【自动化办公】表格数据(excel或word)自动填充到浏览器页面的解决方案+支持windows系统
我们可以将你每天操作浏览器的重复操作进行自动化,只要事先配置好任务步骤,然后执行任务就可以了。比如:你要完成的浏览器录入数据 就称为一个任务。每个任务又包含很多“步骤步骤就是常用的浏览器操作,归纳几点如下:1. 切换浏览器标签页2. 点击按钮等元素3. 输入框输入值4. 下拉选中5. 打开链接等等.... 到时候没有的步骤也可以找我们新增步骤。举个例子,比如我有一个任务: 《 到百度搜索 ”如何高
背景痛点
我是一名程序员, 前阵子xx公司多名员工抱怨到上班按键盘手都快按脱臼了! 找到了我,于是我问其原因:
她们有一个网页,网页上有一个用户信息的数据需要录入,然后录入的数据又来自一个excel文档。关键是excel文档有几百行数据:
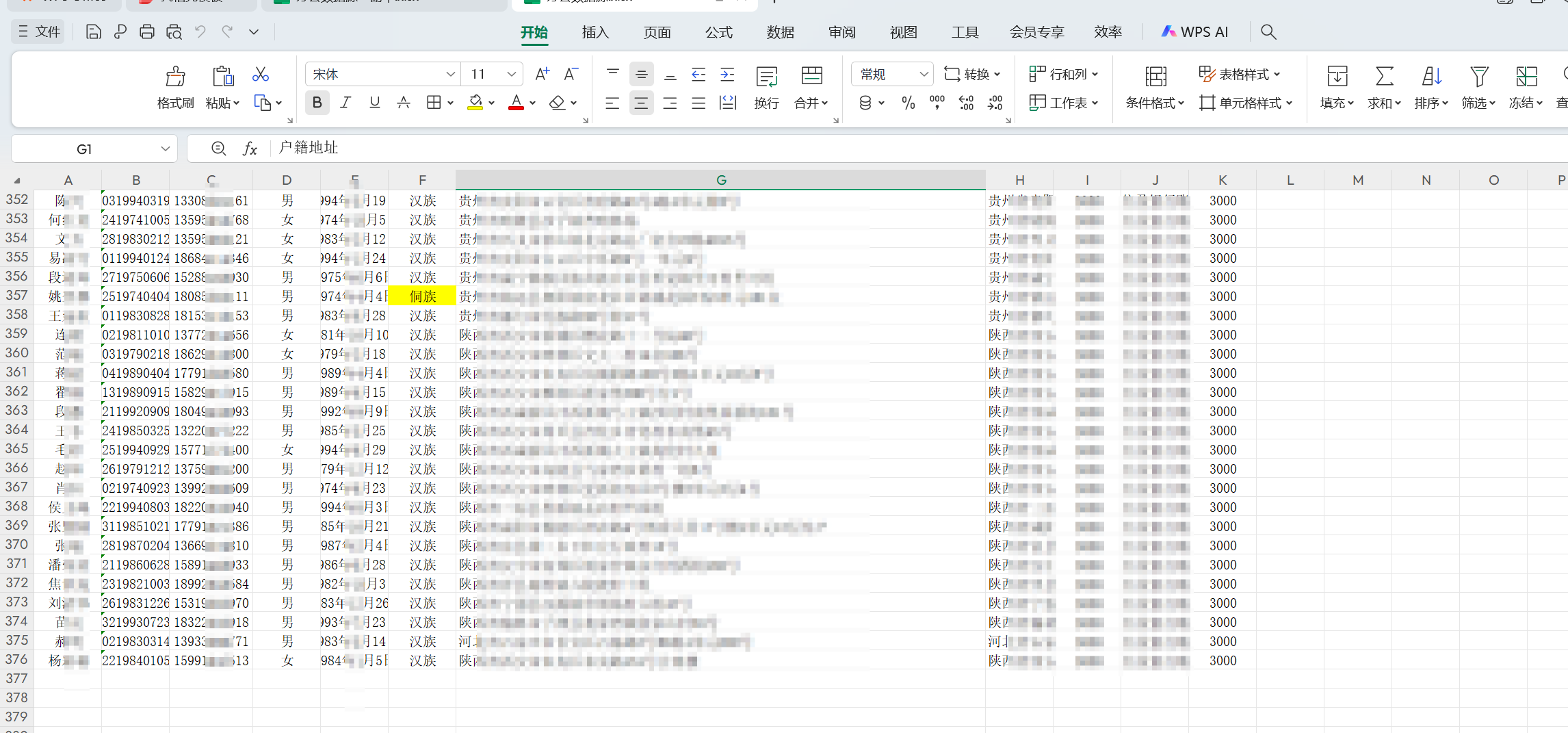
网页长这样 , 需要从表格里面一行一行复制数据,然后粘贴到网页上, 然后确定, 然后继续下一条..... (手速快一条30秒,这简直不可想象,手还能要吗)
