论加速人工神经网络工作的中央处理器架构
在设计用于神经网络和视频处理的处理器中,除了中央处理器核心(CPU - Central Processing Unit)之外,还有专门的处理器核心来加速许多劳动密集型任务,例如:编码和解码,数据压缩等。在 Nvidia 技术获取受限的情况下,开发者和企业被迫寻求替代解决方案,例如基于 ARM 处理器并集成核心加速器的平台,例如 RockChip、联发科、Hailo、NPC Elvis、NTC Mo
目前,比较流行的人工智能 (AI)、机器视觉和视频分析嵌入式硬件平台市面上逐步兴起。
Nvidia 技术广受欢迎,但其应用仍因国际政治局势而面临一些挑战。在 Nvidia 技术获取受限的情况下,开发者和企业被迫寻求替代解决方案,例如基于 ARM 处理器并集成核心加速器的平台,例如 RockChip、联发科、Hailo、NPC Elvis、NTC Module 和 LinQ 等公司的产品。
每种替代方案都有其优点和缺点,因此选择取决于性能要求、成本、功耗和应用细节。
CPU、GPU、TPU、NPU
现代处理器的架构属于“单晶系统”(SoC),将计算系统的多个组件集成在一个晶体上。这可以减少单个微电路的数量,使设备更紧凑,能耗更低。
在设计用于神经网络和视频处理的处理器中,除了中央处理器核心(CPU - Central Processing Unit)之外,还有专门的处理器核心来加速许多劳动密集型任务,例如:编码和解码,数据压缩等。这些专用核心包括GPU,TPU和NPU - 这三种类型的处理器架构最适合执行与图形信息处理,神经网络加速和机器学习相关的并行计算领域的各种任务。
CPU(中央处理器)。经典处理器能够快速执行单个线程,从而缩短单次操作的执行时间并增加连续指令的数量。CPU 的目的是快速处理包括数据提取在内的操作,并减少算术逻辑单元 (ALU) 等待上一条指令完成时的流水线停止时间。CPU 能够以低延迟处理连续指令(图 1a)。多任务处理是通过多个核心(CPU Core)实现的,但所有数据仍然在每个核心上的单个线程中分别处理。
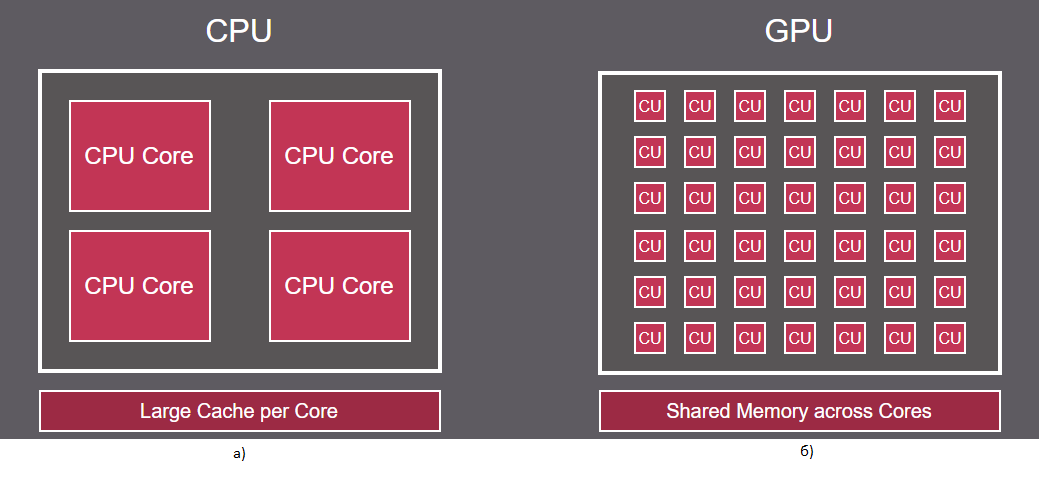
图 1 CPU 和 GPU 处理器架构
需要注意的是,经典的中央处理器(CPU)也可以通过组合成处理器集群来用作神经网络加速器,从而加速向量和数字数组的运算。
GPU(图形处理单元)图形处理器最初是为了加速图形处理和图像渲染而开发的。该架构包含多个能够执行并行计算的核心(图 1b),这使得 GPU 成为并行处理大型数据集的理想选择,而这正是图形应用程序和机器学习任务所必需的。
GPU 处理器可以包含数千个简单核心(计算单元 - CU),这使得它们能够处理大数据流。高水平的并行性使 GPU 处理器能够有效地处理可分解为许多小子任务的任务,例如图像处理、推理和神经网络训练。
