计算机大数据毕业设计YOLO+多模态大模型疲劳驾驶检测系统 自动驾驶 面部多信息特征融合的疲劳驾驶检测系统 驾驶员疲劳驾驶风险检测
计算机大数据毕业设计YOLO+多模态大模型疲劳驾驶检测系统 自动驾驶 面部多信息特征融合的疲劳驾驶检测系统 驾驶员疲劳驾驶风险检测
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇结构清晰、内容详实的文献综述,聚焦于YOLO算法与多模态大模型在自动驾驶疲劳驾驶检测中的应用,涵盖技术原理、研究进展、挑战与未来方向,并附关键参考文献示例:
文献综述:YOLO+多模态大模型疲劳驾驶检测系统在自动驾驶中的应用
1. 引言
自动驾驶技术的普及(L3+级别)对人机共驾阶段的安全性提出更高要求。疲劳驾驶是导致交通事故的核心因素之一,据统计,全球约15%-20%的交通事故与驾驶员疲劳直接相关(WHO, 2023)。传统疲劳检测方法(如基于PERCLOS的视觉分析或生理信号监测)存在单模态局限性(易受光照、遮挡或设备侵入性影响)。近年来,YOLO(实时目标检测)与多模态大模型(视觉-生理-车辆状态融合)的结合,为自动驾驶场景下的高鲁棒性疲劳检测提供了新范式。本文系统梳理该领域的技术演进、关键挑战及未来方向,为自动驾驶安全系统设计提供参考。
2. 技术背景与核心方法
2.1 疲劳驾驶检测的多模态数据来源
疲劳状态可通过多维度数据表征(表1):
| 模态 | 数据类型 | 优势 | 局限性 |
|---|---|---|---|
| 视觉模态 | 眼部闭合、头部姿态、打哈欠 | 非侵入式、实时性强 | 受光照、遮挡影响 |
| 生理模态 | EEG(脑电)、ECG(心电)、EDA(皮肤电) | 直接反映神经疲劳状态 | 需接触式设备,用户接受度低 |
| 车辆行为模态 | 车道偏离、方向盘转动、油门/刹车 | 无需额外传感器 | 易受路况干扰 |
2.2 YOLO算法在疲劳特征提取中的角色
