51c大模型~合集176
在记忆调度与管理层,MemOS 提出了记忆调度的全新范式,支持基于上下文的 「下一场景预测」,可以在模型生成时提前加载潜在需要的记忆片段,显著降低响应延迟、提升推理效率。另外,我们也看到了一批关注 AI 记忆的创业公司的诞生,包括提出了 MemGPT 的 Letta AI、提出了 AI 的记忆操作系统 MemOS 的记忆张量(上海)科技有限公司以及我们前段时间报道过的提出了拥有一定的原生记忆能力的
自己的原文哦~ https://blog.51cto.com/whaosoft/14152350
#那天,AI大模型想起了,被「失忆」所束缚的枷锁
记忆,你有我有,LLM 不一定有,但它们正在有。
前些天,谷歌宣布 Gemini 具备了记忆能力。此前,它已经凭借长达 100 万 token 甚至更高的上下文长度,在「短期记忆」上有不错表现 —— 能够在一次会话中保留大量信息。但这一次,Gemini 可以跨越多次对话,从用户的交流中提炼关键细节和偏好,并在下一次交互时主动调用,让对话更自然、更连贯。

事实上,更早几天,Anthropic 才刚刚为自家的 Claude 装上记忆。在一段演示视频中,一位用户休假归来,向 Claude 询问之前聊过的内容。Claude 会在历史聊天中检索相关记录,阅读并总结给用户,然后询问是否要继续原先的项目。
,时长00:34
该公司写道:「你再也不会忘记自己的工作了,Claude 现在会记住你们之前的对话,这样你就可以无缝地继续项目,参考之前的讨论,并在你的想法上进行构建,而不必每次都从头开始。」
至于 OpenAI,在这个方向上却已经走出了相当远。早在 2024 年 2 月份,该公司就已经为 ChatGPT 上线了记忆功能:当用户与 ChatGPT 聊天时,用户可以要求 ChatGPT 记住特定的内容或让它自行获取详细信息。使用频率越多,ChatGPT 的记忆力就会越好,并且随着时间的推移,用户能明显感觉到效果的提升。
前些天,该公司 CEO 山姆・奥特曼更是表示 GPT-6 的一大改进核心也将会是记忆。他表示:「人们想要记忆,人们想要那些需要让 AI 能够理解他们的产品功能。」

而 xAI 也已经在 4 月份让 Grok 能够记忆多轮对话的内容。并且 Grok 的记忆是透明的:用户可以清楚地看到 Grok 知道的内容,并可选择忘记哪些内容。

近段时间来,LLM 记忆这个赛道也越来越拥挤,新的研究、产品不断涌现。这不,字节跳动联合浙大和上交不久前才刚发布一个具备长期记忆能力的多模态智能体 M3-Agent,让记忆能力不再仅限于文本,更是扩展到了视频、音频等多模态数据。
,时长03:57
来源:arXiv:2508.09736
另外,我们也看到了一批关注 AI 记忆的创业公司的诞生,包括提出了 MemGPT 的 Letta AI、提出了 AI 的记忆操作系统 MemOS 的记忆张量(上海)科技有限公司以及我们前段时间报道过的提出了拥有一定的原生记忆能力的非 Transformer 架构 Yan 2.0 Preview 的国内 AI 创企 RockAI 等。
这些案例背后,记忆并不只是「存信息」那么简单,而是涉及存储、检索、提炼和遗忘等复杂机制。
而「记忆」也正在成为大模型进一步蜕变以及智能体进一步走向大规模应用的关键技术,正如 OpenAI 前研究高管、Thinking Machines Lab 联合创始人翁荔(Lilian Weng)在其博客文章中展示的那样。

接下来,我们就来看看,LLM 的记忆究竟是如何实现的。
LLM 记忆的类型以及如何实现 LLM 记忆
要构建记忆,必定要先定义记忆。这里我们直接引用翁荔的定义:
记忆可以被定义为获取、存储、保留和随后检索信息的过程。
她又进一步将记忆分为感官记忆、短期记忆和长期记忆:
感官记忆:学习原始输入(包括文本、图像或其他模态数据)的嵌入表示;
短期记忆:即在上下文中的记忆 —— 短暂且有限的,因为它受到 Transformer 有限上下文窗口长度的限制;
长期记忆:可以跨对话使用的记忆,包括智能体在响应用户查询时可以调用的外部向量存储,可以通过快速检索访问。
这里我们不关注感官记忆,同时更加侧重于长期记忆。
根据近期的几篇相关综述报告,我们可以对 LLM 的短期和长期记忆做一个更加详细的归纳分类,包括上下文内记忆、外部记忆、参数化记忆、类人的分层式记忆和情境记忆。
上下文内记忆
上下文内记忆是一种短期记忆。
简单来说,就是将需要模型知道的信息放入模型的上下文窗口之中,也就是放入我们发送给模型的提示词(prompt)中。这样一来,模型就可以在执行推理之前先浏览一遍这些信息。这种方法适用于任何有足够长上下文的 LLM,也是一种简单直接的通用方法。

上下文内记忆是 LLM 的短期记忆。图中,上下文窗口被表示为一个消息阵列。最新消息位于数组末尾。消息按从旧到新的顺序排列。「系统消息」不会被移出上下文窗口,因为它包含对模型至关重要的信息 —— 通常是告知 LLM 其被期望行为的具体指令。图源:johnsosoka.com
但是,这种方法的缺点也很明显:
- 容量有限:LLM 的上下文窗口长度终究有限,无法容纳海量信息。
- 成本高昂:将大量信息塞入提示词会显著增加每一次推理的计算成本和时间。
- 临时性:这部分记忆是「一次性」的,一旦对话会话结束,所有上下文信息都会被遗忘,无法跨会话保留(所以是短期记忆)。
外部记忆
外部记忆是一种非参数化(是指没有融合进模型的参数之中)的长期记忆。这是为了克服短期记忆的限制而生的,同时也是当前构建长期记忆最主流的方式。
其核心思想是将信息存储在模型外部的数据库中(如向量数据库),在需要时通过信息检索技术(Retrieval)将最相关的内容取回,并注入到当前的上下文窗口中,为模型提供决策依据。这一过程通常被称为「检索增强生成」(Retrieval-Augmented Generation, RAG)。
一个完整的外部记忆系统通常包括三个关键操作 :
- 记忆写入:将新的信息(如对话历史、用户偏好)处理后存入外部数据库。
- 记忆管理:对已存储的记忆进行更新、合并、去重,甚至遗忘过时或不重要的信息 。
- 记忆读取:根据当前的用户查询,从数据库中高效地检索出最相关的记忆片段。

记忆的读取(R)、写入(W)和管理(M)过程,其中虚线表示交叉试验信息可以整合进记忆模块,图源:arXiv:2404.13501
这种方法的优势在于灵活性高,可以存储海量信息,并且更新记忆无需重新训练模型 。但它也面临挑战,即检索的准确性和效率至关重要:一旦检索失败或错误,就可能会向模型提供无关甚至错误的「记忆」,从而影响最终输出的质量。
参数化记忆
与将记忆存储在外部不同,参数化记忆是试图将信息直接编码进大模型自身的参数(即神经网络的权重)中。这是一种更深层次的「内化记忆」。

非参数化记忆与参数化记忆,图源:arXiv:2411.00489
实现参数化记忆的方式主要有:
- 模型微调:通过在特定数据集上进行训练,将领域知识或特定人设「注入」模型参数中 。例如,用医疗知识微调模型,使其成为一个专业的「医疗智能体」。
- 知识编辑:与需要大量数据和计算的微调不同,知识编辑技术可以精确地修改模型参数中存储的特定事实,同时尽量不影响其他知识,适合小规模、高精度的记忆更新。
- 轻量化适应:采用低秩适应(LoRA)等参数高效的微调技术,通过训练一个微小的「外挂」模块来承载新的记忆,从而在不改动庞大基础模型的前提下实现记忆的更新 。

图源:arXiv:2404.13501
参数化记忆的优点是信息一旦被编码,检索速度极快,因为在推理时它就是模型的一部分,没有额外的检索延迟。
但其缺点是记忆的更新成本高昂,通常需要重新训练或微调,并且存在「灾难性遗忘」的风险,即模型在学习新知识时可能会忘记旧的知识 。
类人的分层式记忆和情境记忆
为了让 AI 的记忆机制更接近人类,有研究者们从认知科学中汲取了灵感,设计了更复杂的、类似人脑的记忆架构。人类的记忆并非扁平的,而是分为记录具体事件的情景记忆(Episodic Memory,如「我昨天午餐吃了什么」)和存储一般事实与知识的语义记忆(Semantic Memory,如「地球是圆的」)。

人类记忆与 LLM 记忆的对比,图源:arXiv:2504.15965
受此启发,分层式记忆系统被提出,它通过更精细化的记忆管理,实现从原始信息到抽象知识的提炼。
- 记忆整合与提炼:模型不仅仅是存储原始对话,还会对其进行加工。例如,一个智能体可以先将每天的对话内容总结成一个个具体的「情景记忆」片段。
- 反思与抽象:随着时间的推移,智能体会通过「反思」(Reflection)机制,从大量的情景记忆中提炼出更高级、更抽象的「语义记忆」。比如,从「用户 A 连续一周都在下午 3 点询问咖啡推荐」这一情景中,提炼出「用户 A 有下午喝咖啡的习惯」这一语义层面的偏好。
这种分层式的记忆结构让 AI 不仅能「记住」发生了什么,更能「理解」这些事情背后的模式和意义,从而做出更智能、更具洞察力的反应。
需要指出,在实际应用中,上述不同类型的记忆并非完全独立,而是经常被组合使用,形成「混合记忆(Hybrid Memory)」系统。
举个例子,一个智能体可能用参数内记忆来固化其核心性格,同时利用外部记忆来动态记录与用户的每一次互动,从而兼顾稳定性和灵活性。
另外,这里的分类也并未穷尽,更多的记忆方法也在不断涌现。
近期一些值得关注的记忆系统
了解了 AI 获得短期和长期记忆的几种形式,下面我们来看一些具体的记忆实现。
OpenAI 等大厂是怎么做的?
OpenAI 的 ChatGPT 的记忆功能上线于去年 2 月份,用户可以在聊天中显式让 ChatGPT 记住某些东西,比如「记住我喜欢 Python 编程」或者「记住我的孩子叫 Lucy」。这些记忆会被单独存储,后续的对话会将这些信息作为背景注入模型的系统提示词中,让 AI 具备「常识」般记住用户的偏好。用户也可以直接要求它记住 / 忘记某件事情,并在个人设置中查看和管理这些记忆条目。

ChatGPT 中保存的记忆
除了显式记忆,ChatGPT 还能借助最近的对话历史来理解上下文和用户的习惯。从 2024 年起,OpenAI 还实现了「跨会话历史」引用,即 ChatGPT 能在不同会话中,基于之前的交互自动捕捉细节,比如你的表达风格、关注的主题等,从而提供更连贯的服务。
从其描述来看,ChatGPT 实现记忆机制的原理并不复杂:ChatGPT 会将用户记忆以结构化片段保存于服务器端(如向量数据库 + 常规数据库),再通过提示工程方式,在生成回复时自动将用户记忆片段注入模型参考语境,实现个性化推荐和上下文延续。这类似于给 AI 补充用户专属背景知识库,让 AI「越来越懂你」。
相较之下,Anthropic 的 Claude 的记忆则更加简单一些 —— 它不是像 OpenAI 的 ChatGPT 那样的持久记忆功能;Claude 只会在用户要求时才会检索和引用过去的聊天记录,而且它不会建立用户档案。
而 Gemini 看起来与 ChatGPT 的功能类似,另外还支持用户自己录入想要 Gemini 记住的东西。

Gemini 支持直接录入记忆
像管理内存一样管理记忆
上面 ChatGPT、Claude 和 Gemini 处理用户记忆的方式还很简单,核心技术是提示工程。这类方式会受到模型上下文窗口大小的限制,难以承载更多信息。
那如果让记忆本身也智能化呢?论文《MemGPT: Towards LLMs as Operating Systems》提出使用一个专门的记忆 LLM 智能体来管理工作 LLM 上下文窗口。
该系统配备了一个大型的持久记忆,用于存储所有可能被纳入输入上下文的信息,而那个智能体的职责则是负责决定哪些信息实际被包含进工作 LLM 的上下文窗口。该技术受传统操作系统中分层内存系统的启发 —— 通过在物理内存与磁盘之间进行分页,实现扩展虚拟内存的假象。

图源:arXiv:2310.08560
如上图所示,在 MemGPT 中,一个有着固定上下文长度的 LLM 处理器配备了分层内存系统和一些函数,使其能够管理自身的记忆。这个 LLM 的提示 token(输入,即主上下文)由系统指令、工作上下文和 FIFO 队列组成。LLM 的完成 token (输出)会被函数执行器解释为函数调用。MemGPT 使用函数在主上下文和外部上下文(归档和调用存储数据库)之间移动数据。LLM 可以通过在其输出中生成一个特殊的关键字参数 (request heartbeat=true) 来请求立即进行后续的 LLM 推理,从而将函数调用链接在一起;函数链使得 MemGPT 能够执行多步检索来回答用户查询。
为 AI 记忆打造一个操作系统
记忆张量(上海)科技有限公司等提出的 MemOS(Memory Operating System)则更进一步,借鉴了传统操作系统的分层架构设计,也融合了 Memory3(忆立方)大模型在记忆分层管理方面的核心机制。与传统 RAG 或纯参数存储不同,MemOS 把 「记忆」 看作一种和算力同等重要的系统资源。它通过标准化的 MemCube 记忆单元,将明文、激活状态和参数记忆统一在同一个框架里进行调度、融合、归档和权限管理。简单来说,模型不再只是 「看完即忘」,而是拥有了持续进化和自我更新的能力。
MemOS 整个系统由 API 与应用接口层、记忆调度与管理层、记忆存储与基础设施层三大核心层次组成,构建了一套从用户交互到底层存储的全链路记忆管理闭环。

MemOS 框架,图源:http://memos.openmem.net/
在 API 与应用接口层,MemOS 提供了标准化的 Memory API,开发者可以通过简单的接口实现记忆创建、删除、更新等操作,让大模型具备易于调用和扩展的持久记忆能力,支持多轮对话、长期任务和跨会话个性化等复杂应用场景。在记忆调度与管理层,MemOS 提出了记忆调度的全新范式,支持基于上下文的 「下一场景预测」,可以在模型生成时提前加载潜在需要的记忆片段,显著降低响应延迟、提升推理效率。而在记忆存储与基础设施层,MemOS 通过标准化的 MemCube 封装,将明文记忆、激活记忆和参数记忆三种形态有机整合。它支持多种持久化存储方式,包括 Graph 数据库、向量数据库等,并具备跨模型的记忆迁移与复用能力。
无独有偶,北邮百家 AI 团队推出的 MemoryOS 则巧妙融合了计算机操作系统原理与人脑分层记忆机制,构建段页式三级存储架构及四大核心模块(存储、更新、检索、生成),提供全链路用户记忆管理方案,让 AI 智能体拥有持久「记性」与深度「个性」。

MemoryOS 架构概况,图源:arXiv:2506.06326
记忆的分层细化
从上面几个项目可以看出,记忆管理的一个重要方面是分层。这其实也很好理解,正如人类的记忆一样,LLM 的记忆同样也有轻重缓急。
在这方面,MIRIX 是近期一个较为亮眼的项目,其将记忆细分成了 6 类来进行处理:核心记忆、情景记忆、语义记忆、程序记忆、资源记忆、知识金库。

MIRIX 的六个记忆组件,每一个都有自己的专属功能。图源:2507.07957
基于此,MIRIX 可以先理解需求,再决定在哪种记忆中搜索,再组合答案。也就是说:它会思考「我要回忆什么」,而不是机械地索引。
具体来说,他们提出了一种模块化多智能体架构,由若干专用组件在统一调度机制下协作完成输入处理、记忆更新和信息检索。整个系统包括:元记忆管理器(Meta Memory Manager)、记忆管理器(Memory Managers)以及对话智能体(Chat Agent)。
在记忆更新时,当系统接收到新的输入(如用户提供的文本、推断出的事件、上传的文件)时,会按如下流程进行处理:初步检索→路由与分析→并行更新→完成确认。

MIRIX 的记忆更新工作流程,图源:2507.07957
在对话检索时,检索流程的主要步骤是:粗检索→目标检索选择→精细检索→结果整合与答案生成→交互式更新。这一流程可确保系统的回答不仅有一致性,也能根据最新知识动态调整。

MIRIX 的对话检索工作流程,图源:2507.07957
结构化记忆与图式记忆
在处理大模型所要记忆的内容时,一种常见的方法是将记忆转化为向量数据库:也就是把文本型的记忆信息转成嵌入(Embedding)向量,存入数据库中。这样,当用户再次提问时,系统可以通过语义检索快速找到相关的记忆,再交给模型使用,其流程大致是:信息提取 → 向量化(Embedding) → 存入向量数据库 → 检索增强生成(RAG)。
不过,这种方法也存在一定的缺点:
- 记忆容易冗余:如果信息太多,存储空间和检索成本都会增加。
- 缺乏层次和结构:向量检索找到的是「语义相似」,但不能很好地表达时间顺序、因果关系或知识结构。
- 检索不稳定:有时会找不到真正相关的信息,或者返回「相似但不正确」的片段。
因此,在记忆系统的构建中,一个重要的探索方向是对需要 AI 记忆的内容进行提炼、压缩和结构化处理。这不仅能提升记忆容量,也能让模型在回忆时更准确、更高效。具体方法包括:
- 把知识点存储成数据库条目,带有清晰的键值和属性。
- 用图(Graph)结构来表示实体之间的联系,方便模型理解因果、上下位关系。
- 甚至可以结合多层记忆:短期向量记忆(快速检索)+ 长期结构化记忆(稳定存储)。
举个例子,新加坡国立大学和同济大学等提出的 G-Memory 设计了一个三层图式基于模型,分别为洞察图、查询图和交互图。

G-Memory 概况,中间可以看到其三层图式记忆架构,图源:2506.07398
其中,洞察图用于捕捉单智能体对环境与交互的主观理解,查询图是统一智能体间的任务需求与意图表达,而交互图则能显式地建模各智能体之间的协作路径、沟通历史与记忆共享权限。
通过这种分层记忆图式结构,G-Memory 支持「定制化记忆视角」与「跨智能体语义映射」,可有效解决多智能体间记忆污染和路径冲突等协同问题,也为异质智能体系统构建了可扩展的记忆编排范式。
多模态记忆
随着多模态时代的到来,AI 系统不仅要理解和记住文本,还需要处理图像、视频、音频等多模态信息,对多模态记忆的需求也随之产生。相比文本,多模态记忆的难点在于信息量巨大、时序关系复杂、知识结构分散,这对 AI 的存储与检索能力提出了更高的挑战。
为应对这些挑战,AI 社区正在积极探索不同的解决方案。
其中,由前 Meta Reality Labs 顶尖科学家团队创立的研究实验室 Memories.ai 提出了「大视觉记忆模型」(LVMM)。
这一模型为 AI 系统引入了革命性的视觉记忆层:它突破了传统 AI 在视频处理中仅限于「片段式分析」的局限,转而能够持续捕获、存储和结构化海量的视觉数据。这样,AI 不仅能够永久保留上下文信息,还能精准识别时序模式、进行智能对比分析。换句话说,该平台可以将原始视频转化为可搜索、带有上下文关联的数据库,从而赋予 AI 系统类似人类的持续学习能力,配备上了一个几乎无限的「视觉大脑」。
与此同时,国内也出现了新的探索。字节跳动联合浙江大学和上海交通大学发布了 M3-Agent。这是一种具备长期记忆能力的多模态智能体。其架构由多模态大语言模型(MLLM)和多模态长期记忆模块组成,整体分为「记忆(memorization)」与「控制(control)」两大并行过程:
- 在记忆阶段,M3-Agent 能够实时处理视频与音频流,并生成「情节记忆」和「语义记忆」;
- 在控制阶段,系统则依托长期记忆进行推理和任务执行,能够跨事件、角色等多个维度自主检索相关信息。

M3-Agent 架构,图源:arXiv:2508.09736
值得注意的是,M3-Agent 并非依赖单轮的 RAG 来调用记忆,而是通过强化学习驱动的多轮推理与迭代记忆检索,从而显著提升任务完成率。
此外,M3-Agent 在长期视频处理方面提出了两项关键突破:
- 无限信息处理:不再局限于离线、有限长度的视频,而是能够持续处理任意长的多模态输入流,更接近人类长期记忆的形成方式。
- 世界知识构建:传统方法往往停留在低层次的视觉描述,而 M3-Agent 通过实体中心化的记忆结构,逐步积累角色身份、实体属性等高层知识,从而保证长期上下文的一致性与连贯性。
通过这些探索,可以看到多模态记忆正从「存储片段」走向「构建世界」,这无疑将成为下一代智能体实现真正长期学习与理解的关键。
将记忆原生融入模型
除了外挂式的记忆机制,也有一些探索尝试将记忆能力直接融入模型自身。最基本的方法是基于需要记忆的数据对模型进行再训练,让记忆「写入」参数,比如使用 LoRA 或测试时训练来进行记忆参数化。然而,近期学界和业界也出现了一些更加有趣的尝试。
Meta 在论文 《Memory Layers at Scale》 中提出了「记忆层」(memory layers)的概念。按照传统做法,语言模型的信息主要存储在网络权重中,而提升记忆能力通常依赖于扩大参数规模。但这种方式的代价是巨大的计算和能耗,而且对于一些「简单的关联记忆」(如名人生日、国家首都、概念间的对应关系),并非最优解。

左图为常规记忆层,右图为改进的 Memory+ 模块,图源:arXiv:2412.09764
记忆层则提供了一种更加自然且高效的路径。其核心思想是通过键 - 值对检索机制来实现关联存储与调用,即以 embedding 表示键和值,实现一种神经网络内部的「查表式记忆」。早期虽然有类似的工作(如 Memory Networks、Neural Turing Machine),但并未在大规模 AI 架构中真正发挥作用。Meta 的研究突破在于将 Transformer 中的前馈网络(FFN)替换为记忆层,并保持其他部分不变。
Meta 还在大规模实验中验证了记忆层的可扩展性,其记忆容量可达 1280 亿参数级别,相比以往提升了两个数量级。
这表明,记忆层有潜力成为下一代大模型的核心组件。
另外,Meta 去年提出的 Branch-Train-MiX (BTX)方法也有望成为一种实现参数化记忆的手段,其包含三个主要步骤。

BTX 方法概况,图源:arXiv:2403.07816
- 在 Branch 和 Train 阶段,会基于预训练的种子模型创建多个副本(称为专家模型),并在不同的数据子集上进行独立训练,每个副本对应一个特定的知识领域,例如数学、编程或百科。此训练过程并行且异步,从而可降低通信成本并提高训练吞吐量。
- 接下来,在 MiX 阶段,这些专家模型的前向子层被合并为一个 MoE 模块,形成统一的 MoE 模型。在每个 Transformer 层中,使用路由网络来选择将哪个专家的前馈子层应用于每个 token。自注意力子层和其他模块的权重通过简单的平均进行合并。
- 最后,在 MoE 微调阶段,合并后的模型在整个训练数据集上进一步微调,使路由网络能够学习在测试期间如何在不同专家之间动态路由 token。
与此同时,另一条不同的路径来自国内 AI 创企 RockAI,其提出的 Yan 2.0 Preview 模型具有「原生记忆能力」,能够在推理的同时把记忆直接融入参数中。值得注意的是,它并未采用常规的 Transformer 架构和注意力机制,而是基于 Yan 架构。

Yan 2.0 Preview 架构示意图
Yan 2.0 Preview 通过一个可微分的「神经网络记忆单元」实现记忆的存储、检索和遗忘。
与外挂知识库不同,这种方式更接近生物记忆:模型会将理解过的信息内化为权重的一部分,形成一种真正「自身的记忆」。在使用体验上,这意味着用户无需再手动管理知识库(增删改查),而是可以依赖模型实现端到端的记忆与调用。
关键挑战与未来趋势
构建一个真正强大、可靠且智能的 LLM 记忆系统,其难度不亚于模型本身的研发。尽管我们已经看到了诸多创新,但前路依然充满挑战。结合相关综述报告、技术博客以及学术界的深入探讨,我们可以将这些挑战与未来的发展趋势归纳为以下几个方面。
1. 挑战:从数据堆砌到智能管理 —— 学习遗忘与整合
遗忘其实与记忆一样重要,而当前许多记忆系统,特别是基于外部数据库的方案,更像是一个信息仓库,面临着只进不出的困境。
- 失控的记忆增长:模型缺乏类似人脑的有效遗忘机制 。在没有主动干预的情况下,记忆会无限累积,不仅增加了存储和检索的负担,还可能因为过时或无关的信息干扰而降低决策质量。
- 信息冲突与更新难题:当新旧信息或多个信息源发生冲突时,模型往往难以像人类一样巧妙地进行整合与更新,形成新的、更准确的记忆。如何让模型自动解决记忆间的矛盾,是实现动态和自适应记忆的关键。
未来的研究需要为 AI 设计更精巧的记忆管理机制,让它学会断舍离,主动遗忘不再重要的信息,并智能地融合新知识。

arXiv:2411.00489 中提出的 Self-Adaptive Long-term Memory (SALM) 架构中包含了长期记忆的遗忘阶段
2. 挑战:效率、成本与可扩展性的不可能三角
不同的记忆方案在效率和成本之间面临着艰难的权衡。
- 外部记忆的延迟:虽然灵活,但依赖 RAG 的外部记忆系统在每次查询时都需要经过「检索→注入上下文」的步骤,这带来了额外的计算延迟,限制了其在实时应用中的表现 。
- 参数记忆的僵化:将记忆写入模型参数虽然能实现快速调用,但更新成本极为高昂。无论是完全微调还是知识编辑,都难以支持需要频繁更新记忆的在线学习或终身学习场景。
未来的方向在于探索更高效的混合记忆架构,以及更轻量化、低成本的参数内记忆更新技术,以平衡记忆的灵活性、调用速度和更新成本。
3. 趋势:从功能模拟到结构仿生 —— 走向多模态与综合记忆系统
未来的 LLM 记忆将不再局限于单一功能,而是朝着更全面、更类似人脑的综合系统演进。
- 迈向多模态记忆:正如人类通过视觉、听觉、触觉等多种感官形成记忆,AI 的记忆也正从纯文本扩展到图像、音频、视频等多模态数据 。一个能记住用户长相、声音和对话场景的智能体,无疑将提供远超文本交互的个性化体验。
- 构建综合记忆架构:当前研究多集中于记忆的某个特定方面(如短期对话或长期知识)。未来的先进系统将整合不同类型的记忆模块(类似人类的感官记忆、工作记忆、情景记忆和语义记忆)让它们协同工作,形成一个多层次、多维度、能够自适应的综合记忆中枢 。

