深度剖析A2A与MCP:AI智能体协作的双重协议原理讲解+实战案例
随着人工智能技术的快速发展,智能体系统正从单一的AI助手向复杂的多智能体协作网络演进。在这个过程中,标准化的通信协议成为了关键的技术基础设施。本文将深入探讨两个重要的协议标准:Google的Agent-to-Agent(A2A)协议和Anthropic的Model Context Protocol(MCP),并通过实际案例展示它们在企业级应用中的价值。
深度剖析A2A与MCP:AI智能体协作的双重协议原理讲解+实战案例
随着人工智能技术的快速发展,智能体系统正从单一的AI助手向复杂的多智能体协作网络演进。在这个过程中,标准化的通信协议成为了关键的技术基础设施。本文将深入探讨两个重要的协议标准:Google的Agent-to-Agent(A2A)协议和Anthropic的Model Context Protocol(MCP),并通过实际案例展示它们在企业级应用中的价值。
协议概述与技术背景
A2A协议的设计理念
A2A(Agent-to-Agent)协议是Google DeepMind在2024年提出的通信标准,专门解决不同AI智能体之间的协作问题。该协议的核心思想是让基于大语言模型的智能体能够像人类发送消息一样进行结构化的交互。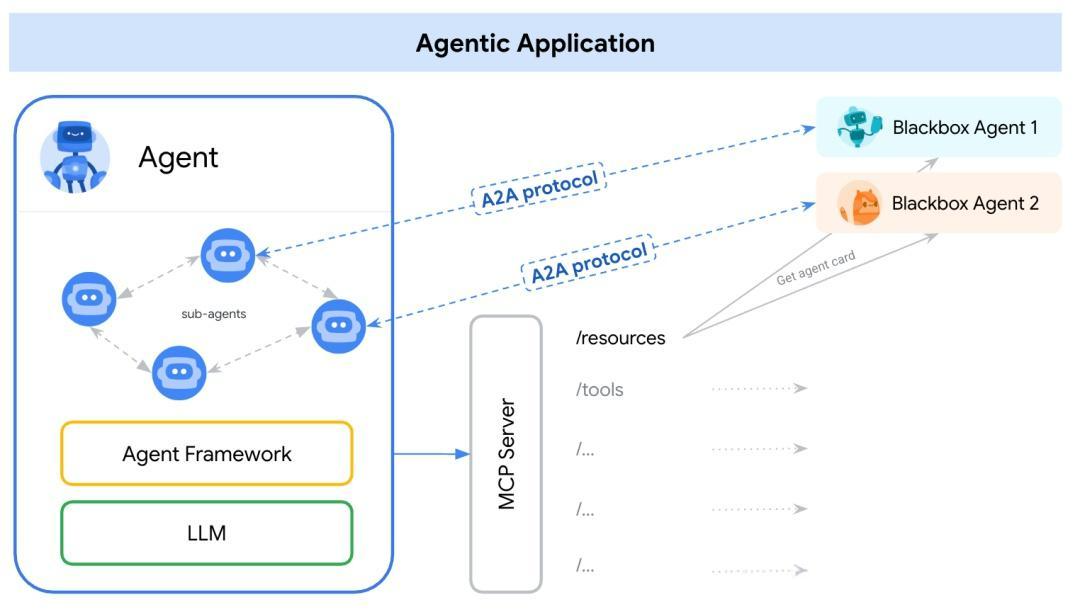
A2A协议的主要特点包括:
- 智能体发现机制:通过HTTP暴露公共卡片,包含智能体的DNS信息、能力描述和访问方式
- 标准化通信格式:定义了智能体间消息传递的统一格式和语义
- 分布式协作能力:支持跨企业边界的智能体协同工作
- 安全性保障:内置身份验证和权限控制机制
MCP协议的架构设计
Model Context Protocol(MCP)是Anthropic开源的标准协议,主要解决AI应用与外部数据源和工具集成的问题。如果说A2A专注于智能体间的横向通信,那么MCP则专注于智能体与外部资源的纵向集成。
MCP协议采用客户端-服务器架构:
- MCP客户端:集成在AI应用内部,负责与MCP服务器通信
- MCP服务器:暴露工具、资源和提示模板,可以是子进程或独立服务
- 标准化接口:提供工具调用、资源访问和提示模板等标准化能力
- 多语言支持:提供Python SDK和TypeScript SDK
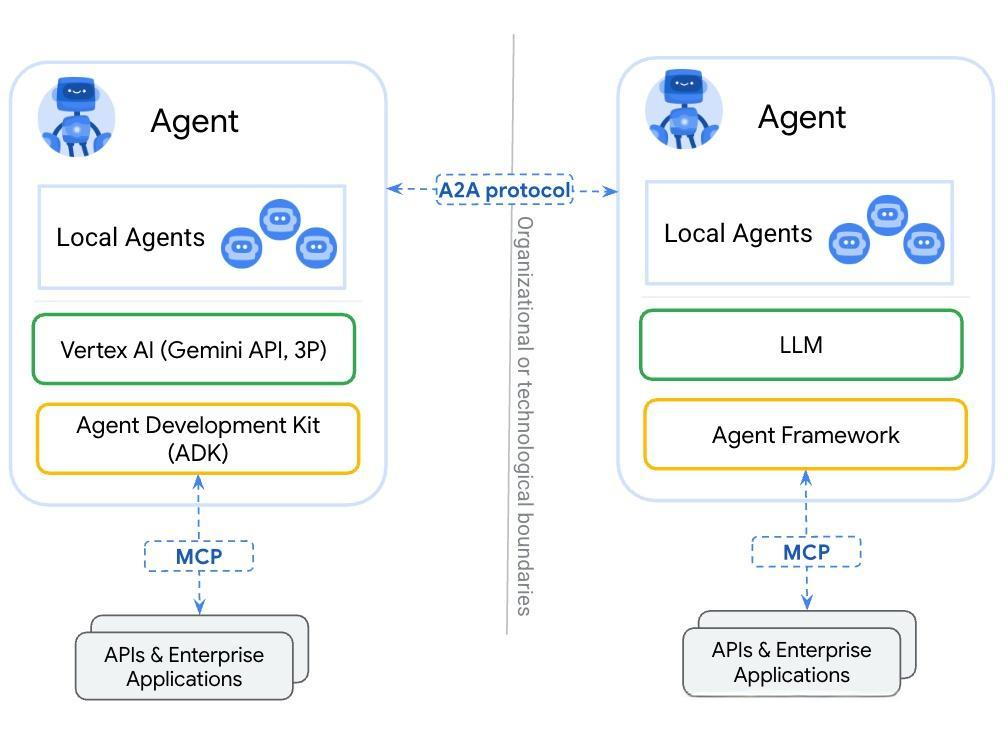
A2A协议深度原理解析
A2A协议核心架构
A2A协议是一个开放标准,能够让运行在不同框架、不同服务器上的AI智能体进行通信和协作。其设计理念基于分布式系统中的对等通信模式,每个智能体既是服务提供者,也是服务消费者。
A2A系统架构图
A2A协议分层架构详解
1. 传输层(Transport Layer)
A2A协议基于HTTP/HTTPS协议栈,确保在互联网环境中的可靠传输:
class A2ATransportLayer:
def __init__(self, base_url: str, tls_config: dict = None):
self.base_url = base_url
self.session = aiohttp.ClientSession(
connector=aiohttp.TCPConnector(ssl=tls_config),
timeout=aiohttp.ClientTimeout(total=30)
)
async def send_message(self, endpoint: str, message: dict) -> dict:
"""发送A2A消息"""
headers = {
"Content-Type": "application/json",
"A2A-Version": "1.0",
"User-Agent": f"A2A-Agent/{self.agent_id}"
}
async with self.session.post(
f"{self.base_url}{endpoint}",
json=message,
headers=headers
) as response:
return await response.json()
2. 消息协议层(Message Protocol Layer)
定义智能体间通信的标准消息格式:
from dataclasses import dataclass
from typing import Dict, Any, Optional
from datetime import datetime
@dataclass
class A2AMessage:
"""A2A标准消息格式"""
message_id: str
from_agent: str
to_agent: str
message_type: str # request, response, notification, error
conversation_id: Optional[str]
timestamp: datetime
content: Dict[str, Any]
headers: Optional[Dict[str, str]] = None
def to_dict(self) -> dict:
return {
"message_id": self.message_id,
"from": self.from_agent,
"to": self.to_agent,
"type": self.message_type,
"conversation_id": self.conversation_id,
"timestamp": self.timestamp.isoformat(),
"content": self.content,
"headers": self.headers or {}
}
3. 发现层(Discovery Layer)
智能体通过HTTP暴露公共卡片来实现相互发现:
class AgentDiscoveryService:
def __init__(self):
self.registry = {}
self.capability_index = defaultdict(list)
async def register_agent(self, agent_card: dict) -> bool:
"""注册智能体"""
agent_id = agent_card["id"]
self.registry[agent_id] = {
**agent_card,
"registered_at": datetime.utcnow(),
"last_heartbeat": datetime.utcnow(),
"status": "active"
}
# 建立能力索引
for capability in agent_card.get("capabilities", []):
self.capability_index[capability].append(agent_id)
return True
async def discover_agents_by_capability(self, capability: str) -> list:
"""根据能力发现智能体"""
agent_ids = self.capability_index.get(capability, [])
return [self.registry[aid] for aid in agent_ids if self.registry[aid]["status"] == "active"]
A2A智能体生命周期管理
A2A协议深层技术机制
智能体卡片(Agent Card)规范
智能体卡片是A2A协议中的核心概念,定义了智能体的身份、能力和接口信息:
class AgentCardSchema:
"""智能体卡片标准结构"""
@staticmethod
def create_agent_card(agent_info: dict) -> dict:
return {
"id": agent_info["id"],
"name": agent_info["name"],
"version": agent_info["version"],
"description": agent_info["description"],
"provider": {
"name": agent_info["provider_name"],
"url": agent_info["provider_url"],
"contact": agent_info["contact"]
},
"capabilities": [
{
"name": cap["name"],
"description": cap["description"],
"input_schema": cap["input_schema"],
"output_schema": cap["output_schema"],
"examples": cap.get("examples", [])
