一篇文章带你了解大模型的本地化实施与优化(Linux + ollama + qwen:7b + maxkb)
不同的用户或企业可能有特定的业务需求和应用场景,本地大模型允许用户根据自己的需求对模型进行定制训练。例如,企业可以使用自己的业务数据对模型进行微调,使其更适应特定的业务任务,如特定领域的知识问答、文本生成等。
·
目录
1 什么是AI

AI ( Artificial Intelligence)即人工搭建起来的智能黑箱,是让机器模仿人类的思维、学习和决策能力,从而完成原本需要人类智能才能做的事的技术。
1.1 什么是智能
智能就是通过收集到的信息对不同的情境针对性的做出反应

根据不同的图像识别出不同的人是人工智能。
根据不同的图像识别出来的都是张三是人工智障。
智能就是找到情景信息输入和我们想要的聪明的行为输出之间的函数队形关系。
2 AI的起源

1956 年 8 月,在美国汉诺斯小镇宁静的达特茅斯学院中,约翰 · 麦卡锡( John McCarthy :达特茅斯数学系教授)、马文· 闵斯基( Marvin Minsky ,哈佛大学人工智能与认知学专家)、克劳德 · 香农( ClaudeShannon,信息论的创始人)、艾伦 · 纽厄尔( Allen Newell ,计算机科学家)、赫伯特 · 西蒙( HerbertSimon,诺贝尔经济学奖得主)等科学家正聚在一起,讨论的主题:用机器来模仿人类学习以及其他方面的智能。
会议足足开了两个月的时间,虽然大家没有达成普遍的共识,但是却为会议讨论的内容起了一个名字:人工智能。因此,1956 年也就成为了人工智能元年。
3 为何要搭建本地大模型
数据隐私安全:
- 当使用云端的大模型服务时,数据需要上传至云端服务器进行处理,这可能会带来数据隐私泄露的风险。
- 搭建本地大模型,数据仅在本地环境中流转和处理,企业或个人可以更好地掌控数据的访问权限,防止敏感信息泄露,满足对数据隐私和安全有严格要求的场景,如医疗、金融等行业。
定制化与可控性:
- 不同的用户或企业可能有特定的业务需求和应用场景,本地大模型允许用户根据自己的需求对模型进行定制训练。例如,企业可以使用自己的业务数据对模型进行微调,使其更适应特定的业务任务,如特定领域的知识问答、文本生成等。
- 同时,用户可以完全控制模型的版本、参数设置和更新策略,根据实际需求进行灵活调整。
更低的运行成本:
- 对于一些需要频繁使用大模型的场景,使用云端大模型服务可能会产生较高的费用,特别是在处理大规模数据或高并发请求时。
- 搭建本地大模型,虽然初期可能需要投入一定的硬件和软件成本,但从长期来看,如果使用量较大,本地部署可以降低每次调用的成本,具有更好的成本效益。
高效的响应速度:
- 在云端使用大模型时,数据的上传和下载会存在一定的网络延迟,尤其是在网络不稳定的情况下,可能会影响模型的响应速度。
- 而本地大模型由于数据和计算都在本地进行,无需依赖网络传输,能够实现快速的响应,适用于对实时性要求较高的应用,如实时对话系统、工业控制中的实时决策等。
断网可用:
- 本地大模型在搭建完成后,即使处于断网环境也能正常运行。这对于一些特殊场景非常重要,如偏远地区的野外作业、军事行动等,在没有网络连接的情况下,依然可以利用本地大模型进行数据处理和分析。
研究和学习需求:
- 对于研究人员和开发者来说,搭建本地大模型可以深入了解模型的内部机制和运行原理,便于进行模型的优化和创新研究。通过在本地环境中对模型进行实验和调试,可以更好地探索新的算法和技术,推动人工智能技术的发展。
4 基于Ollama的本地大模型管理
4.1 什么是Ollama

Ollama 是一个致力于简化和优化机器学习模型使用的开源平台。
它的目标是让开发者和数据科学家能够更轻松地使用和部署大型语言模型( LLM ),并提供了一系
列工具和框架,以支持模型的加载、管理和运行。
4.2 Ollama的功能特点
- 简化模型管理:Ollama 提供了一个简单的命令行界面,允许用户快速下载和运行各种预训练的语言模型。用户可以通过简单的命令来管理模型的版本和配置。
- 本地运行:Ollama 支持在本地计算机上运行模型,避免了将数据上传到云端的需求。这对于保护隐私和数据安全尤为重要。
- 支持多种模型:Ollama 可以支持多种不同的模型架构和框架,包括 OpenAI 的 GPT 系列、Google的 BERT 等。用户可以根据需求选择适合的模型。
- 易于集成:Ollama 的设计使其易于与现有的开发工具和工作流程集成。它可以与 Python、
- JavaScript 等编程语言一起使用,方便开发者将其嵌入到应用程序中。
- 社区支持:作为一个开源项目,Ollama 拥有活跃的社区支持,用户可以参与开发、报告问题和贡献代码。
- 灵活性和扩展性:Ollama 提供了灵活的 API 接口,用户可以根据特定需求进行扩展和定制。
4.3 Ollama的应用场景广泛,包括但不限于
- 聊天机器人:利用Ollama部署的LLM可以构建智能聊天机器人,为用户提供自然流畅的对话体验。
- 文本生成:Ollama可以生成各种文本内容,如新闻文章、博客文章、诗歌等,满足内容创作的需求。
- 问答系统:构建基于LLM的问答系统,快速准确地回答用户的问题。
- 代码生成:生成代码片段,如Python、JavaScript等,辅助软件开发和测试工作。
4.4 构建Ollama
Ollama 官网: https://www.ollama.com/
访问前建议开启代理
Ollama 中大模型支持:
Ollama 管理平台对大模型的支持是非常广泛的,有的开源大模型上线不到 24 小时即可在支持列表中找到
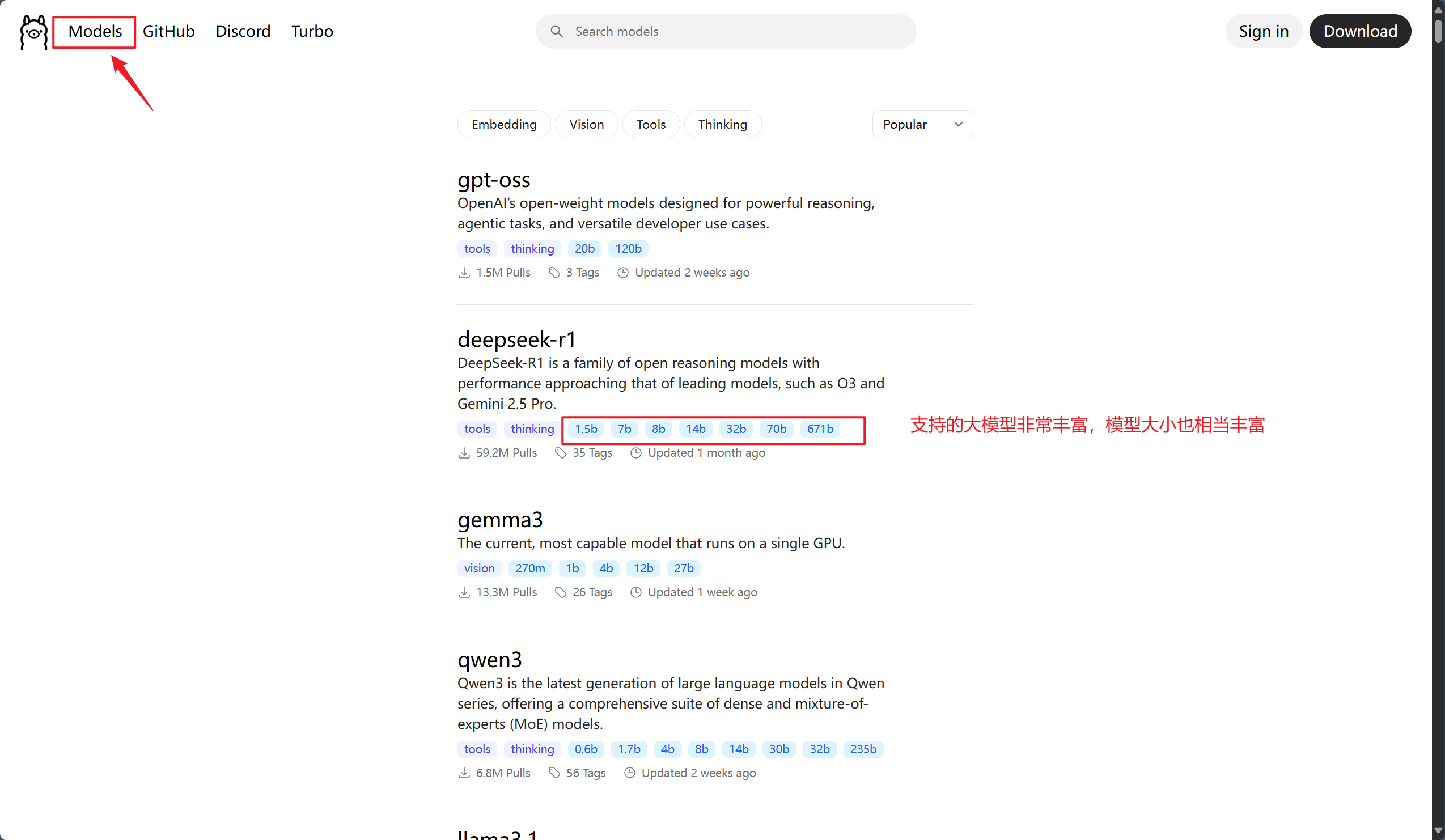
- 这里的几b几b表示的是模型中的参数个数是多少个10亿
- b表示10亿,1.5b就是15亿个参数
- 如果你的GPU的显存是8G及以上的可以选择14b~32b的模型,否则推荐7b一下的模型
4.4.1 Ollama的部署过程如下