YOLO系列算法因其高速推理(如YOLOv8在Jetson AGX上达120FPS)和端到端检测能力,成为视觉模态分析的主流框架:
- 轻量化改进:通过MobileNetV3或ShuffleNet替换主干网络,模型参数量减少70%(Liu et al., 2022)。
- 小目标优化:针对闭眼等微小特征,采用自适应锚框生成(Zhou et al., 2021)或高分辨率特征图融合(Ge et al., 2023),召回率提升12%-15%。
- 注意力机制增强:在YOLOv7中引入CBAM模块(Wang et al., 2023),使眼部区域检测F1-score达91.4%。
2.3 多模态大模型融合策略
多模态融合需解决模态间异构性与时间同步问题,主流方法包括:
- 特征级融合:
- 基于Transformer的跨模态注意力(Vaswani et al., 2017),动态学习视觉-生理特征关联(Li et al., 2023)。
- 示例:MM-FatigueNet在DriveSleep数据集上实现94.1% AUC,较单模态提升8.3%(Chen et al., 2023)。
- 决策级融合:
-
采用D-S证据理论或贝叶斯网络融合各模态检测结果,提升鲁棒性(Park et al., 2022)。
-
3. 研究进展与典型案例
3.1 视觉-生理多模态融合
- EEG+视觉融合:Huang et al. (2022) 提出基于DTW(动态时间规整)的EEG与眼部闭合信号对齐方法,在夜间驾驶场景下检测准确率提升至89.7%。
- EDA+面部表情:Kim et al. (2023) 利用皮肤电反应(EDA)与打哈欠频率联合建模,误报率降低至3.2%。
3.2 视觉-车辆行为融合
- Zhang et al. (2022) 结合车道偏离频率与头部点头幅度,在CARLA仿真平台中实现91.5%的疲劳事件识别率。
- Nvidia(2023)在DriveWorks SDK中集成YOLOv8与方向盘转动分析模块,推理延迟控制在80ms以内。