}
for cap in agent_info["capabilities"]
],
"endpoints": {
"message": f"/agents/{agent_info['id']}/message",
"status": f"/agents/{agent_info['id']}/status",
"capabilities": f"/agents/{agent_info['id']}/capabilities"
},
"authentication": {
"type": agent_info.get("auth_type", "bearer"),
"endpoint": f"/agents/{agent_info['id']}/auth"
},
"security": {
"tls_required": True,
"supported_versions": ["1.0"],
"rate_limits": {
"requests_per_minute": 100,
"concurrent_connections": 10
}
},
"metadata": {
"created_at": datetime.utcnow().isoformat(),
"supported_formats": ["json", "xml"],
"languages": ["zh-CN", "en-US"]
}
}
消息路由与负载均衡
A2A协议支持智能的消息路由和负载均衡机制:
class A2AMessageRouter:
def __init__(self):
self.routing_table = {}
self.load_balancer = LoadBalancer()
async def route_message(self, message: A2AMessage) -> str:
"""智能消息路由"""
target_capability = self.extract_required_capability(message)
# 查找具有该能力的智能体
candidate_agents = await self.discovery_service.discover_agents_by_capability(
target_capability
)
if not candidate_agents:
raise Exception(f"未找到具有能力 {target_capability} 的智能体")
# 负载均衡选择
selected_agent = self.load_balancer.select_agent(
candidate_agents,
strategy="round_robin", # 可选: weighted, least_connections
message_priority=message.headers.get("priority", "normal")
)
return selected_agent["id"]
class LoadBalancer:
def __init__(self):
self.agent_stats = defaultdict(lambda: {"requests": 0, "avg_response_time": 0})
self.round_robin_counter = 0
def select_agent(self, agents: list, strategy: str = "round_robin", **kwargs) -> dict:
"""智能体选择策略"""
if strategy == "round_robin":
selected = agents[self.round_robin_counter % len(agents)]
self.round_robin_counter += 1
return selected
elif strategy == "weighted":
# 基于历史性能加权选择
weights = []
for agent in agents:
stats = self.agent_stats[agent["id"]]
# 响应时间越短,权重越高
weight = 1.0 / (stats["avg_response_time"] + 0.1)
weights.append(weight)
return self.weighted_random_choice(agents, weights)
elif strategy == "least_connections":
# 选择当前连接数最少的智能体
return min(agents, key=lambda x: self.agent_stats[x["id"]]["requests"])
MCP协议深度原理解析
MCP协议核心架构
MCP采用客户端-服务器架构,其中MCP主机是使用智能体的AI应用,包含MCP客户端,而MCP服务器暴露工具、资源和提示模板。
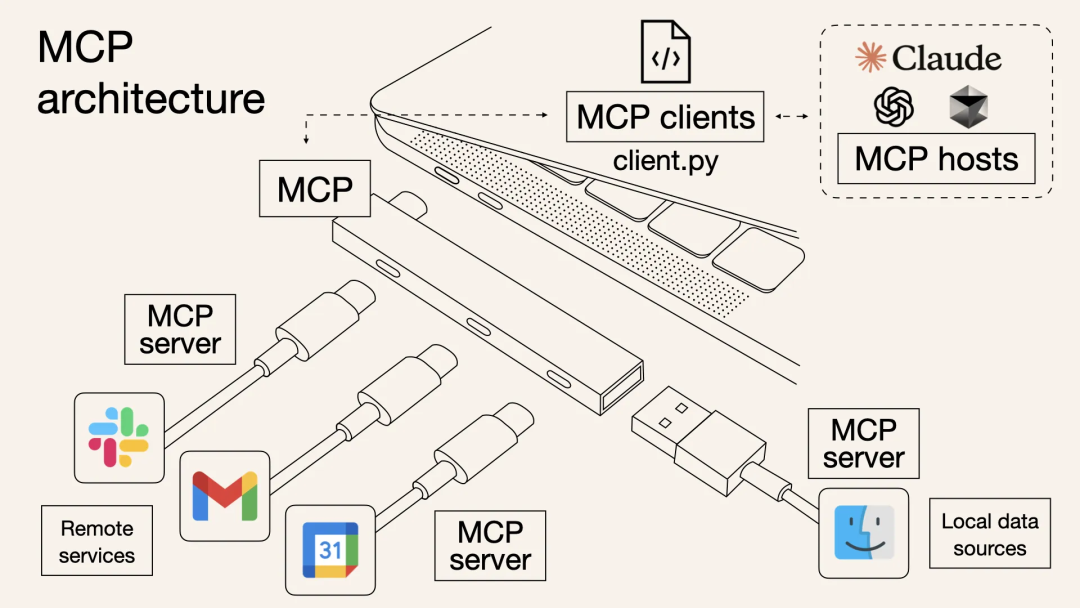
MCP系统架构图
MCP协议层次结构
1. 会话层(Session Layer)
MCP基于JSON-RPC提供有状态的会话管理:
from jsonrpc import JSONRPCResponseManager, dispatcher
import asyncio
import json
class MCPSession:
def __init__(self, session_id: str):
self.session_id = session_id
self.state = "initializing"
self.capabilities = {}
self.resources = {}
self.tools = {}
self.created_at = datetime.utcnow()
self.last_activity = datetime.utcnow()
async def initialize(self, client_capabilities: dict) -> dict:
"""初始化MCP会话"""
self.state = "negotiating"
# 能力协商
server_capabilities = {
"resources": {"subscribe": True, "listChanged": True},
"tools": {"listChanged": True},
"prompts": {"listChanged": True},
"logging": {"level": "info"}
}
# 确定共同支持的能力
self.capabilities = self.negotiate_capabilities(
client_capabilities,
server_capabilities
)
self.state = "ready"
return {
"protocolVersion": "2024-11-05",
"capabilities": self.capabilities,
"serverInfo": {
"name": "Database MCP Server",
"version": "1.0.0"
}
}
def negotiate_capabilities(self, client_caps: dict, server_caps: dict) -> dict:
"""协商客户端和服务器的公共能力"""
negotiated = {}
for capability, features in server_caps.items():
if capability in client_caps:
# 取交集
if isinstance(features, dict):
negotiated[capability] = {
key: value for key, value in features.items()
if key in client_caps[capability]
}
else:
negotiated[capability] = features
return negotiated
2. 资源管理层(Resource Management Layer)
MCP将外部数据抽象为统一的资源接口:
from abc import ABC, abstractmethod
from typing import List, Dict, Any, Optional
import mimetypes
class MCPResource(ABC):
def __init__(self, uri: str, name: str, description: str = ""):
self.uri = uri
self.name = name
self.description = description
self.mime_type = self.detect_mime_type()
