LoRA: Low-Rank Adaptation of LLM
For Large Language Models, there are a significant numbers of parameters, such as GPT3(175B). If we want to fine-tune it to adapt mutiple downstream tasks, then we would need to retrain all the parame
Motivation
For Large Language Models, there are a significant numbers of parameters, such as GPT3(175B). If we want to fine-tune it to adapt mutiple downstream tasks, then we would need to retrain all the parameters, which will greatly waste a lot of computing resources.So this paper proposed a Low-Rank Adapation method, which freezes the pretrained models weights and inject the trainable rank decomposition matrices into each layer of transformer architecture.
Aren't the exist methods good enough?
There are two main-stream methods now. The first one is adding a new adapter, which will introduce inference latency. The another one is to optimize the prompts, which will reduce the usable prompts.
Key contribution
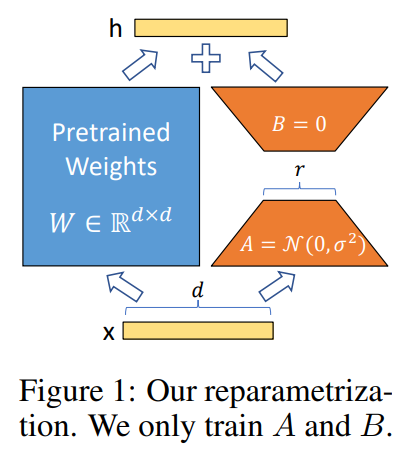
The key formula is the following one:
![]()
it will freeze the pretrained weights and decomposite latter with two low-ranks matrices.
Benefits
- 1. Make the training progress more efficient through using fewer computing resources.
- 2.It's easy to switch between different tasks by changing the BA parts while freezing the pretrained parts.
- 3.introducing no inference latency.
- 4.LoRA is an orthogonal method and can be combined with many of other technical methods, such prefix-tuning.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)