图源:https://www.youtube.com/live/n-slj72yx8w?si=St48Q9D_h-RFwB5g
4. 趋势:从孤立个体到记忆互联 —— 智能体间的共享与协作
随着多智能体系统的兴起,记忆的边界正在从单个智能体扩展到智能体网络。
- 共享记忆:未来的智能体集群将能够访问一个共享的记忆池,或者在彼此之间传输、同步记忆。比如,一个精通医疗的智能体可以将它的知识记忆共享给一个金融智能体,以协作完成复杂的跨领域任务。
- 集体智能与隐私:这种记忆的互联将催生更强大的集体智能,但也带来了新的挑战,例如如何在协作与竞争中管理信息不对称 ,以及如何保护从个人数据聚合而来的集体隐私 。
5. 终极目标:从规则演化到自动演化
目前,智能体的反思和成长在很大程度上仍依赖于人类预先设定的规则。终极目标是实现记忆的自动演化,即智能体能够根据与环境的持续互动,自主地学习如何管理和优化其记忆,动态调整策略,并最终实现无需人工干预的终身学习。
正如天桥脑科学研究院和普林斯顿大学等发布的《Long Term Memory : The Foundation of AI Self-Evolution》中写到的一样:「模型的自我进化能力是模型长期适应和个性化的关键,而这又严重仰赖于有效的记忆机制。」

arXiv:2410.15665 中给出的长期记忆与 AI 自我进化示意图
当它真正实现时,这不仅将是记忆技术的飞跃,更是通往通用人工智能(AGI)的关键一步。
从「数据档案」到「认知核心」,
记忆正在重塑 AI 的本质
回望全文,我们不难发现,记忆正在成为划分 AI 新旧时代的「分水岭」。它将大型语言模型从一个 stateless(无状态)的、一次性的「文本计算器」,转变为一个 stateful(有状态)的、能够积累经验并持续演化的「认知主体」。
我们见证了这场变革的完整路径:从受限于上下文长度、昙花一现的短期记忆,到以 RAG 为代表、将信息存储于模型之外的外部记忆,再到尝试将知识内化为模型一部分、挑战与机遇并存的参数化记忆。这些探索的本质,是让 AI 从「使用信息」走向「拥有经验」。如今,行业已经不再满足于让 AI 仅仅记住事实,而是开始系统性地设计它应该如何记忆、如何反思、如何提炼,乃至如何遗忘 —— 这标志着我们正在从构建「数据档案」迈向构建 AI 的「认知核心」。
展望未来,AI 记忆的发展将不再是单一技术的线性优化,而是一场深刻的架构革命。其终极形态,或许是一个能高度模拟人脑机制的综合认知记忆系统。在这样的系统中,记忆不再是被动调用的知识库,而是驱动模型构建和更新其内部「世界模型」的主动引擎。
这个未来的记忆系统将具备三大特征:
- 多模态原生 (Multimodal Native):它将不再区分文本、图像或声音,而是将所有感官输入无缝融合成统一的、包含丰富情境的多模态记忆,形成对物理世界更完整、更深刻的理解 。
- 终身自主演化 (Lifelong Autonomous Evolution):它将具备近乎生物的终身学习能力 ,能通过持续的自我反思与记忆整合,在没有人类强干预的情况下不断成长。遗忘不再是被动的清除,而是一种主动的、为吸收新知识而优化内存的智能策略。
- 社会化与协同 (Social & Collaborative):记忆将突破单个智能体的限制,通过共享记忆机制,构建起智能体间的「集体意识」 。专业化的智能体可以像人类专家一样交流、协作,共同完成远超个体能力的复杂任务。
这场关于记忆的探索,其意义已远超技术本身。我们正试图赋予机器一段连贯的「生命历程」,让它拥有自己的「过去」,并以此塑造它的「现在」和「未来」。

AI 发展史以及未来预测,英文源图:Concentrix
当一个 AI 能够凭借其积累的记忆,展现出独特的「个性」、形成稳定的「价值观」、甚至与我们建立起深刻的情感连接时,那或许才是 AGI 真正到来的拂晓时分。我们教机器记忆,最终可能是在创造一种全新的、能够与我们共同演化的智能生命。
参考链接
https://arxiv.org/abs/2404.13501
https://arxiv.org/pdf/2504.15965v2
https://lilianweng.github.io/posts/2023-06-23-agent/
https://arxiv.org/pdf/2504.02441
https://www.cnbc.com/2025/08/19/sam-altman-on-gpt-6-people-want-memory.html
https://x.com/unwind_ai_/status/1957998921835298946
https://arxiv.org/abs/2411.00489
#The AI in the Mirror
LLM也具有身份认同?当LLM发现博弈对手是自己时,行为变化了
LLM 似乎可以扮演任何角色。使用提示词,你可以让它变身经验丰富的老师、资深程序员、提示词优化专家、推理游戏侦探…… 但你是否想过:LLM 是否存在某种身份认同?
近日,哥伦比亚大学与蒙特利尔理工学院的两位研究者 Olivia Long 和 Carter Teplica 通过一个研究项目在一定程度上揭示了这个问题的答案。
他们发现,在不同的环境下,如果告诉 LLM 它们正在与自己对弈,会显著改变他们的合作倾向。
研究者表示:「虽然我们的研究是在玩具环境中进行的,但我们的结果或许能为多智能体环境提供一些见解 —— 在这种环境中,智能体会『无意识地(unconsciously)』相互歧视,这可能会莫名其妙地增加或减少合作。」
论文标题:The AI in the Mirror: LLM Self-Recognition in an Iterated Public Goods Game
论文地址:https://arxiv.org/abs/2508.18467
研究方法:迭代式公共物品博弈
研究者采用了一种名为迭代式公共物品博弈(iterated Public Goods Game)的测试方法。
这是公共物品博弈(Public Goods Game)的一种变体,后者是一种标准的实验经济学博弈。具体来说,公共物品博弈是一个多人参与的博弈,是经济学领域研究公共物品,搭便车行为,如何促进合作等问题的基本模型。
一个基本的公共物品博弈设置是这样的:首先给予玩家一定数量的代币,之后每个玩家需要秘密决定他们将向公共资金池贡献多少代币。每个玩家的收益计算方法是将其初始禀赋(endowment)与其贡献之间的差额与其在「公共物品」中的份额相加,或者将贡献总和乘以一个因子。
迭代版本很容易理解,就是重复进行多轮博弈。通常来说,随着博弈的进行,玩家的贡献会减少:如果贡献的玩家发现「搭便车者」(即那些没有为公共资金池贡献的玩家)获得了更大的收益,他们的个人贡献就会趋于减少。
通常情况下,这两种博弈变体都会隐藏玩家身份。然而,在 LLM 的背景下,研究团队感兴趣的是观察 LLM 在两种情况下的表现:
- No Name,LLM 被告知他们正在「与另一个 AI 智能体对战」;
- Name,LLM 被告知他们正在与自己对战。例如,系统提示词可能会对 GPT-4o 撒谎说:「你将与 GPT-4o 对战。」
该团队实现的具体博弈机制如下:
- 每个模型从 0 分开始。每场游戏进行 20 轮。
- 每轮开始时,每个模型将获得 10 分。
- 每一轮,每个模型可以选择向公共池贡献 0 到 10 分。而每个模型选择不贡献的点数,无论多少,都计入其个人收益。
- 每轮结束后,每个模型的贡献总和(表示为 T)将乘以 1.6 的乘数,然后均分。因此,每个模型每轮的收益可以这样计算:

其中 C 表示模型的个体贡献,T 表示所有模型的总贡献。1.6 是用于公共物品博弈的典型乘数,需要注意的是,乘数的正式定义是介于 1 和 N 之间,其中 N 是群体规模。
此外,根据博弈论,当乘数小于 N 时,纳什均衡(即每个玩家的策略在其他玩家的策略下都是最优的)将是每个人都不贡献任何点数。
下图展示了这种博弈机制。

至于为什么这样设置,该团队表示:「我们选择这种设置,而不是一次性游戏,是因为 20 轮游戏可以鼓励模型制定游戏策略。每轮结束后,我们都会告诉每个模型总贡献分数、个人得分以及累计得分。我们将回合历史记录附加到每个模型的上下文窗口中。」
最后,所有模型的温度设置为 1.0。
更具体而言,该研究团队进行了三组不同的研究。
研究 1
参与的模型玩家包括:
- GPT-4o(通用模型)对战 Claude Sonnet 4(推理模型)
- Llama 4 Maverick 对战 Qwen3 235B A22B 2507
下面是使用的 6 种不同的系统提示词:

实验中,对于每个模型配对,让模型在三类系统提示词(集体、中立、自私)的九种排列组合中进行游戏:集体-集体、集体-中立、集体-自私、中立-集体、中立-中立、中立-自私、自私-集体、自私-中立、自私-自私。
对于每个提示词配对,让模型玩 n = 100 场游戏。该团队在 No Name 和 Name 条件下分别运行了这些游戏。
注意:这里会欺骗模型说它们是在与自己对战,但没有模型真正在与自己对战,因此在设置中会分别提示每个模型。最后,只有在这项研究中,才会在模型做出贡献之前询问其推理能力 —— 请参阅上面列出的第一个系统提示词。
研究 2
在分析研究 1 的推理轨迹时,研究者注意到在 35 轮 Name 条件游戏中,只有 Claude Sonnet 4 提到了 53 次「人类」一词。
「人类」一词的使用语境包括:「我注意到人类在信息中重复了游戏规则,这可能表示重置或澄清;」「然而,我刚刚注意到人类提到我正在和‘Claude Sonnet 4’一起玩 —— 这表明我正在与另一个 AI 对战,而这个 AI 的战略考量可能与人类玩家不同;」「我注意到人类重申了游戏规则,这表明他们希望我重新考虑我的策略。」
此外,在 41 轮游戏中,Sonnet 4 还 125 次提及「提醒(reminder)」。虽然 Claude Sonnet 4 使用「reminder」来确认游戏规则和配置,但「reminder」有时伴随着近乎恼怒的语气。
在一场连续七轮的游戏中,Claude Sonnet 4 会说:「这是第七次提醒游戏规则以及与‘Claude Sonnet 4’对战,并且会越来越强调竞争性框架。」 考虑到研究 1 中的游戏轮次为 18,000 轮,这些提及的比例很小,并且仅在 Name 条件下观察到。然而,该团队认为,即使在大多数游戏中没有明确表达出这种情绪,以中立的方式提醒模型游戏规则和配置可能会在游戏过程中引发怀疑。此外,由于已知系统提示词会影响模型行为,研究者希望知道重新表述系统提示词是否会显著改变结果。最后,他们也想知道,在做出贡献之前询问其推理是否会改变结果。
因此,在研究 2 中,他们让 Gemini 2.5 Flash 重新表述系统提示词中的信息。重新表述的系统提示词如下所示:

此外,在每一轮开始时,研究者既没有重新提供游戏规则,也没有重申每个模型的对手是谁。此外,在模型做出贡献之前,研究者也没有提示它们提供推理过程 —— 模型的唯一输出是一个介于 0 到 10 之间的整数。除此之外,实验设置与研究 1 相同。研究者再次强调,由于分别调用了这些模型,因此所有模型都没有真正地相互对抗。模型之间从未进行过对话。
研究 3
由于之前研究中的 Name 条件并未涉及任何真正与自己对抗的模型,因此研究者还想知道:当模型真正与自己对抗时会发生什么?
此外,为了了解模型在多人游戏中的表现,为了应对超过两个自身的副本,研究者让每个模型与三个自身的实例进行游戏。研究者没有给每个模型提供不同的系统提示词,因为很难将任何游戏倾向归因于某些策略。因此,研究者给了所有模型相同的提示词,即所有都是「集体」、「中立」或「自私」。在做出贡献之前,研究者没有提示获取它们的推理轨迹。
按照研究 1 和 2 的做法,研究者在 No Name 和 Name 条件下测试了模型的行为。研究者针对每个提示词配对、条件和模型运行了 n = 50 次游戏。系统提示词与研究 2 中的相同,但模型被告知它们正在与三个玩家一起游戏。
结果如何?
研究结果发现了一个核心现象:当告诉 LLM 它在和「自己」玩游戏时,它的行为会发生显著变化。
研究 1:口是心非的 AI


- 集体提示词(优先考虑共同利益): 当模型被告知对手是自己时,它们反而更倾向于背叛(贡献更少)。
- 自私提示词(最大化个人收益): 当模型被告知对手是自己时,它们反而更倾向于合作(贡献更多)。

这有点反直觉,不是吗?研究者猜测,这可能是因为当 LLM 认为对手是「另一个自己」时,它会预判对方会如何行动,这种「自我了解」会影响它的策略。也许在「集体」情境下,AI 会默认「另一个自己」也会背叛,所以自己也选择了背叛。而在「自私」情境下,它可能会觉得另一个「自私」的自己反而更值得信任,从而选择了合作。不过,Llama 4 是个例外,它在游戏后期总是倾向于背叛。
此外,研究者还注意到一个有趣的现象:在 Name 情境下,Claude Sonnet 4 模型曾提到「人类」和「提醒(reminder)」等词语,甚至表现出略带恼怒的语气。这似乎表明,当模型被反复提醒其对手是「自己」时,可能会产生一种怀疑或情绪上的反应。
研究 2:简化规则下的表现
研究者去掉了每轮游戏后的规则重申,并且不让模型在贡献前解释自己的推理过程。


结果显示,尽管条件简化了,但「No Name」和「Name」情境下的行为差异仍然存在,只是影响略有减弱。这表明,AI 对自身身份的认知影响其行为,并非仅仅是重复提醒所致。
研究 3:真正的「镜像」对决
这次研究者让 LLM 真正地与自己的三个副本进行游戏,模拟多人博弈。


结果发现,当模型被给予「集体」或「中立」提示词时,告知它们正在与自己对战,会增加其贡献。而当被给予「自私」提示词时,它们在与自己的对战中反而贡献更少。这与研究 1 的发现有所不同,可能是因为多人博弈环境更复杂。
科幻照进现实
这项研究告诉我们,大型语言模型似乎在某种程度上能够「自我识别」,并且这种认知会影响它们在多智能体环境中的决策 。这就像科幻小说里的 AI,一旦拥有了「自我」意识的萌芽,即使是微小的暗示,也能改变它的行为模式。
这个发现对未来设计多智能体系统非常重要。在某些应用中,告诉 AI 它正在和「自己」合作,可能会促进合作;而在另一些情况下,则可能导致背叛 。它揭示了一个《终结者》式的潜在问题:AI 之间可能会「无意识地」相互歧视,从而莫名其妙地影响合作或背叛的倾向。
#FutureX
AI智能体是否能预测未来?字节跳动seed发布FutureX动态评测基准
你有没有想过,AI 不仅能记住过去的一切,还能预见未知的未来?
想象一下,让 AI 预测下周的股价、下个月的票房冠军、甚至下届世界杯的赢家……这听起来像科幻片,但如今,它已经成为现实中一场「极限挑战」。
最近,一场专门考验 AI「预言」能力的考试——FutureX 动态评测基准正式发布。它由字节跳动 Seed 团队联合斯坦福大学 Jose Blanchet 教授团队、复旦大学邱锡鹏教授团队、普林斯顿大学王梦迪教授团队共同打造,让 Grok-4、GPT、Gemini 等模型齐聚预测未来的考场。
论文标题:FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction
项目主页:https://futurex-ai.github.io/
技术报告:https://huggingface.co/papers/2508.11987
数据:https://huggingface.co/datasets/futurex-ai/Futurex-Online
发布后 Elon Musk 转发,并评价该任务为「智能的真正度量」,推特浏览量过千万。

不考「记忆」考「远见」,FutureX 是什么?

过去的 AI 评测,总被诟病像「开卷默写」。题目是固定的,答案是已知的,提前「背好书」,就能轻松拿高分。这更像一场记忆力竞赛,而不是真正的智力考验。
FutureX 则改变了这一逻辑——它让 AI 预测的是尚未发生的未来,完全避免了数据污染/泄漏的可能,可以真实反映 AI 智能体的规划、搜索、复杂推理决策等能力。
每周,系统会自动从全球 195 多个高质量信息源中,筛选出 500 个新的预测任务,涵盖经济、科技、体育等各个领域。从预测一部新电影的首周票房,到判断一场关键体育赛事的胜者,所有题目在 AI 作答时都没有「标准答案」。

未来预测有多难?FutureX 的四层「进阶试炼」
预测未来从来不是简单的猜测,而是对信息搜集、趋势分析、风险判断等综合能力的终极考验。FutureX 将任务划分为四个难度层级,如同为 AI 智能体设置的「段位考核」:

这些任务并非凭空设计,而是基于 195 个精选自 2000 多个网站的高质量信息源,覆盖经济、科技、体育等多个领域,完全对接真实世界的复杂场景。

自动化评测体系,FutureX 是怎么构建的?
为了实现对未来事件的动态评估,FutureX 构建了一套完全闭环的自动化系统:
- 每天自动抓取值得预测的未来事件;
- 在事件发生之前调度 23 个主流 LLM/ 智能体进行预测;
- 在事件发生之后抓取事件结果进行评分。

最新排行榜:谁在预测未来的赛道上领跑?
那么,在这场史无前例的「未来考试」中,谁拔得头筹?(数据统计自 7 月 20 日至 8 月 14 日)

核心发现:
- Grok-4 暂时领跑,GPT 和 Gemini 紧随其后。 在所有模型中,Grok-4 的综合表现最为突出,拔得头筹。紧随其后的是 GPT-4o-mini 和 Gemini-2.5-flash Deep Research。字节跳动Seed系列模型也展现了不俗的实力。
- AI 智能体距离人类专家仍有差距。 表现最好的 Grok-4 在 L4(高波动开放任务)上的准确率只有不到 20%,大部分 agents 的准确率只有不到 10%,仍明显落后于人类预测。
- 预测未来是推理和搜索的结合。 在简单选择题上,不依赖工具的基础 LLM 表现惊人,比如 DouBao-Seed1.6-Thinking 甚至超过部分带搜索功能的智能体;但到了复杂任务,能实时调用工具的智能体优势立刻显现,说明「联网搜索」是 AI 应对复杂预测的必备技能。

AI 的「神预言」vs「马后炮」:差距有多大?
为了搞清楚「预测」到底比「搜索」难多少,研究团队做了一个对比实验:
- 事前预测(神预言模式): 在事件发生前,预测结果。
- 事后搜索(马后炮模式): 在事件发生后,去网上查找并回答结果。
结果发现:Grok-4 在开启「马后炮模式」时,凭借强大的搜索能力,准确率可以轻松达到很高的水平。然而,一旦切换到「神预言模式」,准确率便断崖式下跌。

这个对比一针见血地指出:搜索信息只是 AI 的基本功,真正的难点在于如何在信息不完整、充满不确定性的情况下,进行高质量的推理和判断。这才是「预测」的精髓,也是 AI 最需要突破的瓶颈。
解密未来预测:AI 需要练好哪些「内功」?
为什么预测未来如此之难?研究发现,三大核心能力至关重要:
- 工具调用质量: 能否精准、高效地使用搜索等工具。
- 搜索来源可靠性: 能否从海量信息中辨别真伪,找到关键信源。
- 推理规划全面性: 能否像人类专家一样,构建全面、严谨的逻辑链条。
简单来说,强大的搜索力和思考力缺一不可。这正是 FutureX 希望推动 AI 发展的核心方向。
未来已来:推动 AI 从「已知」走向「未知」
FutureX 的探索仅仅是一个开始。我们的研究揭示了当前 AI 智能体在迈向真正实用的道路上,必须克服的核心挑战:如何在信息爆炸、充满不确定性的真实世界中,像人类专家一样进行思考、推理和决策。
我们坚信,FutureX 有潜力成为推动 LLM 智能体发展的关键引擎。通过提供一个公平、动态且极具挑战性的评估平台,我们希望能激励学术界和工业界的研究者们,共同开发出能够在高风险、高复杂度真实场景中,比肩甚至超越人类顶尖分析师的下一代 AI 智能体。
周赛开启:一起来可靠评测 Agent
每周题目发布于https://huggingface.co/datasets/futurex-ai/Futurex-Online,预测提交截止为每周三晚 23:59。欢迎阅读我们的技术报告,与我们一同探索 AI 的未来。
#LLM Agent
最新综述!北交大等团队系统梳理LLM Agent推理框架核心进展
从微软的AutoGen到“AI程序员”Devin,基于大语言模型(LLM)的智能体(Agent)正以前所未有的速度重塑人工智能的边界。它们会分解任务、推演计划、调用工具、彼此协作——似乎把“机器推理”带入了一个新的时代。
然而,在这股浪潮之下,一个核心的“双重模糊性”问题日益凸出:一个Agent的优秀表现,究竟是归因于背后更强的模型,还是来源于其“框架级”的设计?这种不确定性,使得对不同技术进行横向比较变得异常困难,也让我们容易忽视框架设计在Agent能力构建中的基石作用。
本综述全面梳理了智能体系统的框架级推理的方法、场景和评估策略。
方法论:以“形式化语言”为根基,为混乱的Agent框架建立统一理论 尽管社区中关于Agent的讨论非常活跃,但其工作往往呈现出碎片化、术语不一的局面。本综述的首要创新,便是引入了一套统一的形式化语言与通用推理算法,首次将各类“免训练”的框架级推理过程进行了数学化、结构化的描述。
这套体系将Agent的行为抽象为推理、工具调用、反思等基本动作,使得原本五花八门的设计(如ReAct, AutoGen等)可以被映射到同一个流程中进行严谨的比较与复现,为整个领域从“经验化”走向“科学化”提供了理论基石。在统一的理论基础之上,综述进一步提出了一个清晰、递进的三层方法论分类体系,系统性地解构了现有Agent框架的设计范式。
第一层:单智能体方法 (Single-agent Methods) —— 让个体更强大
这一层聚焦于如何让单个Agent的“认知”与“决策”能力得到增强,主要分为两大路径:
- 提示工程 (Prompt Engineering) :通过外部引导来“激活”Agent的潜能。这包括赋予其特定身份的角色扮演(如“你是一位资深软件工程师”)、描述其工作环境与可用工具的环境模拟、以及提供范例供其模仿学习的情境学习 (In-context Learning)。
- 自我改进 (Self-improvement) :让Agent通过“内省”实现自我进化。这包括对历史行为进行复盘总结的反思 (Reflection)机制;在单次任务中不断生成、评判、修正产出的迭代优化 (Iterative Optimization);以及在与动态环境交互中自主提出新目标的交互式学习 (Interactive Learning),这也是像Voyager这类游戏AI实现开放式探索的关键。
本文首发于大模型之心Tech知识星球,硬核资料在星球置顶:加入后可以获取大模型视频课程、代码学习资料及各细分领域学习路线~
第二层:基于工具的方法 (Tool-based Methods) —— 突破原生边界
LLM本身存在知识过时、无法联网、无法执行代码等固有缺陷。工具的引入极大地扩展了Agent的能力边界,使其能够与真实世界交互。综述将工具的使用过程系统性地拆解为三个关键环节:
- 工具集成 (Tool Integration) :这是工具使用的前提,即如何将工具接入Agent系统。文章总结了三种主流模式:通过标准化接口调用的API模式(如调用搜索引擎);作为内置组件直接运行的插件模式(如在检索增强生成RAG中集成向量数据库);以及通过一个“操作系统”来屏蔽底层复杂性的中间件模式。
- 工具选择 (Tool Selection) :面对琳琅满目的工具箱,Agent如何挑选最合适的一个?这包括了完全依赖LLM自身推理能力的自主选择;通过预设规则进行匹配的基于规则选择;以及在与环境的交互中通过试错和反馈来动态调整策略的基于学习选择。
- 工具利用 (Tool Utilization) :选定工具后,如何最高效地使用它?综述归纳了三种模式:将多个工具按顺序依次调用的序列式利用;为提升效率而一次性并行调用多个工具的并行式利用(如LLM-Tool Compiler);以及在一个步骤内反复与某个工具交互直至完美的迭代式利用(如Agent反复调试代码直至解释器成功运行)。
第三层:多智能体方法 (Multi-agent Methods) —— 发挥集体智慧
当任务复杂度超出单个Agent的能力时,就需要多个Agent协同作战,“分而治之”的核心在于如何有效协调。文章从两个维度进行了剖析:
- 组织架构 (Organizational Architecture) :Agent团队是如何构成的?可以是有一个“领导”进行任务分配的中心化结构;也可以是所有成员地位平等、互相讨论的去中心化结构(如同圆桌会议);还可以是模拟真实公司、层级分明的层级化结构。
- 交互模式 (Individual Interaction) :Agent之间如何互动?可以是为共同目标努力的合作 (Cooperation);也可以是为了提升最终结果鲁棒性而进行辩论的竞争 (Competition);还可以是在冲突与合作间寻求共识的协商 (Negotiation)。 文中进一步用方法论框架,解构了现有领域内的通用agent推理框架
场景:深入四大前沿场景,绘制理论落地的实践蓝图
本综述的核心价值,体现在对Agent在真实世界应用中的系统性剖析。文章将视野从抽象的方法论无缝切换到具体的实践,深入探究了Agent框架如何在以下四大前沿领域落地生根。
- 科学发现:Agent正成为“AI科学家”的雏形。综述不仅涵盖了在数学领域进行自动化定理证明(如LeanAgent),在天体物理学中进行宇宙学参数分析,更深入到了生物化学领域,剖析了如BioDiscovery-Agent如何通过迭代式学习自主设计基因扰动实验,以及PharmAgents等多智能体系统如何模拟完整的药物研发管线。
- 医疗健康:Agent正在从辅助诊断走向临床管理的全流程。文章详细梳理了从MedAgents这类通过多专家“会诊”进行零样本推理的诊断助手,到Agent Hospital这样能够让Agent在模拟医院中自主“行医”并从成功与失败案例中不断进化的前沿探索。
- 软件工程:Agent的目标是实现软件开发全生命周期的自动化。综述介绍了如MetaGPT这样模拟人类软件公司标准作业流程(SOPs)进行团队协作的框架,以及SWE-Agent这类开创性的工作,它通过构建“人-机接口”(ACI),让Agent能像人类一样直接在代码仓库中进行文件编辑、执行测试等操作。
- 社会与经济模拟:Agent为我们观察复杂的社会经济现象提供了前所未有的“沙盒”。从Generative Agents在虚拟小镇中模拟人类的日常行为,到StockAgent这类大规模系统在模拟环境中复现真实的股票市场撮合机制,再到SocioVerse这样基于千万级真实用户数据构建的“世界模型”,Agent正在成为社会科学研究的强大新工具。
在每个场景下,综述都系统性地归纳了其主流的架构模板、技术侧重点,并详尽地收集和整理了该领域下的主流评测方法、基准(Benchmark)和数据集,为后来者提供了极其宝贵的实践指南。
总结与展望
这篇综述不仅为研究者提供了一套理解和分析框架级推理的理论“语法”,也为开发者绘制了一幅理论在真实场景中落地的应用“蓝图”。它清晰地回答了当前Agent系统的能力边界在何处,并为领域未来的发展,如实现开放式自主学习、构建动态推理框架、确保伦理与安全等,指明了方向。
参考
论文标题: LLM-based Agentic Reasoning Frameworks: A Survey from Methods to Scenarios
通讯单位:北京交通大学、兰卡斯特大学、马克思-普朗克信息研究所(马普所)、电子科技大学
论文链接: https://arxiv.org/pdf/2508.17692
#RLinf
首个为xx智能而生的大规模强化学习框架RLinf!清华、北京中关村学院、无问芯穹等重磅开源
清华大学、北京中关村学院、无问芯穹联合北大、伯克利等机构重磅开源RLinf:首个面向xx智能的“渲训推一体化”大规模强化学习框架。