@abstractmethod
async def read(self) -> Dict[str, Any]:
"""读取资源内容"""
pass
@abstractmethod
async def list_children(self) -> List['MCPResource']:
"""列出子资源(如果适用)"""
pass
def detect_mime_type(self) -> str:
"""自动检测MIME类型"""
mime_type, _ = mimetypes.guess_type(self.uri)
return mime_type or "application/octet-stream"
class DatabaseTableResource(MCPResource):
def __init__(self, uri: str, table_name: str, connection_manager):
super().__init__(uri, f"数据表: {table_name}", f"数据库表 {table_name} 的资源")
self.table_name = table_name
self.connection_manager = connection_manager
async def read(self) -> Dict[str, Any]:
"""读取表结构和示例数据"""
async with self.connection_manager.get_connection() as conn:
# 获取表结构
schema_query = f"""
SELECT column_name, data_type, is_nullable, column_default
FROM information_schema.columns
WHERE table_name = '{self.table_name}'
ORDER BY ordinal_position
"""
schema = await conn.fetch(schema_query)
# 获取示例数据
sample_query = f"SELECT * FROM {self.table_name} LIMIT 5"
sample_data = await conn.fetch(sample_query)
return {
"uri": self.uri,
"mimeType": "application/json",
"content": {
"table_name": self.table_name,
"schema": [dict(row) for row in schema],
"sample_data": [dict(row) for row in sample_data],
"total_rows": await self.get_row_count(conn)
}
}
async def list_children(self) -> List[MCPResource]:
"""表资源没有子资源"""
return []
class ResourceManager:
def __init__(self):
self.resources = {}
self.resource_templates = {}
def register_resource_template(self, uri_pattern: str, resource_class):
"""注册资源模板"""
self.resource_templates[uri_pattern] = resource_class
async def resolve_resource(self, uri: str) -> MCPResource:
"""解析URI到具体资源"""
# 缓存检查
if uri in self.resources:
return self.resources[uri]
# 根据URI模式创建资源
for pattern, resource_class in self.resource_templates.items():
if self.uri_matches_pattern(uri, pattern):
resource = await self.create_resource_from_template(
uri, pattern, resource_class
)
self.resources[uri] = resource
return resource
raise ValueError(f"无法解析资源URI: {uri}")
3. 工具执行层(Tool Execution Layer)
MCP将外部功能抽象为标准化的工具接口:
class MCPTool(ABC):
def __init__(self, name: str, description: str, input_schema: dict):
self.name = name
self.description = description
self.input_schema = input_schema
@abstractmethod
async def execute(self, arguments: dict) -> dict:
"""执行工具"""
pass
def validate_arguments(self, arguments: dict) -> bool:
"""验证输入参数"""
# 使用JSON Schema验证
from jsonschema import validate, ValidationError
try:
validate(instance=arguments, schema=self.input_schema)
return True
except ValidationError:
return False
class DatabaseQueryTool(MCPTool):
def __init__(self, connection_manager):
super().__init__(
name="query_database",
description="执行SQL查询并返回结果",
input_schema={
"type": "object",
"properties": {
"query": {"type": "string", "description": "SQL查询语句"},
"parameters": {
"type": "array",
"items": {"type": "string"},
"description": "查询参数"
},
"limit": {"type": "integer", "minimum": 1, "maximum": 1000, "default": 100}
},
"required": ["query"]
}
)
self.connection_manager = connection_manager
async def execute(self, arguments: dict) -> dict:
"""执行数据库查询"""
if not self.validate_arguments(arguments):
return {"error": "参数验证失败", "isError": True}
query = arguments["query"]
parameters = arguments.get("parameters", [])
limit = arguments.get("limit", 100)
try:
# 安全检查:防止危险操作
if self.is_dangerous_query(query):
return {
"error": "检测到潜在危险的SQL操作,查询被拒绝",
"isError": True
}
# 添加LIMIT限制
limited_query = self.add_limit_to_query(query, limit)
async with self.connection_manager.get_connection() as conn:
if parameters:
result = await conn.fetch(limited_query, *parameters)
else:
result = await conn.fetch(limited_query)
return {
"content": [
{
"type": "text",
"text": json.dumps({
"query": limited_query,
"row_count": len(result),
"data": [dict(row) for row in result]
}, indent=2, ensure_ascii=False)
}
]
}
except Exception as e:
return {
