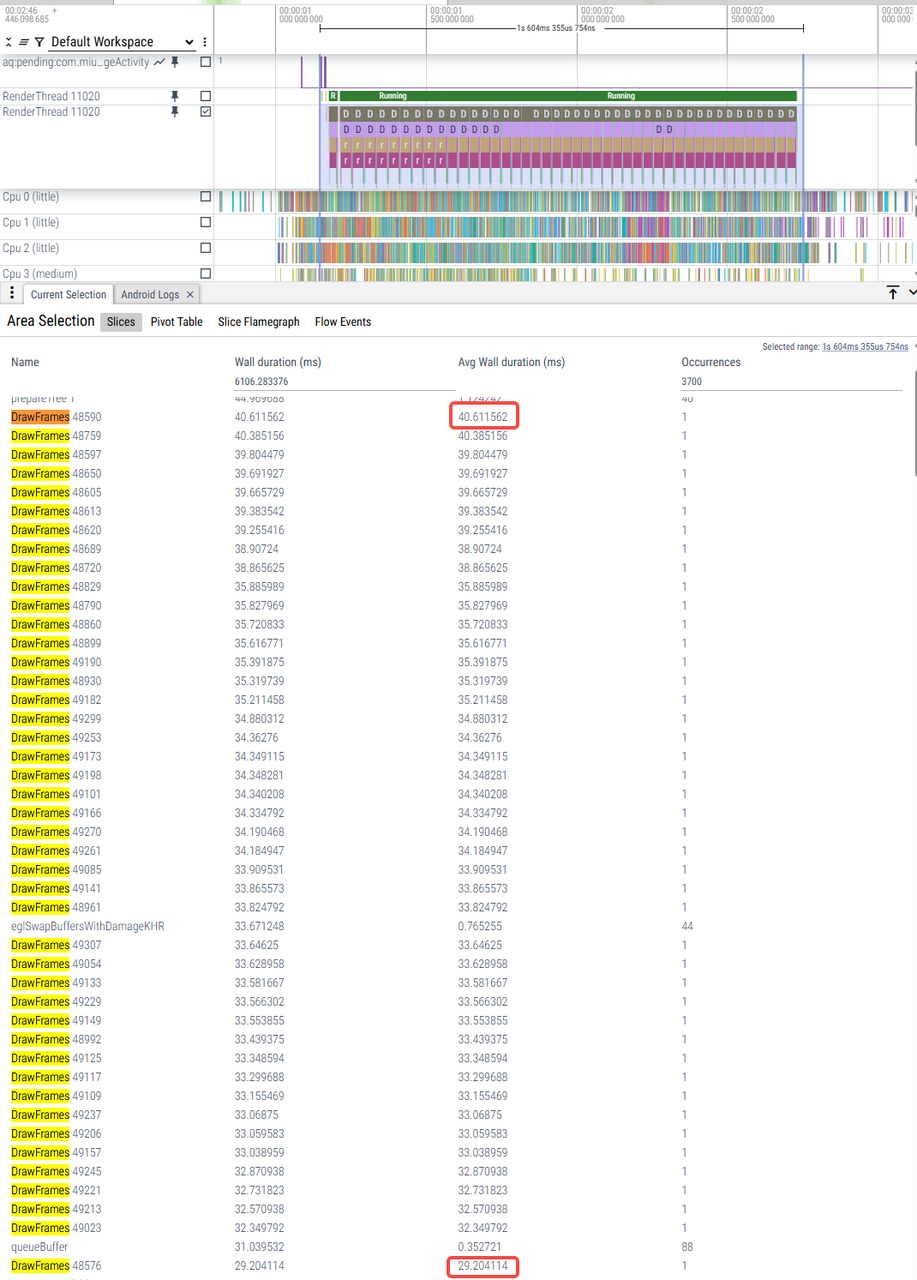
纹理频繁绘制导致相册年视图卡顿
onCombineIfPossible返回kMayChain的话,这之前的判断看起来不复杂,每次onCombineIfPossible的耗时是?4.卡顿原因分析:主要导致耗时的是每次addDrawOp下面会有11次TextureOpImpl::onCombineIfPossible,年视图每一张缩略图都是一个TextureOp,onCombineIfPossible次数太多导致renderFram
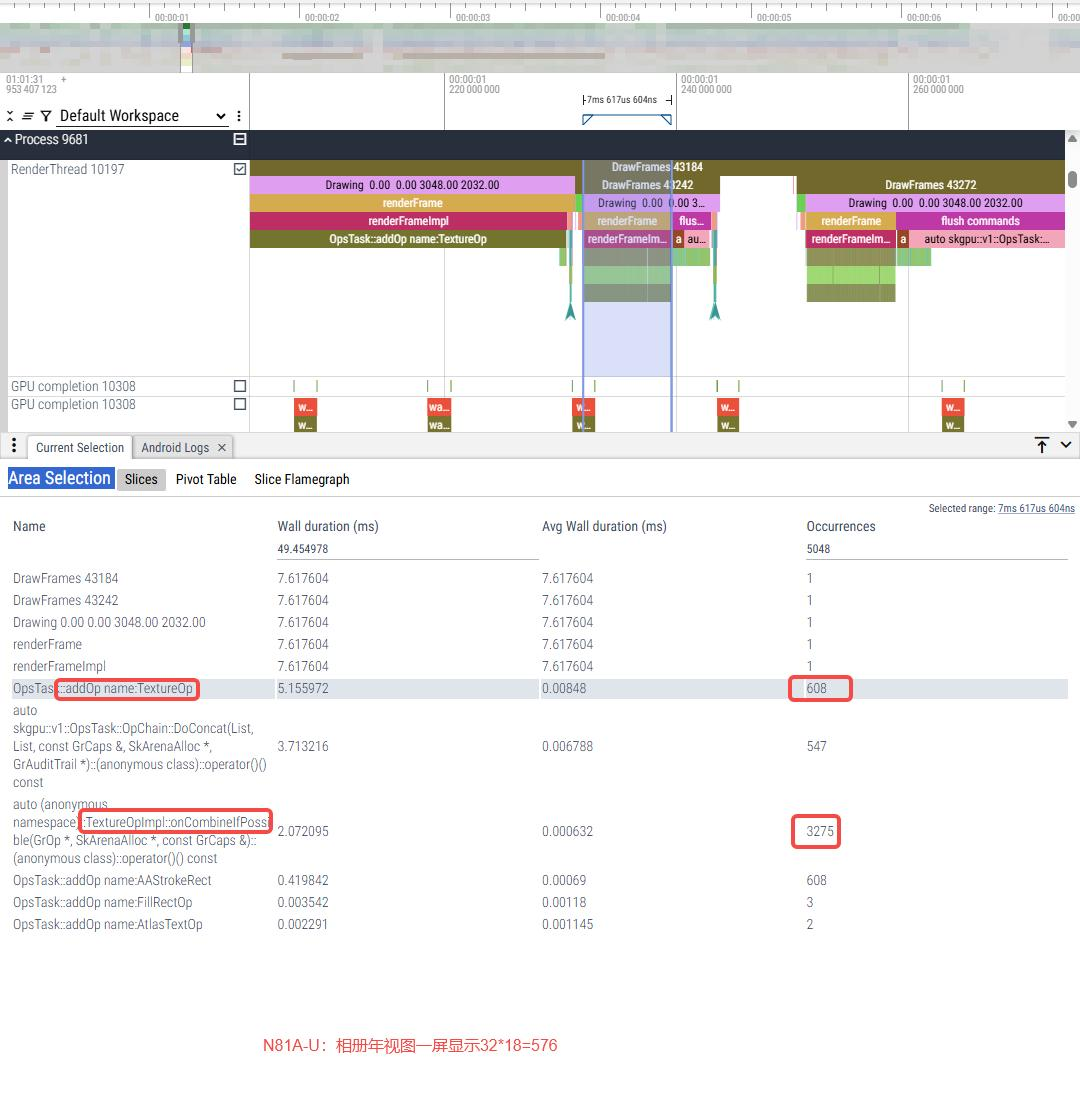
1、问题:系统在处理大量相似的纹理绘制操作,CombineResult onCombineIfPossible被大量调用。
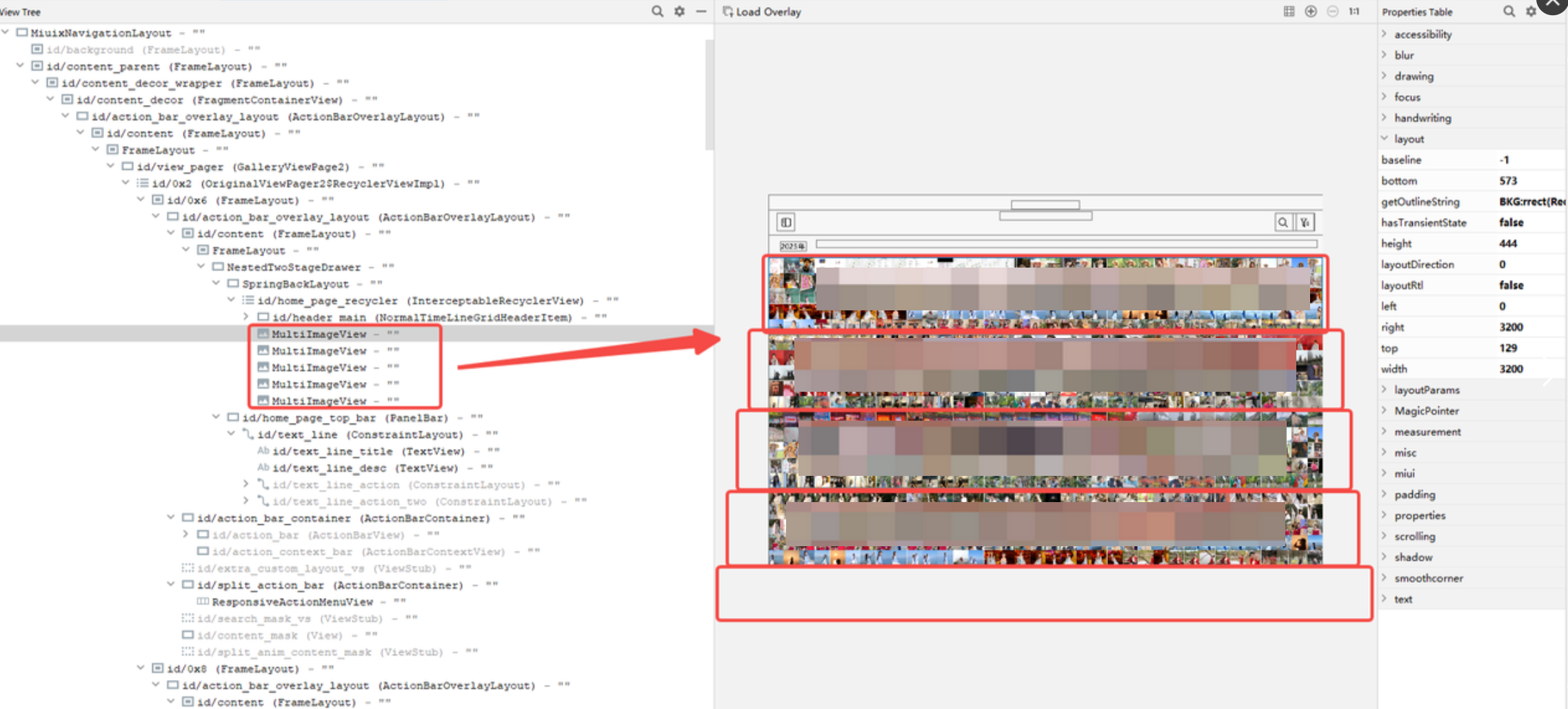
2.相册年视图布局:年视图(收起左侧列表)下,列表InterceptableRecyclerView中图片部分由5个MultiImageView组成,每个MultiImageView包含180张图片(36*5),对应trace中会有180次addDrawOp(TextureOp)。
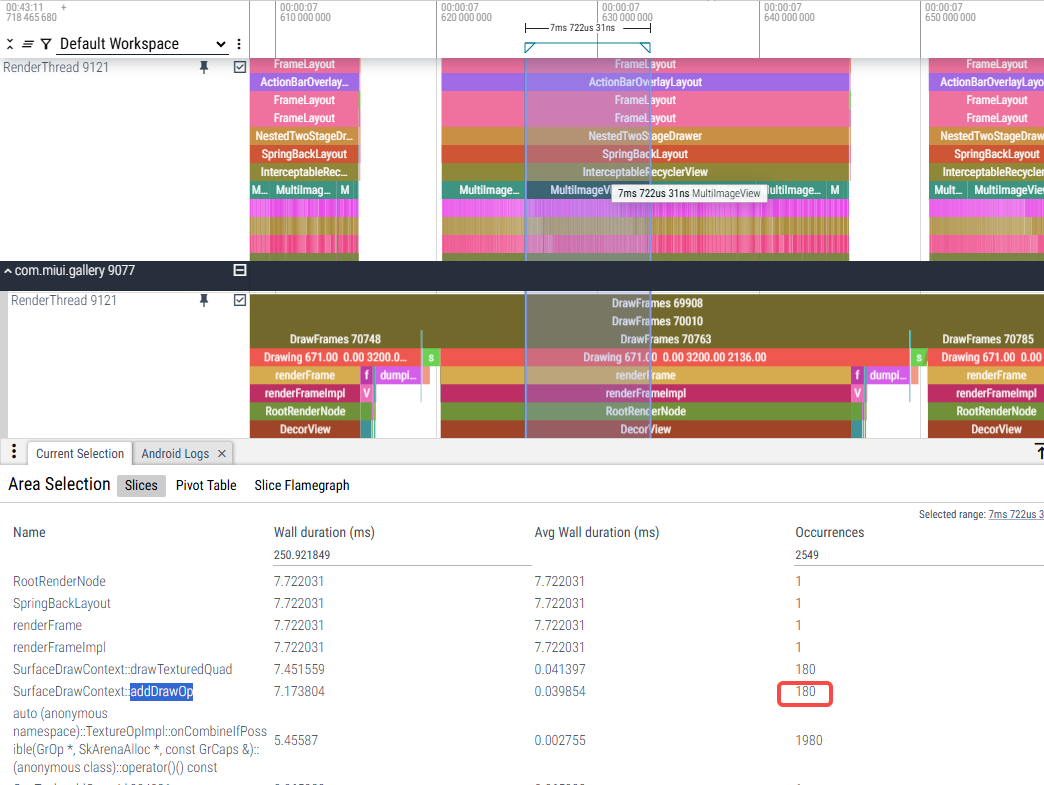
而主要导致耗时的是每次addDrawOp下面会有11次TextureOpImpl::onCombineIfPossible。
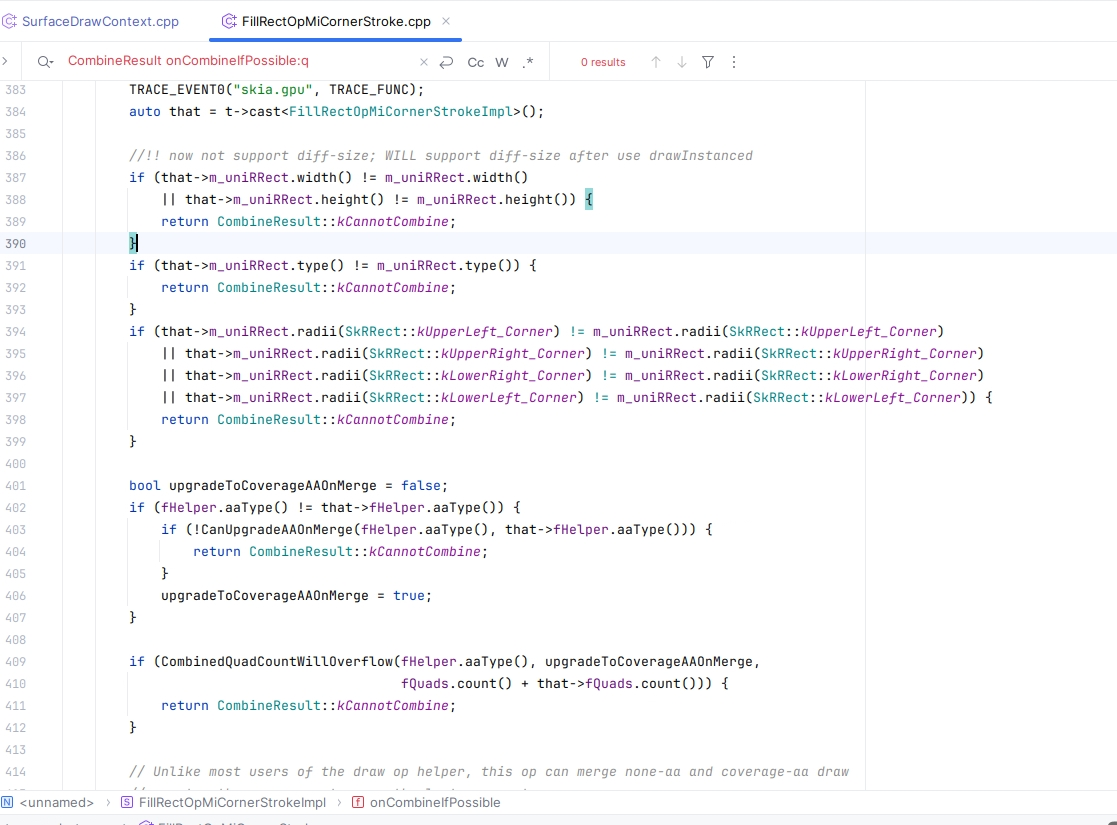
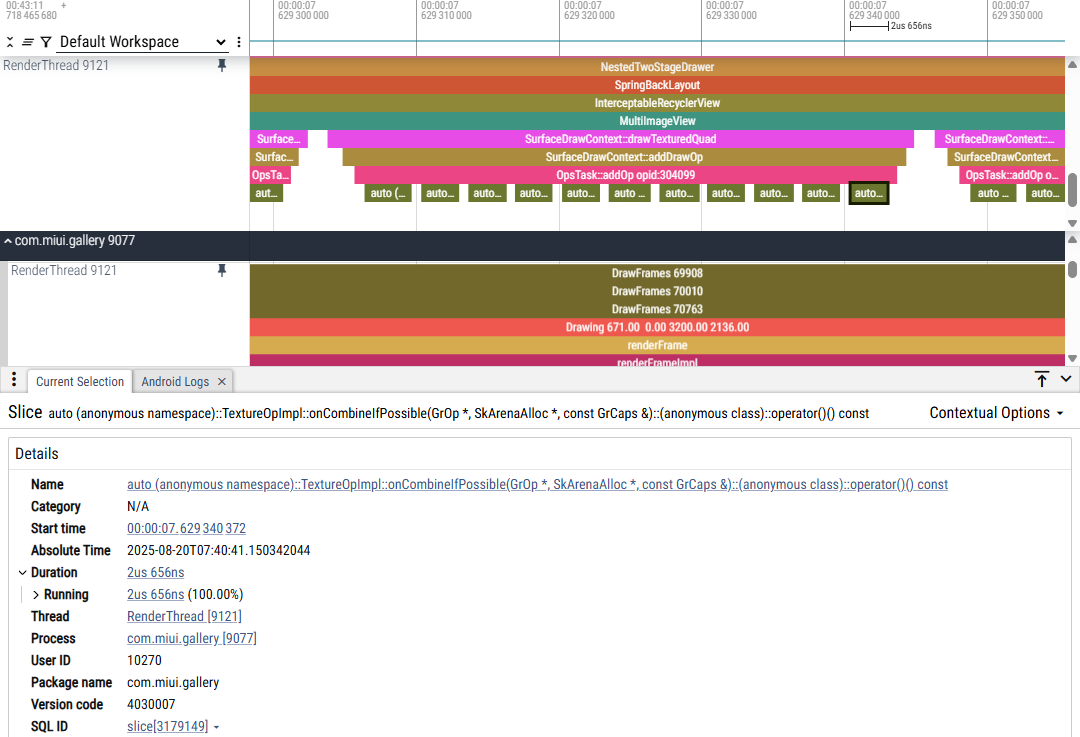
3.相关调用栈:
// src/gpu/ganesh/Device_drawTexture.cpp
Device::drawImageQuadDirect
Device::drawEdgeAAImage
draw_texture
// src/gpu/ganesh/SurfaceDrawContext.cpp
SurfaceDrawContext::drawTexture SurfaceDrawContext::drawTexturedQuad
SurfaceDrawContext::addDrawOp
// src/gpu/ganesh/ops/OpsTask.cpp
OpsTask::addDrawOp
OpsTask::recordOp OpsTask::OpChain::appendOp (return nullptr) OpsTask::OpChain::tryConcat (return false)
OpsTask::OpChain::DoConcat
// src/gpu/ganesh/ops/GrOp.cpp
GrOp::combineIfPossible
// src/gpu/ganesh/ops/TextureOp.cpp
TextureOpImpl::onCombineIfPossible
4.卡顿原因分析:主要导致耗时的是每次addDrawOp下面会有11次TextureOpImpl::onCombineIfPossible,年视图每一张缩略图都是一个TextureOp,onCombineIfPossible次数太多导致renderFrameImpl耗时。
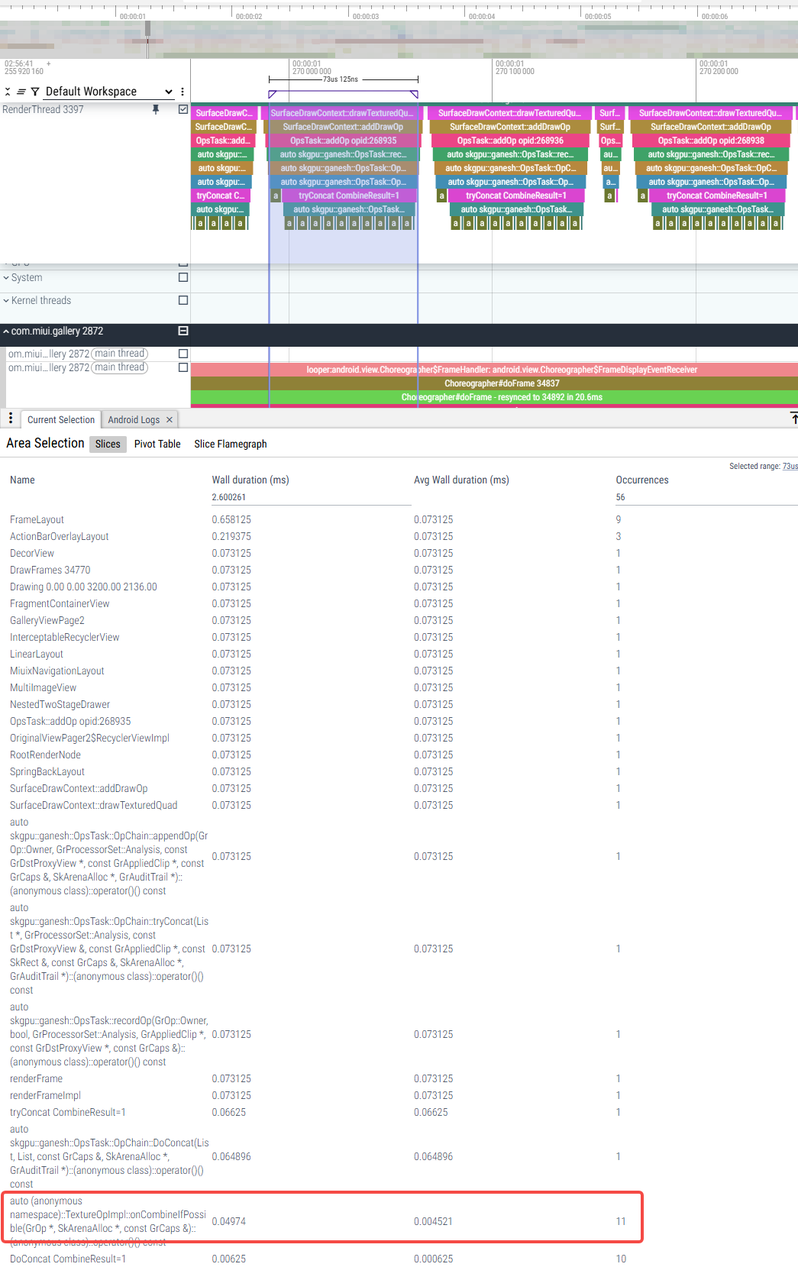
这11次onCombineIfPossible的相关代码逻辑在OpsTask::OpChain::tryConcat 、OpsTask::OpChain::DoConcat中,tryConcat 中调用combineIfPossible回调到TextureOpImpl::onCombineIfPossible,onCombineIfPossible相关逻辑判断返回CombineResult::kMayChain,这是第一次调用onCombineIfPossible;接着tryConcat switch判断CombineResult返回值,如果是CombineResult::kMayChain,则会调用DoConcat,而DoConcat中将chainB(新增op)与chainA(fList)从尾部到头部的顺序进行合并检查,这边也是调用onCombineIfPossible做合并检查,不合并的次数累计10次后,则退出循环,所以DoConcat中会有10次onCombineIfPossible调用。
