Agent开发必读:生产级Agent的12个核心原则
GitHub项目humanlayer/12-factor-agents提出了开发AI-Agent的12项核心原则,强调自然语言到工具调用的转换、提示词与上下文窗口的精细控制、结构化输出与确定性执行的分离、执行状态与业务状态的统一等关键设计理念。这些原则旨在构建可靠、可扩展且易于维护的Agent系统,涵盖从控制流管理到人工协作的全生命周期,为开发者提供了模块化、可测试的Agent开发框架。通过结构化
原作者:俞乾
GitHub 上的humanlayer/12-factor-agents 项目为 Agent 开发提供了 12 个核心原则,所有 AI-Agent 开发者 / 产品经理都应该看下。这些原则旨在帮助开发者构建健壮、可扩展、易于维护的 LLM 驱动型软件。本文将介绍并分析它们如何共同构成 Agent 应用的基础。

Factor 1: 自然语言到工具调用
此要素强调 LLM 在 Agent 架构中的核心作用:作为意图解析器和行动规划器。LLM 理解用户自然语言输入,根据知识和工具定义,生成结构化工具调用。这些调用是 Agent 与外部世界交互的接口。通过将自然语言转化为结构化输出,Agent 实现与外部系统(如 API、数据库、其他服务)的无缝集成。这种分离使 LLM 专注于理解和推理,确定性代码负责可靠执行操作,提高 Agent 可靠性和可测试性。
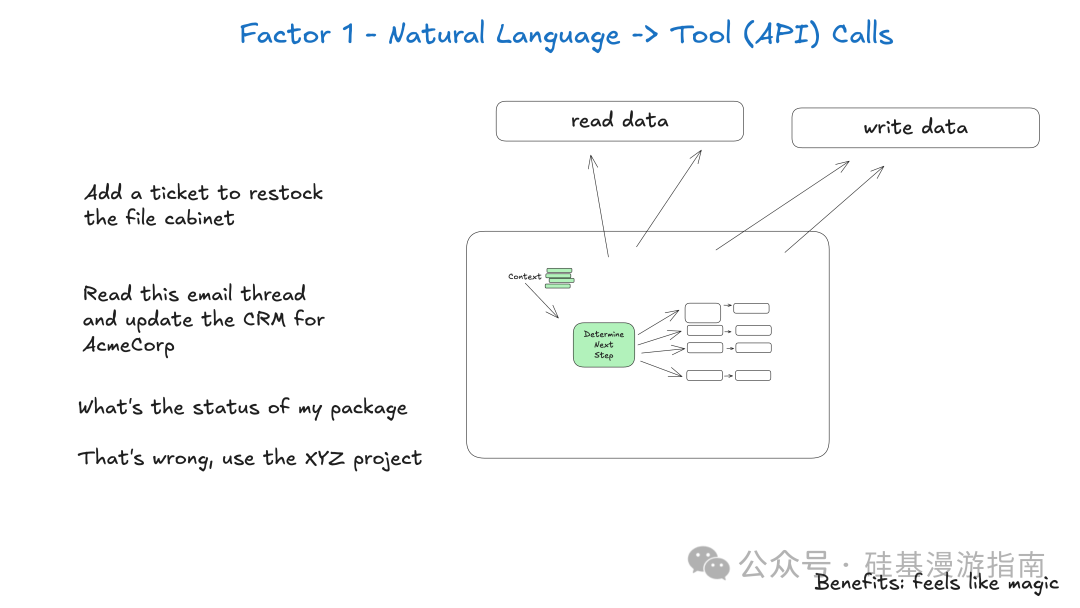
关键点:
- • 意图解析:LLM 将自然语言请求解析为明确、可执行的意图。
- • 结构化输出:LLM 生成标准化结构化数据(如 JSON),描述要调用的工具及其参数。
- • 确定性执行:结构化输出由确定性代码处理,确保操作准确性和可预测性。
- • 解耦:LLM 推理能力与工具执行逻辑解耦,提高系统模块化和可维护性。

Factor 2: 掌控你的提示词
在构建 Agent 时,开发者应完全控制 LLM 的提示词,而非外包给黑盒框架。许多 Agent 框架为简化开发,提供高级抽象,让开发者通过简单参数定义 Agent 行为。这虽有助于快速启动,但难以精细调优,也难精确控制 LLM 输出。

此要素核心是将提示词视为一等公民的代码。提示词应像其他代码一样被设计、版本控制、测试和迭代。通过直接编写和管理提示词,开发者可实现:
- • 完全控制:精确指示 Agent 行为,避免黑盒抽象的不确定性。
- • 测试与评估:为提示词构建测试和评估体系,确保其在不同场景下表现符合预期。
- • 快速迭代:根据实际运行效果快速修改和优化提示词,适应不断变化的需求和模型能力。
- • 透明度:清楚了解 Agent 使用的具体指令,便于调试和问题排查。