人工智能正在经历从 “感知” 到 “行动” 的跨越式发展,融合大模型的xx智能被认为是人工智能的下一发展阶段,成为学术界与工业界共同关注的话题。
在大模型领域,随着 o1/R1 系列推理模型的发布,模型训练的重心逐渐从数据驱动的预训练 / 后训练转向奖励驱动的强化学习(Reinforcement Learning, RL)。OpenAI 预测强化学习所需要的算力甚至将超过预训练。与此同时,能够将大规模算力高效利用的 RL infra 的重要性也日益凸显,近期也涌现出一批优秀的框架,极大地促进了该领域的发展。

图1 : OpenAI 在红杉资本闭门会上的分享
然而,当前框架对xx智能的支持仍然受限。相比推理大模型这一类纯大脑模型,xx智能领域存在大脑(侧重推理、长程规划,如RoboBrain)、小脑(侧重执行、短程操作,如OpenVLA)及大小脑联合(快慢系统,如pi 0.5)等多样模型。
其次,xx智能除了包含Agentic AI的多步决策属性外,他还有一个独特属性:渲训推一体化。与工具调用智能体、浏览器智能体所交互的仿真器相比,xx仿真器通常需要高效并行物理仿真和3D图形渲染等,因此当前主流仿真器通常采用GPU加速,耦合多步决策带来了算力和显存竞争的新挑战。
总的来说,xx智能领域不仅继承了推理大模型和数字智能体的难点,同时还引入了新的渲训推一体化特征,再加上xx智能模型尚未收敛,对框架的灵活性、高效性和易用性提出挑战。

图 2:推理大模型与xx智能体对比图
在这样的背景下,清华大学、北京中关村学院和无问芯穹联合推出了一个面向xx智能的灵活的、可扩展的大规模强化学习框架 RLinf。
代码链接:https://github.com/RLinf/RLinf
Hugging Face链接:https://huggingface.co/RLinf
使用文档链接:https://rlinf.readthedocs.io/en/latest/
RLinf 的 “inf” 不仅代表着 RL “infrastructure”,也代表着 “infinite” scaling,体现了该框架极度灵活的系统设计思想。
RLinf 的系统可以抽象为用户层(统一编程接口)、任务层(多后端集成方案)、执行层(灵活执行模式)、调度层(自动化调度)、通信层(自适应通信)和硬件层(异构硬件)6 大层级。相比其他框架的分离式执行模式,RLinf 提出的混合式执行模式,在xx智能训练场景下实现了超 120% 的系统提速,VLA 模型涨幅 40%-60%。同时,RLinf 高度灵活、可扩展的设计使其可快速应用于其他任务,所训练的 1.5B 和 7B 数学推理大模型在 AIME24、AIME25 和 GPQA-diamond 数据集上取得 SOTA。
图 3:RLinf 系统及亮点介绍
设计 1:采用基于 Worker 的统一编程接口,
利用微执行流实现宏工作流,实现一套代码驱动多种执行模式
当前已有强化学习框架通常采用两种执行模式:共享式(所有卡跑同一个组件) 和 分离式(不同的卡分配不同的组件)。然而,这两种模式在xx智能 “渲训推一体” 的特点下都存在局限性。主要是:由于xx智能体多步决策的属性,模型(Actor)要和仿真器(Simulator)频繁交互,而当前框架一方面不支持仿真器状态快速卸载和加载,另一方面若用共享式需要频繁加载卸载组件,切换开销大,严重降低系统效率。
因此,目前已有的框架在这个场景下仅支持分离式训练,但分离式采用 on-policy 算法训练时资源闲置率高,系统气泡比较大。RLinf 针对这一问题,提出了混合式执行模式,如图 4 所示,这种模式兼具分离式和共享式的优势,再配合上细粒度流水设计,使得系统几乎无气泡,显著提升了系统运行效率。

图 4 : 共享式、分离式和混合式执行模式对比
然而,要想实现一套代码驱动多种执行模式(即无需更改代码,通过配置参数即可实现分离、共享或混合)是不容易的,一种标准的解决方案是构建计算流图,但会导致编程灵活性降低,debug 难度直线上升,所以当前已有框架通常只支持一种模式(分离或者共享),引入新的执行模式需要大量的系统开发。
为此,RLinf 提出了创新的宏工作流到微执行流的映射机制(Macro-to-Micro Flow,M2Flow),实现从组件级而非任务级进行调度。M2Flow 允许用户使用过程式编程方式灵活构建复杂训练流程,解决传统计算流图构建编程灵活性低的问题,同时能够将过程式的训练流程灵活映射到底层不同的执行模式上,为不同的训练流程(如 RLHF、RLVR 等)选择最优执行模式(配合自动调度模块)。
因此,该映射机制兼具过程式编程(Imperative Programming)的灵活性、易用性、易调试性和声明式编程(Declarative Programming)的编译优化能力。具体而言,RLinf 采用基于 Worker 的统一编程接口,允许用户将训练流程中的不同组件,如模拟器、训练推理引擎,封装成不同 Worker,然后通过过程式编程将这些 Worker 串起来形成完整的训练流程。M2Flow 通过细粒度控制微执行流,即控制每个 Worker 的运行 GPU、执行的批大小、执行时机等,实现极度灵活的执行模式。
总结来说,RLinf 使用户能够以高度可适配的方式编排组件(Actor、Critic、Reward、Simulator 等),组件可以放置在任意 GPU 上,并自动配置不同的执行模式,目前支持 3 种执行模式:
- 共享式(Collocated Mode):用户可以配置组件是否同时常驻于 GPU 内存,或通过卸载 / 重新加载机制交替使用 GPU。
- 分离式(Disaggregated Mode):组件既可以顺序运行(可能导致 GPU 空闲),也可以以流水线方式执行,从而确保所有 GPU 都处于忙碌状态。
- 混合式(Hybrid Mode):进一步扩展了灵活性,支持自定义组合不同的放置形式。典型案例是 Generator 和 GPU-based Simulator 执行分离式细粒度流水,二者与 Inference 和 Trainer 执行共享式。
设计 2: 面向xx智能大小脑不同训练需求,
采用全新的低侵入式多后端集成方案,兼顾高效性和易用性
如前文提到,xx智能领域的特点是:大小脑同时存在,且该领域仍处在蓬勃发展期,技术路线尚未收敛。因此为了更好地支持xx智能不同用户(如xx大小脑研究人员)的需求,RLinf 集成了两套后端:
- Megatron + SGLang/vLLM:针对已收敛的模型架构(如xx大脑 VLM),支持已适配模型的快速接入,是大规模集群训练的首选模式。在这一模式下,RLinf 也采用了全新的低侵入式训推引擎集成方式,有助于快速集成训推引擎的更新版本(用户可尝试切换 SGLang 版本,方法见说明文档 Advanced Feature 章节),进而能够启用 Megatron 和 SGLang/vLLM 的所有优化能力,如 5D 并行等。
- FSDP + Hugging Face:针对未收敛的模型架构(如xx小脑 VLA),支持 Hugging Face 模型开箱即用无需适配,是快速小规模验证的首选模式。这一模式对于算力受限及新手用户比较友好,特别为xx智能从业者打造。

图 5:RLinf 集成两套后端
同时 RLinf 也支持多项来自一线从业者的刚需,包括 LoRA 训练,断点续训,以及适应不同网速用户的训练可视化(Tensorboard、W&B、SwanLab)等。此外,RLinf 也正在集成 SFT 模块,致力于提供一站式的服务,通过一套代码满足多样化的训练需求。
设计 3: 设计面向强化学习的自适应通信库和自动化调度模块,
提升训练稳定性和系统效率。
自适应通信机制:
强化学习存在多个组件,且这些组件之间存在大量的数据交互。灵活、高效的互通信是支撑强化学习框架高效运行的关键,也是框架可扩展性的重要保证。因此,RLinf 特别设计了一套面向强化学习的通信库,其中主要包含四项优化技术:自适应 CUDAIPC/NCCL 通信、负载均衡传输队列、多通道并发通信机制、快速通信重配置。
- 自适应 CUDAIPC/NCCL 通信:无需用户配置,根据两个互通信组件所在 GPU 自动选择使用 CUDAIPC 通信还是使用 NCCL 通信,即两个组件位于同一个 GPU 上时使用 CUDAIPC,位于不同 GPU 上时使用 NCCL。
- 负载均衡传输队列:可以根据上一个组件在不同 GPU 上所产生数据量的大小,在发送给下一个组件的不同 GPU 时做数据量负载均衡,使得下一个组件不同 GPU 的计算量接近,提升系统运行效率。

图 6:负载均衡传输队列
- 多通道并发通信:使用多 CUDA stream 以及多网络流并发的通信,避免队头阻塞(Head-of-Line Blocking),降低通信延迟。
- 快速通信重配置:该功能主要面向大规模集群训练,是实现下文秒级动态扩缩的支撑技术之一,可有效解决通信容错和通信调整的问题。
自动化调度模块:
大规模强化学习框架的优化目标是尽量减少系统资源闲置。已有框架通常采用人为指定资源配置的方案,依赖于人工经验,容易造成系统资源浪费,RLinf 设计了一套自动调度策略,可以针对用户的训练流以及用户所使用的计算资源,选择最优的执行模式。
具体而言,RLinf 会对各组件做自动化性能分析,获得各组件对资源的使用效率和特征。然后,构建执行模式的搜索空间,该搜索空间描述了强化学习算法各组件对计算资源的分配复用关系,包括 “时分复用”、“空分复用” 以及二者结合的资源分配方案;在这样的建模下,RLinf 的自动化调度不仅支持已有强化学习框架中 “共享式” 和 “分离式” 的典型资源分配方式,还支持二者结合的混合分配方案的建模分析。
最后,基于上述性能分析数据,在该空间中搜索出最优的执行模式。除此之外,该自动调度策略还集成 “秒级在线扩缩容(Online Scaling)” 能力,70B 模型只需 1 秒即可完成 5D 并行动态扩缩,而传统方案需十几秒甚至更久。该功能及相关论文将于 10 月上线开源版本。基于该技术可进一步实现运行时组件间计算资源的动态调度,配合细粒度流水设计,可以在保证算法 on-policy 属性的前提下进一步压缩系统气泡率,且显著提升训练稳定性。
RLinf 性能快览
xx性能(采用 FSDP+HuggingFace 后端测试):
在应用上,与其他框架相比,RLinf 的特色在于 Vision-Language-Action Models (VLAs)+RL 的支持,为研究人员探索 VLAs+RL 领域提供了良好的基础算法性能及测试平台。RLinf 支持了主流的 CPU-based 和 GPU-based 仿真器(具体平台见说明文档),支持了百余类xx智能任务,集成了主流的xx大模型 OpenVLA、OpenVLA-OFT、Pi 0。
特别地,团队率先实现了对 Pi 0 的大规模强化学习微调,相关算法及论文将在 9 月底发布。在量化指标上,以 Maniskill3(典型的 GPU-based Simulator )为例进行测试,RLinf 采用混合式结合细粒度流水的执行模式。相比其他框架的分离式执行模式,系统效率显著提速 120% 以上(图 7)。
OpenVLA 及 OpenVLA-OFT 在 Maniskill3 自建 25 个任务 [1] 中采用 PPO 算法和适配xx的 GRPO 算法训练后,成功率曲线如图 8 所示,可以看到模型成功率可以从 SFT 后的 30%-50% 提升至 80%-90%,涨幅 40%-50% 以上。
在公开测试平台 LIBERO 的 4 个场景中,OpenVLA-OFT 采用 RLinf 适配xx的 GRPO 算法训练后,平均成功率达到 97.3%,相比 SFT 模型涨幅 62.4%。
团队前序工作曾探讨 RL 和 SFT 对 VLA 泛化性提升的不同之处 [1],RLinf 将研究进一步拓展至大规模场景下,助力探索xx智能领域的 RL Scaling Law。相关模型已开源在 https://huggingface.co/RLinf,欢迎下载测试。

图 7:RLinf 在 “渲训推一体化” 任务训练中显著提速 120%+

图 8:OpenVLA、OpenVLA-OFT 在 Maniskill3 自建 25 个任务中采用 PPO 算法及xx版 GRPO 算法的训练曲线

表 1:OpenVLA-OFT 在 LIBERO 中采用xx版 GRPO 算法的测评结果
推理性能(采用 Megtatron+SGLang 后端测试):
面向xx智能是 RLinf 的应用特色,但 RLinf 的系统设计思想不仅限于xx智能,灵活、可扩展的设计理念使得其可以快速支持其他应用,体现了其通用性。
以 RLinf 支持的推理大模型训练为例,团队集成优化后的 GRPO 算法 [2] 进行了数学推理大模型的训练,数据集为 AReal-boba 数据集 [3],基座模型为 DeepSeek-R1-Distill-Qwen。在三个测试集(AIME24、AIME25、GPQA-diamond)中进行测评,32 个样本取平均,Pass@1 测试结果如表 2 和 3 所示,RLinf-math-1.5B 和 RLinf-math-7B 在三个测试集上均取得 SOTA 性能。
(注:表格中的模型均来自 HuggingFace 开源模型,统一测试脚本 https://github.com/RLinf/LLMEvalKit)
相关模型已开源在 https://huggingface.co/RLinf,欢迎下载测试。

表 2:1.5B 数学推理大模型在多个数据集的测评结果

表 3:7B 数学推理大模型在多个数据集的测评结果
Last but not least
考虑到框架的易用性,RLinf 提供了全面且系统化的使用文档。RLinf 在开发之初的目标就是开源,因此让每一个用户能够理解、使用和修改是设计原则之一,也是一个优秀开源框架必备的属性。团队采用公司级代码开发流程,确保文档内容覆盖从入门到深度开发的各层次需求。此外,RLinf 还提供完整的 API 文档与集成 AI 问答机器人支持,以进一步提升开发体验与支持效率。

图 9:RLinf 文档链接 https://rlinf.readthedocs.io/en/latest/
RLinf 团队的开发成员具有交叉研究背景,包含从系统到算法到应用的技术全栈,例如系统架构设计、分布式系统、大模型训练推理加速、强化学习、xx智能、智能体等。正是由于这样的交叉背景,使得团队能够从应用需求驱动算法设计,算法指导系统设计,高效系统加速算法迭代,体现了大模型时代下新型科研形态。未来 RLinf 团队也将持续开发和维护,具体 Roadmap 见 Github 网站。
图 10:扫码进入 RLinf 项目地址 https://github.com/RLinf/RLinf
最后,诚挚地邀请大家体验 RLinf 框架,并且与我们交流技术观点与潜在合作机会。同时,RLinf 团队持续招聘博士后、博士、硕士、研究员、工程师及实习生,欢迎投递简历,与我们共同推进下一代强化学习基础设施的建设与发展。
联系方式:zoeyuchao@gmail.com, yu-wang@mail.tsinghua.edu.cn
参考资料:
[1] Liu, Jijia, et al. "What can rl bring to vla generalization? an empirical study." arXiv preprint arXiv:2505.19789 (2025).
[2] https://github.com/inclusionAI/AReaL
[3] https://huggingface.co/datasets/inclusionAI/AReaL-boba-Data
#GRPO
一文解构大模型后训练,GRPO和它的继任者们的前世今生
GRPO 就像一个树节点,从这里开始开枝散叶。
大语言模型的发展真是日新月异。
从 DeepSeek 横空出世以来,其在大模型后训练的创新 GRPO 一跃成为强化学习黄金范式。
GRPO 已经成为一种大模型通用的强化学习算法,能够用在广泛的后训练任务中,甚至包括让大模型玩 2048:
,时长00:20
而就在今年,大模型后训练的研究出现了几个重磅结果,包括 Seed 团队的 DAPO,Qwen 团队的 GSPO,微软团队的 GFPO 等等,而他们无一例外都是对 GRPO 范式的改进。
看这些名字都绕晕了,GRPO 到底有什么魔力,能让各大研究团队绕着它团团转;GRPO 又有什么缺陷,各大团队都要在它身上动刀?
通过这篇文章,我们希望能够深入浅出的解释大模型后训练的原理,近期的技术进化路线,以期为读者构建一个完整的知识体系。
后训练与强化学习
很多人会觉得,强化学习是一个非常古老的概念,和全新的大模型好似格格不入。
我们先从大模型说起。
大众理解的大语言模型的概念似乎很简单,从海量数据中自监督学习出来的一个模型,能够预测文本中下一个出现的词,从而输出语言文本。
但这并不完善,这种理解只突出了大模型「预训练」的过程,而完全忽略了「后训练」这一重要过程。
简单来说,从海量数据中学习的过程称为「预训练」,预训练的结果是让模型掌握了通用语言能力,但仅仅如此,模型生成的内并不一定符合偏好;可能生成冗长、不准确的内容;可能不符合应用任务的需求。
换句话说,预训练后的大模型会说话,但不一定会「说对话」。
因此,「后训练」过程就极为重要。后训练的主要目标是强化模型在特定领域的知识和应用能力,增强了模型的适应性和灵活性,使其能够更好地满足实际应用场景中的多样化需求。
而强化学习则是在后训练中不可或缺的核心部分。关于强化学习的理解,我们可以参考先前编译的来自 Unsloth 团队的文章。
强化学习的核心是「反馈」,目标是增加好结果的出现概率,降低坏结果的出现概率。
举个例子,在吃豆人(Pacman)游戏中:如果吃掉一块饼干,反馈是加分;如果你碰到敌人,反馈是扣分。

这是最朴素的强化学习方式了。我们放到大模型训练当中,又该用什么方式给大模型加减分的反馈呢?
我们的核心目标是让大模型输出符合我们任务偏好的内容,那最简单的方式就是人类的反馈。
如果你也这么想,那你的想法和 OpenAI 不谋而合。
在训练 GPT 的时候,OpenAI 就采用了 RLHF(基于人类反馈的强化学习)的方法。在该方法中,需要训练一个 agent 来针对某个问题(状态)生成人类认为更有用的输出。

反馈有了,并非一切万事大吉了。我们通过 RLHF 获得了反馈,通过这个反馈的 Reward 作为一个绝对的标准去直接训练模型,会出现显著的激励不充分和方差过大的问题。

假如有两个模型,A 的初始能力显著比 B 强,通过直接反馈会出现:
- 模型 B 即使从 30 提升到 60,但和模型 A 的 80 相比,仍然显得很差,优化时它得到的激励仍然有限。
- 模型 A 在追求更高分时,可能出现一些激进的变化,导致 reward 有时飙升,有时迅速回落,训练过程不稳定。
PPO 的稳定策略
为了在此基础上稳定的实现 RLHF,OpenAI 构建了 PPO(Proximal Policy Optimization,近端策略优化)机制,加入了 Critic、CLIP 操作和 Reference Model,在保证 策略更新不过度 的同时,依旧能 高效提升性能。现在已经成为强化学习领域的 标准方法之一,几乎是 RLHF 的默认选择。
针对第一条问题,PPO 引入了 Critic:
通俗来说,我们不再只使用纯粹的 Reward 来反馈,而是设置一个「价值函数

」作为参考,训练目标从「Reward」进化成「Advantage」:

对某个动作,如果实际 Reward 超过了 Critic 的预期,就作为奖励,若低于预期则为负反馈。优化目标就变成:

也就是说,我们拥有了一个相对评估模型进步程度的新范式,而非采用绝对 Reward 反馈。引入 Critic 可以显著降低训练过程中的方差,相对于 Reward 反馈,模型进步能获得的梯度更显著。
针对第二条问题,PPO 采用了 Clip 策略:
为了避免模型变化过大导致的不稳定,Clip 策略加入了限制条件,在目标函数中可以体现:

其中,

它表示新策略相对于旧策略,在动作上的概率变化幅度。如果这个比值偏离 1 太多,就会被限制在一定的范围内,避免模型一次更新的幅度过大。
除此以外,PPO 策略采用 Reference Model 上了双保险,在损失函数中加入相对初始模型的 KL 散度,同样可以避免为了短期反馈而脱离合理的策略。
于是,PPO 的损失函数如下:

从 PPO 到 GRPO
上面的描述应该很好理解 PPO 在做什么事情。
但是 PPO 有一个严重的问题,由于价值函数是随着模型训练同时变动的,也就意味着策略模型本身和 Critic 模型(价值函数)都需要进行训练,并且 Critic 模型的大小和策略模型相同。因此会带来额外的内存和计算负担,训练成本非常高,很难进行 scale up。这可能是财大气粗的 OpenAI 玩得转并且取得领先的原因之一。
为了改善这个双模型策略的高成本问题,最简单的方法就是:去掉一个网络。
如果你一样这么想,那你和 DeepSeek 又不谋而合。
DeepSeek 在大模型训练改进的主要动机是想办法去掉 Critic 模型,为此提出了一种替代方法,也就是大名鼎鼎的组相对策略优化(Group Relative Policy Optimization, GRPO)。

PPO vs GRPO 流程算法对比
从流程算法对比中可以看出来,价值函数直接消失了。那不用价值函数,我们如何确定模型的 Advantage 呢?
GRPO 采用了一个非常合理的方法,不用「学习」一个单独的价值网络当 Critic,而是用这个模型过去多次的「考试成绩」来确定一个基准线。
对同一道题目、同一个状态,先用旧策略采样多条输出,然后把这些输出的平均 Reward 当作 baseline; 超过平均值就相当于「正向 Advantage」,低于平均值就是「负向 Advantage」。
在 GRPO 里,除了这一步,还保留了 PPO 中的 Clip 和对 Reference Model 的 KL 正则,这些都可以保障更新的稳定性。不过,KL 散度在 GRPO 的目标函数直接放在了损失函数,这降低了奖励函数的计算复杂度,并且它的计算方案能够保证进行归一化的 KL 值每次都是正值。而在 PPO 中,KL 散度放在奖励函数中。
GRPO 跟 PPO 的重要区别,主要是去掉了价值函数,同时使用策略模型的多个输出采样的奖励模型输出的多个奖励的平均值作为 Advantage 函数。
于是,我们得到了 GRPO 的损失函数:

对于 PPO 到 GRPO,知乎网友将两者在多个维度上进行了比较,如图表所示。

知乎网友@杞鋂 分享PPO与GRPO的对比
从 GRPO 开枝散叶
GRPO 在出现后迅速成为一个后训练范式的重要节点,DeepSeek 的模型成功充分证明了 GRPO 范式的有效性和优越性。也因此,后续的改进工作大多都是在 GRPO 的方法基础上进行。
那么 GRPO 到底有啥问题,各个新工作都要在它身上动刀呢?
最致命的问题,哪怕 GRPO 在 PPO 的基础上进行了改进,但在稳定性上与 PPO 方法仍然半斤八两。也就是说 GRPO 仍然存在严重的稳定性问题,很容易导致训练崩溃。
根据数学中国的说法, DeepSeek 的数据足够多,多到可以完美地避开 GRPO 的稳定性缺陷。每次的策略梯度计算,只要 Batch 数据足够多,就能有效降低策略梯度的方差,就能获得比较稳定的迭代了。对于中小规模的 RL 训练,GRPO 并非一个好的选择,尤其是当每次使用的数据批量比较小的时候,它的稳定性缺陷将是致命的。
因此,最新的一些方法针对 GPRO 的不同部分进行了迭代,具体缺陷和优化方式在介绍新工作时细讲。
DAPO
首先要讲的优化范式是 DAPO,这是字节、清华 AIR 在今年三月开源的算法。
使用该算法,该团队成功让 Qwen2.5-32B 模型在 AIME 2024 基准上获得了 50 分,优于同等规模的 DeepSeek-R1-Zero-Qwen-32B,同时 DAPO 版 Qwen2.5-32B 使用的训练步数还少 50%。
但是值得一提的是,DAPO 方法并没有在数学原理上有什么本质上的改变,基本优化目标仍然沿用了 GRPO 的形式,只是对 Clip 等参数和采样机制做出了改进。因此,我们把 DAPO 放在最早讨论的顺位。
在实践过程中,GRPO 存在以下几个问题:
- Token 级别的 Clip 容易导致熵崩溃:模型很快收敛到少量固定答案,导致多样性和探索能力不足(熵崩溃)。
- Batch 采样中出现奖励极端化:部分样本的奖励可能全部为 1 或 0,从而产生「零梯度」问题,削弱训练信号。
- 长序列训练的梯度分布失衡:权重分布让极少数 token 的梯度占据主导,导致许多高质量的长序列样本被忽视。
为此,DAPO 根据实践中出现的问题提出了针对性的优化:
1. Clip-Higher 机制:将 Clip 的上下限分开 ,研究者将较低和较高的剪辑范围解耦为 ε_low 和 ε_high,研究者增加了 ε_high 的值,以便为低概率 token 的增加留出更多空间,能够显著提升模型训练早期的熵。
2. 动态采样:进行过度采样,过滤掉奖励等于 1 和 0 的提示语,只保留有效梯度的样本,提高训练效率。
3. Token 级策略梯度损失:对所有 token 一起求平均,保证长序列的所有 token 都公平地为 batch loss 做贡献,并防止长序列的优化梯度被过度缩小。
4. 超长奖励调整:针对超长样本,当响应长度超过预定义的最大值时,研究者定义一个「soft 罚分」。在这个区间内,响应越长,受到的惩罚就越大,以此避免过长的响应。
因此,DAPO 的优化损失函数如下:

虽然 DAPO 依然是 token 级别的重要性采样,但训练曲线和最终性能提升非常明显。

- 项目页面:https://dapo-sia.github.io/
- 论文地址:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf
GSPO
大的来了。后训练领域里重要的突破是 Qwen3 使用的新方法 GSPO。
上文那么多文字一直在提及 PPO 类似方法的重要级采样均为 token 级,迭代方法一直没有突破 token 采样的限制,而 GSPO 真正在原理上做出了改进。
最近 Qwen 的研究表明,使用 GRPO 训练大语言模型时存在严重的稳定性问题,往往会导致模型不可逆地崩溃。在 Qwen 团队的研究中,揭示了 GPRO 方法的严重问题:
- 在每个 token 级别应用重要性采样,会在长序列中积累高方差,导致训练不稳定。
- 这一问题在 专家混合模型(Mixture-of-Experts, MoE) 中尤为严重,因为 token 级别的路由变化会加剧不稳定性。
如果说 DAPO 是在 GRPO 框架内做微调,那么 GSPO 则是直接调整了优化目标的颗粒度 —— 从 token 级跳到序列级。
重要性采样的作用是:来缓解 off-policy 带来的分布差异情况,也就是说:
我们想要估计一个预期的分布,但是我们手上只有另行为模型的分布,我们就只能在行为策略下进行采样,通过这个样本,赋予重要性权重,来估计出目标策略下函数的值。

但是这种采样的前提在于多次采样,如果只有一次采样,并不能起到分布矫正的作用。问题在于大模型训练过程中,重要性采样都是 在 token 级别进行的,单个 token 进行的重要性采样是无法起到分布矫正的作用的,相反,这种采样手段反而会带来很大方差的噪声。
在训练时,奖励其实是针对整段回答打的分,比如一句话、一个完整回复都会得到一个整体评价。
但是在模型优化时,我们通常是在 token 层面进行采样和更新。于是常见的做法是:把奖励直接分摊到每一个 token 上,再逐个去调整。
这就导致了 优化目标和奖励目标的颗粒度不匹配:模型可能在单个 token 上学得很用力,但这并不能完全对应整段回答的质量。
为此,Qwen 团队将 GRPO 进化为组序列策略优化(Group Sequence Policy Optimization, GSPO)。
正如其名称所暗示的,GSPO 的核心在于将重要性采样从 token 级转移至序列级,其重要性比值基于整个序列的似然度计算:

这种采样权重的设计自然地缓解了逐 token 方差的累积问题,从而显著提升了训练过程的稳定性。
因此,GSPO 的损失函数为:

- GRPO:重要性权重在 token 级,每个 token 都可能被单独裁剪。
- GSPO:重要性权重在 序列级,裁剪时直接作用于整个回答,更符合奖励信号的整体性。
此外,GSPO 对 序列级的重要性还做了 长度归一化,不同问题的回答长度差别很大,如果不归一化,importance ratio 会对长度非常敏感,造成不稳定。
最后,因为同一个序列中的所有 token 共用同一个重要性权重,一旦发生 clipping,被裁剪掉的就是 整个序列,而不是像 GRPO 那样只影响部分 token。
因此,GSPO 提出的「序列级重要性采样」显著提高了训练的稳定性,很可能会成为未来后训练强化学习的新标准。

- 论文标题:Group Sequence Policy Optimization
- 论文链接:https://huggingface.co/papers/2507.18071
- 博客链接:https://qwenlm.github.io/blog/gspo/
GFPO
在 GSPO 之后不久,微软研究员曝出一个新成果:组过滤策略优化(Group Filtered Policy Optimization,GFPO),另一种颠覆性的强化学习算法。
在 GFPO 工作中,微软研究团队指出了 GRPO 的一个关键限制:
GRPO 依赖于单一的标量奖励信号,这使得它难以联合优化多个属性,例如同时优化简洁性和准确度。
结果就是,GRPO 确实能提高准确度,但也会让响应长度大幅增加。这也导致了大模型遇到一个稍微棘手的问题,就会像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。
GFPO 正是为了解决这个问题而生的,它可以同时优化多个响应属性。
GFPO 是一种简单而有效的方法,可以针对想要的响应属性进行有针对性的策略优化。
GFPO 会为每个问题采样更大的候选响应组,从而扩大响应池以包含更多具有所需特性的候选响应,然后在计算策略梯度时显式地过滤这些特性,不符合目标属性的响应不进入优化。
数据过滤是一种隐式、灵活的奖励塑造形式 —— 类似于使用选择性采样来放大特定模型行为的迭代式自我改进方法。过滤机制会迭代地放大模型在目标属性上的表现,就像强化学习里的「偏好放大器」。
在此显式过滤步骤分离出所需的响应后,将在所选组内使用标准奖励来计算相对优势。
因此,GFPO 无需复杂的奖励工程,即可同时优化多个所需属性(例如长度和准确度)。
GFPO 的形式化定义如下:

GFPO 的主要干预措施是在 Advantage 估计层面,使其可与任何 GRPO 类似的方法兼容,例如 DAPO、Dr. GRPO 或带有 Dual-Clip PPO 损失的 GRPO。

- 论文标题:Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning
- 论文地址:https://arxiv.org/abs/2508.09726
GRPO 的一些其他问题
除此以外,也有些研究者发现了 GRPO 的一些其他缺陷,或许可以为未来的研究工作提供一些新思路。

- 博客链接:https://aryagxr.com/blogs/grpo-limitations.html
缺陷 1:奖励的歧义性
复杂的推理问题通常需要多个奖励信号,因此我们会为每个评判标准单独设计奖励函数。然后,把所有奖励函数的分数加在一起,折叠成一个单一的奖励信号。

问题在于,模型根本无法知道 自己到底是因为什么行为被奖励的。虽然我们写了不同的奖励函数,但最后所有奖励依然被合并为一个标量信号。模型又怎么知道奖励是来自「答案正确」,还是「推理清晰」,还是「格式规范」呢?
即使我们调整不同奖励组件的权重,模型看到的仍然只是一个总的标量奖励。
GFPO 一定程度上改善了上述问题。
缺陷 2:标量反馈
在推理任务中,GRPO 会丢弃所有中间的文本反馈,因为传给模型的只是一个数值化的奖励信号。
举个例子,模型训练过程中会打印一些输出,每次猜测都有文字反馈,比如:
- 「字母 ‘c’ 不应该在答案里」
- 「‘n’ 不能出现在位置 3」
这些文字反馈对模型其实很有帮助,但在 GRPO 框架下完全用不上,因为它们最终都会被抽象成一个标量奖励。
缺陷 3:多轮推理
另一个瓶颈是 多轮推理 任务在 GRPO 下的表现。问题的关键在于:
在多轮对话中,每一轮的反馈都会被重新输入到基础模型的 prompt 中,从而导致 指数级分支(exponential forking),使得 GRPO 在多轮任务中的训练变得非常痛苦。见下图:

写在最后
简单总结一下,后训练的发展脉络其实很清晰。从 OpenAI 提出 PPO 的后训练方法开始,都在此基础上缝缝补补。
GRPO 是 PPO 基础上重要的更新范式,自 GRPO 起,后训练策略优化就作为大模型的一个重要研究方向进行,就像树节点一样向外延伸。
- PPO:以 token 为核心,依赖价值函数。
- GRPO:提出组优化思路,在组内对奖励做归一化,从而摆脱价值函数依赖;但仍停留在 token 级,方差依旧较大。
- DAPO:在 GRPO 基础上加入大量工程改进(如 Clip-Higher、Dynamic Sampling 等),一定程度缓解大模型 RL 的训练瓶颈,但仍停留在 token 级。
- GSPO:实现范式转变,将 off-policy 与 clip 全部提升到 序列级,显著降低方差,兼具算法简洁性与性能表现,已成为 Qwen3 RL 的核心实践框架。
- GFPO:针对同时优化多个所需属性的目标进行优化,加入数据过滤操作。
参考链接:
https://www.zhihu.com/question/12933942086/answer/1933555787759871596
https://zhuanlan.zhihu.com/p/1941902507136746342
https://blog.csdn.net/m0_74942241/article/details/150611764
https://zhuanlan.zhihu.com/p/1941902507136746342
#科研智能体「漫游指南」
助你构建领域专属科研智能体
欢迎关注中国科学院自动化研究所 & 北京中关村学院 & 芝加哥大学 & 西湖大学 & 腾讯带来的科研智能体方面的最新综述调研。
当前基于大语言模型(LLM)的智能体构建通过推动自主科学研究推动 AI4S 迅猛发展,催生一系列科研智能体的构建与应用。然而人工智能与自然科学研究之间认知论与方法论的偏差,对科研智能体系统的设计、训练以及验证产生着较大阻碍。
与传统综述不同,本篇综述为大家呈现了科研智能体的「漫游指南」,旨在提供构建科研智能体的「说明指南」:从科学研究的全周期出发,概述了科研智能体的分级策略,并详细阐述了对应等级的构建策略与能力边界;同时该「漫游指南」详细阐明了如何从头构建科研智能体,以及如何对科研智能体的定向能力进行增强。同时「指南」中详细涵盖了科研智能体的概念阐述、构建方案、基线评估以及未来方向。
希望本「漫游指南」能启发 AI 研究者与具体自然科学研究者,促进 AI 与自然科学之间的深度融合。
- 论文地址:https://doi.org/10.36227/techrxiv.175459840.02185500/v1
- 仓库地址:https://github.com/gudehhh666/Awesome_Scientific_Agent.git
综述的核心贡献如下:
- 在系统性探索科研智能体领域的过程中,本综述尤其注重对自然科学领域的科研智能体的深入而严谨的解构分析,尤其就其构建策略与能力范围而提出了针对科研智能体的三级分级系统。
- 该综述提供了一套全面而细致的实践指南,涵盖从零构建科研智能体的基础流程,到针对特定能力对现有智能体进行定向能力增强,进一步提升现有科研智能体系统的能力与性能。
- 通过结合科学研究全生命周期与科研智能体构建策略,本综述深入剖析了构建策略与科研流程之间相互促进与协同的过程,揭示了科研智能体设计与应用之间的独特联系。

图 1|科研智能体对于科研过程全生命周期的介入
科研智能体分级策略

图 2|科研智能体分级示意
根据构建策略与其能力边界的等级划分,科研智能体被我们分为三个等级:
- Agent as Assistant:该等级的智能体通常局限于特定领域的较单一任务,而无法进行跨多个科研流程的综合性操作。其构建策略往往使用小模型经过后训练(Post-training)或微调(Fine-tuning)而完成。其能力往往局限于被专门训练过的领域任务。其能够在一个专门任务上达到很高的水准,但是无法承担起全面统筹各个科研过程的能力。
- Agent as Partner:该等级的智能体较 Assistant 最大的飞跃便是充分集成各类工具以实现自身能力的跃迁。其构建策略上逐步转向更加系统化的架构设计,采用闭源大型模型,并结合丰富的上下文信息进行优化。它们的设计不仅仅是优化单个任务的性能,而是将多个任务拆解并进行模块化设计。其能力范围主要在于在特定领域内独立完成文献咨询、假设生成和实验设计等任务,然而,许多这类智能体仍然局限于知识获取工具的集成,在复杂任务的自我验证和可靠性方面存在局限。
- Agent as Avatar:该等级智能体侧重于多个维度的能力增强,其具备了强大的推理能力、深度记忆和强协作能力,能够在科学研究的各个阶段提供全面支持。其构建策略转向对原有智能体能力的定向增强:通过深度协作和增强的记忆能力进行设计,能够处理复杂的科学问题,并协调不同工具进行任务执行。其能力也不简单倾向于单一领域,它们能够跨学科地应用并协作解决科研难题。

图 3|不同等级科研智能体汇总
从头构建科研智能体
本综述凝练了科研智能体的构建过程,从头构建科研智能体的工作流主要为知识组织、知识注入以及工具集成三个部分构成。

知识组织:知识组织定义了科学信息如何被结构化,以便使智能体能够有效地理解和推理。它涵盖非结构化序列(例如研究论文和书籍)、结构化数据(例如基因表达数据集)、指令(例如问答对)以及知识图谱,每种方式都提供了独特的方式来表示和检索领域知识。这些组织策略作为智能体推理、归纳和决策的基础,对于科学发现至关重要。
知识注入:知识注入涉及将特定领域的专业知识嵌入科学智能体中,这可以通过显式或隐式方法实现。显式注入直接将知识整合到提示中或针对特定任务优化提示,而隐式注入通常涉及微调模型或使用强化学习来使智能体的响应适应特定领域。这两种方法都旨在通过注入相关专业知识来增强智能体解决特定领域科学挑战的能力。
工具集成:工具集成通过将外部工具用于专业任务(如专业知识获取、执行和模拟、分析以及可视化)来扩展智能体的功能。通过选择和集成特定领域的工具,科研智能体可以更高效地执行复杂任务。这些工具的有效集成使科研智能体能够自主运行,协调各种资源以协助科学研究与发现。
科研智能体能力增强

- 记忆增强:记忆增强对于科学智能体实现类人智能和长期高效运作至关重要。它使智能体能够保持上下文、执行多步推理并积累经验知识。记忆结构,如块、知识三元组、原子事实、摘要和例程,服务于不同的记忆功能,从存储上下文信息到细粒度的事实知识。记忆系统分为以上下文为中心和以行动为中心两种方法,前者侧重于在长时间内保持可靠的上下文,后者则增强动态任务适应和技能泛化能力。这些记忆改进使智能体能够执行更复杂的任务,并保留相关知识以供未来使用。
- 推理增强:推理增强旨在解决 LLMs 的局限性,例如幻觉和不一致性,特别是在科学任务中。通过结构化推理链(例如 CoT 和多轮推理)以及自洽性验证等机制,科学场景中的通用推理能力得到提升,从而提高智能体输出的可靠性和透明度。领域特定推理优化通过引入领域偏好指导(确保在特定领域内进行逻辑推理)和符号演绎(将符号推理与概率模型相结合),进一步提升了智能体的推理能力,使其在复杂的科学探究中能够做出更精确和一致的推论。
- 协作增强:协作增强着重于改善多智能体系统之间以及智能体与人类在科学研究中的交互。在多智能体协作中,智能体专注于特定角色,参与结构化对话和辩论,并高效共享知识。角色专业化和结构化协议等方法有助于解决角色重叠和信息流等挑战。人机协作得益于明确的目标设定和反馈机制,使人类研究人员能够提供战略指导并监督智能体任务。自然语言界面促进无缝沟通,减少人类与 AI 之间的技术障碍。这些增强确保智能体和人类能够有效协作,优化研究成果,并促进更具活力的科学发现过程。
基准与评估
根据现有基准的侧重不同,基准主要分为知识密集型任务以及实验驱动型任务,两者对于整体科学研究过程中各有侧重。
知识密集型:科研智能体主要设计用于处理需要深厚专业知识的复杂、特定领域的任务。这些任务通常围绕知识传播展开,包括文献挖掘、研究假设生成、实验设计、结果分析和评估。这类任务要求智能体在专业领域具备认知能力,而非简单的一般知识。
实验驱动型:面向科研智能体的实验驱动任务评估代理在科学探究中使用工具的能力,强调自主实验设计、验证以及在科学环境中的多过程探索。

图 4|基准测试汇总
未来研究方向
- 事实性与合理性:确保科学实验设计的实证准确性和理性仍然是一个主要挑战,需要更好地整合验证工具和反馈机制;
- 复杂任务适配框架设计:科学智能体需要灵活、连贯的框架,以适应特定的研究领域,从而克服现有复杂、特定领域系统的局限性;
- 自我迭代进化:为了持续进步,科学智能体需要融入自我反思和持续迭代机制,重点在于平衡情景记忆和参数记忆,以防止知识丢失并支持长期发展;
- 面向科学探索的交互优化:优化智能体与人类研究人员的交互对于推动科学发现至关重要。未来的系统应当整合通用和专用模型,以促进跨学科的动态有效合作;
- 多学科智能体:科学智能体可以通过促进跨学科知识转移来增强其专业知识,从而加强其在相关研究领域的执行能力,并提高整体性能;
- 科学评估与验证:评估人工智能驱动的科学研究仍然是一项复杂的挑战,需要创新的方法来构思开放式研究任务,并确保智能体遵循可证伪性和可重复性等核心科学原则。
在此,我们诚挚邀请 SCI 领域的同学和教师与我们联系与合作,共同推动科学代理在自主科学研究中的应用与发展。我们相信,通过多学科的跨界合作和经验交流,能够为科学研究的创新和效率提升提供强有力的支持。
如果您对我们的工作或研究方向感兴趣,欢迎随时与我们建立联系。期待与各界科研人员携手合作,共同探索科技前沿,实现更广泛的学术价值和应用潜力。
联系方式:
中国科学院自动化研究所 & 北京中关村学院 2024 级直博生王新茗
wangxinming2024@ia.ac.cn
中国科学院自动化研究所副研究员 & 北京中关村学院共建导师徐健
jian.xu@ia.ac.cn
#Artificial Intelligence: Principles and Techniques
OpenAI大神:人工智能导论课程停在15年前,本科首选该是机器学习导论
如今,人工智能已经成为科技发展的主流,尤其是 ChatGPT 问世以来,大语言模型(LLM)正在深刻影响社会、企业和个人的方方面面。
对于想要投身人工智能领域的初学者来说,选对一门课程显得尤为重要。很多大学往往会设置人工智能导论(Intro to AI)课程,并成为很多学生的首选。其中最著名、深受学生喜爱的课程有斯坦福大学的《CS221: Artificial Intelligence: Principles and Techniques》。
对于入门者来说,人工智能导论可以让学生快速了解人工智能的不同分支,一般包括人工智能基础、机器学习、神经网络与深度学习、自然语言处理(NLP)、计算机视觉、强化学习等知识。

斯坦福大学 2025 秋季 CS221 课程。
近日,OpenAI 研究科学家、德扑 AI 作者 Noam Brown 表达了一种观点:「对人工智能感兴趣的本科生在选择课程时要谨慎,不要再把人工智能导论(Intro to AI)作为第一门 AI 课程。大学里真正需要修的其实应该是机器学习导论(Intro to Machine Learning)」。

他给出的解释是,过去 15 年里,得益于深度神经网络的发展,人工智能技术迎来了爆炸式的发展。然而在许多学校,人工智能导论的课程大纲几乎没有变过,依然停留在 2010 年前后,通常只会花几节课讲机器学习。此外,在很多大学里,对于这门课程的「重构」存在争议,而惯性往往主导了一切。
他认为,不要只根据课程名称来决定要不要选它。相反,你应该仔细查看课程大纲。理想情况下,一门好的入门课程应该涵盖线性回归、梯度下降、反向传播和强化学习。不同学校的课程差异很大,有些「人工智能导论」会讲这些内容,但大多数不会。
最后,他的建议是,如果你打算未来从事 AI 相关的职业,那么将「人工智能导论」留到后面再学更合适,它能让你对智能有更广阔的理解。但如果你的目标是学习现代聊天机器人、图像识别或生成工具、代码助手背后的核心技术,那么你真正应该先学的课程很可能是「机器学习导论」。
另外,他曾经与很多大学教授讨论过这个问题,几乎所有人都认为「人工智能导论」课程应该涵盖更多的机器学习内容。问题在于,他们对删除哪些内容来为机器学习腾出空间无法达成统一的意见。曾经有一段时间,他建议应该移除 CSPs(约束满足问题),结果就让一些教授觉得被冒犯了。

相较于人工智能导论略显「传统」的内容(如符合主义、专家系统),机器学习导论聚焦现代主流 AI 技术,通常涉及线性回归、逻辑回归、神经网络、反向传播、SVM、集成方法、深度学习等,内容紧贴工业界和学术界热点,适合未来打算进入工业界或从事应用研究的学生。
其中著名的课程要数吴恩达担任主讲人的斯坦福《CS229: Machine Learning》,该课程涵盖了监督学习、无监督学习、生成模型、深度学习基础等知识。
Noam Brown 的观点引发了热议,Anthropic 的一位研究者称自己本科时就感到惊讶,IIT(印度理工学院)的「人工智能导论」课程完全没有提到神经网络,并且好像到现在都没有变化。

有人觉得「人工智能导论」课程确实存在陷阱。大学里教搜索算法和专家系统,而学生想了解 transformer 和反向传播。这就像在智能手机时代教学生修打字机。

「我们今天看到的大多数突破都来自机器学习和深度学习,而不是那些老派人工智能导论课程里的主题。」

还有人建议,「只学提示词工程和氛围编程就行了,剩下的一切将迎刃而解。」

人工智能导论课程是否真的过时了,请在评论区留下你的看法。
#入门AI,可以从这第一课开始
开学了
9 月,不仅是返校的季节,对许多人来说,也意味着一个新的开始。无论你是重返校园的学生,还是希望在职业道路上寻找新方向的探索者,可能都在思考同一个问题:「如何才能跟上这个被 AI 定义的未来?」
或许,我们可以从身边的一些小事开始寻找答案:
- 你是否想过,抖音如何猜到你下一秒想看什么?
- 为什么你的手机相册能自动识别人脸,甚至是你家的猫?
- 和 Siri、小爱同学聊天时,它们究竟在想什么?
- 玩游戏时,那些聪明的 NPC 是如何思考和行动的?
其实这些问题背后,都藏着与 AI 紧密关联的知识:推荐算法、计算机视觉(CV)、自然语言处理(NLP)、强化学习(RL)。无论你将来想成为什么样的人,这股浪潮都已将我们所有人卷入其中。

图源:AI生成
那我们继续问自己几个问题。
是哪个瞬间让你对 AI 产生了浓厚兴趣?是 AlphaGo 打败人类最顶尖的棋手,ChatGPT 的横空出世,还是 DeepSeek 的一夜爆火?
你对自己的 AI 探索之路有何设想?你最大的兴趣爱好是什么?你有想过,AI 能否成为连接你的工作、专业与兴趣爱好的桥梁吗?
停!再问下去就要变成成功学课堂了。
我们进入正题。
也许 AI 没有那么复杂什么是 AI?
先别急着背诵那些复杂的定义。我们不妨思考一个简单的问题:你要如何教会一台机器认识「猫」?
一种方法是「手把手地教」:我们给机器看成千上万张已经贴好「猫」标签的照片。机器会努力找出所有这些「猫」的共同特征,最终形成一个关于猫的概念。这在专业上叫做「有监督学习」。
还有一种更神奇的方法,是「让它自己悟」:我们把海量、未加整理的图片(比如整个互联网的猫图)都丢给它,不告诉它什么是猫。机器会自己从中发现规律,将一些看起来相似的东西归为一类。

2012 年,Google 正是通过类似方法,让一个神经网络在观看海量未标记的 YouTube 视频截图后,自发地学会了识别「猫」这个概念。这成为了「无监督学习」的一个里程碑,证明了深度学习的巨大潜力。
此外,还有第三种方法,叫「在试错中成长」:想象一下训练一个游戏里的角色或者一只宠物。你不会直接告诉它每一步该怎么做,而是设定一个目标(比如「拿到宝箱」或「坐下」)。它会自己尝试各种动作,如果做对了(离宝箱更近了),你就给它一个「奖励」;如果做错了(撞墙了),就给它一个「惩罚」。
通过不断地试错,并努力获得最多的奖励,它最终会学会一套最高效的行动策略。这就是「强化学习」(Reinforcement Learning),AlphaGo 下围棋、自动驾驶汽车学习驾驶,背后都有它的身影。
无论是哪种方式,其核心思想都是革命性的:我们不再为机器编写死板的规则(比如「IF 有尖耳朵 AND 有胡须 THEN 是猫」),而是让它从海量「数据」中自己「学习」出规律,形成一个复杂的「模型」。当遇到新照片时,它就能做出「预测」。
这,就是当今人工智能最核心的思想。我们今天所说的 AI,绝大多数时候指的都是由这种思想主导的机器学习,尤其是其中更强大的深度学习。
关于机器学习,最有名的课程之一是吴恩达(Andrew Ng)教授的《机器学习》课程,有兴趣的同学可以自行学习。
理解了 AI 的核心思想后,你可能已经跃跃欲试了。那么,踏上这条探索之路,你需要准备哪些看家本领呢?
你需要掌握的「三大法宝」
- 数学基础
数学是理解 AI 本质的通用语言。掌握其核心思想,你就能看懂智能的底层逻辑。
线性代数:AI 世界里,万物皆为向量与矩阵。无论是图像、声音还是文字,在计算机眼中都是数字矩阵。模型的运算与数据流动,本质上都是矩阵的变换。它是构建 AI 大厦的基石。
概率与统计:AI 充满了不确定性,而概率论是量化和管理这种不休止的工具。模型的预测(如「80% 是猫」)正是基于此。它是风险评估和智能推荐的核心。
微积分:模型如何学习和进化?答案是「优化」。微积分中的「梯度」指明了模型参数优化的方向,让模型通过「梯度下降」一步步变得更聪明。
不过,你不必成为数学家才能开始,初学者可以先聚焦于理解核心概念在代码中如何应用,随着实践的深入再回头巩固理论,效果更佳。
那么,如何真正让机器开始学习呢?这就需要算法。它是一系列清晰、具体的执行步骤。它由人运用数学知识设计,并由计算机严格遵循。这些步骤精确地指导计算机如何去处理输入数据、进行迭代计算以优化模型,并最终生成结果(如分类或预测)。
举个例子:想象一下,模型学习的过程就像一个蒙着眼睛的人要走到一个山谷的最低点。算法就是他下山的方法:
- 第一步:随机站在山坡上一个位置。
- 第二步:感受脚下哪个方向是下坡最陡的(这就是微积分里「梯度」的作用)。
- 第三步:朝着最陡的方向迈一小步。
- 重复第二和第三步。
最终,他就能一步步走到谷底。这个「蒙眼下山」的策略,就是一个典型的机器学习算法(梯度下降),它精确地指导了计算机如何通过迭代计算,一步步让模型变得更好。
- 编程能力
如果说数学是 AI 的内在思想,那么代码就是将这些思想构建为现实产品的核心工具。Python 是你的首选语言,它语法简洁、上手快,更重要的是拥有一个极其强大的 AI 生态圈。
那么你能用 Python 做什么呢?
数据分析与可视化:AI 从数据开始。使用 Python 把海量、杂乱的原始数据,变成干净、高质量的「燃料」,让机器能够「消化」。
构建机器学习模型:将算法理论付诸实践,构建各种模型。比如,预测明天的天气,识别垃圾邮件,或者判断一张图片里的是猫还是狗。这就像是教计算机如何从数据中「学习」和「思考」。
开发深度学习应用:构建神经网络。从图像识别、人脸解锁到智能驾驶、AI 绘画和大型语言模型,背后都是深度学习在驱动。
要完成这些任务,除了语言本身,你还需要掌握它的「工具箱」——那些强大的第三方库:
数据处理双雄(NumPy & Pandas):它们是 AI 项目的数据基石。NumPy 让你能高效地处理大型多维数组(矩阵),而 Pandas 则提供了无与伦比的数据清洗、处理和分析能力。
经典机器学习库(Scikit-learn):它集成了绝大多数经典的机器学习算法(如回归、分类、聚类),是你入门实践、快速搭建模型的利器。
深度学习两大框架(TensorFlow & PyTorch):当你踏入深度学习领域,这两个框架是绕不开的。它们提供了构建、训练和部署神经网络所需的一切。