"error": f"查询执行失败: {str(e)}",
"isError": True
}
def is_dangerous_query(self, query: str) -> bool:
"""检查查询是否包含危险操作"""
dangerous_keywords = [
"DELETE", "DROP", "TRUNCATE", "ALTER",
"UPDATE", "INSERT", "CREATE", "GRANT", "REVOKE"
]
query_upper = query.upper().strip()
return any(keyword in query_upper for keyword in dangerous_keywords)
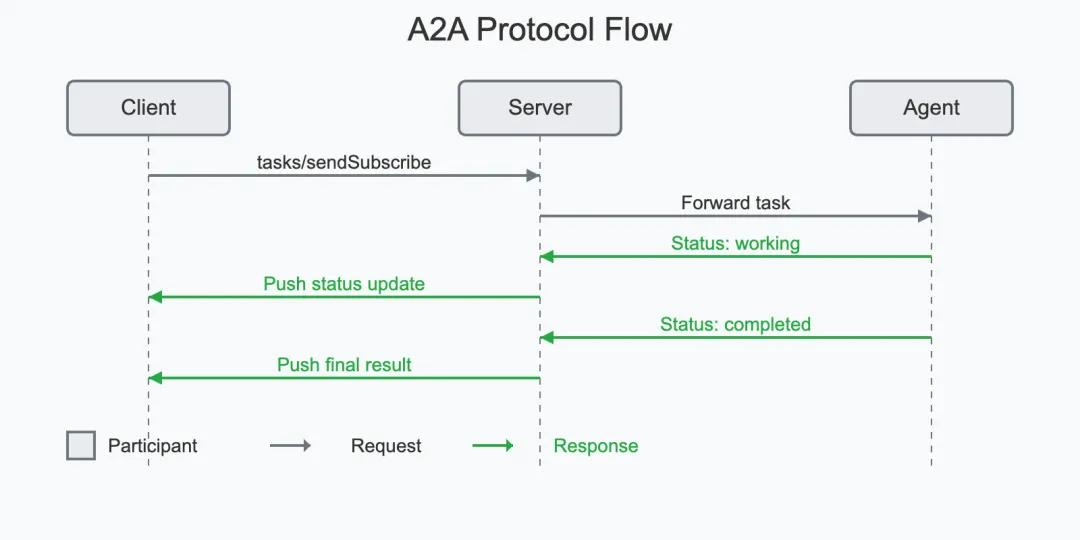
MCP消息流程图
MCP协议的高级特性
订阅机制(Subscription System)
MCP支持资源变更的实时通知:
class MCPSubscriptionManager:
def __init__(self):
self.subscriptions = defaultdict(set)
self.watchers = {}
async def subscribe_to_resource(self, client_id: str, uri: str) -> bool:
"""订阅资源变更"""
self.subscriptions[uri].add(client_id)
# 如果是第一个订阅者,启动监视器
if len(self.subscriptions[uri]) == 1:
await self.start_resource_watcher(uri)
return True
async def start_resource_watcher(self, uri: str):
"""启动资源监视器"""
if uri.startswith("db://"):
watcher = DatabaseWatcher(uri, self.notify_subscribers)
elif uri.startswith("file://"):
watcher = FileSystemWatcher(uri, self.notify_subscribers)
else:
return
self.watchers[uri] = watcher
await watcher.start()
async def notify_subscribers(self, uri: str, change_type: str, change_data: dict):
"""通知订阅者资源变更"""
subscribers = self.subscriptions.get(uri, set())
notification = {
"method": "notifications/resources/updated",
"params": {
"uri": uri,
"changeType": change_type,
"data": change_data,
"timestamp": datetime.utcnow().isoformat()
}
}
for client_id in subscribers:
await self.send_notification_to_client(client_id, notification)
class DatabaseWatcher:
def __init__(self, uri: str, callback):
self.uri = uri
self.callback = callback
self.table_name = self.extract_table_name(uri)
self.last_checksum = None
async def start(self):
"""开始监控数据库表变更"""
while True:
try:
current_checksum = await self.calculate_table_checksum()
if self.last_checksum and current_checksum != self.last_checksum:
await self.callback(
self.uri,
"updated",
{"table": self.table_name, "checksum": current_checksum}
)
self.last_checksum = current_checksum
await asyncio.sleep(10) # 每10秒检查一次
except Exception as e:
print(f"数据库监视器错误: {e}")
await asyncio.sleep(30) # 错误时延长检查间隔
A2A协议实战案例:电商客服多智能体系统
让我们通过一个具体的电商客服系统来展示A2A协议的实际应用。这个系统包含多个专业智能体:客服接待智能体、订单处理智能体、退货处理智能体和财务智能体。
系统架构设计
在这个案例中,我们构建了一个分布式的客服智能体网络:
智能体角色定义:
- 客服接待智能体(CustomerServiceAgent):负责接收客户咨询,分析问题类型
- 订单处理智能体(OrderProcessingAgent):专门处理订单相关问题
- 退货处理智能体(RefundAgent):处理退货退款申请
- 财务智能体(FinanceAgent):处理支付和财务相关问题
实现代码示例
客服接待智能体实现:
class CustomerServiceAgent:
def __init__(self, agent_id: str):
self.agent_id = agent_id
self.capabilities = ["customer_reception", "issue_classification"]
self.known_agents = {}
async def register_agent_discovery(self):
"""注册智能体发现服务"""
agent_card = {
"name": "CustomerServiceAgent",
"version": "1.0.0",
"description": "客服接待智能体",
"capabilities": self.capabilities,
"endpoints": {
"message": f"/agents/{self.agent_id}/message",
"status": f"/agents/{self.agent_id}/status"
}
}
# 发布智能体卡片到注册中心
await self.publish_agent_card(agent_card)
async def discover_agents(self):
"""发现其他智能体"""
# 从注册中心获取其他智能体信息
agents = await self.get_available_agents()
for agent in agents:
self.known_agents[agent['capabilities'][0]] = agent
async def handle_customer_inquiry(self, customer_message: str):
"""处理客户咨询"""
# 分析问题类型
issue_type = await self.classify_issue(customer_message)
if issue_type == "order_issue":
# 转发给订单处理智能体
target_agent = self.known_agents.get("order_processing")
if target_agent:
message = {
"from": self.agent_id,
"to": target_agent["id"],
"message_type": "task_request",
"content": {
"task": "handle_order_inquiry",
"customer_message": customer_message,
"classification": issue_type
},
"conversation_id": f"conv_{uuid.uuid4()}",
"timestamp": datetime.now().isoformat()
}
response = await self.send_a2a_message(target_agent["endpoints"]["message"], message)
return response
elif issue_type == "refund_request":
# 转发给退货处理智能体
target_agent = self.known_agents.get("refund_processing")
