OpenCV与AI深度学习 | 性能炸场!YOLO13 强势来袭!
YOLO系列目标检测技术最新进展综述:YOLOv13通过超图增强机制HyperACE显著提升性能,YOLOv12创新融合注意力机制在精度与速度上取得突破。研究还展示了YOLO与SAM结合的细胞核分割方案、轻量化YOLOv3在大豆产量预测中的应用,以及空间通道协作注意力改进的SCCA-YOLO网络。实验数据表明,最新YOLO模型在各类任务中均保持领先性能,其中YOLOv13-N在MSCOCO数据集上
本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:性能炸场!YOLO13 强势来袭!
在目标检测领域,YOLO 系列绝对是绕不开的 “顶流”—— 从最初开创实时检测范式,到 YOLOv13 凭性能炸场刷新行业认知,再到 YOLOv14 即将登场的消息引发热议,它每一次迭代都在推动技术边界向前突破。
1. YOLOv13
推荐论文:YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception

【要点】本研究提出了一种新的实时物体检测模型YOLOv13,通过引入超图增强的自适应相关强化机制HyperACE,实现了高效的跨位置和跨尺度特征融合,显著提升了检测精度和计算效率。
【方法】研究采用超图计算方法,提出HyperACE机制,以及基于HyperACE的全流程聚合与分配范式FullPAD,并使用深度可分离卷积优化网络结构。
【实验】在MS COCO数据集上进行广泛实验,YOLOv13-N模型相比YOLO11-N和YOLOv12-N在mAP指标上分别提高了3.0%和1.5%,证明了模型性能的提升。
2.YOLOv12
推荐论文:YOLOv12: Attention-Centric Real-Time Object Detectors

【要点】本研究提出了一个以注意力机制为核心的实时物体检测框架YOLOv12,它在保持与传统基于CNN的模型速度相当的同时,利用了注意力机制的性能优势,实现了更高的准确度和竞争力速度。
【方法】作者通过将注意力机制融入YOLO框架中,设计了一种新的网络架构,该架构能够在不牺牲速度的前提下提升检测性能。
【实验】在T4 GPU上,YOLOv12-N模型以1.64毫秒的推理延迟达到了40.6的准确度,超越了先进的YOLOv10-N和YOLOv11-N模型,并在不同规模模型上均有显著表现。此外,YOLOv12-S也在RT-DETR和RT-DETRv2等改进的端到端实时检测器上取得了领先。
3.YOLO+注意力机制
推荐论文:SCCA-YOLO: A Spatial and Channel Collaborative Attention Enhanced YOLO Network for Highway Autonomous Driving Perception System
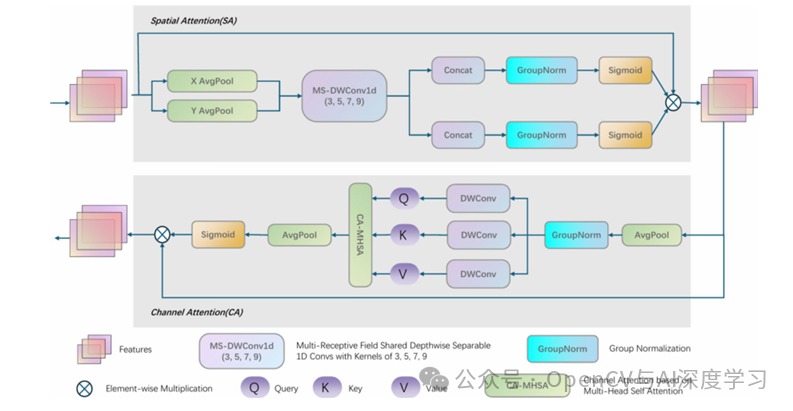
【要点】本文提出了一种适用于农村道路环境的SCCA-YOLO网络,通过融合空间注意力和通道自注意力,提高了YOLOv8的检测精度,并引入Ghost模块以减轻网络负担。
【方法】研究采用了一种创新的空间通道协作注意力机制,将空间注意力和共享语义结合的注意力模型以及通道自注意力依次融合,增强了网络的特征表达能力。
【实验】在私有和公开数据集上的评估结果显示,所提出的SCCA-YOLO网络在检测性能上具有优越性,但具体数据集名称未在摘要中提及。
4. YOLO+SAM
推荐论文:Nuclei Segmentation in Hepatocytes Using YOLO and SAM

【要点】本文提出了一种混合方法,将YOLO架构用于检测肝细胞核,并将SAM用于这些细胞结构的分割,旨在简化并提高组织病理学图像中细胞定量与形态学分析的任务,为研究人员提供一种与手工标注相比无显著统计差异的自动化分析工具。
【方法】该方法结合了YOLO架构和SAM,其中YOLO用于检测,SAM用于分割。
【实验】研究测试了三个不同版本的YOLO模型(YOLOv3,YOLOv8和YOLOv9),在平均精度(AP)方面分别达到70.28%,70.98%和71.5%。在精确度和召回率方面,YOLOv3达到90.7%和92.4%,YOLOv8达到90.4%和92.94%,YOLOv9达到92.16%和93.66%。成对t检验显示,与手工标注相比,YOLO模型之间没有显著的统计差异。在形态学分析中,评估了默认SAM模型以及微调后的MED-SAM和Micro-SAM模型,结果显示默认SAM模型表现最佳,其Dice系数为93.65%,IOU为88.2%。
5. 轻量YOLO目标检测
推荐论文:Soybean Yield Preharvest Prediction Based on Bean Pods and Leaves Image Recognition Using Deep Learning Neural Network Combined with GRNN
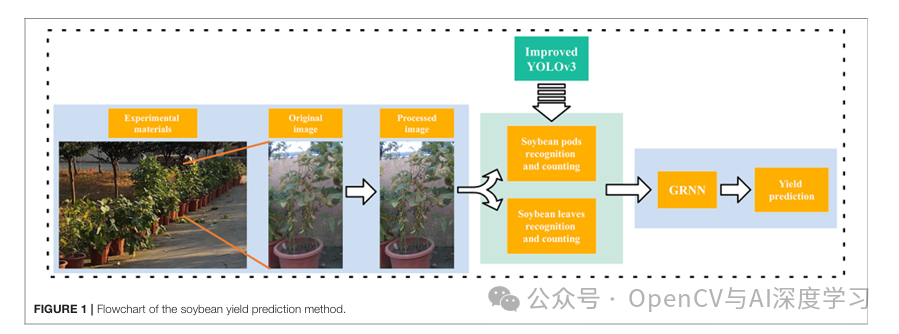
【要点】本文提出了一种基于深度学习神经网络与广义回归神经网络(GRNN)结合的大豆产量预测方法,通过识别大豆荚果和叶片图像,实现了田间大豆产量的实时预测。
【方法】使用Faster R-CNN、FPN、SSD和YOLOv3等深度学习算法进行大豆荚果识别,通过改进YOLOv3算法提高了识别精度,并利用GRNN模型结合不同类型荚果数量和叶片数量预测大豆产量。
【实验】实验采用YOLOv3算法进行大豆荚果识别,识别精度和速度分别为90.3%和39 FPS;通过PLSR、BP和GRNN模型预测大豆种子数量,预测结果分别为96.24%、96.97%和97.5%,最终得到大豆产量的平均预测准确率达到97.43%。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)