- • 高级技巧:利用 LLM API 支持的非标准用法,如角色扮演、模型行为控制等,实现更复杂或高效的行为。
Factor 3: 掌控你的上下文窗口
掌控上下文窗口强调开发者应主动管理和构建传递给 LLM 的上下文信息,而非仅依赖标准消息格式。LLM 是无状态函数,将输入转化为输出。为获最佳输出,需提供最佳输入,即进行精细的“上下文工程”。
上下文窗口不仅是对话历史,它包含 LLM 决策所需的一切信息,例如:
- • 提示词和指令:LLM 接收的初始指令和角色设定。
- • 外部数据:通过检索增强生成(RAG)等方式获取的相关文档或外部数据。
- • 历史状态:过去的工具调用、执行结果、错误信息及其他相关历史记录。
- • 记忆:来自相关但独立历史或对话的过去消息或事件。
- • 结构化输出指令:关于 LLM 应输出何种结构化数据的明确指示。
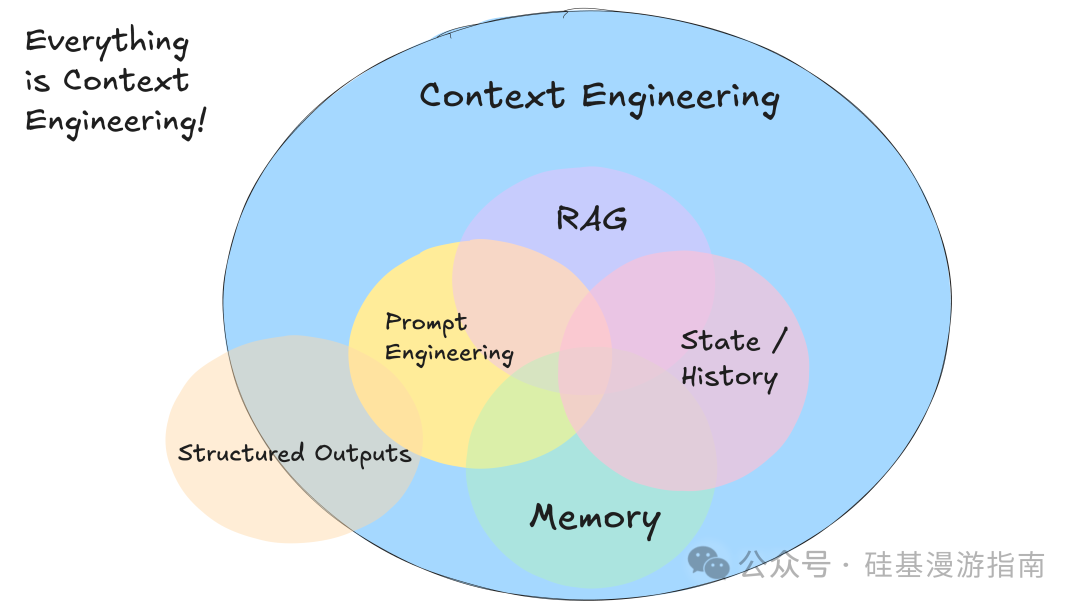
此要素核心在于,开发者可构建自定义上下文格式,最大化 LLM 理解能力和令牌效率。例如,将所有相关信息打包到一个用户消息中,使用 XML 或其他自定义标记组织不同类型数据(如 Slack 消息、Git 标签列表、工具调用结果等)。此方式允许开发者:
- • 信息密度:以 LLM 最易理解和处理的方式组织信息,提高信息利用率。
- • 错误处理:以有助于 LLM 恢复的方式包含错误信息,可选择性隐藏已解决错误。
- • 安全性:控制哪些信息传递给 LLM,过滤敏感数据。
- • 灵活性:根据用例需求灵活调整上下文格式,通过实验找到最佳实践。
- • 令牌效率:优化上下文格式,在有限令牌预算内传递更多有效信息。
通过掌控上下文窗口,开发者能更精细控制 LLM 输入,显著提升 Agent 性能、可靠性和自我修复能力。Agent 能更好理解当前状态、历史事件和外部信息,做出更准确、智能的决策。
Factor 4: 工具只是结构化输出
此要素揭示 Agent 中工具调用的本质:它们是 LLM 生成的结构化数据,触发确定性代码执行。LLM 核心任务是决定“做什么”,实际“如何做”由确定性代码控制。
此模式带来清晰分离:
- \1. LLM 输出结构化 JSON:LLM 根据自然语言理解和上下文,生成描述下一步操作的结构化数据。
- \2. 确定性代码执行:应用程序代码接收并解析结构化输出,执行实际确定性操作,如调用外部 API、更新数据库或触发其他服务。
- \3. 结果反馈:操作结果被捕获并反馈回 LLM 上下文,供 LLM 后续推理。
此设计理念优势:
- • 解耦:LLM 专注于决策和意图表达,执行细节由可靠确定性代码处理,降低 LLM 出错风险。
- • 灵活性:开发者可根据业务需求,自由定义工具结构和行为,不受 LLM 框架预设限制。
