【经济学】量化模型Qlib图片速览 “Qlib: An AI-oriented Quantitative Investment Platform” 论文阅读
【经济学】量化模型Qlib图片速览 “Qlib: An AI-oriented Quantitative Investment Platform” 论文阅读
| paper | code |
|---|---|
| Qlib: An AI-oriented Quantitative Investment Platform | https://github.com/microsoft/qlib |
Abstract
- 量化投资的目标是在一系列金融工具的连续交易周期内实现收益最大化,并最小化风险。近年来,人工智能技术在量化投资领域的快速发展及其巨大潜力的推动下,越来越多地被应用于量化研究和投资实践。人工智能技术在丰富量化投资方法论的同时,也对量化投资系统提出了新的挑战。具体而言,量化投资新的学习范式要求基础设施升级以适应新的工作流程;此外,人工智能技术的数据驱动特性也意味着对性能更强大的基础设施的需求;此外,将人工智能技术应用于金融场景中的不同任务也面临着一些独特的挑战。为了应对这些挑战,并弥合人工智能技术与量化投资之间的差距,我们设计并开发了Qlib,旨在挖掘人工智能技术的潜力,赋能量化研究,并创造其在量化投资领域的价值。
1 Introduction
- 金融数据的信噪比(SNR)极低(“噪声”几乎淹没了“信号”)。
- 在金融行业中,随着跟随某一投资策略的投资者增多,该策略的盈利能力会逐渐下降。因此,金融从业者,尤其是量化研究人员,从来不热衷于分享自己的算法和工具。
- Qlib 集成了一批专门为量化投资场景下的机器学习而设计的工具,以帮助用户充分利用 AI 技术。
2 Background and Related Works
- 略
3 AI-oriented Quantitative Investment Platform
3.1 Overall Design
-
在与具有多年金融市场实战经验的量化研究人员合作过程中,我们遇到了上述所有问题,并探索了各种解决方案。基于当前的形势,我们开发了 Qlib,以将人工智能技术应用于量化投资。
-
AI-oriented framework
- Qlib 的设计基于现代研究工作流程,采用模块化架构,以提供最大程度的灵活性来适应人工智能技术。量化研究人员可以扩展这些模块,并构建适合自己的工作流程,从而高效地验证他们的想法。在每个模块中,Qlib 都提供了若干默认的实现方案,这些方案在实际投资中表现良好。借助这些开箱即用的模块,量化研究人员可以专注于某个特定模块中的问题,而不必被其他琐碎细节分散注意力。除了代码之外,部分模块中的计算与数据也可以共享,因此 Qlib 被设计成一个平台,而不仅仅是一个工具箱。
-
High-performance infrastructure
- 数据处理的性能对 AI 等数据驱动方法至关重要。作为一个面向 AI 的平台,Qlib 提供了高性能的数据基础设施。Qlib 提供了一种时序扁平文件数据库。这种数据库专为金融数据的科学计算而设计,在量化投资研究中的一些典型数据处理任务上,性能远超当前常见的通用数据库和时序数据库。除此之外,该数据库还提供了一个表达式引擎,能够加速因子/特征的实现与计算,使依赖表达式计算的研究课题成为可能。
