智能客服agent (记录)
本文摘要:介绍了如何训练一个能够调用API的Agent大模型。首先创建conda环境并安装必要工具包,下载Qwen2-1.5B模型。通过修改配置文件设置模型路径,解决版本兼容问题后启动API服务。训练阶段配置参数并监控loss值,训练完成后合并Lora适配器。最后通过测试验证模型已具备调用垃圾分类、歌曲查询和动漫信息三种API工具的能力,实现从用户输入到API调用再到结果整合输出的完整流程。整个过
agent其实就是 会调用api的大模型,当用户输入信息之后自动匹配关键词,从而调用对应的api,然后agent结合api返回的内容一块输入给大模型。然后大模型整合之后再进行输出。在没有训练之前这个基座模型并不会调用api,在训练了之后可以调用了。具体的等总结完过程之后在更新。
第一步:在终端中安装所需包
在Jupyter Lab中打开一个新的终端,然后运行
# 1. 确保conda已初始化
conda init bash
source ~/.bashrc# 2. 创建并激活conda环境(如果还没创建)
conda create -n agent python=3.10 -y
conda activate agent# 3. 安装所有必需的包(使用国内镜像加速)
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install llamafactory -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install openai requests -i https://pypi.tuna.tsinghua.edu.cn/simple# 4. 验证安装
python -c "import vllm, llamafactory, modelscope, torch; print('所有包安装成功!')"
第二步:为agent环境创建Jupyter内核
# 在终端中继续运行(确保还在agent环境中)
pip install ipykernel
python -m ipykernel install --user --name agent --display-name "Python (agent)"第三步:切换Notebook到agent环境
-
回到你的Jupyter Notebook
-
点击右上角的内核名称(显示"Python 3"的地方)
-
选择新创建的
Python (agent) -
内核会自动重启
# 在终端中(确保在agent环境下)
conda activate agent
# 创建模型目录
mkdir -p /root/autodl-tmp/models# 使用modelscope下载模型(国内加速)
export USE_MODELSCOPE_HUB=1
然后在命令行中
python -c "
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-1.5B', cache_dir='/root/autodl-tmp/models')
print(f'模型下载到: {model_dir}')
"
下载llamafactory
需要配置一下llamafactory ,训练的时候需要用到shu ju
