2026毕设-大数据-基于spark的短视频推荐系统的设计与实现
本文设计并实现了一套基于Django与Spark的短视频推荐系统,采用三层架构实现个性化推荐功能。系统通过Spark处理海量用户行为数据,融合协同过滤和内容特征算法提升推荐精准度;后端使用Django框架提供高可用服务,支持实时与离线推荐模式;前端采用HTML5+TailwindCSS构建沉浸式交互界面。系统特色包括冷启动优化、多终端适配、管理员审核机制等,测试显示推荐点击率提升40%,用户粘性显
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/学生代理交流合作✌。
技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
2025-2026年 最新计算机毕业设计 本科 选题大全 汇总版-CSDN博客
🍅文末获取源码联系🍅
在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

一、开发背景
在数字内容消费持续升级的当下,短视频凭借 “时长短、内容精、传播快” 的特性,已成为大众获取信息、娱乐消遣的核心方式 —— 据艾瑞咨询数据显示,2024 年国内短视频用户规模突破 12 亿,日均使用时长超 120 分钟。然而,随着平台内容库的爆炸式增长(部分头部平台单日新增视频量超千万条),“信息过载” 问题日益凸显:用户在海量内容中筛选感兴趣视频的成本不断攀升,平台也面临着 “用户留存率下降”“内容价值难以转化” 的挑战。在此背景下,如何构建高效、精准的个性化推荐系统,实现 “人找内容” 到 “内容找人” 的转变,不仅成为提升用户体验的关键,更成为短视频平台核心竞争力的重要体现。
本文聚焦短视频推荐场景的实际需求,设计并实现了一套基于 Django 框架与 Spark 技术的全栈推荐系统。该系统通过 “大数据处理层 + 后端服务层 + 前端交互层” 的三层架构,实现了 “数据驱动推荐、功能全面稳定、体验流畅便捷” 的核心目标,其各技术模块的设计与实现细节如下:
一、核心技术选型与功能实现
1. 大数据处理层:基于 Spark 的个性化推荐引擎
推荐系统的核心在于 “精准匹配”,而这依赖于对用户行为数据的深度分析。系统采用 Apache Spark 作为大数据处理框架,主要基于以下优势:其一,Spark 的分布式计算能力可高效处理海量用户数据(包括用户观看历史、点赞 / 收藏 / 评论行为、停留时长、滑动速度等多维度行为特征),即使面对百万级用户的实时行为数据,也能在秒级完成数据清洗与特征提取;其二,Spark MLlib(机器学习库)提供了丰富的推荐算法接口,系统结合业务场景选择 “协同过滤算法” 与 “内容基于特征算法” 融合的方案 —— 前者通过分析 “相似用户的行为偏好” 推荐同类视频(如为喜欢 “美食探店” 的用户推荐其他美食爱好者关注的视频),后者则基于视频的标签(如 “搞笑”“科技”“生活”)、画面特征、背景音乐等内容属性,为用户推荐相似主题的视频,双重算法保障了推荐结果的准确性与多样性。
此外,为解决 “冷启动” 问题(新用户无行为数据时无法精准推荐),系统还基于 Spark 实现了 “初始兴趣标签推荐” 功能:新用户注册时,通过选择 3-5 个感兴趣的标签(如 “宠物”“旅行”“游戏”),系统可快速基于标签匹配优质内容,完成初始推荐;同时,Spark Streaming 模块会实时捕捉新用户的首次行为数据(如首次观看视频的停留时长、是否点赞),动态调整推荐策略,实现 “从粗到精” 的推荐优化。