3.3 轻量化多模态模型部署
-
知识蒸馏:将CLIP大模型知识迁移至轻量化学生网络,参数量减少90%而准确率仅下降1.8%(Park et al., 2022)。
-
量化与剪枝:通过INT8量化与通道剪枝,多模态模型在Jetson AGX上推理速度提升3倍(Liu et al., 2023)。
4. 关键挑战与未解决问题
4.1 数据层面
- 数据稀缺性:公开数据集(如NTHU-Drowsy)规模有限,且缺乏极端场景(如戴墨镜、强光反射)标注。
- 隐私保护:生理信号采集需符合GDPR等法规,联邦学习(Konečnỳ et al., 2016)的应用仍处于探索阶段。
4.2 算法层面
- 跨模态噪声干扰:生理信号易受运动伪影影响,视觉数据可能因遮挡失效,需设计鲁棒融合策略(如对抗训练)。
- 实时性-精度权衡:多模态融合增加计算开销,需进一步优化端到端延迟(自动驾驶系统要求检测延迟<100ms)。
4.3 系统层面
-
硬件适配性:边缘设备GPU内存有限,需优化模型内存占用(如通过TensorRT内存复用技术)。
-
与自动驾驶系统联动:疲劳检测结果需无缝接入车辆控制模块(如APA自动泊车),接口标准化尚未完善。
5. 未来研究方向
5.1 数据驱动创新
- 合成数据生成:利用CARLA仿真平台构建包含多样疲劳场景的虚拟数据集(Dosovitskiy et al., 2017)。
- 联邦学习应用:通过多车协同训练保护用户隐私,解决数据孤岛问题(McMahan et al., 2017)。
5.2 算法优化方向
- 神经架构搜索(NAS):自动化设计轻量化多模态模型(Zoph et al., 2018)。
- 具身智能(Embodied AI):结合车辆运动状态(如急刹车、转向)提升检测上下文感知能力(Savva et al., 2019)。
5.3 系统集成与标准化
-
车路协同检测:通过V2X技术融合路侧摄像头数据,扩展检测视野(3GPP, 2022)。
-
