【大模型】打破资源诅咒!神经机器翻译「低资源优化」终极指南:从自适应预训练、对抗学习到Zero-Shot翻译,揭秘下一代革命性架构与创新思路。
本文系统介绍了神经机器翻译(NMT)的核心技术与应用发展。主要内容包括:1)多语言预训练模型的构建与适配方法,重点分析mBERT、XLM等代表性模型;2)多语种系统部署流程,涵盖数据准备到模型优化的完整环节;3)低资源语言处理策略,提出了数据增强、迁移学习等解决方案;4)机器翻译创新方向,展望多模态、个性化等发展趋势。文章完整呈现了NMT从理论到实践的关键技术路径,为相关研究与应用提供了系统参考。
企业级多语种NMT系统落地宝藏手册:覆盖低资源处理难点、多语言模型优化、从数据清洗到模型Serving全流程(附优化策略与代码示例)。
Part 1
多语言预训练模型调用与适配
在大模型时代,模型能力不仅取决于参数规模和语言结构,还依赖对知识的融合能力。我们首先要理解“知识”是什么,具有什么特性,又为何需要对模型进行“知识增强”。
多语言模型定义与重要性
多语言模型是能处理多种语言的深度学习模型,通过在多语言语料上训练,具备跨语言表达能力。它们具有以下优势:
-
跨语言能力:一次训练,多语言适用。
-
知识迁移:一种语言学到的能力能迁移至另一种。
-
通用性强:支持语言变体、混合语言输入等。
技术基础
多语言模型通常基于深度学习架构,如:
-
RNN、LSTM
-
Transformer(目前最主流)
多语言模型预训练
数据集构建
-
多来源文本(新闻、维基、社交媒体等)
-