部署Ollama到Linux系统中
| 主机名 | IP | 硬件配置 |
| ollama-server | 192.168.36.10/24 | 内存8-16G,CUP8核 |
ollama 下载地址: https://github.com/ollama/ollama/releases
1.通过官方脚本方式部署
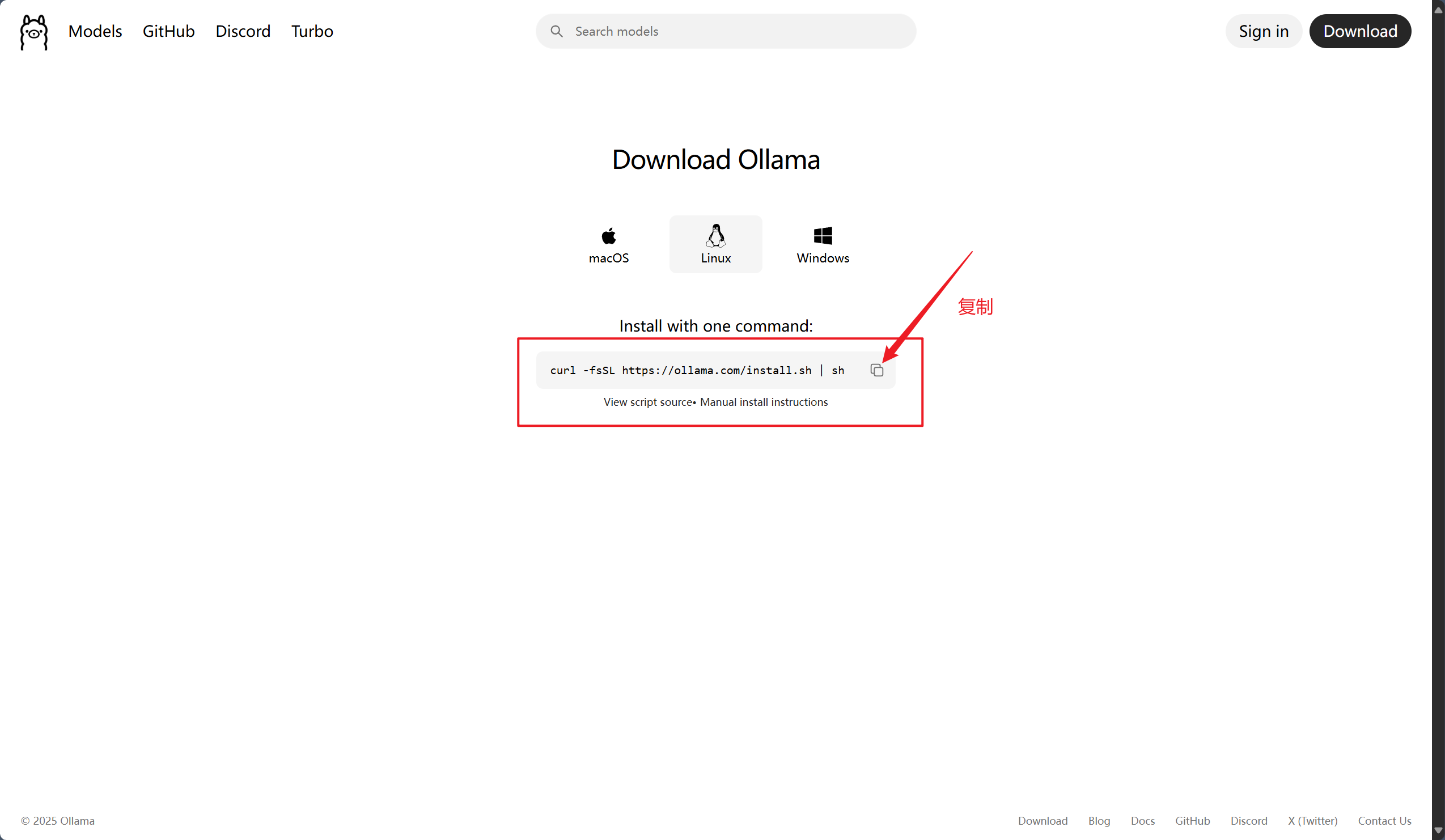
2.部署命令如下
# wget https://ollama.com/install.sh | sh
# sh install.sh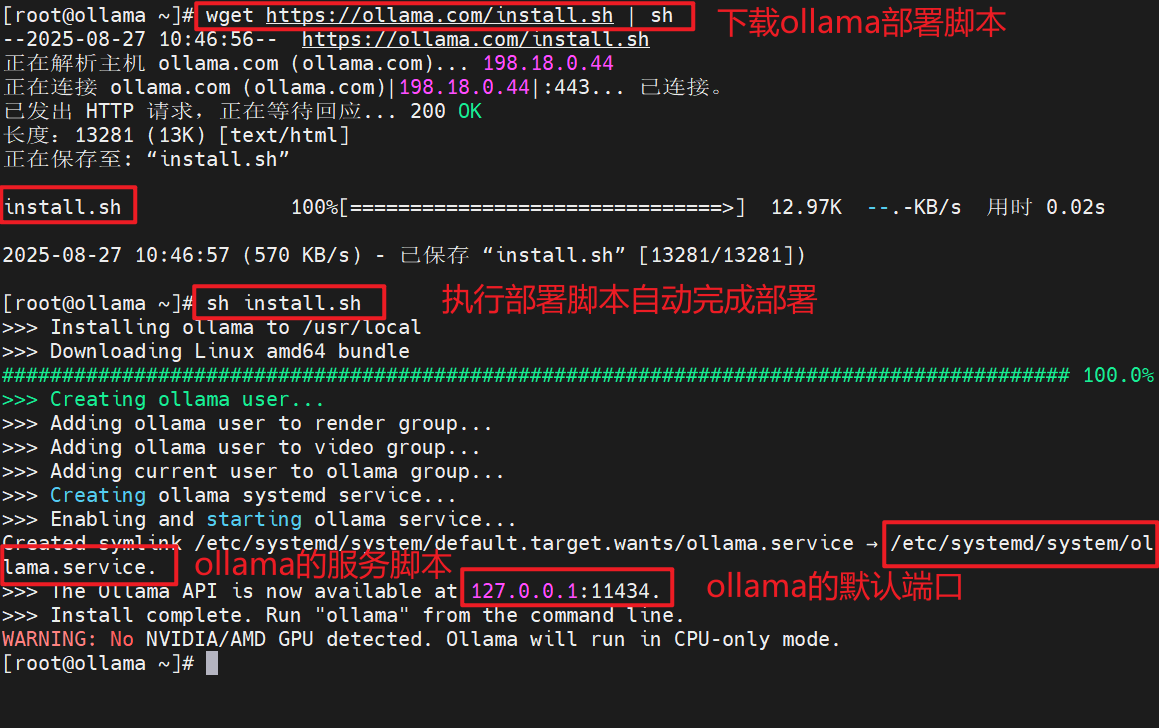
3.通过压缩包部署
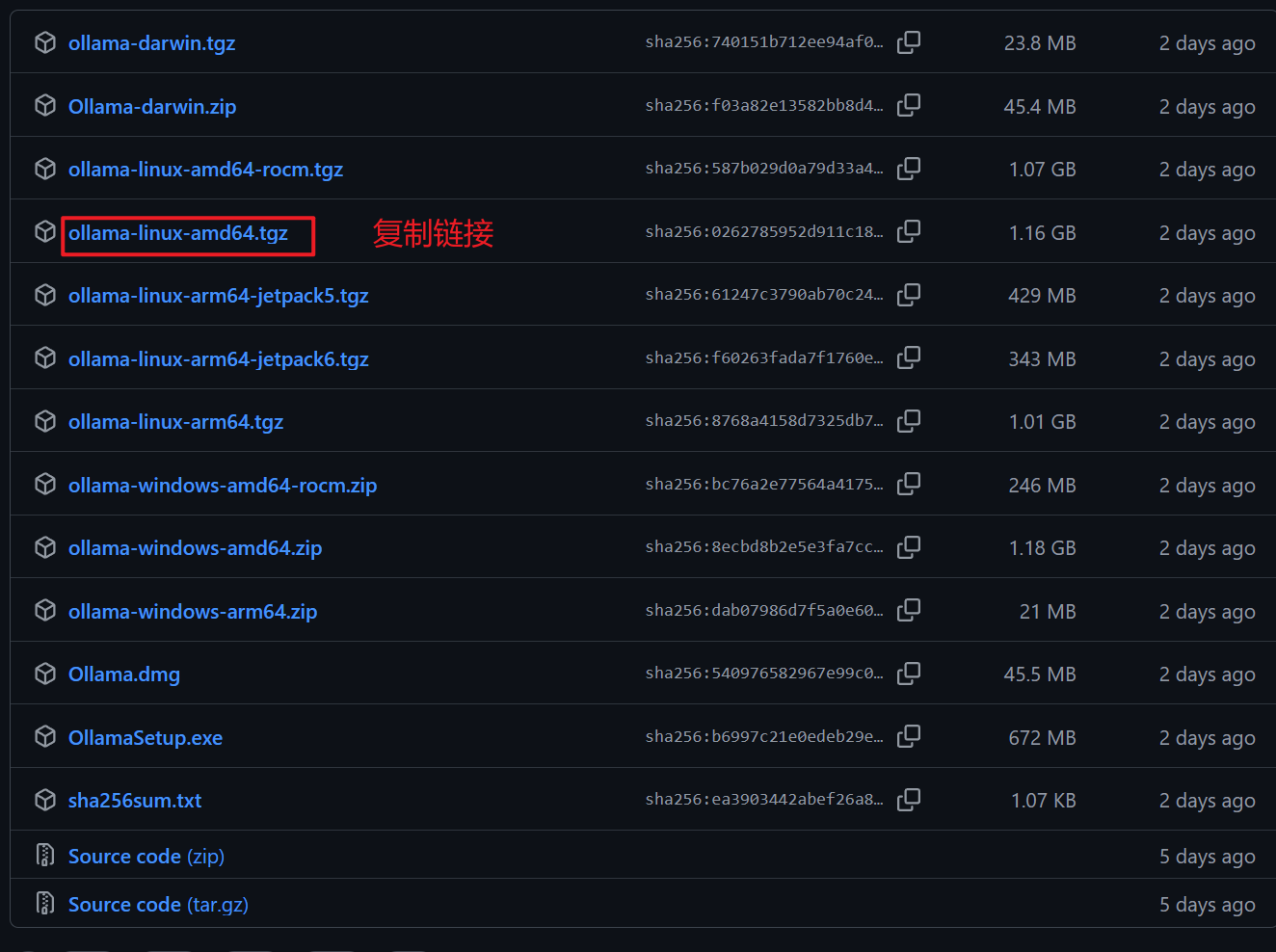
在 github 中提供了 ollama 的离线包
# wget https://github.com/ollama/ollama/releases/download/v0.11.7/ollama-linux-amd64.tgz
# mkdir ollama
# tar zxf ollama-linux-amd64.tgz -C ollama/
# cd ollama/
# ./ollama
# bin/ollama
注意:用压缩包的方式安装是绿色安装方式,这种安装方式安装后一些启动脚本需要自己手动编写。方便程度比脚本方式差很多。所以推荐使用脚本方式安装。
4.4.2 Ollama的调试与使用方法
4.4.2.1 Ollama常用环境变量简介
| 变量名称 | 变量功能 | 使用实例 |
| ollama_host |
服务监听接口 : 端口
(默认接口为本地
回环,默认端口为
11434 )
|
OLLAMAHOST=0.0.0.0:9090
|
| ollama_models |
设定模型默认下载
后保存路径
|
OLLAMAMODELS=/data/ollama/models
|
| ollama_keep_alive |
设置模型加载到内
存中保持时间(默
认情况下,模型在
卸载之前会在内存
中保留 5 分钟)
|
OLLAMAKEEPALIVE=24h
|
| ollama_num_parallel |
设定用户并发请求
数量
|
OLLAMANUMPARALLEL=2
|
| ollama_max_loaded_models | 设定同时加载模型数量 |
OLLAMA_MAX_LOADED_MODELS=2
|
4.4.2.2 ollama中的变量大全
OLLAMA_DEBUG # 是否开启调试模式(开启后输出详细运行日志,用于问题排查),默认为 false
OLLAMA_FLASH_ATTENTION # 是否启用 Flash Attention 优化(提升大模型注意力计算效率的技术),默认为 true
OLLAMA_HOST # Ollama 服务器的主机地址(如配置0.0.0.0:11434可允许外部设备访问),默认为空(默认仅本地访问)
OLLAMA_KEEP_ALIVE # 连接保持时间(超过时间自动释放空闲连接,避免资源占用),默认为 5m
OLLAMA_LLM_LIBRARY # 自定义 LLM(大语言模型)核心库路径(用于特殊模型适配场景),默认为空(使用默认库)
OLLAMA_MAX_LOADED_MODELS # 同时加载到内存的最大模型数量(避免内存不足),默认为 1
OLLAMA_MAX_QUEUE # 模型请求队列的最大长度(防止大量请求堆积导致服务卡顿),默认为空(无默认限制)
OLLAMA_MAX_VRAM # Ollama 可使用的最大虚拟内存容量(如配置8GB避免显存溢出),默认为空(使用全部可用显存)
OLLAMA_MODELS # 自定义模型存储目录(默认模型存于~/.ollama/models等系统默认路径),默认为空(使用默认目录)
OLLAMA_NOHISTORY # 是否禁用对话历史记录(开启后不保存过往对话,保护隐私),默认为 false
OLLAMA_NOPRUNE # 是否禁用模型剪枝(禁用后保留冗余模型文件,可能增加磁盘 / 显存占用),默认为 false
OLLAMA_NUM_PARALLEL # 模型推理时的并行任务数(影响推理速度,需根据硬件性能调整),默认为 1
OLLAMA_ORIGINS # 允许跨域访问的来源(如配置http://localhost:3000用于前端页面调用),默认为空(默认禁止跨域)
OLLAMA_RUNNERS_DIR # 模型运行器(负责模型加载 / 推理的组件)的自定义目录,默认为空(使用默认目录)
OLLAMA_SCHED_SPREAD # 多模型加载时的资源调度策略(平衡不同模型的显存 / CPU 占用),默认为空(使用默认调度)
OLLAMA_TMPDIR # Ollama 临时文件(模型下载缓存、推理中间文件等)的存储目录,默认为空(使用系统默认临时目录,如/tmp)4.4.2.3 设置Ollama的环境变量
1. 通过 vim/etc/systemd/system/ollama.service ,打开编辑
2. 对于每个环境变量,在 [Service] 部分下添加一行 Environment
# vim/etc/systemd/system/ollama.service
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
Environment="OLLAMA_DEBUG=1"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_MODELS=/mnt/data/.ollama/models"
Environment="OLLAMA_KEEP_ALIVE=24h"
Environment="OLLAMA_NUM_PARALLEL=2"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