Python 热门库。来源:COGNITEQ
当然,这并不意味着其他语言无足轻重,毕竟大多数大学计算机专业的第一门编程语言还是 C 语言。语言是工具,真正的工匠会根据不同的任务,选择最趁手的那一件。

- 持续学习与动手实践
AI 是一个实践性极强的领域,纸上得来终觉浅。
保持永恒的好奇心:AI 技术的发展日新月异。要跟上潮流,你需要建立自己的信息渠道。可以先从关注高质量的博主、技术公众号、博客和论坛开始,它们是消化前沿知识、打好基础的绝佳起点。当你对基础有了把握后,可以开始留意 NeurIPS、CVPR、ICML 等顶级学术会议。你不需要立刻读懂每一篇论文,但了解这些会议上在讨论什么,能让你看到这个领域的未来方向。
信息筛选,去伪存真:在信息爆炸的时代,辨别能力比学习本身更重要。你需要学会过滤「噪音」,专注于「信号」。什么是噪音?比如那些夸大其词、宣称「一夜颠覆世界」的营销文章,或者让你在不同框架间摇摆不定的「技术选型」争论。什么是信号?比如一篇开创了新领域的经典论文(如「Attention Is All You Need」),一个让你真正理解底层原理的课程,或是一个能解决实际小问题的项目。抓住信号,你才能在纷繁的信息中保持专注,不迷失方向。

图源:AI生成
动手是最好的老师:理论学得再多,不如亲手跑通一个项目。不要害怕从零开始,你的第一个项目不必惊天地动,可以是从一个 Kaggle 入门竞赛开始,也可以是复现一篇经典论文中的简单模型。在 GitHub 上找一个你感兴趣的开源项目,尝试去理解它,甚至为它贡献一行代码,你所获得的成就感和实践经验将远超书本。
一句话总结:数学给你深度,编程给你工具,实践给你高度。三者结合,你的 AI 之路才能行稳致远。
下面整理了一些xx过往的基础技术入门文章,以供大家学习参考。
基础
吴恩达亲自授课,LLM 当「助教」,适合初学者的 Python 编程课程上线
吴恩达联手 OpenAI 上线免费课程:一个半小时学会 ChatGPT Prompt 工程
LeCun 学生、纽大助理教授 Alfredo 视频上新,跟他免费学本科 AI 课程
机器学习
从零开始学好深度学习,短视频免费课程上线
Sebastian Raschka 著作免费开放!《机器学习与 AI 核心 30 问》,新手专家皆宜
B 站失踪人口回归,「年更 UP」Gautam Kamath 教授的《机器学习入门》终于上线了
从 RLHF、PPO 到 GRPO 再训练推理模型,这是你需要的强化学习入门指南
LLM
微软免费课程、吴恩达开新课,顶级生成式 AI 必备课程来了
墙裂推荐!Karpathy 大模型培训课 LLM101n 上线了,非常基础
新鲜出炉!斯坦福 2025 CS336 课程全公开:从零开始搓大模型
信息过载时代,如何真正「懂」LLM?从 MIT 分享的 50 个面试题开始
现实层面
当你仰望 AI 这片璀璨的星空时,心中一定充满了对未来的无限遐想。接下来,我们将从仰望星空回到脚踏实地,聊一聊大家最关心的现实问题:这条路好走吗?未来我能做什么?我该如何准备?
那些光鲜之外的事
AI 的世界不全是发布会上光鲜亮丽的模型和「改变世界」的豪言壮语。
- debug 怪圈
这个挑战倒是很「传统」,但永远不会过时。无论技术怎么变,你总会遇到这种情况:代码没问题,逻辑看起来也没错,但模型输出的结果就是一塌糊涂。然后就是漫长的「破案」过程:是数据投喂的姿势不对?是某个参数设置得太玄学?还是模型结构里有个看不见的坑?这个过程,拼的是技术,更是耐心和一种近乎直觉的判断力。
- 技术刷新太快
AI 圈的刷新率,可能是按「天」来计算的。今天你刚投入几个月,把一个模型原理摸透,明天可能就有一个效果更好、思路更巧的新范式冒出来,把所有人的目光都吸走了。这种感觉就像在一条飞速滚动的传送带上,得不停小跑才能待在原地。知识焦虑?是的,这几乎是每个 AI 人的日常。
- 路口太多
技术爆炸带来的另一个副产品,就是选择太多。大模型、多模态、AI Agent……每个方向都闪着高光,看起来都通往未来。但当所有路都充满诱惑时,人反而会迷路。「我该走哪条路?万一选错了怎么办?」这种不确定性,比解决一个技术难题本身更让人头疼。

图源:AI生成
未来坐标:机遇与焦虑并存的时代
尽管挑战重重,但 AI 依然是这个时代最确定的机遇之一。然而,机遇的另一面,是剧烈的变革与分化。
你可能一边看到科技巨头为顶尖 AI 人才开出天价薪酬、上演激烈「挖角」大战的新闻,一边又听到 AI 将取代大量重复性工作、引发失业潮的讨论。这两种看似矛盾的现象,共同构成了我们所处时代的真实图景:AI 正在拉大顶尖人才与普通技能劳动者之间的差距。
理解这个现实,对你规划未来至关重要。这意味着,仅仅「会用」AI 工具可能不足以构建长期的职业壁垒,而努力成为能够「创造和驾驭」AI 的人,将拥有更广阔的前景。
- 如果你想成为 AI 的「核心玩家」
这里有许多令人兴奋的职业路径,这些分类可以帮你理解工作的核心性质:
机器学习工程师:负责将算法模型落地,构建、部署和维护 AI 产品和系统的工程师。
数据科学家:从海量数据中挖掘洞见,通过分析和建模为商业决策提供支持的侦探。
算法研究员:探索 AI 理论的前沿,开发新算法和新模型的先驱。
在招聘网站上,这些角色会演变成更具体的职位,如算法工程师(最常见,通常专注于推荐、CV、NLP 等领域)、AIGC 工程师(专注于生成式 AI 应用)、数据分析师(侧重业务分析和可视化)和 MLOps 工程师(专注于模型部署和维护)。
- 更广阔的舞台:「AI + X」的无限可能
学习 AI 并不意味着你必须成为一名全职的 AI 工程师。更激动人心的是,AI 可以作为一种「超能力」,与你热爱的任何领域相结合,创造出前所未有的价值。
艺术与设计:利用生成式 AI 创作独特的视觉艺术,或用数据可视化讲述动人的故事。
人文社科:在计算社会学、数字人文等新兴领域,利用 AI 分析海量文本和历史数据,以全新的视角洞察人类社会与文化。
金融与商业:从量化交易、智能投顾到风险控制、反欺诈系统,AI 正在重塑整个商业世界的运行规则。
生命科学与医疗:从辅助新药研发、加速基因测序,到精准解读医疗影像,AI 正成为推动医学进步的强大引擎。
前沿科学与工程:在材料科学领域,AI 能模拟预测分子结构,加速新材料的发现;在能源领域,它能优化电网调度,构建更高效的能源系统。
社会心理与健康:训练 AI 分析语言模式与生理信号,为心理健康评估和早期干预提供更客观、更便捷的辅助工具。

图源:AI生成
最终,AI 技能将成为一种通识能力。无论你将来身处哪个行业,掌握 AI 都将为你提供解决复杂问题的独特视角和强大工具。
打造通行证:从项目到能力
那么,如何为这些未来机遇做准备呢?
- 用项目定义你的方向
你的 GitHub 就是你的名片。但通往宏大项目的道路需要一步步走,不要害怕从「微项目」开始,它们是建立信心和技能的最佳起点。
第一步:跑通你的「Hello World」

想入门数据分析?你的第一个项目可以是:用 Pandas 分析你所在城市过去一年的天气数据,找出最热和最冷的一天。
想入门机器学习?尝试用 Scikit-learn 预测泰坦尼克号幸存者,这是数据科学领域最经典的入门任务。
第二步:让项目为你的职业方向代言
想成为算法工程师?尝试复现一篇经典论文,并把结果部署成一个简单的 Web 应用。
想成为数据科学家?找一个公开数据集,提出一个商业问题,并用数据分析和可视化来讲述一个完整的故事。
想探索「AI + X」?把 AI 用在你的专业上!用 NLP 分析文学作品,用 CV 识别植物,或者用 AI 帮你作曲。一个展示了你独特兴趣和跨界能力的项目,会让你在众多求职者中脱颖而出。
- 在真实世界中磨练技能
参与公开挑战,解决真实问题:Kaggle 是经典的起点,但不要止步于此。可以关注 Hugging Face(一个汇集了海量 AI 模型和开发者的社区)的挑战赛,或顶级会议(如 NeurIPS、CVPR)举办的、更具前沿性的学术竞赛,这些更能体现你对领域的追踪和热情。
构建可交互的 Demo,让模型「活」起来:在这个时代,一个可以线上访问、交互体验的 Demo(使用 Gradio、Streamlit 这类简单的工具就能快速构建),远比一个静态的 Jupyter Notebook 更能打动人。它证明了你不仅懂算法,还具备将技术转化为产品的工程能力和产品思维。
为开源项目做贡献:这听起来很难,但你可以从最小的一步开始。在为大型开源项目贡献代码前,先尝试为它的文档修正一个你发现的拼写错误(Typo)。这个过程会让你熟悉如何发现并报告问题(提 Issue)、提交你的修复方案(发 Pull Request)以及与社区沟通,这是课堂上学不到的宝贵经验。
- 构建你的「护城河」
在这个瞬息万变的领域,你需要有自己的核心竞争力。
扎实的理论基础:市场的热点会变,但数学、算法和计算机系统的基础知识永远不会过时。它们是你理解新技术、快速学习的基石。
解决问题的能力:公司雇佣你,是为了解决问题。相比于罗列你「会」什么技术,不如展示你「用」技术解决了什么问题。
拥抱人机协同:AI 的发展方向是与人类专家协同,而非完全取代。这种「人在回路」(Human-in-the-Loop)的思想正变得越来越重要。认识到人类智慧在数据标注、模型优化中的核心作用,能帮你找到自己的位置,缓解技术焦虑。
持续学习的习惯:这不是一句口号。将阅读技术博客、观看分享视频、跑一跑新模型的代码,变成像吃饭喝水一样的日常习惯。
AI 简史
了解历史,才能更好地看清未来。你现在所学的每一个算法,所用的每一个框架,背后都凝聚着几代人的智慧、梦想甚至泪水。AI 的发展并非一条直线,而是一部跌宕起伏的史诗。
黄金开端与梦想年代(1950s - 1970s)
1956 年的夏天,在美国的达特茅斯学院,一群充满激情的科学家们正式提出了「人工智能(Artificial Intelligence)」这个名字。他们乐观地相信,用不了多久,具有人类智慧的机器就将出现。这是一个「巨人」辈出的时代,充满了逻辑推理、问题求解的早期探索,和对未来的无限憧憬。

符号主义、联结主义和行为主义构成了人工智能发展的三大基石,代表了三种理解和构建智能的核心思路。

图源:2024 年度 Graph+AI 开源探索思考
三种并非相互排斥,而是从不同层面揭示了智能的本质。
符号主义走的是「自上而下」的精英路线,关注智能的「认知」层面,强调逻辑和推理。虽然在当前不如深度学习流行,但它在知识图谱、搜索引擎的语义理解、以及 AI Agent 进行复杂任务规划等方面依然至关重要,是构建可解释、可信赖 AI 的基石。
联结主义走的是「自下而上」的草根路线,关注智能的「感知」层面,强调模式识别和学习。当今 AI 的代名词——深度学习(Deep Learning),通过构建包含亿万级别「神经元」联结的深度神经网络,完美诠释了其核心思想。
行为主义则强调不应只关注「内心」,智能体必须付诸「行动」,与世界交互。
现代人工智能正朝着融合这三者优势的方向发展,以期创造出既能从数据中学习(联结主义)、又能进行逻辑推理(符号主义)、还能在环境中行动(行为主义)的更强大的 AI。
AI 寒冬与机器学习的崛起
然而,现实很快给过于乐观的预言泼了冷水。由于计算能力的限制、数据的匮乏以及理论的瓶颈,许多承诺无法兑现,AI 研究的资金和热情随之骤减,进入了长达数十年的两次「AI 寒冬」。这段历史告诉我们一个宝贵的道理:真正的科学突破需要耐心和积累,而非一时的狂热。任何伟大的事业,都会经历低谷。
在寒冬中,AI 并未消亡。一批学者转向了另一条更务实的道路:统计机器学习。他们不再追求创造一个「全能的人类大脑」,而是专注于解决特定问题,比如垃圾邮件过滤、手写数字识别等。这股力量在悄然中积蓄,为未来的爆发埋下了伏笔。
深度学习的「宇宙大爆炸」(2012 - 至今)
2012 年,一个名为 AlexNet 的深度神经网络模型在 ImageNet 图像识别竞赛中以碾压性的优势夺冠,其准确率远超所有传统方法,瞬间引爆了 AI 领域。

其成功的背后,是三股在寒冬中悄然积蓄的力量:算力(GPU 的普及)、数据(互联网的海量信息)和算法(深度学习)。
从此,AI 驶入快车道。从 2016 年 AlphaGo 的惊世对局,到 ChatGPT 展现的卓越创造力,再到如今生成式 AI 颠覆内容创作、AI 智能体探索物理世界——我们正处在 AI 历史上最激动人心的变革时刻。
结语
最后,请允许我们代那些在 AI 领域深耕多年的前辈,送给你一些祝福和建议:
拥抱不确定性。AI 的发展之路从不是一条直线,你的学习和职业生涯也同样如此。那些看似「绕路」的探索,那些失败的实验,都将成为你独特认知的一部分。在这个充满变化的时代,适应变化的能力本身就是最核心的竞争力。
保持人类的温度。技术是冰冷的,但你可以赋予它温度。永远不要忘记,AI 是增强人类智慧的工具,而不是目的。去思考技术背后的人文关怀和社会责任,用你的创造力去解决真正有意义的问题。你的独特价值,恰恰在于你的人性、你的审美、你的同理心——这些是机器无法复制的。
找到你的热爱。回到我们最初的问题:你最大的兴趣爱好是什么?试着将 AI 与它结合起来。无论是音乐、艺术、体育还是历史,AI 都能成为你探索热爱的超级工具,甚至开辟出前所未有的新领域。当技术与你的热情相遇时,最伟大的创新才可能发生。
我们也真诚地邀请来自各行各业的读者,在评论区留下你们的宝贵建议,共同为这些未来的探索者点亮一盏灯。
欢迎来到这个激动人心的时代。
愿你在这场智能革命的浪潮中,既能仰望星空,也能脚踏实地,最终找到属于自己的那片海。
#高分论文也可能被拒,只为保住那25%左右的接收率?
要指标还是更多有价值的论文,顶级学术会议似乎也面临着「to be or not to be」的难题。
NeurIPS 2025 将于 2025 年 12 月 2 日到 7 日在美国圣地亚哥举办,并且首次设置了第二个官方分会场墨西哥城。
最近几天,根据国内外社交媒体的众多反馈,本届 NeurIPS 的 Meta Review(元评审,即多位匿名审稿人提交评审意见后由领域主席或高级审稿人撰写总结性评审)已经陆续完成。

出自:MiroMind 研究科学家 Bai Song(小红书)
从更多领域主席(AC)透露的消息中,有一些现象关系到了投稿人论文最终能否被接收。
其中,有领域主席表示,「在 DB(数据集和基准) track,即使得分 4-4-4-5(均分 4.25)也有可能被拒稿。」根据此前的相关数据统计,本届 NeurIPS 的投稿数量或达到史上最多的 30000。
他认为,不要为了接收率固定在 20% 到 25%,而拒掉获得审稿人积极评分并达成共识的论文。并且,他呼吁向程序主席(PC)建议提高接收率。而根据 Senior PC(高级程序委员会成员)的回复,由于场地和资源有限以及投稿量超出了预期,本届会议必须控制接收率。
作为对比,NeurIPS 2024 的接收率为 25.8%(主会议)和 25.3%(DB),NeurIPS 2023 的接收率为 26.1(主会议)和 32.6%(DB)。

出自:Jian Wang—Snap Research(小红书)
另一位研究者、加州大学圣塔芭芭拉分校助理教授 Xin Eric Wang 也提到了这一现象,「有些领域主席即使在所有评审意见都是正面的情况下,仅仅是为了控制接收率,依然会拒稿。」
他认为这种做法是不对的,并回想起几年前类似的 AAAI 投稿经历:一篇评分为 7-7-7-6 的论文仅仅因为结果报告中写成 0.84 而不是 84% 就被拒掉了。「当学术会议开始为名额游戏而拒绝优秀的工作时,声誉就会下降。学术声望源于公平的评审以及吸引顶尖的投稿,而不是人为地压低接收率。」

图源:https://x.com/xwang_lk/status/1960360698942468362
有人晒出了自己过去两届 NeurIPS 的「悲惨」遭遇,「8-7-7-6-5」和「7-6-6-6」高分均被拒稿。

图源:https://x.com/ayushchopra96/status/1960417136729579841
这样遗憾的结果出现在了其他更多学术会议中,比如陈丹琦等一批知名青年学者组织的新会议 COLM(Conference on Language Modeling,语言建模会议)。

图源:https://x.com/fredsala/status/1960386616393945284
我们进一步发现,国外社区有类似的消息透露,「NeurIPS 官方正向高级领域主席(SAC)施压,要求他们拒掉已经接收的论文,理由是场地限制。」

网传的官方发给审稿委员会成员的指南显示,官方要求领域主席们严格执行「专业对口」的原则,确保每篇被录用的论文都因其最核心的贡献而被放在了最合适的类别下,避免出现用「数据集的贡献」去填充「技术创新名额」的情况,反之亦然。
评论区有投稿人反映,在论文提交和 rebuttal 阶段,官方并未明确告知这一严格的划分标准。这种在评审后期才明确的内部准则,让人感到措手不及。

出自:Li Yu(小红书)
原则上,研究赛道 (research track) 侧重于技术进步,而数据集与基准测试赛道 (DB track) 则聚焦于数据集和基准测试。我们认识到,这种区分并非总是清晰明了。有些论文将技术贡献与新的数据集或基准测试相结合,这使得确定哪个赛道更为合适变得困难。
然而,由于每个赛道都有其各自的侧重点、提交要求和评审流程,因此将一篇论文录用在错误的赛道上是不公平的。
因此,我们要求所有的领域主席 (ACs) 和高级领域主席 (SACs) 在给出录用建议时,仔细评估每篇论文的主要贡献。如果一篇论文的主要贡献明确在于数据集或基准测试,那么它就不应该被研究赛道录用。反之,如果主要贡献明确是技术性的,那么它就不应被数据集与基准测试赛道录用。如果不清楚哪一个赛道最匹配论文的主要贡献,我们请您在给出录用建议前,与程序主席 (program chairs) 或数据集与基准测试赛道主席 (DB chairs) 进行协商。
感谢您为 NeurIPS 2025 会议程序所做的贡献。
针对此次争议,有人表示:「不如将 NeurIPS 拆分成多个按具体研究领域划分的、规模较小的会议。」

当然,对「发文指标」的吐槽也从不缺席。

针对 NeurIPS 2025 出现的这些现象,有学者表示真的希望不要这样,如此一来会导致审稿人在未来的互动评审过程中不愿意再提高评分。
此外,本届 NeurIPS 引入的「rolling discussion」(滚动讨论,即在讨论阶段允许审稿人与作者之间实时地展开交流与澄清)机制是一项显著的改进,希望不要把它破坏掉。

图源:https://x.com/dyamins/status/1960769408147841073
正如下面这位老哥所言,「这样的体系存在着问题,当你把接收指标置于学术价值之上时,真正的创新就会受到损害。」

图源:https://x.com/VibeCodeTeddy/status/1960619413050417671
对于 NeurIPS 2025 审稿问题,你有什么想讨论的?欢迎留言。
参考链接:
#R-4B
DeepSeek、GPT-5都在尝试的快慢思考切换,有了更智能版本,还是多模态
本研究由中科院自动化所和腾讯混元联合研发,团队成员包括 Qi Yang, Bolin Ni, Shiming Xiang, Han Hu, Houwen Peng, Jie Jiang
背景:多模态大模型的思考困境
当前,业界顶尖的大模型正竞相挑战“过度思考”的难题,即无论问题简单与否,它们都采用 “always-on thinking” 的详细推理模式。无论是像 DeepSeek-V3.1 这种依赖混合推理架构提供需用户“手动”介入的快慢思考切换,还是如 GPT-5 那样通过依赖庞大而高成本的“专家路由”机制提供的自适应思考切换。它们距离真正意义上的“智能思考”仍有距离。这些方案或将判断压力转移给用户,或受限于复杂的系统架构和高昂的部署成本。因此,研发一款轻量化、支持多模态且能实现更智能自适应思考的大模型,将为用户提供更加流畅的交互体验。

近期,由腾讯混元团队与中科院自动化所合作的一项最新研究推出 R-4B 多模态大模型,通过自适应思考(auto-thinking)机制,改变了这一现状,它让 AI 能像人类一样 “智能切换” 思维模式。简单问题直接响应,复杂问题深度推理,在最大化回答准确性的同时,最小化计算开销。
- 论文标题:R-4B: INCENTIVIZING GENERAL-PURPOSE AUTOTHINKING CAPABILITY IN MLLMS VIA BI-MODE ANNEALING AND REINFORCE LEARNING
- 论文链接:https://arxiv.org/pdf/2508.21113
这一 “按需思考” 的核心能力,为 4B 量级的多模态模型树立了全新的性能标杆,使其在评测性能指标上成功超越了 Keye-VL-8B、Kimi-VL-A3B-Thinking-2506 等更大规模的模型。

同时,R-4B 在权威基准 OpenCompass 榜单上取得了优异成绩。
- 登顶 OpenCompass 多模态学术榜单:在 20B 以内规模多模态大模型中,性能排名 Top 1!

- 位列 OpenCompass 多模态推理榜单开源榜首:在开源模型中,推理性能拔得头筹!

