Grok-1:马斯克旗下 xAI 首个开源大模型全面解析
在大模型百家争鸣的时代,马斯克旗下的 AI 公司 xAI 于 2024 年 3 月 17 日正式开源 Grok-1 —— 这不仅是一次模型的放出,更是 xAI 在开源生态上的重大布局。本文将带你深入了解 Grok-1 的背景、技术架构、MoE 特性以及其在开源 LLM 生态中的意义。
在大模型百家争鸣的时代,马斯克旗下的 AI 公司 xAI 于 2024 年 3 月 17 日正式开源 Grok-1 —— 这不仅是一次模型的放出,更是 xAI 在开源生态上的重大布局。
本文将带你深入了解 Grok-1 的背景、技术架构、MoE 特性以及其在开源 LLM 生态中的意义。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
1.为什么 Grok-1 参数量巨大却推理成本较低?
2. Grok-1 是如何使用专家的?和 Mixtral 类似吗?
3. 相比其他开源模型,Grok-1 的技术优势是什么?
一、Grok 是什么?
Grok 是 xAI 打造的一系列大型语言模型的统称,名字取自 Robert Heinlein 科幻小说中的术语 “Grok”,意思是完全理解与共鸣。

Grok 模型最早整合于 X(原 Twitter)平台中,用于智能问答、对话生成等任务,定位为对标 ChatGPT 的产品。
而 Grok-1 是其第一代模型,也是目前唯一一个真正完全开源的版本。
二、Grok-1 的开源信息概览

| 属性 | 内容 |
|---|---|
| 发布时间 | 2024 年 3 月 17 日 |
| 开源协议 | Apache 2.0 |
| 模型类型 | 语言模型(预训练) |
| 参数量 | 314B(31.4B × MoE 架构,激活 2 个专家) |
| 架构 | Decoder-only Transformer + Mixture of Experts (MoE) |
| 上下文长度 | 8192 tokens |
| 编码方式 | RoPE(旋转位置编码) |
| 是否对话调优 | ❌ 纯预训练模型,无 SFT / RLHF |
| GitHub 地址 | github.com/xai-org/grok-1 |
三、技术架构解析:MoE + Transformer
Grok-1 的架构基于经典的 Decoder-only Transformer,但引入了当前非常流行的 Mixture of Experts (MoE) 技术来提升性能与效率:
核心特点:
- 64 层 Transformer block
- MoE 层分布在部分 block 中,共 8 个专家网络,每次前向传播时仅激活其中 2 个(Top-2 路由)
- 总参数量超 300B+,实际激活参数仅约 63B,极大提高了训练效率
- 使用 RoPE(旋转位置编码) 替代传统的绝对位置编码,提升长文本建模能力
- 使用 bfloat16 精度 进行训练(高效硬件支持)
MoE 的设计灵感来源于人脑中“只调用部分神经元处理任务”的理念,可以在保持大模型容量的同时,显著降低训练与推理成本。
四、为什么开源 Grok-1 是一件大事?
虽然 LLaMA、Mistral、Command R 等开源模型层出不穷,但 Grok-1 的出现具有以下几个关键意义:
1. 马斯克阵营首次完全放开模型
此前 xAI 一直闭门造车,Grok 被广泛用于 X 平台,但并无详细公开。此次 Grok-1 的开源表明 马斯克在开源 AI 社区迈出了实质性一步。
2. 提供高质量 MoE 架构示范
不同于多数开源模型是 Dense 架构(如 LLaMA),Grok-1 直接给出了一套成熟的 稀疏 MoE 实现,对于研究人员与开发者具有极高的参考价值。
3. 可作为基础模型微调
虽然 Grok-1 没有经过对话微调,但其预训练权重完全开放,开发者可以基于此进行 SFT、RLHF、RAG、LoRA 等下游任务定制。
五、如何使用 Grok-1?
