更Pythonic的技术路线和工具组合(考虑兼容大、小数据量)
Grok-4给出了更Pythonic的方案:方案1: LlamaIndex + Memgraph + DGL + Unstructured + GraphRAG(推荐首选,简单上手)方案2: Haystack + ArangoDB + Spektral + PyMuPDF + spaCy(备选,更pipeline化)
更Pythonic的技术路线和工具组合
调研结论
Grok-4给出了更Pythonic的方案:
方案1: LlamaIndex + NetworkX / Memgraph + DGL + Unstructured + GraphRAG(推荐首选,简单上手)
方案2: Haystack + ArangoDB + Spektral + PyMuPDF + spaCy(备选,更pipeline化)
背景
阶段目标:
服务于应用场景:
一、涉及多模态数据源,要能从照片(文字、其它图像)、笔录、音频中准确地提取主体、关系、属性;
二、要能集成GNN(图卷积),进行深度的隐式关系挖掘和补全;
三、针对小众社交类网络, 要利用拿到的数据,进行网络结构、节点、关系、角色等针对现实的复原;
四、要利用残缺的网络信息,不断推导预测出阶段关键节点(人物)、关系变化、地点、事件及时间,作为线索提供,并针对线索给出一个价值判断和置信度判断;通过迭代持续地拓展该网络结构;
Grok-4给了2个推荐方案:
**方案1**: LlamaIndex + Neo4j/Amazon Neptune + DGL (Deep Graph Library) + Unstructured.io + GraphRAG
**方案2**: Haystack + ArangoDB + Spektral + Multimodal LLM (如Kosmos-2) + Zep/Graphiti变体
因为与最初调研结果给出的最佳方案差异较大,游移不定之际,想起,咱的技术栈以Python为主,别的语言比较弱,这个前期未曾考虑进来。这是个big problem,极其影响落地。因此,需进一步调研:考虑语言能力背景下(只擅长Python),最优方案是什么?
调研




总结
Grok-4给出了更Pythonic的方案:
方案1: LlamaIndex + Memgraph + DGL + Unstructured + GraphRAG(推荐首选,简单上手)
方案2: Haystack + ArangoDB + Spektral + PyMuPDF + spaCy(备选,更pipeline化)
一个补充调研:
回复的中间有一个说明:
如果你数据小,用纯Python的NetworkX替换Memgraph(内存图,实时快)
意味着在数据量小的情况下,NetworkX 是比 Memgraph 更优的选择。但数据量多小算小?问问逼魔道,它是这么说的:
性能比较:NetworkX适合<10万节点,Memgraph处理>百万节点无压力。 类似工具如cuGraph(GPU加速)也可参考,但Memgraph更易与NetworkX兼容。
潜在挑战:迁移需处理序列化差异,但Memgraph提供工具简化(e.g., GraphRAG示例)。 如果您的报告数据(如截图中的目录)涉及大规模网络,优先Memgraph。
本次项目面临的网络可能是不大的,因此NetworkX或许能完全覆盖。但也考虑后期别的项目可能会很大的情况下,是否Memgraph能够无缝切换??或者说,有没有工具能够让二者互通?逼魔道回答我: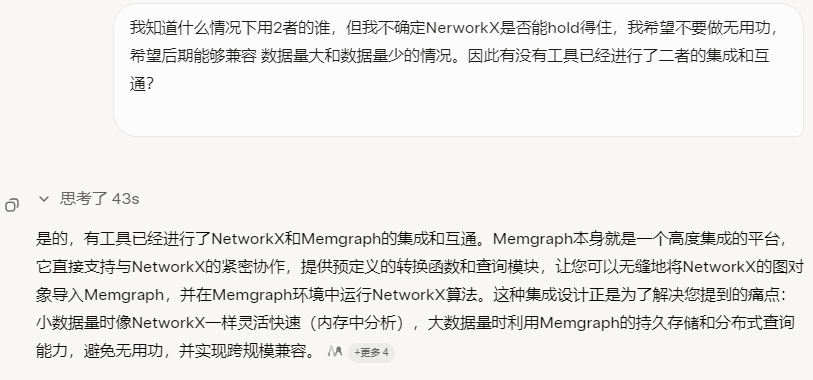

所以,二者有互通的基础,大小数据量均可解决。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)