使用最小最大插值的非均匀快速傅里叶变换
摘要 本文提出了一种基于最小最大插值的非均匀快速傅里叶变换(NUFFT)方法,用于高效计算非均匀采样频点的傅里叶变换。该方法采用两步框架:首先对输入信号进行加权过采样FFT,然后通过最小最大准则优化的插值器近似目标频率值。通过理论推导和数值实验表明,该方法相比传统Dirichlet、高斯钟形和Kaiser-Bessel插值器能显著降低最坏情况误差(最高达两个数量级)。研究还分析了不同参数(邻域大小
使用最小最大插值的非均匀快速傅里叶变换
J. A. Fessler and B. P. Sutton, “Nonuniform fast Fourier transforms using min-max interpolation,” in IEEE Transactions on Signal Processing, vol. 51, no. 2, pp. 560-574, Feb. 2003, doi: 10.1109/TSP.2002.807005.
引言与背景
快速傅里叶变换(FFT)在信号处理领域中被广泛应用,它能够高效地计算有限长度信号在均匀间隔频率位置上的傅里叶变换。对于N点信号,FFT只需要O(N log N)次运算,而直接计算离散傅里叶变换则需要O(N²)次运算。然而,在许多应用中,我们需要在频域进行非均匀采样,这就是非均匀傅里叶变换(Nonuniform Fourier Transform)的需求所在。
这类应用已经被认识了至少30年,包括雷达成像、通过Radon变换计算定向小波、计算电磁学、FIR滤波器设计等。本文作者的工作特别受到迭代磁共振图像(MRI)重建和基于傅里叶切片定理的迭代断层图像重建方法的启发。这些问题与从非均匀样本重建带限信号的问题密切相关。
一维理论推导
问题的数学表述
给定均匀间隔的信号样本 xnx_nxn,其中 n=0,…,N−1n = 0, \ldots, N-1n=0,…,N−1,对应的傅里叶变换为:
X(ω)=∑n=0N−1xne−iωnX(\omega) = \sum_{n=0}^{N-1} x_n e^{-i\omega n}X(ω)=n=0∑N−1xne−iωn
我们希望在一组(非均匀间隔的)频率位置 ωm\omega_mωm 处计算傅里叶变换:
X^m≜X(ωm)=∑n=0N−1xne−iωmn,m=1,…,M\hat{X}_m \triangleq X(\omega_m) = \sum_{n=0}^{N-1} x_n e^{-i\omega_m n}, \quad m = 1, \ldots, MX^m≜X(ωm)=n=0∑N−1xne−iωmn,m=1,…,M
这里的符号"≜\triangleq≜"表示"定义为"。频率位置 ωm\omega_mωm 可以是任意实数。这种形式被称为非均匀离散傅里叶变换(NDFT)。直接计算上式需要O(MN)次运算,对于大规模问题来说计算量过大。快速计算这个表达式就是NUFFT的目标。
NUFFT方法的两步框架
大多数NUFFT方法的第一步是选择一个合适的过采样因子K ≥ 1,并计算加权的K·N点FFT:
Yk=∑n=0N−1snxne−iγkn,k=0,…,K⋅N−1Y_k = \sum_{n=0}^{N-1} s_n x_n e^{-i\gamma kn}, \quad k = 0, \ldots, K \cdot N - 1Yk=n=0∑N−1snxne−iγkn,k=0,…,K⋅N−1
其中 γ≜2π/K\gamma \triangleq 2\pi/Kγ≜2π/K 是K·N点DFT的基频。非零的 sns_nsn 是算法设计变量,被称为"缩放因子"。我们将 s=(s1,…,sN)\mathbf{s} = (s_1, \ldots, s_N)s=(s1,…,sN) 称为缩放向量。s\mathbf{s}s 的目的是部分预补偿后续频域插值中的不完美性。
