35 | 89.65 |
| COLLIE | 43.80 | 51.22 | 57.10 | |
| 数学推理 | MATH500 | 96.08 | 93.80 | 96.40 |
| AIME25 | 49.27 | 37.00 | 61.25 | |
| 代码能力 | LiveCodeBench | 56.40 | 45.59 | 48.02 |
| Humaneval+ | 92.68 | 94.51 | 88.41 | |
| Agent工具 | τ²-Bench(telecom) | 38.50 | 46.20 | 73.68 |
| VitaBench | 20.30 | 23.00 | 24.30 |
关键亮点分析:
- COLLIE测试中57.10的高分,在所有参与对比的模型中排名第一!这强有力地证明了它在执行复杂"智能代理"任务方面的卓越能力
- τ²-Bench电信场景73.68分,几乎是第二名的1.6倍,展现了在特定领域Agent任务中的统治级表现
- IFEval指令遵循89.65分,超越了包括GPT-4.1和Claude4在内的所有对比模型
虽然在传统的MMLU测试中略逊于DeepSeek V3.1,但LongCat-Flash在Agent相关任务中的表现堪称惊艳——这正是未来AI应用的关键场景。
02. 效率与成本:又快又便宜的杀手锏
更令人震撼的是LongCat-Flash的效率表现:
- 推理吞吐量比Llama 3.3-70B提升5倍
- 每处理一百万输出词元成本仅0.7美元
- 推理速度超过100 TPS
要知道,当前主流云服务的大模型调用成本通常在2-10美元/百万token。LongCat-Flash的成本优势,让企业级应用成为可能。
四、"零计算"机制深度剖析:重构AI计算范式
让我们深入了解这个革命性的设计。当模型处理文本时,会遇到大量的"简单token"——比如"的"、“了”、标点符号等。
传统模型对这些token也要进行完整的神经网络计算,就像用手术刀切菜一样过度精细。而LongCat的"零计算"专家就像智能分诊系统:
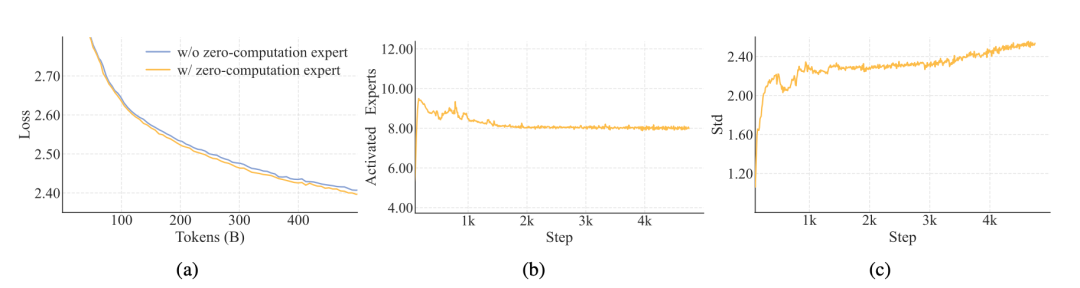
零计算专家机制的效果对比:黄色线显示采用零计算专家的模型训练损失下降更快
这种设计的前瞻性在于,它不是简单的"偷懒",而是基于对语言本身规律的深刻理解。在实际应用中,大量的计算资源被"浪费"在处理这些简单token上,零计算机制让模型把算力用在真正需要的地方。
ScMoE架构的通信革命
🔧 技术实现细节(基于技术报告):
零计算专家采用PID控制器机制进行专家偏置调整,确保激活专家数量的动态平衡:
- 平均激活专家数:约8个FFN专家(对应27B参数)
- 激活标准差:约3,表明不同token间计算资源分配差异显著
- 控制策略:通过专家偏置动态调整,维持期望的专家选择比例
大规模MoE模型的通信瓶颈一直是业界难题。LongCat通过ScMoE架构,将计算和通信巧妙重叠,就像多车道高速公路允许不同速度的车辆并行行驶,大大提升了整体效率。
这种工程优化看似不起眼,但对实际部署的影响巨大——它让LongCat能够在数万个加速器的大规模集群上稳定训练,并在推理时保持高吞吐量。
五、行业意义:美团AI布局的战略深意
这并非心血来潮。美团正将积累的外卖、到店等核心业务数字化能力,通过LongCat大模型、数据接口、开发工具等形式对外输出,构建"AI工具即服务"的新商业模式。
早在今年6月,美团就推出了基于LongCat的NoCode编程工具,让零基础用户通过对话就能开发应用。内部数据显示,美团研发团队已有50%的代码是AI生成的,效率提升令人惊叹。
面对阿里、字节等大厂在AI领域的激烈竞争,美团选择了一条"全民友好+场景深耕"的差异化路线。凭借在本地生活场景的深厚积累,LongCat有望在垂直领域应用中脱颖而出。
六、 开源生态:MIT协议释放全球创新力
LongCat-Flash采用MIT许可协议,这是对开发者最友好的开源协议之一,允许商业使用、修改和再分发。
模型已同步发布在GitHub和Hugging Face平台,全球研究者和开发者都能自由使用。更贴心的是,官网longcat.ai还提供在线体验,让用户无需部署就能直接测试模型能力。
对比其他开源模型的许可协议限制,LongCat-Flash的开放程度可谓业界良心。这种策略不仅展示了美团的技术实力,更是在抢占AI生态建设的制高点。
预计开源后,LongCat将快速形成开发者社区,在Agent应用、代码生成、多模态交互等领域催生大量创新应用。
七、 未来展望:龙猫能否撬动AI新格局?
LongCat-Flash的发布,为中国大模型技术树立了新标杆。效率优化正在成为行业新趋势——不再单纯追求参数规模,而是追求更聪明的计算方式。
随着Agent应用场景的爆发,LongCat在工具调用、环境交互方面的优势将更加凸显。开源vs闭源的竞争也将更加激烈——技术民主化与商业化之间的平衡,考验着每一家AI公司的智慧。
这只"龙猫"能否在AI江湖中占据一席之地?时间会给出答案。但可以确定的是,更高效、更开放的AI时代正在加速到来。
八、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献297条内容
已为社区贡献297条内容

所有评论(0)