九、《算力性价比巅峰:华为CloudMatrix384超节点技术解析》--揭秘单卡推理吞吐2300 Tokens/s背后的架构革命
CloudMatrix384超节点不仅实现了国产算力从"能用"到"好用"的跨越,更为整个AI产业打开了一条更加高效、普惠、可持续的技术道路。在AI推理需求预计将占到通用人工智能总计算需求70%以上的未来,这种系统级创新具有极其重要的战略意义。
一、超节点性能突破:重新定义算力性价比
2025年可谓AI推理的爆发之年。据数据显示,从2024年初到2025年6月底,中国日均Token消耗量从1000亿激增至30万亿,短短18个月内增长了300多倍。这种指数级增长对算力基础设施提出了前所未有的挑战。
在此背景下,华为云CloudMatrix384超节点的性能数据令人震撼:
-
单卡推理吞吐能力:从非超节点方案的600 Tokens/s提升至2300 Tokens/s
-
增量Token输出时延:从100ms降低到50ms以下
-
每卡性能可达英伟达H20的三倍
从成本角度看,这意味着每小时可产出828万Token,按每小时租金15元计算,百万Token成本仅约1.8元,比业界主流GPU方案更具性价比。
二、架构创新揭秘:三大技术突破实现性能跃升
华为CloudMatrix384超节点的性能飞跃非单点优化,而是系统级全栈创新的结果。
2.1 一切可池化:打破硬件边界
CloudMatrix384通过统一的、超高性能的MatrixLink网络,将NPU、CPU、内存、网络等资源解耦,形成可独立扩展的资源池。这种设计突破了传统的"AI内存墙",EMS弹性内存存储实现"以存强算",彻底释放了每一颗芯片的算力。
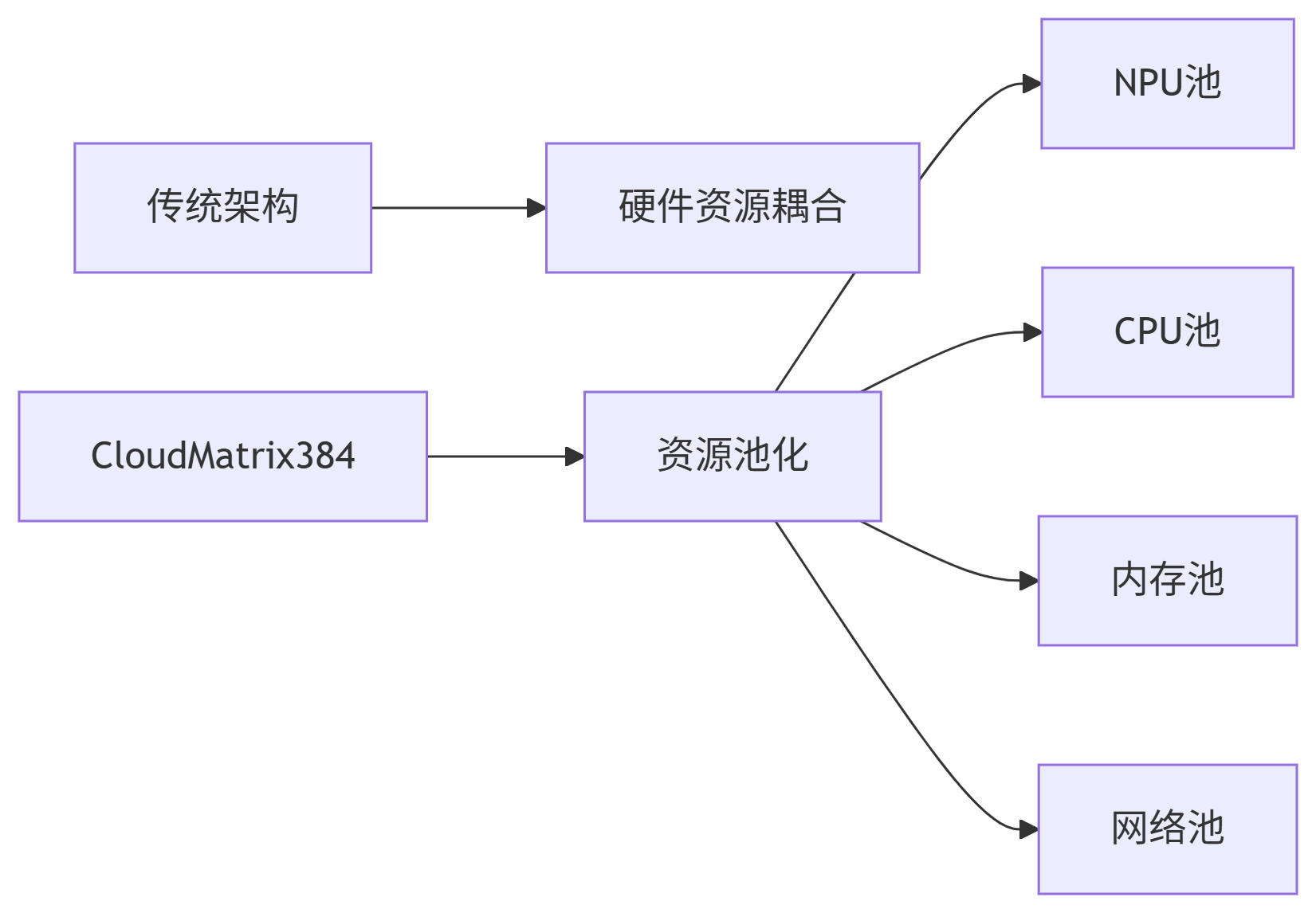
2.2 一切皆对等:重构互联范式
与传统以GPU为中心的计算范式不同,CloudMatrix384采用全对等互联架构。将384颗昇腾NPU和192颗鲲鹏CPU通过全新高速网络MatrixLink全对等互联,形成一台拥有超大带宽、超大内存、超高算力的超级"AI服务器"。