第二步是通过插值 YkY_kYk 来近似每个 X^m\hat{X}_mX^m,使用 ωm\omega_mωm 在DFT频率集 ΩK≜{0,γ,2γ,…,(K⋅N−1)γ}\Omega_K \triangleq \{0, \gamma, 2\gamma, \ldots, (K \cdot N - 1)\gamma\}ΩK≜{0,γ,2γ,…,(K⋅N−1)γ} 中的某些邻居。线性插值器的一般形式为:
X^(ωm)=∑k=0K−1vm,k∗Yk=⟨Y,vm⟩,m=1,…,M\hat{X}(\omega_m) = \sum_{k=0}^{K-1} v_{m,k}^* Y_k = \langle \mathbf{Y}, \mathbf{v}_m \rangle, \quad m = 1, \ldots, MX^(ωm)=k=0∑K−1vm,k∗Yk=⟨Y,vm⟩,m=1,…,M
最小最大插值器的推导
本文采用最小最大准则来选择插值系数 {uj(ωm)}\{u_j(\omega_m)\}{uj(ωm)}。对于每个期望的频率位置 ωm\omega_mωm,我们确定系数向量 u(ωm)∈CJ\mathbf{u}(\omega_m) \in \mathbb{C}^Ju(ωm)∈CJ,使其最小化 X^m\hat{X}_mX^m 和 XmX_mXm 之间在所有单位范数信号上的最坏情况近似误差:
u(ωm)=argminu∈CJmax∥x∥2=1∣X^(ωm)−X(ωm)∣\mathbf{u}(\omega_m) = \arg\min_{\mathbf{u} \in \mathbb{C}^J} \max_{\|\mathbf{x}\|_2 = 1} |\hat{X}(\omega_m) - X(\omega_m)|u(ωm)=argu∈CJmin∥x∥2=1max∣X^(ωm)−X(ωm)∣
从数学上讲,这个最小最大问题变为:
minu(ωm)∈CJmaxx∈CN:∥x∥2≤1∣X^(ωm)−X(ωm)∣\min_{\mathbf{u}(\omega_m) \in \mathbb{C}^J} \max_{\mathbf{x} \in \mathbb{C}^N : \|\mathbf{x}\|_2 \leq 1} |\hat{X}(\omega_m) - X(\omega_m)|u(ωm)∈CJminx∈CN:∥x∥2≤1max∣X^(ωm)−X(ωm)∣
值得注意的是,这个最小最大问题有解析解。通过Cauchy-Schwarz不等式,对于给定频率 ω\omegaω,最坏情况信号是 x=q∗(ω)/∥q(ω)∥\mathbf{x} = \mathbf{q}^*(\omega)/\|\mathbf{q}(\omega)\|x=q∗(ω)/∥q(ω)∥,即:
max∥x∥=1∣⟨x,q(ω)⟩∣=∥q(ω)∥\max_{\|\mathbf{x}\|=1} |\langle\mathbf{x}, \mathbf{q}(\omega)\rangle| = \|\mathbf{q}(\omega)\|∥x∥=1max∣⟨x,q(ω)⟩∣=∥q(ω)∥
将此代入最小最大准则并应用相关公式,最小最大问题简化为以下最小二乘问题:
minu(ω)∥S∗CΛ(ω)u(ω)−b(ω)∥2\min_{\mathbf{u}(\omega)} \|\mathbf{S}^* \mathbf{C} \Lambda(\omega) \mathbf{u}(\omega) - \mathbf{b}(\omega)\|^2u(ω)min∥S∗CΛ(ω)u(ω)−b(ω)∥2
