年化390%,回撤7%,夏普6.32 | A股量化策略配置
原创内容第985篇,专注AGI+,AI量化投资、个人成长与财富自由。年岁渐长,了解一些事实、真相和细节,越发喜欢简单、纯粹的东西。我加了一个,人生之关键词: 自由,安全,真理,分享。确实,条条大路通罗马。哪条路并不重要,也不确定。今天看到一本书,提及人生规划,目标比路径重要。有人天生就擅长且喜欢,组织他人就完成一件事。年化390%,回撤7%,夏普6.32。她写的人生的关键词:自由,真理,分享。往回
·
原创内容第985篇,专注AGI+,AI量化投资、个人成长与财富自由。
又一年七夕,又一年秋风起。
往回看,时光如白驹过隙,弹指一挥间。
今日策略
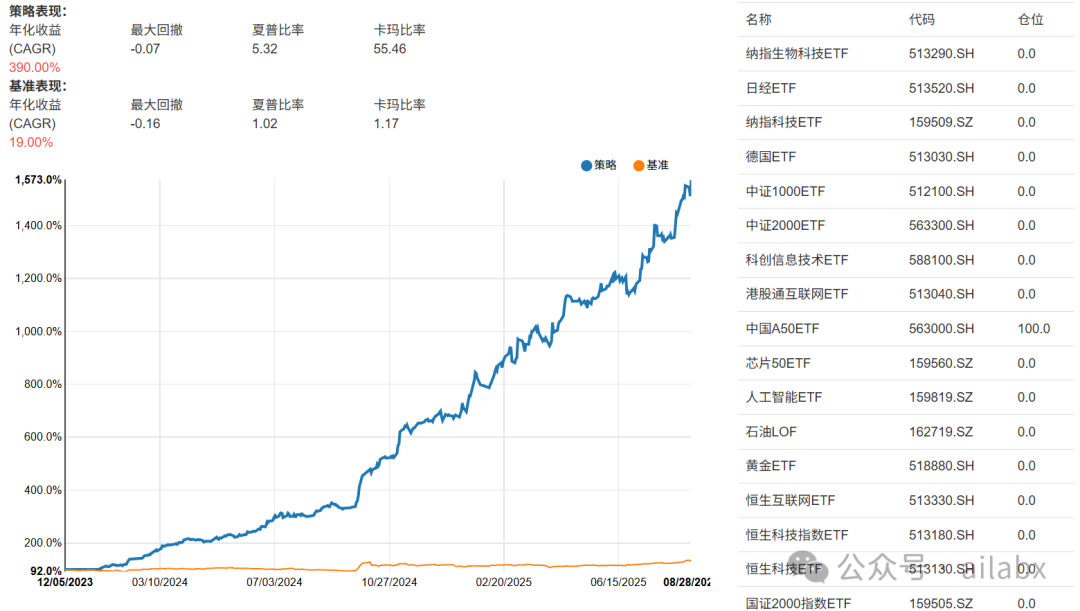
年化390%,回撤7%,夏普6.32。
线上地址:
http://www.ailabx.com/strategy/6898b4d92e5568a9eeba4c94,
大家可以查看参数,学习案例。
量化系统开发
股票可视化策略回测配置的代码如下:
from dataclasses import dataclass, fieldfrom typing import List, Optional, Dict, Any# 操作符映射字典,将中文操作符转换为对应的符号OP_MAP = {'大于': '>','小于': '<','大于等于': '>=','小于等于': '<=','等于': '==','不等于': '!=','包含': 'in','不包含': 'not in'}# 因子表达式映射,包含表达式模板和参数描述FACTOR_EXPRS = {'动量': {'expr': 'roc(close,{})','params_desc': ['周期']},'流通市值': {'expr': 'circ_mv','params_desc': [],'is_base':True},# 可以添加更多因子表达式'收盘价': {'expr': 'real_close','params_desc': [],'is_base':True,},'最大值': {'expr': 'ts_max(close,{})','params_desc': ['周期']},# 更多因子...}@dataclassclass Rule:factor_name: str = ''params: List[int] = field(default_factory=lambda: [20])op: str = '大于'value: float = 0.0@dataclassclass SortRule:factor_name: str = ''params: List[int] = field(default_factory=lambda: [20])desc: bool = Trueweight: float = 1.0 # 修正了拼写错误from datetime import datetime@dataclassclass StockTask:name: str = '股票策略'period: str = 'RunDaily'period_days: Optional[int] = Nonestart_date: str = '20100101'end_date: Optional[str] = datetime.now().strftime('%Y%m%d')benchmark: str = '510300.SH'filters_rules: List[Rule] = field(default_factory=list) # 明确指定为Rule列表orderby_rules: Optional[List[SortRule]] = field(default_factory=list) # 明确指定为SortRule列表topK: int = 20@classmethoddef from_dict(cls, data: Dict[str, Any]) -> 'StockTask':"""从字典创建 StockTask 实例Args:data: 包含 StockTask 数据的字典Returns:StockTask 实例"""# 处理 filters_rulesfilters_rules = []if 'filters_rules' in data and data['filters_rules']:for rule_data in data['filters_rules']:if isinstance(rule_data, Rule):filters_rules.append(rule_data)else:filters_rules.append(Rule(**rule_data))# 处理 orderby_rulesorderby_rules = []if 'orderby_rules' in data and data['orderby_rules']:for rule_data in data['orderby_rules']:if isinstance(rule_data, SortRule):orderby_rules.append(rule_data)else:orderby_rules.append(SortRule(**rule_data))# 创建 StockTask 实例return cls(name=data.get('name', '股票策略'),period=data.get('period', 'RunDaily'),period_days=data.get('period_days'),start_date=data.get('start_date', '20100101'),end_date=data.get('end_date', datetime.now().strftime('%Y%m%d')),benchmark=data.get('benchmark', '000300.SH'),filters_rules=filters_rules,orderby_rules=orderby_rules,topK=data.get('topK', 20))def get_filter_rules(self):"""根据filters生成过滤条件表达式列表例如:['roc(close,20) > 0.08', 'ts_min(close,20) < 10.5']"""if not self.filters_rules:return []filter_expressions = []base_expressions = []for rule in self.filters_rules:# 获取因子表达式信息factor_info = FACTOR_EXPRS.get(rule.factor_name)if not factor_info:continue# 使用参数展开替换表达式中的占位符expr_template = factor_info['expr']try:# 使用*params展开参数列表if len(rule.params) == 0:expr = expr_templateelse:expr = expr_template.format(*rule.params)except (IndexError, ValueError):# 如果参数数量不匹配,跳过这个规则print('参数不匹配,跳过')continue# 获取对应的操作符op_symbol = OP_MAP.get(rule.op, rule.op)# 构建过滤表达式if isinstance(rule.value, str) and (rule.op == '包含' or rule.op == '不包含'):# 处理字符串值的包含/不包含操作filter_expr = f"{expr}{op_symbol}({rule.value})"else:# 处理数值比较操作filter_expr = f"{expr}{op_symbol}{rule.value}"is_base = factor_info.get('is_base', False)if is_base:base_expressions.append(filter_expr)filter_expressions.append(filter_expr)return filter_expressions,base_expressionsdef get_order_by_factor(self) -> str:"""根据orderby_rules生成排序因子表达式规则:按weight加权,如果desc=True,则权重乘以-1例如:roc(close,20)*0.8 + ts_min(close,20)*0.6"""if not self.orderby_rules:return ""expressions = []for rule in self.orderby_rules:# 获取因子表达式信息factor_info = FACTOR_EXPRS.get(rule.factor_name)if not factor_info:continue# 使用参数展开替换表达式中的占位符expr_template = factor_info['expr']try:# 使用*params展开参数列表expr = expr_template.format(*rule.params)except (IndexError, ValueError):# 如果参数数量不匹配,跳过这个规则continue# 应用权重(如果desc为True,则权重取负)weight = rule.weight * (1 if rule.desc else -1)weighted_expr = f"({expr}) * {weight}"expressions.append(weighted_expr)# 组合所有表达式return " + ".join(expressions) if expressions else ""def get_orderby_rule_name(self):return '排序因子'def get_filter_rules_names(self) -> List[str]:"""根据filters生成过滤规则名称列表格式:['因子名_参数1_参数2', ...]例如:['动量_20', '最小值_22_23']"""if not self.filters_rules:return []rule_names = []for rule in self.filters_rules:# 构建基础名称(因子名)name_parts = [rule.factor_name]# 添加参数部分if rule.params:# 将参数转换为字符串并用下划线连接param_str = "_".join(str(p) for p in rule.params)name_parts.append(param_str)# 组合成完整的规则名称rule_name = "_".join(name_parts)rule_names.append(rule_name)return rule_namesif __name__ == '__main__':task = StockTask()task.filters_rules.append(Rule(factor_name='动量',params=[5,],op='大于',value=0.08))task.filters_rules.append(Rule(factor_name='最大值',params=[21,],op='小于等于',value=0))task.orderby_rules.append(SortRule(factor_name='动量',params=[21,],weight=1.0))task.orderby_rules.append(SortRule(factor_name='最小值',params=[3, ],weight=0.6,desc=False))print(task.get_order_by_factor())print(task.get_filter_rules())print(task.get_filter_rules_names())
吾日三省吾身
今天看到一本书,提及人生规划,目标比路径重要。
确实,条条大路通罗马。哪条路并不重要,也不确定。
没有方向,哪个方向都是逆风。
她写的人生的关键词:自由,真理,分享。
我加了一个,人生之关键词: 自由,安全,真理,分享。
“宏图霸业笑谈中,不胜人生一场醉”。
年岁渐长,了解一些事实、真相和细节,越发喜欢简单、纯粹的东西。
协作是一件复杂的事情。
有人天生就擅长且喜欢,组织他人就完成一件事。
有人天生就喜欢安静地做事情。
代码和数据下载:AI量化实验室——2025量化投资的星辰大海
机器学习驱动的策略开发通过流程 | 普通人阶层跃迁的可能路径?
年化30.24%,最大回撤19%,综合动量多因子评分策略再升级(python代码+数据)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)