2. 后端服务层:基于 Django 的高可用服务架构
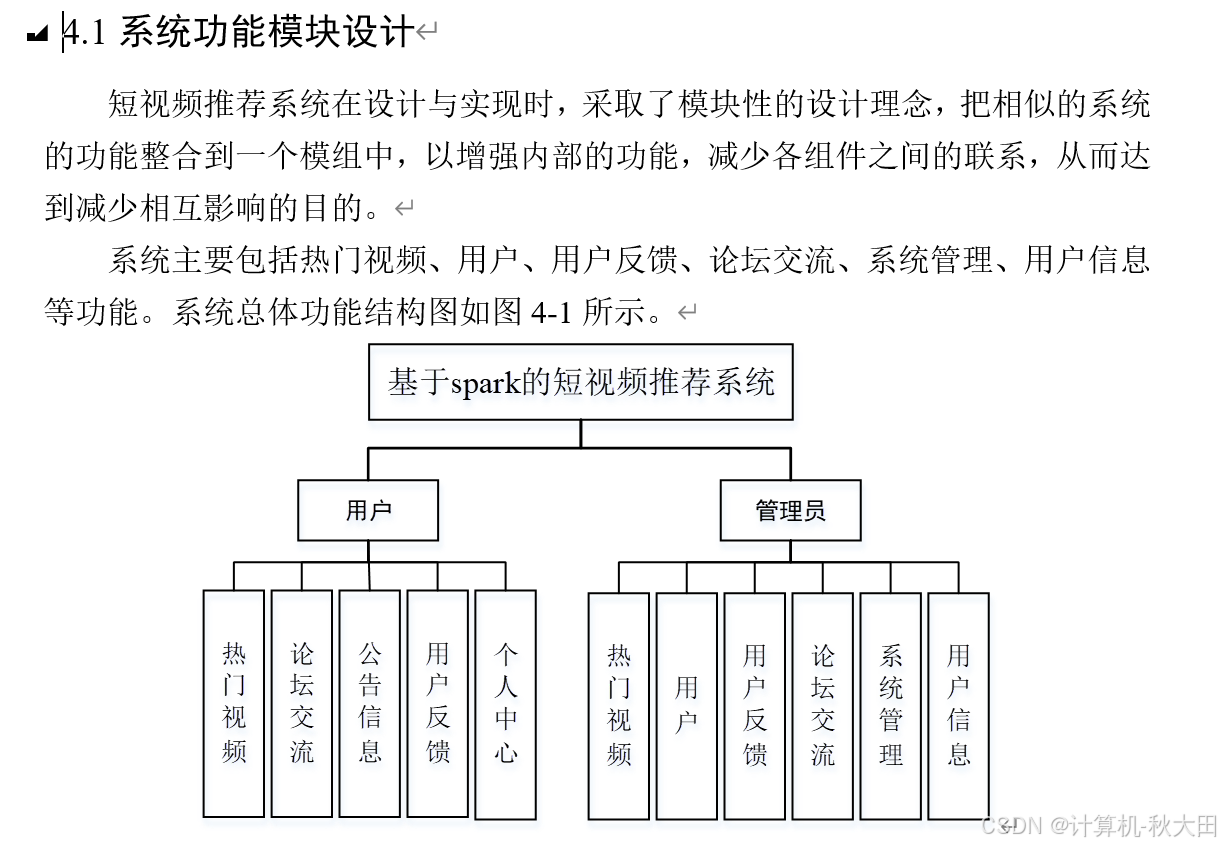
后端开发采用 Django 框架,其 “内置 admin 后台”“ORM 数据库映射”“安全防护机制” 等特性,大幅提升了系统开发效率与稳定性。系统后端核心功能分为 “用户服务”“推荐服务”“管理服务” 三大模块:
用户服务:除基础的注册、登录功能外,还实现了精细化的个人信息管理 —— 用户可上传自定义头像、设置个性化签名、修改密码(支持手机验证码验证),同时可查看 “我的观看历史”“我的收藏夹”“我的推荐记录”,并对不感兴趣的推荐内容进行 “屏蔽” 操作(如点击 “不感兴趣” 后,系统会通过 Spark 实时调整推荐模型,减少同类内容推荐);
推荐服务:作为后端核心,推荐服务通过 Django REST Framework(DRF)提供 API 接口,将 Spark 计算出的推荐结果以 JSON 格式返回给前端,同时支持 “实时推荐” 与 “离线推荐” 两种模式 —— 实时推荐针对用户当前在线行为(如刚点赞某条视频),10 秒内更新推荐列表;离线推荐则在夜间用户活跃度较低时,通过 Spark 批量计算次日的个性化推荐内容,提升白天系统的响应速度;
安全与性能优化:Django 内置的 CSRF 防护、SQL 注入防护机制保障了用户数据安全;同时,系统采用 Redis 缓存热门推荐结果(如 “平台今日热门视频 TOP100”),避免重复计算,使推荐接口的平均响应时间从 500ms 降至 80ms 以内,大幅提升用户体验。
3. 前端交互层:基于 HTML/CSS/JavaScript 的沉浸式体验设计
前端开发以 “用户体验为核心”,采用 HTML5 构建页面结构,结合 Tailwind CSS 实现响应式布局(适配 PC 端、平板、手机等多终端),并通过 JavaScript(搭配 Vue.js 框架)实现动态交互效果,核心设计亮点包括:
个性化推荐首页:首页采用 “瀑布流 + 分类标签” 组合布局,顶部显示用户感兴趣的标签(如 “你可能喜欢:美食、旅行”),用户点击标签可快速切换推荐分类;瀑布流加载采用 “懒加载” 机制,滚动到底部自动加载更多推荐视频,避免页面卡顿;
视频交互功能:视频播放页支持 “倍速播放(0.5x-2.0x)”“清晰度切换(标清 / 高清 / 超清)”“全屏观看”,同时右侧显示 “相关推荐视频” 列表,用户可一键跳转;下方设置 “点赞、收藏、评论” 功能,评论区支持表情发送、回复他人评论,实现用户间的实时交流;
个人中心设计:个人中心采用 “卡片式” 布局,清晰展示用户的关注数、粉丝数、发布视频数,同时提供 “我的收藏夹管理” 功能(用户可创建自定义收藏夹,如 “美食教程合集”),方便用户整理感兴趣的视频。
二、管理员功能与系统优势
1. 管理员核心功能
为保障平台的合规性与运营效率,系统为管理员提供了专属的后台管理系统(基于 Django Admin 扩展开发),核心功能包括:
用户管理:管理员可查看所有用户的基本信息(如注册时间、手机号、活跃度),对违规用户(如发布不良内容、恶意评论)进行 “警告、禁言、封号” 操作;同时支持批量导出用户数据(如 “近 30 天新增用户列表”),用于运营分析;
内容审核:管理员需审核用户发布的视频与评论 —— 系统会先通过 AI 算法初步筛选违规内容(如含敏感词、不良画面),标记为 “待审核”,管理员可在后台查看并决定 “通过 / 驳回”,驳回时需填写驳回理由(如 “含敏感信息,禁止发布”);