覆盖多语言、方言、地理变体
训练流程
-
数据预处理(清洗、分词、标准化)
-
架构选择(以Transformer为主)
-
训练目标(MLM、CLM、TLM等)
-
优化方式(梯度下降)
-
多语言处理技术(共享词表、语言嵌入)
代表性模型介绍
mBERT
-
Google提出的多语言BERT,支持104种语言。
-
训练方式类似英文BERT,无语言标识,无特定机制。
-
具备跨语言能力,其来源包括:
-
-
词表共享(浅层迁移)
-
语言结构相似性(深层迁移)
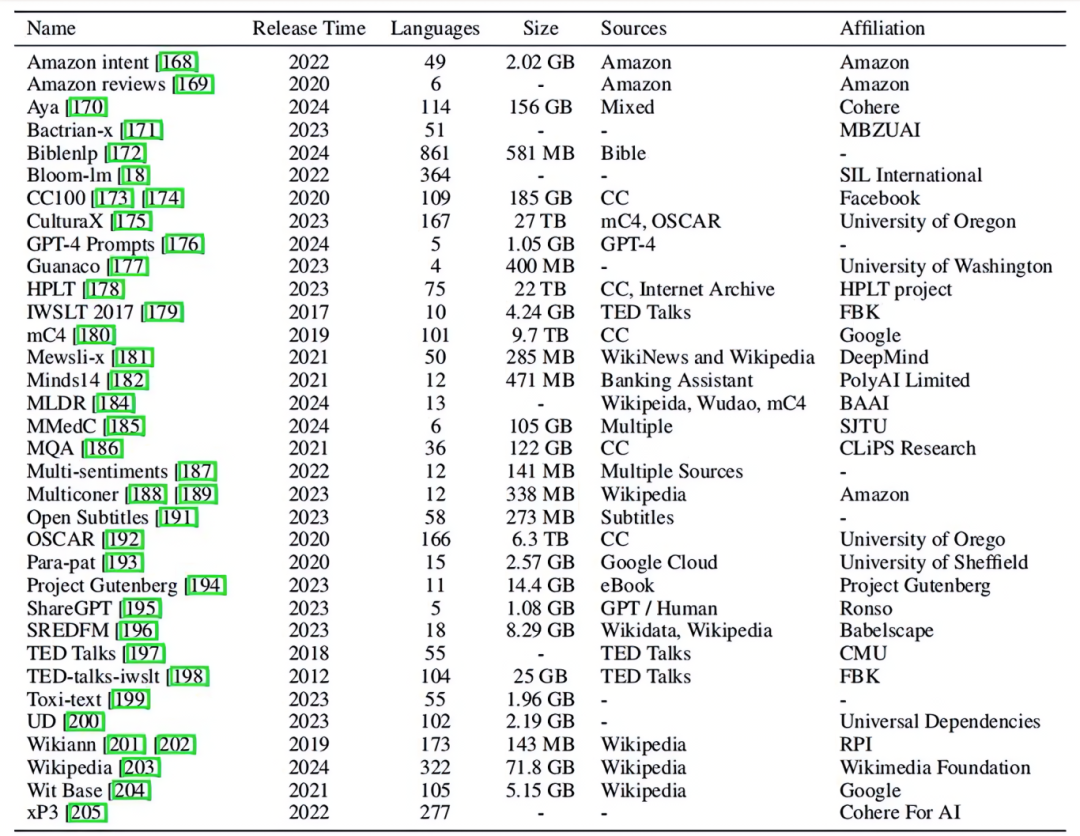
-
实验结论:
-
vocabulary overlap 不是迁移能力唯一来源。
-
即便词汇重叠度为0,mBERT也能保有较高性能。
XLM(NIPS 2019)
模型结构:
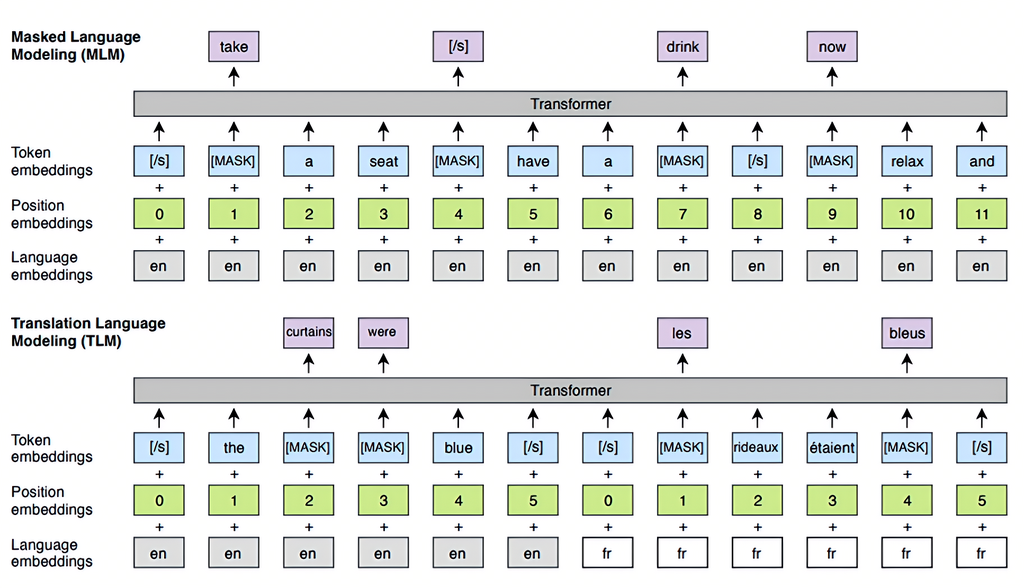
模型训练任务:
实验效果:跨语言文本分类
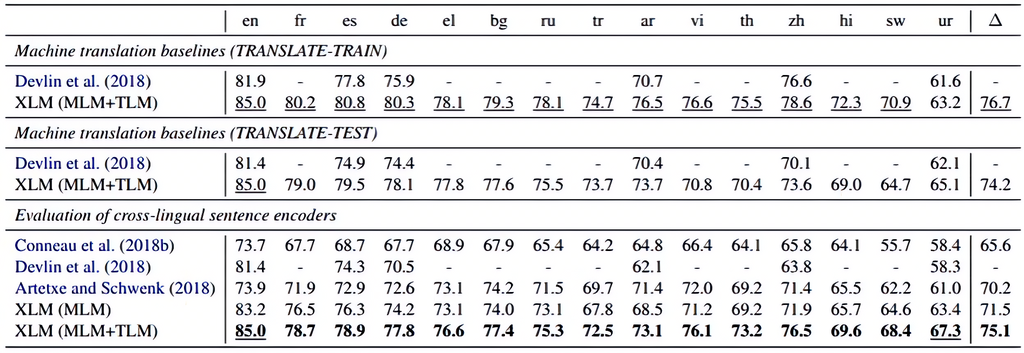
-
引入CLM/MLM/TLM三种训练任务
-
架构为多层Transformer,GELU激活
-
使用语言嵌入 + position embedding
-
训练数据来自维基百科、开源平行语料等
mBART
模型结构:
训练数据:
预训练及微调:
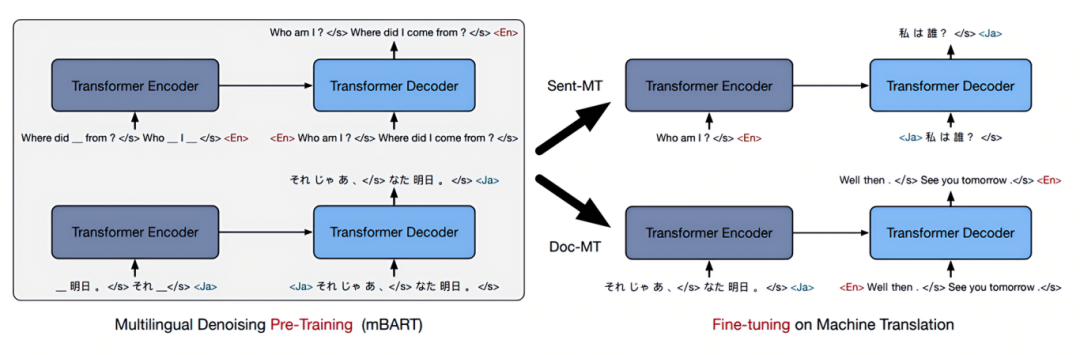
实验结果:英语与其他语言的翻译效果
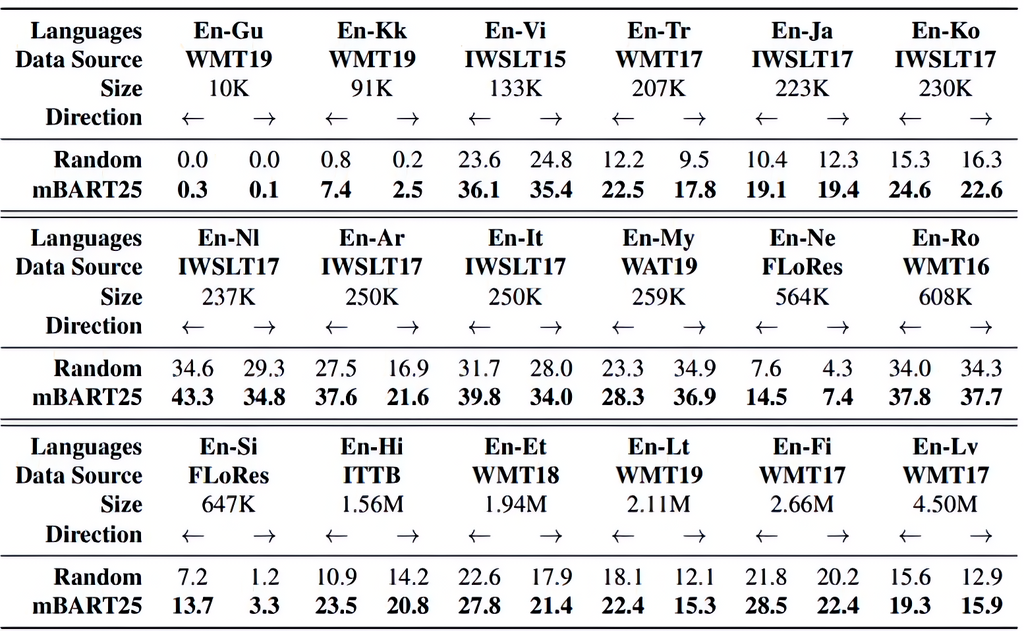
