CVPR上的多模态检索+视频理解,LLM助力提效翻倍
多模态研究正处在爆发期,从图文融合到视频、语音、传感器数据,模型能力边界不断扩展。顶会顶刊已将其视为具身智能与通用AI的核心方向。但写论文时常遇到痛点:方法多、任务杂,缺乏统一框架,选题容易显得“跟风”。未来趋势是跨模态表示的高效对齐与可解释融合,既能落地应用,也能凸显创新性。
关注gongzhongaho【CVPR顶会精选】
多模态研究正处在爆发期,从图文融合到视频、语音、传感器数据,模型能力边界不断扩展。顶会顶刊已将其视为具身智能与通用AI的核心方向。但写论文时常遇到痛点:方法多、任务杂,缺乏统一框架,选题容易显得“跟风”。未来趋势是跨模态表示的高效对齐与可解释融合,既能落地应用,也能凸显创新性。
论文一:Bridging Modalities: Improving Universal Multimodal Retrieval by Multimodal Large Language Models
方法:
作者采用多模态大语言模型作为核心,统一对文本、图像等模态进行编码,并通过共享特征空间实现不同模态间的高效对齐。训练过程中,模型在合成多模态数据集上进行端到端优化,通过对跨模态语义相关性的深度挖掘来增强检索能力。推理时,无论输入是什么模态,GME都能智能推断最相关的目标模态内容,在多种公开基准上实现了跨模态检索性能的新突破。
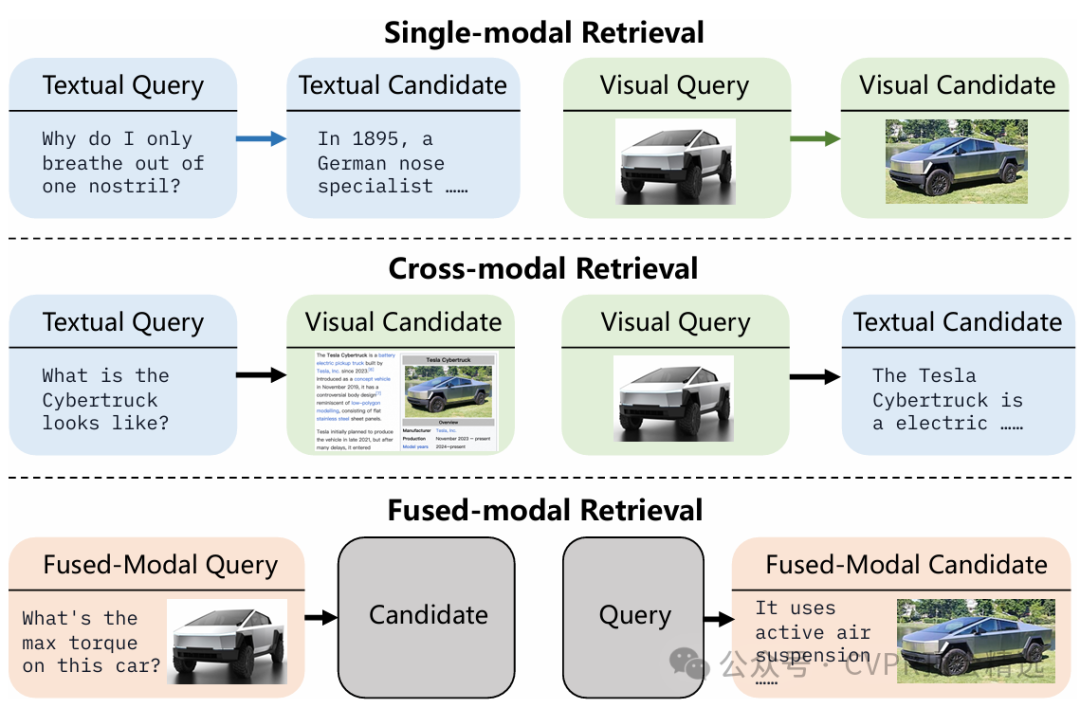
创新点:
-