-
Guidance for machine learning
- Qlib 已经集成了一些典型的量化投资数据集,在这些数据集上,常见的机器学习算法能够成功学习具有泛化能力的模式。Qlib 为机器学习用户提供了一些基本指导,并集成了一些合理的任务,这些任务包含合理的特征空间和目标标签。此外,还提供了一些典型的超参数优化工具。在这些指导和合理设置的帮助下,机器学习模型能够学习具有更好泛化能力的模式,而不仅仅是对噪声进行过拟合。
3.2 AI-oriented Framework
-
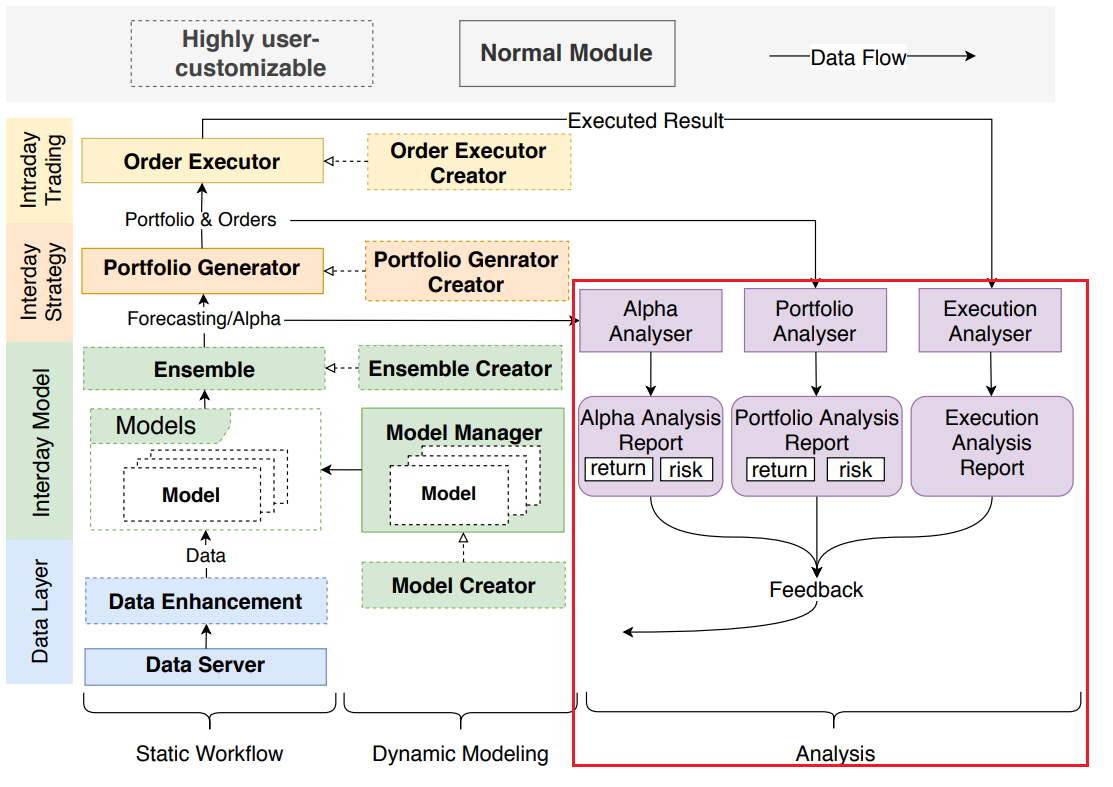
图 1 展示了 Qlib 的整体框架。该框架的目标是:
-
- 适应现代 AI 技术;
-
- 帮助量化研究人员以最小的成本构建完整的研究工作流程;
-
- 为研究人员在探索感兴趣的问题时提供最大灵活性,而不被其他部分干扰。
-
-
这一目标从系统设计的角度促成了模块化设计。系统根据现代实际研究工作流程被划分为若干独立模块。大多数量化投资研究方向,无论是传统方法还是基于 AI 的方法,都可以被视为一个或多个模块接口的实现。Qlib 为每个模块提供了几个在实际投资中表现良好的典型实现。此外,各模块还提供了灵活性,允许研究人员覆盖现有方法以探索新思路。借助这样的框架,研究人员可以以最低成本尝试新想法,并与其他模块共同测试整体性能。
-
图 1 中列出了 Qlib 的各个模块,并展示了它们在典型工作流程中的连接方式。每个模块对应量化投资中的一个典型子任务,而模块中的实现可以被视为该任务的解决方案。我们将介绍每个模块,并给出一些现有量化研究的相关示例,以展示 Qlib 如何适配这些任务。
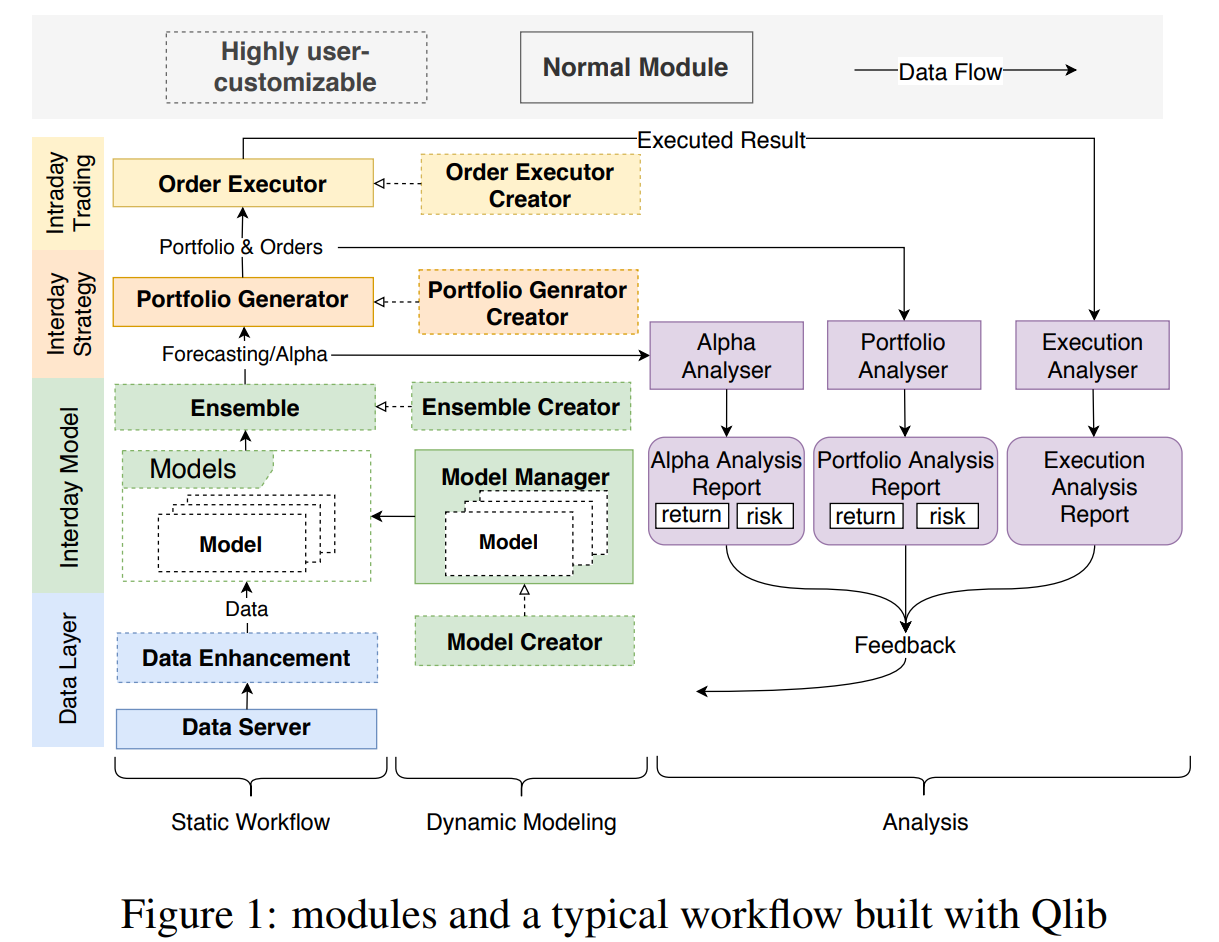
-
流程从左下角的 Data Server(数据服务)模块 开始,该模块提供数据引擎,用于查询和处理原始数据。获取数据后,研究人员可以在 Data Enhancement(数据增强)模块 中构建自己的数据集。研究人员尝试了多种方法,通过探索和构建有效因子/特征来生成更优的数据集 [Potvin et al., 2004; Neely et al., 1997; Allen and Karjalainen, 1999; Kakushadze, 2016]。另一种研究方向是 生成训练数据集 [Feng et al., 2019],为数据集提供解决方案。
-
Model Creator(模型创建)模块 基于数据集进行模型训练。近年来,众多研究者探索了各种模型,以从金融数据集中挖掘交易信号 [Sezer et al., 2019]。此外,元学习(meta-learning) [Vilalta and Drissi, 2002]——尝试“学习如何学习”——为模型创建模块提供了一种新的学习范式。现代研究工作流中有大量建模方法,使得 模型管理系统 成为工作流中必不可少的一部分。Model Manager(模型管理)模块 的设计正是为现代量化研究人员解决这一问题。
