超级简洁的搭建本地大模型Ollama +open UI(亲自实操)
本文提供了一套基于Ollama0.3.0+和OpenUI1.5.0的AI大模型本地化极简部署方案。方案包含硬件配置建议、Ollama环境搭建与模型下载、OpenUI安装配置等完整流程,实测30分钟内可完成部署。重点介绍了Windows系统下环境变量设置、模型下载路径修改等关键步骤,并提供了Docker配置参数和本地访问方法。该方案操作简单,适合新手快速搭建本地AI智能体,为追求数据隐私和定制化需求
引言
在AI大模型普及的今天,本地化部署成为开发者追求隐私保护与定制化需求的核心方案。本文基于Ollama 0.3.0+和Open UI 1.5.0最新版本,提供一套经过实测的极简部署方案,30分钟内即可搭建完成。
一、环境准备(5分钟)
1.1 硬件要求
|
组件 |
最低配置 |
推荐配置 |
|
CPU |
4核 |
8核以上 |
|
内存 |
16GB |
32GB+ |
|
存储 |
50GB SSD |
200GB NVMe |
|
GPU(可选) |
NVIDIA 1080Ti |
RTX 4090/A100 |
二、Ollama 下载 ollama
2.1 Ollama 下载 ollama
https://ollama.com/ 下载 ollama,可以选择需要安装的操作系统,这里我选择的是windows
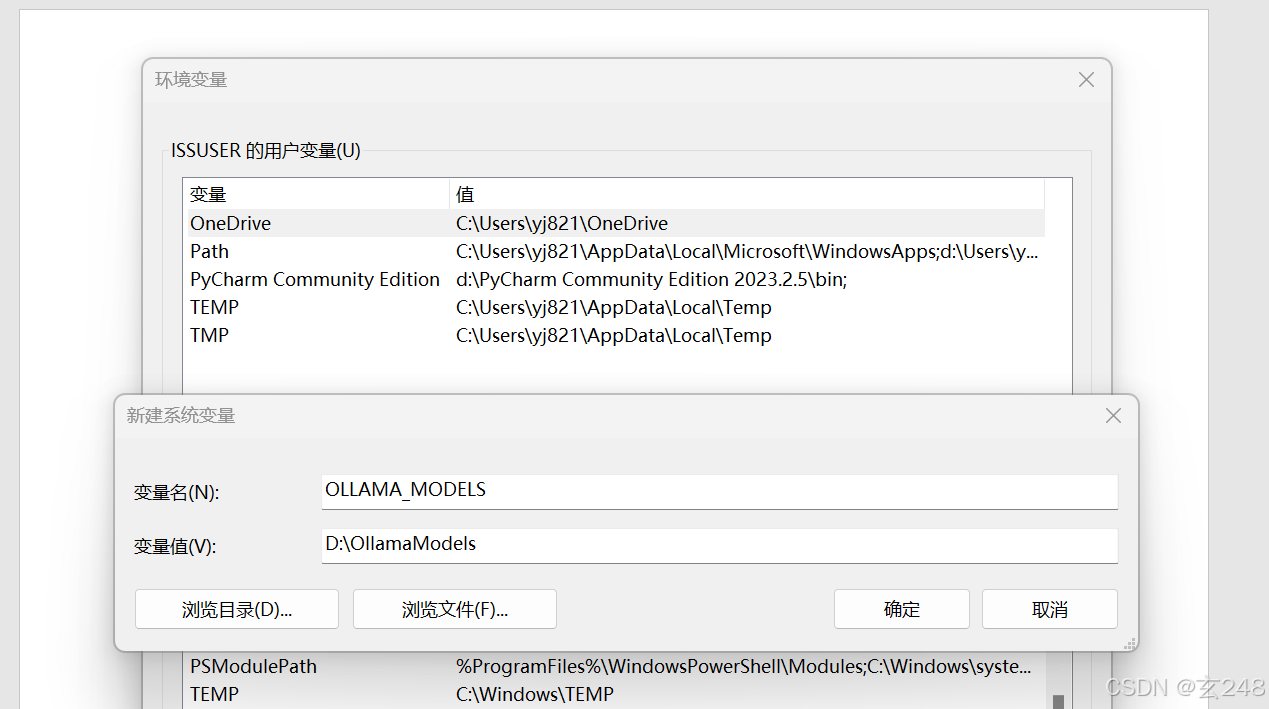
2.2 用ollama下载需要的大模型,注意要先到系统的属性里面进行ollama 环境变量设置模型的存放地址,不然都会存放到C 盘。
在Windows系统中,为Ollama指定模型下载位置可以通过设置环境变量来实现。以下是详细步骤: OLLAMA_MODELS D:\OllamaModels(可以根据自己的情况选择要存放的地方,一定要有较大空间),如下图进行设置:
三、Ollama开源模型下载
3.1 继续在终端用命令下载需要的模型:
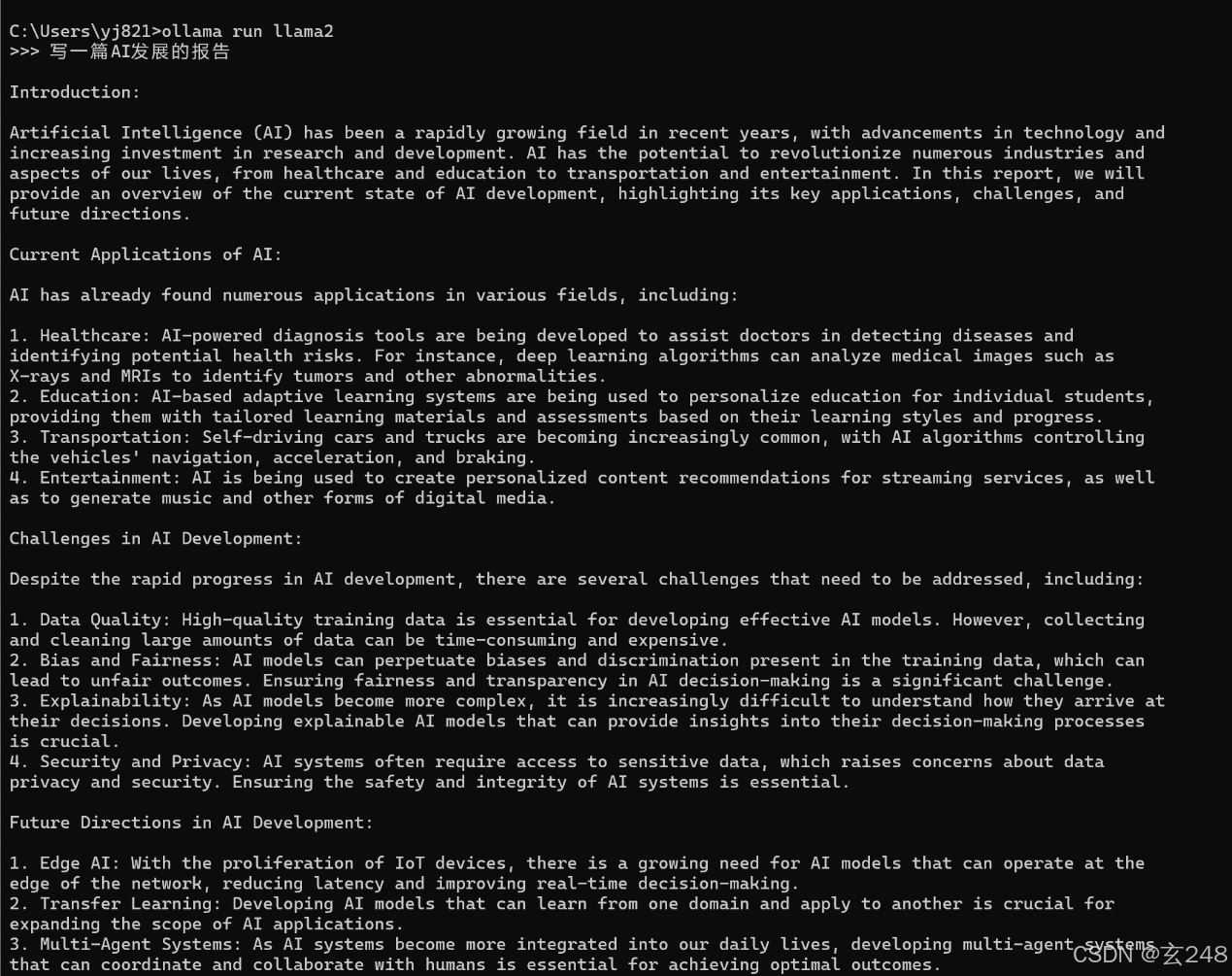
在终端里面用命令:ollama run llama2
模型下载完后,对模型进行测试,如果要退出可以用Use Ctrl + d or /bye to exit.