- • 可控性:即使 LLM“调用”工具,开发者仍可在确定性代码层面进行额外验证、审批或自定义逻辑,确保高风险操作安全。
- • 可测试性:工具执行逻辑确定,易于单元测试和集成测试。
Factor 5: 统一执行状态和业务状态
传统基础设施系统常区分执行状态(当前步骤、等待状态、重试次数等)和业务状态(Agent 工作流中已发生事件,如 OpenAI 消息列表、工具调用结果等)。这种分离管理复杂性,但在 AI 应用中可能过于复杂或不必要。
统一执行状态和业务状态的原则建议,尽可能简化并统一这两种状态。Agent 执行状态可从上下文窗口推断。例如,Agent 当前步骤或等待状态,即其历史记录中的元数据。将所有相关信息(包括执行元数据)纳入 Agent 上下文窗口,可实现:
- • 简化性:所有状态信息集中一处,减少管理多个独立状态存储的复杂性。
- • 可序列化:Agent 整个“线程”(上下文历史)可轻松序列化和反序列化,便于存储、传输和恢复。
- • 可调试性:整个历史记录一目了然,极大简化调试和问题排查。
- • 灵活性:通过添加新事件类型,轻松扩展 Agent 状态表示。
- • 可恢复性:Agent 可从任何历史点恢复运行,只需加载相应线程状态。
- • 可分叉性:通过复制线程子集到新上下文,轻松创建 Agent 工作流分叉。
- • 人类接口和可观察性:将线程转换为人类可读 Markdown 或丰富 Web 应用 UI,增强 Agent 可观察性和与人类交互能力。
Factor 6: 通过简单 API 启动/暂停/恢复
Agent 作为程序,应具备启动、查询、恢复和停止的能力。此要素强调为 Agent 提供简单、直观的 API 接口,方便用户、应用、数据管道或其他 Agent 轻松交互。
具体而言:
- • 轻松启动:Agent 应能通过简单 API 调用启动,无论是通过用户界面、命令行工具还是自动化系统。
- • 灵活暂停:Agent 需执行长时间操作(如等待人工输入、外部系统响应或复杂计算)时,应能暂停。暂停不应阻塞执行流,而应释放资源并等待外部事件。
- • 无缝恢复:外部触发器(如 Webhooks、消息队列事件)应能让 Agent 从上次暂停处恢复执行,无需与 Agent 编排器深度集成。这使 Agent 能处理异步事件和长时间任务。
此要素与统一执行状态和业务状态(Factor 5)及掌控控制流(Factor 8)密切相关。通过将 Agent 执行状态(如当前步骤、等待状态)与业务状态统一,并存储在可序列化上下文中,Agent 可轻松在不同时间点暂停和恢复。这对于构建持久化、可靠 Agent 至关重要,尤其在需人工干预或等待外部事件的复杂工作流中。
Factor 7: 通过工具调用联系人工
传统 LLM API 在返回纯文本和结构化数据间存在高风险抉择。此要素提出更可靠方法:LLM 始终输出结构化数据,并通过工具调用明确与人工交互。