-
在拥有多样化模型的情况下,集成学习(ensemble learning) 是提升机器学习模型性能和鲁棒性的有效方法,在金融领域被广泛应用 [Qiu et al., 2014; Yang et al., 2017; Zhao et al., 2017],这一功能由 Model Ensemble(模型集成)模块 支持。
-
Portfolio Generator(投资组合生成)模块 旨在根据模型输出的交易信号生成投资组合,这一过程被称为投资组合管理 [Qian et al., 2007]。Barra [Sheikh, 1996] 提供了该任务最常用的解决方案。获得目标投资组合后,我们提供一个高保真交易模拟器——Orders Executor(订单执行)模块,用于检验策略表现;同时,Analyser(分析)模块 可自动分析交易信号、投资组合及执行结果。值得注意的是,Order Executor 模块被设计为一个响应式模拟器,而非传统的回测函数,它可以为某些需要环境反馈(如强化学习 RL)的学习范式提供基础设施,而环境反馈由 Analyser 模块生成。
-
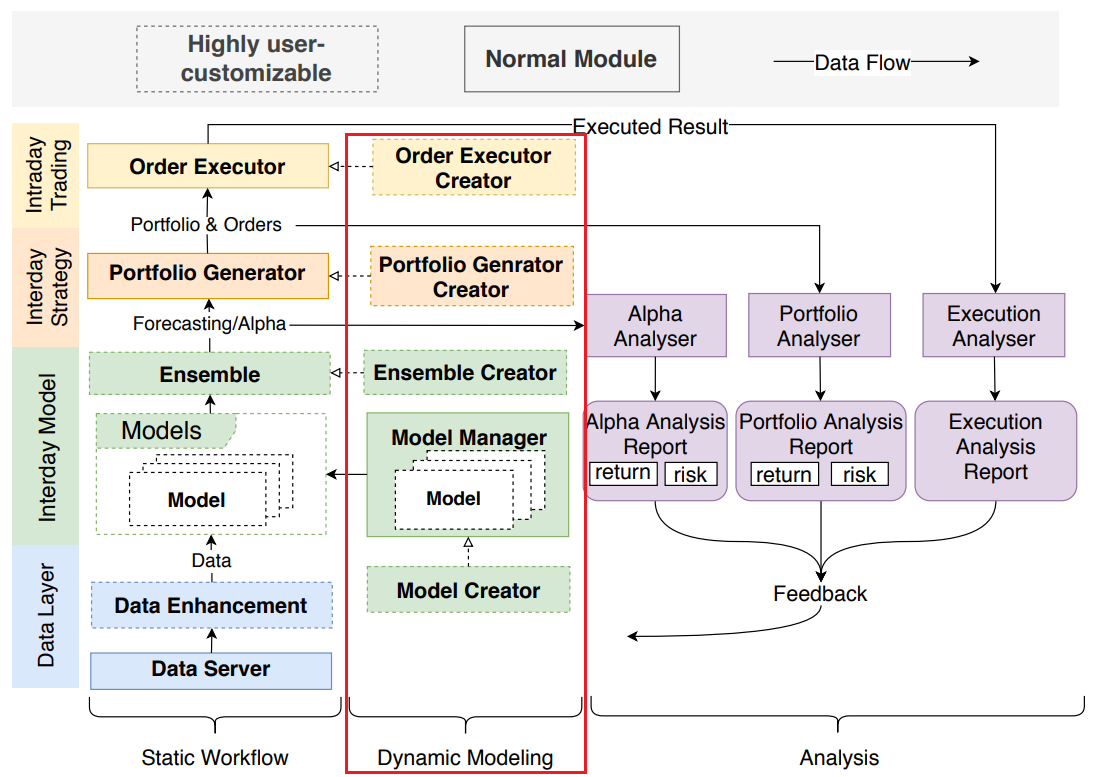
量化投资中的数据是时间序列格式,并会随着时间不断更新。样本内数据集的规模会随时间增长。一个典型的做法是定期更新模型 [Wang et al., 2019b],以充分利用不断增加的样本内数据。除了更好地利用新增数据外,动态更新模型 [Yang et al., 2019] 和 交易策略 [Wang et al., 2019a] 可以进一步提升性能,这是由于股市的动态特性 [Adam et al., 2016] 所致。因此,在静态工作流中使用一套固定的模型和交易策略显然不是最优方案(it is obviously not the optimal solution to use a set of static model and trading strategies in Static Workflow.)。模型和策略的动态更新 是量化投资中的一个重要研究方向。Dynamic Modeling(动态建模)模块 提供了接口和基础设施,以支持这类解决方案。
3.3 High Performance Infrastructure
Financial data
- 在本节中,我们将总结量化研究中的数据需求。在量化研究中,最常用的数据格式如下:
BasicData T = { x i , t , a } , i ∈ Inst , t ∈ Time , a ∈ Attr \text{BasicData}_T = \{x_{i,t,a}\}, \quad i \in \text{Inst}, \; t \in \text{Time}, \; a \in \text{Attr} BasicDataT={xi,t,a},i∈Inst,t∈Time,a∈Attr
-
其中, x i , t , a x_{i,t,a} xi,t,a 表示基础类型的数据值(例如 float、int);
Inst 表示金融工具集合(例如股票、期权等);