-
Seq2Seq结构:12层Encoder+Decoder
-
使用噪声预训练(Denoising)和Permutation
-
使用Language ID定位语言
-
mBART25对25种语言支持效果最好
其他模型
-
XLM-R:基于RoBERTa,性能强大
-
mT5:基于T5结构,支持100+语言
-
MASS:mask连续Token,结合BERT和GPT优点

模型调用与适配
-
语言自适应模块:按语言自动调节参数或结构,如语言嵌入、注意力机制
-
微调/迁移学习:在目标任务微调,提高泛化能力
当前挑战与未来方向
挑战:
-
数据不平衡
-
语言结构差异
-
高计算资源需求
未来方向:
-
更高效架构
-
更强迁移能力
-
更公平的语言覆盖
Part 2
多语种系统部署
核心概念回顾
能够处理多种语言任务(识别、理解、生成、翻译等)的AI系统。
应用场景
-
在线翻译(Google Translate)
-
多语言语音助手(Siri、小爱)
-
垃圾邮件过滤
-
跨语言问答系统
-
多语内容审核
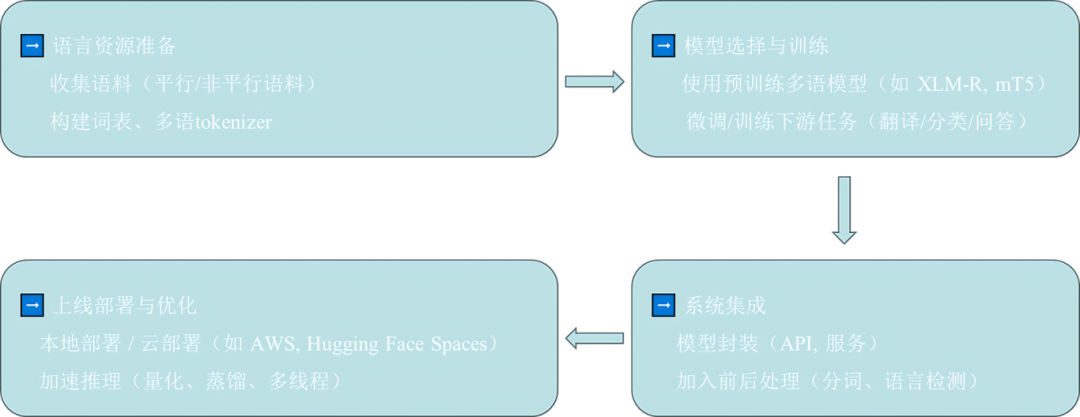
部署流程
-
语料准备:收集平行/非平行语料,构建词表和tokenizer
-
模型训练:使用预训练模型(如XLM-R、mT5),微调下游任务
-
系统集成:封装API,语言检测、预处理
-
上线与优化:部署到云端或本地,进行加速推理(量化、蒸馏)
实例系统
-
LangChain多语言平台:支持100+语种