这种设计特别适合大模型的训推任务,尤其是MoE混合架构的大模型。传统集群模式下进行推理,需在每张单卡上分配所有"专家",导致每个"专家"只能获得少量的计算和通信能力。
2.3 一切可组合:灵活资源调配
CloudMatrix384超节点池化的所有资源,可以根据不同的任务需求,像搭积木一样进行灵活调配组合。这种架构支持"一卡一专家"模式,即每张卡只部署一个"专家",集中处理所有相关问题,增加单次推理的批量大小,减少单位计算的调度开销,大幅提升推理效率。
三、xDeepServe框架:推理性能的关键引擎
作为CloudMatrix384超节点的原生服务,xDeepServe采用Transformerless的极致分离架构,把MoE大模型拆成可独立伸缩的Attention、FFN、Expert三个微模块。
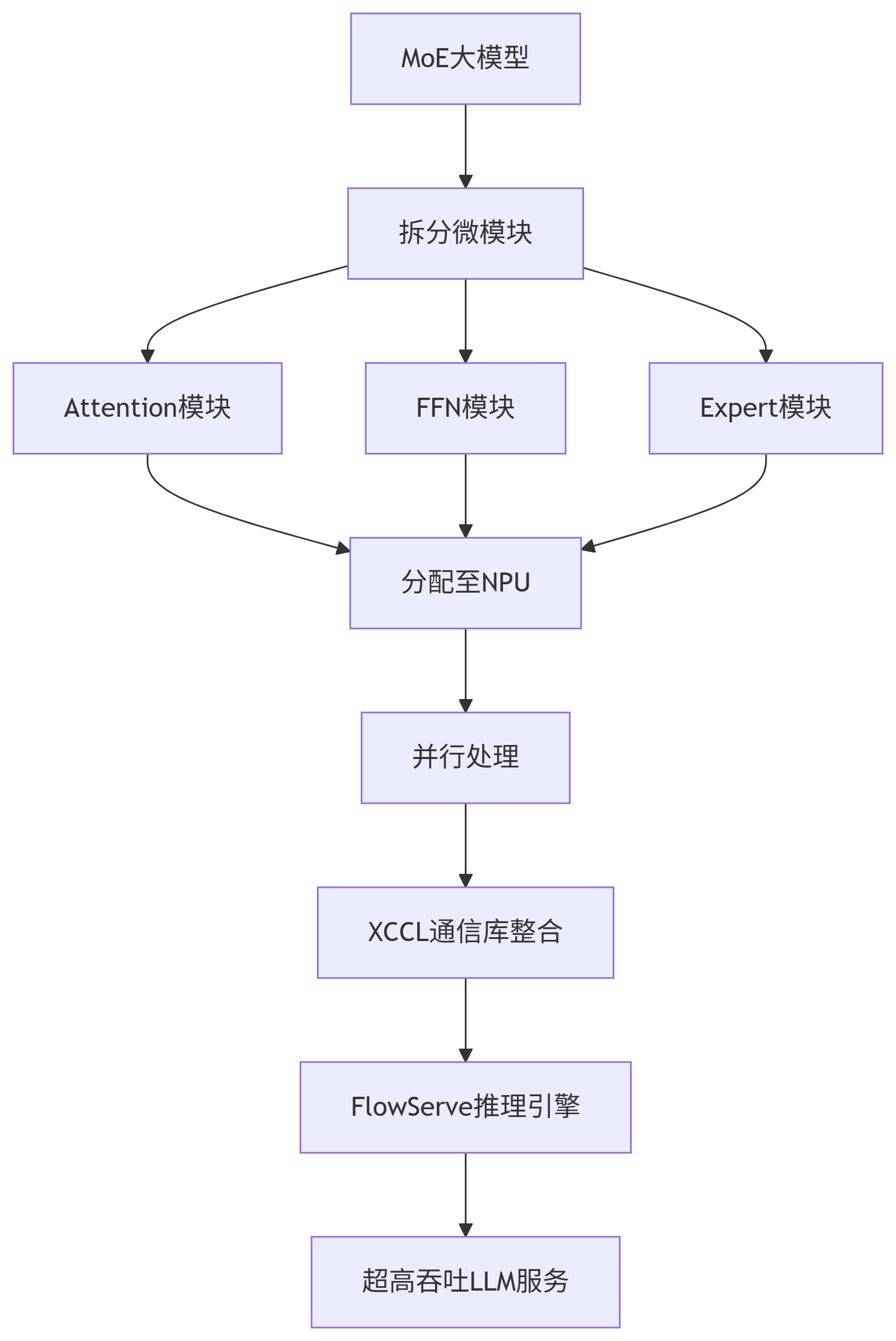
这种架构相当于在一台CloudMatrix384上把"大模型"拆成"积木",并分派到不同的NPU上同步处理任务。之后,再用基于内存语义的微秒级XCCL通信库与FlowServe自研推理引擎把它们重新拼成一个超高吞吐的LLM服务平台,即Tokens的"超高速流水线"。
CANN作为硬件加速计算的中间层,包含多个算子库和XCCL这种高性能通信库等组件,共同支撑AI模型的高效运行。其中,XCCL作为专为超节点上的大语言模型(LLM)服务而量身打造的高性能通信库,能够充分发挥CloudMatrix384扩展后的UB互联架构(UB fabric)的全部潜力。
四、企业实践案例:降本增效成果显著
4.1 新浪:推理交付效率提升50%以上
新浪基于CloudMatrix384昇腾AI云服务,为"智慧小浪"智能服务体系构建了统一的推理平台,推理的交付效率提升超过50%。这一提升显著降低了AI服务的运营成本,提高了用户体验。
