AI 真的“懂”上下文吗?自注意力机制带你揭开大模型的思维密码
摘要: 自注意力机制是AI理解上下文的核心技术,通过Q(问题)、K(索引)、V(答案)三个向量模拟信息检索。例如,判断“他”指代谁时,AI用Q匹配上下文中的K,计算相似度后加权融合V,最终关联到“小明”。多头注意力则像多专家投票,从不同角度分析语义。相比传统RNN的逐字处理,自注意力赋予AI全局视野,能捕捉远距离依赖关系,实现逻辑推理。尽管AI的“理解”本质是统计关联,但自注意力机制使其接近人类的
你有没有好奇过,当你说“他昨天赢了比赛”,AI 是怎么知道“他”指的是小明,而不是小红或教练?
它不像人一样有生活经验,也没法打电话去问当事人。但它却能精准地理解语义、把握指代、捕捉情感。这背后的核心技术,就是——自注意力机制(Self-Attention)。
今天,我们不讲复杂的数学公式,也不堆砌术语。用借书、聊天、聚会这些日常场景,带你彻底搞懂:AI 是如何“理解上下文”的?
一、自注意力的本质:找信息的“搜索引擎”
想象你走进图书馆,想找一本关于“人工智能”的书。
但书架上没有目录,每本书只贴了一个标签(比如“机器学习”“神经网络”),内容还得翻开才知道。
你怎么找?
- 你想找什么? → “人工智能”
- 你扫一眼所有书的标签 → 哪些和“人工智能”相关?
- 挑出最相关的几本 → 重点看它们的内容
这个过程,其实就是 自注意力机制的核心逻辑。
在 AI 看来:
- Q(Query):你想找什么?——“人工智能”
- K(Key):每个项目的“标签”是什么?——书名标签
- V(Value):真正的“内容”是什么?——书里的知识
✅ 一句话总结:Q 是问题,K 是索引,V 是答案。用 Q 去匹配 K,找到最相关的 V。
二、四步算出“注意力”:AI 的思考流程
我们用一个简单句子来演示:“他昨天赢了比赛”,目标是搞清楚“他”到底是谁。
假设上下文提到了“小明参加了比赛”,那么模型就要判断:“他”是不是小明?
以下是自注意力的四个步骤:
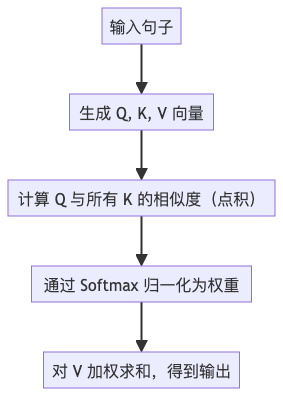
第一步:生成 Q、K、V
每个词(如“他”“昨天”“赢了”)都会被转换成三个向量:
- Q(查询向量):这个词在“寻找”什么上下文?
- K(键向量):这个词能“提供”什么信息?
- V(值向量):这个词的“实际内容”是什么?
比如,“他”的 Q 向量可能在问:“前面谁提到了人名?”
第二步:点积计算相似度
用“他”的 Q 去和每一个词的 K 做点积(dot product),结果越大,说明越相关。
|
词 |
相似度(Q·K) |
|
他 |
0.2 |
|
昨天 |
0.1 |
|
赢了 |
0.3 |
|
比赛 |
0.4 |
|
小明 |
0.9 |
看到没?“小明”得分最高——因为它是一个人名,最可能被“他”指代。
第三步:Softmax 归一化
把相似度转成概率分布,确保总和为 1:
[0.1, 0.05, 0.15, 0.2, 0.5] → “小明”占 50% 权重第四步:加权求和 V
最后,用这些权重去“加权读取”每个词的 V 向量,得到一个新的、融合了上下文的信息向量。
结果:“他”现在不仅代表自己,还“吸收”了“小明”的语义特征。
所以 AI 才能知道:“他”=“小明”。
三、多头注意力:多个专家一起投票
如果只让一个“注意力头”来判断,可能会偏颇。比如有人只关注语法,有人只看动词。
所以,Transformer 引入了 多头注意力(Multi-Head Attention) ——就像请来多个专家,各自从不同角度分析。
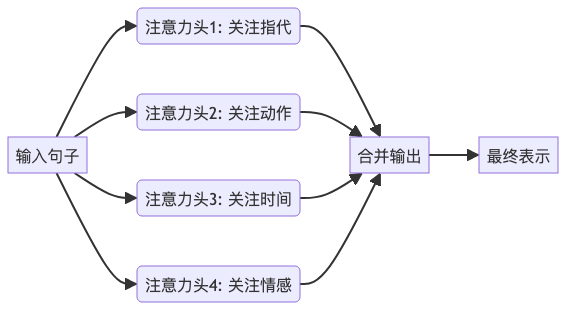
每个头学习不同的 Q、K、V 投影,捕捉不同类型的依赖关系:
- 有的关注“谁做了什么”
- 有的关注“什么时候发生的”
- 有的关注“语气是积极还是消极”
最后把所有头的结果拼在一起,再压缩一下,形成更丰富、更全面的理解。
🌟 就像开会决策:一个人容易误判,但多人投票,结论更可靠。
四、真实例子:“他昨天赢了比赛”到底在说谁?
我们回到开头的例子。
完整上下文可能是:
“小明报名参加了马拉松。他昨天赢了比赛。”
模型会这样推理:
- “他”的 Q 向量出发,搜索前面的名词
- “小明”作为人名,K 与 Q 高度匹配
- Softmax 给“小明”分配高权重
- 最终,“他”的表示融合了“小明”的语义
✅ 所以 AI 能正确理解:“他” = “小明”
而如果是:
“教练鼓励了小明。他昨天赢了比赛。”
这时,“教练”和“小明”都是人,模型会结合动词“赢了”(通常指参赛者)进一步判断,倾向于“小明”。
这正是自注意力的强大之处:它不仅能看词,还能理解角色、动作、逻辑关系。
五、为什么自注意力改变了 AI 的游戏规则?
在它出现之前,NLP 模型主要靠 RNN 一步步处理文本,像读小说一样逐字推进。
问题来了:
- 读到“他”时,早就忘了前面的“小明”
- 长句子根本记不住远距离依赖
而自注意力一次性看到整个句子,所有词两两计算关联,无论距离多远,都能建立联系。
🔥 它让 AI 第一次真正具备了“全局视野”。
这也是为什么 GPT、BERT 等大模型都能“上下文推理”,甚至写出连贯文章、回答复杂问题。
结语:AI 的“理解”,其实是“关联”
严格来说,AI 并不“理解”语言,它只是在学习词语之间的统计关联模式。
但自注意力机制,让它能像人类一样:
- 抓重点
- 找指代
- 推逻辑
- 看整体
这已经足够接近“理解”的边界。
下一次当你问 AI:“他说的‘他’是谁?”
你可以知道——
它不是瞎猜,而是用 Q、K、V,在万亿次计算中,找到了最可能的答案。
如果你觉得这篇文章有帮助,欢迎点赞、转发,让更多人看懂AI背后的逻辑

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 41
41 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)