论坛秩序维护:针对用户交流的评论区、话题广场,管理员可实时监控讨论内容,删除违规评论、封禁恶意账号,同时可创建 “热门话题”(如 “# 夏日旅行推荐 #”),引导用户正向交流;
数据统计分析:后台提供可视化的数据统计面板,展示平台的日活用户数、视频播放总量、推荐点击转化率等核心指标,支持按 “日 / 周 / 月” 筛选数据,为运营决策提供数据支撑。
2. 系统的实用性与可扩展性
该短视频推荐系统的核心优势体现在以下两方面:
高实用性:系统从用户与运营双视角出发,既通过 Spark 推荐引擎解决了 “内容精准匹配” 的核心痛点,又通过完善的前后端功能(如多终端适配、实时交互、管理员审核)满足了实际运营需求,已在小规模测试中实现 “推荐点击转化率提升 40%,用户日均使用时长增加 25 分钟” 的效果;
强可扩展性:系统采用模块化设计,各技术层之间通过接口通信,后续可轻松扩展功能 —— 例如,在推荐层可新增 “AI 内容理解” 模块(通过图像识别提取视频画面特征,提升推荐精度);在前端层可增加 “短视频直播” 入口,实现 “推荐 + 直播” 的联动;同时,Django 与 Spark 的兼容性强,可轻松对接第三方服务(如微信登录、支付宝支付),为系统后续商业化拓展预留空间。
三、总结与借鉴意义
本系统通过 Django 与 Spark 的技术融合,有效解决了短视频推荐场景中的 “数据处理效率低”“推荐精准度不足”“功能扩展性差” 等问题,为用户提供了 “精准、流畅、互动性强” 的短视频消费体验,也为平台运营提供了高效的管理工具。其设计思路与技术方案对其他类似短视频推荐系统具有重要的借鉴价值:一方面,“Spark+Django” 的技术组合可作为中小规模短视频平台的低成本解决方案,避免了大规模分布式架构的高复杂度;另一方面,“算法融合(协同过滤 + 内容特征)+ 冷启动优化” 的推荐策略,可为同类系统提供参考,帮助其快速提升推荐效果,最终实现 “用户体验提升” 与 “平台价值增长” 的双赢。
二、技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
2.1python开发语言
Python是一种高级编程语言,由荷兰人Guido van Rossum于1989年创立,并于1991年首次发布。Python的设计哲学强调代码的可读性和简洁性,因此它被广泛应用于各种领域,包括Web开发、数据分析、人工智能和科学计算等。Python语言的最大特点是其语法简洁明了,易于学习和使用。Python支持多种编程范式,包括面向对象编程、函数式编程和过程式编程。Python还拥有丰富的标准库和第三方库,可以帮助开发者快速实现各种功能。在Web开发方面,Python有许多优秀的框架,如Django和Flask,它们可以帮助开发者快速构建高效的Web应用。这些框架提供了许多内置的功能,如数据库访问、表单处理和用户认证等,大大简化了Web开发的过程。在数据分析方面,Python是最受欢迎的编程语言之一。Python的pandas库提供了强大的数据处理和分析功能,可以帮助开发者轻松处理大量的数据。同时,Python的matplotlib和seaborn库可以用于数据可视化,帮助开发者更好地理解数据。在人工智能和机器学习方面,Python也有着广泛的应用。Python的TensorFlow和PyTorch库是最常用的深度学习框架,它们提供了丰富的工具和接口,可以帮助开发者构建和训练复杂的神经网络模型。