TPU(张量处理单元)张量处理单元是另一种专门用于加速和训练神经网络的处理器。
TPU 使用脉动阵列来快速执行高性能矩阵乘法和加法运算。
与通用中央处理器 (CPU) 或图形处理单元 (GPU) 不同,TPU 旨在加速 AI 任务和工作负载,例如由标量、矢量和张量数学组成的神经网络层的操作。
NPU(神经处理单元)神经处理器是一种专用硬件加速器,其架构模拟人脑的神经网络。NPU 和 TPU 在用途和工作原理上非常相似。NPU通常被用作神经网络加速器的统称。
举例来说,图2展示了某国产处理器制造商的TPU核心结构。如图2所示,TPU设计有多个计算核心,每个核心称为NPU。TPU基于单指令多数据(SIMD)架构,采用多核设计。它由BDC(广播数据控制器)和GDMA(全局直接内存访问)组成。
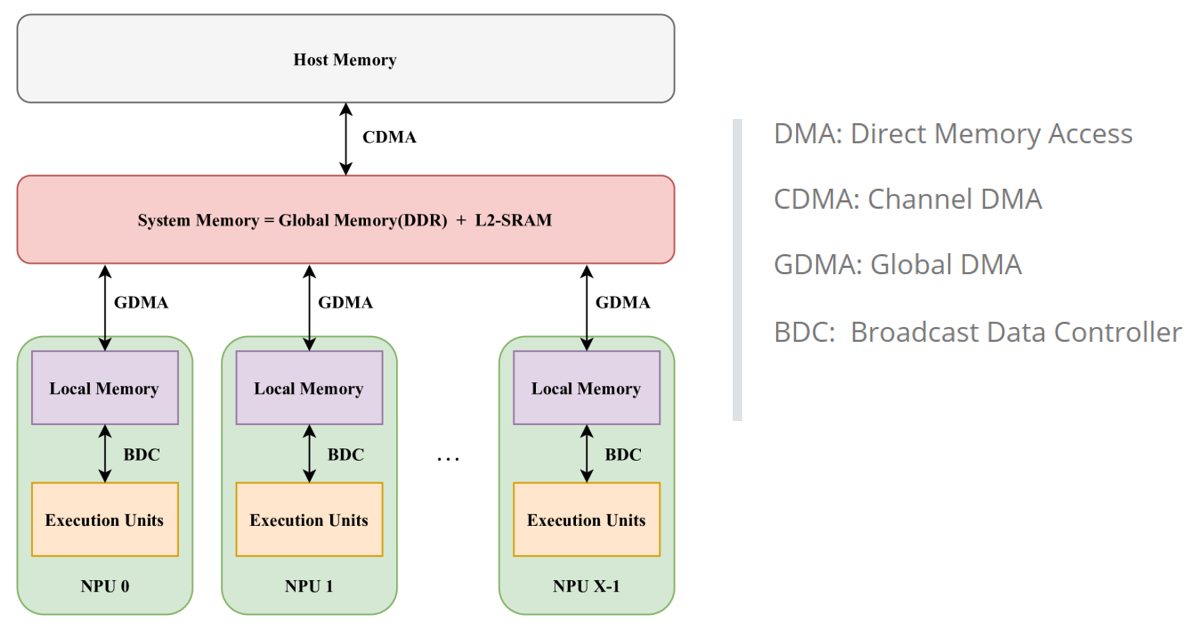
图 2 TPU 处理器架构
在该架构中,TPU采用SIMD原理进行计算,即在任何给定时间,所有NPU都执行相同的计算指令,但每个NPU处理不同的数据。
TPU 在大规模深度学习任务上表现出色,特别是在需要高吞吐量和低延迟的场景下。
NPU/TPU 内核通常与中央处理单元 (CPU) 一起使用,以提供额外的计算能力。
集成 NPU/TPU 加速器的国产处理器。
许多国产制造商的处理器可被视为神经网络处理、视频分析和计算机视觉领域设备中英伟达的替代品,瑞芯微(RockChip)的处理器尤为突出。
RockChip 是一家国产处理器制造商,为嵌入式系统、移动设备和物联网解决方案提供广泛的芯片。他们的部分型号(例如 RK3568、RK3576、RK3588)配备了 NPU,以加速 AI 任务。
在瑞芯微 (RockChip) 处理器中,RK3588 脱颖而出。基于这款 CPU 的模块有望成为 Nvidia Jetson 平台的有力替代品,尤其是在人工智能和视频处理相关任务方面。
为了方便在 Rockchip 硬件平台上进行模型的性能评估、部署和执行,Rockchip 提供了一套工具和库RKNN Toolkit2 – Rockchip 神经网络(图 3)。RKNN 软件栈可帮助用户在 Rockchip 芯片上快速部署 AI 模型。
借助RKNN Toolkit2 ,可以将 Caffe、TensorFlow、TFLite ONNX、Darknet、Pytorch 模型转换为 RKNN 模型,并在 Rockchip NPU 平台上加载使用,充分利用 Rockchip NPU(神经处理单元)的硬件加速能力。
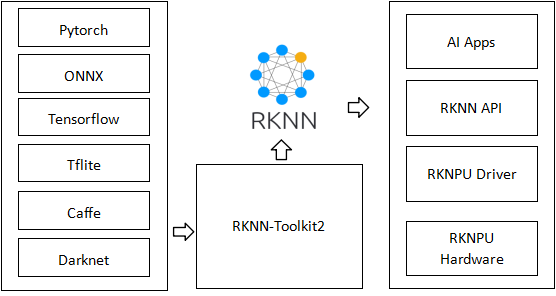
图3 RKNN Toolkit2 总体结构

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)