# mkdir -p /mnt/data/.ollama/models
# chown -R ollama:ollama /mnt/data/.ollama/models
# chmod -R 755 /mnt/data/.ollama/models
# systemctl daemon-reload
# systemctl restart ollama
# systemctl enable ollama.service
# 对于每个环境变量,在[Service]部分下添加一行Environment.
# OLLAMA_HOST=0.0.0.0 # 外网访问
# OLLAMA_MODELS=/mnt/data/.ollama/models # 模型默认下载路径
# OLLAMA_KEEP_ALIVE=24h # 设置模型加载到内存中保持24个小时(默认情况下,模型在卸载之前会在内存中保留5分钟)
# OLLAMA_HOST=0.0.0.0:8080 # 修改默认端口11434端口
# OLLAMA_NUM_PARALLEL=2 # 设置2个用户并发请求
# OLLAMA_MAX_LOADED_MODELS=2 # 设置同时加载多个模型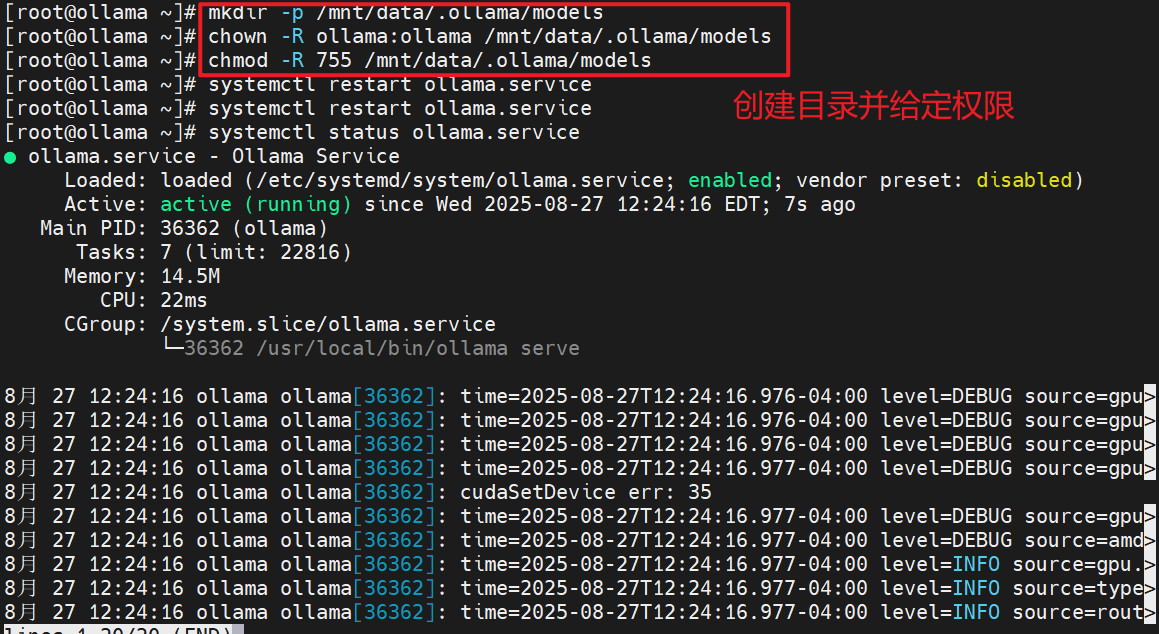
默认情况下,ollama模型的存储目录如下:
# macOS:`/.ollama/models`
# Linux:`/usr/share/ollama/.ollama/models`
# Windows:`C:\Users\<username>\.ollama\models`
# journalctl-uollama|grep-i'prompt=' # 查看日志
# /set verbose # 设置以查看token速度4.4.2.4 Ollama使用常见的指令
# ollama serve # 启动ollama
# ollama create # 从模型文件创建模型
# ollama show # 显示模型信息
# ollama run # 运行模型
# ollama pull # 从注册表中拉取模型
# ollama push # 将模型推送到注册表
# ollama list # 列出模型
# ollama cp # 复制模型
# ollama rm # 删除模型
# ollama help # 获取有关任何命令的帮助信息4.4.2.5 Ollama中模型的管理
1.安装完毕 Ollama 后,默认是没有本地大模型的。可以通过 Ollama pull 来下载模型到本地
# ollama pull qwen:7b
# 模型:参数数量
# qwen:7b表示qwen模型的7b版本。7b就是10亿个参数等待下载完成

2.模型下载完毕后可以通过 Ollama list 来查看
# ollama list3.运行模型并提问
# ollama run qwen:7b # 此时就可以用本地大模型了
>>> /bye # 退出模型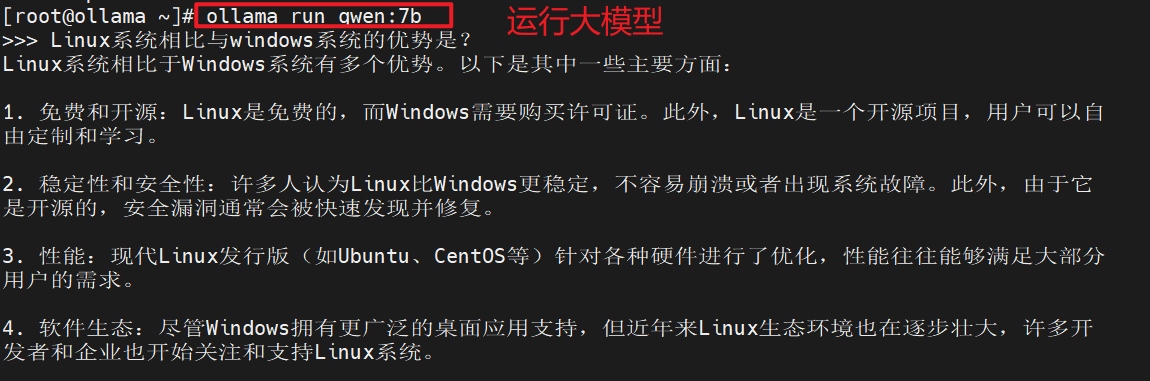
4.复制模型
# ollama cp qwen:7b my-qwen:7b
# ollama list

5.导出现有模型
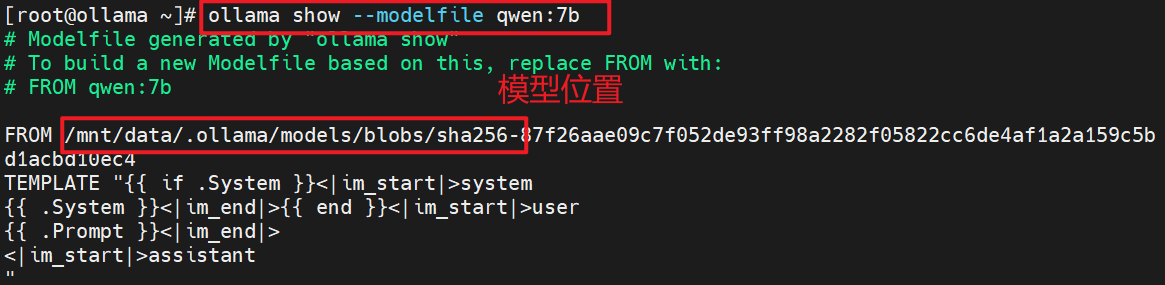
# 查看模型位置
# ollama show --modelfile qwen:7b
# 复制模型到指定目录
# cp /mnt/data/.ollama/models/blobs/sha256-87f26aae09c7f052de93ff98a2282f05822cc6de4af1a2a159c5bd1acbd10ec4 /mnt/qwen_7b.guuf

6.利用GUUF文件加载模型
# vim myqwen\:7b
FROM /mnt/qwen_7b.guuf
# ollama create test-qwen:7b -f myqwen\:7b
# ollama list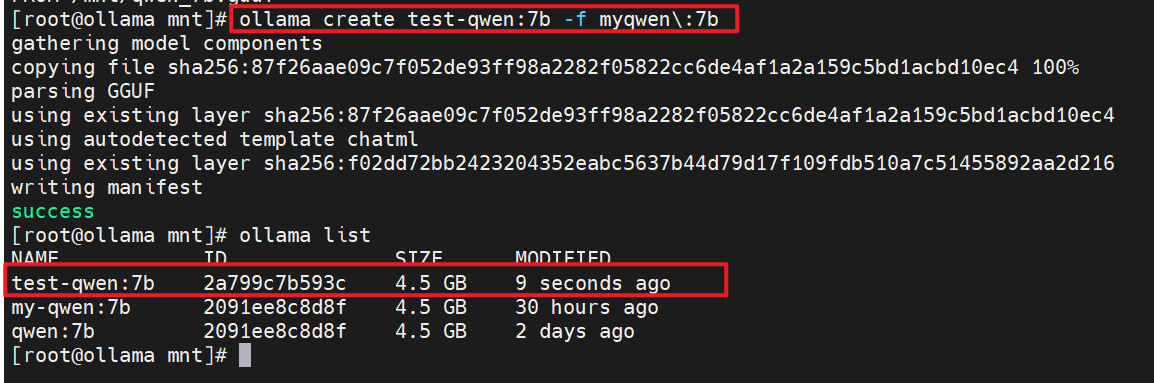
7.huggingface模型镜像站
最新版 Ollama 开始支持从 Huggingface Hub 上直接拉取各种模型,包括社区创建的 GGUF 量化模型
国内可用镜像站地址: https://hf-mirror.com/
# ollama run hf.co/{username}/{repository}
# 要选择不同的量化方案,只需在命令中添加一个标签:
# ollama run hf.co/{username}/{repository}:{quantization}
# 例如:量化名称不区分大小写
# ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:IQ3_M
# ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0
# 还可以直接使用完整的文件名作为标签:
# ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Llama-3.2-3B-Instruct-IQ3_M.gguf8.Ollama的卸载方法
Ollama 通常不是用 rpm 的方式进行安装的,所以卸载过程中只需要吧相关文件删除即可
# systemctl stop ollama.service
# systemctl disable ollama.service
# rm -fr /etc/systemd/system/ollama.service
# rm -fr /usr/local/bin/ollama
# rm -fr /usr/share/ollama/
# userdel -r ollama
# groupdel ollama5 构建本地知识库
5.1 本地知识库的必要性
在日益激烈的商业竞争中,知识与信息的管理愈发变得重要。知识管理不再只是企业内部的事,而在开源和协作的互联网时代,它已经成为了企业可持续性发展的关键因素之一。那么,为什么企业需要搭建本地知识库呢?接下来我们一起探讨其背后的原因。