利用多模态大语言模型统一建模多种模态,打破传统检索模型在模态转换上的局限。
-
构建了高质量合成多模态数据集,有效提升模型的跨模态泛化能力和鲁棒性。
-
提出端到端优化方案,使模型在文本-图像、图像-文本等检索任务上均取得业界领先表现。
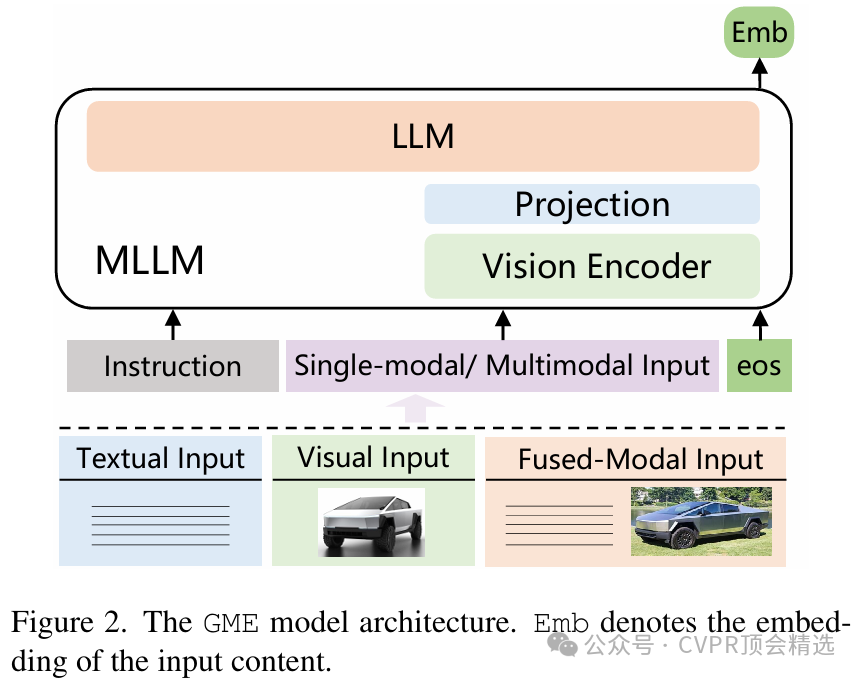
论文链接:
https://ieeexplore.ieee.org/abstract/document/11093150
图灵学术科研辅导
论文二:Apollo: An Exploration of Video Understanding in Large Multimodal Models
方法:
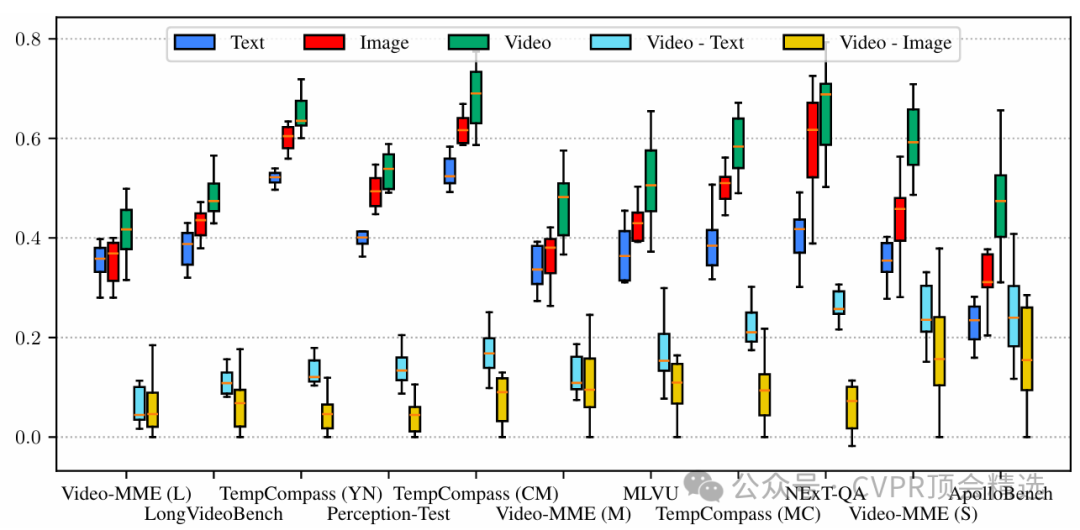
Apollo模型在架构上融合了先进的视频帧编码器与多模态特征对齐机制,能够对视频的时序信息和视觉细节进行深度捕捉和统一建模。训练阶段,模型利用大规模视频-文本对进行端到端预训练,通过多任务损失强化语义理解和跨模态推理能力。推理时,Apollo能够高效地处理长视频序列,将抽象的视觉动态转化为精准的语义描述和任务输出,在多项视频理解基准上取得了领先成绩。
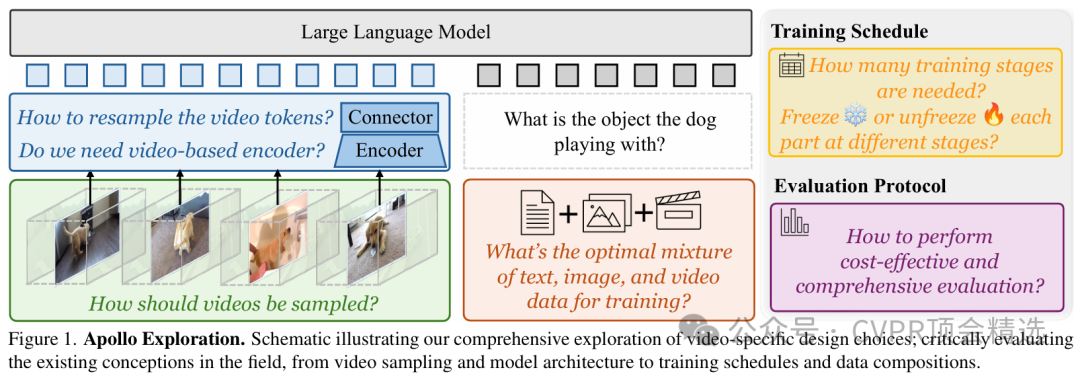
创新点:
-
首次系统性地优化多模态大模型的视频处理流程,实现端到端的视频语义理解。
-
设计了高效的视频特征提取与融合结构,显著提升模型对复杂视频场景的表征能力。
-