// external/skia/src/gpu/ganesh/ops/OpsTask.cpp
bool OpsTask::OpChain::tryConcat(
List* list, GrProcessorSet::Analysis processorAnalysis, const GrDstProxyView& dstProxyView,
const GrAppliedClip* appliedClip, const SkRect& bounds, const GrCaps& caps,
SkArenaAlloc* opsTaskArena, GrAuditTrail* auditTrail) {
...
do {
// 第一次调用combineIfPossible
auto result = fList.tail()->combineIfPossible(list->head(), opsTaskArena, caps);
// ATRACE_ANDROID_FRAMEWORK_ALWAYS("tryConcat CombineResult=%d", result);
switch (result)
{
case GrOp::CombineResult::kCannotCombine:
// If an op supports chaining then it is required that chaining is transitive and
// that if any two ops in two different chains can merge then the two chains
// may also be chained together. Thus, we should only hit this on the first
// iteration.
SkASSERT(first);
return false;
case GrOp::CombineResult::kMayChain:
// CombineResult返回值为kMayChain,接着调用DoConcat
fList = DoConcat(std::move(fList), std::exchange(*list, List()), caps, opsTaskArena,
auditTrail);
// The above exchange cleared out 'list'. The list needs to be empty now for the
// loop to terminate.
SkASSERT(list->empty());
break;
case GrOp::CombineResult::kMerged: {
GrOP_INFO("\t\t: (%s opID: %u) -> Combining with (%s, opID: %u)\n",
list->tail()->name(), list->tail()->uniqueID(), list->head()->name(),
list->head()->uniqueID());
GR_AUDIT_TRAIL_OPS_RESULT_COMBINED(auditTrail, fList.tail(), list->head());
// The GrOp::Owner releases the op.
list->popHead();
break;
}
}
SkDEBUGCODE(first = false);
} while (!list->empty());
// The new ops were successfully merged and/or chained onto our own.
fBounds.joinPossiblyEmptyRect(bounds);
return true;
}
OpsTask::OpChain::List OpsTask::OpChain::DoConcat(List chainA, List chainB, const GrCaps& caps,
SkArenaAlloc* opsTaskArena,
GrAuditTrail* auditTrail) {
...
//获取chainA(fList)尾部节点
GrOp* origATail = chainA.tail();
SkRect skipBounds = SkRectPriv::MakeLargestInverted();
do {
...