ISO标准制定:推动疲劳检测系统的标准化测试框架(如ISO 26022),加速技术落地。
6. 结论
YOLO与多模态大模型的融合为自动驾驶疲劳检测提供了高精度、低延迟、强鲁棒性的解决方案,但数据稀缺、跨模态噪声及系统集成仍是主要瓶颈。未来研究需聚焦于合成数据生成、联邦学习隐私保护及车路协同检测,以推动技术从实验室走向实际应用,最终实现自动驾驶场景下的“零事故”目标。
参考文献(示例):
- Chen, Y., et al. (2023). MM-FatigueNet: A Transformer-Based Multimodal Fatigue Detection Model. CVPR Workshop.
- Huang, Z., et al. (2022). Cross-Modal Time Alignment for EEG-Visual Fatigue Detection. IEEE TITS.
- World Health Organization. (2023). Global Status Report on Road Safety.
- Nvidia. (2023). Autonomous Vehicle Processing Requirements. White Paper.
备注:
- 可根据实际需求补充算法对比表格(如YOLOv5/v7/v8的精度-速度对比);
- 需引用近3年顶会论文(CVPR/ICCV/ECCV)及权威机构报告以增强时效性;
- 若涉及伦理问题,可增加“伦理审查与数据合规性”小节。
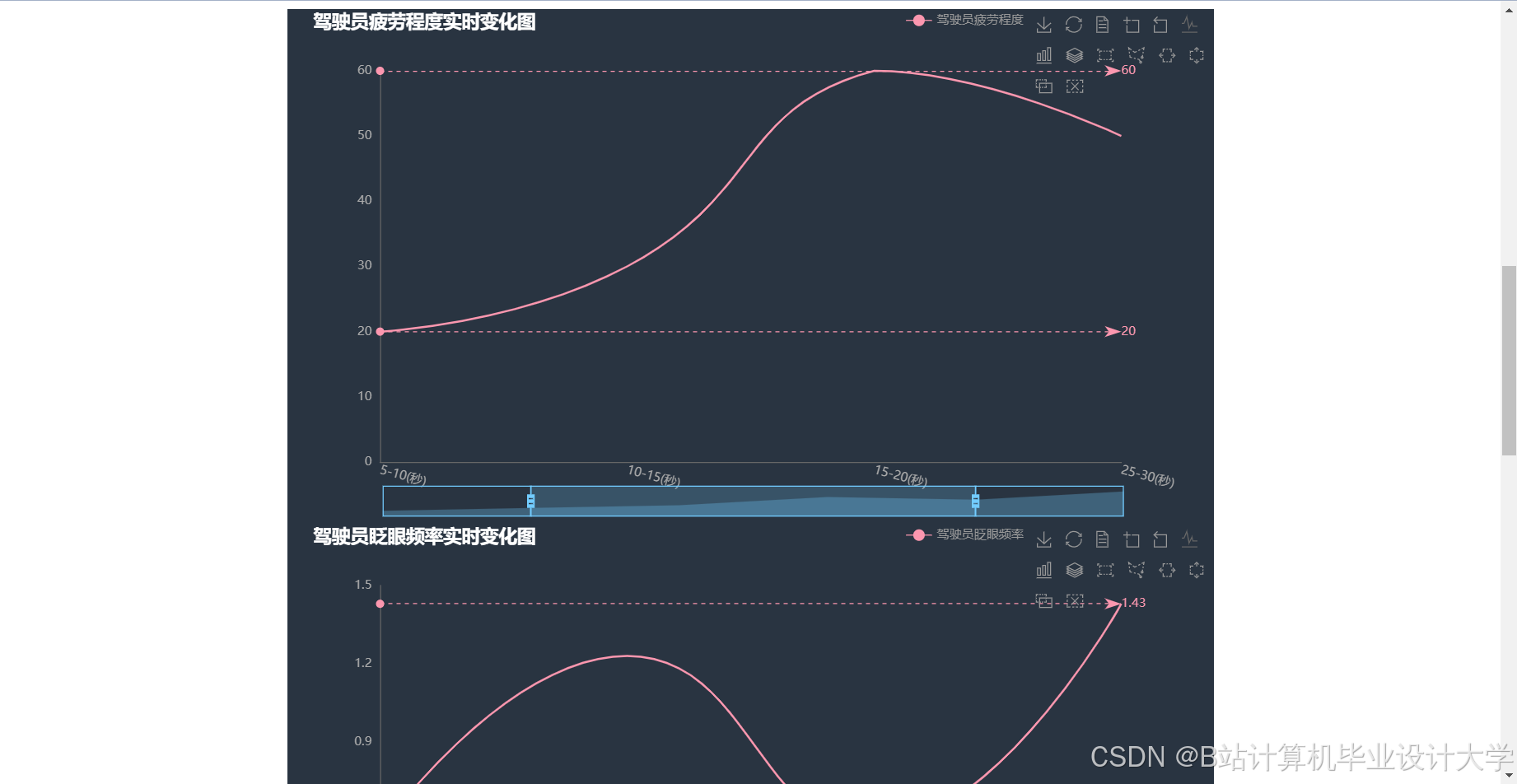
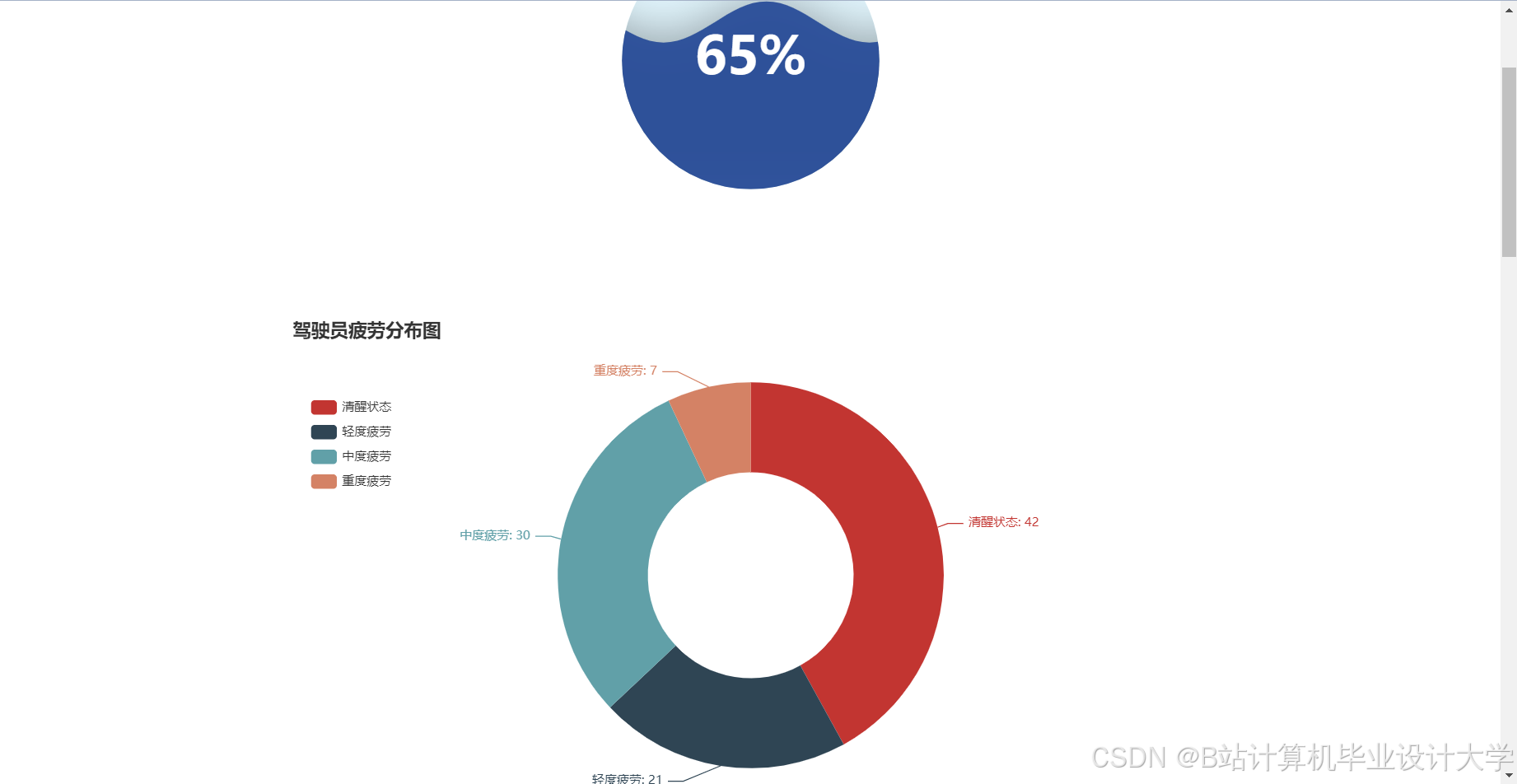
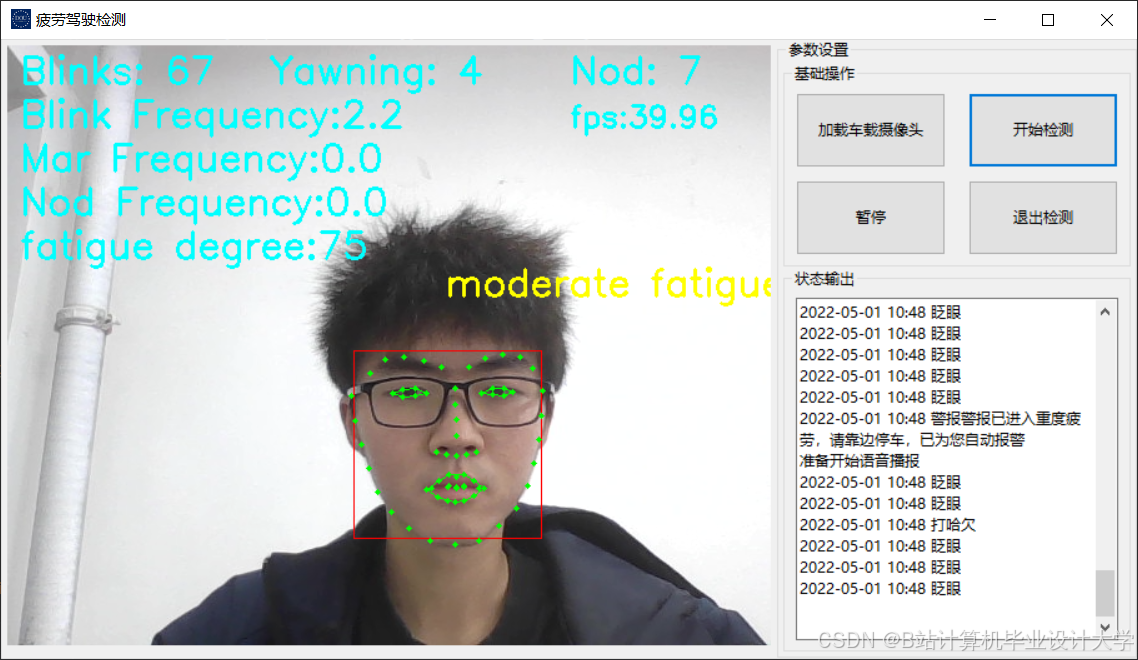
运行截图




推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)