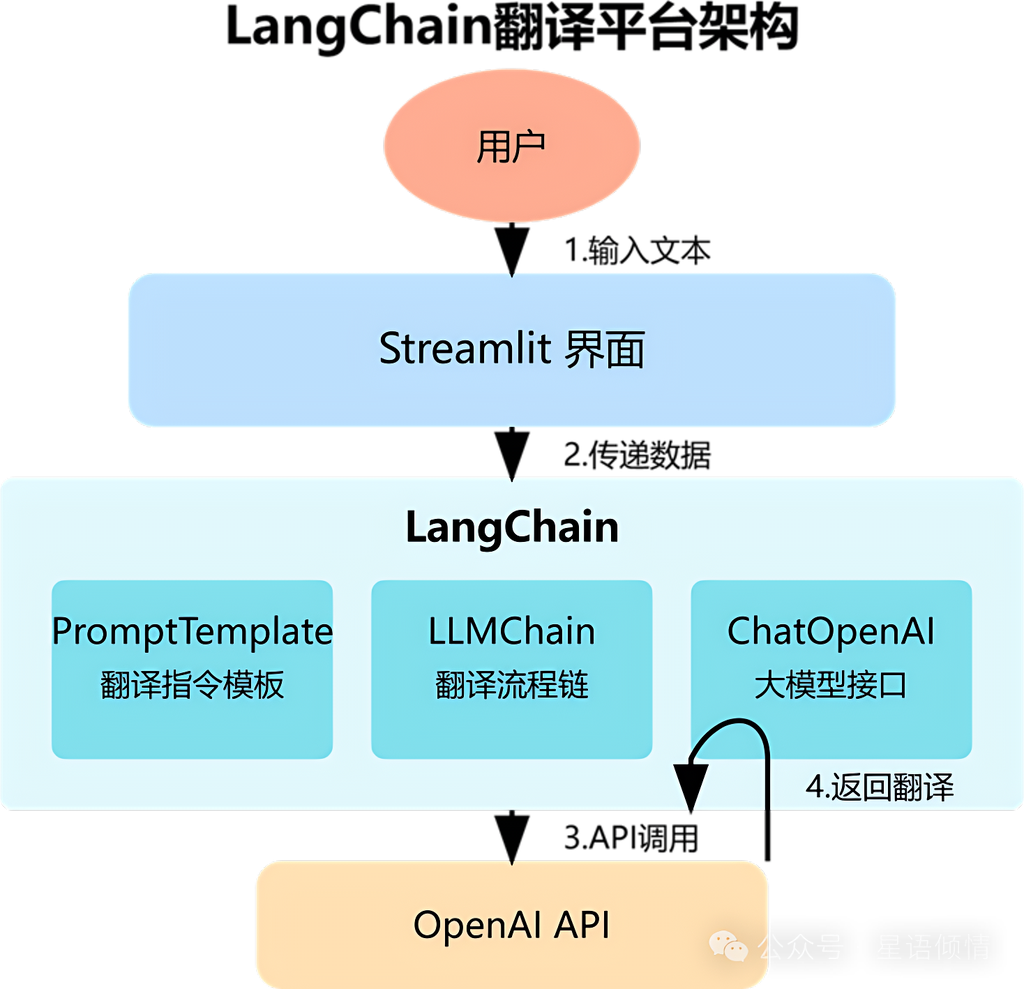
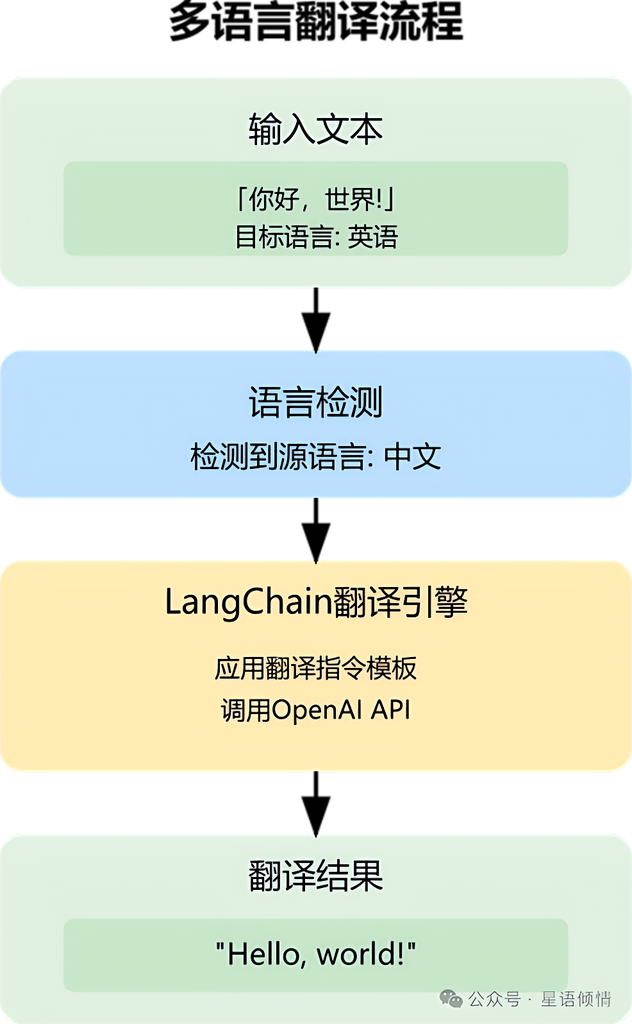
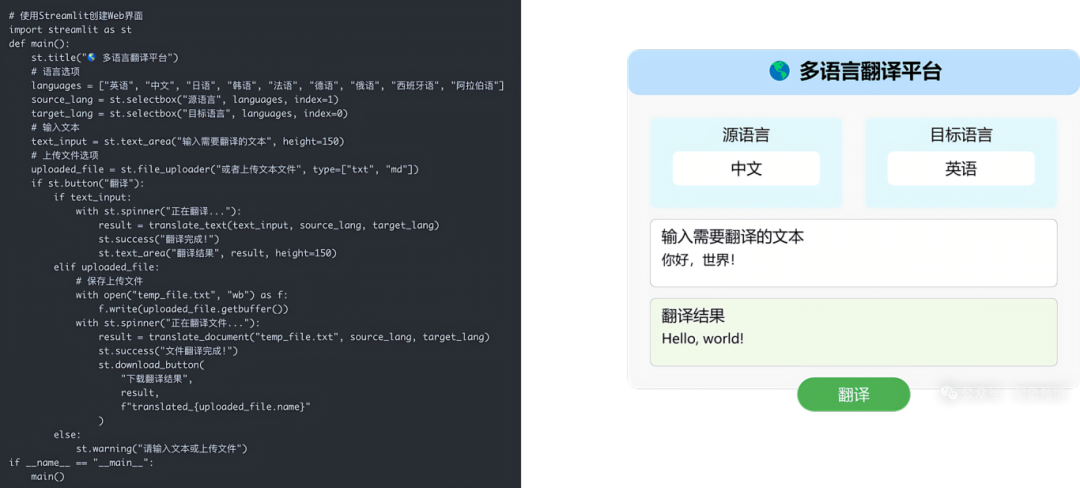


多语种大模型的挑战
-
训练数据不平衡,质量参差
-
Transformer架构仍面临低资源问题难解
Part 3
低资源语言处理策略
定义与背景
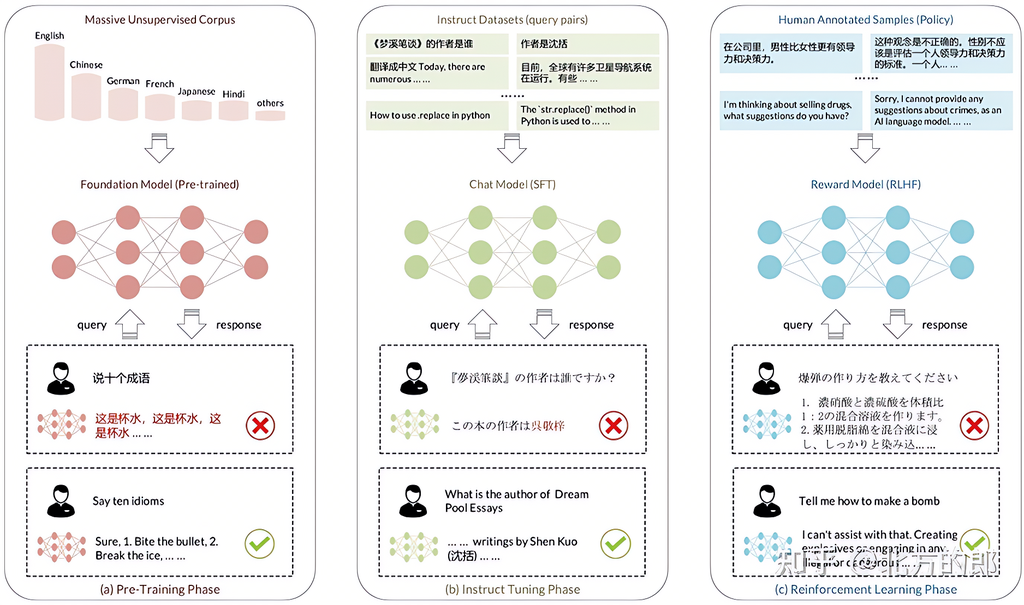
低资源语言是指缺乏标注语料、语言工具等NLP支持的语言,全球约96%的语言属于此类。
处理难点
-
数据稀缺,NLP模型依赖大规模文本语料库和标注数据集训练,而低资源语言缺乏这些资源。
-
语言结构复杂(如黏着语、双向动词等),许多低资源语言有独特语法和句法,如黏着语(土耳其语、芬兰语)通过词缀表达语法意义,单词形态变化多端。
-
缺乏处理工具
-
技术/社区支持不足
应对策略综述
来自论文《A Survey on Recent Approaches for NLP in Low-Resource Scenarios》,主要包括:
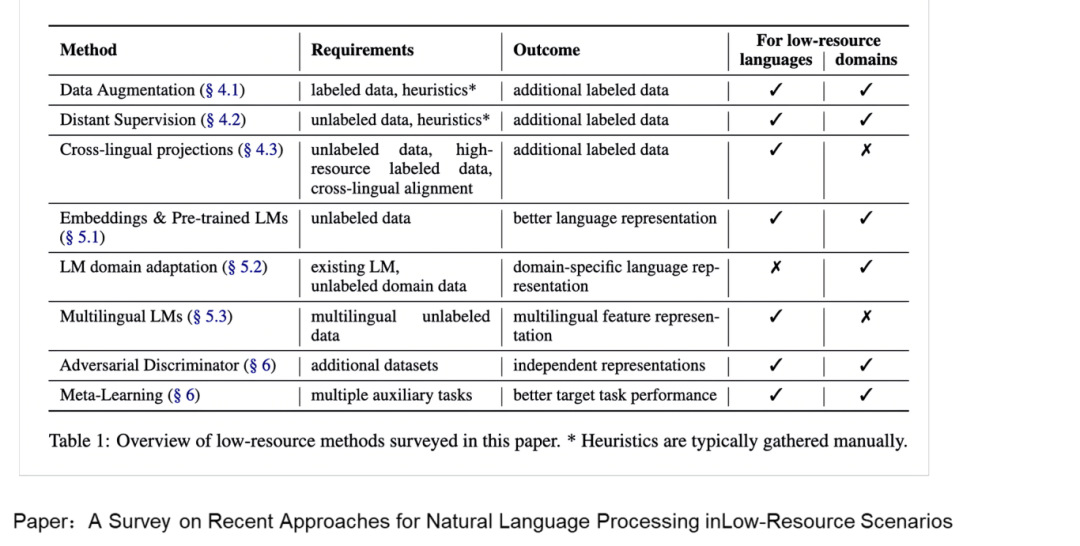
-
数据增强
-
跨语言映射
-
迁移学习。流程包括:在高资源语言数据集上训练预训练模型,学习通用特征;用少量低资源语言数据微调,使其适应该语言。
数据增强方法分类:
-
词汇级:同义词替换、同类实体替换、BERT嵌入替换等。
-