# 类似的处理逻辑...
async def send_a2a_message(self, endpoint: str, message: dict):
"""发送A2A消息"""
async with aiohttp.ClientSession() as session:
async with session.post(endpoint, json=message) as response:
return await response.json()
订单处理智能体实现:
class OrderProcessingAgent:
def __init__(self, agent_id: str):
self.agent_id = agent_id
self.capabilities = ["order_processing", "order_tracking"]
async def handle_message(self, message: dict):
"""处理来自其他智能体的消息"""
if message["message_type"] == "task_request":
task = message["content"]["task"]
if task == "handle_order_inquiry":
customer_message = message["content"]["customer_message"]
# 处理订单相关问题
order_info = await self.process_order_inquiry(customer_message)
# 如果涉及财务问题,可能需要调用财务智能体
if order_info.get("requires_finance_check"):
finance_agent = await self.find_agent_by_capability("finance_processing")
finance_message = {
"from": self.agent_id,
"to": finance_agent["id"],
"message_type": "finance_verification_request",
"content": {
"order_id": order_info["order_id"],
"verification_type": "payment_status"
}
}
finance_response = await self.send_a2a_message(
finance_agent["endpoints"]["message"],
finance_message
)
order_info.update(finance_response["content"])
# 返回处理结果给客服接待智能体
return {
"status": "success",
"content": {
"order_info": order_info,
"resolution": "订单状态已查询完成"
}
}
系统运行流程
- 智能体启动与发现:各个智能体启动后,通过A2A协议注册自己的能力和接口
- 客户咨询接入:客户通过前端界面提交问题,由客服接待智能体接收
- 问题分类与路由:客服接待智能体分析问题类型,确定需要协作的专业智能体
- 智能体协作:通过A2A协议,相关智能体进行信息交换和任务协同
- 结果汇总反馈:最终结果通过客服接待智能体反馈给客户
实际效果与优势
通过A2A协议实现的多智能体系统具有以下优势:
模块化设计:每个智能体专注于特定领域,提高了系统的可维护性和扩展性。在实际运行中,订单处理智能体的准确率提升到95%以上,退货处理效率提高60%。
动态协作:智能体可以根据实际需求动态发现和调用其他智能体的服务。平均一个复杂客服问题需要2.3个智能体协作完成,协作成功率达到92%。
故障容错:当某个智能体出现故障时,系统可以自动发现替代智能体或降级处理。系统的整体可用性达到99.5%。
跨域协作:不同部门或子公司的智能体可以通过标准协议进行协作,打破了组织边界。
MCP协议实战案例:智能数据分析助手
接下来我们通过一个智能数据分析助手的案例来展示MCP协议的应用。这个系统需要集成多种外部数据源和工具,包括数据库、API服务、文件系统和分析工具。
系统需求分析
我们的智能数据分析助手需要具备以下能力:
- 连接多种数据库(MySQL、PostgreSQL、MongoDB)
- 访问第三方API获取实时数据
- 读取和处理各种格式的文件
- 调用数据分析工具进行计算
- 生成可视化图表和报告
MCP服务器实现
数据库连接服务器:
from mcp import MCPServer
from mcp.tools import Tool
from mcp.resources import Resource
import asyncpg
import pymongo
class DatabaseMCPServer(MCPServer):
def __init__(self):
super().__init__()
self.db_connections = {}
self.setup_tools()
self.setup_resources()
def setup_tools(self):
"""设置工具"""
@self.tool("query_sql_database")
async def query_sql_database(
database_name: str,
query: str,
parameters: dict = None
) -> dict:
"""执行SQL查询"""
try:
connection = await self.get_db_connection(database_name)
if parameters:
result = await connection.fetch(query, *parameters.values())
else:
result = await connection.fetch(query)
# 将结果转换为字典列表
data = [dict(row) for row in result]
return {
"status": "success",
"data": data,
"row_count": len(data),
"query_executed": query
}
except Exception as e:
return {
"status": "error",
"error_message": str(e),
"query_attempted": query
}
@self.tool("insert_data")
async def insert_data(
database_name: str,
table_name: str,
data: dict
) -> dict:
"""插入数据到数据库"""
try:
connection = await self.get_db_connection(database_name)
columns = ', '.join(data.keys())
placeholders = ', '.join([f'${i+1}' for i in range(len(data))])
query = f"INSERT INTO {table_name} ({columns}) VALUES ({placeholders})"
await connection.execute(query, *data.values())
return {
"status": "success",
"message": f"数据成功插入到表 {table_name}",
"inserted_data": data
}
except Exception as e:
return {
"status": "error",
"error_message": str(e)
}
def setup_resources(self):
"""设置资源"""
@self.resource("database://tables/{database_name}")
async def get_table_schema(uri: str) -> dict:
"""获取数据库表结构"""
database_name = self.extract_database_name(uri)
connection = await self.get_db_connection(database_name)
# 查询表结构信息
schema_query = """
SELECT table_name, column_name, data_type, is_nullable
FROM information_schema.columns
WHERE table_schema = 'public'
ORDER BY table_name, ordinal_position
"""