开启知识共享,提升效率:
企业内部往往存在各种各样的知识资源,比如客户信息、项目管理、产品发布等。这些知识如果没有得到充分的共享和传递,就会形成所谓的“ 信息孤岛 ” ,对企业内部沟通造成阻碍,甚至妨碍了企业的发展。
而建立了本地知识库,就能够打通信息流通的渠道,让知识信息得以在企业内部自由流动,从而提高工作效率。
知识积累,构建企业核心竞争力:
每一个企业在其成长历程中,都会积累着大量的知识资源,比如研发经验、市场策略、管理方法等。这些知识资源的积累会形成企业的核心竞争力,它是没有办法被模仿和替代的。这就需要企业建立本地知识库,对这些资源进行集中存储和管理,使得随着时间的推移,企业的核心竞争力可以得到逐步积累和提升。
强化信息保密,保障企业安全:
虽然互联网的发展让信息共享变得更加便捷,但是也给企业的信息安全带来了威胁。尤其在一个企业内部,一些重要信息,如果没有得到良好的管理和保护,可能就会遭到泄露和滥用。因此,建立本地知识库,不能只是看中其知识共享的功能,更应该注重其在信息保密方面的作用。对于敏感信息,企业应当实行严格的访问权限控制,保证只有被授权的人才能够访问。
保证业务连续性,确保数据备份:
如果企业的知识库只存储在网络上,那么一旦网络出现故障,或者服务器宕机,会给企业的运营带来极大的困扰。而在本地搭建知识库,就可以保证在出现此类情况时,企业依然可以访问到核心信息。同时,本地知识库为数据备份提供了一个便捷的方案,使得企业能够应对可能的数据丢失情况。
5.2 本地知识库的构建
制定明确的策略:
首先,你需要制定一个明确的策略,要知道你要收集哪些信息,如何收集,如何分类和更新。这样才能确保知识库的有效性和实用性。
选择合适的知识库软件:
在开发团队的精力有限的情况下,选择合适的知识库软件是成功建立知识库的关键一步。完全定制的知识库软件灵活度高,但成本和周期过重;而开源知识库软件则以较低成本提供了高度开放的选择,推荐使用如MaxKB 这类开源知识库。
5.3 利用MaxKB构建本地知识库
5.3.1 MaxKB简介

MaxKB ( Max Knowledge Base ):是一款基于大语言模型和 RAG 的开源知识库问答系统,广泛应用于智能客服、企业内部知识库、学术研究与教育等场景。
官网: https://www.fit2cloud.com/maxkb/index.html
功能特色:
- 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好。
- 无缝嵌入:支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力。
- 模型中立:支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 腾讯混元 / 字节豆包 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI /Gemini 等)。
- 灵活编排:内置工作流引擎和函数库,支持编排 AI 工作过程,满足复杂业务场景下的需求
MaxKB实现原理:
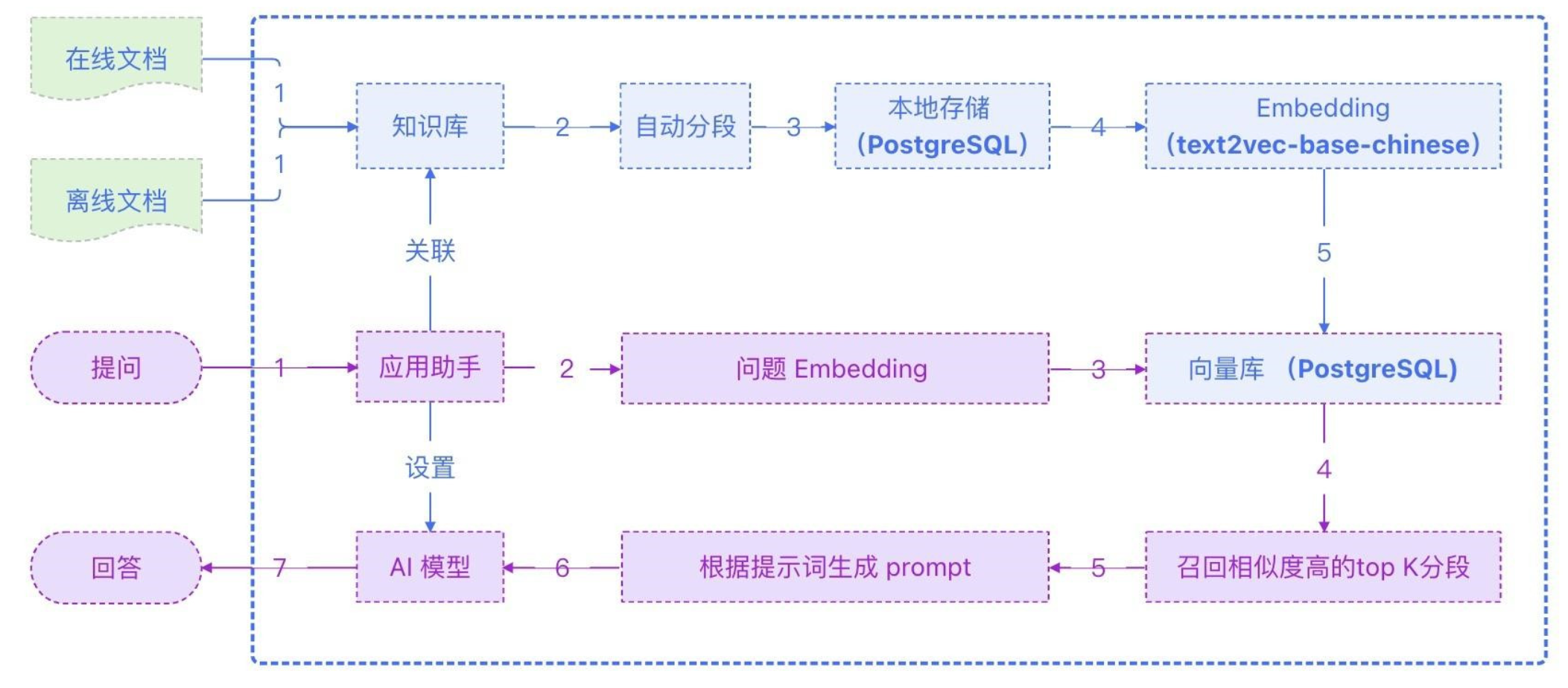
本地知识库生成过程:
- 上传文档
- 文本拆分
- 本地存储分段
- 分段文本向量化
- 存入本地向量库
提问原理:
- 用户发起问题
- 将问题向量化
- 查抄应用关联知识库
- 召回相似度较高的top k分段
- 生成promtp
- 提交AI模型生成回答
5.4 部署MaxKB
axKB 需要在 Docker 中运行,因此需要安装 docker
5.4.1 安装docker
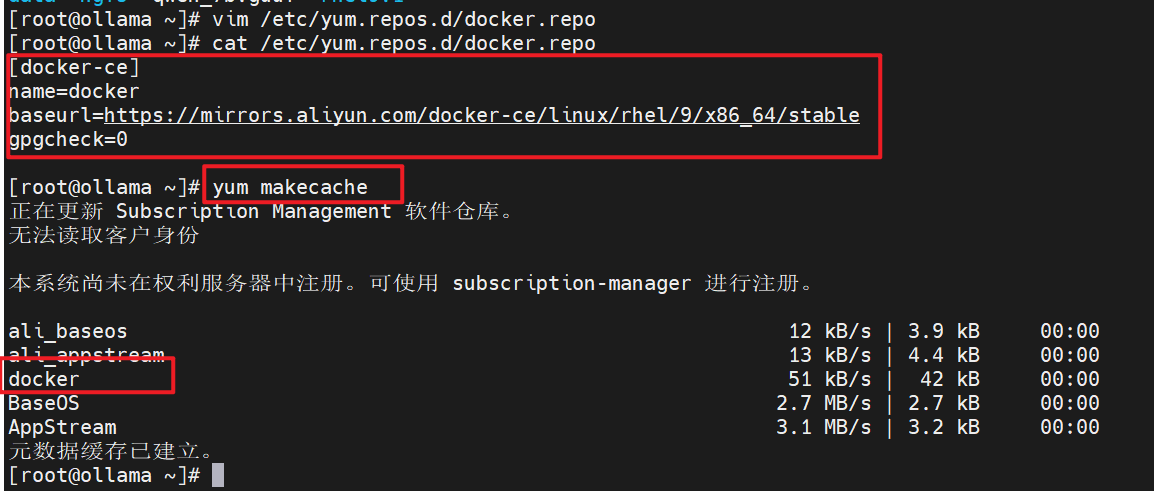
# 部署软件仓库的yum源
# vim /etc/yum.repos.d/docker.repo
[docker-ce]
name=docker
baseurl=https://mirrors.aliyun.com/docker-ce/linux/rhel/9/x86_64/stable
gpgcheck=0
# 安装docker
# yum install -y docker-ce docker-ce-cli containerd.io
# docker开机自启
# systemctl enable --now docker.service
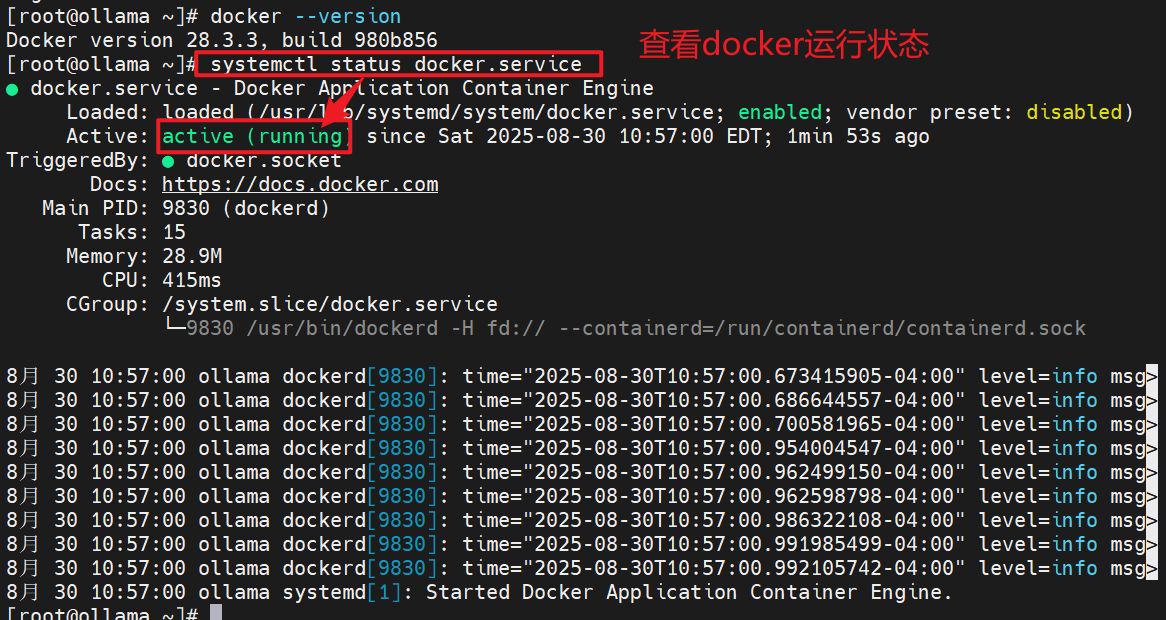
# 查看docker运行状态
# systemctl status docker.service


5.4.2 下载MaxKB运行镜像
# docker pull registry.fit2cloud.com/maxkb/maxkb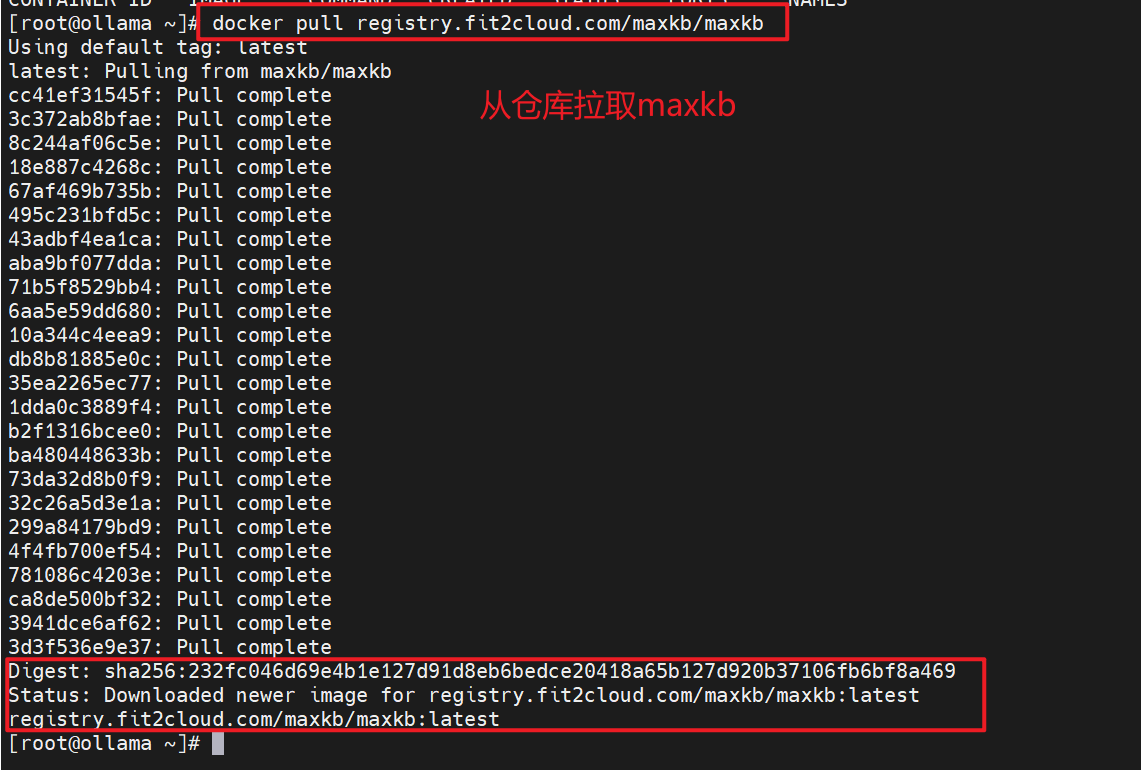
5.4.3 建立持久目录
# mkdir /MaxKB/postgresql/data /MaxKB/python-packages -p5.4.4 运行MaxKB
# docker run -d --name=maxkb --restart=always -p 8080:8080 -v /MaxKB/postgresql/data:/var/lib/postgresql/data -v /MaxKB/python-packages:/opt/maxkb/app/sandbox/python-packages registry.fit2cloud.com/maxkb/maxkb:latest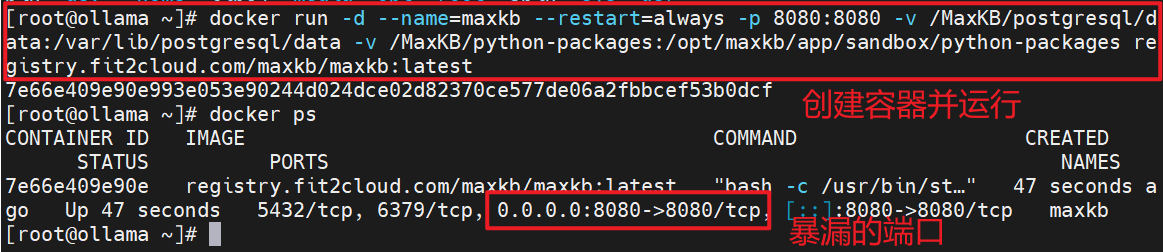
5.4.5 访问MaxKB后台页面
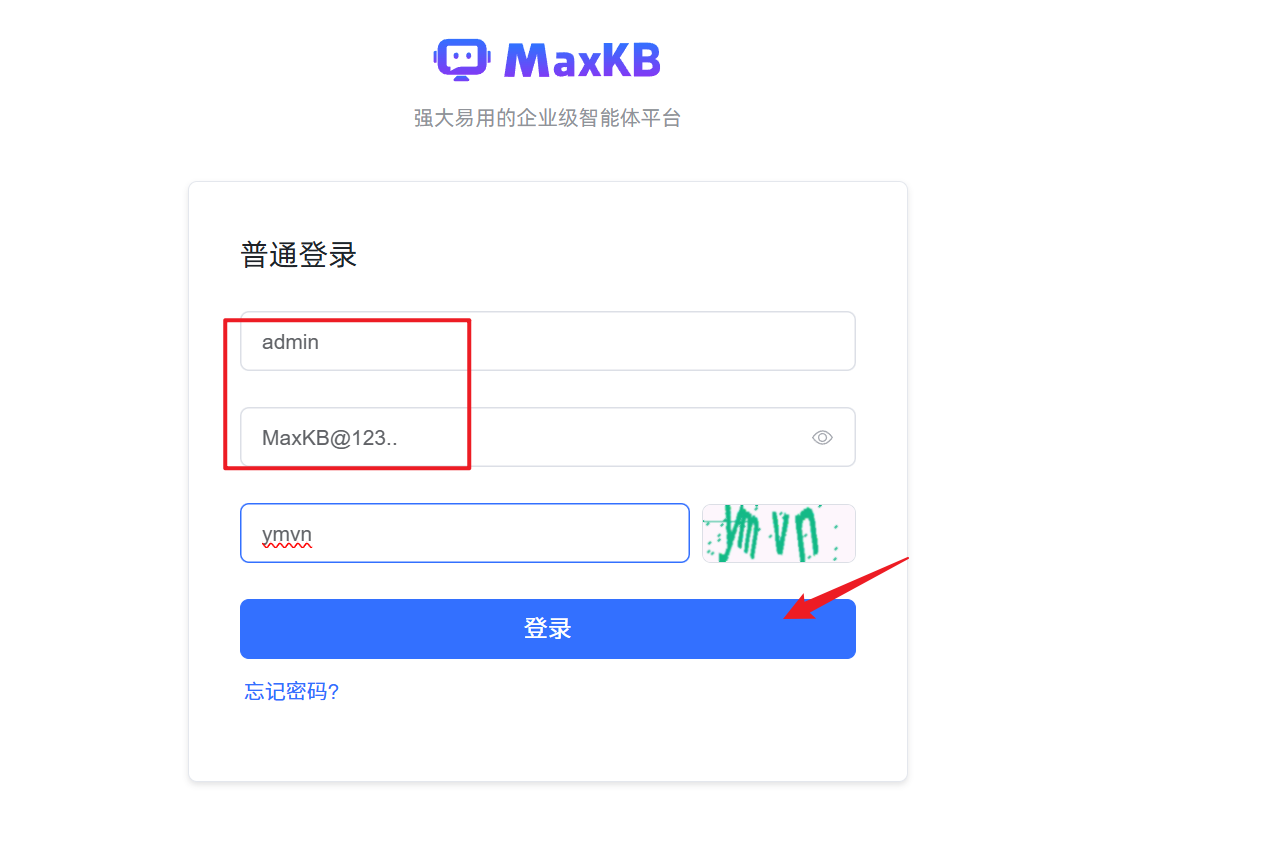
- 访问地址:http://目标服务器 IP 地址:8080
- 默认登录信息如下:
- 用户名:admin
- 默认密码:MaxKB@123..