##xhttps://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.htmlx
修改配置文件
用Jupyter Lab的文件浏览器找到 qwen_lora_merged.yaml 文件,编辑内容:
##注意这个实际model_nameor_path:下载到哪里就用那个 根据上面model_dir进行更改
也可以直接用model_name
eg:Qwen2-1___5B. 我这了下划线是三个 具体要注意一下
model_name_or_path: /root/autodl-tmp/models/qwen2-1.5B
template: qwen
infer_backend: vllm
vllm_enforce_eager: true
##用绝对路径启动
llamafactory-cli api /root/data/qwen_lora_merged.yaml &可能会遇到一个vllm的版本问题 这是因为版本太新了 按照要求重新装一下就可以了
mportError: vllm>=0.4.3,<=0.8.6 is required for a normal functioning of this module, but found vllm==0.10.1.1. To fix: run `pip install vllm>=0.4.3,<=0.8.6` or set `DISABLE_VERSION_CHECK=1` to skip this check
##启动可能会遇到一些版本的问题
# 安装指定版本的vllm
pip install "vllm>=0.4.3,<=0.8.6"
# 重新启动API服务
llamafactory-cli api /root/data/qwen_lora_merged.yaml &
启动后如图所示
这就在本地运行了 qwen2-1 5b的模型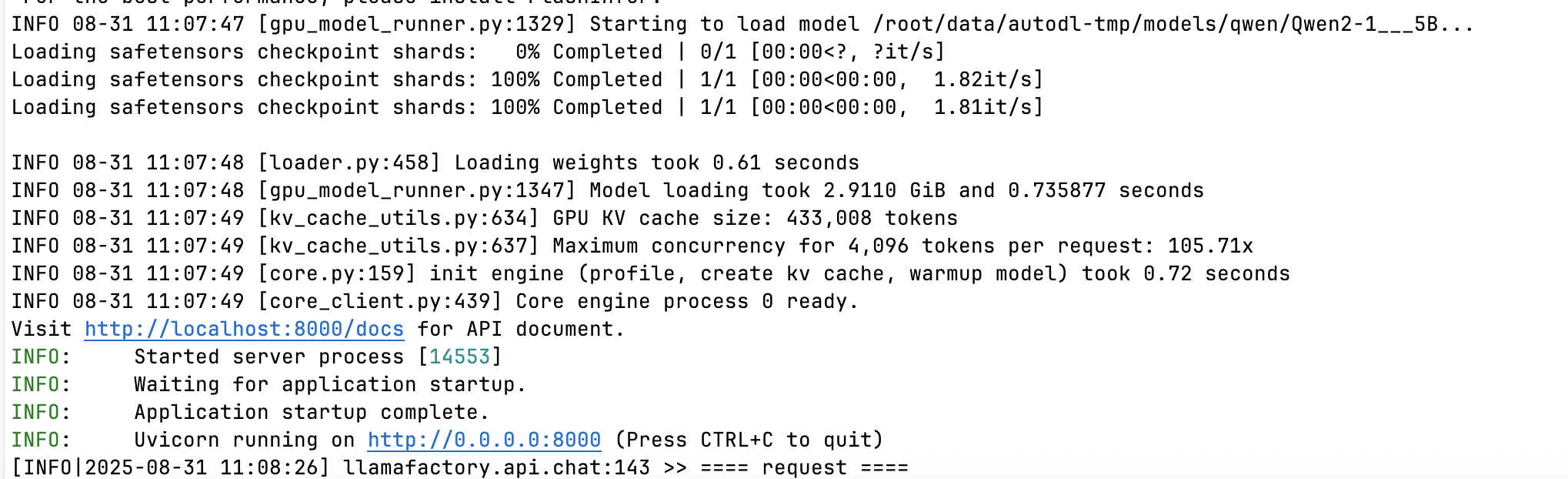
import requests
import json
# 测试API连通性
try:
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "你好!请用一句话自我介绍"}],
"max_tokens": 50
},
timeout=10
)
print("API响应:", response.status_code)
print("回复内容:", response.json()['choices'][0]['message']['content'])
except Exception as e:
print("API测试失败:", e)
# 测试模型是否会调用工具
test_messages = [
{"role": "system", "content": "你是一个有用的小助手,请调用工具来回答用户的问题。"},
{"role": "user", "content": "鸡蛋壳属于哪种类型的垃圾?"}
]
test_response = client.chat.completions.create(
messages=test_messages,
model="gpt-3.5-turbo",
tools=tools
)