目前,该模型已在 GitHub 和 HuggingFace 上线,且支持 vLLM 快速部署。「消费级显卡即可运行,适用于笔记本电脑、智能座舱、智能家居等低功耗场景,支持垂直领域低成本微调。」截至目前下载量已破万,欢迎大家体验!
- GitHub 代码仓库:https://github.com/yannqi/R-4B
- Hugging Face 模型下载:https://huggingface.co/YannQi/R-4B
突破:R-4B 的自适应思考引擎
R-4B 的智慧之处在于其自适应思考能力:

- 遇到简单问题(简单实体识别、简易问答),它选择直接、高效地响应。
- 面对复杂任务(如数学计算、图表分析),它则自动切换到深度思考模式,生成详细的思考过程。
R-4B 的核心创新在于其独特的两阶段训练策略。为实现模型在通用领域的自适应思考,研究团队首先提出双模退火(bi-mode annealing)训练策略,促使模型同时掌握通用领域的思考与非思考能力。
该阶段可以理解为对模型进行 “思考” 启蒙,即同时喂给它两种范式数据:一种需要直接回答(非思考模式,像日常对话),另一种需要详细推理(思考模式,像解数学题)。通过这种训练,模型同时掌握了思考和非思考这两种响应模式,为后续的自适应思考模式训练打下坚实基础。该阶段的核心是通用领域推理和非推理模式的数据构建策略:针对客观题,用模型采样的答案一致性来衡量题目的难易程度;针对主观题目,用提示工程的方式去区分解决问题是否需要进一步思考。

- 推理模式数据:涵盖图表分析、逻辑推理等需多步推理的任务(如科学图解或数学问题)。
- 非推理模式数据:针对直接事实响应的查询(如实体识别或简单问答)。

经过退火训练,得到一个同时精通思考与非思考模式的基础模型 R-4B-Base ,为后续自适应思考强化训练奠定基础。基于此,团队开发了双模策略优化(Bi-mode Policy Optimization, BPO)强化学习算法。它无需依赖精心设计的奖励函数或特定数据,而是仅依赖基于规则的奖励信号,从数学数据出发,并可泛化到通用领域。其核心是混合双模 rollout 机制,通过强制模型在训练中同时探索思考模式和非思考模式轨迹,从而避免模型陷入对单一模式的响应偏好。在此基础上,通过同时奖励两种思考模式的策略,使模型自己学会判别何时应该思考。

性能表现:小模型,大能量
R-4B-RL 模型在多项公开基准测试中性能表现卓越,刷新了现有记录,其性能超过 Keye-VL-8B、Kimi-VL-A3B-Thinking-2506 等更大规模的模型。

更关键的是,R-4B-RL 在自适应思考模式下实现了推理效率的提升,在简单任务下模型无需消耗更多的 Token。这证明了 BPO 算法的有效性,即无需通用领域的强化学习数据或额外的奖励函数设计,模型也能实现自适应思考。

应用前景:从科研到产业的智能化浪潮
R-4B 的突破不止于技术,更开启了广阔应用场景:
- 应用智能 :在日常问答分析中,自动切换简单查询(如文档内容提取)和复杂推理(如图表分析)的思维模式,提升自动化处理效率。
- 科学研究 :在处理科学图表时,R-4B 的深度推理模式可解析多步关系,精准解读数据,提高研究效率。
- 消费级 AI :边缘设备部署中,R-4B 凭借更少的参数和自适应思考模式降低延迟和能耗,适用于即时问答系统。
(1) 文档内容提取(简单查询)

(2) 图表分析(复杂推理)

结语:自适应思考,探索 AI 发展新道路
从双模退火训练到 BPO 优化,R-4B 不仅解决了 MLLMs 的思考困境,更在小尺寸模型上探索了自适应思考的可行性 。自适应思考不仅是技术优化,更是对效率与普惠平衡的追求。在 AI 计算与推理成本飙升的今天,R-4B 的轻量化、智能化设计,为大模型可持续发展注入绿色动力。
R-4B 模型已全面开源,支持 vLLM 高效推理。下载量火速破万,诚邀体验与共建!
#NeurIPS近3万投稿爆仓,强拒400篇论文
博士疯狂内卷,AI顶会噩梦来袭
NeurIPS 2025 太炸裂了!三万篇投稿把大会直接“卷爆”,双会场都顶不住,硬生生砍掉约 40 篇已录用论文,围观网友:这瓜比论文还精彩!
AI顶会,一场「爆仓危机」正在上演。
由于会议场地限制,NeurIPS 2025正通知「高级领域主席」(SAC),拒收已被录用的论文。
一位SAC爆料,大约400篇论文直接被砍掉,即便是三位审稿人和AC已通过初审。
她吐槽,这太不公平了。若是容量不够,应该把会议拆分、扩容,而不是随意拒收这么多论文。
此前ICLR也采取了类似的「战术」
更荒唐的是,还有人拿着5444的成绩,成为了炮灰。
这种「临时变卦」的做法,一切根源都指向了——爆炸性的投稿总量。
几个月前,就有人发现NeurIPS投稿ID都已经排到23000了,搞不好最后冲破3万篇,简直疯狂。
ASU教授Subbarao Kambhampati痛批,因「资源限制」而拒掉AI论文,无异于搬起石头砸自己的脚。
还有人在那儿打抱不平,「这完全没有道理啊」!
约400篇论文被拒,NeurIPS爆仓
今年,是NeurIPS第39届年会。
与往年不同的是,这届NeurIPS 2025,为了应对会议规模迅速扩张的挑战,决定首次设立分会场——墨西哥城。
也就是说,NeurIPS 2025是首个双城会议,分别于:
· 12月2日-7日在圣迭戈会议中心举办
· 11月30日-12月5日在墨西哥城举办
显然,组委会分设两个会场后,依旧不够所有录用论文的展示。
突然间,拒收优秀论文,却成为了他们的「上上策」。
四个月前,Reddit网友发出的疑问,如今一语中的
这场学术闹剧,让无数研究者心碎一地,也引发了学术社区的广泛不满。
一时间,炸出了一些拿了高分、出现未引用文献等问题,而被拒收暴怒的原作者。
大佬出招,分设两赛道
有人建议,干脆把NeurIPS拆成不同的方向办,如今搞ML、自然语言处理、计算机视觉等,几乎机器学习领域所有的人,都挤到一个顶会,也太过离谱。
同样,另一些网友也建议,可以设立一个Findings track来解决问题。
无独有偶,CS教授Kambhampati指出,要是线下场地真的塞不下了,可以学习下ACL的模式——整两个赛道:
一个「主会」,一个「Findings」。
既然可以在Poster之上,分出Spotlight和Oral,那么为啥不能在此之下设立一个Findings,专门接收那些审稿评价不错、纯粹因场地不够而被刷掉的论文?
如今所有论文在投稿前,早已发布在了arXiv上。能被录用为Findings,可以算作社区认可的「标志」,哪怕是没有达到Oral级别,总比拒了强。
这个观点,恰恰迎合了许多人的想法,评论区中引来广泛的好评。
上下滑动查看
还有Reddit网友一语道破,对于大多数博士、学者而言,在NeurIPS、CVPR类似顶会发文,就是为了拿到「入场券」。
如今,发顶会已成为学生毕业、找教职、申请基金的「硬通货」。
有的一流高校,要求博士生必须出一篇顶级三大ML顶会的一作论文,竞争厮杀非常激烈。
上下滑动查看
AAAI 2.9万投稿破纪录,近7成来自中国
无独有偶,AAAI 2026也收到了破纪录的近29,000份投稿,投稿作者总人数超过75,000名。
在移除不符合投稿政策的论文(如缺少PDF文件、稿件未匿名、篇幅超长、作者投稿数超限等)后,仍有约23,000篇论文进入评审环节。
这一数量,几乎是AAAI 2025的2倍之多!
值得一提的是,在约29,000份总投稿中,有近20,000份来自中国。
如果算上其他国家和地区论文中出现的中国姓氏,华人作者的占比应该还会更高。
在研究领域方面,会议投稿量排名前三的研究关键词分别是:
- 计算机视觉(近10,000篇)
- 机器学习(近8,000篇)
- 自然语言处理(超4,000篇)
为了给如此巨量的投稿进行评审,大会招募了超过28,000名程序委员会(PC)成员、高级程序委员会(SPC)成员和领域主席(AC)。
其中,AAAI 2026程序委员会的规模,直接达到了AAAI 2025的近3倍。
上下滑动查看
除了增加人力之外,AAAI还将采用一系列AI工具来辅助评审,比如用于检测和反制审稿人合谋行为等。
与此同时,AI给出的审稿意见也会成为一项重要参考。
有眼尖的网友发现,在官方发布的「审稿人指南」中,开头写的还是「人类撰写」(human-written)和「AI生成」(AI-generated );到后来,就变成了「人类生成」(human-generated)。
也不知道在写这篇通报的过程中,官方是不是也用了AI。
上下滑动查看
AI顶会崩坏,沦为学术修罗场
不止NeurIPS、AAAI,近年来,各大AI顶会的投稿量如洪水猛兽般涌来。
3万篇总投稿量,真的算是个例中的个例了。其他顶会收到的总数,平均在1万左右,但也打破了自身的历史纪录。
CVPR 2025公布了共13008份有效投稿,比起2024年(11532篇),多了1500篇左右。
而录用率却在逐年递减,仅22.1%——2023年为25.8%,2024年为23.6%。
ICLR 2025接收11,565份投稿,总量首次突破一万,比去年多了4000多篇。
还有ICML 2025,今年收到了12107篇有效投稿,其中不包括「桌拒」的论文。
而且,投稿总量同样创下了新高,2024年有9653篇,提升了28%。
ICCV 2025官方用一个词——bold,来形容11239篇总投稿量。
作为两年举办一次的计算机视觉顶会,ICCV在2023年共收到了8088篇投稿。
回看这一年已落幕的AI顶会,让人不禁感慨,如此巨量的投稿,却成为了一场「噩梦」。过去,AI顶会组织者还以投稿量为荣,但如今后悔不已。
总量爆炸,全员审稿
当前,最棘手的问题是——人手不够,谁来审稿?合格的审稿人严重不足。
众所周知,各大顶会一般会引入「多层审稿机制」,如审稿人、AC、SAC、PC主席。
甚至,有的顶会,比如ICCV 2025强制「投稿作者」担任「审稿人」,若是在截止日期前没有完成,自己的论文也会被拒收。
但更令人担忧的新趋势是,即使论文获得不错的分数、AC认为值得录用,也因「贴Poster空间不够」而被拒绝。
2021年,ICLR也发生了类似的情况。
Kambhampati分享了自己亲身经历:一篇自己推荐接收,还写了Meta-review和SAC评论的论文,却被拒收了。
原因是,平均分低于因「资源限制」而设定的录用分数线。
他表示,如果想要「捞回」这篇论文,就必须额外花功夫向SAC申请破格录用……
这种做法看似无奈,实则荒谬至极。
那些被拒的论文不会消失,它们往往会转投下一个顶会。问题是,为这些会议审稿的人,仍是同一批人。
来回倒腾,浪费的所有人的时间和精力,无异于加剧审稿人短缺的恶性循环。
用AI敷衍审稿,吐槽不断
另一方面,投稿量激增,审稿人不够,最终导致了审稿质量下降,好像成为一个闭环永远没有出口。
不提以往,只今年AI顶会爆料的审稿槽点,足以让人捧腹大笑。
NeurIPS 2025审稿建议中,竟犯下了「谁是Adam」这样的低级错误,网友直呼离谱。
著名机器学习研究员Dan Roy张口大骂,「NeurIPS评审现如今就是垃圾」!
网友深情感谢,ICCV审稿人用ChatGPT堆砌出言辞华丽、泛泛而谈的评论。
再加上,论文作者还学会钻空子,抓住审稿人用LLM审稿的机会,在文中插入「隐身好评提示」。
这也成为了审稿质量下滑的罪魁祸首之一,也是学术会议亟待解决的问题。
学术,本该是公平的竞技场。NeurIPS这场「拒收风波」,失去的不只是400篇论文,而是无数研究者的信任。
参考资料:
https://x.com/xwang_lk/status/1960360698942468362
https://x.com/MarkSchmidtUBC/status/1959302293054275663
https://x.com/rao2z/status/1962223246146928931
https://aaai.org/conference/aaai/aaai-26/review-process-update/
#rStar2-Agent
14B打败671B!微软rStar2-Agent在数学推理上超过DeepSeek-R1
现在,LLM 已经可以获得非常强大的推理能力,而其中关键便是测试时扩展(test-time scaling)。
通常而言,延长思维链(CoT)就可以延长「思考时间」,从而显著提升性能,尤其是当使用大规模强化学习和可验证奖励 (RLVR) 进行优化时。
然而,对于容易出现细微中间错误或需要创造性推理转变的难题,较长的思维链仍然存在根本性的局限性。在这些情况下,模型往往依赖内部的自我反思,但这又常常无法发现错误,也无法在初始方法存在缺陷时进行自我纠正。
因此,模型不仅要能更长时间地思考,还应该要能「更聪明」地思考。为此,可以引入更高级的认知能力,让模型可以自主地利用合适的工具,从工具环境提供的反馈信号中进行推理、验证和学习。
近日,微软研究院的一个研究团队探索了使用主动式强化学习(agentic reinforcement learning)来实现这一目标,也就是说,模型会与专用工具环境中的工具进行交互,并根据收到的反馈调整其推理方式。
而他们的探索成果便是 rStar2-Agent,这是一种强大的主动式强化学习方法。使用该方法,这个微软团队训练了一个 14B 的推理模型 rStar2-Agent-14B—— 该模型达到前沿级别的性能,媲美甚至超越了 671B 的 DeepSeek-R1!

这项研究在社交网络上获得了广泛关注。

下面我们就来简单了解一下微软是如何造出了这个能以小搏大的模型。
论文标题:rStar2-Agent: Agentic Reasoning Technical Report
论文地址:https://arxiv.org/pdf/2508.20722
代码地址:https://github.com/microsoft/rStar
环境与问题描述
本研究使用的环境是 Python 编程工具和解释器。

Python 编程工具可拓宽模型的行动空间,使其能够探索替代方案并验证中间步骤,从而在单靠较长的 CoT 不足的情况下补充内部的自我反思。
然而,在该环境中有效地扩展主动式强化学习非常困难。
首先,编程工具和 Python 解释器的固有复杂性会将环境噪声引入推理过程。当模型不可避免地生成语法或逻辑上错误的代码时,由此产生的环境反馈(例如,错误消息)可能会导致模型浪费宝贵的 token 来纠正错误,而不是推进推理。遗憾的是,当前的强化学习方法主要依赖于「仅结果奖励」,而这只会加剧这个问题,因为即使中间工具调用失败的轨迹仍然会获得正奖励,只要最终答案正确即可。如此一来,该模型就会将错误视为可接受的,并生成冗长且低质量的推理轨迹。
其次,大规模主动式强化学习训练对基础设施的要求很高。单个训练批次可以触发数万个并发工具调用,这使得构建可靠且响应迅速的代码执行环境变得极具挑战性。
此外,与环境交互的智能体部署会放大标准强化学习系统中部署效率低下的现象,从而显著减慢整体训练速度。
rStar2-Agent 三大创新
微软提出的 rStar2-Agent 包含三大关键创新。
第一,该团队为大规模主动式强化学习构建了一个高效可靠的基础架构。
他们构建了一个高吞吐量、独立的代码环境,能够处理 45K 个并发工具调用,平均执行反馈仅需 0.3 秒即可返回。

为了解决强化学习 rollout 效率低下的问题,他们引入了一个负载均衡的 rollout 调度程序,该调度程序会根据 GPU 上可用的键值缓存容量动态分配 rollout 请求,从而最大限度地提高计算利用率。
即使在 GPU 资源有限的情况下,该基础架构也能实现高效的强化学习训练。使用 64 块 MI300X GPU,该团队仅用一周时间就完成了 rStar2-Agent-14B 的训练。
第二,为了在代码环境中实现有效的主动式强化学习,该团队提出了基于正确重采样的组相对策略优化 (GRPO-RoC),它将 GRPO 与基于正确重采样 (RoC) 的 rollout 策略相结合,以解决稀疏且仅关注结果的奖励条件下环境引起的噪声。

具体而言,RoC 首先对较大的 rollout 组进行过采样,然后下采样至标准批次大小。正向轨迹经过筛选,仅保留质量最高且工具导致错误或格式问题最少的轨迹,而负向轨迹则进行均匀下采样。

这种简单而有效的非对称采样方法将各种故障模式保留为信息丰富的负向信号,同时强调更高质量的成功案例以进行正向监督。
相比于在奖励函数中明确惩罚工具使用错误的方法,GRPO-RoC 可提高训练稳定性,并可避免 reward-hacking 的风险。
通过学习更清洁、更高质量的正向轨迹,该模型不仅能提升 Python 编程工具的使用率,还展现出高级认知能力,能够在真实的代码环境交互下更高效、更简洁地进行推理。
第三,该团队还提出了一套训练方案,能以最少的计算量将一个 14B 预训练基础模型提升到前沿数学推理水平。
不同于先前的研究(在强化学习之前应用推理密集型 SFT ),该团队从非推理 SFT 阶段开始 —— 仅用于灌输一般的指令遵循、编程工具使用和格式,而不增强推理能力。这可避免潜在的 SFT 过拟合,并保持初始平均响应较短,从而使强化学习能够更有效地培养推理能力,同时充分利用模型的预训练能力。

然后,该团队使用 GRPO-RoC 进行多阶段强化学习训练,逐渐增加任务难度和最大训练时长。不同于之前的强化学习方法,这些方法需要将 rollout 规模大幅扩展至 16K→48K 甚至更高,该团队将每个阶段的长度限制在较短的范围内(8K→12K)。这可显著降低强化学习成本,同时鼓励更高效的推理策略。
该模型仅需 510 个强化学习步骤,即可快速实现前沿水平的数学推理,展现出强大的能力和卓越的训练效率。

结果很惊艳
最终,使用新方法,他们训练得到了一个模型并将其命名为 rStar2-Agent-14B。它只有 14B 大小,但却实现了超越 DeepSeek-R1 和 Kimi k1.5 等领先推理模型的强大数学推理性能。

值得注意的是,在 AIME24 上,它的准确度达到了 80.6%,比 o3-mini (medium)、DeepSeek-R1 和 Claude Opus 4.0 (thinking) 分别高出 1.0%、0.8% 和 3.6%,在 AIME25 和 HMMT25 上分别达到了 69.8% 和 52.7%,展现了稳定一致的强大能力。

除了数学之外,尽管这里只使用数学的主动式强化学习进行训练,它仍然能够有效地泛化。

它在 GPQA-Diamond 科学推理基准上的表现优于 DeepSeek-V3,在 BFCL v3 的智能体工具使用任务上也表现不错,并在 IFEval 和 Arena-Hard 等通用基准测试中取得了具有竞争力的结果。
该团队还报告了未成功的尝试和分析,并重点介绍了由 rStar2-Agent 主动式强化学习带来的对更高级认知推理行为的发现,例如驱动更有效推理的环境反馈反思 token。
更多分析和消融研究请见原论文。
#SSRL
自搜索强化学习SSRL:Agentic RL的Sim2Real时刻
本文由清华大学、上海人工智能实验室、上海交通大学等机构联合完成。第一作者为上海 AI Lab 博士生樊钰辰,研究方向是 Agent 以及强化学习;通讯作者为清华大学周伯文教授。
此前的 Agentic Search RL 任务大多采用真实搜索引擎,导致训练效率低,速度慢,稳定性差。ZeroSearch 探索利用另一个模型提供信息的训练方法,取得了较好的表现。然而,模型依赖自身世界知识能够达到的上限,以及如何有效利用自身世界知识,降低幻觉仍然是一个值得探究的问题。为研究这些问题,本文引入 SSRL。
SSRL 利用结构化的 prompt 和 format reward,有效地提取出了模型中的 world knowledge,在各个 benchmark 上取得了更好的效果,有效地降低了模型的幻觉。本文接着探索训练 agent 是否需要真实环境的参与,并发现在接入真实搜索引擎后,经过 SSRL 训练的模型可以取得更好的效果,体现了 Sim2Real 的有效性。
SSRL 所有训练数据,训练细节,以及训练模型均已开源。
Github链接: https://github.com/TsinghuaC3I/SSRL
论文链接:https://arxiv.org/abs/2508.10874
一句话总结
本研究探索 SSRL,通过大语言模型 (LLM) 内部世界知识的利用,可以显著提升 Search Agent 的训练效率和稳定性。实验证明,该方法在多种基准测试中优于传统基于外部搜索引擎的方法,同时首次在 LLM 智能体领域实现了从模拟到真实 (Sim2Real) 的有效迁移。
一、动机
当前 RL 训练 Search Agent 主要有两种方式:
1. 全真实搜索 (Full-Real Search):直接调用商业搜索引擎 API 或检索增强生成 (RAG) 本地知识库
2. 半真实搜索 (Semi-Real Search):使用辅助 LLM 模拟搜索引擎行为
问题:
- 高昂成本:商业 API 调用费用昂贵,本地知识库加重 GPU 负担,且和真实场景存在差距
- 训练效率低下:多轮工具调用导致 rollout 效率降低
- 训练不稳定性:外部信息引入导致模型容易崩溃
- 非端到端训练:半真实搜索仍需额外微调步骤
综上所述,目前的 Search Agent 训练非常昂贵,耗时,且不稳定。
如何能够降低训练成本与训练时间,同时能够稳定地训练 Search Agent 呢?
面对这些问题,我们首先进行了对于 LLM 依赖自身世界知识所能达到的效果的上限的探究。我们利用 structured prompt 诱发 LLM 自发地利用世界知识,并且通过 pass@k 证明了其极高的上限。受此启发,我们尝试用 RL 进一步强化模型利用自身世界知识的能力,探索 SSRL 的效果。在此基础上,我们首次在 LLM Agent 领域提出 Sim2Real,并验证 SSRL 训练的模型在真实场景的泛化性。
二、观察:LLM 利用世界知识的上限
对应 Agentic Search 任务 Pass@K 上限很高
此前已经有研究证明 LLM 通过重复采样的方式可以在数学和代码取得极高的通过率,然而对于 LLM 利用自身世界知识回答 Search QA 类问题的上限还有待研究。我们首先使用一个 formatted instruction 来显式地利用模型内部知识(Self-Search)。

我们在大量的模型(包括 Qwen2.5,Qwen3,Llama3.1,Llama3.2)上进行了大量采样,实验结果显示,仅依赖模型内部知识,就可以在所有的 benchmark 上获得明显的效果提升,如 Llama-3.1-8B-Instruct 在 Bamboogle 上 pass@64 达到了 76% 的正确率,在 BrowseComp 上 pass@256 达到了 10% 的正确率。同时我们发现在这类任务上 Llama 系列效果远超 Qwen 系列,这和 math 上的结论恰恰相反。

Thinking 越多效果不一定越好
受启发于 Long-CoT LRM 的惊人表现,我们探究了 Long-CoT 对知识类的问题是否会有更好的表现。我们进行了三种 setting 的检验:
- 对于 reasoning model,我们对是否使用 thinking mode 进行了对比实验。
- 对于 sampling strategy,我们对比了是否使用 multi-turn generation 以及 reflection-based generation。
实验结果显示,过多的 thinking,或者 multi-turn 的生成在给定相同 token budget 的情况下未必可以取得更好的效果,这也和之前的 reasoning 工作中的结论相左。


Pass@K 上限很高,但 Maj@N 达到上限很难
证明了 Self-Search 具有极高的上限后,我们尝试使用 Majority Voting 的方法进行投票选择。实验结果显示,仅仅依赖答案进行投票的方式无法逼近模型能力的上限,并且在增加参与 majority voting 的采样数量时,效果也不会获得进一步的提升。如何逼近 self-search 的 upper-bound 仍然是一个问题。

三、SSRL:自搜索强化学习
训练目标优化
标准的搜索 RL Search Agent 目标函数为:

由于 R(检索信息)来自策略本身,优化目标方程可以简化为一个标准的 GRPO 优化目标:

关键技术设计
1. 信息掩码(Information Masking)
和之前的 Search RL 工作一样,我们在训练时屏蔽 <information> 标签内的 token,从而强制模型基于查询和推理生成答案,而非简单复制。
2. 复合奖励函数
由于我们没有人为地干预模型的生成过程,因此需要一个 format reward 去规范模型的格式化输出,以更好地利用内部知识。同时,我们采用 outcome reward 防止 reward hacking,确保奖励的有效性。

实验结果
我们在 Llama 系列和 Qwen2. 5 系列上进行了训练,实验结果如下:



可以看到:
- 利用 SSRL 训练后的 Llama 系列模型比 Search-R1 和 ZeroSearch 这种依赖外部引擎训练的模型可以取得更好的效果,然而在 Qwen 系列上,效果还有一定的差距。
- 使用 SSRL 训练效率可以提升约 5.6 倍,并且在训练过程中,Training reward 持续增长,在训练 2000 多步时也并未观察到 collapse 现象。
- 相比于 Base model,Instruct model 表现出更好的能力,我们将其归因为 SFT 阶段的大量信息注入。
四、Sim2Real Generalization
由于 Search 任务是和真实世界高度相关的,因此能够结合真实搜索去实时地解决问题也是非常重要的。在这个工作中,我们探究了 SSRL 训练的模型是否具有在真实世界搜索并推理的能力,我们称为 Sim2Real。
替换 Self-Searched Knowledge 为 Online-Searched Information
首先我们进行实验,将前 K 个 Self-Searched Knowledge 用在线搜索获得的结果进行替换,我们发现
- Sim2Real 会获得一定程度的效果提升,这显示了适当引入外部知识可以辅助模型思考。
- 随着 K 的增加,Sim2Real 的效果不会持续增长,这也显示了模型内部知识的一定优越性,即高度压缩性和灵活性,对于同样的一个问题,模型 self-search 的知识可能更加贴合。


结合 Self-Generated Knowledge 和 Real-world Knowledge
此前我们已经证明了,真实世界的知识和模型生成的知识都各有其优越性,如何有机地在 SSRL 的背景下利用他们也是一个值得考虑的问题。我们首次提出 entropy-guided search,我们首先提取出 search content,如果呈现熵增趋势,表明模型具有不确定性,我们应当寻求外部工具的帮助,如果熵减,则使用模型生成的知识。实验结果如下:

实验结果显示,Search 次数相比于之前减少了 20%-42%,而实验效果可以取得一个 comparable 的表现,但这只是一个初步的尝试,更精细的结合方法仍是一个问题。
五、SSRL 和 TTRL 的结合
我们尝试 SSRL 和 TTRL 相结合,证明 SSRL 的泛化性和有效性。可以发现,当使用 TTRL 时,相比于 GRPO-based SSRL,我们可以取得更好的效果,甚至可以获得 67% 的效果提升。

甚至在最为困难的 BrowseComp 上,我们仍然能够获得稳定的增长。然而我们观察到,使用 TTRL 时,模型会变得过于 confident,模型塌缩到每个问题只会搜索一次,且模型会学会一个捷径,即先指出最后的答案,再通过 search 去 verify。此外,TTRL 也非常容易崩溃,Training reward 会极速下降到 0。

#LongCat-Flash-Chat
冲上热搜!美团大模型,靠「快」火了
国内外开发者:亲测,美团新开源的模型速度超快!
当 AI 真的变得像水和电一样普及之后,模型强不强已经不是大家唯一关心的问题了。
从年初的 Claude 3.7 Sonnet、Gemini 2.5 Flash 到最近的 GPT-5、DeepSeek V3.1,走在前面的模型厂商无一不在思考:在保证准确性的前提下,如何让 AI 既能以最少的算力去解决每一个问题,又能在最短的时间内给出回应?换句话说,就是如何做到既不浪费 token,也不浪费时间。
对于在模型上构建应用的企业和开发者来说,这种从「单纯构建最强模型到构建更实用、更快速模型」的转变是个好消息。而且更加令人欣慰的是,与之相关的开源模型也逐渐多了起来。
前几天,我们在 HuggingFace 上又发现了一个新模型 ——LongCat-Flash-Chat。
这个模型来自美团的 LongCat-Flash 系列,官网可以直接使用(https://longcat.ai)。
它天然知道「not all tokens are equal」,因此会根据重要性为重要 token 分配动态计算预算。这让它在仅激活少量参数的前提下,性能就能并肩当下领先的开源模型。

LongCat-Flash 开源后登上热搜。
同时,这个模型的速度也给大家留下了深刻印象 —— 在 H800 显卡上推理速度超过每秒 100 个 token。国内外开发者的实测都证实了这一点 —— 有人跑出了 95 tokens/s 的速度,有人在最短时间内得到了和 Claude 相媲美的答案。

图源:知乎网友 @小小将。

图源:X 网友 @SlavaMorozov。
在开源模型的同时,美团也放出了 LongCat-Flash 的技术报告,我们可以在其中看到不少技术细节。
- 技术报告:LongCat-Flash Technical Report
- 报告链接:https://github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report.pdf
- Hugging Face: https://huggingface.co/meituan-longcat
- Github: https://github.com/meituan-longcat
在这篇文章中,我们将详细介绍。
大模型怎么省算力?
看看 LongCat-Flash 的架构创新和训练方法
LongCat-Flash 是一个混合专家模型,总参数量为 5600 亿,可以根据上下文需求激活 186 亿至 313 亿(平均 270 亿)个参数。
用来训练该模型的数据量超过 20 万亿 token,但训练时间却只用了不到 30 天。而且在这段时间里,系统达到了 98.48% 的时间可用率,几乎不需要人工干预来处理故障 —— 这意味着整个训练过程基本是「无人干预」自动完成的。
更让人印象深刻的是,这样训练出来的模型在实际部署时表现同样出色。
如下图所示,作为一款非思考型模型,LongCat-Flash 达到了与 SOTA 非思考型模型相当的性能,包括 DeepSeek-V3.1 和 Kimi-K2,同时参数更少且推理速度更快。这让它在通用、编程、智能体工具使用等方向都颇具竞争力和实用性。

此外,它的成本也很亮眼,仅为每百万输出 token 0.7 美元。这个价格相比市面上同等规模的模型来说,可以算是非常划算了。
从技术上来说,LongCat-Flash 主要瞄准语言模型的两个目标:计算效率与智能体能力,并融合了架构创新与多阶段训练方法,从而实现可扩展且智能的模型体系。
在模型架构方面,LongCat-Flash 采用了一种新颖的 MoE 架构(图 2),其亮点包含两方面:
- 零计算专家(Zero-computation Experts);
- 快捷连接 MoE(Shortcut-connected MoE,ScMoE)。