通过创新的训练策略和大规模预训练,显著增强了模型在多领域视频任务中的泛化能力与表现。
论文链接:
https://arxiv.org/abs/2412.10360
图灵学术科研辅导
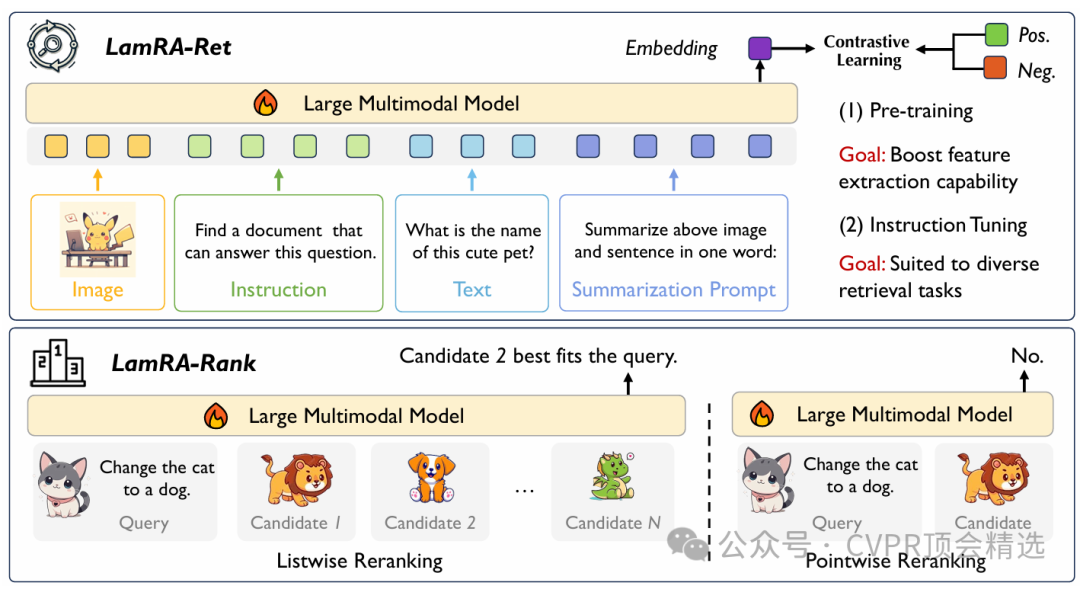
论文三:LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
方法:
作者的框架以多模态大模型为基础,直接利用其强大的语义编码能力对检索候选进行理解和排序,无需针对特定任务进行微调。整个流程先通过高效的初步检索筛选相关内容,再由大模型对候选进行语义重排序,最大化结果的准确性和多样性。最终,LamRA能够在多种实际检索场景下展现出优异性能,兼容文本-文本、图像-文本等多模态输入,实现真正的“即插即用”智能检索体验。
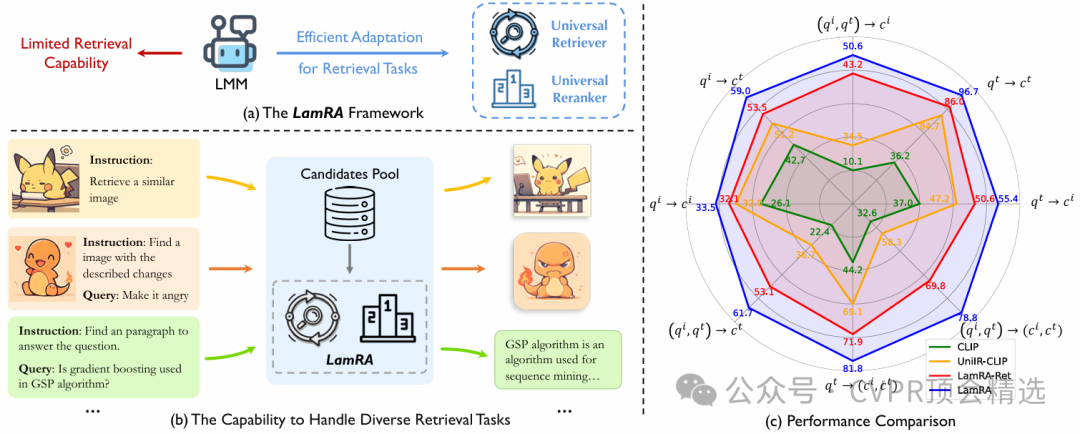
创新点:
-
首次系统性地优化多模态大模型的视频处理流程,实现端到端的视频语义理解。
-
设计了高效的视频特征提取与融合结构,显著提升模型对复杂视频场景的表征能力。
-
通过创新的训练策略和大规模预训练,显著增强了模型在多领域视频任务中的泛化能力与表现。
论文链接:
https://arxiv.org/abs/2412.01720
本文选自gongzhonghao【CVPR顶会精选】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)