GrOp* a = origATail;
// 从chainA(fList)尾部开始遍历
while (a) {
bool canForwardMerge =
(a == chainA.tail()) || can_reorder(a->bounds(), forwardMergeBounds);
if (canForwardMerge || canBackwardMerge) {
// 调用combineIfPossible方法 判断执行op合并
auto result = a->combineIfPossible(chainB.head(), opsTaskArena, caps);
// ATRACE_ANDROID_FRAMEWORK_ALWAYS("DoConcat CombineResult=%d", result);
SkASSERT(result != GrOp::CombineResult::kCannotCombine);
// 返回值为kMerged,则合并op
merged = (result == GrOp::CombineResult::kMerged);
}
if (merged) {
...
break;
} else {
// merged==false 10次后退出chainA循环
if (++numMergeChecks == kMaxOpMergeDistance) {
break;
}
forwardMergeBounds.joinNonEmptyArg(a->bounds());
canBackwardMerge =
canBackwardMerge && can_reorder(chainB.head()->bounds(), a->bounds());
// 获取链表上一个节点
a = a->prevInChain();
}
}
// If we weren't able to merge b's head then pop b's head from chain b and make it the new
// tail of a.
if (!merged) {
// 如果退出循环后,merged为false,则直接将chainB头部链接到chainA的尾部
chainA.pushTail(chainB.popHead());
skipBounds.joinNonEmptyArg(chainA.tail()->bounds());
}
} while (!chainB.empty());
return chainA;
}
// external/skia/src/gpu/ganesh/ops/GrOp.cpp
GrOp::CombineResult GrOp::combineIfPossible(GrOp* that, SkArenaAlloc* alloc, const GrCaps& caps) {
SkASSERT(this != that);
if (this->classID() != that->classID()) {
return CombineResult::kCannotCombine;
}
auto result = this->onCombineIfPossible(that, alloc, caps);
if (result == CombineResult::kMerged) {
this->joinBounds(*that);
}
return result;
}
// external/skia/src/gpu/ganesh/ops/TextureOp.cpp
CombineResult onCombineIfPossible(GrOp* t, SkArenaAlloc*, const GrCaps& caps) override {
TRACE_EVENT0("skia.gpu", TRACE_FUNC);
auto that = t->cast<TextureOpImpl>();
...
const auto* thisProxy = fViewCountPairs[0].fProxy.get();
const auto* thatProxy = that->fViewCountPairs[0].fProxy.get();
if (fMetadata.fProxyCount > 1 || that->fMetadata.fProxyCount > 1 ||
thisProxy != thatProxy) {