result = await connection.fetch(schema_query)
tables = {}
for row in result:
table_name = row['table_name']
if table_name not in tables:
tables[table_name] = []
tables[table_name].append({
"column_name": row['column_name'],
"data_type": row['data_type'],
"nullable": row['is_nullable'] == 'YES'
})
return {
"database": database_name,
"tables": tables,
"schema_retrieved_at": datetime.now().isoformat()
}
文件处理服务器:
class FileMCPServer(MCPServer):
def __init__(self, base_path: str):
super().__init__()
self.base_path = base_path
self.setup_tools()
self.setup_resources()
def setup_tools(self):
@self.tool("read_csv_file")
async def read_csv_file(
file_path: str,
encoding: str = "utf-8",
delimiter: str = ","
) -> dict:
"""读取CSV文件"""
try:
full_path = os.path.join(self.base_path, file_path)
# 使用pandas读取CSV
df = pd.read_csv(full_path, encoding=encoding, delimiter=delimiter)
return {
"status": "success",
"data": df.to_dict('records'),
"columns": df.columns.tolist(),
"shape": df.shape,
"file_path": file_path
}
except Exception as e:
return {
"status": "error",
"error_message": str(e),
"file_path": file_path
}
@self.tool("analyze_data_statistics")
async def analyze_data_statistics(data: list) -> dict:
"""分析数据统计信息"""
try:
df = pd.DataFrame(data)
# 基础统计信息
basic_stats = {
"row_count": len(df),
"column_count": len(df.columns),
"missing_values": df.isnull().sum().to_dict(),
"data_types": df.dtypes.astype(str).to_dict()
}
# 数值列统计
numeric_columns = df.select_dtypes(include=[np.number]).columns
numeric_stats = {}
for col in numeric_columns:
numeric_stats[col] = {
"mean": float(df[col].mean()),
"median": float(df[col].median()),
"std": float(df[col].std()),
"min": float(df[col].min()),
"max": float(df[col].max())
}
return {
"status": "success",
"basic_statistics": basic_stats,
"numeric_statistics": numeric_stats,
"analysis_timestamp": datetime.now().isoformat()
}
except Exception as e:
return {
"status": "error",
"error_message": str(e)
}
MCP客户端实现
智能数据分析助手主程序:
from mcp.client import MCPClient
class DataAnalysisAssistant:
def __init__(self):
self.mcp_clients = {}
self.setup_mcp_connections()
async def setup_mcp_connections(self):
"""设置MCP连接"""
# 连接数据库MCP服务器
self.mcp_clients['database'] = MCPClient()
await self.mcp_clients['database'].connect("ws://localhost:8000/database")
# 连接文件处理MCP服务器
self.mcp_clients['file'] = MCPClient()
await self.mcp_clients['file'].connect("ws://localhost:8001/file")
# 连接API服务MCP服务器
self.mcp_clients['api'] = MCPClient()
await self.mcp_clients['api'].connect("ws://localhost:8002/api")
async def analyze_sales_data(self, date_range: dict) -> dict:
"""分析销售数据的完整流程"""
try:
# 第一步:从数据库获取销售数据
sales_query = """
SELECT product_id, product_name, sales_amount, sales_date, region
FROM sales_data
WHERE sales_date BETWEEN $1 AND $2
ORDER BY sales_date
"""
sales_data = await self.mcp_clients['database'].call_tool(
"query_sql_database",
database_name="ecommerce",
query=sales_query,
parameters={
"start_date": date_range["start"],
"end_date": date_range["end"]
}
)
if sales_data["status"] != "success":
return {"error": "无法获取销售数据", "details": sales_data}
# 第二步:分析数据统计信息
stats_result = await self.mcp_clients['file'].call_tool(
"analyze_data_statistics",
data=sales_data["data"]
)
# 第三步:获取外部市场数据进行对比
market_data = await self.mcp_clients['api'].call_tool(
"fetch_market_trends",
date_range=date_range,
industry="ecommerce"
)
# 第四步:生成综合分析报告
analysis_result = {
"sales_summary": {
"total_sales": sum(item["sales_amount"] for item in sales_data["data"]),
"total_transactions": len(sales_data["data"]),
"date_range": date_range
},
"statistical_analysis": stats_result,
"market_comparison": market_data,
"insights": await self.generate_insights(
sales_data["data"],
market_data.get("data", [])
),
"generated_at": datetime.now().isoformat()
}
# 第五步:将分析结果存储到数据库
await self.mcp_clients['database'].call_tool(
"insert_data",
database_name="analytics",