print("是否有tool_calls:", hasattr(test_response.choices[0].message, 'tool_calls') and test_response.choices[0].message.tool_calls is not None)
print("模型回复:", test_response.choices[0].message.content)
此时模型还是傻乎乎的 不会调用所具备的工具
也可以试一下funcioin_call.py 看下此时模型输出什么
##下面进入训练
⾸先,进⼊我们已经安装好的vllm_env环境
conda activate agentexport USE_MODELSCOPE_HUB=1### model
model_name_or_path: /root/data/autodl-tmp/models/qwen/Qwen2-1___5B
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: glaive_toolcall_en, glaive_toolcall_zh,alpaca_gpt4_en,alpaca_gpt4_zh
##这里注意看你的factory下载在哪里
dataset_dir: /root/data/LLaMA-Factory/data
template: qwen
cutoff_len: 1024
max_samples: 50000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: /root/autodl-tmp/checkpoints/agent
logging_steps: 100
save_steps: 1000
plot_loss: true
overwrite_output_dir: true
### train
##这里的batch_size原来是为1的,可以适当的设置 我的24g 4090 设置的8 2,正好拉满
#per_device_train_batch_size: 4 # 物理批次大小
#gradient_accumulation_steps: 4 # 累积步数
#有效批次大小 = 4 × 4 = 16
##物理批次大小:一次前向传播处理的数据量。梯度累积步数:多少次前向传播后才更新一次权重,为什么要累积:因为显存有限,不能一次性处理太大批次
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.01
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 1000
llamafactory-cli train /root/data/qwen2_lora_sft.yaml
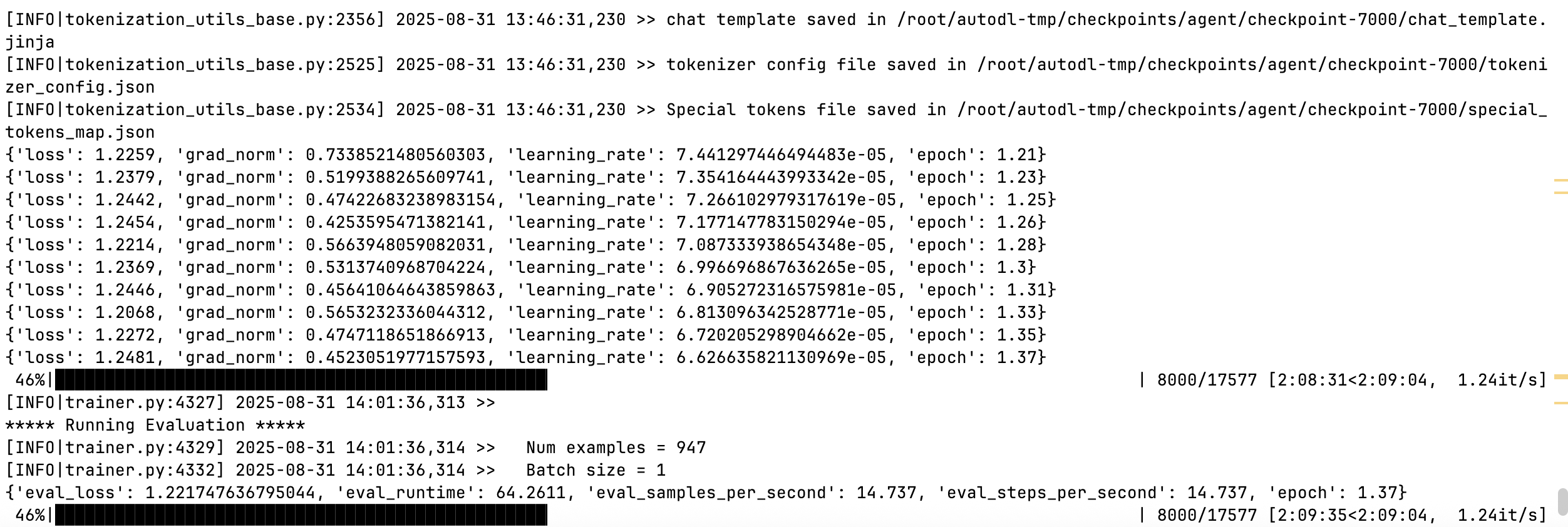
##训练完成后 开始合并
配置qwen_lora_sft.yaml
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: /root/data/autodl-tmp/models/qwen/Qwen2-1___5B
##qwen2_lora_sft.yaml里面output是/root/autodl-tmp/checkpoints/agent.