// We can't merge across different proxies. Check if 'this' can be chained with 'that'.
if (GrTextureProxy::ProxiesAreCompatibleAsDynamicState(thisProxy, thatProxy) &&
caps.dynamicStateArrayGeometryProcessorTextureSupport() &&
fMetadata.aaType() == that->fMetadata.aaType()) {
// We only allow chaining when the aaTypes match bc otherwise the AA type
// reported by the chain can be inconsistent. That is, since chaining doesn't
// propagate revised AA information throughout the chain, the head of the chain
// could have an AA setting of kNone while the chain as a whole could have a
// setting of kCoverage. This inconsistency would then interfere with the validity
// of the CombinedQuadCountWillOverflow calls.
// This problem doesn't occur w/ merging bc we do propagate the AA information
// (in propagateCoverageAAThroughoutChain) below.
return CombineResult::kMayChain;
}
return CombineResult::kCannotCombine;
}
...
return CombineResult::kMerged;
}从上面代码流程上看,导致每次addOp中出现多次onCombineIfPossible的主要原因是进入return CombineResult::kMayChain这块判断条件里,本地临时将此处返回值改为kCannotCombine后,年视图滑动卡顿优化很多,此处修改减少了renderFrameImpl阶段的耗时,但是增加了flush commands阶段耗时,flush commands会遍历所有添加的TextureOp会走prepare和execute。
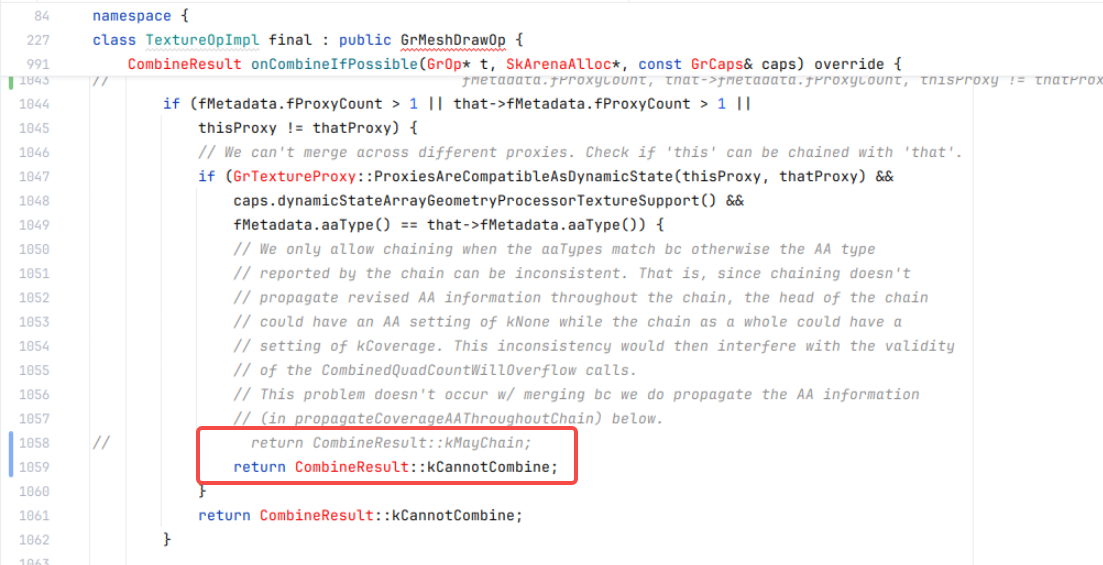
修改前:
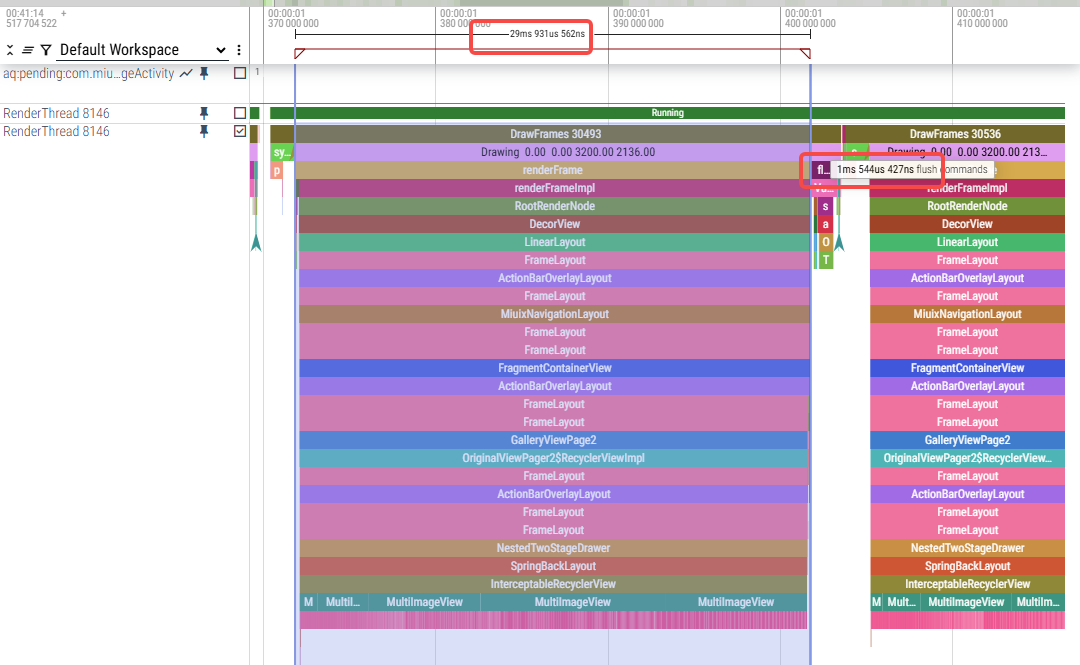
修改后:
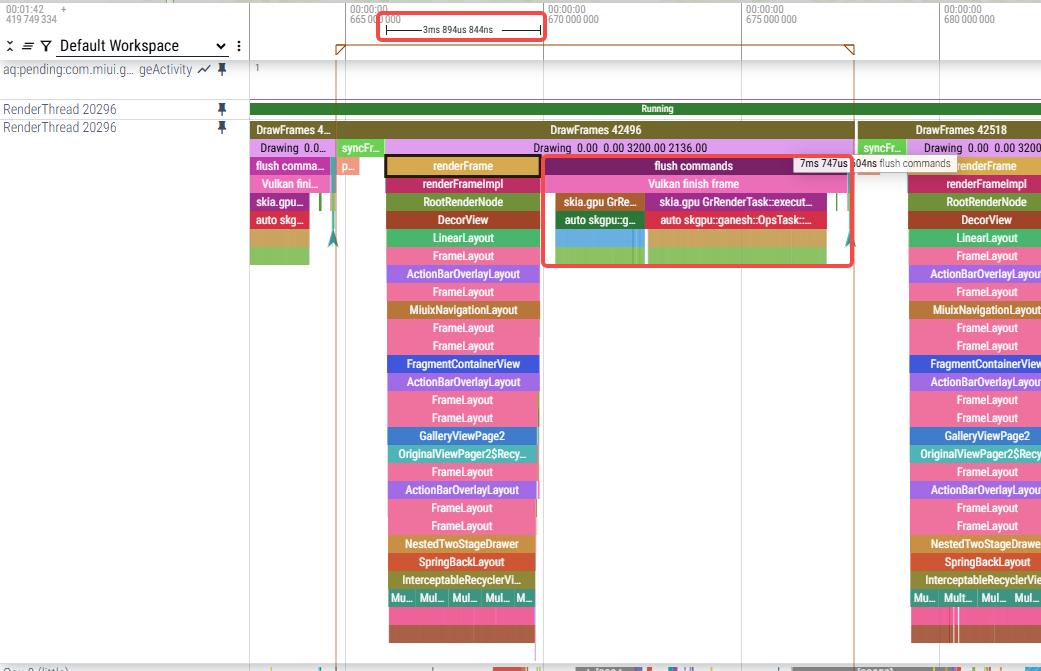
5.临时方案验证
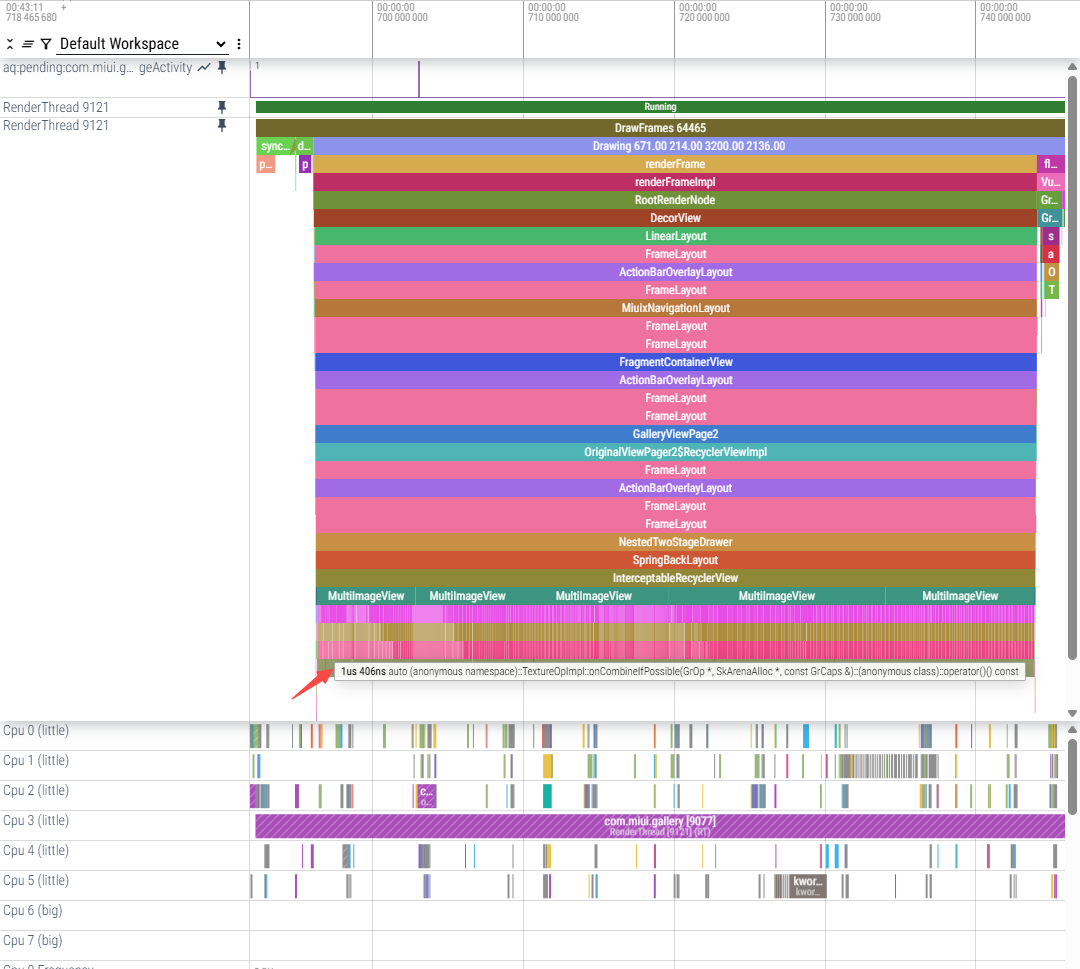
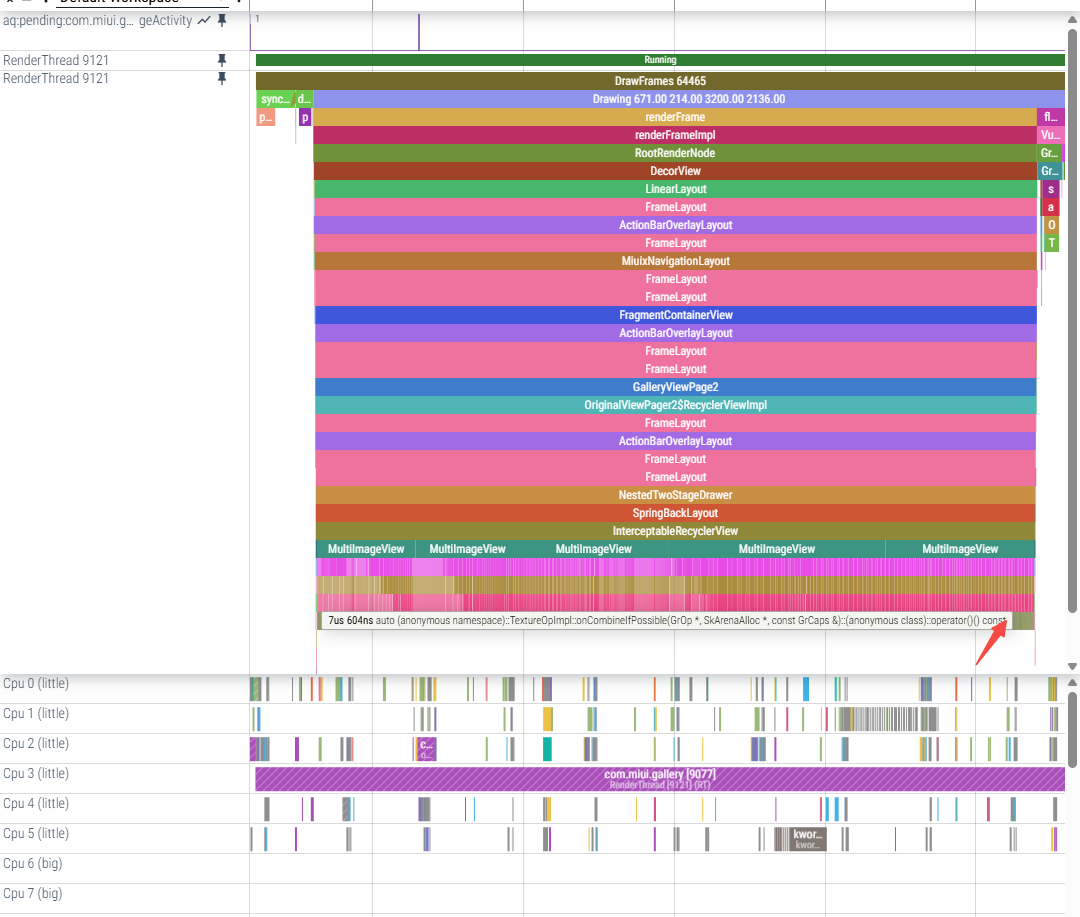
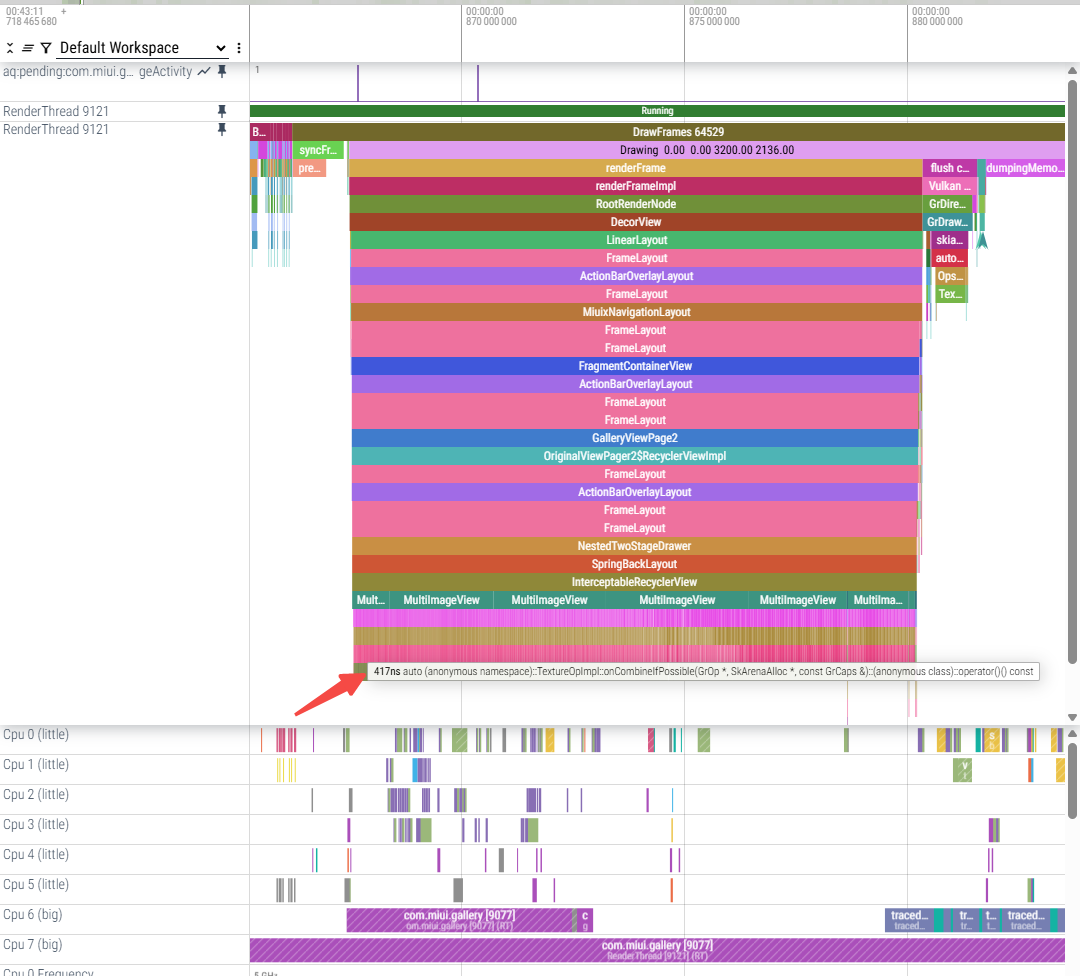
(1)单次onCombineIfPossible耗时,耗时逐渐增加:
a.跑小核每次约1us~8us
b.跑大核每次约400ns~1us
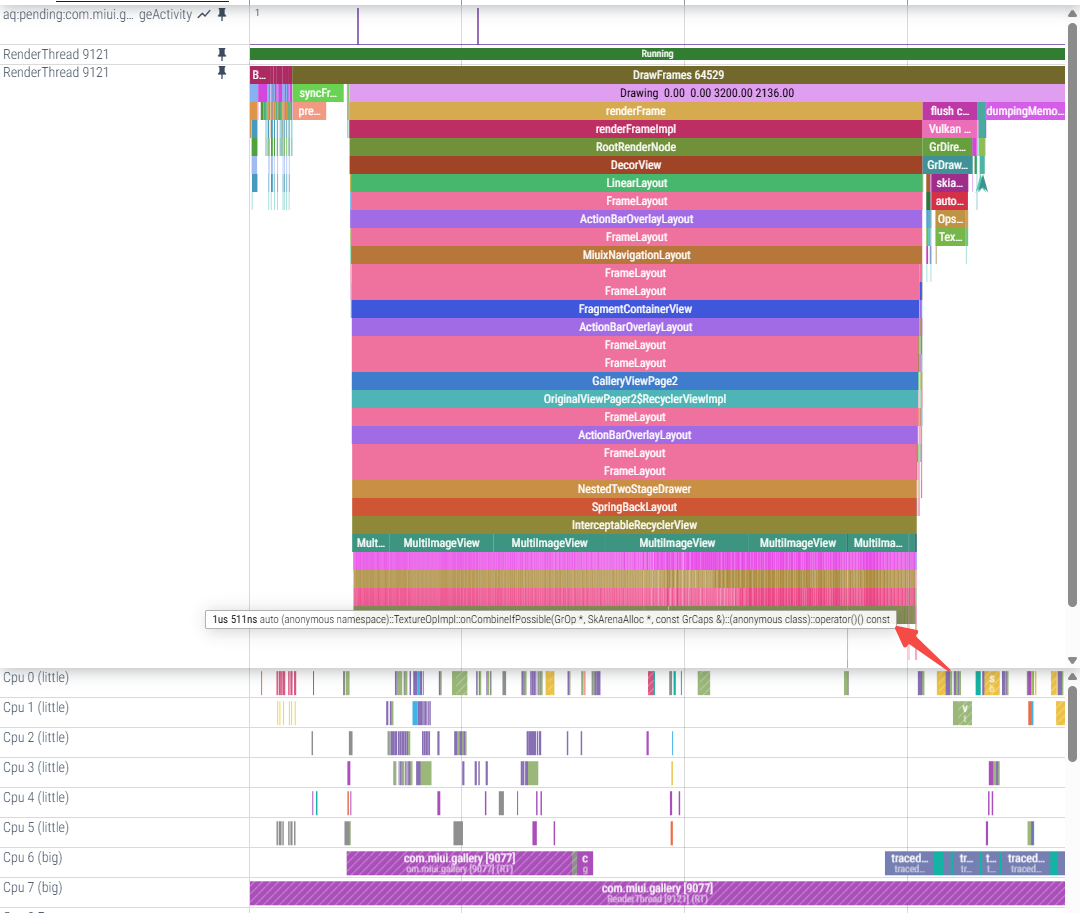
(2)实验1
onCombineIfPossible返回kMayChain的话,这之前的判断看起来不复杂,每次onCombineIfPossible的耗时是?想测一下把单次onCombineIfPossible最简单化的话可以在onCombineIfPossible的最开始先写死return CombineResult::kCannotCombine;测一下
trace看结果跟昨天修改结果差不多,renderFrameImpl耗时减少明显,flush commands耗时会增加,会遍历所有TextureOp并执行prepare和execute:
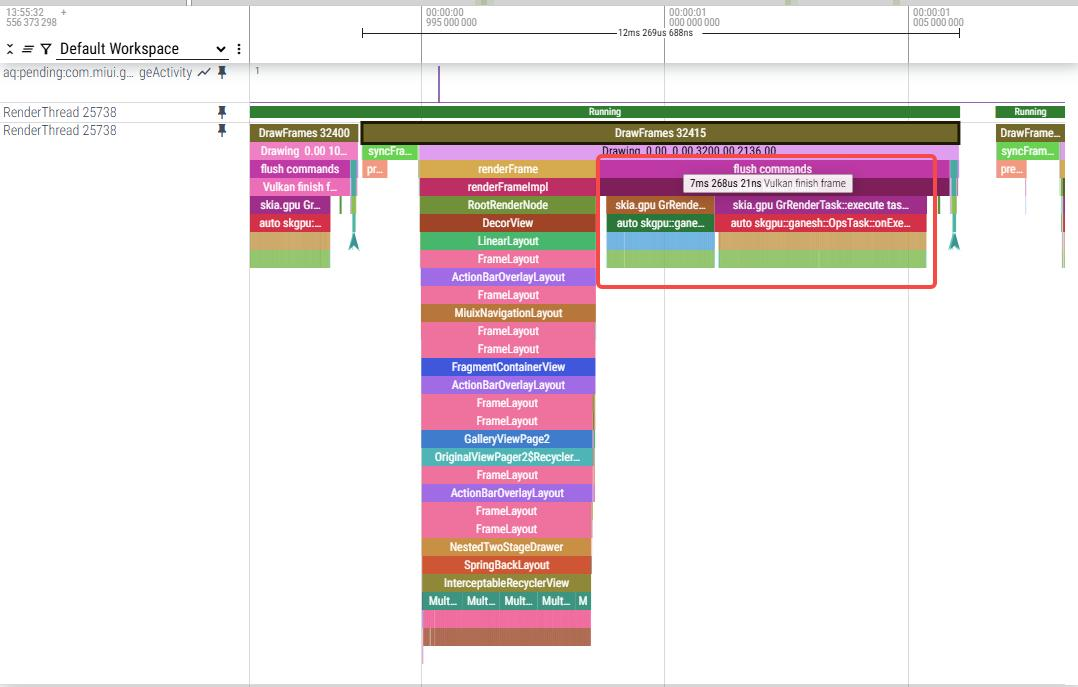
(3)实验2
11次应该是因为// Experimentally we have found that most combining occurs within the first 10 comparisons.