Time 表示时间戳集合(例如股市的交易日);
Attr 表示金融工具的可能属性集合(例如开盘价、成交量、市值);
T 表示数据的最新时间戳(例如最近交易日)。
x i , t , a x_{i,t,a} xi,t,a 表示工具 i i i 在时间 t t t 的属性 a a a 的数值。 -
此外,工具池(instrument pool) 是必要的信息,用于指定随时间变化的金融工具集合:
Pool T = { pool t } , t ∈ Time , pool t ⊆ Inst \text{Pool}_T = \{\text{pool}_t\}, \quad t \in \text{Time}, \; \text{pool}_t \subseteq \text{Inst} PoolT={poolt},t∈Time,poolt⊆Inst
-
例如,标普 500 指数(S&P 500 Index) 就是一个典型的工具池示例。
-
数据更新是一个核心功能。已有的历史数据随时间不会发生变化,因此只需要对新数据进行 追加操作。形式化的更新操作为:
BasicData T = OldBasicData T ∪ { x i , t , a new } \text{BasicData}_T = \text{OldBasicData}_T \cup \{x_{i,t,a_{\text{new}}}\} BasicDataT=OldBasicDataT∪{xi,t,anew}
BasicData T + 1 = BasicData T ∪ { x i , T + 1 , a } \text{BasicData}_{T+1} = \text{BasicData}_T \cup \{x_{i,T+1,a}\} BasicDataT+1=BasicDataT∪{xi,T+1,a}
Pool T + 1 = Pool T ∪ { pool t + 1 } \text{Pool}_{T+1} = \text{Pool}_T \cup \{\text{pool}_{t+1}\} PoolT+1=PoolT∪{poolt+1}
- 用户查询可以形式化为:
DataQuery = { x i , t , a ∣ i t ∈ pool t , pool t ∈ Pool query , a ∈ Attr query , t i m e start ≤ t ≤ t i m e end } \text{DataQuery} = \{ x_{i,t,a} \mid i_t \in \text{pool}_t, \; \text{pool}_t \in \text{Pool}_{\text{query}}, \; a \in \text{Attr}_{\text{query}}, \; time_{\text{start}} \le t \le time_{\text{end}} \} DataQuery={xi,t,a∣it∈poolt,poolt∈Poolquery,a∈Attrquery,timestart≤t≤timeend}
-
这表示在特定工具池中,对金融工具的某些属性在特定时间范围内进行的数据查询。
-