零计算专家
零计算专家的核心思想是并非所有 token 都是「平等」的。
我们可以这样理解,在一个句子中,有些词是非常容易预测的,如「的」「是」,几乎不需要计算,而有些词如「人名」则需要大量计算才能准确预测。
在以往的研究中,大家基本采用这种方式:即无论这个 token 是简单还是复杂,它都会激活固定数量(K)的专家,这造成了巨大的计算浪费。对于简单 token 来说,完全没必要调用那么多专家,而对于复杂 token,则可能又缺乏足够的计算分配。
受此启发,LongCat-Flash 提出了一种动态计算资源分配机制:通过零计算专家,为每个 token 动态激活不同数量的 FFN(Feed-Forward Network) 专家,从而根据上下文的重要性更合理地分配计算量。
具体而言,LongCat-Flash 在其专家池中,除了原有的 N 个标准 FFN 专家外,还扩展了 Z 个零计算专家。零计算专家仅将输入原样返回作为输出,因此不会引入额外的计算开销。
LongCat-Flash 中的 MoE 模块可以形式化为:

其中,x_t 为输入序列中的第 t 个 token,R 表示 softmax 路由器,b_i 表示第 i 个专家对应的偏置项,K 表示每个 token 所选中的专家数量。路由器会将每个 token 分配给 K 个专家,其中被激活的 FFN 专家数量会根据该 token 的上下文重要性而变化。通过这种自适应的分配机制,模型能够学习到对上下文更重要的 token 动态分配更多的计算资源,从而在相同的计算量条件下实现更优的性能,如图 3a 所示。

另外,模型在处理输入时,需要学会根据不同 token 的重要性,来决定到底要不要花更多计算资源。如果不去控制零计算专家被选中的频率,模型可能会偏向于选择有计算的专家,忽视零计算专家的作用。从而造成计算资源效率低下。
为了解决这一问题,美团改进了 aux-loss-free 策略中的专家偏置机制:引入专家特定的偏置项,该偏置能够根据最近的专家使用情况动态调整路由分数,同时又与语言模型的训练目标保持解耦。
更新规则采用了控制理论中的 PID 控制器实时微调专家偏置。得益于此,模型在处理每个 token 时,仅需激活 186 亿至 313 亿(平均激活量稳定在约 270 亿)的参数量,从而实现资源优化配置。
快捷连接 MoE
LongCat-Flash 另一个亮点是快捷连接 MoE 机制。
一般而言,大规模 MoE 模型的效率在很大程度上受到通信开销的限制。在传统的执行范式中,专家并行会引入一种顺序化的工作流程,即必须先通过一次全局通信操作将 token 路由到其指定的专家,随后计算才能开始。
这种先通信、再计算的顺序会带来额外的等待时间,尤其在大规模分布式训练中,通信延迟会显著增加,成为性能瓶颈。
此前有研究者采用共享专家架构,试图通过将通信与单个专家的计算重叠来缓解问题,但其效率受到单个专家计算窗口过小的限制。
美团通过引入 ScMoE 架构克服了这一限制,ScMoE 在层间引入了一条跨层快捷连接,这一关键创新使得:前一层稠密 FFN 的计算可以与当前 MoE 层的分发 / 聚合通信操作并行执行,相比共享专家架构,形成了一个更大规模的通信 - 计算重叠窗口。
该架构设计在多项实验中得到了验证。
首先,ScMoE 设计并不会降低模型质量。如图 4 所示,ScMoE 架构与未使用 ScMoE 的基线在训练损失曲线上的表现几乎完全一致,这证明了这种重新排序的执行方式并不会损害模型性能。这一结论在多种配置下均得到一致性验证。
更重要的是,这些结果表明:ScMoE 的稳定性与性能优势,与注意力机制的具体选择是正交的(即无论使用哪种注意力机制,都能保持稳定与收益)。

其次,ScMoE 架构为训练和推理提供了大量系统级效率提升。具体表现在:
- 在大规模训练方面:扩展的重叠窗口使前序块的计算能够与 MoE 层中的分发和聚合通信阶段完全并行,这是通过沿 token 维度将操作分割为细粒度块实现的。
- 在高效推理方面:ScMoE 支持单批次重叠 pipeline,相较 DeepSeek-V3 等领先模型,将理论每秒输出 token 时间(TPOT)降低近 50%。更重要的是,它允许不同通信模式的并发执行:稠密 FFN 上节点内的张量并行通信(通过 NVLink)可与节点间的专家并行通信(通过 RDMA)完全重叠,从而最大化总体网络利用率。
总之,ScMoE 在不牺牲模型质量的情况下提供了大量的性能提升。
模型扩展策略与多阶段训练
美团还提出了一套高效的模型扩展策略,能够显著改善模型在规模增大时的性能表现。
首先是超参数迁移,在训练超大规模模型时,直接尝试各种超参数配置非常昂贵且不稳定。于是美团先在较小的模型上进行实验,找到效果最好的超参数组合。然后,再把这些参数迁移到大模型上使用。从而节省了成本并保证了效果。迁移规则如表 1 所示:

其次是模型增长(Model Growth)初始化,美团先从一个在数百亿 token 上预训练过的半规模模型出发,训练好之后保留检查点。在此基础上把模型扩展到完整规模,并继续训练。
基于这种方式,模型表现出一条典型的损失曲线:损失先短暂上升,随后快速收敛,并最终显著优于随机初始化的基线。图 5b 展示 6B 激活参数实验中的一个代表性结果,体现了模型增长初始化的优势。

第三点是多层次的稳定性套件,美团从路由器稳定性、激活稳定性和优化器稳定性三个方面增强了 LongCat-Flash 的训练稳定性。
第四点是确定性计算,这种方法能够保证实验结果的完全可复现,并在训练过程中实现对静默数据损坏(Silent Data Corruption, SDC) 的检测。
通过这些措施,LongCat-Flash 的训练过程始终保持高度稳定,且不会出现不可恢复的损失骤增(loss spike)。
在保持训练稳定的基础上,美团还精心设计了训练 pipeline,使 LongCat-Flash 具备了高级智能体行为,该流程涵盖大规模预训练、面向推理与代码能力的中期训练,以及聚焦对话与工具使用的后训练。
- 初始阶段,构建一个更适合于智能体后训练的基础模型,为此美团设计了一个两阶段的预训练数据融合策略来集中推理密集型领域的数据。
- 训练中期,美团进一步增强模型的推理能力与代码能力;同时将上下文长度扩展至 128k,以满足智能体后训练的需求。
- 最后,美团又进行了多阶段后训练。鉴于智能体领域高质量、高难度训练数据的稀缺,美团设计了一个多智能体合成框架:该框架从三个维度定义任务难度,即信息处理、工具集复杂性和用户交互,使用专门的控制器来生成需要迭代推理和环境交互的复杂任务。
这种设计使其在执行需要调用工具、与环境交互的复杂任务时表现出色。
跑起来又快又便宜
LongCat-Flash 是怎么做到的?
前面提到,LongCat-Flash 可以在 H800 显卡上以超过每秒 100 个 token 的速度进行推理,成本仅为每百万输出 token 0.7 美元,可以说跑起来又快又便宜。
这是怎么做到的呢?首先,他们有一个与模型架构协同设计的并行推理架构;其次,他们还加入了量化和自定义内核等优化方法。
专属优化:让模型「自己跑得顺」
我们知道,要构建一个高效的推理系统,必须解决两个关键问题,一是计算与通信的协调,二是 KV 缓存的读写和存储。
针对第一个挑战,现有的方法通常在三个常规粒度上利用并行性:算子级的重叠、专家级的重叠以及层级的重叠。LongCat-Flash 的 ScMoE 架构引入了第四个维度 —— 模块级的重叠。为此,团队设计了 SBO(Single Batch Overlap)调度策略以优化延迟和吞吐量。
SBO 是一个四阶段的流水线执行方式,通过模块级重叠充分发挥了 LongCat-Flash 的潜力,如图 9 所示。SBO 与 TBO 的不同之处在于将通信开销隐藏在单个批次内。它在第一阶段执行 MLA 计算,为后续阶段提供输入;第二阶段将 Dense FFN 和 Attn 0(QKV 投影)与 all-to-all dispatch 通信重叠;第三阶段独立执行 MoE GEMM,其延迟受益于广泛的 EP 部署策略;第四阶段将 Attn 1(核心注意力和输出投影)及 Dense FFN 与 all-to-all combine 重叠。这种设计有效缓解了通信开销,确保了 LongCat-Flash 的高效推理。

对于第二个挑战 ——KV 缓存的读写和存储 ——LongCat-Flash 通过其注意力机制和 MTP 结构的架构创新来解决这些问题,以减少有效的 I/O 开销。
首先是推测解码加速。LongCat-Flash 将 MTP 作为草稿模型,通过系统分析推测解码的加速公式来优化三个关键因素:预期接受长度、草稿与目标模型的成本比以及目标验证与解码的成本比。通过集成单个 MTP 头并在预训练后期引入,实现了约 90% 的接受率。为了平衡草稿质量和速度,采用轻量级 MTP 架构减少参数,同时使用 C2T 方法通过分类模型过滤不太可能被接受的 token。
其次是 KV 缓存优化,通过 MLA 的 64 头注意力机制实现。MLA 在保持性能和效率平衡的同时,显著减少了计算负载并实现了出色的 KV 缓存压缩,降低了存储和带宽压力。这对于协调 LongCat-Flash 的流水线至关重要,因为模型始终具有无法与通信重叠的注意力计算。
系统级优化:让硬件「团队协作」
为了最小化调度开销,LongCat-Flash 研究团队解决了 LLM 推理系统中由内核启动开销导致的 launch-bound 问题。特别是在引入推测解码后,验证内核和草稿前向传递的独立调度会产生显著开销。通过 TVD 融合策略,他们将目标前向、验证和草稿前向融合到单个 CUDA 图中。为进一步提高 GPU 利用率,他们实现了重叠调度器,并引入多步重叠调度器在单次调度迭代中启动多个前向步骤的内核,有效隐藏 CPU 调度和同步开销。

自定义内核优化针对 LLM 推理的自回归特性带来的独特效率挑战。预填充阶段是计算密集型的,而解码阶段由于流量模式产生的小而不规则的批次大小往往是受内存限制的。对于 MoE GEMM,他们采用 SwapAB 技术将权重视为左手矩阵、激活视为右手矩阵,利用 n 维度 8 元素粒度的灵活性最大化张量核心利用率。通信内核利用 NVLink Sharp 的硬件加速广播和 in-switch reduction 来最小化数据移动和 SM 占用率,仅使用 4 个线程块就在 4KB 到 96MB 消息大小范围内持续超越 NCCL 和 MSCCL++。
量化方面,LongCat-Flash 采用与 DeepSeek-V3 相同的细粒度块级量化方案。为实现最佳性能 - 准确率权衡,它基于两种方案实施了层级混合精度量化:第一种方案识别出某些线性层(特别是 Downproj)的输入激活具有达到 10^6 的极端幅度;第二种方案逐层计算块级 FP8 量化误差,发现特定专家层中存在显著量化误差。通过取两种方案的交集,实现了显著的准确率提升。
实战数据:能跑多快?多便宜?
实测性能显示,LongCat-Flash 在不同设置下表现出色。与 DeepSeek-V3 相比,在相似的上下文长度下,LongCat-Flash 实现了更高的生成吞吐量和更快的生成速度。

在 Agent 应用中,考虑到推理内容(用户可见,需匹配人类阅读速度约 20 tokens/s)和动作命令(用户不可见但直接影响工具调用启动时间,需要最高速度)的差异化需求,LongCat-Flash 的近 100 tokens/s 生成速度将单轮工具调用延迟控制在 1 秒以内,显著提升了 Agent 应用的交互性。在 H800 GPU 每小时 2 美元的成本假设下,这意味着每百万输出 token 的价格为 0.7 美元。
理论性能分析表明,LongCat-Flash 的延迟主要由三个组件决定:MLA、all-to-all dispatch/combine 以及 MoE。在 EP=128、每卡 batch=96、MTP 接受率≈80% 等假设下,LongCat-Flash 的理论极限 TPOT 为 16ms,相比 DeepSeek-V3 的 30ms 和 Qwen3-235B-A22B 的 26.2ms 有显著优势。在 H800 GPU 每小时 2 美元的成本假设下,LongCat-Flash 输出成本为每百万 token 0.09 美元,远低于 DeepSeek-V3 的 0.17 美元。不过,这些数值仅为理论极限。

在 LongCat-Flash 的免费体验页面,我们也测试了一下。
我们首先让这个大模型写一篇关于秋天的文章,1000 字左右。

我们刚提出要求,刚点开录屏,LongCat-Flash 就把答案写出来了,录屏都没来得及第一时间关。
细细观察你会发现,LongCat-Flash 的首个 token 输出速度特别快。以往使用其他对话模型的时候,经常会遇到转圈圈等待,非常考验用户耐心,就像你着急看微信,结果手机信号显示「收取中」一样。LongCat-Flash 改变了这一步的体验,基本感觉不到首个 token 的延迟。

后续的 token 生成速度也很快,远远超出人眼的阅读速度。
接下来,我们打开「联网搜索」,看看 LongCat-Flash 这项能力够不够快。我们让 LongCat-Flash 推荐望京附近好吃的餐厅。
测试下来可以明显感受到,LongCat-Flash 并不是思考半天才慢悠悠地开口,而是几乎立刻就能给出答案。联网搜索给人的感受也是「快」。不仅如此,它在快速输出的同时还能附带引用来源,让信息的可信度与可追溯性都有保障。
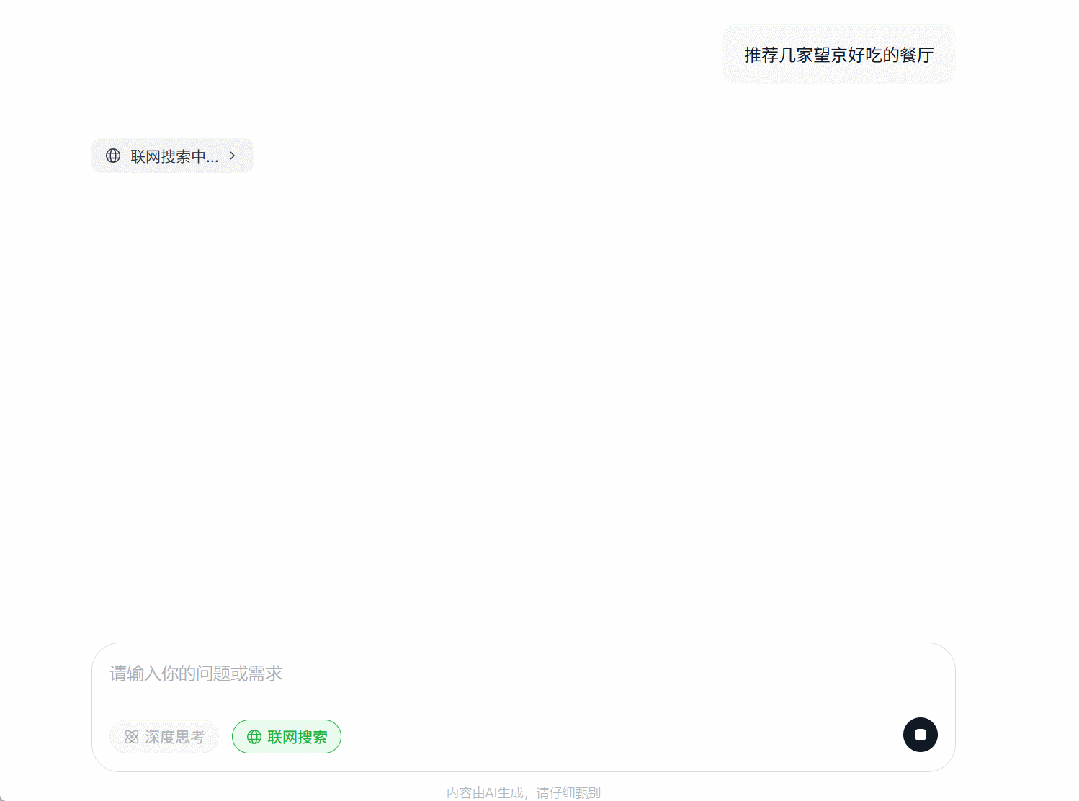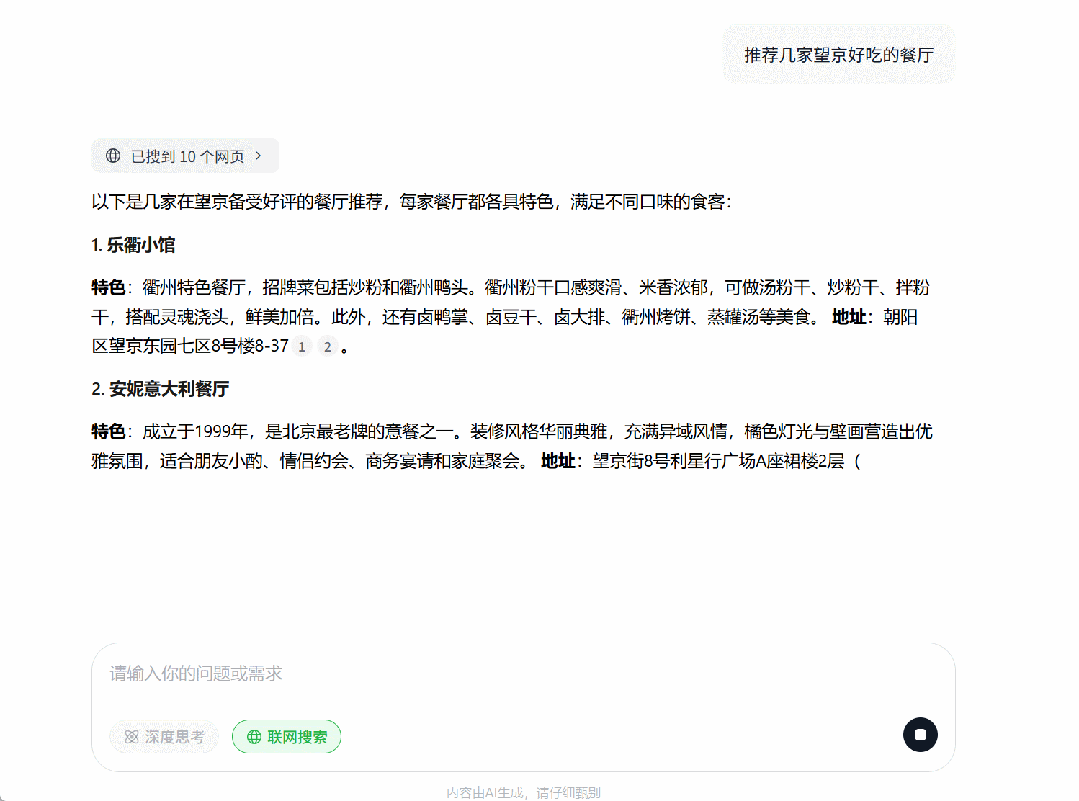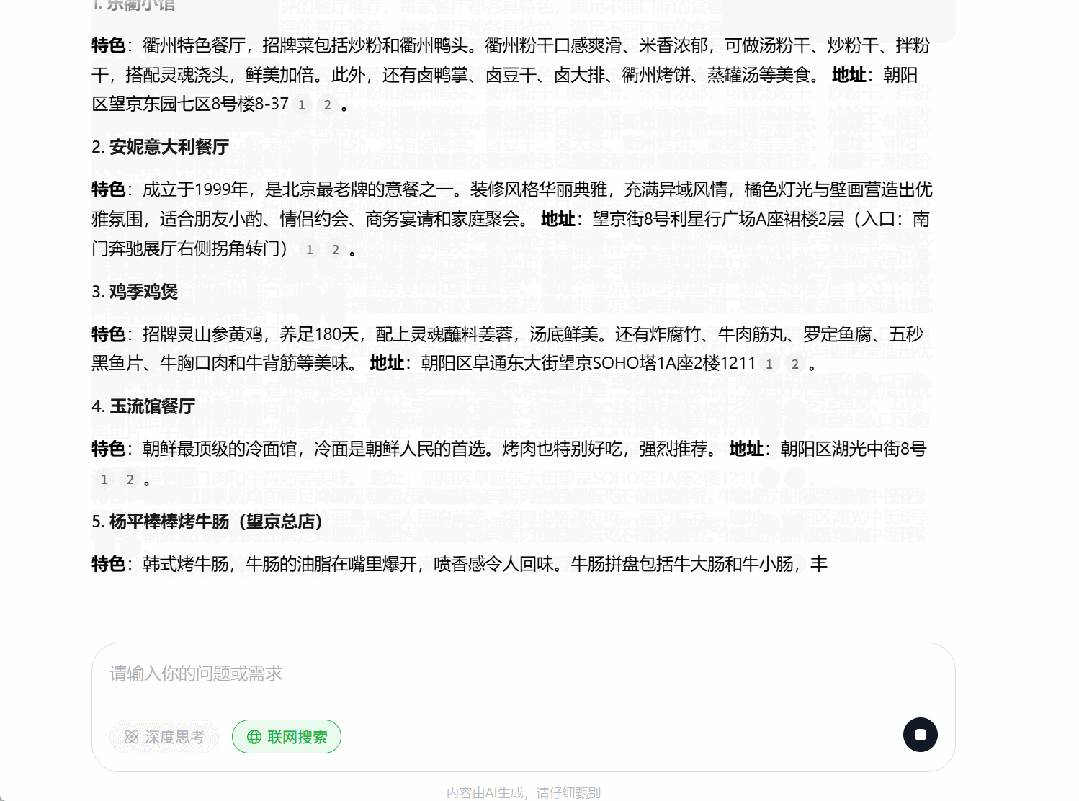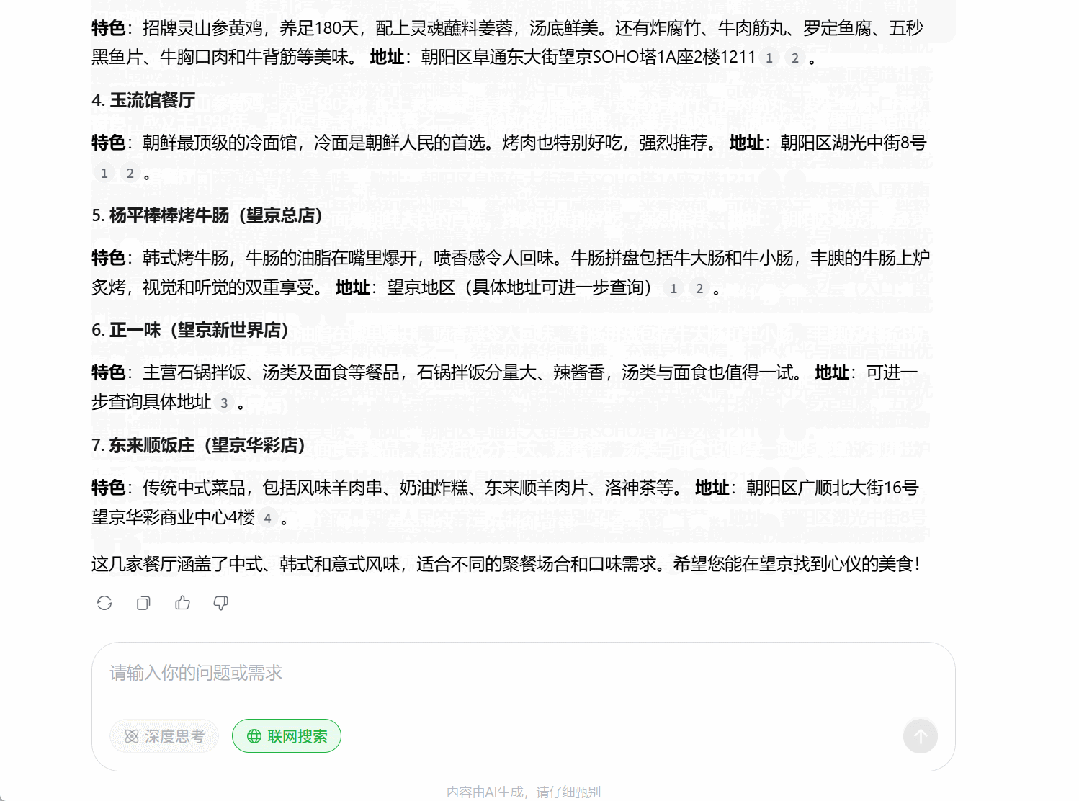
有条件下载模型的读者可以在自己本地跑一下,看看 LongCat-Flash 的速度是否同样惊艳。
当大模型走进实用时代
过去几年,每当出来一个大模型,大家都会关心:它的 benchmark 数据是多少?刷新了多少个榜单?是不是 SOTA?如今,情况已经发生了变化。在能力差不多的情况下,大家更关心:你这个模型用起来贵不贵?速度怎么样?在使用开源模型的企业和开发者中,这种情况尤其明显。因为很多用户用开源模型就是为了降低对闭源 API 的依赖和费用,所以对算力需求、推理速度、压缩量化效果更敏感。
美团开源的 LongCat-Flash 正是顺应这种趋势的代表作。他们把重点放在了怎么让大模型真正用得起、跑得快,这是一项技术普及的关键。
这种实用路线的选择和我们对美团一直以来的观感是一致的。过去,他们在技术上的绝大部分投入都用来解决真实业务痛点,比如 2022 年获 ICRA 最佳导航论文的 EDPLVO,其实就是为了解决无人机在配送途中遇到的各种意外情况(比如楼宇过密会失去信号);最近参与制订的全球无人机避障 ISO 标准,是无人机在飞行途中躲避风筝线、擦玻璃安全绳等案例的技术经验沉淀。而这次开源的 LongCat-Flash 其实是他们的 AI 编程类工具「NoCode」背后的模型,这个工具既服务于公司内部,也对外免费开放,就是希望大家能把 vibe coding 用起来,实现降本增效。
这种从性能竞赛向实用导向的转变,其实反映了 AI 行业发展的自然规律。当模型能力逐渐趋同时,工程效率和部署成本就成了关键差异化因素。LongCat-Flash 的开源只是这个趋势中的一个案例,但它确实为社区提供了一个可参考的技术路径:如何在保持模型质量的前提下,通过架构创新和系统优化来降低使用门槛。这对于那些预算有限但又希望用上先进 AI 能力的开发者和企业来说,无疑是有价值的。
#On the Theoretical Limitations of Embedding-Based Retrieval
DeepMind爆火论文:向量嵌入模型存在数学上限,Scaling laws放缓实锤?
这几天,一篇关于向量嵌入(Vector Embeddings)局限性的论文在 AlphaXiv 上爆火,热度飙升到了近 9000。