四、下载open UI
4.1 Open UI 下载
访问:https://github.com/open-webui/open-webui
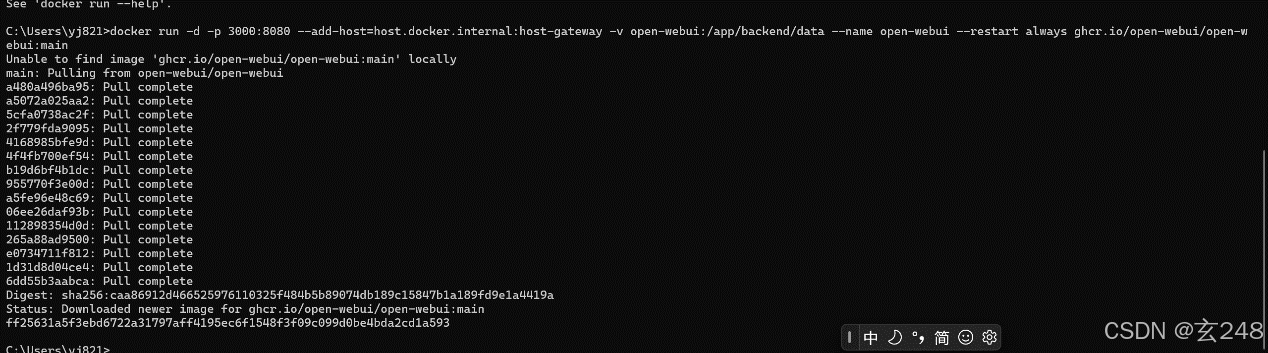
五、在Docker 里面进行配置
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
六、本地启动openUI
配置好后,本地启动http://localhost:3000/
选择需要的模型,然后就可以进行本地智能体访问,我这里让他生成的是一个AI的报告
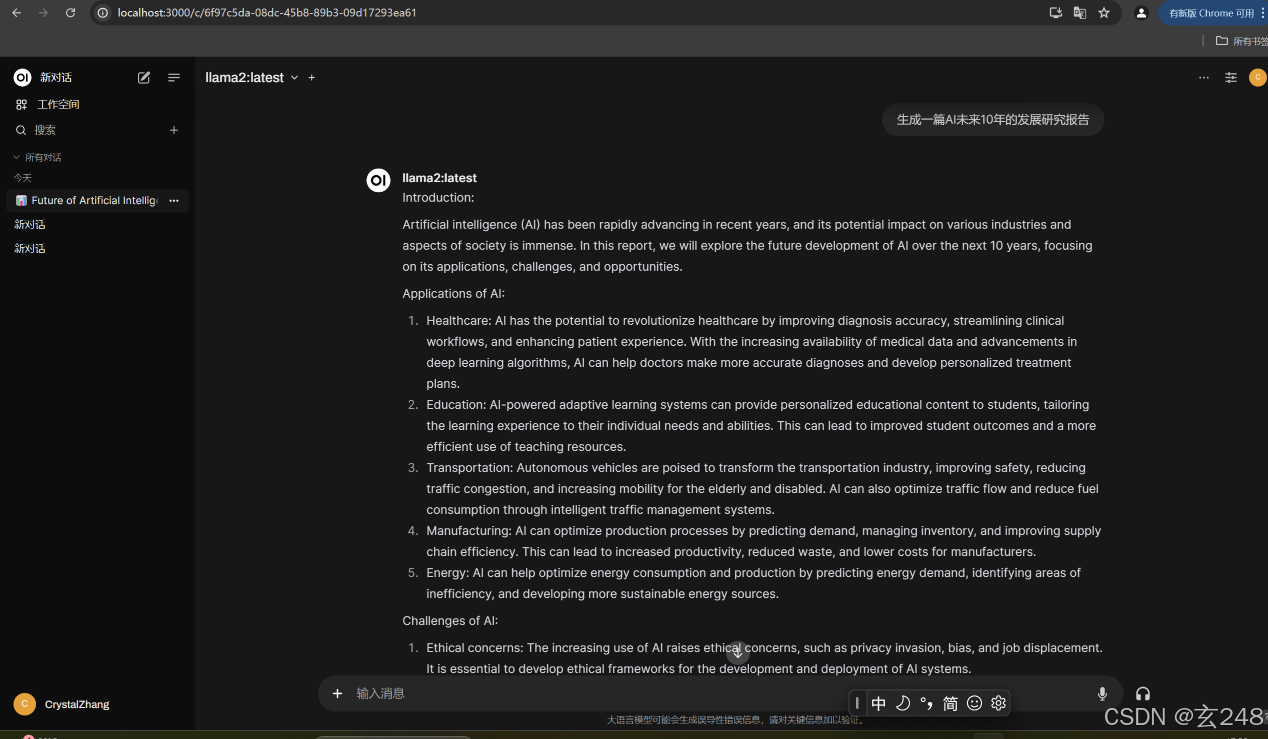
以上操作都非常简单,适合新手,后续或持续更新优化其他更好的本地部署大模型的方法

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)