这样的需求相当简单,许多现成的开源解决方案都支持此类操作。我们将这些方案分为三类,并列出每类中常用的实现。
- 通用数据库:MySQL [MySQL, 2001]、MongoDB [Chodorow, 2013]
- 时序数据库:InfluxDB [Naqvi et al., 2017]
- 面向科学计算的数据文件:以 numpy [Oliphant, 2006] 数组或 pandas [McKinney, 2011] DataFrame 组织的数据
-
通用数据库支持多样化的数据格式和结构,并提供诸如索引、事务、实体关系模型等复杂机制。然而,这些机制通常会为特定任务增加额外依赖和不必要的复杂性,而并不能解决特定场景中的关键问题。
-
时序数据库对时间序列数据的结构和查询进行了优化,但它们仍未针对量化研究设计。在量化研究中,数据通常以紧凑的数组形式存储,以便科学计算能够充分利用硬件加速。
如果数据能够从磁盘到客户端全程保持这种紧凑数组格式,无需格式转换,将节省大量时间。然而,通用数据库和时序数据库为了通用性,通常会以不同的格式存储和传输数据,这对于科学计算来说效率低下。 -
由于数据库效率低下,基于数组的数据在科学界越来越受欢迎。Numpy array 和 pandas DataFrame 是科学计算中的主流实现,通常以 HDF5 或 pickle 格式存储在磁盘上。这类数据依赖轻量,并且在科学计算中非常高效。
然而,这类数据通常存储在单一文件中,难以进行更新或查询。 -
经过对上述存储方案的调研,我们发现没有一种能很好地适应量化研究场景,因此有必要为量化研究设计一种定制化的数据存储解决方案。
File storage design
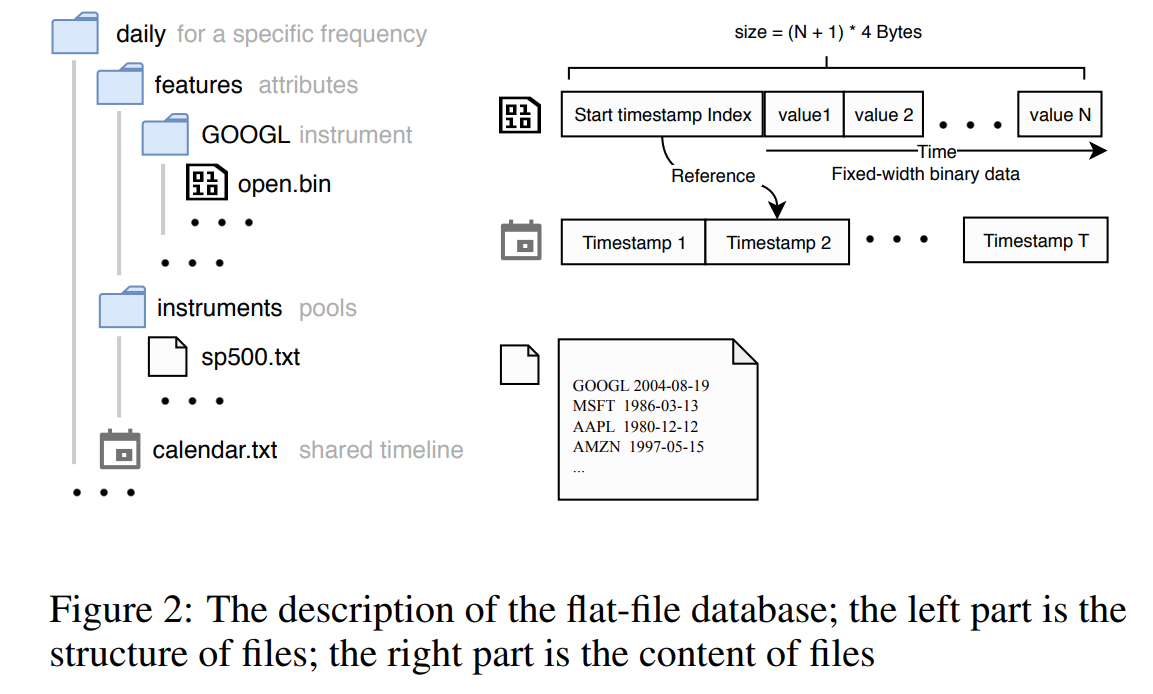
- 图 2 展示了 文件存储设计。如图左侧所示,Qlib 将文件组织成树状结构。数据根据不同的频率、金融工具和属性被分隔到不同的文件夹和文件中。所有属性的数值都以紧凑的固定宽度二进制格式存储,从而可以按字节进行索引。共享的时间轴单独存储在名为
"calendar.txt"的文件中。属性值的数据文件将前 4 个字节设置为时间轴的索引值,用以指示数据序列的起始时间戳。有了起始时间索引,Qlib 就可以在时间维度上对所有数值进行对齐。 - 数据以紧凑格式存储,可高效地组合成数组用于科学计算。它既能像科学计算中的数组数据一样实现高性能,又能满足量化投资场景中的数据更新需求。所有数据按时间顺序排列,新数据可以通过追加操作进行更新,这非常高效。添加或删除属性或金融工具也十分直接且高效,因为它们存储在独立的文件中。这种设计极为轻量化。没有数据库带来的额外开销,Qlib 依然能够实现高性能。
Expression Engine
-
基于基础数据开发新的因子/特征是一个非常常见的任务,这类任务在许多量化研究人员的时间投入中占据很大比例。无论是用代码实现这些因子,还是进行计算,过程都十分耗时。因此,Qlib 提供了一个表达式引擎,以尽量减少这类任务的工作量。
-