该普通最小二乘问题的最小值为 ω=ωm\omega = \omega_mω=ωm,其中:
u(ω)=A†(ω)[C∗SS∗C]−1C∗Sb(ω)\mathbf{u}(\omega) = \mathbf{A}^{†}(\omega) [\mathbf{C}^* \mathbf{S} \mathbf{S}^* \mathbf{C}]^{-1} \mathbf{C}^* \mathbf{S} \mathbf{b}(\omega)u(ω)=A†(ω)[C∗SS∗C]−1C∗Sb(ω)
由于 S\mathbf{S}S 是酉矩阵,这就是最小最大插值器的一般表达式。
图形分析与可视化
图1:J=6, K/N=2时的最小最大插值器
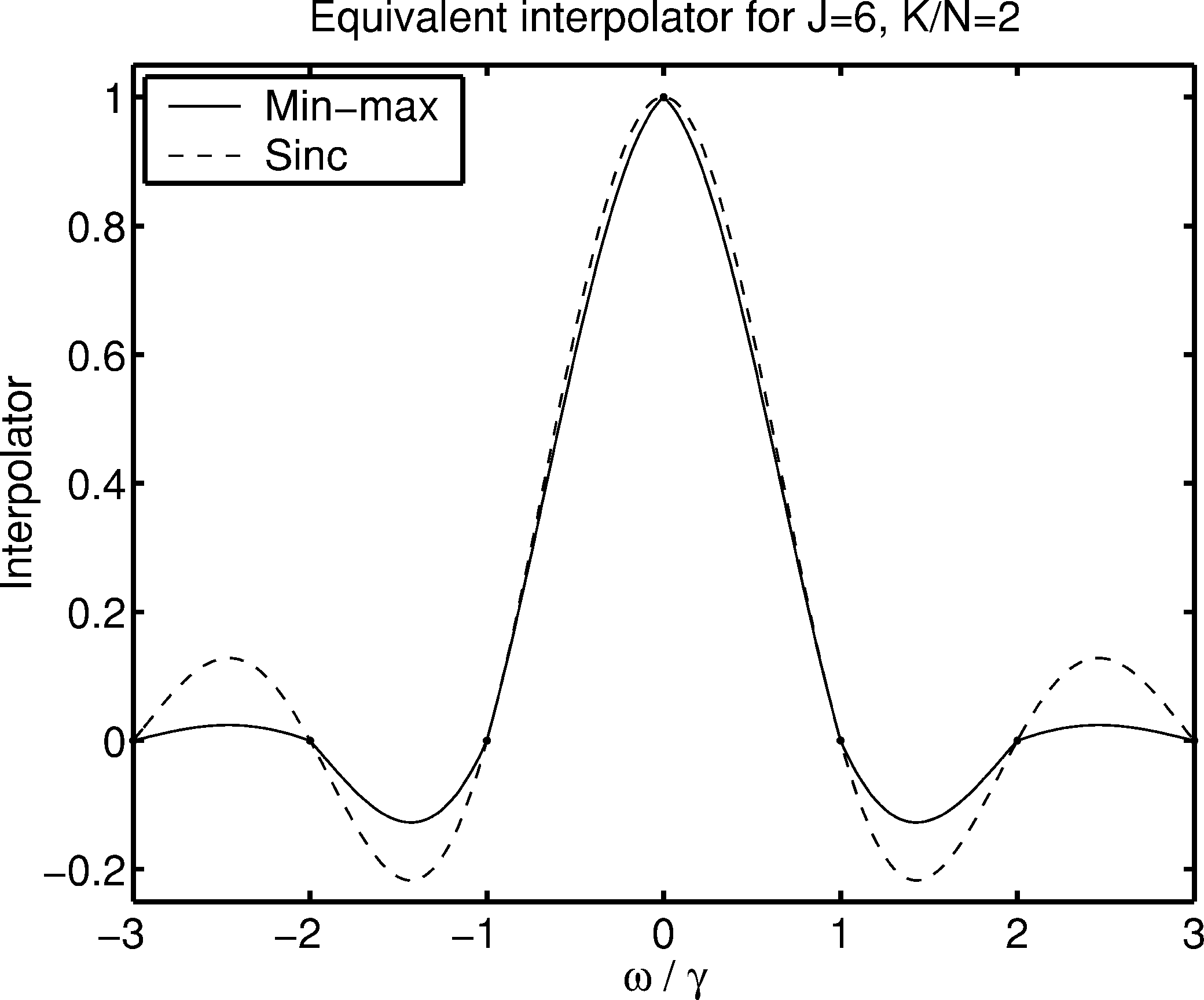
图1 展示了J=6、N=128、K/N=2和均匀缩放因子条件下对应于公式(33)的最小最大插值器。图中实线表示最小最大插值器,虚线表示sinc插值器的一部分。这个图揭示了几个重要特征:最小最大插值器在整数参数处不可微。插值器在零处的值并非恰好为1,在其他DFT样本点也不为零,这与经典插值器的性质有显著差异。尽管表面上看起来最小最大插值器与(截断的)理想Dirichlet插值器相似,但图1中看似微小的差异会强烈影响最大误差。
图2:J=7时的插值器比较
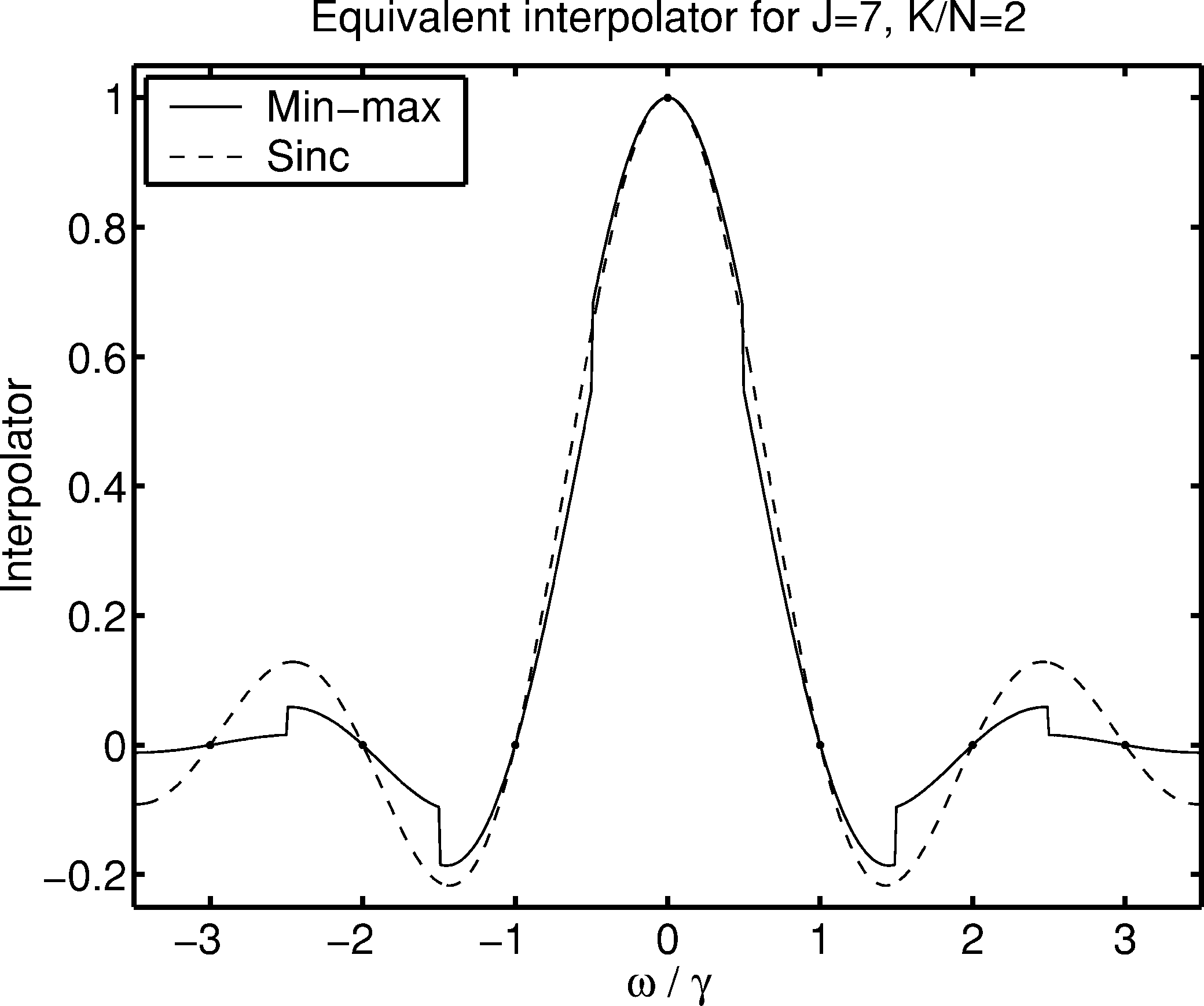
图2 展示了J=7、N=128、K/N=2和均匀缩放因子条件下的最小最大插值器。对于奇数J,最小最大插值器在DFT样本之间的中点处有不连续性,因为在该点邻域发生变化。这些特性与经典插值器有很大差异,但它们不必令人惊讶,因为规律性不是最小最大公式的一部分。
图3:不同J和K/N值的最大误差
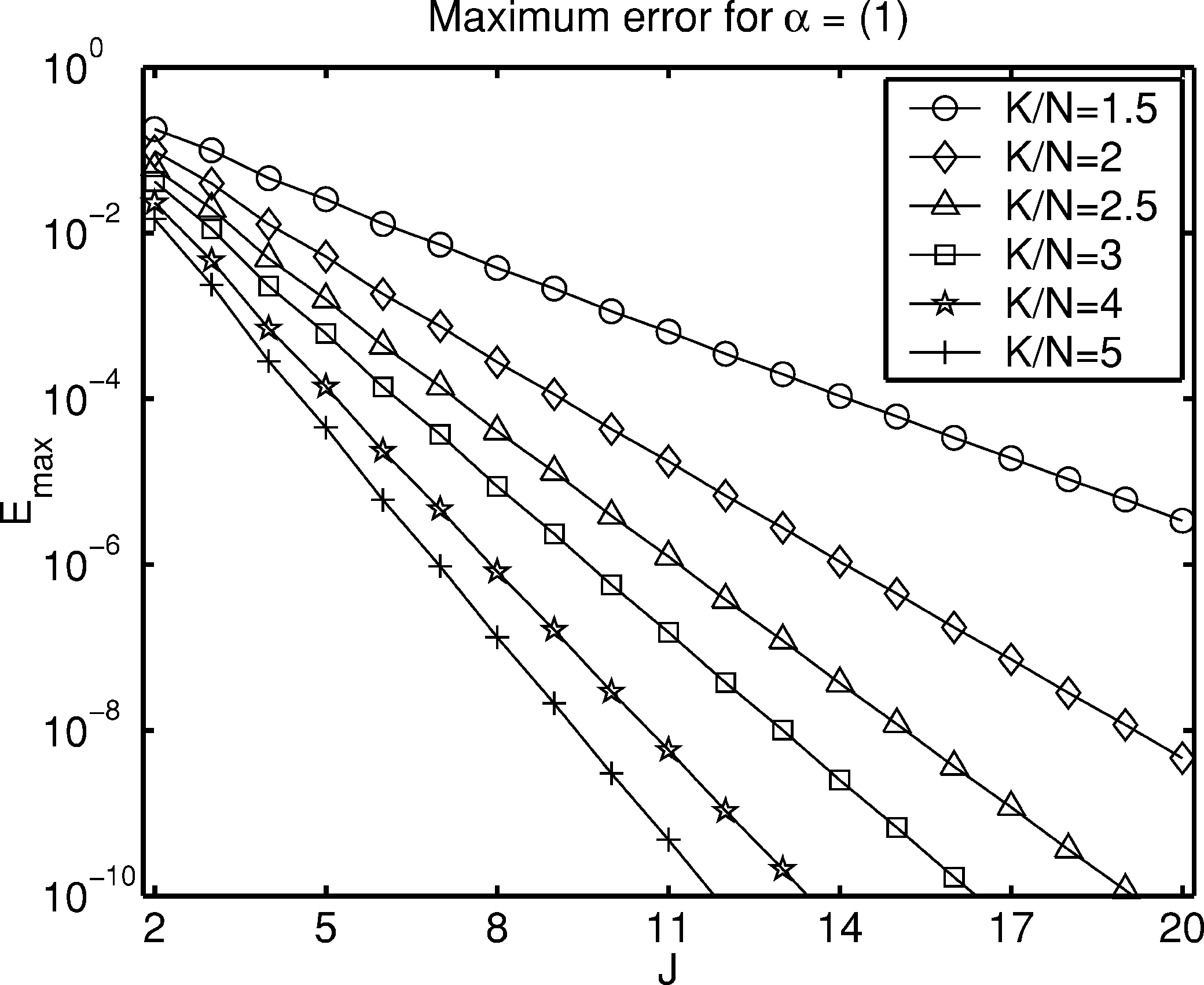
图3 绘制了使用均匀缩放向量(s=1)时,各种邻域大小J和过采样因子K/N的最小最大插值器的最大误差 Emax\mathcal{E}_{\max}Emax。图中显示了从K/N=1.5到K/N=5的多条曲线。如预期的那样,增加K或J会减少误差,但收益递减。通过检查许多这样的曲线,作者拟合了以下经验公式:
Emax≈0.75exp(−J[0.29+1.03log(KN)])\mathcal{E}_{\max} \approx 0.75 \exp\left(-J\left[0.29 + 1.03 \log\left(\frac{K}{N}\right)\right]\right)Emax≈0.75exp(−J[0.29+1.03log(NK)])
图6:缩放向量优化的效果
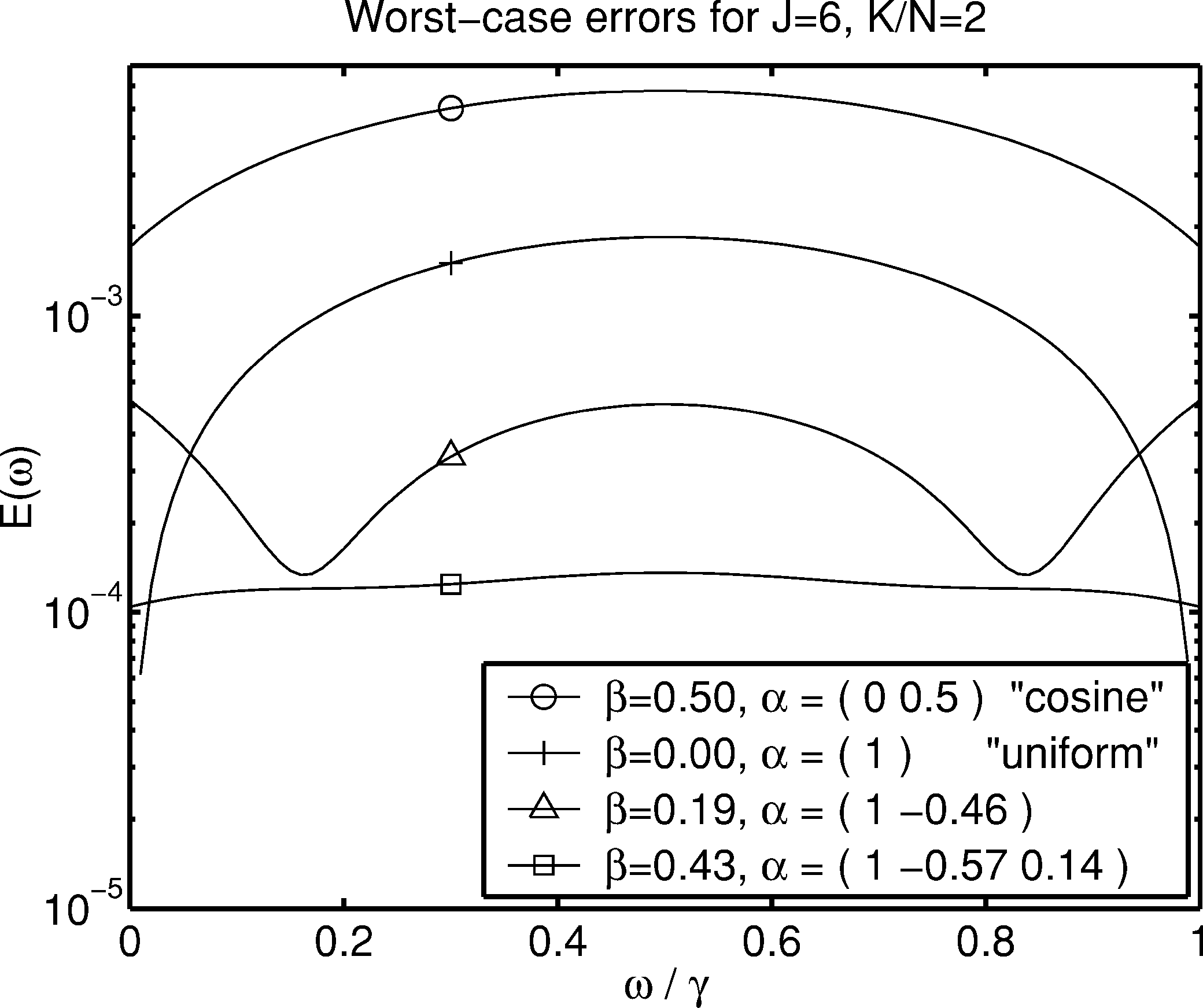
图6 比较了各种缩放向量的最坏情况误差。图中展示了三种情况:均匀缩放因子(β=0.50,α=(0,0.5)\beta=0.50, \alpha=(0, 0.5)β=0.50,α=(0,0.5)),优化的缩放因子(β=0.00,α=(1)\beta=0.00, \alpha=(1)β=0.00,α=(1)),以及具有特定参数的情况。优化的缩放因子倾向于平衡DFT样本处和中点处的误差。实践中这种特性更可取,因为期望的频率位置通常具有本质上的随机位置。
与传统插值方法的详细比较
截断的Dirichlet插值器
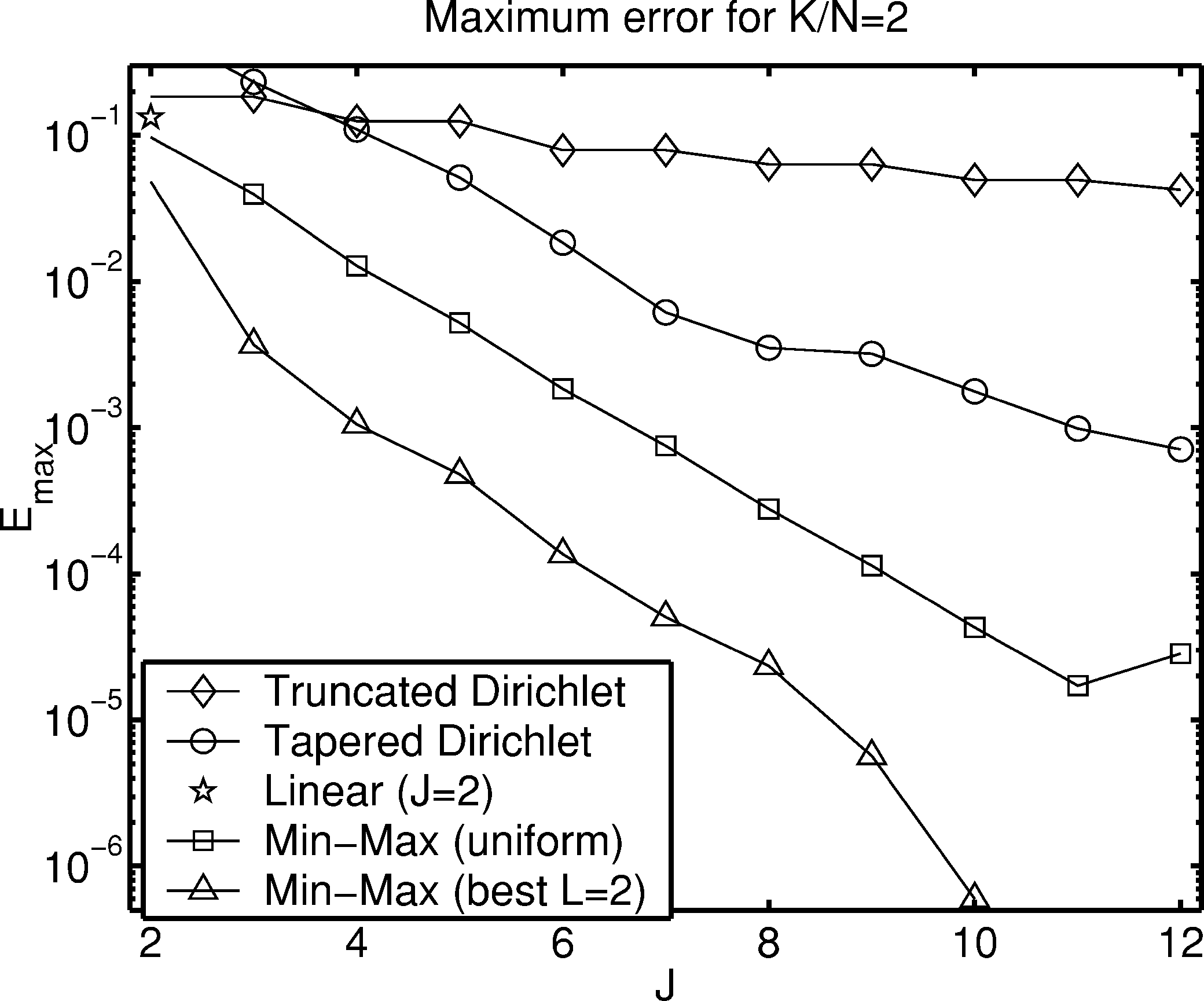