句法结构级:句子重组、删减、依存结构旋转等。
-
表示学习级:向量扰动、插值生成等。
-
任务标签级:标签控制生成、反向翻译、错误模拟等。
跨语言映射
-
使用平行语料对齐token标签
-
翻译高资源语料后进行投射标注
迁移学习
-
基于语言之间结构/语义共性
-
多语言预训练模型微调(如mBERT、XLM-R)
-
使用适配器机制(MAD-X)进一步提升迁移效率
神经机器翻译任务 低资源/零资源
问题背景:语料资源受限
神经机器翻译(NMT)在语料资源丰富的语对上表现优异,如中英翻译。但在小语种等资源匮乏的语对中,性能会显著下降。因此,如何利用有限数据提升翻译效果,成为NMT的重要研究方向。
低资源翻译(Low-resource MT)
指源语言和目标语言之间有少量双语平行语料,但可获取较多的单语语料。
面临挑战
-
双语数据规模太小,难以训练鲁棒的翻译模型
-
单语资源虽多,但如何有效利用仍是关键问题
解决策略
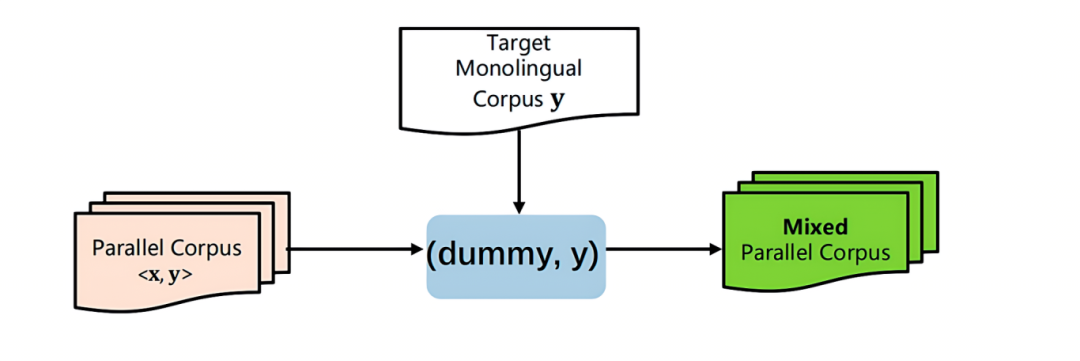
(1)构建伪平行语料(Pseudo Parallel Corpus)
方法1:将源语言对应的句子设置为空, 得到句对 (dummy,y),加入到平行语料中进行训练
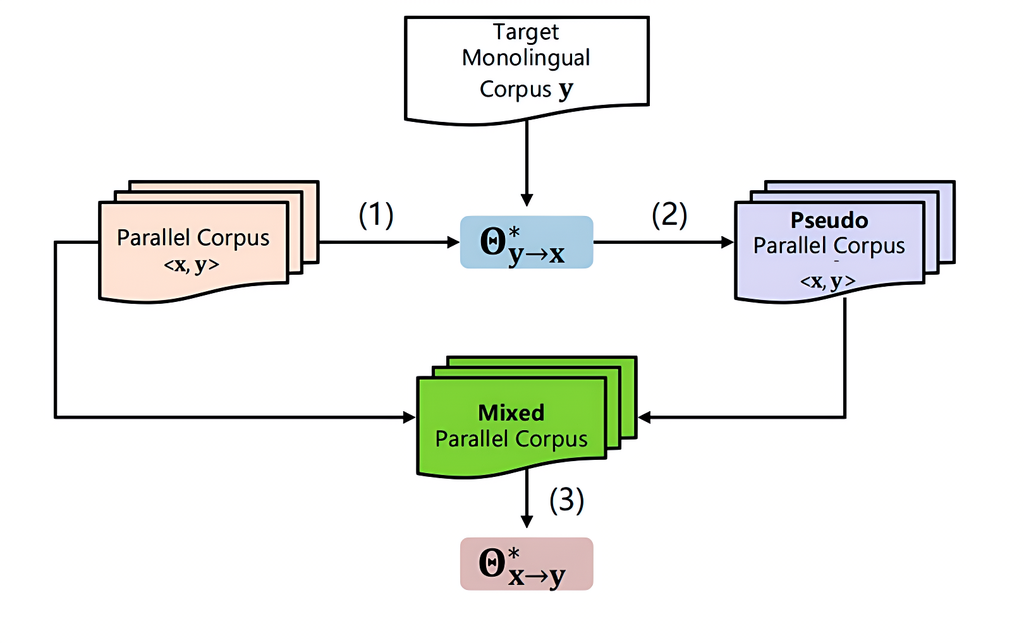
方法2:反向翻译
-
使用目标语单语数据,通过反向翻译(back-translation)生成源语句,形成伪双语对,用于增强训练集。
(2)半监督学习(Semi-supervised Learning)