实际上,因子/特征的本质是一个将基础数据转换为目标值的函数。该函数可以拆解为一系列表达式的组合。表达式引擎正是基于这一思想设计的。借助这个表达式引擎,量化研究人员可以通过编写表达式而非复杂代码来实现新的因子/特征。例如,Bollinger Band(布林带) 技术指标 [Bollinger, 2002] 是一个广泛使用的技术因子,其上轨可以通过一个简单的表达式实现
(MEAN($close, N) + 2 * STD($close, N) - $close) / MEAN($close, N)使用表达式引擎即可完成,而无需编写复杂的代码。 -
这种实现方式简单、可读、可复用且易于维护。用户只需一系列简单的表达式,就可以轻松构建数据集。通过搜索表达式来构建有效的交易信号是一个典型的研究课题,已经被许多研究者探索过 [Allen and Karjalainen, 1999; Neely et al., 1997; Potvin et al., 2004]。因此,表达式引擎 是这类研究课题中不可或缺的工具。
Cache system
-
为了避免重复计算,Qlib 内置了一个缓存系统。该系统由内存缓存和磁盘缓存组成。
-
内存缓存
当 Qlib 使用其表达式引擎计算因子/特征时,它会将表达式解析为语法树。所有节点的计算结果都会存储在内存中的 LRU(最近最少使用)缓存 中,从而避免对相同的(子)表达式进行重复计算。 -
磁盘缓存
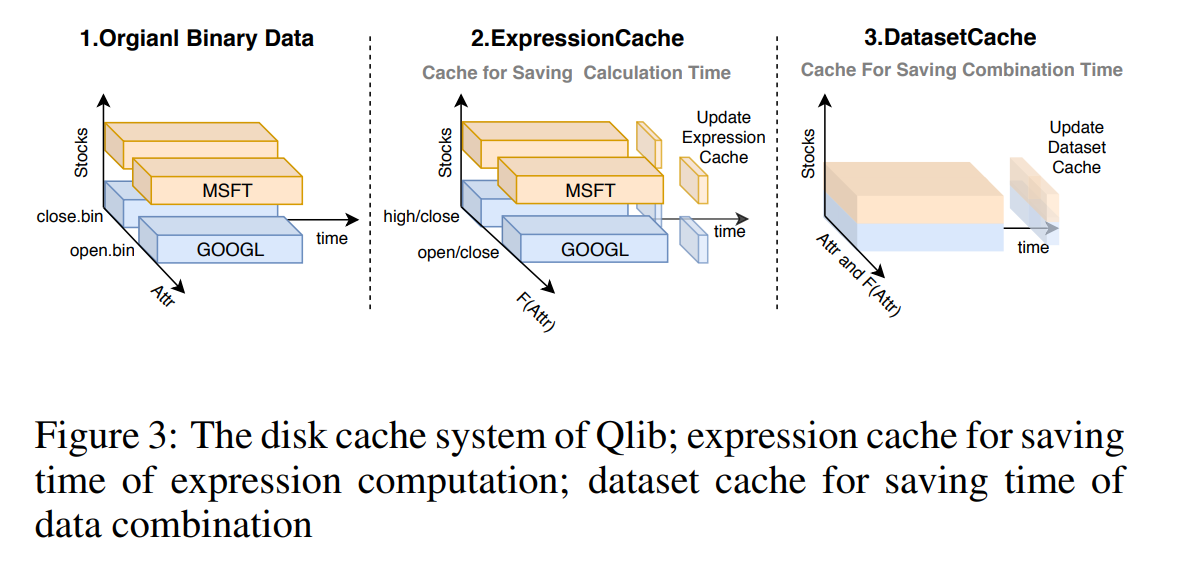
量化投资中的典型数据处理工作流可以分为三个步骤:获取原始数据、计算表达式以及将数据组合成数组以用于科学计算。计算表达式和数据组合非常耗时。如果能够缓存共享的中间数据,将节省大量时间。在实际的数据处理任务中,许多中间结果是可以共享的,例如相同的表达式计算可以被不同的数据处理任务共享。因此,Qlib 设计了一个两级磁盘缓存机制。如图 3 所示,左侧是我们在第 3.3 节描述的原始数据。- 第一级为表达式缓存,将所有计算过的表达式结果保存到磁盘缓存中,其数据结构与原始数据相同。通过表达式缓存,相同的表达式只需计算一次。
- 第二级为数据集缓存(dataset cache),用于存储组合后的数据,以节省组合数据的时间。
-
这两个级别的缓存数据都按时间排列,并可在时间维度上索引,因此即使查询时间发生变化,磁盘缓存也可以共享。此外,由于数据按时间排列,Qlib 支持通过追加新数据进行更新。借助这种机制,数据的维护变得更加容易。
3.4 Guidance for Machine Learning
-
正如我们在第 2 节中讨论的,对机器学习算法的指导非常重要。Qlib 提供了典型的机器学习数据集,并包含一些典型的任务设置,如数据预处理、学习目标等。研究人员无需从零开始探索所有内容。这些指导为研究人员提供了大量领域知识,帮助他们顺利进入该研究领域。
-
对于大多数机器学习算法,超参数优化 是实现更好泛化能力的必要步骤。尽管重要,但这一过程既费时又高度重复。因此,Qlib 提供了一个 超参数调优引擎(Hyperparameters Tuning Engine,HTE) 来简化这一任务。HTE 提供接口用于定义超参数搜索空间 Θ \Theta Θ,并能够自动搜索最佳超参数 θ \theta θ。
-