图8展示了截断Dirichlet插值器、cos2\cos^2cos2锥形Dirichlet插值器、线性插值器(J=2)和最小最大插值器在各种邻域大小J和过采样因子K/N=2下的最大误差。尽管图1中存在相似性,但最小最大方法相对于截断或锥形Dirichlet显著减少了误差。对于J=6,最小最大插值器的误差比截断Dirichlet低约两个数量级。
高斯钟形插值器
许多NUFFT论文都关注使用截断高斯钟形插值的方法:
ψ(κ)=e−(κ/σ)2/2rect(κγJ)\psi(\kappa) = e^{-(\kappa/\sigma)^2/2} \text{rect}\left(\frac{\kappa}{\gamma J}\right)ψ(κ)=e−(κ/σ)2/2rect(γJκ)
图9比较了最小最大插值器和优化高斯钟形插值的最大误差。对于每个J,通过穷举搜索在数值上优化了高斯钟形宽度σ以最小化最坏情况误差。图中显示了最小最大方法的三种缩放因子选择:均匀、数值优化和对优化高斯钟形的LS拟合。
Kaiser-Bessel插值器
Kaiser-Bessel函数在成像问题的"网格化"方法中很受欢迎:
ψ(κ)=(12)mπd/2(J2)dαmΛ(z(κ))Im(α)\psi(\kappa) = \left(\frac{1}{2}\right)^m \pi^{d/2} \left(\frac{J}{2}\right)^d \alpha^m \frac{\Lambda(z(\kappa))}{I_m(\alpha)}ψ(κ)=(21)mπd/2(2J)dαmIm(α)Λ(z(κ))
其中 ImI_mIm 表示m阶修正贝塞尔函数。图12比较了(优化的)Kaiser-Bessel插值器、(优化的)高斯钟形插值器和几个最小最大插值器的最大误差。对于这里研究的缩放因子选择(特别是最小二乘拟合方法),相对于Kaiser-Bessel插值器的误差减少为30-50%。
二维和多维扩展
最小最大方法向二维和更高维度的扩展在概念上非常直接。在二维中,我们在两个方向上对二维FFT进行过采样,并为每个期望的频率位置预计算和存储最小最大插值器,使用最近的J×J个样本位置。
对于二维图像,如果使用J₁×J₂的邻域,过采样因子分别为K₁/N₁和K₂/N₂,则矩阵变为Kronecker积:
C(2)=C(1)(N2)⊗C(1)(N1)\mathbf{C}^{(2)} = \mathbf{C}^{(1)}(N_2) \otimes \mathbf{C}^{(1)}(N_1)C(2)=C(1)(N2)⊗C(1)(N1)
S(2)=diag{sn2}⊗diag{sn1}\mathbf{S}^{(2)} = \text{diag}\{s_{n_2}\} \otimes \text{diag}\{s_{n_1}\}S(2)=diag{sn2}⊗diag{sn1}
Λ(2)=Λ(1)(ω2)⊗Λ(1)(ω1)\Lambda^{(2)} = \Lambda^{(1)}(\omega_2) \otimes \Lambda^{(1)}(\omega_1)Λ(2)=Λ(1)(ω2)⊗Λ(1)(ω1)
b(2)=b(1)(ω2)⊗b(1)(ω1)\mathbf{b}^{(2)} = \mathbf{b}^{(1)}(\omega_2) \otimes \mathbf{b}^{(1)}(\omega_1)b(2)=b(1)(ω2)⊗b(1)(ω1)
因此 T\mathbf{T}T 矩阵变为:
T2D=T1D(J2,μ2)⊗T1D(J1,μ1)\mathbf{T}_{2D} = \mathbf{T}_{1D}(J_2, \mu_2) \otimes \mathbf{T}_{1D}(J_1, \mu_1)T2D=T1D(J2,μ2)⊗T1D(J1,μ1)
实际应用:二维示例