4.2 面壁智能:推理业务性能提升2.7倍
面壁智能使用CloudMatrix384昇腾AI云服务,让"小钢炮"模型的推理业务性能得到了2.7倍的提升。这种性能提升直接转化为成本下降和服务质量提升。
4.3 三甲医院:AI影像诊断成本下降60%
某三甲医院引入了CloudMatrix384云算力技术来处理AI影像诊断,结果令人欣喜:成本下降了60%。这不仅降低了医疗成本,也让AI辅助诊断技术能够惠及更多患者。
4.4 智能驾驶:感知模型性能提升3倍
华为云围绕智能驾驶领域集中发布CloudVeo智能驾驶云服务等解决方案。多个项目的实际测试结果显示,在典型感知模型、E2E、VLA模型上,CloudMatrix384超节点可以达到或者超过H100 2.5-3倍的性能。
五、规模扩展与稳定性:支撑企业级应用
对于万亿、十万亿参数的大模型训练任务,CloudMatrix384可以通过横向扩展方式,将432个超节点连在一起,组成一个16万卡的AI集群。如果这个集群用于训练千亿参数大模型,可以同时支持1300个。
关键指标线性度(节点数量增加后性能按比例提升的能力)已经超过95%,实现了性能提升与资源扩展的比例接近1:12。
CloudMatrix384超节点昇腾AI云服务支持训推算力一体部署,如"日推夜训"模式(白天推理,晚上训练)以及"40天长稳训练、10分钟快速恢复"能力,保障长周期训练的稳定性和中断后的快速恢复。
六、架构师行动指南:如何有效利用超节点
6.1 应用场景评估
CloudMatrix384超节点特别适用于以下场景:
-
大规模MoE模型推理:充分利用"一卡一专家"模式
-
高并发推理服务:如智能客服、内容生成平台
-
混合负载环境:利用训推一体化架构实现资源复用
6.2 迁移建议
对于考虑迁移到CloudMatrix384的企业,建议采取以下步骤:
-
工作负载分析:分析现有AI工作负载的特征,识别适合迁移的场景