即使 Agent 需联系人工,也通过特定工具调用(如request_human_input)表达意图,而非直接自然语言提问。此工具调用包含人工输入问题、上下文及可能选项(如紧急程度、响应格式)。Agent 发出此调用后,执行流可暂停,等待人工响应。
此方法优势:
- • 清晰指令:结构化工具调用使 LLM 更精确指示人工介入类型和目的。
- • 内外循环分离:Agent 支持外部循环工作流,由非人工事件触发,关键时主动联系人工寻求帮助、反馈或批准。与传统人工-Agent 交互模式(内部循环)对比。
- • 多人工访问:结构化事件轻松跟踪协调不同人工输入。
- • 多 Agent 协作:简单抽象可扩展支持 Agent 间请求和响应。
- • 持久性:结合启动/暂停/恢复(Factor 6),构建持久、可靠、可内省多人协作工作流。
将人工交互视为特殊工具调用,Agent 控制流更可预测、可管理。Agent 可处理高风险操作,执行前强制人工审批。为构建更智能、协作 Agent 系统奠定基础,使其更好融入人工工作流程。
Factor 8: 掌控你的控制流
掌控控制流强调开发者应完全控制 Agent 执行流程,而非委托给黑盒框架。开发者可根据用例需求,构建自定义控制结构,实现更灵活、智能的 Agent 行为。
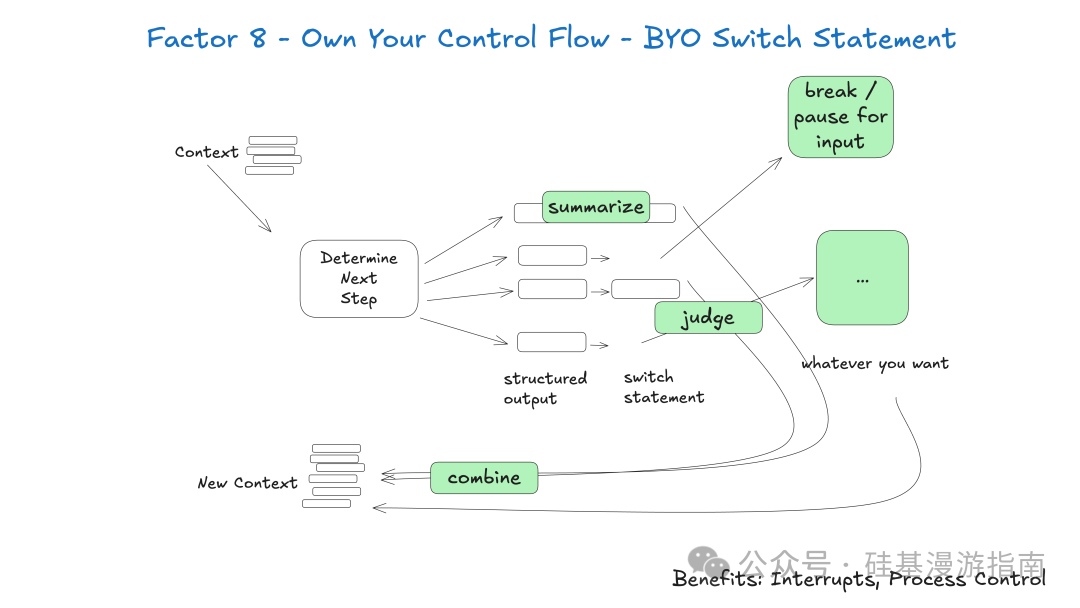
掌控控制流可实现高级功能:
- • 中断与恢复:LLM 请求信息(如
request_clarification)或需人工审批(如create_issue)时,可中断 Agent 执行循环,等待外部响应,收到响应后从中断点恢复。 - • 同步与异步操作:根据工具调用性质,决定同步执行并立即反馈结果(如
fetch_git_tags),或异步执行并等待外部事件触发恢复。 - • 结果摘要与缓存:对工具调用结果摘要或缓存,优化上下文窗口使用和 LLM 性能。
- • LLM 作为判断者:LLM 对结构化输出判断或验证。
- • 上下文窗口压缩与记忆管理:实现复杂记忆管理策略,如压缩上下文窗口或选择性移除旧事件。
- • 日志、追踪与指标:集成全面日志、追踪和指标收集,便于监控调试。
- • 客户端限速:客户端层面实现 LLM 调用限速。
- • 持久化休眠/暂停/等待事件:实现 Agent 持久化休眠机制,长时间等待特定事件发生。
此要素核心是,Agent 执行循环非简单线性过程,而是可中断、调整、恢复的动态过程。例如,Agent 需人工输入时,可暂停执行,发送请求,等待人工响应 Webhook。收到响应后,Agent 从中断处继续执行。
Factor 9: 将错误压缩到上下文窗口