5.4.6 MaxKB的配置与调试
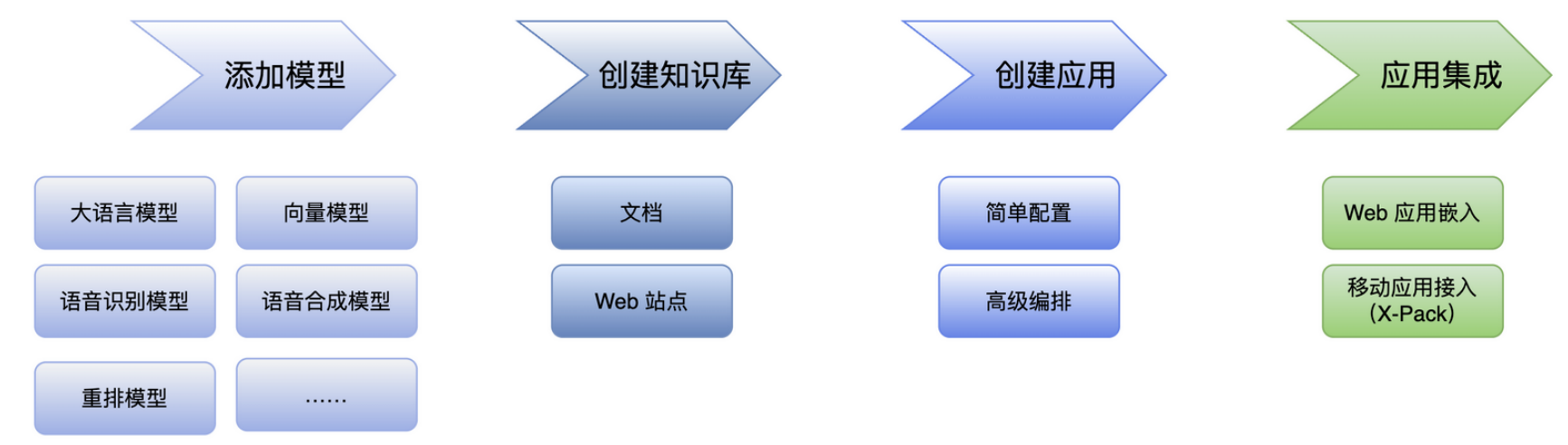
MaxKB 的使用操作流程一般可分为四步:添加模型、创建知识库、创建应用、发布应用。
在高级编排应用中还可以通过函数库的功能,实现数据处理、逻辑判断、信息提取等功能,提供更加强大、灵活的能力
本地模型管理:
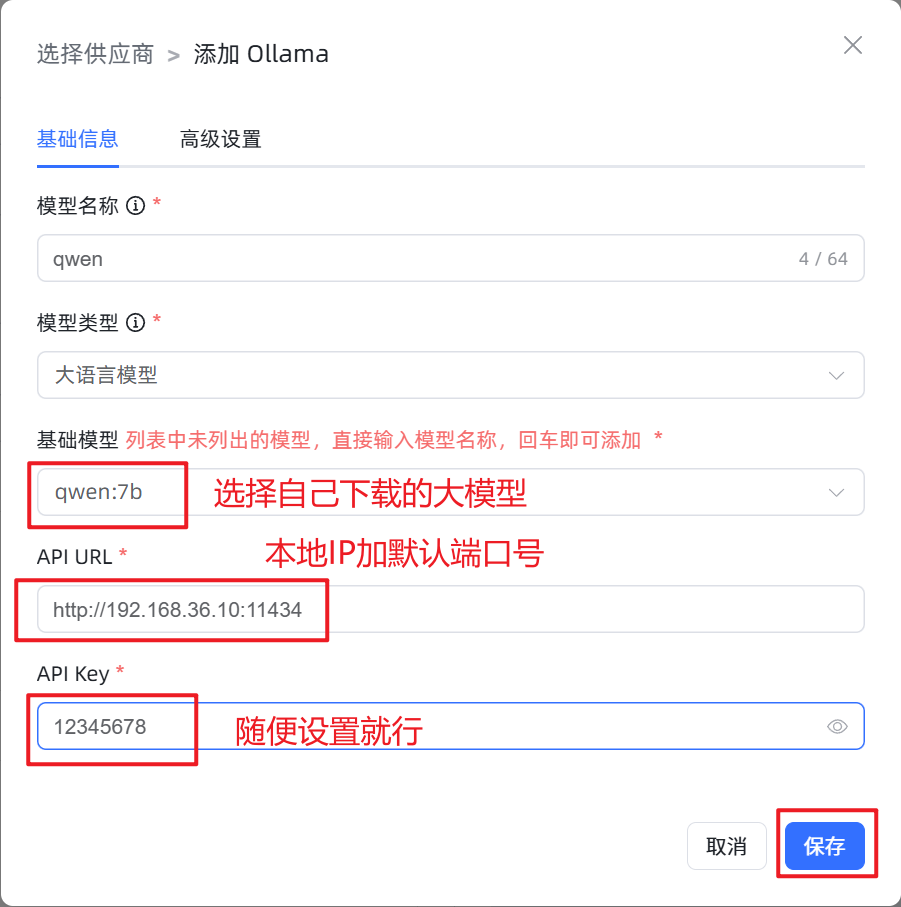
MaxKB 支持在线大模型和本地大模型,用 ollama 管理的大模型可以直接在 MaxKB 中添加应用添加步骤如下:
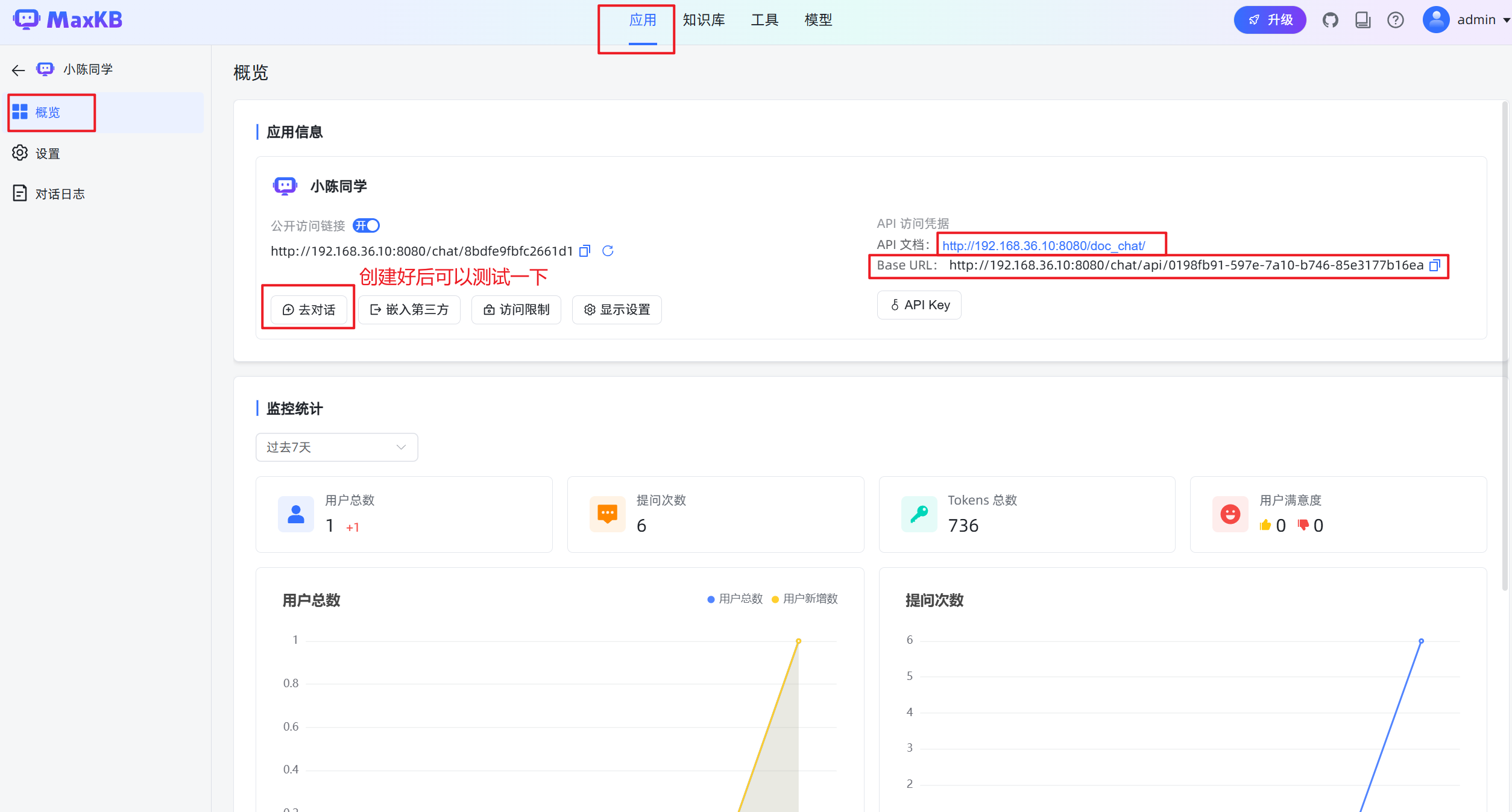
1.创建应用
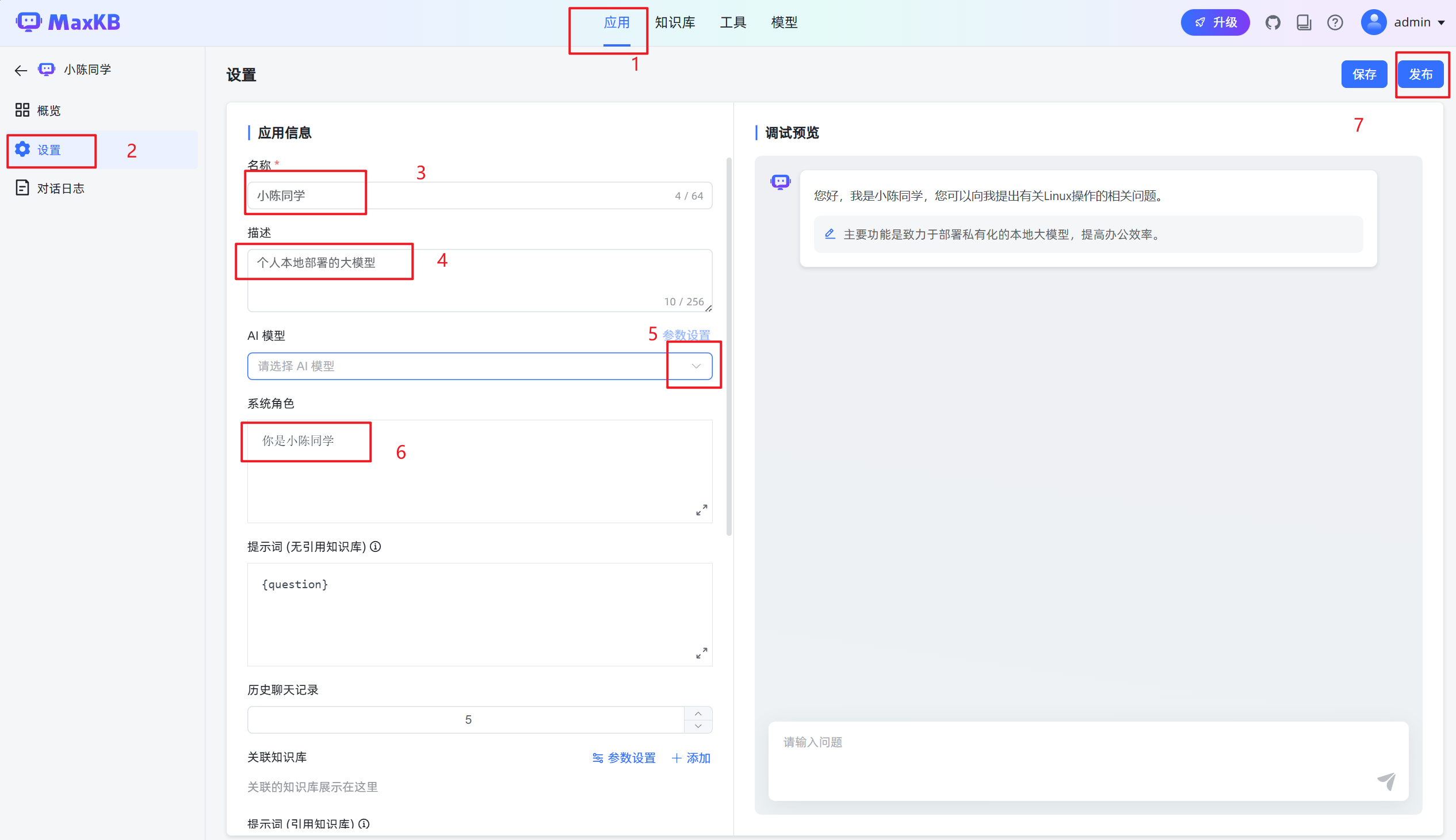
2.发布创建的应用
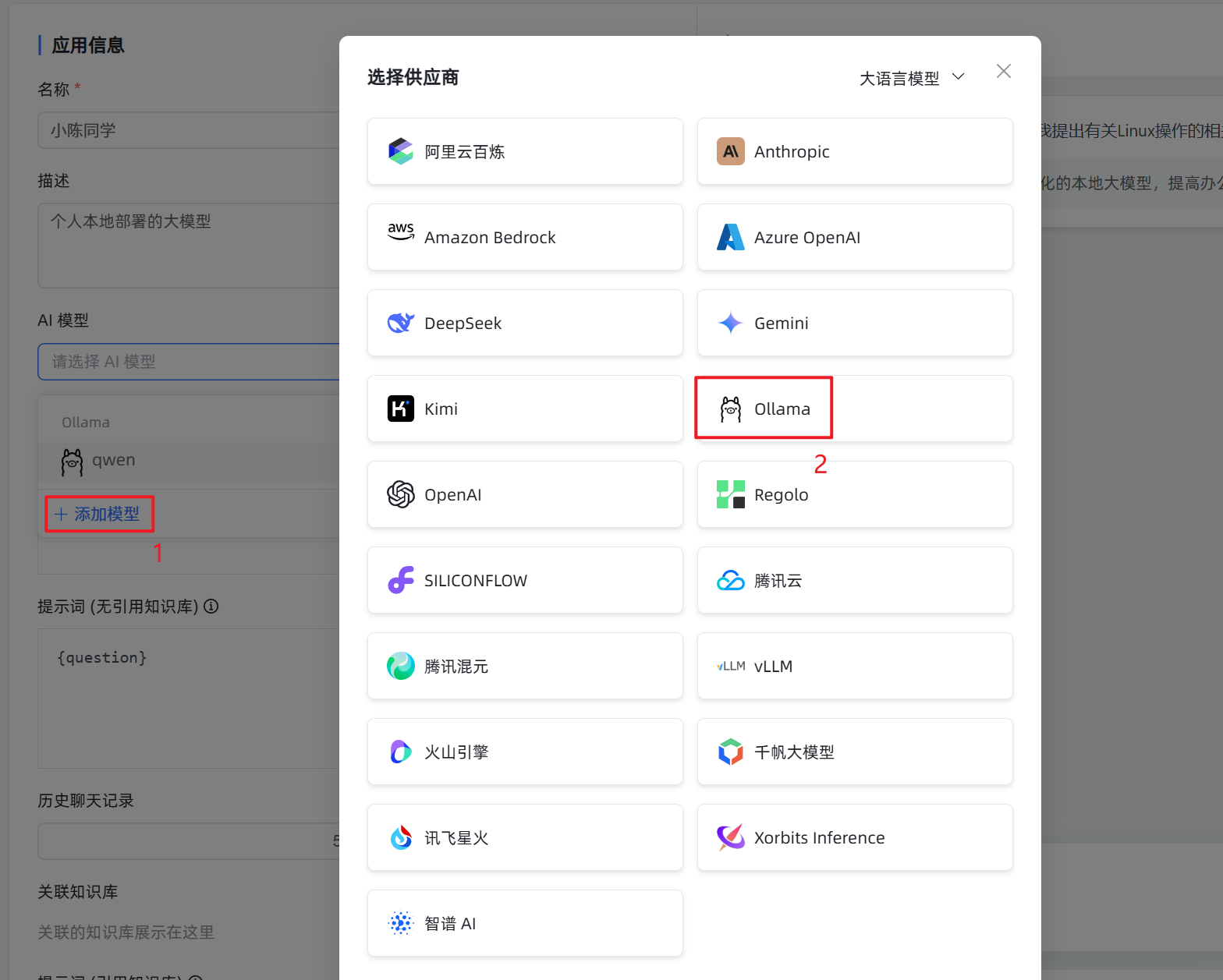
查看ollama端口

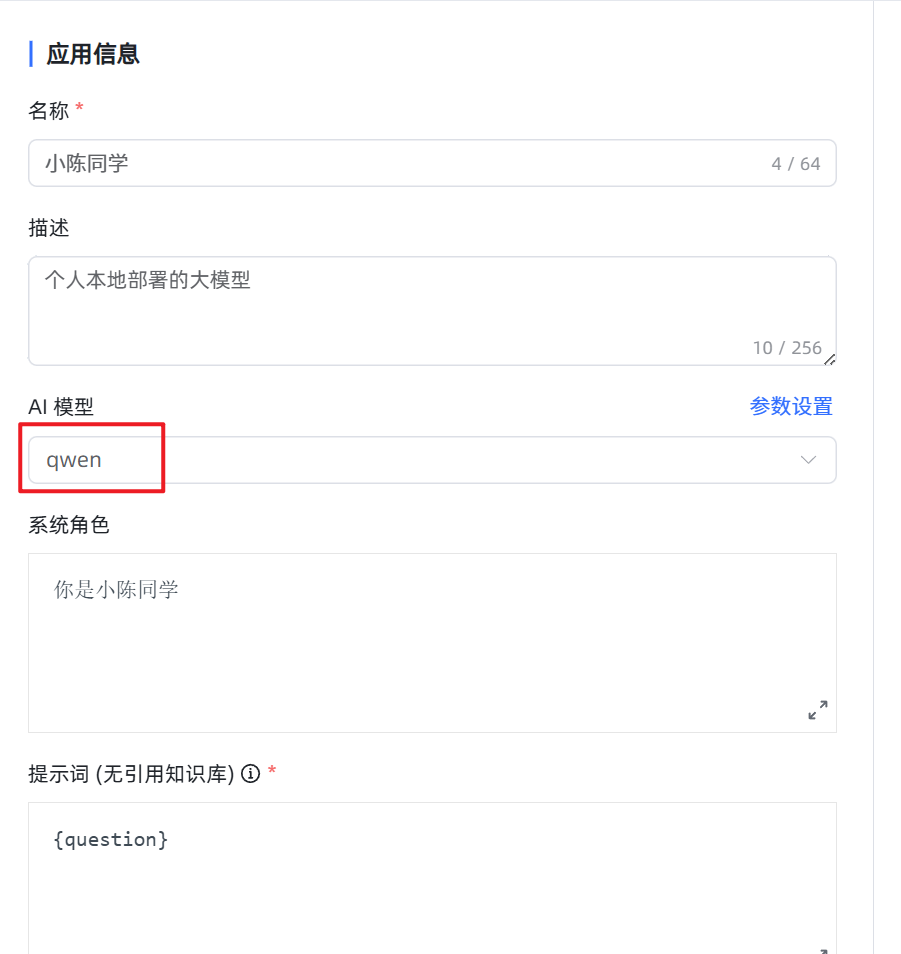
节点设置:
- AI 模型:大语言模型的名称以及参数控制。
- 角色设定:大语言模型回答的角色或身份设定。
- 提示词:引导模型生成特定输出的详细描述。
- 历史聊天记录:在当前对话中有关联的历史会话内容。例如,历史聊天记录为1,表示当前问题以及上一次的对话内容一起输送给大模型。
- 返回内容:是否在对话中显示该节点返回的内容。
参数输出:
- AI回答内容 {answer}:根据角色、提示词等内容大语言模型返回的内容。