为了说明NUFFT方法在实际环境中的准确性,作者考虑了经典的128×128 Shepp-Logan图像。他们在 [−π,π]×[−π,π][-\pi, \pi] \times [-\pi, \pi][−π,π]×[−π,π] 中生成了10,000个随机频率位置 (ωms)(\omega_{m}^s)(ωms),并精确计算了二维傅里叶变换(在Matlab的双精度范围内),同时使用J=6和K/N=2的最小最大二维NUFFT方法进行计算。
相对百分比误差定义为:
maxm∣X^(ωm)−X(ωm)∣maxm∣X(ωm)∣×100%\frac{\max_m |\hat{X}(\omega_m) - X(\omega_m)|}{\max_m |X(\omega_m)|} \times 100\%maxm∣X(ωm)∣maxm∣X^(ωm)−X(ωm)∣×100%
使用均匀缩放因子时,误差小于0.14%。使用表II中L=2的优化缩放因子时,误差小于0.011%。当缩放因子基于Kaiser-Bessel缩放因子的最小二乘拟合时,误差小于2.1×10⁻⁴%。这些数量级的误差减少与图3和图12中显示的减少一致,确认了最小化最坏情况误差即使对于实际感兴趣的信号也能带来显著的误差减少。
精确FT方法需要的CPU时间是NUFFT方法的100多倍(由Matlab的tic/toc函数测量)。作为比较,这个问题的经典双线性插值产生6.7%的相对误差。这个大误差就是为什么线性插值对于通过傅里叶方法进行断层重投影不够准确的原因。
附录:深入的数学推导
附录A:最小最大插值器的完整推导
从误差表达式开始:
X^(ωm)−Xm=∑j=1JY[km+j]Kuj∗(ωm)−X(ωm)\hat{X}(\omega_m) - X_m = \sum_{j=1}^{J} Y_{[k_m+j]_K} u_j^*(\omega_m) - X(\omega_m)X^(ωm)−Xm=j=1∑JY[km+j]Kuj∗(ωm)−X(ωm)
使用矩阵形式,误差可以写为:
X^(ωm)−Xm=uH(ωm)Ym−xHdm\hat{X}(\omega_m) - X_m = \mathbf{u}^H(\omega_m) \mathbf{Y}_m - \mathbf{x}^H \mathbf{d}_mX^(ωm)−Xm=uH(ωm)Ym−xHdm
其中 dm\mathbf{d}_mdm 是具有元素 dm,n=e−iωmnd_{m,n} = e^{-i\omega_m n}dm,n=e−iωmn 的向量。
将公式(3)和(12)代入,误差表达式变为:
X^(ωm)−Xm=xH[uH(ωm)Gm−dm]\hat{X}(\omega_m) - X_m = \mathbf{x}^H [\mathbf{u}^H(\omega_m) \mathbf{G}_m - \mathbf{d}_m]X^(ωm)−Xm=xH[uH(ωm)Gm−dm]
其中 Gm\mathbf{G}_mGm 是N×J矩阵,元素为:
(Gm)n,j=sne−iγ(km+j)n(\mathbf{G}_m)_{n,j} = s_n e^{-i\gamma(k_m+j)n}(Gm)n,j=sne−iγ(km+j)n
定义以下矩阵和向量:
S=diag{sn},D(ω)=diag{eiωn}\mathbf{S} = \text{diag}\{s_n\}, \quad \mathbf{D}(\omega) = \text{diag}\{e^{i\omega n}\}S=diag{sn},D(ω)=diag{eiωn}
C 是 N×K⋅N 矩阵,Λ(ω) 是 J×J 对角矩阵\mathbf{C} \text{ 是 } N \times K \cdot N \text{ 矩阵,} \Lambda(\omega) \text{ 是 } J \times J \text{ 对角矩阵}C 是 N×K⋅N 矩阵,Λ(ω) 是 J×J 对角矩阵