在典型的金融时间序列建模任务中,新数据是按时间顺序到来的。为了利用这些新数据,模型必须定期在新数据上重新训练。新的最佳超参数 θ \theta θ 会发生变化,但通常接近之前的最佳超参数。
-
HTE 提供了一个专门针对金融任务的超参数优化机制。它为超参数搜索空间生成新的分布,以便在更少的尝试下更有可能找到最佳点。超参数搜索分布可以形式化表示为:
p new ( x ) = p prior ( x ) ϕ θ prev , σ 2 ( x ) E x ∼ p prior [ ϕ θ prev , σ 2 ( x ) ] p_{\text{new}}(x) = \frac{p_{\text{prior}}(x) \, \phi_{\theta_{\text{prev}}, \sigma^2}(x)}{\mathbb{E}_{x \sim p_{\text{prior}}}[\phi_{\theta_{\text{prev}}, \sigma^2}(x)]} pnew(x)=Ex∼pprior[ϕθprev,σ2(x)]pprior(x)ϕθprev,σ2(x)
- 其中, p prior p_{\text{prior}} pprior 是原始超参数搜索空间; ϕ θ prev , σ 2 ( x ) ∼ N ( θ prev , σ 2 ) \phi_{\theta_{\text{prev}}, \sigma^2}(x) \sim \mathcal{N}(\theta_{\text{prev}}, \sigma^2) ϕθprev,σ2(x)∼N(θprev,σ2); θ prev \theta_{\text{prev}} θprev 是上一次模型训练中的最佳超参数。超参数搜索空间的取值域保持不变,但在 θ prev \theta_{\text{prev}} θprev 附近的概率密度增加。
4 Use Case & Performance Evaluation
4.1 Use Case

- Qlib 提供了一个 配置驱动流水线引擎(Config-Driven Pipeline Engine,CDPE),以帮助研究人员更轻松地构建图 1 所示的完整研究工作流。用户只需通过一个简单的配置文件就可以定义工作流。这种接口并非强制性的,我们保留了最大的灵活性,允许用户像搭积木一样,通过代码自行构建量化研究工作流。
4.2 Performance Evaluation
-
数据处理的性能对于像 AI 技术这样的数据驱动方法非常重要。作为一个面向 AI 的平台,Qlib 提供了数据存储和处理的解决方案。为了展示 Qlib 的性能,我们将其与第 3.3 节讨论的其他几种方案进行比较,包括 HDF5、MySQL、MongoDB、InfluxDB 和 Qlib。
-
其中,Qlib +E -D 表示启用表达式缓存(Expression Cache)但禁用数据集缓存(Dataset Cache)的 Qlib,其他组合以此类推。
-
这些解决方案的任务是从股票市场的基础 OHLCV(开盘价 Open、最高价 High、最低价 Low、收盘价 Close、成交量 Volume)日数据创建一个数据集,这包括数据查询和处理。最终数据集由 14 个因子/特征 构成,这些因子/特征由 OHLCV 数据派生而来(例如
