【AI】【机器学习】【最优化算法】【梯度下降算法】梯度下降算法资料汇总、个人理解
机器学习中梯度算法对比
机器学习中梯度算法对比
其他参考:
梯度下降、牛顿法、高斯牛顿法、LM法之间的区别与联系之感性理解
| 不同梯度下降算法 | 个人总结 | 优秀参考 |
|
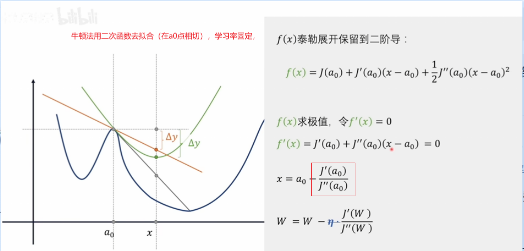
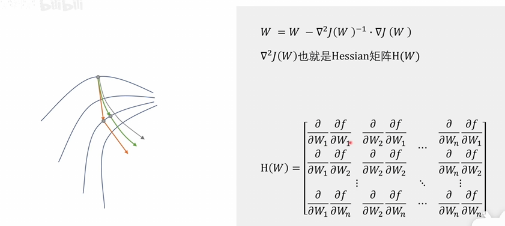
一个从计算量考虑:由此衍生出 小批量,随机梯度下降 一个从下降路径考虑(改善震荡,改善学习率): 改善震荡:动量法(又称指数加权平均),可以使梯度下降方向朝优化点迭代时候上下抖动减少,尽量朝最终优化点迭代 学习率: AdaGrad 牛顿法:
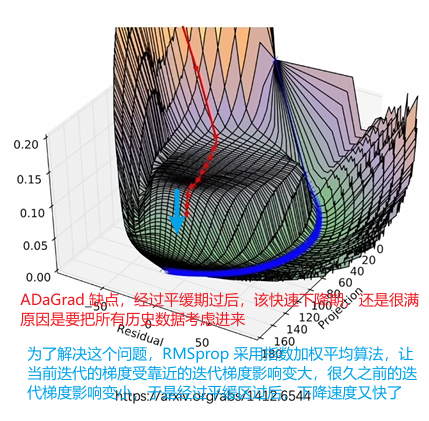
b友笔记: 两个思路:1.每一次训练的计算量都太大了,能不能减少每一次训练的计算量。2.经过很多次的计算才能慢慢地达到一个极值点,那能不能优化下降路径,用更少的步数更快地到达极值点。 思路一: 现在的随机梯度下降算法,也不是每次只挑一个数据,而是随机挑一个批次,用一个批次去进行训练,也被称为mini-batch方法。 思路二: 优化下降路径,用更少的步数,更快地到达极值点。 牛顿法,可以拿来求最优化,好是好,但是计算量太大,每次都要去计算这么个矩阵。只是理论上的方法,实用性较差。牛顿法本质上就是把下降路径的所有的纬度放到一起,统一考虑,看看能不能找到一个更好的路径。 换个思路,把下降路径的纬度拆分开,一个纬度一个纬度来考虑。 冲量法,把历史的数据也考虑进来,对参数的修改进行一些修正,让变化不是那么剧烈,减少震荡。(用历史的数据去修正下一步要下降的方向,通过此方法能减少震荡) 对梯度下降法进行优化,不进可以参考历史的数据,还可以超前地去参考未来的数据。 Nesterov方法,不只是依赖历史数据,它会向前超前一步,然后再修正下降的方向。 这两种方式其实就是相当于在训练和学习的时候,对那个参数的变化量,增加了一个0次项的修正。 既然0次项能进行修正,是不是也可以考虑对1次项也进行修正呢?也就是说针对学习率也进行一些修正。 AdaGrad方法,可以修正两个方向上的学习率,修正学习率大的方向就不会在这个方向上快速的下降以至于冲过头,而是朝着一个更中庸的方向进行下降。它是一个自适应梯度算法。 AdaGrad方法特别适合稀疏数据。那稀疏数据就是指,给了一个训练集,训练集里的两个数据,它们之间的不同,更多的是体现在了特征的不同上,而不是体现在某一个具体特征上的程度不一样。比如只需要去判断某个特征到底是有还是没有,不用去考虑某一个具体的特征它的程度是多还是少,区别是人还是猫看有没有尾巴;另一种情况,都有某个具体特征,那就看毛的长短啊什么的,颜色蓝白什么的就是程度上的划分。 同理,如果咱用一个训练集去训练神经网络,最后出来的效果,判断两个不一样的分类,它们更多的是依赖特征不一样而不是某一个特征上的程度不同,那么可以称这个数据集是一个稀疏数据。如果这个训练的数据出来的效果更多的依赖某一个特征上的程度不一样,那么这个数据就不能称为稀疏数据。你想呀,如果你遇到了一个稀疏的数据,就是说明,你在某一个特征或者是某一个纬度上提供的数据就没那么充分,这时,再去求梯度下降法的话,那可能就会比较容易出现震荡的情况。如果你选择AdaGrad方法,那这个优势就会比较明显了。 其实吧,随着纬度的增加,咱遇到稀疏数据的可能性会越来越高。 不论是动量法还是AdaGrad方法,它们虽然都是基于历史数据的,都是在调整一个纬度上的变化情况,但是动量法修正的是这个计算的0次项,AdaGrad方法修正的是1此项,它们互相之间是不能替代的。这就为后来两种方法的结合提供了可能性。 优化,可以把Adagrad方法和动量法结合起来,其实真正结合的是RMSprop和动量法的结合,结合之后的算法叫做Adam方法。也可以和Nesterov方法结合。 |
①耿直哥:【梯度下降】3D可视化讲解通俗易懂_哔哩哔哩_bilibili ② 王木头:“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”,打包理解对梯度下降法的优化_哔哩哔哩_bilibili |
|

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)