b(ω) 是 N 维向量,具有相应的元素\mathbf{b}(\omega) \text{ 是 } N \text{ 维向量,具有相应的元素}b(ω) 是 N 维向量,具有相应的元素
Dnn(ω)=eiωneiγk0(ω)(n−n0)D_{nn}(\omega) = e^{i\omega n} e^{i\gamma k_0(\omega)(n-n_0)}Dnn(ω)=eiωneiγk0(ω)(n−n0)
Cn,j=eiγj(n−n0)NC_{n,j} = \frac{e^{i\gamma j(n-n_0)}}{\sqrt{N}}Cn,j=Neiγj(n−n0)
Λjj(ω)=e−i[ω−γk0(ω)+γj]n0\Lambda_{jj}(\omega) = e^{-i[\omega - \gamma k_0(\omega) + \gamma j]n_0}Λjj(ω)=e−i[ω−γk0(ω)+γj]n0
bn(ω)=ei[ω−γk0(ω)](n−n0)Nb_n(\omega) = \frac{e^{i[\omega - \gamma k_0(\omega)](n-n_0)}}{\sqrt{N}}bn(ω)=Nei[ω−γk0(ω)](n−n0)
在这种形式下,最小最大问题(11)变为:
minu∈CNmaxx∈CN:∥x∥2≤1N∣⟨x,q(ω)⟩∣\min_{\mathbf{u} \in \mathbb{C}^N} \max_{\mathbf{x} \in \mathbb{C}^N : \|\mathbf{x}\|_2 \leq 1} \sqrt{N} |\langle\mathbf{x}, \mathbf{q}(\omega)\rangle|u∈CNminx∈CN:∥x∥2≤1maxN∣⟨x,q(ω)⟩∣
通过Cauchy-Schwarz不等式,对于给定频率 ω\omegaω,最坏情况信号是:
x=q∗(ω)/∥q(ω)∥\mathbf{x} = \mathbf{q}^*(\omega) / \|\mathbf{q}(\omega)\|x=q∗(ω)/∥q(ω)∥
将此情况代入最小最大准则并应用相关公式,最小最大问题简化为:
minu(ω)∥S∗CΛ(ω)u(ω)−b(ω)∥2\min_{\mathbf{u}(\omega)} \|\mathbf{S}^* \mathbf{C} \Lambda(\omega) \mathbf{u}(\omega) - \mathbf{b}(\omega)\|^2u(ω)min∥S∗CΛ(ω)u(ω)−b(ω)∥2
这个普通最小二乘问题的最小值在 ω=ωm\omega = \omega_mω=ωm 处,其中:
u(ω)=A†(ω)C∗Sb(ω)\mathbf{u}(\omega) = \mathbf{A}^{†}(\omega) \mathbf{C}^* \mathbf{S} \mathbf{b}(\omega)u(ω)=A†(ω)C∗Sb(ω)
其中 A=C∗S∗SC\mathbf{A} = \mathbf{C}^* \mathbf{S}^* \mathbf{S} \mathbf{C}A=C∗S∗SC。
附录B:高效计算的详细推导
为了有效计算,我们将 sns_nsn 展开为傅里叶级数:
sn=∑l=−LLαleiγβ(n−n0),n=0,…,N−1s_n = \sum_{l=-L}^{L} \alpha_l e^{i\gamma\beta(n-n_0)}, \quad n = 0, \ldots, N-1sn=l=−L∑Lαleiγβ(n−n0),n=0,…,N−1