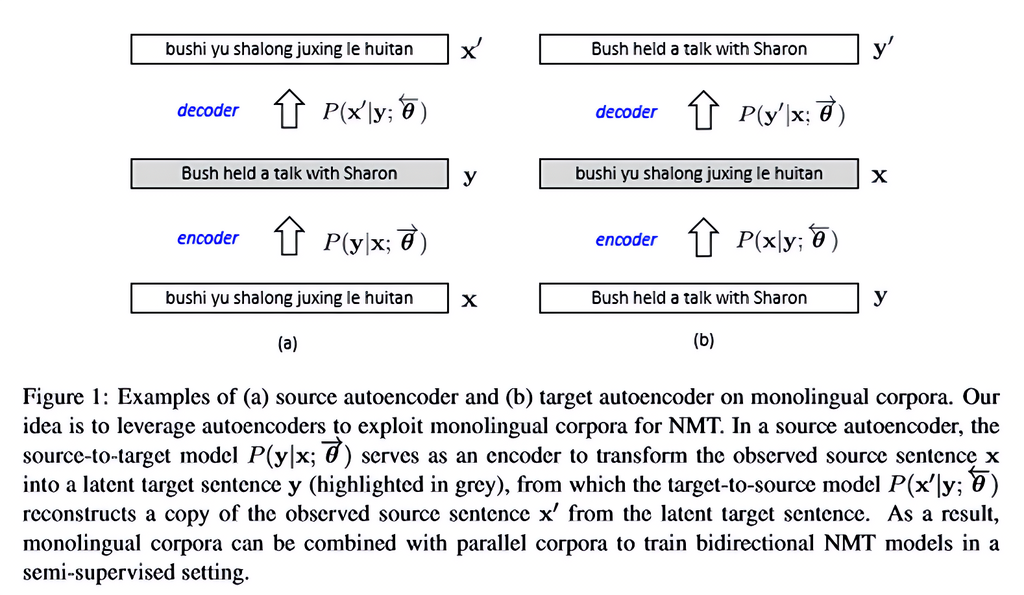
-
结合有限标注数据与大量未标注数据,通过自训练、自编码器、对抗训练等方式进行联合优化。
(3)对偶学习(Dual Learning)
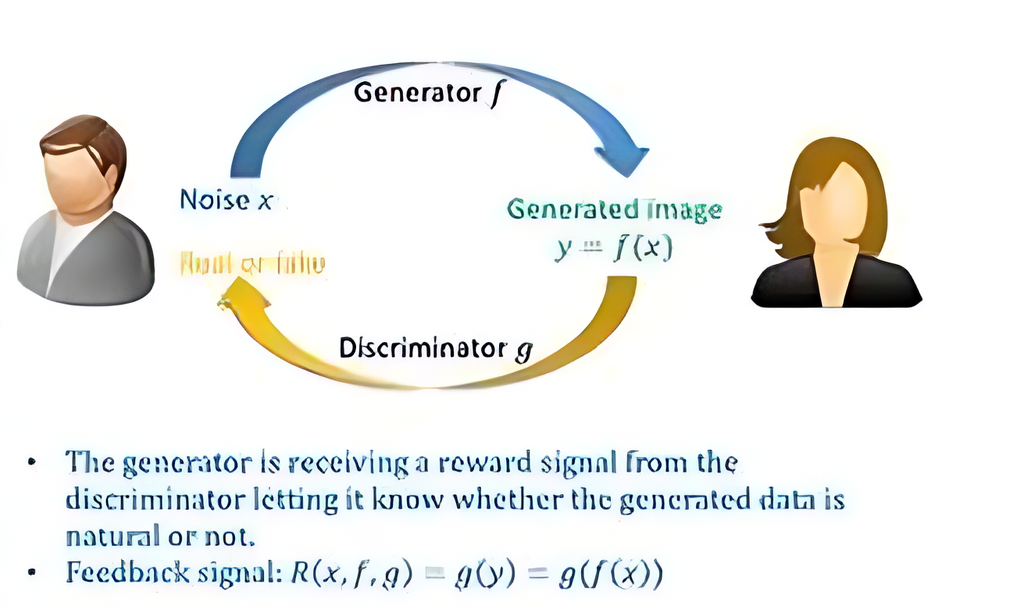
-
同时训练源→目标和目标→源两个模型,通过循环反馈机制提升模型翻译质量。
零资源翻译(Zero-resource MT)
零资源翻译任务更具挑战性,根据资源可用性又可细分为两种场景:
场景一:间接平行(存在第三语言)
特点
-
源语言和目标语言之间没有直接的平行语料
-
但源语言 ↔ 第三语言、目标语言 ↔ 第三语言之间分别有平行语料
挑战
如何利用**第三语言(Pivot Language)**搭建桥梁,实现源→目标的翻译能力迁移。
方法:教师-学生架构(Teacher-Student Framework)
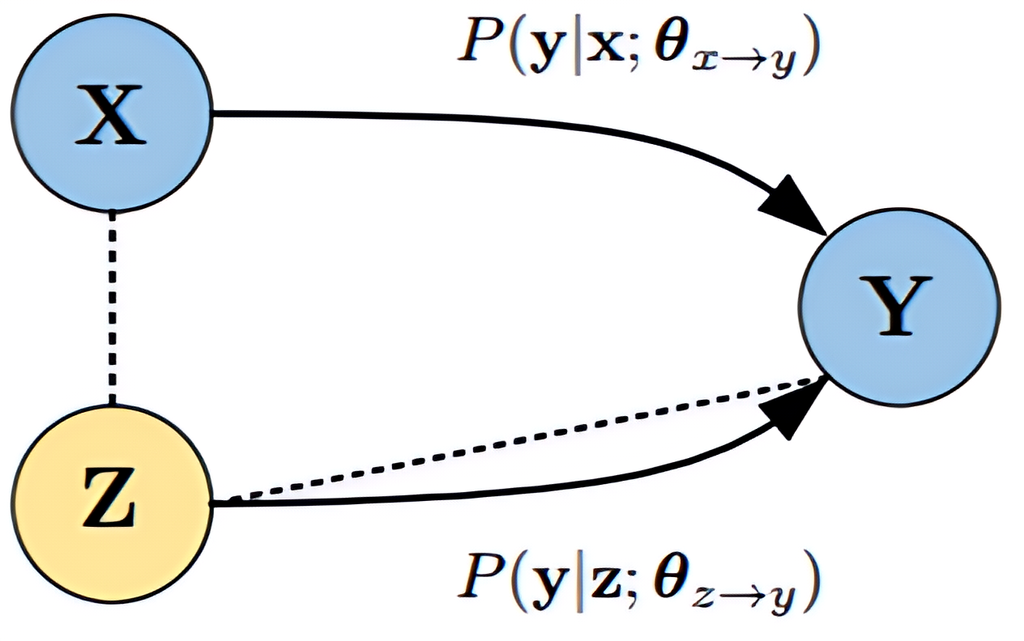
-
使用源↔第三语言、第三语言↔目标语言两个模型联合生成伪源↔目标语料
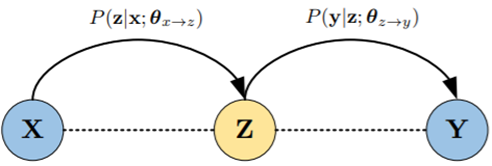
-
利用这些伪数据训练目标模型,或通过知识蒸馏提升性能
场景二:完全无平行语料
特点
-
源语言与目标语言之间没有平行语料
-
也没有与其他语言的平行语料
-
只能利用单语语料
挑战
如何在无任何翻译监督信号下建立有效的翻译系统。
解决方法
(1)多语言翻译与模型参数共享