-
渐进式迁移:先从非关键业务开始,逐步迁移核心业务
-
性能调优:利用xDeepServe架构特性重新优化模型部署
-
成本效益评估:对比现有解决方案,计算TCO节省
6.3 成本优化策略
-
利用训推一体:采用"日推夜训"模式提高资源利用率
-
弹性伸缩:根据业务负载动态调整资源规模
-
混合部署:将不同类型工作负载整合到统一平台
七、未来展望:算力架构的发展方向
华为云正在构建"全国算力一张网",围绕贵安、乌兰察布、和林格尔、芜湖三大核心枢纽布局。在贵州已部署超40套CloudMatrix384超节点。相比去年同期,华为云整体算力规模增长接近250%,昇腾AI云服务客户从去年的321家增长到今年1714家。
未来,随着xDeepServe框架进一步发展,将把Attention、MoE、Decode全部改成自由流动的数据流,并把同样的拼图方法复制到多台超节点,让推理吞吐像铺轨一样线性延伸,最终实现吞吐量的更大突破。
结语
华为CloudMatrix384超节点代表了算力架构设计的一次范式转变:从单点优化走向系统级创新,从硬件堆叠走向智能协同,从固定配置走向灵活组合。通过三大架构创新(可池化、皆对等、可组合)与xDeepServe推理框架的完美结合,实现了单卡推理吞吐2300 Tokens/s的突破性性能。
对于企业用户而言,这意味着能够以更低成本获得更高性能的AI算力服务,大幅降低了AI应用的门槛。正如华为常务董事、华为云计算CEO张平安所言:"芯片重不重要?重要。但更重要的是,能够提供客户所需要的计算结果"。
CloudMatrix384超节点不仅实现了国产算力从"能用"到"好用"的跨越2,更为整个AI产业打开了一条更加高效、普惠、可持续的技术道路。在AI推理需求预计将占到通用人工智能总计算需求70%以上的未来,这种系统级创新具有极其重要的战略意义。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)