将此展开代入 Cn,j∗\mathbf{C}_{n,j}^*Cn,j∗ 的定义:
Cn,j∗=∑l=−LL∑s=−LLαl∗αseiγ[βl+β(t−l)](n−n0)ujj(ω)\mathbf{C}_{n,j}^* = \sum_{l=-L}^{L} \sum_{s=-L}^{L} \alpha_l^* \alpha_s e^{i\gamma[\beta l + \beta(t-l)](n-n_0)} u_{jj}(\omega)Cn,j∗=l=−L∑Ls=−L∑Lαl∗αseiγ[βl+β(t−l)](n−n0)ujj(ω)
经过一系列代数运算,我们得到:
Cn,j∗=∑l=−LL∑s=−LLαl∗αsδN(j−l+β(t−s))\mathbf{C}_{n,j}^* = \sum_{l=-L}^{L} \sum_{s=-L}^{L} \alpha_l^* \alpha_s \delta_N(j - l + \beta(t - s))Cn,j∗=l=−L∑Ls=−L∑Lαl∗αsδN(j−l+β(t−s))
其中 δN(⋅)\delta_N(\cdot)δN(⋅) 是之前定义的Dirichlet类函数。
类似地,对于 r(ω)=D(ω)[S∗CΛ(ω)u(ω)−b(ω)]\mathbf{r}(\omega) = \mathbf{D}(\omega) [\mathbf{S}^* \mathbf{C} \Lambda(\omega) \mathbf{u}(\omega) - \mathbf{b}(\omega)]r(ω)=D(ω)[S∗CΛ(ω)u(ω)−b(ω)]:
rj(ω)=∑n=0N−1Cn,j∗snbn(ω)=∑t=−LLαt1N∑n=0N−1eiγ[ω/γ−k0(ω)−j+βt](n−n0)r_j(\omega) = \sum_{n=0}^{N-1} C_{n,j}^* s_n b_n(\omega) = \sum_{t=-L}^{L} \alpha_t \frac{1}{N} \sum_{n=0}^{N-1} e^{i\gamma[\omega/\gamma - k_0(\omega) - j + \beta t](n-n_0)}rj(ω)=n=0∑N−1Cn,j∗snbn(ω)=t=−L∑LαtN1n=0∑N−1eiγ[ω/γ−k0(ω)−j+βt](n−n0)
=∑t=−LLαtδN(ωγ−k0(ω)−j+βt)= \sum_{t=-L}^{L} \alpha_t \delta_N\left(\frac{\omega}{\gamma} - k_0(\omega) - j + \beta t\right)=t=−L∑LαtδN(γω−k0(ω)−j+βt)
附录C:误差界的严格分析
组合方程(20)和(21)并简化,得到频率 ω\omegaω 处的最坏情况误差:
Eexact(ω)N=∥S∗[C∗SS∗C]−1C∗Sb(ω)−b(ω)∥\frac{\mathcal{E}_{\text{exact}}(\omega)}{\sqrt{N}} = \|\mathbf{S}^* [\mathbf{C}^* \mathbf{S} \mathbf{S}^* \mathbf{C}]^{-1} \mathbf{C}^* \mathbf{S} \mathbf{b}(\omega) - \mathbf{b}(\omega)\|NEexact(ω)=∥S∗[C∗SS∗C]−1C∗Sb(ω)−b(ω)∥
=∥(I−QQ†)b(ω)∥= \|(\mathbf{I} - \mathbf{Q} \mathbf{Q}^{†}) \mathbf{b}(\omega)\|=∥(I−QQ†)b(ω)∥