"Std($close, 5)/$close")。数据时间范围为 2007/1/1 到 2020/1/1。股票池每天包含 800 支股票,每日更新变化。 -
除了对每种方案的总耗时进行比较外,我们将任务拆解为以下步骤以提供更多细节:
-
Load Data(加载数据)
将 OHLCV 数据或缓存加载到内存中,并以基于数组的格式存储,以便科学计算。 -
Compute Expr.(计算表达式)
计算派生因子/特征。 -
Convert Index(转换索引)
仅适用于 Qlib。由于 Qlib 原始数据中不存储索引(即时间戳、股票 ID),因此必须建立数据索引。 -
Filter Data(过滤数据)
根据特定股票池过滤股票数据。例如,SP500 总共包含超过 1000 支股票,但每天只包括 500 支股票。即使某些数据曾经属于 SP500,也应在特定日期被过滤掉。由于一些派生特征依赖历史 OHLCV 数据,因此在加载数据时无法完成过滤。 -
Combine Data(合并数据)
将不同股票的所有数据合并为单个基于数组的数据块。
-
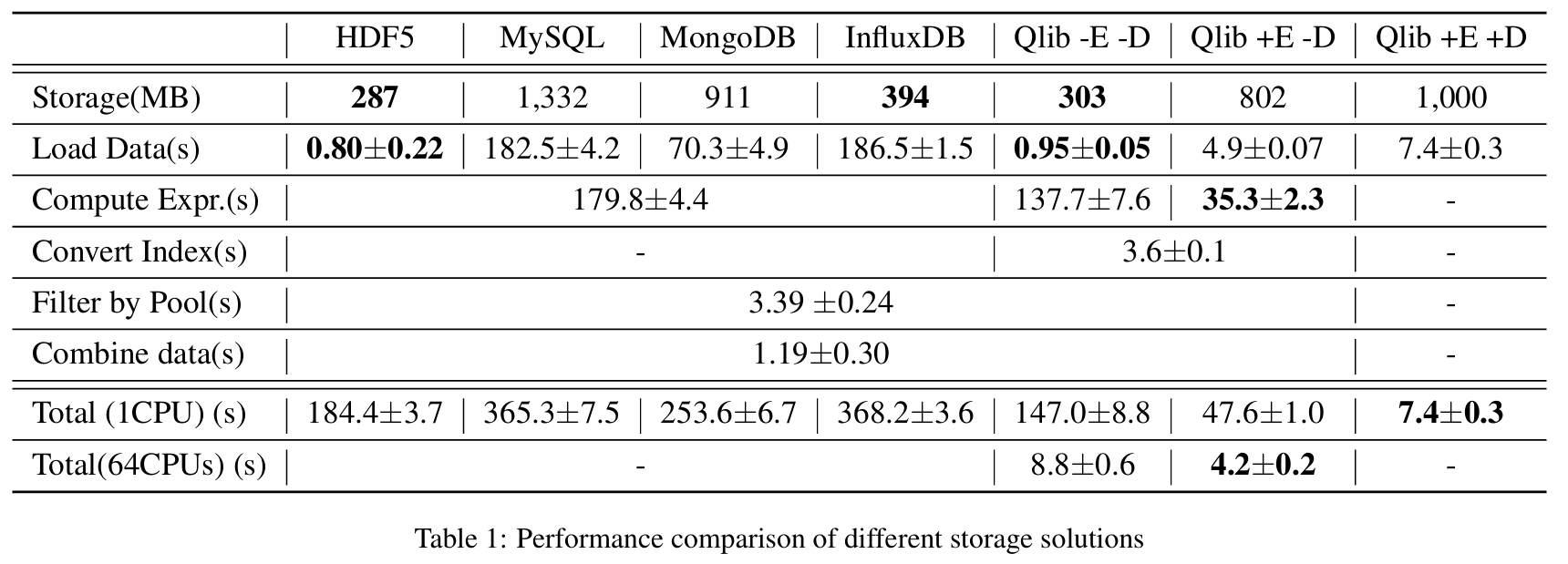
-
如表 1 所示,Qlib 的紧凑存储在数据大小和加载速度上与专用的科学 HDF5 数据文件相当。而数据库在加载数据时耗时过多。深入分析底层实现后,我们发现无论是通用数据库还是时间序列数据库,数据在加载过程中都经历了过多的接口层和不必要的格式转换,这些开销大大降低了数据加载速度。
-
借助 Qlib 的内存缓存,Qlib -E -D 在 Compute Expr. 步骤上节省了约 24% 的时间。此外,Qlib 提供了表达式缓存和数据集缓存机制。启用表达式缓存的 Qlib +E -D,如果没有缓存未命中,Compute Expr. 步骤可节省 80.4% 的时间。将各股票的因子/特征合并为单个基于数组的数据块是 Qlib +E -D 的主要耗时部分,这部分包含在 Compute Expr. 步骤中。
-
除了计算开销外,最耗时的步骤是数据合并。数据集缓存(dataset cache) 的设计就是为了减少这类开销。如 Qlib +E +D 列所示,时间成本进一步降低。
-
此外,Qlib 可以利用多 CPU 核心加速计算。如表 1 最后一行所示,多核 CPU 显著降低了 Qlib 的时间成本。而 Qlib +E +D 无法进一步加速,因为它仅读取已有缓存,几乎不进行计算。
4.3 More about Qlib
- Qlib 是一个持续开发的开源平台。更详细的文档可以在其 GitHub 仓库 中找到。本文未详细介绍的许多功能(例如:基于客户端-服务器架构的数据服务、分析系统、云端自动部署等)都可以在在线仓库中查看。欢迎大家为该项目贡献力量。
5 Conclusion
- 在本文中,我们提出了 AI 时代现代量化研究人员所面临的实际问题。基于这些问题,我们设计并实现了 Qlib,旨在赋能每一位量化研究人员,让他们能够充分发挥 AI 技术在量化投资中的巨大潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)