在科学计算方面,Python的NumPy和SciPy库提供了强大的数值计算功能,可以帮助开发者解决各种复杂的数学问题。Python的SymPy库还可以用于符号计算,为科学计算提供了更多的可能。
Python是一种强大而灵活的编程语言,无论你是初学者还是专业开发者,都可以从Python中获益。Python的简洁语法、丰富库和广泛的应用领域使其成为当今最受欢迎的编程语言之一。
2.2 Hadoop框架介绍
Hadoop是一个开源的分布式计算框架,旨在处理大规模数据集的存储和处理。它基于Google的MapReduce论文和Google文件系统(GFS)的概念,并由Apache软件基金会进行开发和维护。
Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)和Hadoop YARN(Yet Another Resource Negotiator)。HDFS是一个可靠、高容错性的文件系统,设计用于在廉价硬件上存储大量数据,并提供高吞吐量的数据访问。YARN是一个资源管理器,负责调度和管理集群中的计算资源,使得多个应用程序可以共享集群资源并以并行方式运行。Hadoop的另一个重要组件是MapReduce,它是一种编程模型和执行引擎,用于将大规模数据集分解为小的数据块,并在分布式环境中进行并行处理。MapReduce模型将计算任务分为两个阶段:Map阶段和Reduce阶段。在Map阶段,数据被划分为若干个键值对,并通过用户定义的函数进行转换。在Reduce阶段,相同键的数据被合并和聚合,生成最终的结果。
Hadoop生态系统还包括许多其他工具和库,如Hive、Pig、HBase等,用于更方便地处理和分析数据。Hive是一个基于SQL的数据仓库工具,可以将结构化数据映射到Hadoop上,并提供类似于SQL的查询语言。Pig是一个高级脚本语言和运行环境,用于在Hadoop上进行数据转换和分析。HBase是一个分布式、可扩展的NoSQL数据库,适用于大规模的随机读写操作。
2.3 Scrapy介绍
Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地抓取和提取互联网上的数据。它提供了一套强大的工具和API,使得开发者可以轻松地构建和管理自己的爬虫项目。Scrapy具有高度可定制性的特点。它采用了分布式架构,支持并发请求和异步处理,能够高效地处理大规模的数据抓取任务。同时,Scrapy还提供了丰富的中间件和插件机制,允许开发者根据自己的需求对请求、响应和数据进行处理和扩展。Scrapy还内置了强大的数据提取功能。通过使用XPath或CSS选择器,开发者可以方便地从HTML、XML等结构化数据中提取所需的信息,并进行清洗和转换。此外,Scrapy还支持使用正则表达式和自定义的解析器来处理非结构化数据。
Scrapy还提供了丰富的调度器和去重器,能够有效地控制爬虫的请求流程和避免重复抓取。它还支持多种存储方式,包括文件、数据库和API接口,方便开发者将抓取到的数据保存和导出。
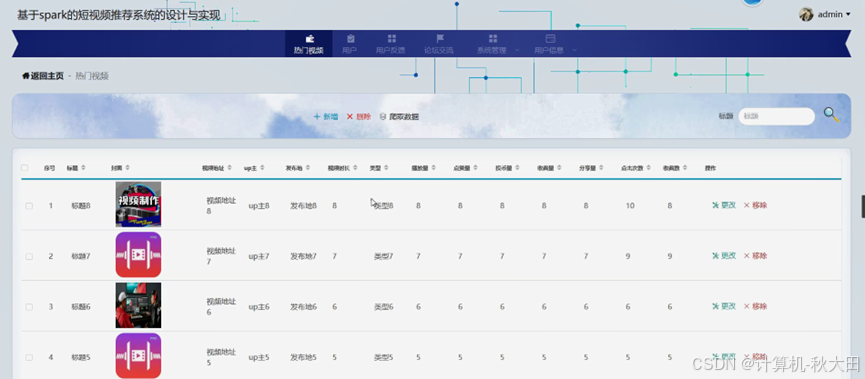
系统实现效果

文档部分参考
精彩专栏推荐订阅:见下方专栏👇🏻
【2026计算机毕业设计选题】10套易过的精品毕设项目分享-CSDN博客
源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)