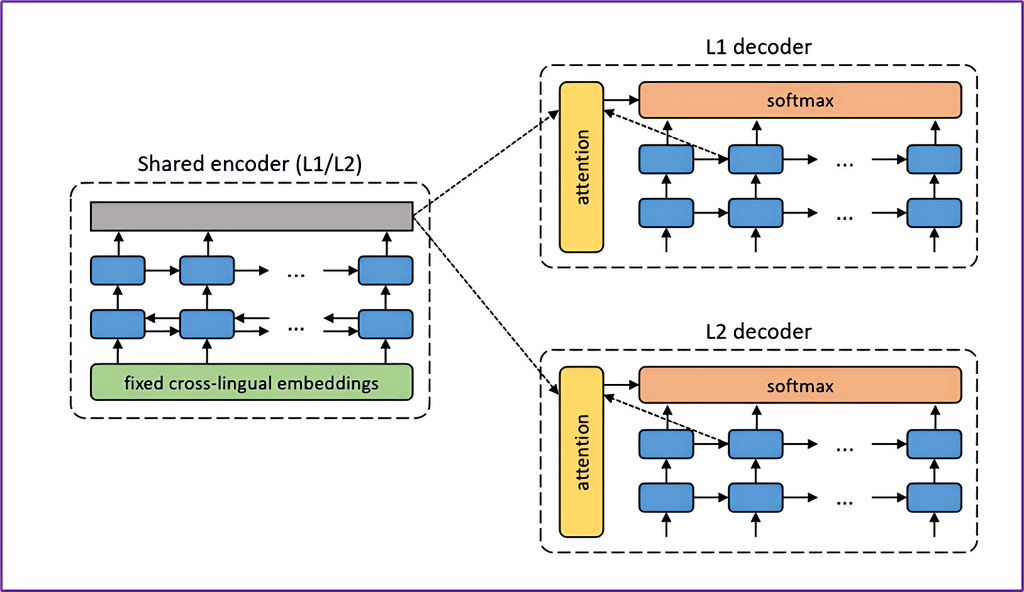
-
利用统一的编码器-解码器架构,在多语言任务中共享参数,让模型具备跨语言泛化能力。
-
常结合大规模多语预训练模型,如 mBART、mT5 等。
(2)无监督学习(Unsupervised MT)
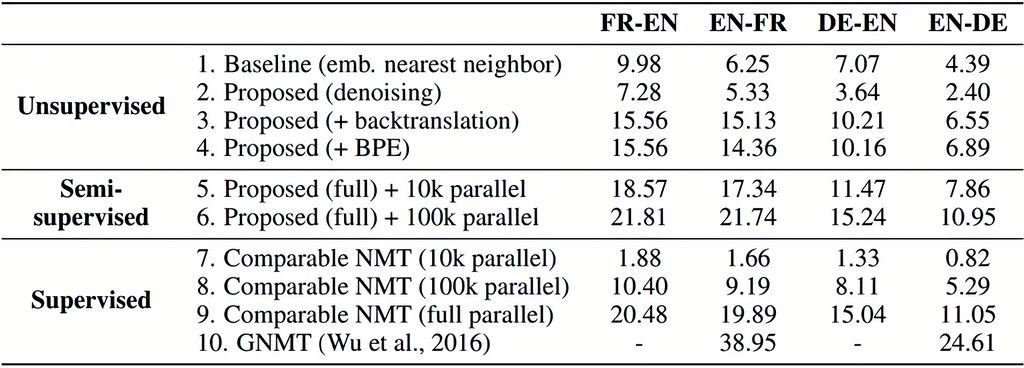
-
基于单语语料进行训练的技术路线,如循环回译(iterative back-translation)、语言模型对抗训练等。
-
关键技术包括:
-
-
词汇对齐或词典初始化
-
单语自编码训练
-
对抗语义空间对齐
-
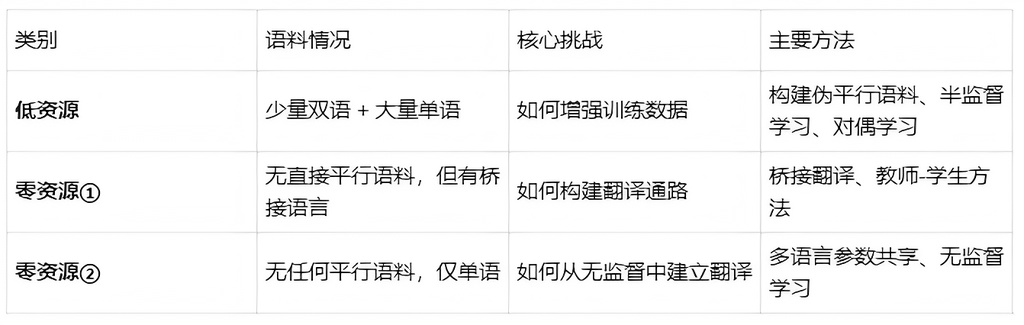
总结:资源受限条件下的主要策略一览
Part 4
机器翻译的创新思想
历史发展简述
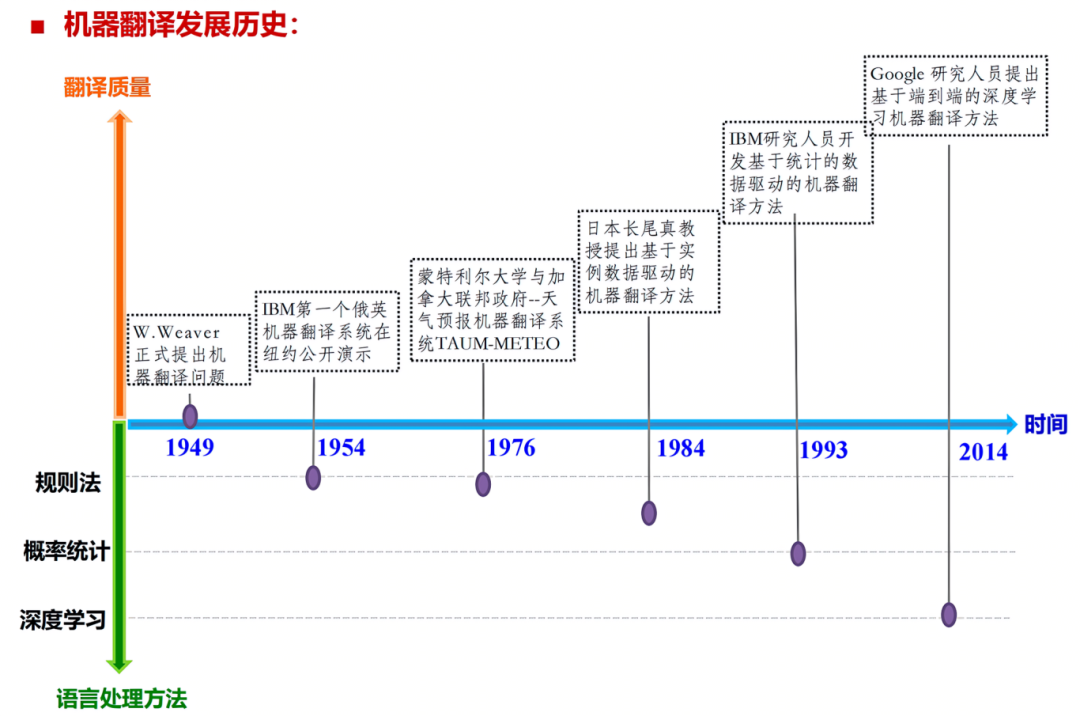
-
20世纪30年代起提出设想
-
1966年ALPAC报告否定MT可行性
-
90年代互联网催化发展
-
2013年深度学习推动神经机器翻译(NMT)
各种翻译范式
-
基于规则:依赖人工词典和语法规则

-
基于实例:检索相似句对并修改

-
统计方法(SMT):学习概率模型
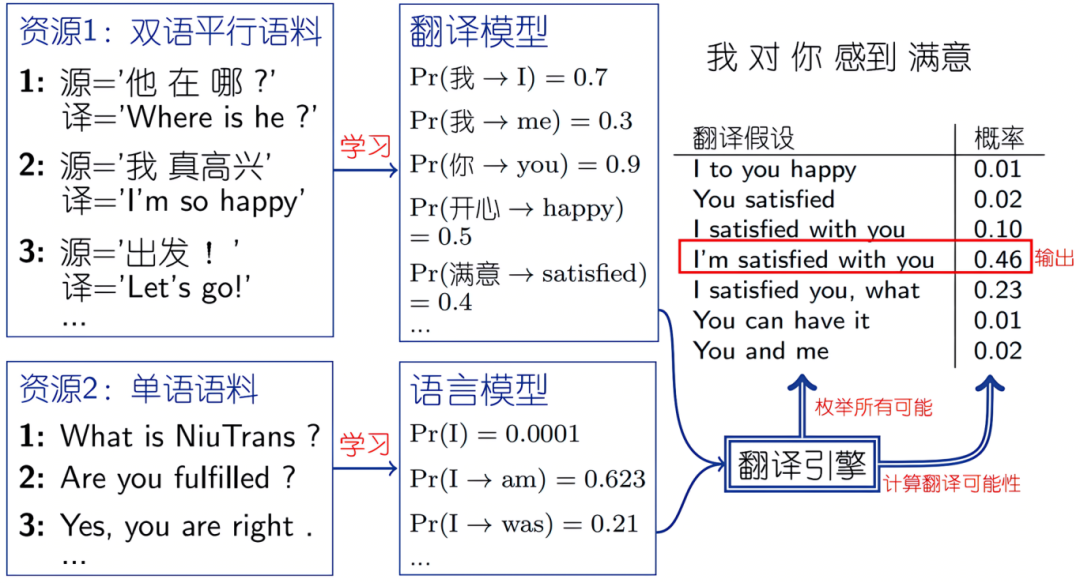
-
神经网络方法(NMT):Encoder-Decoder结构
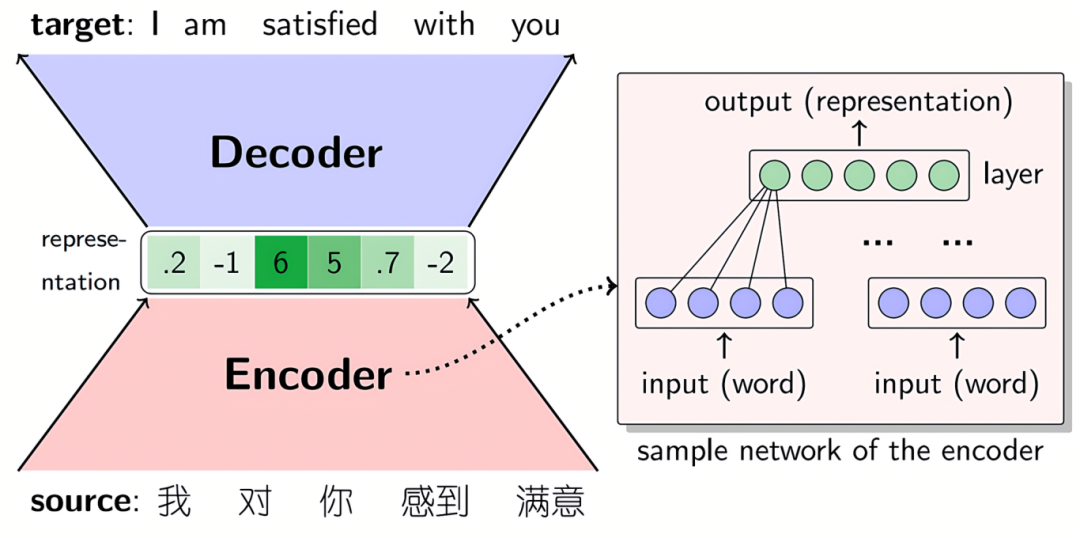