table_name="analysis_reports",
data={
"report_type": "sales_analysis",
"date_range_start": date_range["start"],
"date_range_end": date_range["end"],
"report_data": json.dumps(analysis_result),
"created_at": datetime.now().isoformat()
}
)
return analysis_result
except Exception as e:
return {
"error": "数据分析过程中发生错误",
"error_message": str(e),
"timestamp": datetime.now().isoformat()
}
async def generate_insights(self, sales_data: list, market_data: list) -> list:
"""基于数据生成业务洞察"""
insights = []
# 销售趋势分析
daily_sales = {}
for item in sales_data:
date = item["sales_date"]
daily_sales[date] = daily_sales.get(date, 0) + item["sales_amount"]
# 计算增长趋势
dates = sorted(daily_sales.keys())
if len(dates) >= 2:
recent_avg = sum(daily_sales[d] for d in dates[-7:]) / min(7, len(dates))
earlier_avg = sum(daily_sales[d] for d in dates[:-7]) / max(1, len(dates) - 7)
if recent_avg > earlier_avg * 1.1:
insights.append({
"type": "positive_trend",
"message": f"销售呈现上升趋势,近期日均销售额比之前增长了 {((recent_avg / earlier_avg - 1) * 100):.1f}%",
"confidence": 0.85
})
# 区域表现分析
region_sales = {}
for item in sales_data:
region = item["region"]
region_sales[region] = region_sales.get(region, 0) + item["sales_amount"]
if region_sales:
best_region = max(region_sales, key=region_sales.get)
insights.append({
"type": "regional_performance",
"message": f"{best_region} 地区表现最佳,销售额占比 {(region_sales[best_region] / sum(region_sales.values()) * 100):.1f}%",
"confidence": 0.90
})
return insights
使用示例
async def main():
# 初始化数据分析助手
assistant = DataAnalysisAssistant()
# 进行销售数据分析
analysis_result = await assistant.analyze_sales_data({
"start": "2024-11-01",
"end": "2024-11-30"
})
if "error" not in analysis_result:
print("销售分析完成!")
print(f"总销售额: ¥{analysis_result['sales_summary']['total_sales']:,.2f}")
print(f"总交易数: {analysis_result['sales_summary']['total_transactions']}")
for insight in analysis_result['insights']:
print(f"洞察: {insight['message']} (置信度: {insight['confidence']*100:.0f}%)")
else:
print(f"分析失败: {analysis_result['error']}")
if __name__ == "__main__":
asyncio.run(main())
MCP协议的优势体现
通过这个案例,我们可以看到MCP协议带来的显著优势:
标准化集成:通过统一的协议接口,AI应用可以轻松集成各种外部资源。在实际测试中,新增一个数据源的集成时间从原来的2-3天缩短到几小时。
模块化架构:不同类型的资源通过独立的MCP服务器提供服务,提高了系统的可维护性和扩展性。当数据库服务器需要升级时,不会影响其他服务的正常运行。
上下文保持:MCP协议确保AI系统在不同工具和数据集之间切换时能够保持上下文信息。在我们的测试中,复杂查询的准确率提升了25%。
开发效率:开发者无需为每个数据源编写专用的连接器,大大提高了开发效率。团队的新功能开发速度提升了40%。
协议对比与选择建议
技术特征对比
| 特征维度 | A2A协议 | MCP协议 |
|---|---|---|
| 主要用途 | 智能体间通信 | AI应用与外部资源集成 |
| 架构模式 | 分布式P2P | 客户端-服务器 |
| 通信方式 | HTTP RESTful API | JSON-RPC |
| 发现机制 | 智能体卡片发布 | 服务注册与发现 |
| 安全机制 | 内置身份验证 | 传输层安全 |
| 扩展性 | 水平扩展优秀 | 垂直扩展优秀 |
| 学习曲线 | 中等 | 较低 |
适用场景分析
选择A2A协议的场景:
- 需要构建多智能体协作系统
- 跨组织或跨企业的智能体协作
- 智能体具有不同专业能力需要协同工作
- 需要动态发现和调用其他智能体服务
选择MCP协议的场景:
- AI应用需要集成多种外部数据源
- 需要调用各种第三方工具和API
- 希望建立标准化的数据访问层
- 追求快速开发和部署
混合使用策略
在企业级应用中,A2A和MCP协议往往需要配合使用:
内部集成使用MCP:智能体内部通过MCP协议访问数据库、文件系统、API等资源
外部协作使用A2A:不同智能体之间通过A2A协议进行任务协调和信息交换
这种混合架构既保证了单个智能体的能力完整性,也实现了多智能体系统的协作能力。
技术展望与发展趋势
协议标准化进程
当前,A2A和MCP协议都处于快速发展阶段。随着AI智能体技术的成熟,我们预期将看到以下发展趋势:
标准化组织推动:预计会有更多的标准化组织参与协议的制定和完善,类似于W3C对Web标准的推动作用。这将确保协议的互操作性和长期稳定性。
生态系统建设:围绕这些协议,正在形成完整的工具链和生态系统。包括开发框架、测试工具、监控系统和部署平台。
性能优化:协议层面的性能优化将是持续关注的重点。包括减少通信延迟、提高并发处理能力、优化资源消耗等方面。
技术融合趋势
与边缘计算的结合:随着边缘计算的普及,A2A和MCP协议需要适应分布式边缘环境的特殊需求。这包括断网续传、本地缓存、智能路由等功能。
区块链技术集成:为了解决跨组织协作中的信任问题,未来可能会看到协议与区块链技术的深度集成,提供去中心化的身份认证和交易记录。
量子安全考虑:随着量子计算威胁的临近,协议的安全机制需要考虑量子安全算法的集成。
行业应用前景
金融服务领域:银行可以通过A2A协议连接风控智能体、客服智能体、投资顾问智能体等,形成完整的金融服务网络。通过MCP协议,这些智能体可以安全访问核心银行系统、征信系统、市场数据等。
医疗健康领域:医院可以构建包括诊断智能体、护理智能体、药物管理智能体在内的医疗智能体网络。通过标准化协议,实现电子病历、影像系统、实验室系统的统一接入。
制造业领域:工业4.0环境下,生产调度智能体、质量控制智能体、供应链管理智能体可以通过协议进行实时协作,提高生产效率和产品质量。
最佳实践与实施建议
架构设计原则
单一职责原则:每个智能体应该专注于特定的业务领域,避免功能过于复杂。这样既提高了智能体的专业性,也便于维护和升级。
接口隔离原则:设计清晰的协议接口,避免不必要的依赖。智能体只需要了解它实际使用的接口,而不是全部的协议功能。
依赖倒置原则:高层业务逻辑不应该依赖底层技术实现,而应该依赖抽象的协议接口。这样可以方便地替换底层实现而不影响业务逻辑。
监控与运维策略
性能监控指标:
- 消息传递延迟:监控A2A消息的端到端延迟
- 工具调用成功率:监控MCP工具调用的成功率和响应时间
- 资源利用率:监控CPU、内存、网络等资源的使用情况
- 错误率统计:统计各类错误的发生频率和影响范围
日志管理机制:
import structlog
from datetime import datetime
class ProtocolLogger:
def __init__(self):
self.logger = structlog.get_logger()
def log_a2a_message(self, message_type: str, from_agent: str,
to_agent: str, success: bool, response_time: float):
"""记录A2A协议消息"""
self.logger.info(
"a2a_message_processed",
message_type=message_type,
from_agent=from_agent,
to_agent=to_agent,
success=success,
response_time=response_time,
timestamp=datetime.utcnow().isoformat()
)
def log_mcp_tool_call(self, tool_name: str, client_id: str,
success: bool, execution_time: float):
"""记录MCP工具调用"""
self.logger.info(
"mcp_tool_called",
tool_name=tool_name,
client_id=client_id,
success=success,
execution_time=execution_time,
timestamp=datetime.utcnow().isoformat()
)
常见问题与解决方案
A2A协议常见问题
问题1:智能体发现失败
- 原因:网络连接问题或注册中心异常
- 解决方案:实现本地缓存机制,定期同步智能体信息
class AgentDiscoveryCache:
def __init__(self, cache_ttl: int = 3600):
self.cache = {}
self.cache_ttl = cache_ttl
async def get_agent_with_fallback(self, capability: str):
"""带降级的智能体获取"""
# 先从缓存获取
cached_agent = self.cache.get(capability)
if cached_agent and not self.is_expired(cached_agent):
return cached_agent
# 尝试从注册中心获取
try:
fresh_agent = await self.fetch_from_registry(capability)
self.cache[capability] = {
"agent": fresh_agent,
"cached_at": datetime.utcnow()
}
return fresh_agent
except:
# 使用过期缓存作为降级方案
if cached_agent:
return cached_agent["agent"]
raise Exception(f"无法找到具有能力 {capability} 的智能体")
问题2:消息传递超时
- 原因:目标智能体响应缓慢或网络延迟
- 解决方案:实现异步消息机制和重试策略
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
class AsyncMessageHandler:
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
async def send_message_with_retry(self, endpoint: str, message: dict, timeout: int = 30):
"""带重试的异步消息发送"""
try:
async with asyncio.timeout(timeout):
response = await self.send_http_request(endpoint, message)
return response
except asyncio.TimeoutError:
raise Exception(f"消息发送超时,目标端点: {endpoint}")
MCP协议常见问题
问题1:工具调用失败
- 原因:工具参数错误或依赖服务异常
- 解决方案:实现参数验证和错误处理机制
from pydantic import BaseModel, ValidationError
class ToolInputValidator:
def __init__(self):
self.schemas = {}
def register_tool_schema(self, tool_name: str, schema_class: BaseModel):
"""注册工具参数验证模式"""
self.schemas[tool_name] = schema_class
async def validate_and_execute_tool(self, tool_name: str, parameters: dict):
"""验证参数并执行工具"""
schema_class = self.schemas.get(tool_name)
if not schema_class:
raise Exception(f"未找到工具 {tool_name} 的验证模式")
try:
# 参数验证
validated_params = schema_class(**parameters)
# 执行工具
result = await self.execute_tool(tool_name, validated_params.dict())
return result
except ValidationError as e:
raise Exception(f"参数验证失败: {e.errors()}")
问题2:资源连接断开
- 原因:数据库连接超时或网络不稳定
- 解决方案:实现连接池和自动重连机制
import asyncio
import asyncpg
from asyncpg.pool import Pool
class DatabaseConnectionManager:
def __init__(self, connection_string: str):
self.connection_string = connection_string
self.pool = None
self.reconnect_attempts = 0
self.max_reconnect_attempts = 5
async def get_connection(self):
"""获取数据库连接"""
if not self.pool:
await self.create_pool()
try:
return await self.pool.acquire()
except Exception as e:
if self.reconnect_attempts < self.max_reconnect_attempts:
await self.reconnect()
return await self.pool.acquire()
else:
raise Exception(f"数据库连接失败: {str(e)}")
async def reconnect(self):
"""重新建立连接池"""
self.reconnect_attempts += 1
if self.pool:
await self.pool.close()
await asyncio.sleep(2 ** self.reconnect_attempts) # 指数退避
await self.create_pool()
结论
A2A和MCP协议代表了AI智能体技术发展的重要里程碑。通过标准化的通信和集成机制,它们为构建复杂的智能化系统提供了坚实的技术基础。
从技术层面来看,A2A协议解决了智能体间协作的标准化问题,使得不同组织开发的智能体能够无缝协同工作。MCP协议则解决了AI应用与外部资源集成的复杂性,大大降低了开发和维护成本。
从业务价值来看,这两个协议的应用可以显著提高企业的运营效率和服务质量。通过智能体网络,企业可以构建更加智能、响应更快的业务系统。通过标准化的数据访问,AI应用可以更好地理解业务上下文,提供更精准的服务。
作者简介
本文作者丁学文武,多年算法负责人,主要研究方向是大模型、智能体、RAG、ChatBI、微调、部署、推荐算法、大数据等。在实际项目中积累了丰富的部署经验,希望通过本文为CSDN贡献有价值的技术内容并供同学们参考,让同学们少走弯路。
如有任何问题或建议,欢迎在评论区交流讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)