static const int kMaxOpMergeDistance = 10;
static const int kMaxOpChainDistance = 10;
这个值影响所有Op往chain里加的时候与多少个相邻op尝试合并,也可以把这个值改成1/2去测一下
a.修改至为1,小核耗时10ms左右,大核耗时3ms左右

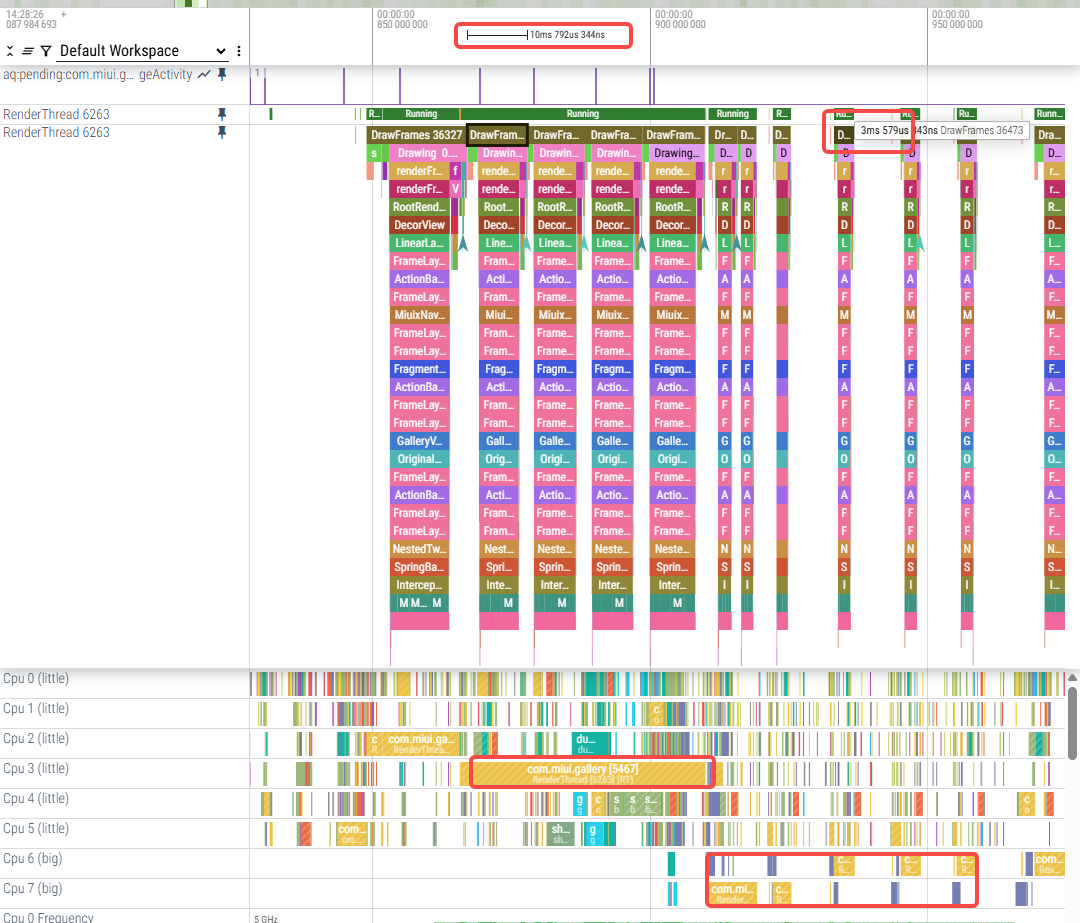
b.修改至为2,小核耗时13-14ms


6.Android U VS W
差异点:
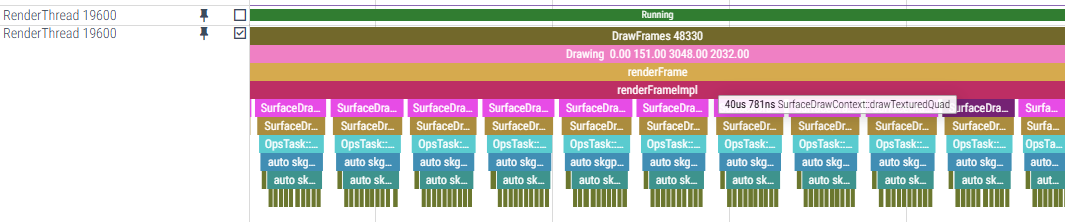
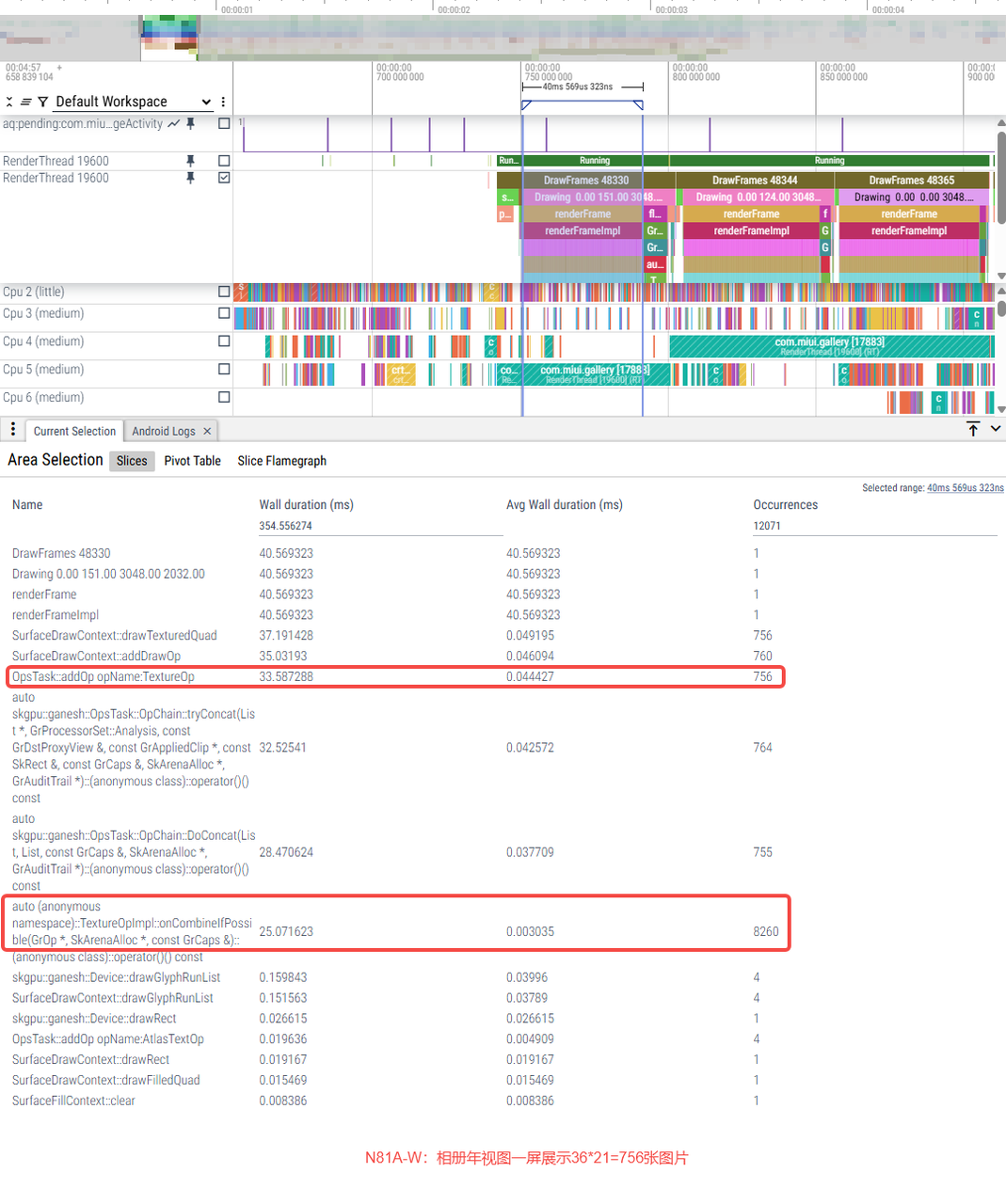
(1)布局view差异:U上年视图一屏展示32*18=576张图片;W上年视图一屏展示36*21=756张图片,图片数量差异直接影响TextureOp数量。
(2)绘制逻辑差异:U上相册绘制的是drawTexturedQuad+drawRect配合使用,TextureOp和AAStrokeRect两个Op是轮流添加的,这就使得TextureOp合并检查时调用onCombineIfPossible次数少很多;W上只有drawTexturedQuad,所以一直在添加TextureOp。
|
N81A-U |
N81A-W |
|
|
图片数量 |
32*18=576 |
36*21=756 |
|