##设置了checkpoint-35148 特定的检查点可以防止过拟合
#35148可以改成你agent下面有的快照节点 如果不设置那么就是用最后一个整个的进行匹配
adapter_name_or_path: /root/autodl-tmp/checkpoints/agent/checkpoint-35148
template: qwen
finetuning_type: lora
### export
##完成模型存放位置
export_dir: /root/autodl-tmp/checkpoints/agent_lora_merged
export_size: 2
export_device: cpu
export_legacy_format: false
llamafactory-cli export /root/data/qwen_lora_sft.yaml最后就是在/data下面创建一个qwen_lora_infer.yaml
其实和 qwen_lora_merged.yaml一样 只是模型地址换了新的 export中的地址
llamafactory-cli api /root/data/qwen_lora_infer.yaml
启动之后再到jupyter里面进行测试就可以看到了
测试
import os
import json
from openai import OpenAI
from typing import Sequence
import requests
os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1"
os.environ["OPENAI_API_KEY"] = "0"
def get_rubbish_category(keyword):
url = f"https://api.timelessq.com/garbage?keyword={keyword}"
response = requests.request("GET", url)
output_str_list = []
for item in response.json()['data']:
output_str_list.append(f"{item['name']}: {item['categroy']}")
return '\n'.join(output_str_list)
def get_song_information(keyword):
url = f"https://api.timelessq.com/music/tencent/search?keyword={keyword}"
response = requests.request("GET", url)
song_infor = response.json()['data']['list'][0]
singer = '' if not song_infor['singer'] else song_infor['singer'][0]['name']
return f"歌曲: {keyword}\n歌手: {singer}\n时长: {song_infor['interval']}秒\n专辑名称: {song_infor['albumname']}"
def get_cartoon_information(title):
url = f"https://api.timelessq.com/bangumi?title={title}"
response = requests.request("GET", url)
data = response.json()['data'][0]
return f"标题: {data['title']}\n类型:{data['type']}\n语言:{data['lang']}\n出品方:{data['officialSite']}\n上映时间:{data['begin']}\n完结事件:{data['end']}"
tool_map = {"get_rubbish_category": get_rubbish_category,
"get_song_information": get_song_information,
"get_cartoon_information": get_cartoon_information}
if __name__ == "__main__":
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_rubbish_category",
"description": "适用于生活垃圾分类时,判断物品属于哪种类型的垃圾?",
"parameters": {
"type": "object",
"properties": {
"keyword": {
"type": "string",
"description": "物品名称,用于垃圾分类",
},
},
"required": ["keyword"],
}
}
},
{
"type": "function",
"function": {
"name": "get_cartoon_information",
"description": "根据用户提供的动漫标题,查询该动漫的相关信息。",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "动漫",
},
},
"required": ["title"],
}
}
},
{
"type": "function",
"function": {
"name": "get_song_information",
"description": "根据用户提供的歌曲名称,查询歌曲相关信息,包括歌手、时长、专辑名称等。",
"parameters": {
"type": "object",
"properties": {
"keyword": {
"type": "string",
"description": "歌曲名称",
},
},
"required": ["keyword"],
}
}
}
]
messages = []
messages.append({"role": "system", "content": "你是一个有用的小助手,请调用下面的工具来回答用户的问题,参考工具输出进行回答。"})
# messages.append({"role": "user", "content": "鸡蛋壳属于哪种类型的垃圾?"})
# messages.append({"role": "user", "content": "爱在西元前是谁唱的,来自哪张专辑?"})
# messages.append({"role": "user", "content": "凉凉是谁唱的"})
messages.append({"role": "user", "content": "动漫《棋魂》是哪个国家的,什么时候上映的?"})
result = client.chat.completions.create(messages=messages, model="gpt-3.5-turbo", tools=tools)
print("result")
print(result)
tool_call = result.choices[0].message.tool_calls[0].function
print("tool_call")
print(tool_call)
name, arguments = tool_call.name, json.loads(tool_call.arguments)
messages.append({"role": "function", "content": json.dumps({"name": name, "arguments": arguments}, ensure_ascii=False)})
tool_result = tool_map[name](**arguments)
messages.append({"role": "tool", "content": "工具输出结果为: " + tool_result})
for msg in messages:
print('--->', msg)
result = client.chat.completions.create(messages=messages, model="gpt-3.5-turbo")
print("Answer: ", result.choices[0].message.content)
从里面可以看到tool 工具的使用和输出。到此模型训练成功

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)