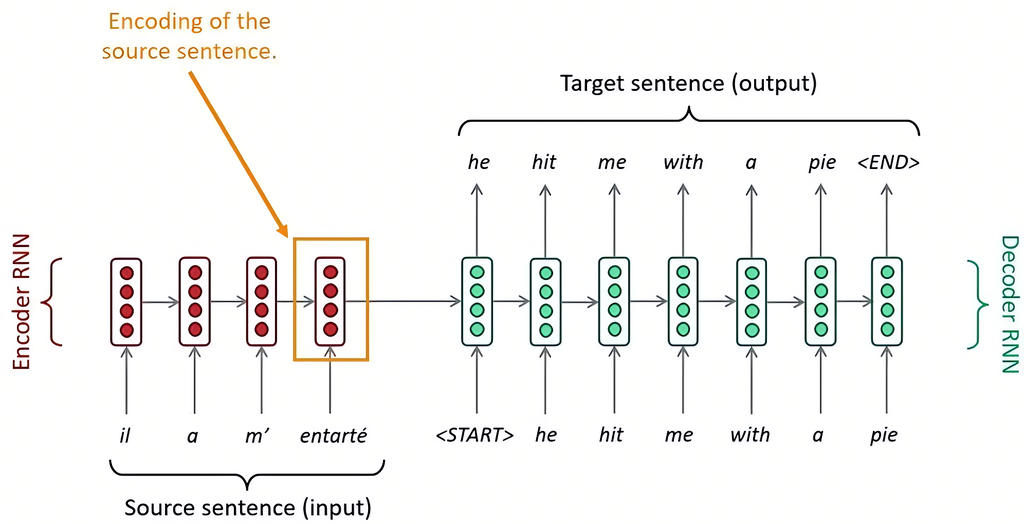
Seq2Seq的NMT,它由两个RNN组成:Encoder RNN和Decoder RNN。
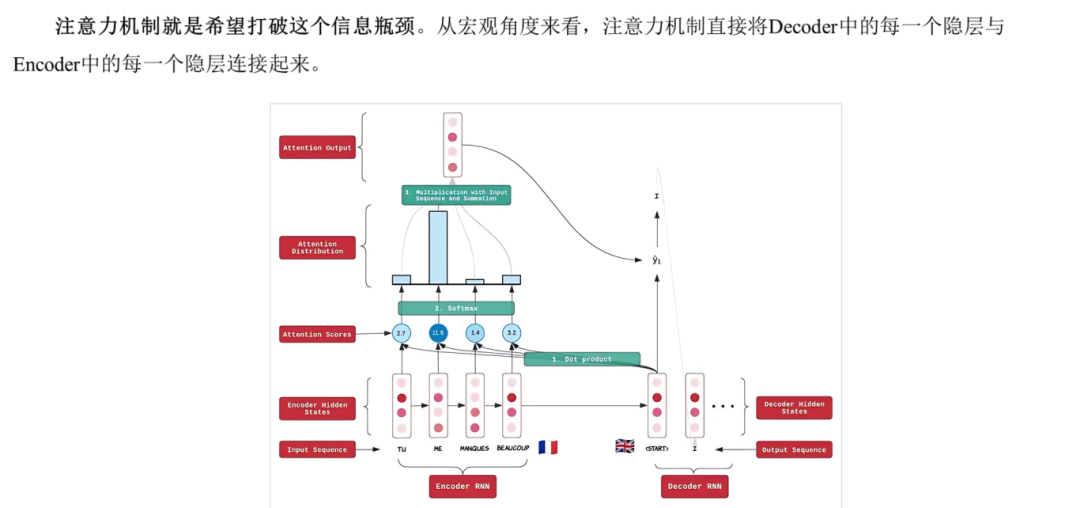
注意力机制
打破“信息瓶颈”,直接连接Decoder各时刻与Encoder全部状态。
未来趋势展望
-
多语言支持提升,低资源语言有更多突破
随着全球化发展,机器翻译将在低资源语言和方言上迎来更多突破。深度学习进步将提升对复杂语法和文化背景的处理能力,进一步增强翻译的准确性与流畅性。
-
行业定制(法律、医疗等)翻译模型
机器翻译将深入法律、医疗、金融等专业领域,通过专用语料训练,实现术语准确、内容精确的翻译效果。
-
多模态翻译(文本+语音+图像)
未来机器翻译将向多模态发展,整合文本、语音和图像,广泛应用于视频、实时语音等场景,满足跨国交流中的多样化翻译需求。

-
个性化自适应翻译
机器翻译将逐步实现自适应与个性化,基于用户反馈调整翻译风格和术语,使结果更贴合特定领域或个人需求。
-
人机协同翻译,将成主流
机器翻译将与人工翻译协同工作,机器提供初译,人工负责修订与润色,“人机结合”将成为主流,显著提升翻译效率与质量。
结语:
神经机器翻译已成为AI技术前沿的重要分支,其在全球化背景下的价值日益凸显。随着多语言模型、低资源策略和系统部署能力的持续进步,未来NMT将在跨文化沟通中发挥更广泛的作用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)