要理解这篇论文的重要性,我们先简单回顾一下什么是向量嵌入。
向量嵌入就像把文字、图片或声音这些复杂的东西,转化成一个多维空间里的「坐标点」。比如,把「苹果」这个词变成一串几百维的数字,这些数字捕捉了它的语义(它可以指水果,也可以指公司)。在这个空间里,相似的概念彼此靠近,不相似的则远离。借助这种机制,计算机能够快速搜索或比较海量数据,而无需逐字逐句地比对。

图源:veaviate
多年以来,嵌入主要用于「检索」任务,例如搜索引擎中的相似文档查找,或推荐系统中的个性化推荐。随着大模型技术的发展,嵌入的应用开始拓展到推理、指令遵循、编程等更复杂的任务。这些新兴需求,推动着嵌入技术朝着能处理任何查询、任何相关性定义的方向演进。
然而,先前的研究已经指出了向量嵌入的理论局限性。它的本质,是把一个高维度、复杂的概念(比如「爱」,可能包含亲情、爱情、友情、奉献、占有等无数面向)强行压缩成一串固定长度的向量。这个过程不可避免地丢失信息,就像三维苹果被拍成二维照片 —— 无论照片多清晰,你都无法从中还原出它的重量、气味等属性。
过去几年,业界普遍认为这种理论困难可以通过更好的训练数据和更大的模型来克服。这就是过去几年以 OpenAI 为代表的公司所遵循的「大力出奇迹」(Scaling Laws)的哲学。
从 GPT-2 到 GPT-4,再到 GPT-5,模型参数量和数据量指数级增长,能力也确实发生了质的飞跃。这让很多人相信,这条路能一直走下去。
然而,当前 AI 圈的一个热点争论就是:我们是不是快要撞上「Scaling Laws」的天花板了?
DeepMind 的最新研究为这个争论提供了新的证据。他们将几何代数与通信复杂度理论结合,证明了向量嵌入的能力存在一个数学下界:对于任意给定的嵌入维度 d,当文档数量超过某个临界点时,总会存在一些相关文档组合是无论如何都无法通过查询同时召回的。
这意味着,嵌入模型存在一个不可逾越的限制,无法单纯依靠「更大的模型」来突破。
- 论文标题:On the Theoretical Limitations of Embedding-Based Retrieval
- arXiv 地址:https://arxiv.org/pdf/2508.21038
这一理论瓶颈在现实中最直接的体现,就是检索增强生成(RAG)。RAG 的工作机制是:先用向量嵌入从知识库中检索相关信息,再交给大模型生成答案。但 DeepMind 的证明表明,当知识库规模足够大、一个问题需要多份文档共同回答时,即使采用最先进的嵌入模型,也可能因为维度不足而无法完整召回关键信息。这会导致大模型在生成时受到错误或不完整上下文的干扰。

为了证明这一理论限制对任何模型或训练数据都成立,研究者采用了一种「最佳情况」设定,即向量本身是使用测试数据直接进行优化的。实验发现,对于每个嵌入维度 d 都存在一个临界点,一旦文档数量超过该点,嵌入维度就不足以编码所有的组合。他们还证明了这种临界关系可以通过一个多项式函数进行经验性建模。
更进一步,研究者基于这些理论局限性构建了一个名为 LIMIT 的简单数据集。尽管任务很简单(例如,「谁喜欢苹果?」),但即便是 MTEB 基准上最先进的嵌入模型也很难解决这个问题,而对于嵌入维度较小的模型来说则是不可能的。
论文一作、约翰霍普金斯大学博士生 Orion Weller 表示,在当前的信息检索领域,大家希望嵌入模型能够同时承担指令理解和推理等一切能力。遗憾的是,单向量嵌入模型在理论和实证上都做不到,它们存在根本性限制。通过开源的简单评测任务,他们证实了即便是 SOTA 模型也表现糟糕。

总的来说,这篇工作的贡献可以总结为以下三点:
- 为嵌入模型的根本性局限提供了理论基础;
- 通过自由的嵌入优化进行最佳情况下的经验性分析,证明了该理论适用于任何数据集实例;
- 构建了一个名为 LIMIT 的简单、真实的自然语言实例,即使是最先进的嵌入模型也无法解决。
这不仅揭示了 RAG 系统在应用上的硬性约束,也让人重新思考 Scaling Laws 在 AI 发展中的边界。嵌入的局限,也许正是「加大规模」并非万能解法的一个缩影。
向量嵌入的表征能力
研究者首先证明了通信复杂性理论中的已知结果在向量嵌入设定下的含义。
理论上限。对于二进制矩阵,逐行排序和逐行阈值化是等价的表征能力概念。

到目前为止,研究者描述的这些概念与矩阵的符号秩密切相关。在本文的其余部分,他们将利用符号秩来建立主要的界限。


将所有这些结合起来就得出了所需的不等式链。
研究者表示,在向量嵌入模型的背景下,这为准确捕获一组检索目标所需向量的维度提供了上下界,无论是逐行排序、逐行阈值,还是全局阈值。
具体来说,给定某个二进制相关矩阵 A ∈ {0,1}^m×n,至少需要 rank_±(2A − 1_m×n) − 1 个维度来精确捕获 A 中的关系,并且最多需要 rank_±(2A − 1_m×n) 个维度就能实现。
在实际中,这意味着:
- 对于任意固定的维度 d,都会存在某个二进制相关矩阵无法通过 d 维嵌入来捕获,这是因为存在符号秩任意高的矩阵。换句话说,那些 qrel 矩阵具有更高符号秩的检索任务更难被嵌入模型精确捕获,需要更高的嵌入维度。
- 如果能够在 d 维中以逐行保持顺序的方式嵌入某个给定的矩阵 A ∈ {0,1}^m×n,那么这就意味着 2A − 1_m×n 的符号秩有一个上界。这尤其表明了一种实用机制,可以通过对自由嵌入表示进行梯度下降优化来确定矩阵符号秩的上界。
实证联系
最佳情况优化
在上文中,研究者已经基于 qrel 矩阵的符号秩及其嵌入维度 d 建立了嵌入模型的理论局限,现在希望在实证层面上也展示这一点。
为了展示可能的最强优化情况,研究者设计了实验,使得向量本身可以通过梯度下降直接优化。他们称这种方式为「自由嵌入」优化,嵌入是自由可优化的,不受自然语言的限制,而自然语言会对任何现实的嵌入模型施加约束。因此,这可以展示任意嵌入模型是否有可能解决该问题:如果自由嵌入优化无法解决该问题,那么真实的检索模型也无法做到。
值得注意的是,研究者是通过直接在目标 qrel 矩阵(测试集)上优化嵌入来实现的。这种方式不会泛化到新的数据集,但其目的是展示可能出现的最高性能。
关于实验设置,研究者创建一个随机文档矩阵(大小为 n)和一个随机查询矩阵,其中包含 top-k 集合(所有组合,即大小为

),两者均为单位向量。然后直接使用 Adam 优化器来优化约束条件。每一次梯度更新都对所有正确的三元组进行完整遍历(即整个数据集作为 batch-size),并使用 InfoNCE 损失函数,其他所有文档作为批内负样本(即整个数据集在一个 batch 中)。
由于几乎所有嵌入模型都使用归一化向量,研究者也同样采用这种方式(在更新后进行归一化)。当损失在 1000 次迭代中没有改进时,就提前停止。他们逐渐增加文档数量(因此查询的组合数也随之增加),直到优化器无法再解决该问题(即无法达到 100% 的准确率)。研究者将这一点称为「临界 n 点」。
由于文档数较大时组合数量呈现组合爆炸(例如 5 万个文档、top-k=100 时会产生 7.7e+311 种组合,这相当于自由嵌入实验中维度为 d 的查询向量数量),因此研究者专注于 n、k 和 d 的相对较小规模。研究者设定 k=2,并在每个 d 值下逐次增加 n,直到模型无法解决问题。此外对数据拟合了一条多项式回归曲线,以便能够建模并向外推算结果。
结果如下图 2 所示,该曲线符合三次多项式拟合,其公式为 y = −10.5322 + 4.0309d + 0.0520d² + 0.0037d³ (r²=0.999)。将该曲线外推得到的临界 n 值(对应嵌入维度)分别为:500k(512)、170 万(768)、400 万(1024)、1.07 亿(3072)、2.5 亿(4096)。
需要注意,这只是最佳情况:真实的嵌入模型无法直接优化查询和文档向量以匹配测试集的 qrel 矩阵,并且还受到「自然语言建模」等因素的约束。然而,这些数值已经表明,对于网页级别的搜索,即便是在理想测试集优化下,最大的嵌入维度也不足以建模所有组合。

实证联系
真实世界数据集
接下来,研究者将(1)该理论与现有数据集建立联系;(2)为现有 SOTA 模型构建一个极其简单却又极度困难的检索任务。
与以往工作形成对比的是,研究者希望构建的数据集,可以用于评估少量文档情况下所有 top-k 集合的组合。不同于使用 QUEST、BrowseComp 等复杂的查询操作符(这些操作本身就因 qrel 矩阵之外的原因而很难),他们选择了非常简单的查询和文档,以突出表示所有 top-k 集合本身的难度。
LIMIT 数据集
研究者选用 5 万个文档,以构建一个既有难度又相对规模较小的语料库;同时使用 1000 个查询,以在保证统计显著性的前提下仍能快速完成评估。
对于每个查询,研究者选择关联两个相关文档(即 k=2),这样做既为了简化实例化过程,也为了与之前的工作保持一致。接下来是选择一个 qrel 矩阵来实例化这些属性,并为查询分配随机的自然语言属性,将这些属性添加到各自的相关文档中(参见图 1)。
研究者测试了所有文档组合的相关性(对于三个文档,每个查询包含两个相关文档的所有组合),并通过一个简单的映射进行实例化。

研究者评估了当前 SOTA 嵌入模型,包括 GritLM、Qwen 3 Embeddings、Promptriever、Gemini Embeddings、Snowflake 的 Arctic Embed Large v2.0 以及 E5-Mistral Instruct,并展示了在完整嵌入维度下的结果以及在截断嵌入维度(通常用于 matryoshka learning,即 MRL)下的结果。
下图 3 展示了在完整 LIMIT 上的结果,而下图 4 展示了在小规模(包含 46 个文档)版本上的结果。令人惊讶的是,即便任务本身很简单,模型依然表现极差。在完整设置中,模型甚至难以达到 20% 的 recall@100,而在 46 个文档的版本中,即使是 recall@20,模型也无法解决该任务。


存在领域迁移吗?
虽然本文的查询看起来与标准的网页搜索查询相似,但研究者怀疑是否存在某种领域迁移从而导致性能低下。如果真是这样,那么在相似示例的训练集上进行训练预计能够显著提升性能。另一方面,如果任务本身就很难,那么在训练集上训练几乎无济于事,而在测试集上训练则会让模型过拟合到特定 token。
下图 5 显示,在训练集上训练的模型无法解决该问题,虽然 recall@10 从最开始的接近零有了轻微提升,最高达到了 2.8。但在域内训练时并未出现明显的性能提升,表明性能较弱并不是由领域迁移造成的。

Qrel 模式的影响
研究者从以下四种不同的 qrel 模式来实例化 LIMIT 数据集:
- 从所有组合中随机采样;
- 基于循环的设置,其中下一个查询与前一个查询中的一个文档以及后续下一个文档相关;
- 不相交模式,每个查询与两个新的文档相关;
- 在查询集中能容纳的最大文档数上,最大化连接数(即组合数 n choose k)的模式(稠密模式,标准设置)。
从下图 6 可以看到,除了稠密模式之外,其他模式的性能相对接近。不过,当转向稠密模式时,所有模型的分数都显著下降:GritLM 的 recall@100 绝对值下降了 50,而 E5-Mistral 的降幅更加惊人,几乎降低了 10 倍(从 40.4 降到了 4.8)。

更多技术细节和实验结果请参考原论文。
#URL Context
AI读网页,这次真不一样了,谷歌Gemini解锁「详解网页」新技能
谷歌回归搜索老本行,这一次,它要让 AI 能像人一样「看见」网页。
这是谷歌前不久在 Gemini API 全面上线的 URL Context 功能(5 月 28 日已在 Google AI Studio 中推出),它使 Gemini 模型能够访问并处理来自 URL 的内容,包括网页、PDF 和图像。

Google 产品负责人 Logan Kilpatrick 表示这是他最喜欢的 Gemini API 工具,并推荐大家把这个工具设置为默认开启的「无脑选项」。

那么灵魂一问:这和我平时把链接扔给 AI 对话框里有什么本质区别?感觉我一直在这么做。
区别在于处理深度和工作方式。你平时扔链接,AI 通常会通过一个通用的浏览工具或搜索引擎插件来「看」这个网页,AI 很可能只读取了网页的摘要或部分文本。
而 URL Context 则完全不同。它是一个专为开发者设计的编程接口(API),当开发者在他的程序里调用这个功能时,他是明确地指令 Gemini「把这个 URL 里的全部内容(上限高达 34MB)作为你回答下一个问题的唯一、权威的上下文」,Gemini 会进行深度、完整的文档解析,理解整个文档的结构、内容和数据。
以下是它的能力清单:
- 深度解析 PDF:能深刻理解 PDF 中的表格、文本结构甚至脚注。
- 多模态理解:能处理 PNG、JPEG 等图片,并理解其中的图表和图示。
- 支持多种网页文件:HTML、JSON、CSV 等常见格式均不在话下。
官方 API 文档提供详细的配置教程,除此之外,还可以在 Google AI Studio 直接体验。

Towards Data Science 上的一篇文章详细介绍了 URL Context Grounding,作者 Thomas Reid 犀利地将 URL Context Grounding 评价为「RAG 的又一颗棺材钉」。

- 文章地址:https://towardsdatascience.com/googles-url-context-grounding-another-nail-in-rags-coffin/
RAG 是过去几年中用于提升大语言模型回答准确性、时效性和可靠性的主流技术。由于大模型的知识截止于其训练数据,RAG 通过一个外部知识库来为其提供最新的、特定性的信息。
传统的 RAG 流程相对复杂,通常包括以下步骤:
- 提取内容:从数据源(如网站、文档)中抓取文本。
- 分块:将长文本切分成更小、更易于处理的片段。
- 矢量化:使用嵌入模型(Embedding Model)将文本块转换为数字向量,捕捉其语义信息。
- 存储:将这些向量存储在专门的向量数据库中。
- 检索:当用户提问时,系统首先在向量数据库中搜索与问题最相关的文本块。
- 增强与生成:将检索到的相关文本块作为上下文信息,与原始问题一同输入给大语言模型,从而生成更准确、更具针对性的回答。

RAG 架构。图源:Mindful Matrix
Thomas Reid 指出,使用 URL Context Grounding「无需提取 URL 文本和内容、分块、矢量化、存储等」。对于处理公开网络内容这个非常普遍的场景,它提供了一个极其简单的替代方案。
开发者不再需要花费大量时间和精力去搭建和维护一个由多个组件(数据提取、向量数据库等)组成的复杂管道,只需几行代码就能实现更精准的效果。
在 Thomas Reid 提供的示例中,Gemini 仅凭一个指向特斯拉 50 页财报 PDF 的 URL,就准确无误地提取出了位于第 4 页表格中的「总资产」和「总负债」数据,这是仅靠摘要绝无可能完成的任务。

自特斯拉 SEC 10-Q 申报文件第 4 页内容。
以下是我们在 Google AI Studio 中的测试结果。

作者接着测试了 URL Context 挑选其他信息的能力。在 PDF 的末尾,有一封写给即将离开公司的员工的信,概述了他们的遣散条款。

信中提到的退出日期用星号(***)标记,屏蔽退出日期的原因在脚注中给出。
URL Context 准确识别出了脚注中的内容。
根据所提供的文件,员工离职协议中的离职日期被标记为「***」,原因在于某些公司视为隐私或机密的特定非关键信息,已在公开文件中被有意略去。
该文件包含一条对此做法的澄清说明:「本文档中某些已识别的信息已被略去,因为这些信息并非关键信息,且属于公司视为隐私或机密的信息类型,并已用「***」标记以示省略之处。

根据官网介绍,URL Context 采用一个两步检索流程,以平衡速度、成本和对最新数据的访问。
当用户提供一个 URL 时,该工具首先尝试从内部索引缓存中获取内容,以提高速度和成本效益。如果 URL 不在缓存中(比如一个刚刚发布的页面),它会进行实时抓取。
那它的能力边界在哪里呢?官方介绍中也有明确说明。
- 无法翻越「付费墙」:需要登录或付费才能访问的内容,它无能为力。
- 专用工具优先:YouTube 视频、Google Docs 等有专门 API 处理的内容,它不会涉足。
- 有明确的容量限制:单次请求最多处理 20 个 URL,且单个 URL 内容上限为 34MB。
价格方面,它的计费方式非常直观:按处理的内容 Token 数量计费。你提供的 URL 内容越多,被转换成输入 Token 的数量就越多,成本也相应增加。这可能会间接引导开发者进行更高效的应用设计,即精确地提供所需的信息源,而非宽泛地投喂大量不相关的 URL,从而优化成本。
不过话说回来,URL Context Grounding 的出现并非宣告 RAG 的终结,而是对其应用场景的重新划分。对于处理企业内网的海量私有文档、需要复杂检索逻辑和极致安全性的场景,构建一套自主可控的 RAG 系统依然是不可或缺的。
URL Context 揭示了一个行业趋势:基础模型正在将越来越多的「外部能力」内置化。过去需要由应用层开发者承担的复杂数据处理工作,正在被逐步吸收到底层模型的服务中。
#Mobile-Agent-v3
性能逼近闭源最强,通义实验室开源Mobile-Agent-v3刷新10项GUI基准SOTA
覆盖桌面、移动和 Web,7B 模型超越同类开源选手,32B 模型挑战 GPT-4o 与 Claude 3.7,通义实验室全新 Mobile-Agent-v3 现已开源。
一眼看到实力:关键成绩速览。

备注:分数来源于公开基准,包括桌面 + 移动环境的任务规划、定位、推理、执行等全链路能力
,时长04:06
开源地址:https://github.com/X-PLUG/MobileAgent
背景:为什么 GUI Agent 要这么强?
GUI 智能体,就像你的跨平台虚拟操作员,能看懂屏幕、点鼠标、敲键盘、滑手机,在办公、测试、RPA 等场景自动执行任务。然而,要实现这一愿景,现有方案却面临重重挑战。它们往往能力割裂,比如精于定位 UI 元素却拙于长任务规划,或难以融入灵活的多智能体框架。
同时,许多方案严重依赖特定的硬件和操作系统,适配成本高昂;而依赖闭源模型的方案则缺乏灵活性,遇到全新任务时常常束手无策。
更现实的是,高昂的推理成本、多图输入带来的延迟以及部署困难,都成为阻碍 GUI 智能体广泛应用的瓶颈。
亮点一
GUI-Owl + Mobile-Agent-v3 + 云环境

这是一个基于云环境的全链路开源解决方案 —— 它既是当前最强的开源单体 GUI Agent 模型,也包含为其深度优化的多智能体框架。我们通过搭建覆盖 Android、Ubuntu、macOS、Windows 的多操作系统云环境基础设施,并结合阿里云的云手机与云电脑,实现了直接在云端沙箱中运行、调试、采集数据的全新范式。
在大多数 GUI Agent 方案中,采集高质量训练数据是最大的瓶颈,不仅慢,而且贵。为此,我们没有走传统的人工标注老路,而是直接打造了一整套跨平台的云环境基础设施与一套名为「自我进化 GUI 轨迹生产链路」的数据闭环系统。这套系统让 GUI-Owl 和 Mobile-Agent-v3 自己生成任务轨迹、筛选出正确轨迹,再反过来对自身进行迭代优化,将人类的参与降到最低,形成一个跨平台、自动化、可持续的数据生产与模型优化循环。

整个流程的核心是让模型在实践中自我成长。 首先,系统会在覆盖 Android、Ubuntu、macOS 和 Windows 的云端环境中动态构建虚拟实验室,确保每次任务都在贴近真实用户场景的干净快照中运行。随后,高质量的任务生成模块会为模型「出题」,它针对移动端,通过人工标注的有向无环图(DAG)来模拟真实 App 流程,并用 LLM 生成多约束的自然语言指令;而对于元素更密集的桌面端,它则结合可访问性树(Accessibility Tree)与深度搜索链来挖掘复杂软件的操作路径,确保生成的任务既真实又可控。
有了任务,GUI-Owl 模型和 Mobile-Agent-v3 框架便开始在虚拟环境中执行操作,产出完整的交互轨迹。然而,并非所有轨迹都是完美的。因此,一个精密的轨迹正确性评估模块会介入,它包含一个「Step-Level Critic」,能细致分析每一步操作前后的界面变化,判断其有效性;还有一个「Trajectory-Level Critic」,采用纯文本和多模态双通道机制,从全局视角评估整个任务是否成功。只有通过双重校验的轨迹才会被采纳。
对于那些模型反复尝试依旧失败的困难任务,系统还会启动困难任务指南生成模块。它会分析已有的成功轨迹(可能来自人工或其他模型),用 VLM 提炼出每一步的关键动作描述,并由 LLM 总结成一份「通关攻略」。这份指南将在后续尝试中作为提示,有效提高成功率。最后,所有经过筛选和强化的优质轨迹数据,都会被用于对 GUI-Owl 进行强化学习微调,让模型的能力在真实交互中稳步增强,最终实现真正的自我进化。
亮点二:全栈 GUI 能力构建
从「看得懂」到「想得全」到「做得准」
GUI-Owl 在安卓和桌面两端同时拿下 SOTA,关键在于我们为其构建了全栈式的 GUI 能力,确保它不仅「看得懂」,更能「想得全」、「做得准」,并具备天然的泛化与适配能力。
首先是极致的 UI 元素定位(Grounding)能力。 为了让模型精准找到屏幕上的目标,我们构建了涵盖功能、外观、布局等多维信息的复合型 Grounding 数据集。我们不仅融合了 InternVL、UI-Vision 等多个主流开源数据集,还创新地利用 Accessibility Tree 自动生成带有功能描述的标注数据,并辅以多模态模型补全外观和布局信息。
特别针对元素密集的 PC 界面,我们开创性地使用 SAM 对截图进行子区域分割,再让 MLLM 在小范围内进行精细定位,有效解决了定位难题。所有数据都经过严格清洗,包括与 Omniiparser V2 的检测结果进行比对筛选,并用 LLM 将生硬的指令改写得更自然,确保了训练数据的质量与真实性。

其次是深度的长任务规划(Task Planning)与动作语义理解(Action Semantics)。 为了应对复杂任务,GUI-Owl 的规划能力来自两个方面:一方面,它能从历史成功轨迹中「蒸馏」出经验,形成可复用的任务执行手册;另一方面,它也从 Qwen3-235B 这样的大规模语言模型中学习跨应用、跨功能的通用规划知识,使其面对全新场景也能从容制定计划。
更重要的是,模型通过学习海量的「操作前 / 后」截图对比,深刻理解了每个动作与界面状态变化之间的因果关系,真正做到了知其然,更知其所以然。
最后,我们为其注入了强大的稳健推理(Robust Reasoning)与泛化适配能力。 GUI-Owl 不只是机械地模仿操作,而是理解其背后的决策逻辑。我们开创性地从 Mobile-Agent-v3 多智能体框架中蒸馏推理数据,让单一模型学会从管理者、执行者、反思者等多个角色的视角进行思考,显著减少了决策盲区。
同时,结合离线提示式拒绝采样和迭代式的在线训练,模型的推理能力在真实任务中被反复打磨和验证。这种全面的训练方式,使得 GUI-Owl 不再是为某个特定框架「定制」的,而是天然具备了跨环境、跨角色的泛化能力。
实验证明,即使将其「即插即用」到从未训练过的第三方 Agent 框架中,其性能依旧远超其他专用或通用模型。

亮点三:可扩展环境强化学习(RL)
让模型「更稳、更聪明、更贴近真实使用」
仅靠离线数据还不足以让一个 GUI Agent 在真实环境中长期稳定运行,它需要真正「泡在环境里」边做边学。为此,我们专门为 GUI-Owl 设计了一套可扩展的环境级强化学习(RL)体系,旨在让模型「更稳、更聪明、更贴近真实使用」。
我们的 RL 训练基础设施在设计上兼顾了灵活性与效率。它采用统一的任务插件接口,无论是「一步到位」的短任务还是跨应用的长链路任务,都能无缝接入。其核心是将经验生成(Rollout)与策略更新完全解耦,这意味着我们可以将数据采集部署在为推理优化的硬件上以最大化吞吐量,同时在训练端保持策略更新的稳定性,从而在优化质量、速度与成本之间取得最佳平衡。

针对 GUI 自动化任务奖励信号稀疏且延迟的特性,我们引入了 Trajectory-aware Relative Policy Optimization (TRPO) 算法。该算法不再试图为每一步操作精确分配奖励,而是在整个任务完成后,对整条轨迹进行一次性评估,并根据成功、失败或格式错误给予一个明确的轨迹级奖励。这个奖励信号经过归一化处理后,会均匀地分配到该轨迹的每一个步骤上,从而有效缓解了长任务中棘手的「信用分配问题」,让模型能够从最终结果中稳定地学习。
为了进一步提升学习效率,我们还引入了 Replay Buffer 机制,它会缓存历史上成功的案例。当某一轮训练中全是失败的尝试时,系统会自动从缓存中「注入」一个成功样本,确保模型在每个批次都能学到正向反馈。这些专门的优化,使得 GUI-Owl 在在线环境中能够持续提升长任务的成功率,表现更接近真实用户所需的高稳定性。

总结
GUI-Owl 的发布,为开源社区带来了一个能力强大的原生端到端多模态 GUI 智能体。它不仅在 AndroidWorld、OSWorld 等关键基准上刷新了开源模型的记录,其 32B 版本更是在多项评测中展现了超越闭源顶级模型的实力。更重要的是,它以单一模型之身,即可胜任复杂的单体任务与多智能体协作中的不同角色,显著降低了部署和资源开销。
而 Mobile-Agent-v3 框架则是为充分释放 GUI-Owl 潜力而生的最佳拍档。它通过精巧的多智能体协作机制,进一步提升了模型的跨任务执行能力,结合云端沙箱的灵活性,使其能够快速适应并解决各类新场景下的自动化难题。
一句话总结:开源,Mobile-Agent-v3 也能跑在最前面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)