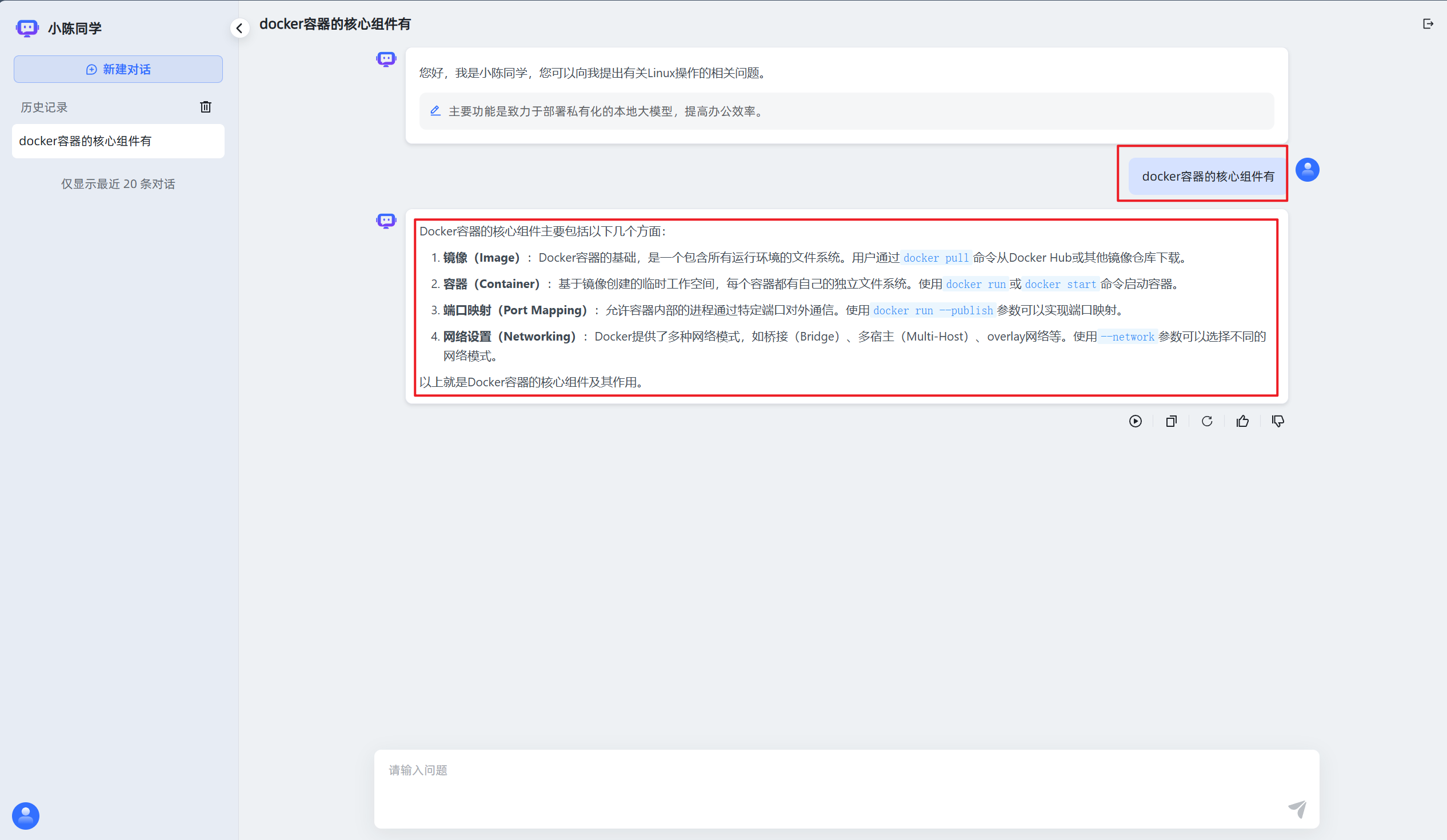
3.测试效果
5.5 训练本地知识库,建立企业定制AI
我们以日常使用共有大模型为例,大家不难发现,在大多数 AI 中我们把遇到的问题提出,公有 AI 为我们提供的答案相对全面,但是不具体,换句话说,AI 为我们把还有这个问题的数据全部阅读,并把可能或者不可能的内容全部呈现在我们的面前对于学生来说,根据AI 说明不能快速定位到问题点,这样会大大影响我们的学习效率
构建本地知识库
企业私有的专业知识库,包含各种类型的数据,是问答对话中回答用户问题的知识来源。MaxKB 中知识库分为通用型知识库和 Web 站点知识库两种类型。
- 通用型知识库:对离线文档上传管理,支持的文本文件、表格以及 QA 问答对。
- Web 站点知识库:用于获取在线静态文本数据管理,输入 Web 根地址后自动同步根地址及子级地址的文本数据。
MaxKB 支持知识库创建、重新向量化、设置、同步、导出、删除等功能。
1.创建本地知识库
打开【知识库】页面,点击【创建知识库】,进入创建知识库页面。
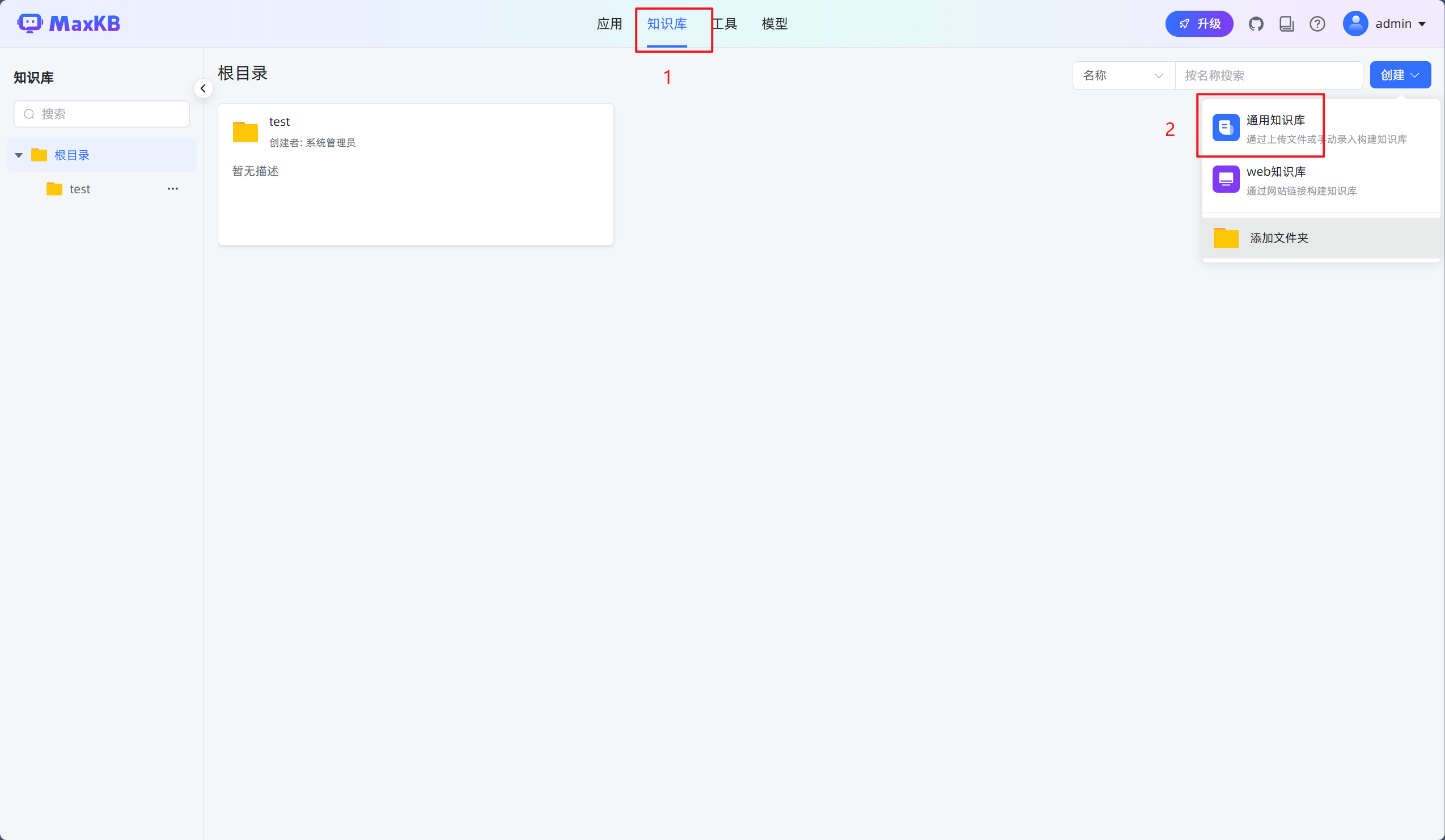
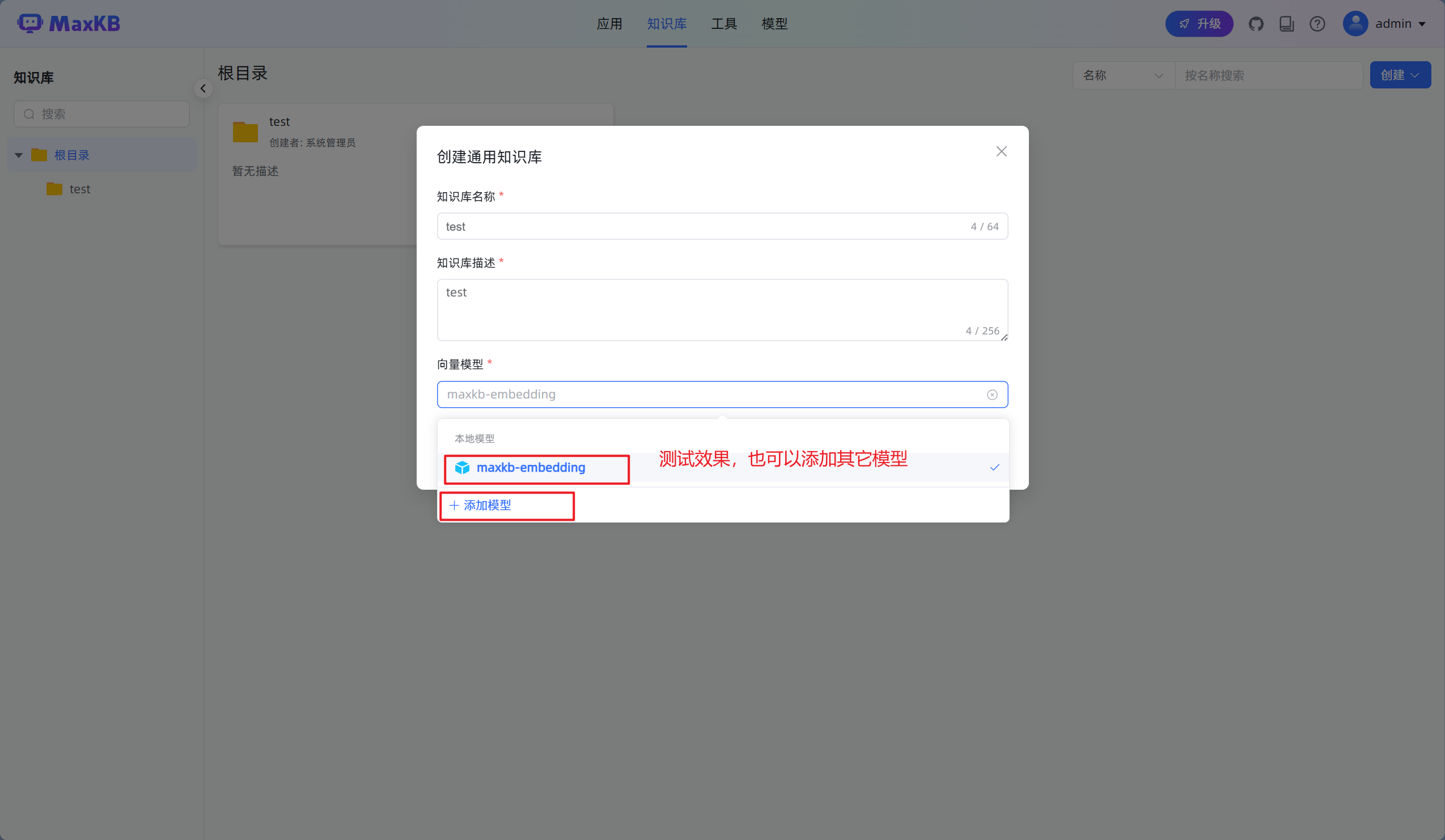
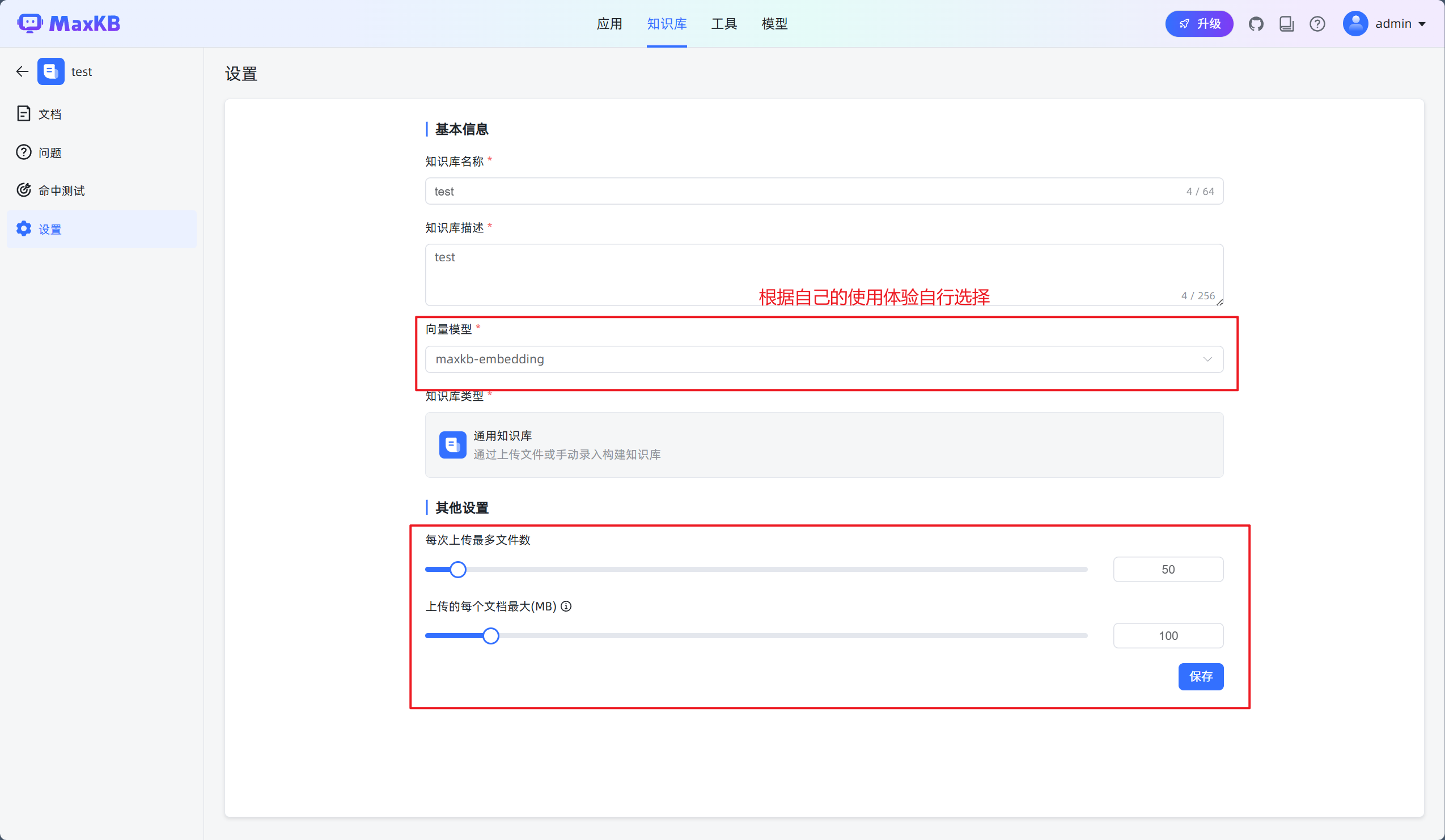
2.选择向量模型
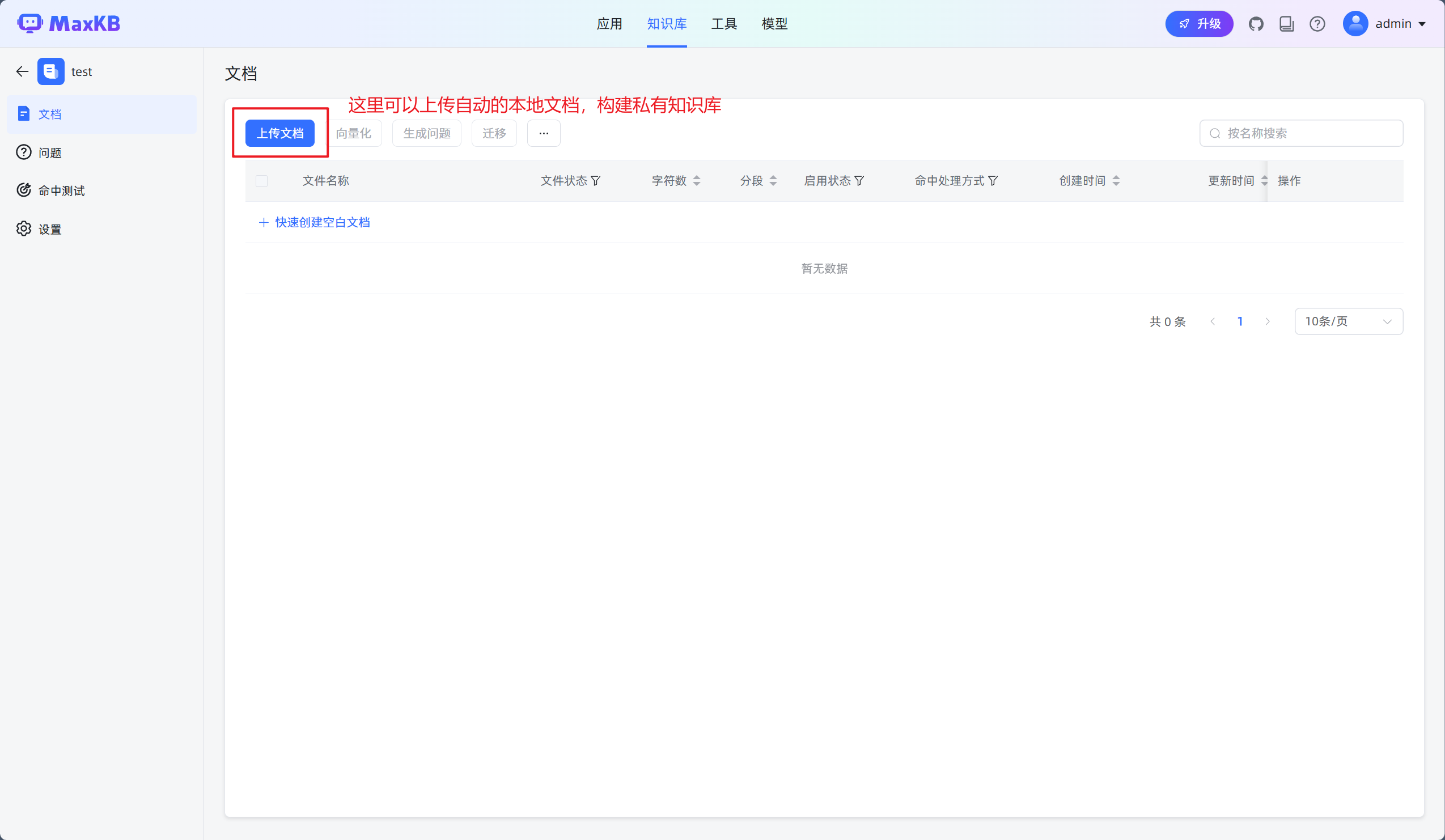
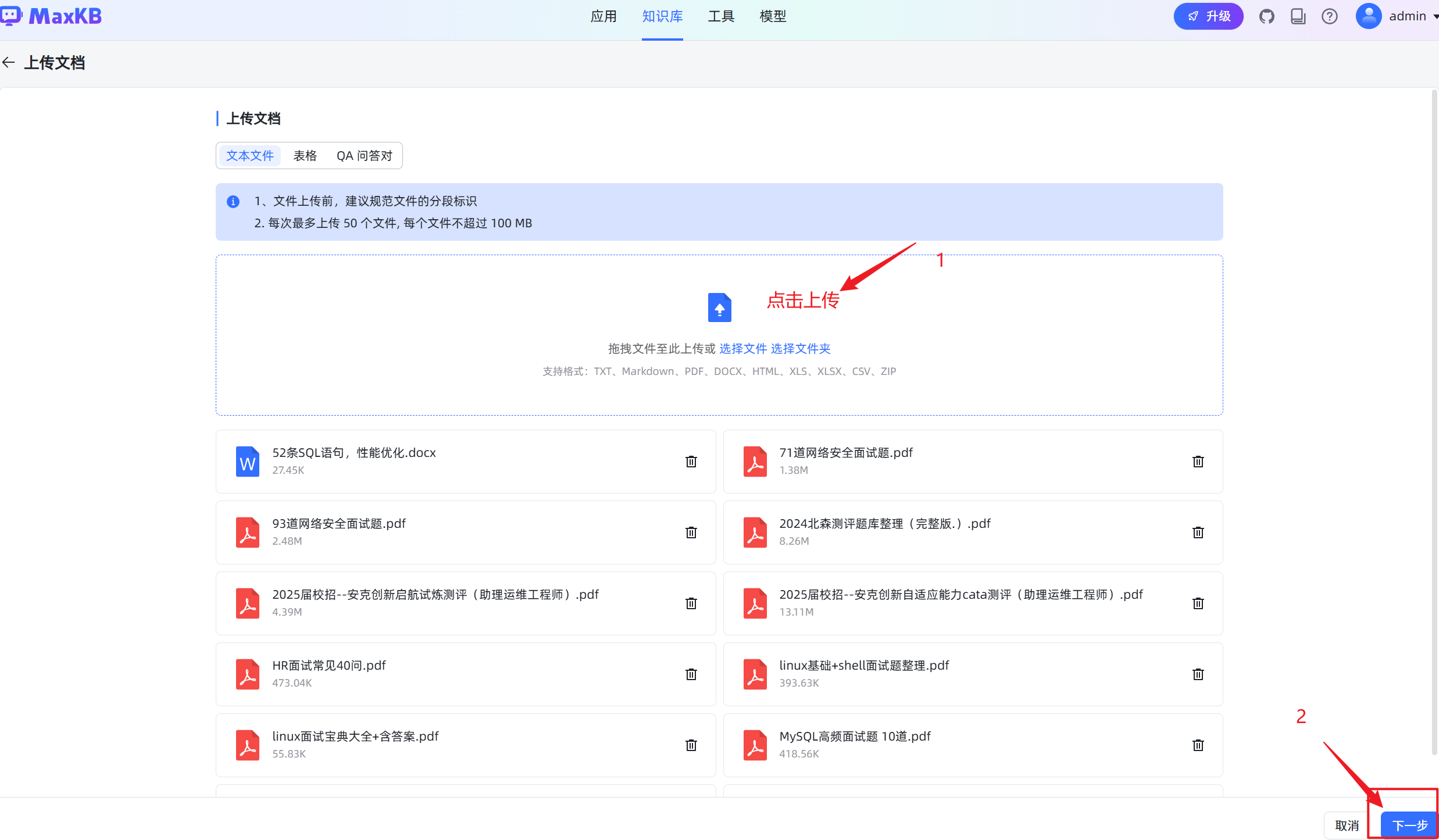