其中 Q\mathbf{Q}Q 在(23)中定义。NUFFT论文中给出的误差界通常被描述为悲观的。相比之下,(40)给出的精确最坏情况误差是可达到的。当然,达到这个最坏情况误差的单位范数信号可能不代表许多感兴趣的问题。
或者,组合(25)和(20)得到:
Eexact(ω)N=1−r†(ω)T−1r(ω)\frac{\mathcal{E}_{\text{exact}}(\omega)}{\sqrt{N}} = \sqrt{1 - \mathbf{r}^{†}(\omega) \mathbf{T}^{-1} \mathbf{r}(\omega)}NEexact(ω)=1−r†(ω)T−1r(ω)
当 J<10−K/NJ < 10 - K/NJ<10−K/N 时,简单形式(41)通常是充分的。对于较大的J,平方根内的减法在数值上是不精确的,所以我们恢复到(40)。
附录D:多维Kronecker积形式
对于d维信号,最小最大插值器的形式变为d个一维插值器的Kronecker积:
u(d)=u(1)(ωd)⊗u(1)(ωd−1)⊗⋯⊗u(1)(ω1)\mathbf{u}^{(d)} = \mathbf{u}^{(1)}(\omega_d) \otimes \mathbf{u}^{(1)}(\omega_{d-1}) \otimes \cdots \otimes \mathbf{u}^{(1)}(\omega_1)u(d)=u(1)(ωd)⊗u(1)(ωd−1)⊗⋯⊗u(1)(ω1)
相应的误差为:
EdD=∏i=1dE1D(ωi)\mathcal{E}_{d\text{D}} = \prod_{i=1}^{d} \mathcal{E}_{1\text{D}}(\omega_i)EdD=i=1∏dE1D(ωi)
这给出了相对于一维的二维潜在精度"惩罚"的上界。它还表明,良好的一维最小最大插值器的张量积应该在更高维度上工作良好。
附录E:缩放因子优化的数值方法
理想情况下,我们希望使用以下准则选择缩放因子:
mins∈CNmaxωE(ω)\min_{\mathbf{s} \in \mathbb{C}^N} \max_{\omega} \mathcal{E}(\omega)s∈CNminωmaxE(ω)
不幸的是,这个优化问题的解析解已被证明是难以捉摸的。对于理想插值器(5),均匀缩放因子是最优的。直觉上,对于良好的插值器,sns_nsn 应该相当平滑,所以(28)中的低阶展开应该足够。
使用级数展开(28)并表示 Emax\mathcal{E}_{\max}Emax 对傅里叶级数系数 α\alphaα 和 β\betaβ 的依赖,对于给定的L,我们希望求解:
minα,βEmax(α,β)\min_{\alpha, \beta} \mathcal{E}_{\max}(\alpha, \beta)α,βminEmax(α,β)
由于缺乏解析解,作者通过对小L值联合搜索 β\betaβ 和 {αl}\{\alpha_l\}{αl} 来数值探索这种最小化。例如,对于L=2、J=6和K/N=2的情况,他们在 [−0.8,0.8]×[−0.8,0.8][-0.8, 0.8] \times [-0.8, 0.8][−0.8,0.8]×[−0.8,0.8] 上联合搜索 α1\alpha_1α1 和 α2\alpha_2α2。最佳 β\betaβ 是0.19,图4绘制了该 β\betaβ 的 Emax\mathcal{E}_{\max}Emax 与 α1\alpha_1α1 的关系。最小值在 α1=−0.46\alpha_1 = -0.46α1=−0.46 而不是0,所以显然均匀缩放因子是次优的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)