绘制逻辑 |
 |
 |
|
1、TextureOp数量 2、TextureOpImpl::onCombineIfPossible次数 |
 |
 |
|
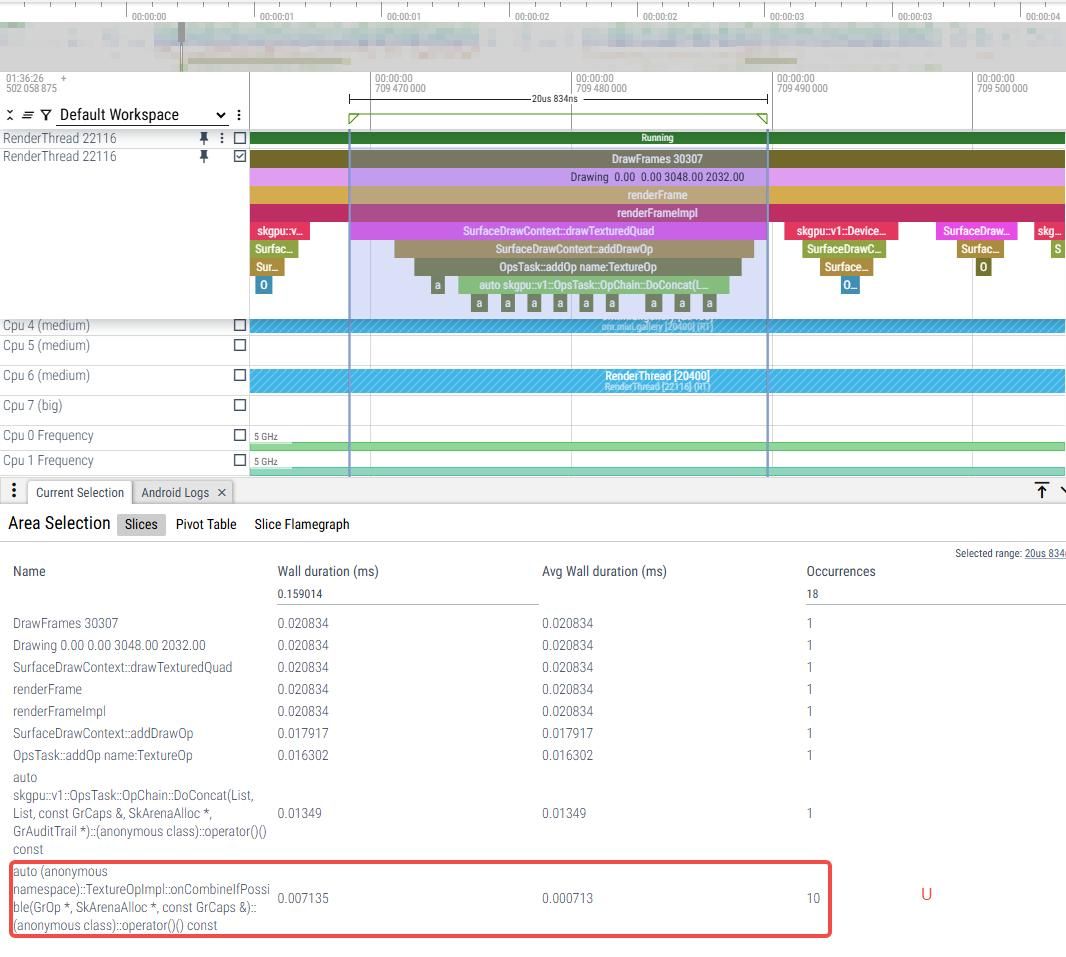
单个drawTexturedQuad耗时对比:选择调用10次TextureOpImpl::onCombineIfPossible单帧对比u和w,耗时相差不大 |
 |
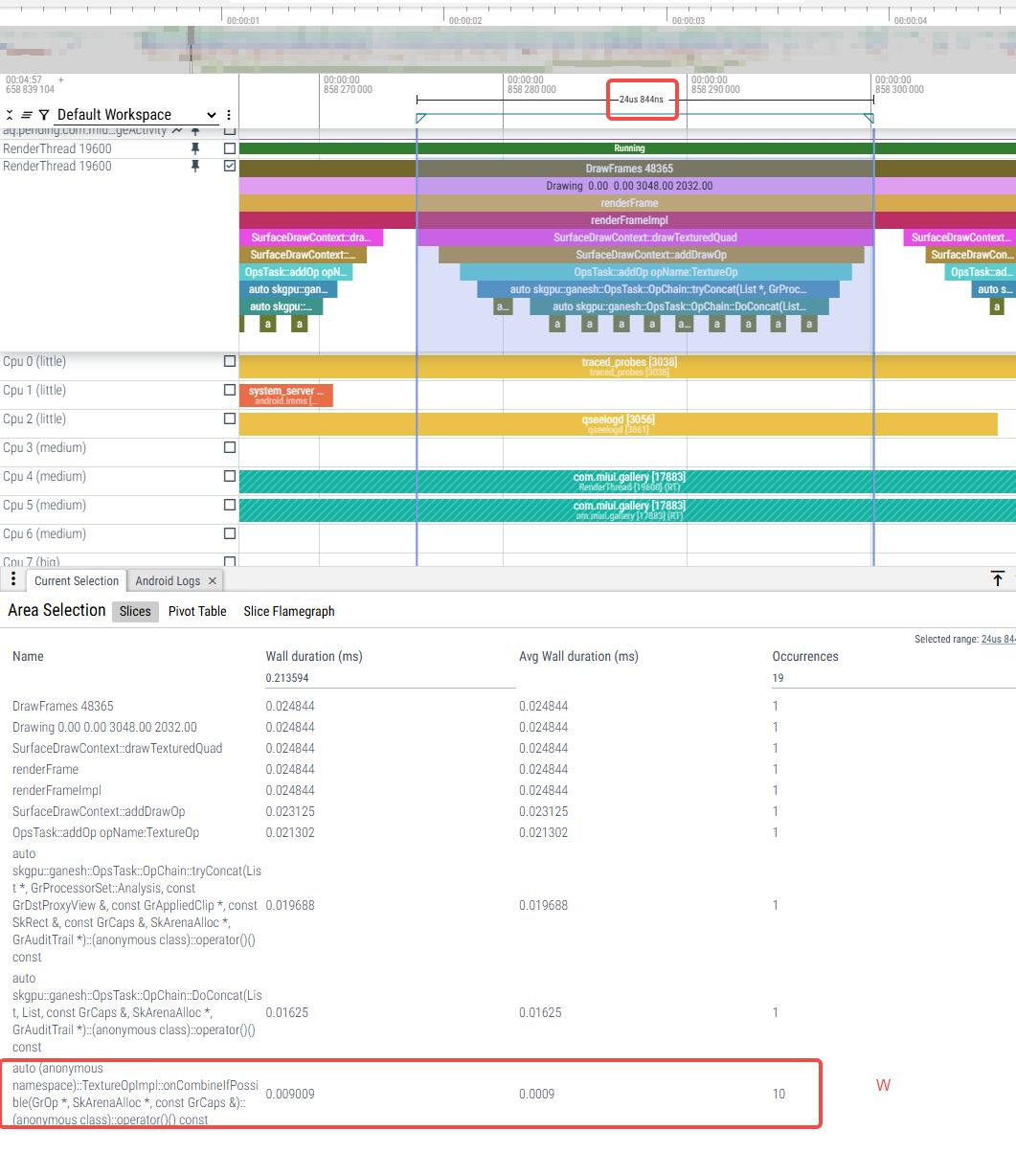 |
|
单帧总耗时对比 |
U上renderFrame 12.7ms + flush commands 3.8ms
|
W上renderFrame 31.9ms + flush commands 1.8ms
|
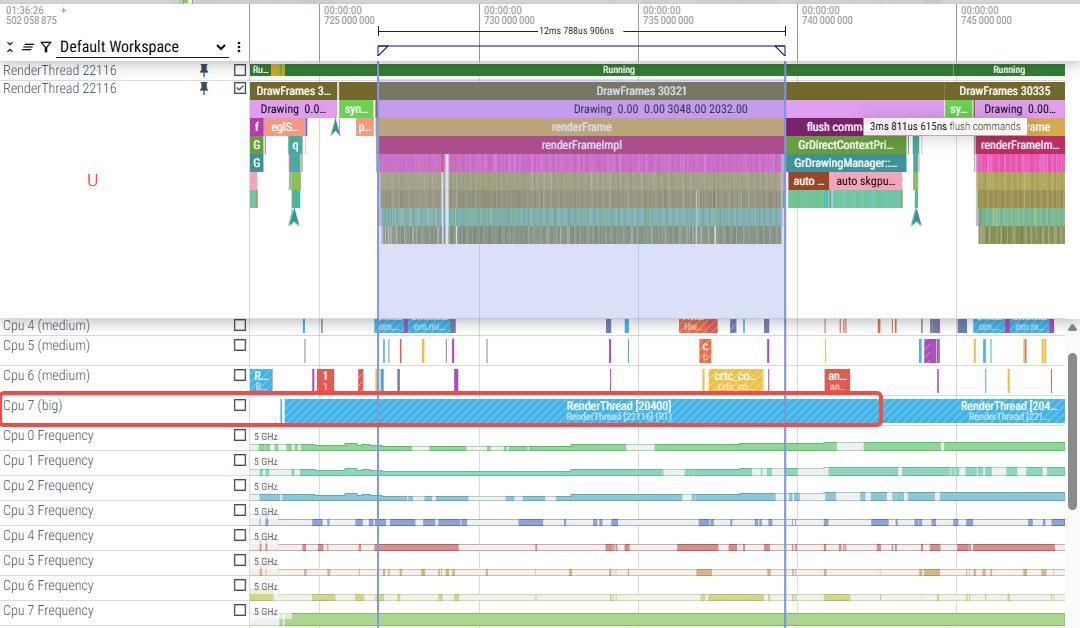
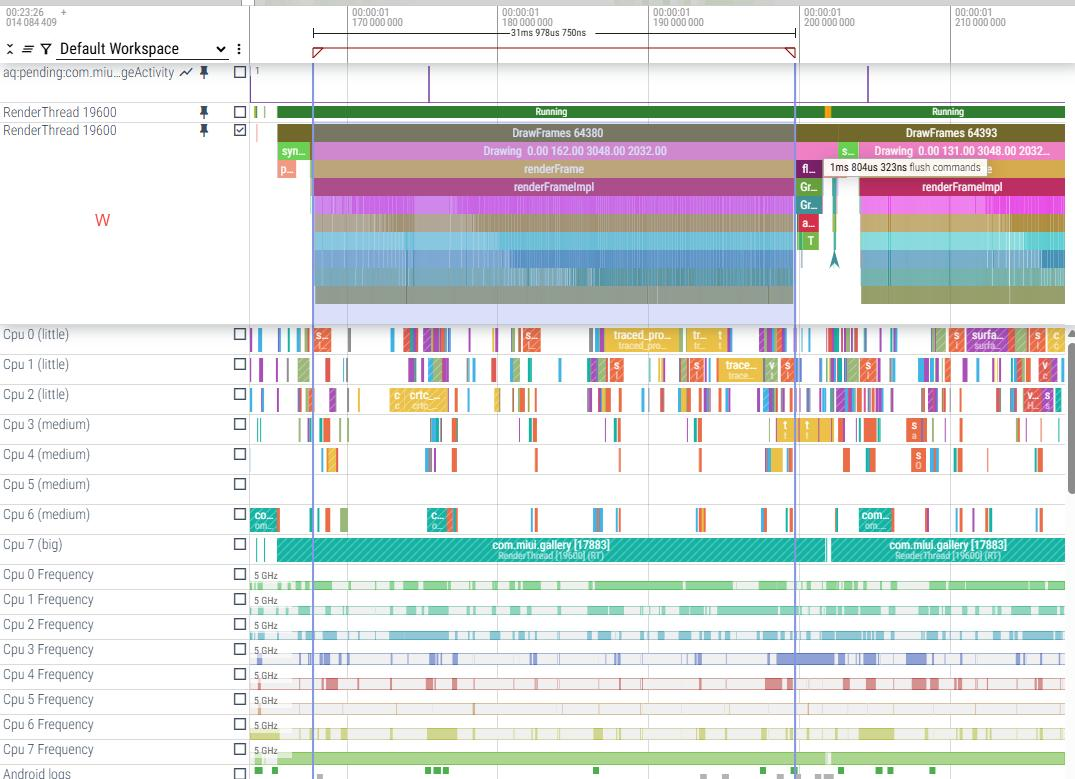
U/V/W 耗时对比
相册应用版本:
U:apk versionName=3.7.2.12
V:apk versionName=4.2.2.8
W:apk versionName=4.3.0.7
视图切换(年视图、月视图)
|
U trace_09-01-11-09-31-u-视图切换 |
V trace_09-01-12-06-05-v-切换视图 |
W优化前 trace_09-01-10-37-57-w原始-视图切换 |