此要素关注 Agent 的自我修复能力。Agent 执行任务时,工具调用失败常见。优秀 LLM 能通过读取错误消息或堆栈跟踪,调整后续工具调用,实现自我纠正。此要素核心是将错误信息以对 LLM 有用的方式注入上下文窗口,以便 LLM 理解学习。
此要素实现通常包括:
- • 错误捕获:在工具调用周围使用 try-except 块捕获异常。
- • 错误格式化:将原始错误信息(如堆栈跟踪)格式化为 LLM 易懂的简洁形式,提取关键错误类型、消息和上下文。
- • 错误注入:将格式化错误信息作为新事件类型(如
error)添加到 Agent 上下文窗口。 - • 重试机制:可实现简单重试计数器,限制对同一工具的连续失败尝试次数,防止 Agent 陷入无限循环。
此方法优势:
- • 自愈能力:LLM 识别并响应错误,提高 Agent 鲁棒性和任务完成能力。
- • 持久性:即使单个工具调用失败,Agent 也能继续运行,尝试从错误中恢复。
需注意,过度注入原始错误信息可能导致 LLM 失控,重复相同错误。结合掌控控制流(Factor 8)和掌控上下文窗口(Factor 3),开发者可精细管理错误信息呈现方式,如多次失败后移除旧错误事件,或将问题升级给人工。最重要的是,构建小型、专注的 Agent(Factor 10),可从根本上减少错误发生可能性和复杂性。
Factor 10: 小而精的 Agent
此要素主张,与其构建包揽一切的庞大 Agent,不如构建专注于特定任务、功能单一的 Agent。Agent 应视为更大、主要由确定性系统组成的系统中的构建块。此原则核心洞察在于 LLM 局限性:任务越庞大复杂,所需步骤越多,上下文窗口越长。上下文增长,LLM 越易失焦。
将 Agent 关注点限制在特定领域,工作流控制在 3-10 步(最多 20 步),可保持上下文窗口可管理性,维持 LLM 高性能。此方法优势:
- • 可管理上下文:更小上下文窗口意味着 LLM 性能更佳,因模型不必处理过多信息。
- • 清晰职责:每个 Agent 有明确范围和目的,避免职责不清。
- • 更高可靠性:复杂工作流中迷失可能性更小,提高 Agent 可靠性。
- • 更易测试:单一功能更易测试验证,简化开发维护。
- • 改进调试:问题发生时,更易识别修复,因问题范围限于小而专注的 Agent。
Factor 11: 随时随地触发,满足用户需求
此要素强调 Agent 的无处不在性和易用性。Agent 应能从各种渠道被触发,并通过用户习惯渠道响应。Agent 不应局限于特定界面或平台,而应融入用户日常工作流,无论是 Slack、电子邮件、短信或其他自定义应用。
此要素与通过简单 API 启动/暂停/恢复(Factor 6)和通过工具调用联系人工(Factor 7)紧密相关。Agent 若能轻松启动、暂停、恢复,并能通过工具调用与人工交互,则具备在任何地方被触发和响应的基础。此方法带来以下好处:
- • 以用户为中心:Agent 出现在用户最常用沟通渠道,提供无缝体验,让用户感觉 Agent 是真正的数字同事。
- • 外部循环 Agent:Agent 可由非人工事件(如定时任务、系统告警、数据变化)触发,即使长时间运行,关键时也能主动联系人工寻求帮助、反馈或批准。
- • 高风险工具:Agent 若能快速与各种人工沟通协作,可赋予其执行更高风险操作的能力,如发送外部邮件、更新生产数据等。清晰标准和可审计性确保 Agent 执行这些操作时的信心。
Factor 12: 让你的 Agent 成为无状态的 Reducer
此要素概括 Agent 设计重要理念:将 Agent 视为纯函数,接收状态(上下文窗口),返回新状态(下一步操作)。此设计借鉴函数式编程 Reducer 概念,强调 Agent 无状态性和确定性。
无状态 Reducer Agent:
- • 纯函数:Agent 输出完全由输入决定,不依赖外部可变状态。相同输入,总产生相同输出。
- • 状态通过上下文传递:Agent 状态不存储在内部变量,而是通过上下文窗口(历史事件和信息)显式传递。Agent 接收上下文,处理后生成下一步操作,将结果作为新事件添加到上下文。
- • 可预测性:Agent 无状态,行为高度可预测,调试、测试和推理更易。
- • 可伸缩性:无状态特性使 Agent 易于水平扩展,各实例独立处理请求,无需担心共享状态。
- • 持久性:Agent 整个历史(上下文)可持久化,需要时重新加载,实现持久化和恢复。
结论
humanlayer/12-factor-agents的 12 个原则,涵盖 Agent 设计与实现各方面,从自然语言输入处理到状态与错误管理,并强调 Agent 与人工及外部系统的高效协作。它们共同构成了健壮、可扩展、易维护的 Agent 架构。仓库地址:https://github.com/humanlayer/12-factor-agents
总结:
- • 拥抱结构化:将自然语言转化为结构化工具调用,工具视为结构化输出,并以结构化方式管理上下文和错误。
- • 掌控核心组件:完全控制提示词和上下文窗口,避免黑盒抽象。
- • 简化与统一:统一执行状态和业务状态,Agent 设计为无状态 Reducer,提高可预测性和可伸缩性。
- • 模块化与专注:构建小型、专注 Agent,将复杂任务分解为更小、可管理部分。
- • 无缝集成:通过简单 API 实现启动/暂停/恢复,支持 Agent 在任何地方被触发,在用户所在之处满足用户,并通过工具调用与人工高效协作。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)