xAI 官方提供了 Grok-1 模型权重和加载代码,你可以使用如 vLLM、Transformers、tgi 等工具加载。
示例:
git clone https://github.com/xai-org/grok-1.git
# 使用 vLLM 加载模型
pip install vllm
python -m vllm.entrypoints.openai.api_server --model-path grok-1
六、Groks性能评估
xAI 使用了一些旨在衡量数学和推理能力的标准机器学习基准对 Grok-1 进行了一系列评估:
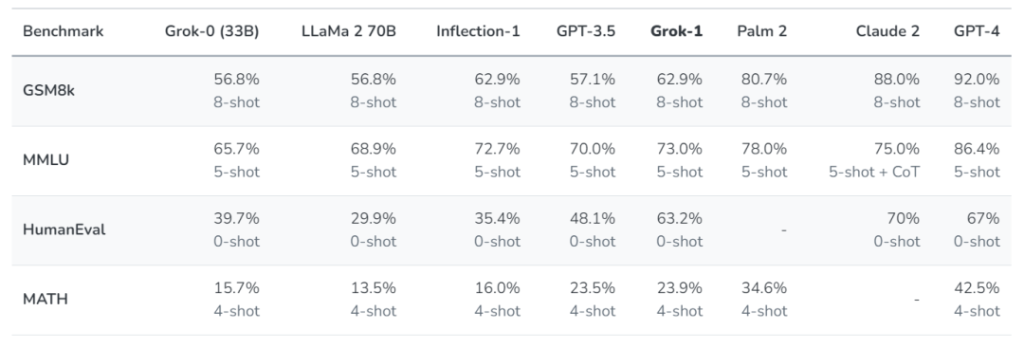
在这些基准测试中,Grok-1 显示出了强劲的性能,超过了其计算类中的所有其他模型,包括 ChatGPT-3.5 和 Inflection-1。只有像 GPT-4 这样使用大量训练数据和计算资源训练的模型才能超越它。
| 模型 | 开源程度 | 架构 | 训练量级 | 推理效率 | 对话优化 |
|---|---|---|---|---|---|
| Grok-1 | 完全开源 | MoE + RoPE | 高(未知) | 高(稀疏) | ❌ 无 |
| LLaMA-3 | 完全开源 | Dense + RoPE | 高 | 中 | ✅ 有 |
| Mistral/Mixtral | 完全开源 | MoE | 中等 | 高 | ❌ 无 |
如果你想探索高效训练、稀疏激活、多专家机制,Grok-1 是不可多得的实战材料;但如果你要部署对话应用,可能还需对 Grok-1 进一步微调。
七、结语
从 Grok-1 的开源可以看出,xAI 正逐步与 Hugging Face 等生态接轨,未来如果 Grok-2/3 也开放权重,将极大提升开源模型领域的竞争力与活力。
马斯克曾表示:“我们要打造最聪明、最诚实、最有趣的 AI。”
Grok 是否能实现这个目标?我们拭目以待。
最后,我们回答一下文章开头提出的问题。
1. 为什么 Grok-1 参数量巨大却推理成本较低?
Grok-1 采用了 Mixture of Experts(MoE)架构,每层只激活少数专家(如 Top-2),尽管总参数量达到 314B,但每次推理仅使用其中的一小部分,因此计算开销大幅下降,实际推理成本仅相当于一个 25B 左右的 dense 模型。这种稀疏激活策略使得模型容量大但运行高效,兼顾了表达力与部署成本。
2. Grok-1 是如何使用专家的?和 Mixtral 类似吗?
是的,Grok-1 使用的 MoE 结构与 Mixtral 类似,每层包含多个专家子网络,由一个门控网络根据 token 的语义特征动态选择 Top-2 专家进行计算。最终输出是这两个专家结果的加权求和。这种设计使每个专家可以专注于处理特定类型的输入,从而提升模型的泛化和精度。
3. 相比其他开源模型,Grok-1 的技术优势是什么?
Grok-1 的技术亮点在于它同时具备大模型的表达能力和高效推理的可部署性。此外,它在数学推理与逻辑任务上表现尤为出色,并率先实现了完整 MoE 架构的开源(包括权重、代码和推理工具)。这种“能力强 + 高透明 + 易用性高”的组合,使其在开源模型中具有独特的竞争力。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)