W优化后 trace_09-01-10-43-56-w优化-视图切换 |
|
|
trace |
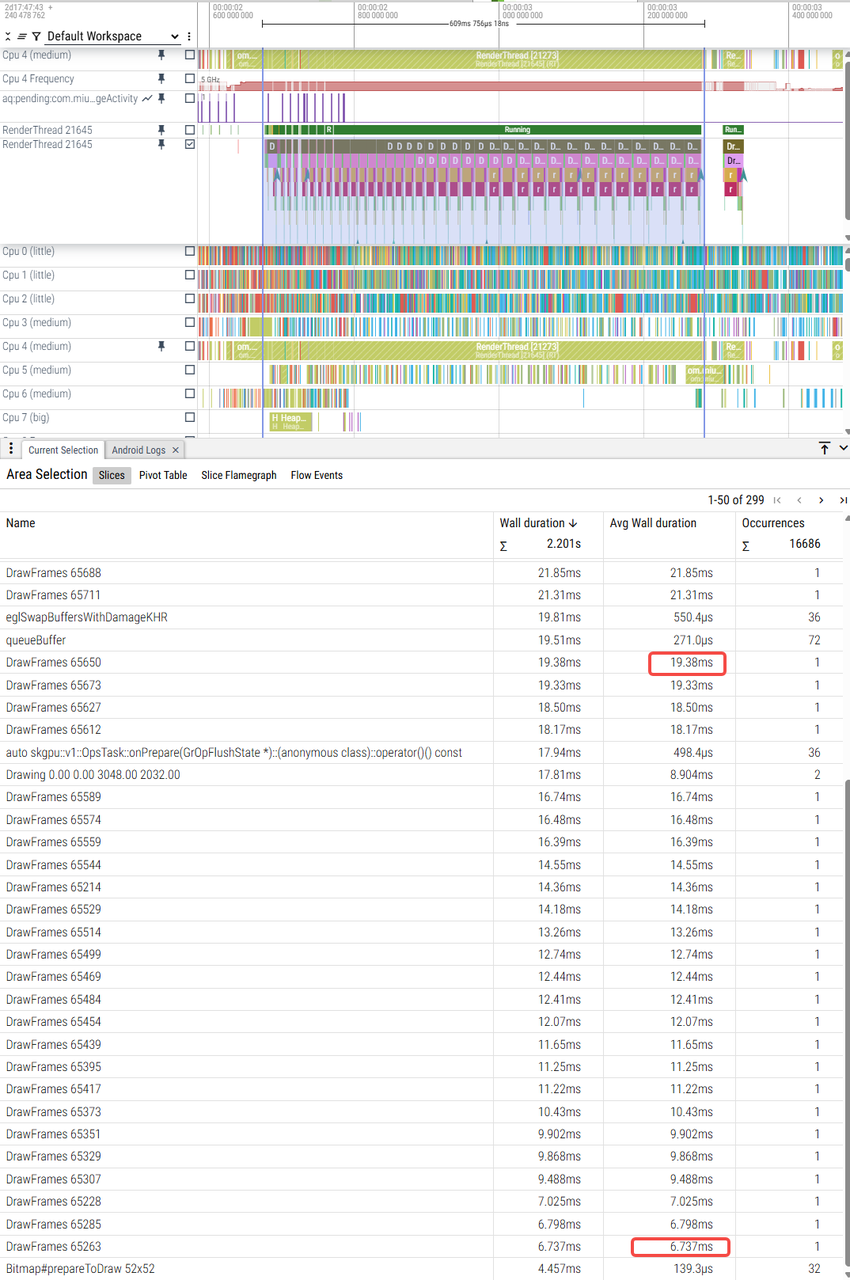 |
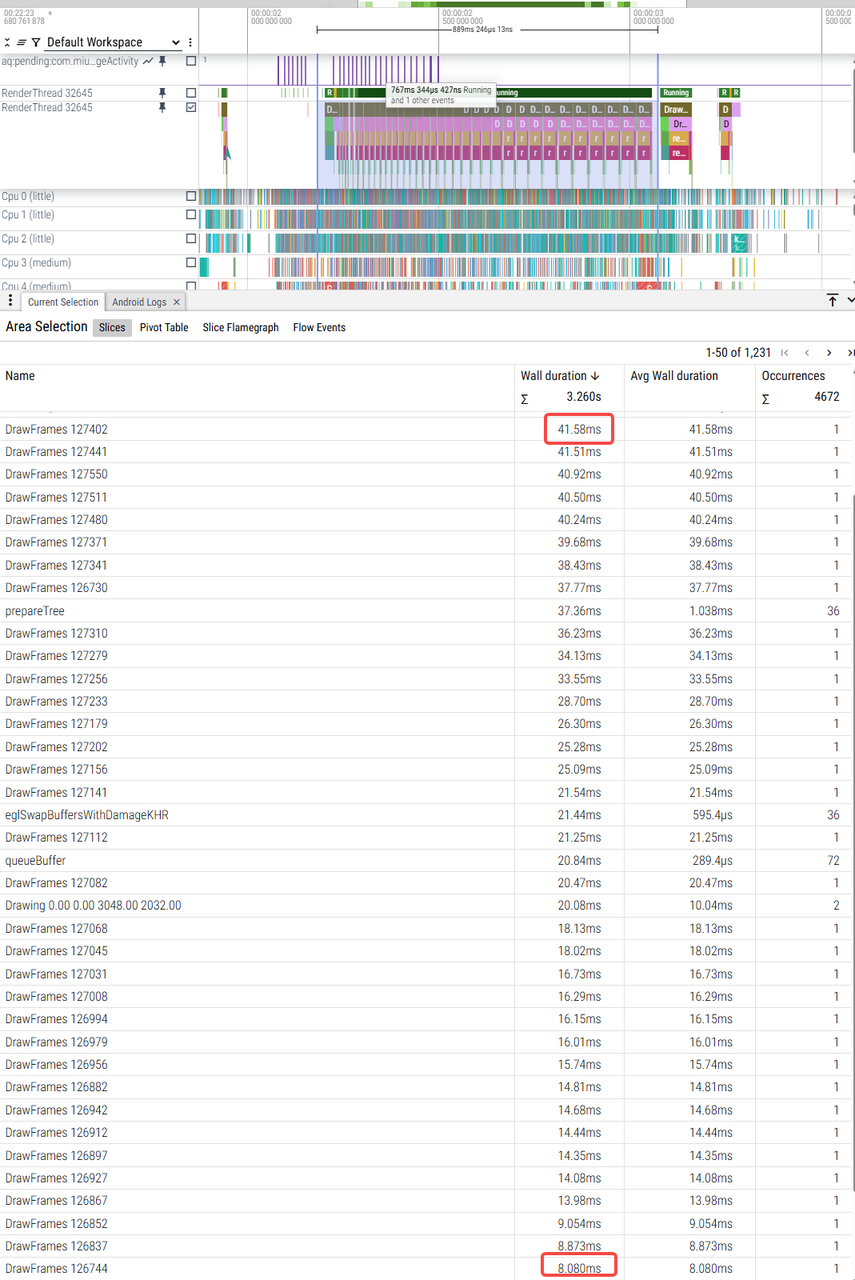 |
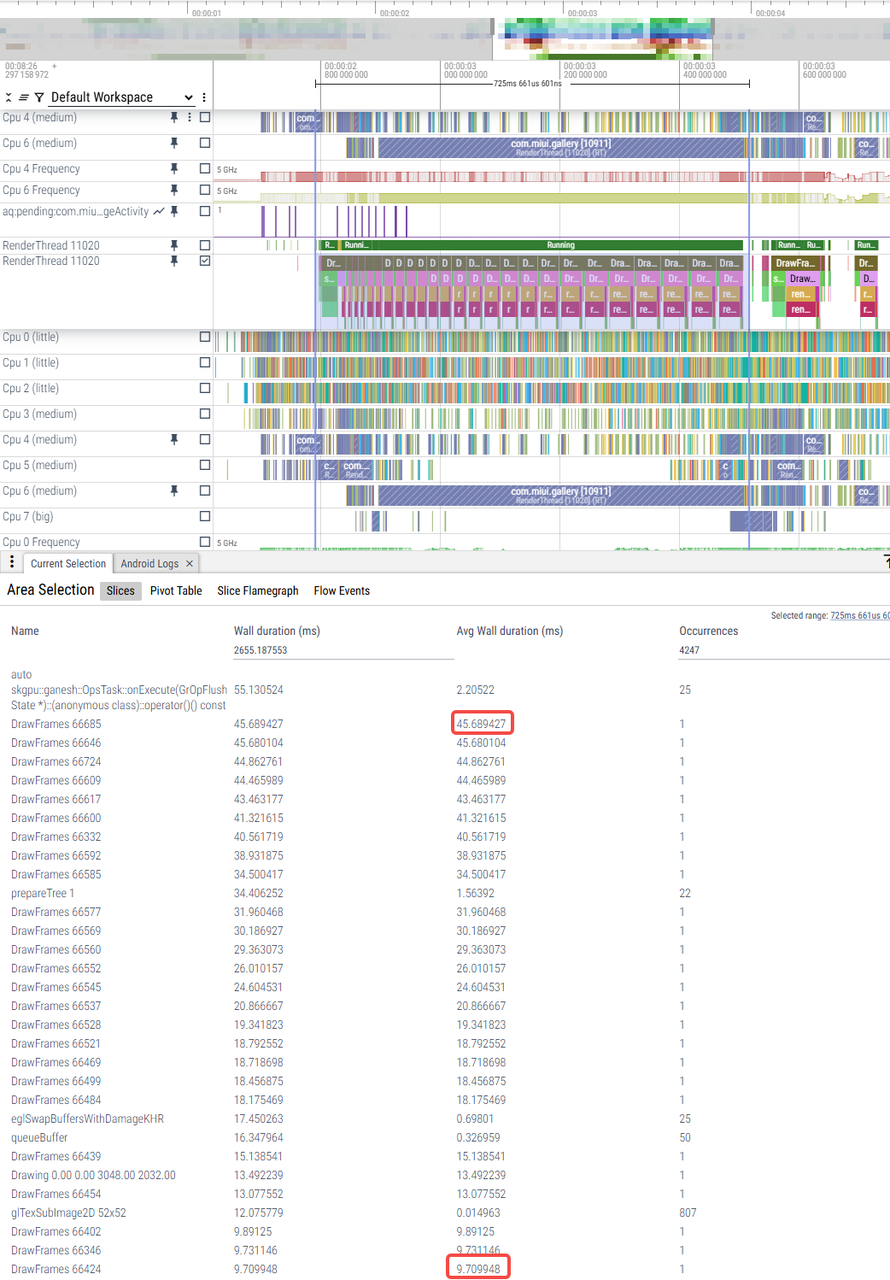 |
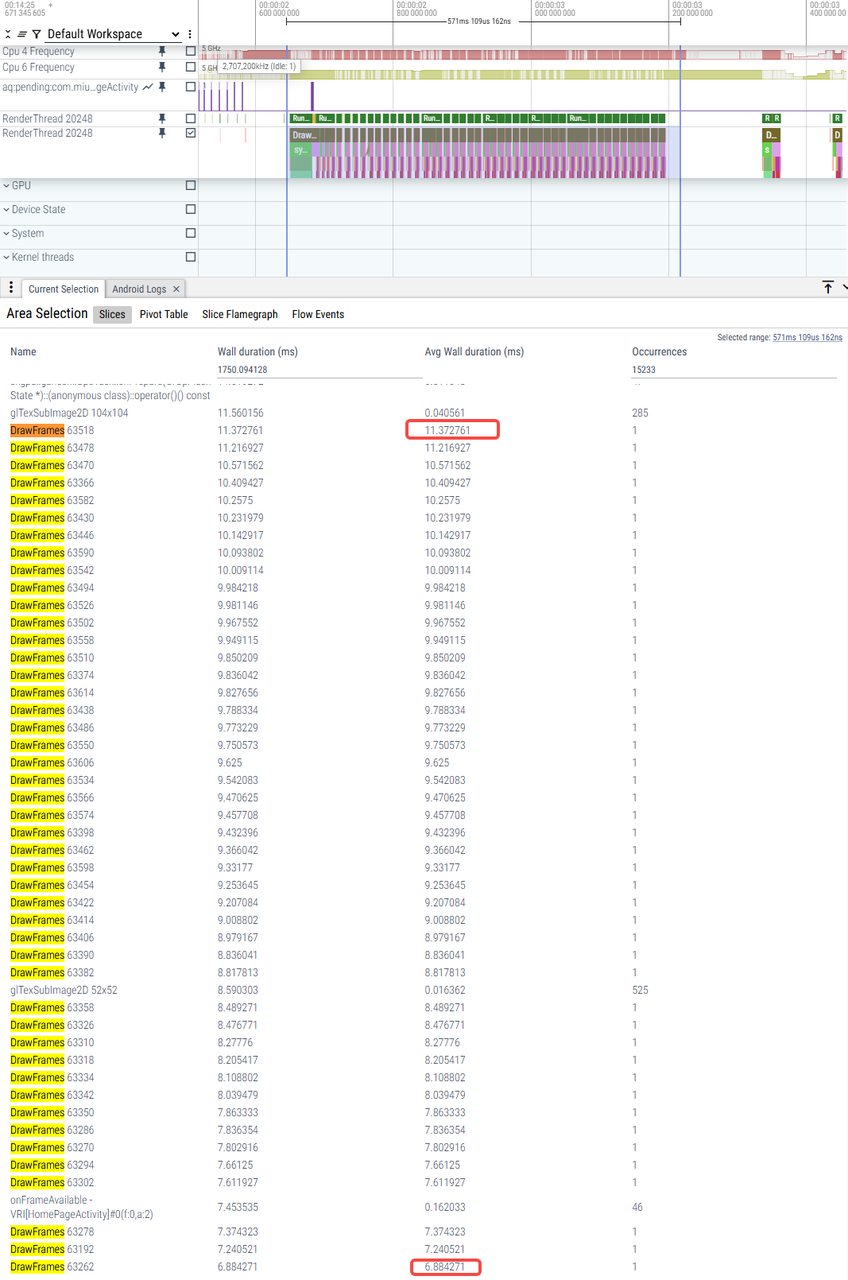 |
|
RenderThread耗时 |
6ms-19ms |
8ms-41ms |
9ms-45ms |
6ms-11ms |
|
主观感受 |
轻微卡顿 |
严重卡顿 |
严重卡顿 |
不卡顿 |
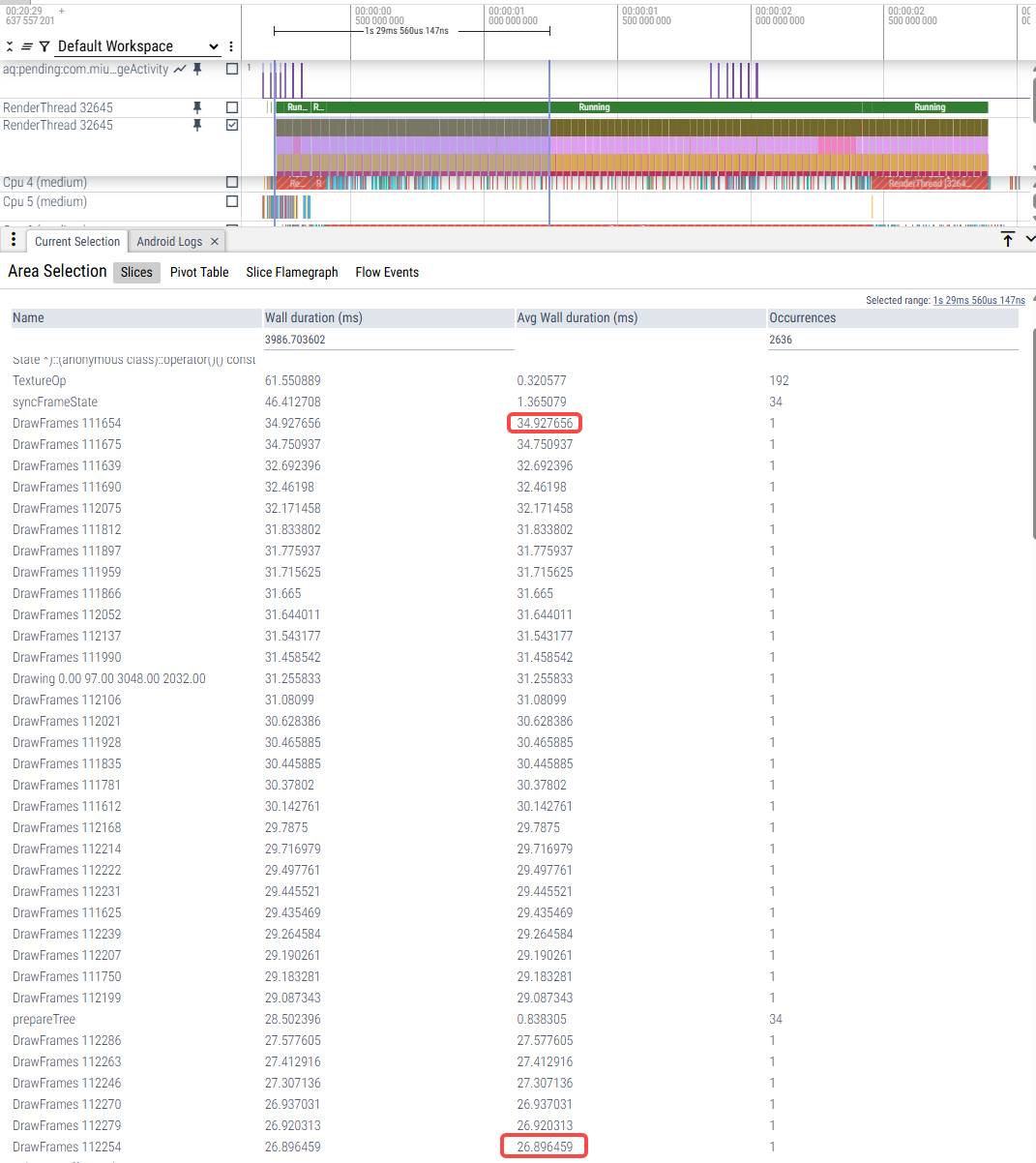
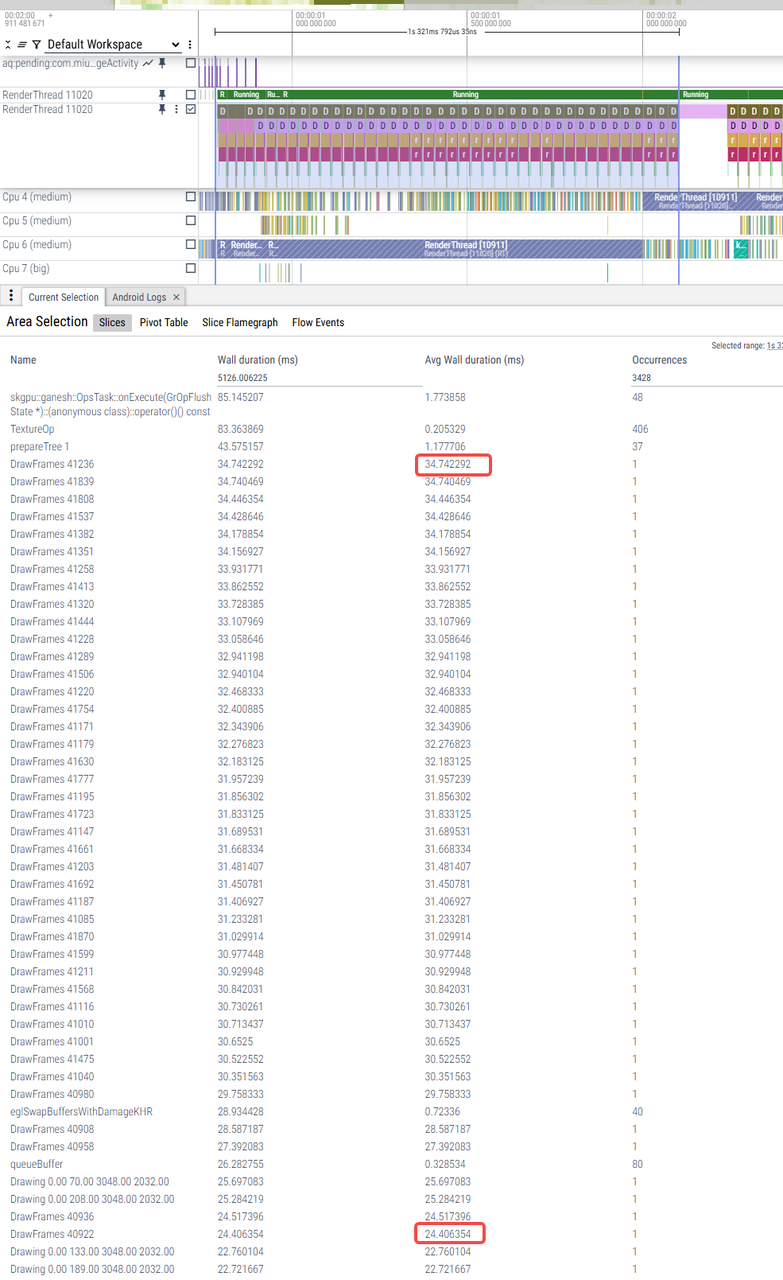
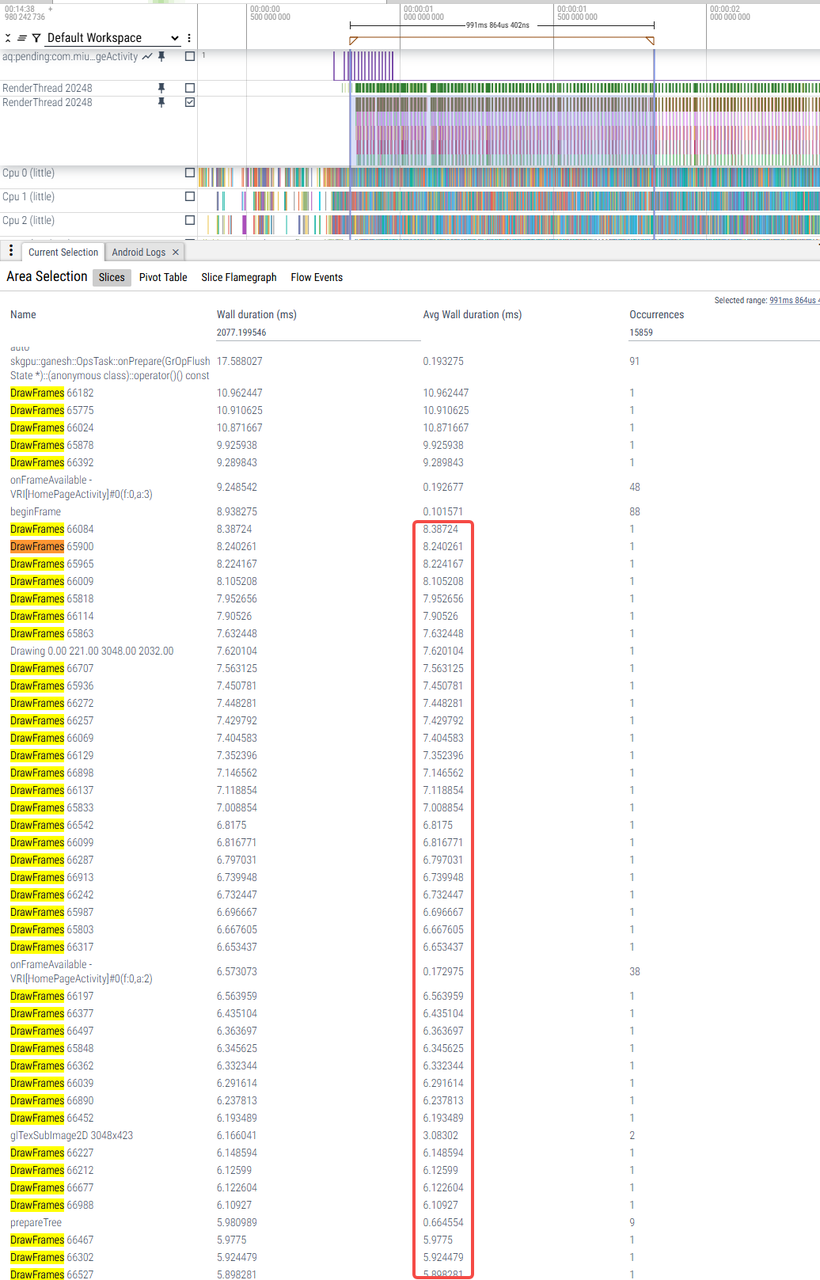
年视图滑动
|
U trace_09-01-11-09-59-u-年视图滑动 |
V trace_09-01-12-04-11-v-年视图滑动 |
W优化前 trace_09-01-10-31-31-w原始-年视图滑动 |
W优化后 trace_09-01-10-44-09-w优化-年视图滑动 |
|
|
trace |
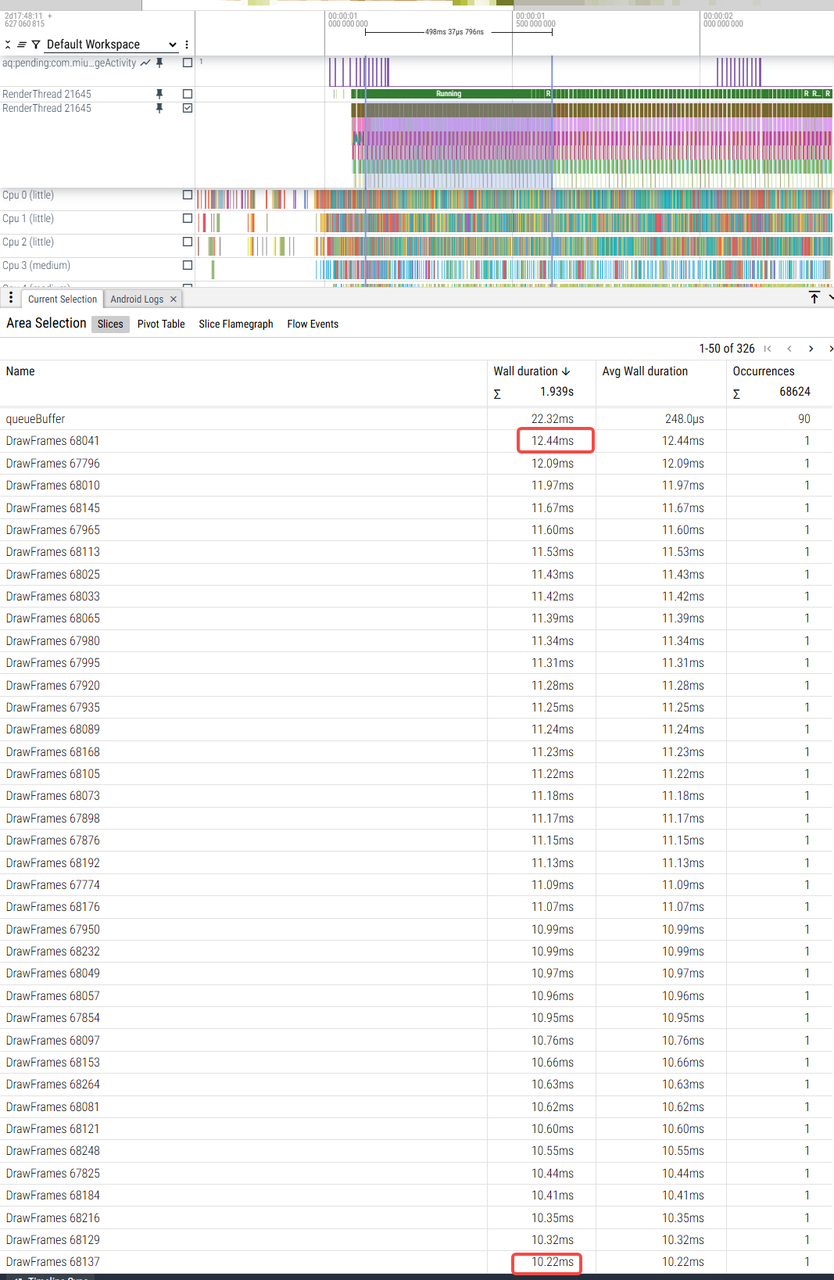 |