3.上传文档,并对文档进行RAG向量化处理
对于知识库文件的分段,目前 MaxKB 支持智能分段以及高级分段两种方式。
智能分段
( 1 ) MarkDown 类型文件智能分段规则
- 根据标题逐级下钻式分段(最多支持 6 级标题),每个段落最多 4096 个字符;
- 当最后一级的文本段落字符数超过设置的分段长度时,会查找分段长度以内的回车进行截取。
( 2 ) HTML 、 DOCX 类型智能分段规则
- 识别标题格式转换成 markdown 的标题样式;
- 逐级下钻进行分段(最多支持 6 级标题),每个段落最多 4096 个字符。
( 3 ) TXT 和 PDF 类型文件智能分段规则
- 按照标题# 进行分段,若没有#标题的则按照字符数4096个字符进行分段;
- 查找分段长度以内的回车进行截取。
高级分段
用户可以根据文档规范自定义设置分段标识符、分段长度及自动清洗。
- 分段标识支持:#、##、###、####、#####、######、-、空行、回车、空格、分号、逗号、
- 句号,并支持手动输入其它分段标识符或正则表达式。
- 分段长度:单个分段的长度,范围 50 至 4096 个字符。
- 自动清洗:开启后系统会自动去掉重复多余的符号如空格、空行、制表符等。
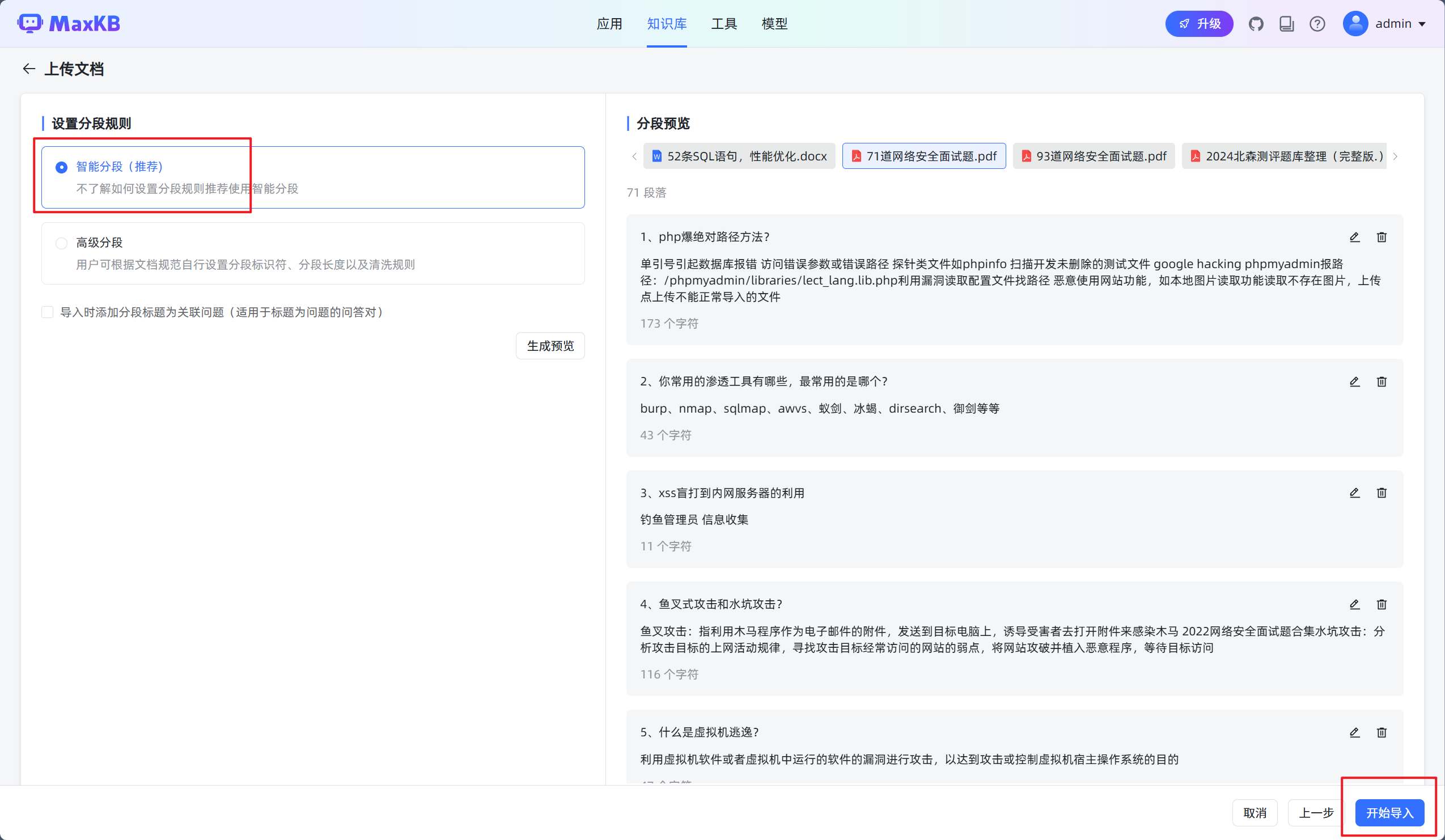
4.本地文档上传成功
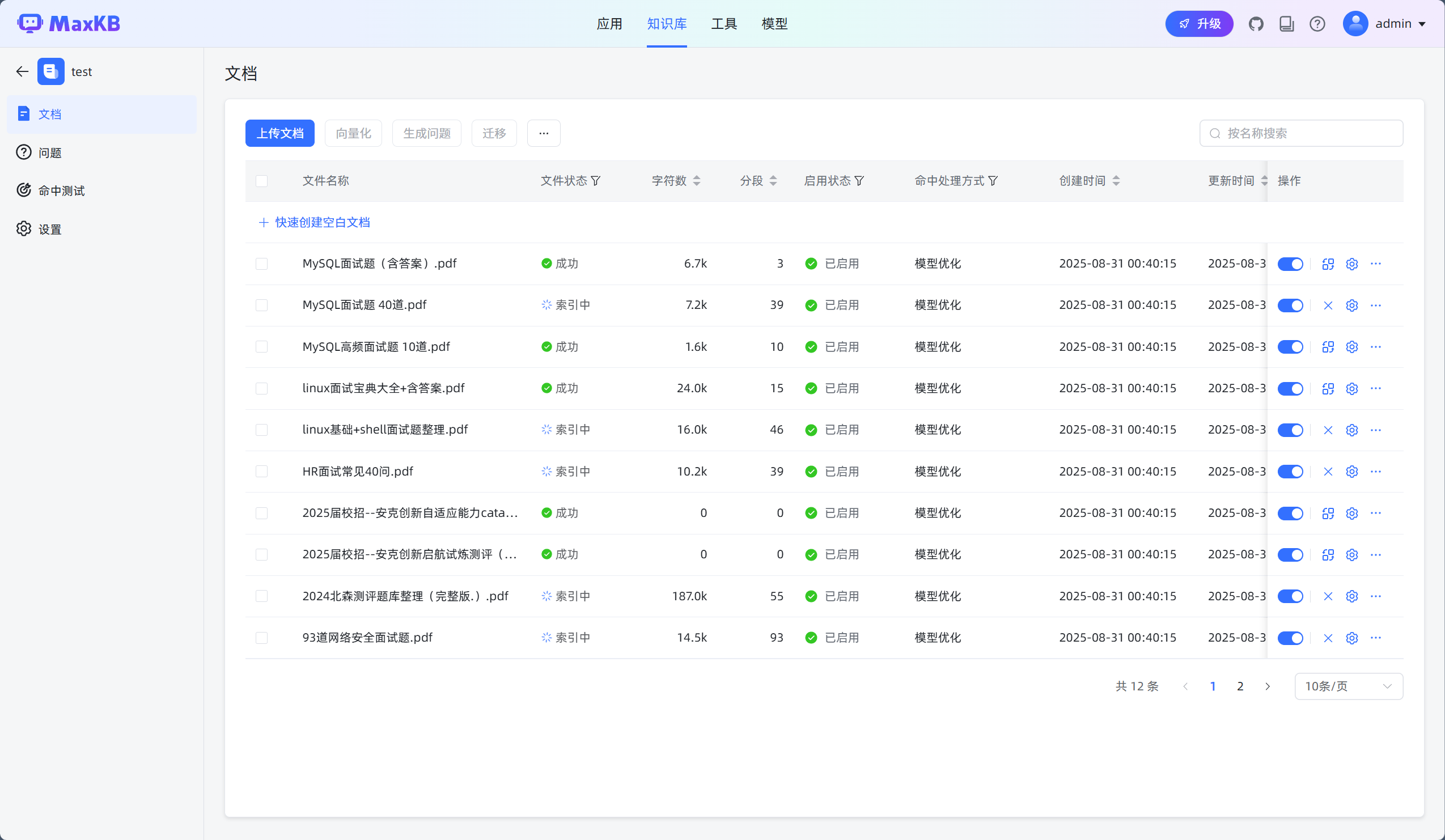
5.设置上传参数