 |
 |
 |
|
RenderThread耗时 |
10ms-12ms |
26ms-34ms |
24ms-34ms |
4ms-8ms(少数帧9、10ms) |
|
主观感受 |
轻微卡顿 |
严重卡顿 |
严重卡顿 |
不卡 |
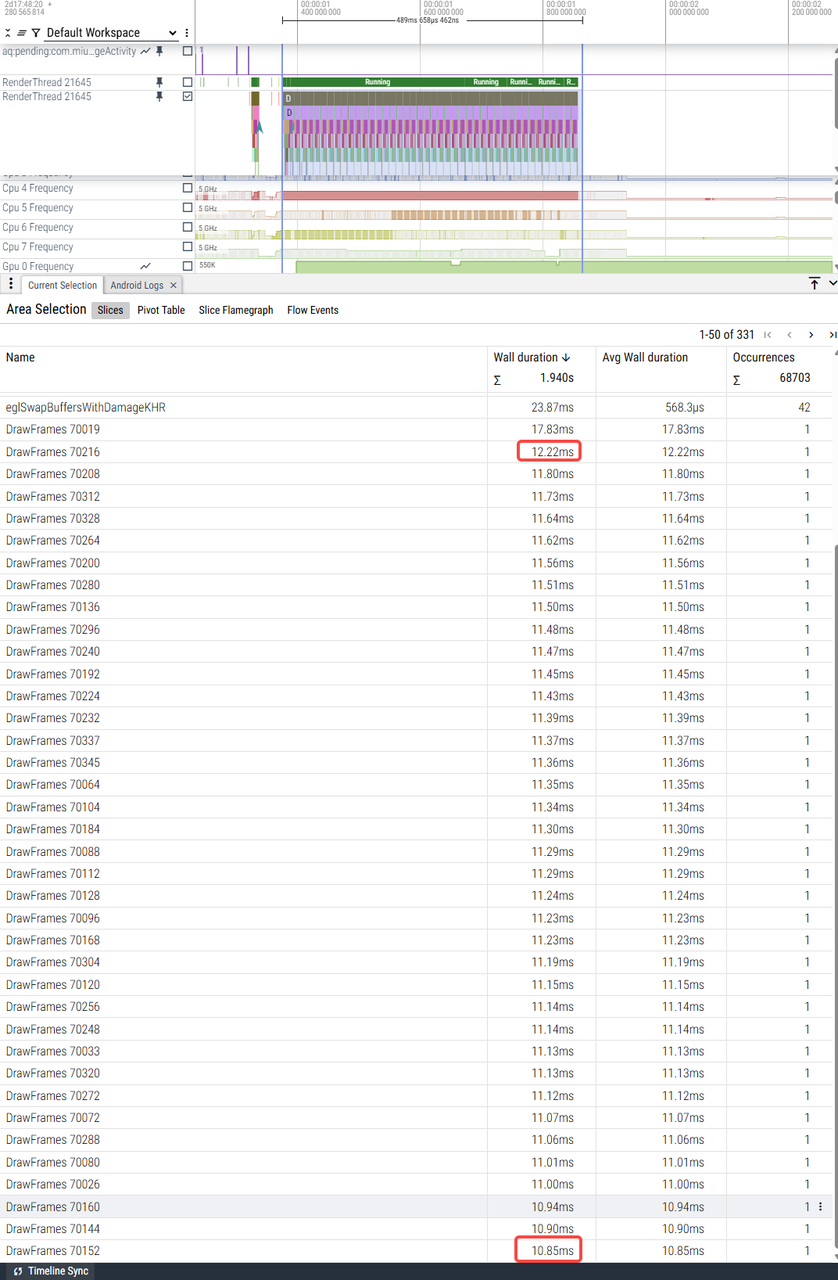
左侧列表展开收起
|
U trace_09-01-11-10-08-u-左侧列表展开收起 |
V trace_09-01-12-04-36-v-左侧列表展开收起 |
W优化前 trace_09-01-10-32-17-w原始-左侧列表展开 |
W优化后 trace_09-01-11-56-52-w优化-左侧列表展开收起 |
|
|
trace |
 |
|
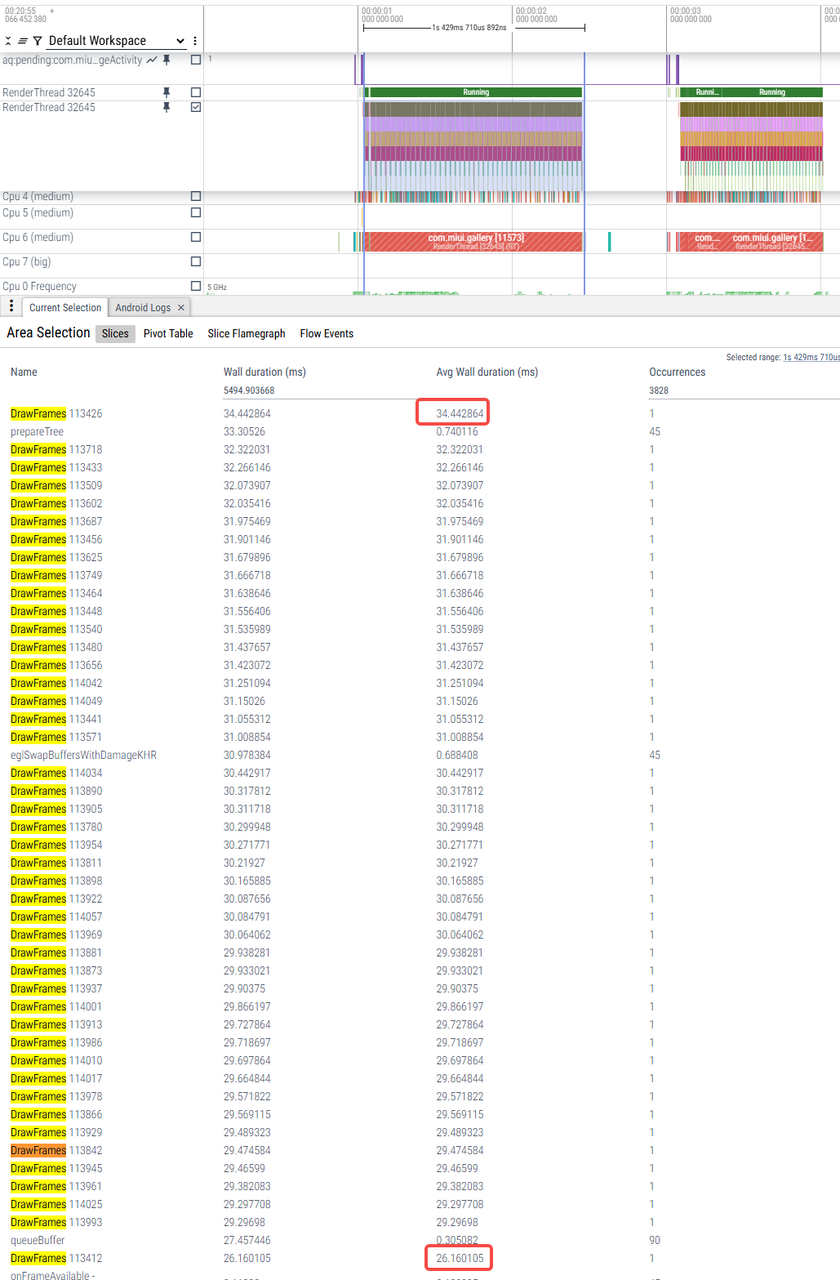
 |
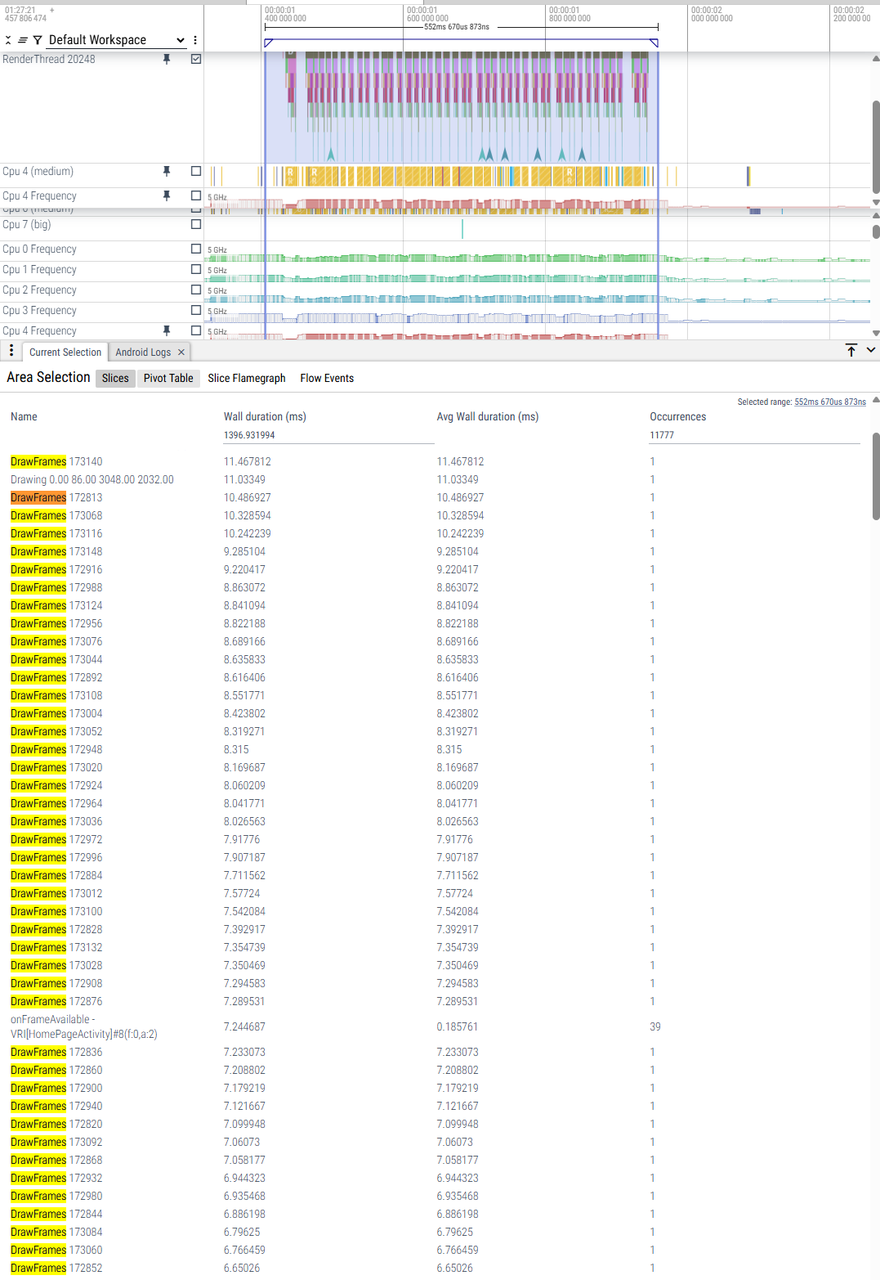 |
|
RenderThread耗时 |
10ms-12ms |
26ms-34ms |
29ms-40ms |
6ms-8ms(少数帧9-11ms)CPU没有满频 |
|
主观感受 |
不卡顿 |
严重卡顿 |
严重卡顿 |
不卡顿(展开列表时,右边会出现白边,应用逻辑导致) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)