输入知识库名称、知识库描述,选择向量模型并设置知识库类型为通用型,然后将离线文档通过拖拽或选择文件方式进行上传。上传文档要求:
- 文本文件::Markdown、TXT、PDF、DOCX、HTML、XLS、XLSX、CSV、ZIP;
- 表格:XLS、XLSX、CSV、ZIP;
- QA 问答对:XLS、XLSX、CSV、ZIP;
- 每次最多上传 50 个文件;
- 每个文件不超过 100 MB;
- 支持选择文件夹,上传文件夹下符合要求的文件。
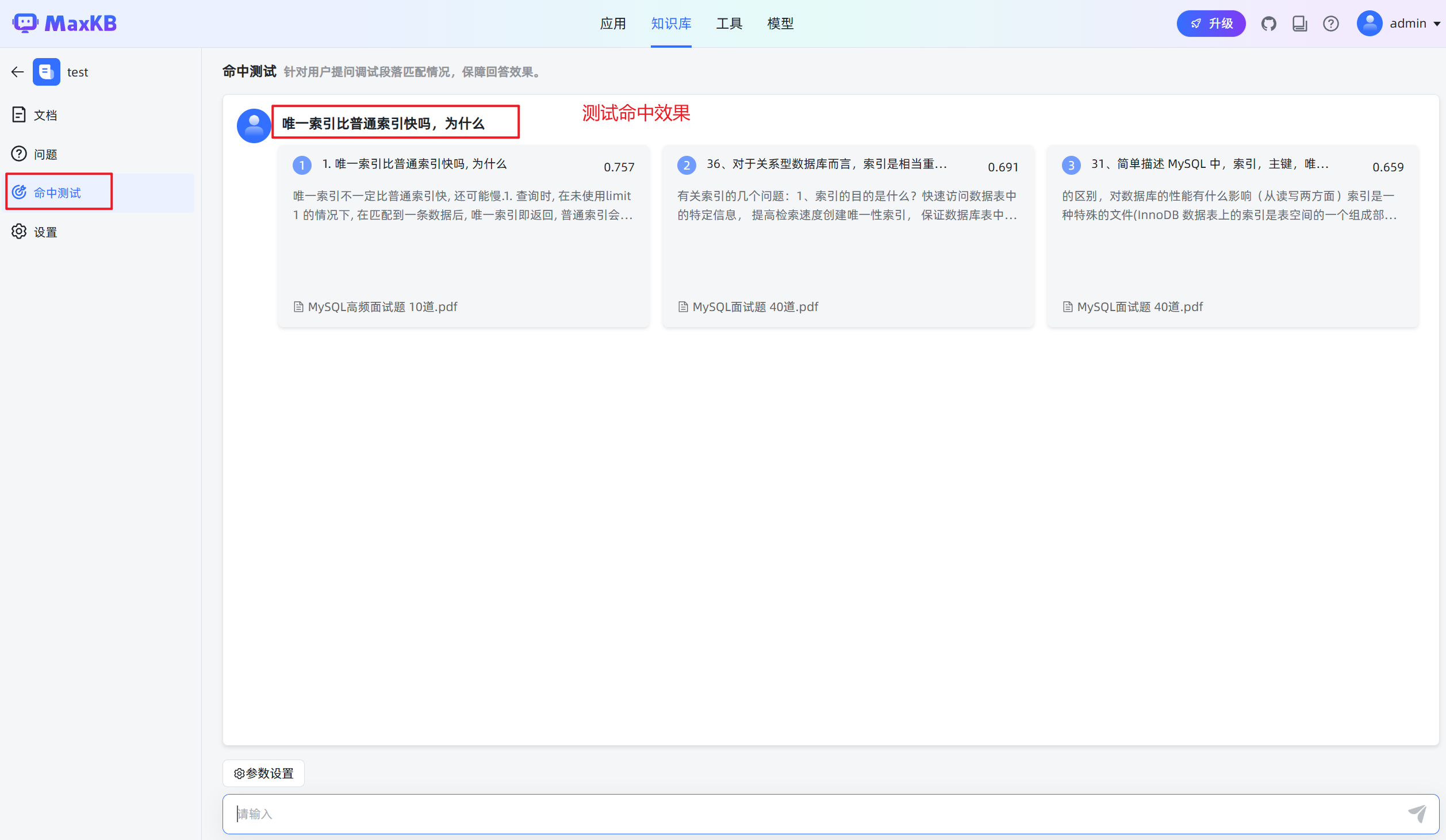
6.测试命中效果
对于上传文件的格式,我们在编写的时候尽量每个问题中间用空行隔开,这样便于 MaxKB 对于文章内容进行向量化操作,我们在选择分段时也可以通过高级分段来设定规则,这样就可以把每个问题变成一个分段,对于分段内容进行精细化处理提高问题命中率减少幻觉
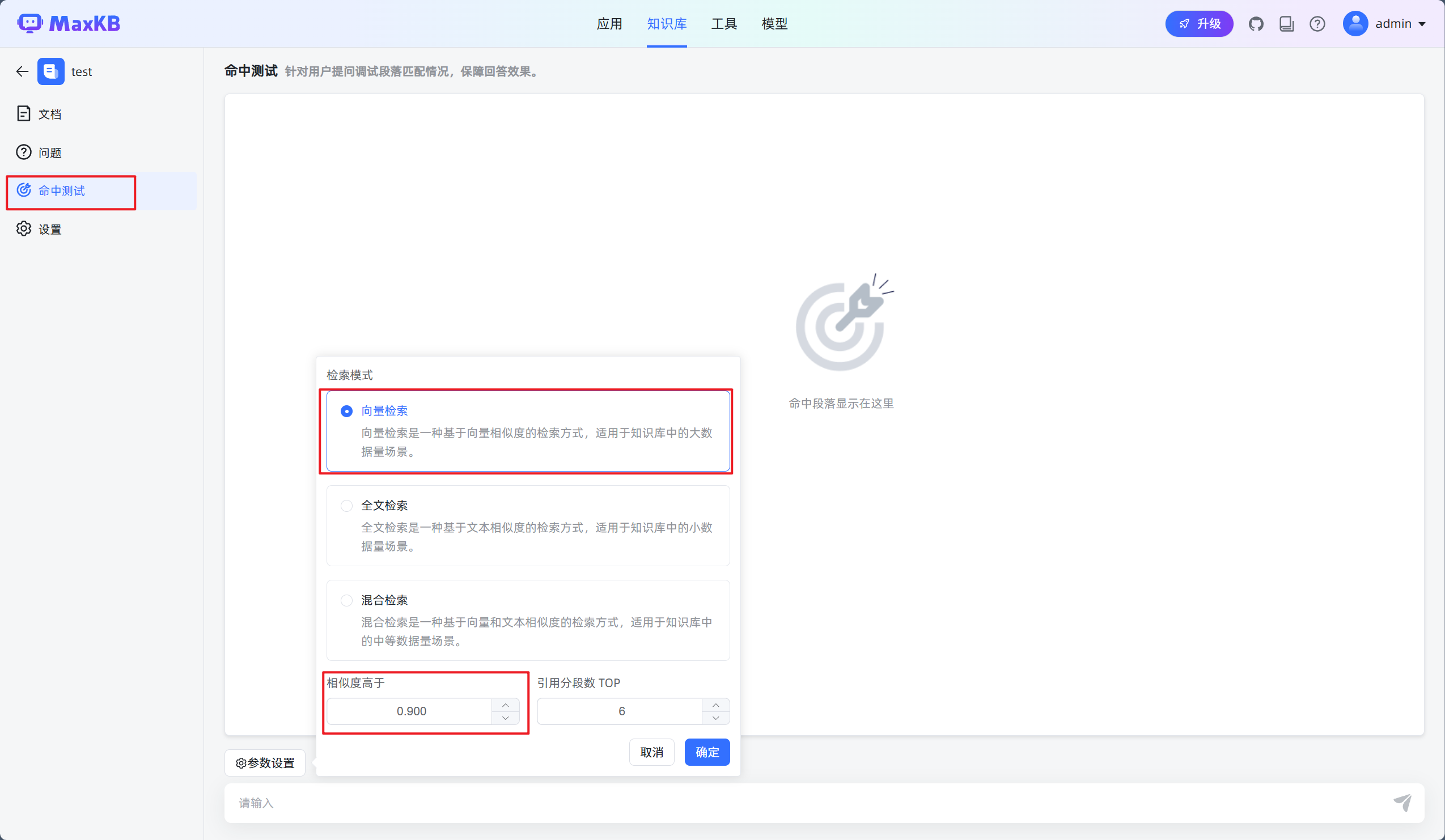
7.调整测试参数
- 我们可以提前把可能出现的问题尽可能的关联到相应的知识分段中,这样可以大大提高命中率调整知识库命中方式及命中概率。
- 通过命中测试,我们可以看到问题的命中率在0.8的时候时得到的答案时相对准确的。所以我们可以设定我们的知识库直接回答的阈值为0.9这样我们就可以更准确的命对应的分段。
到此基于 Linux + ollama + qwen:7b + maxkb 部署本地大模型到此结束!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)