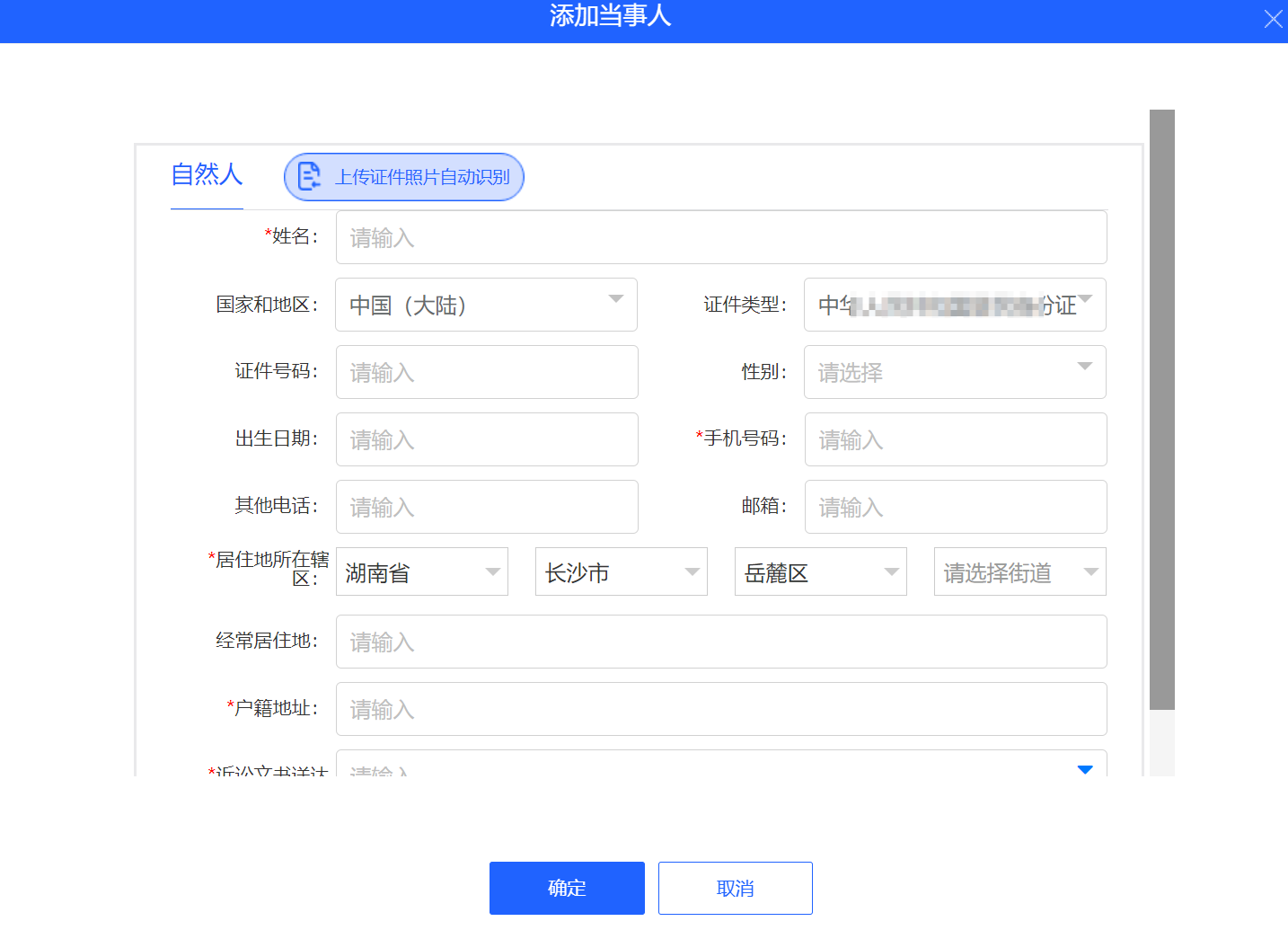
于是我给他提供了解决方案。下面我将讲解如何解决,以及解决办法的实现原理。
解决演示视频
自动填充表单功能演示
文章末尾关注公众号,回复:“小鱼办公” , 查看解决方案。
文章末尾关注公众号,回复:“小鱼办公” , 查看解决方案。
功能介绍
功能概述
我们可以将你每天操作浏览器的重复操作进行自动化,只要事先配置好任务步骤,然后执行任务就可以了。
比如:你要完成的浏览器录入数据 就称为一个“任务”。每个任务又包含很多“步骤”。 步骤就是常用的浏览器操作,归纳几点如下:
1. 切换浏览器标签页
2. 点击按钮等元素
3. 输入框输入值
4. 下拉选中
5. 打开链接
等等.... 到时候没有的步骤也可以找我们新增步骤。
举个例子,比如我有一个任务: 《 到百度搜索 ”如何高效办公“ 》 我们就可以拆分成很多步骤:
1. 打开链接到 ”www.baidu.com“。
2. 在百度输入框输入”如何高效办公?“。
3. 点击搜索按钮。
把这些步骤在我们这配置好之后,点击执行任务就可以了。不要人工去操作浏览器。
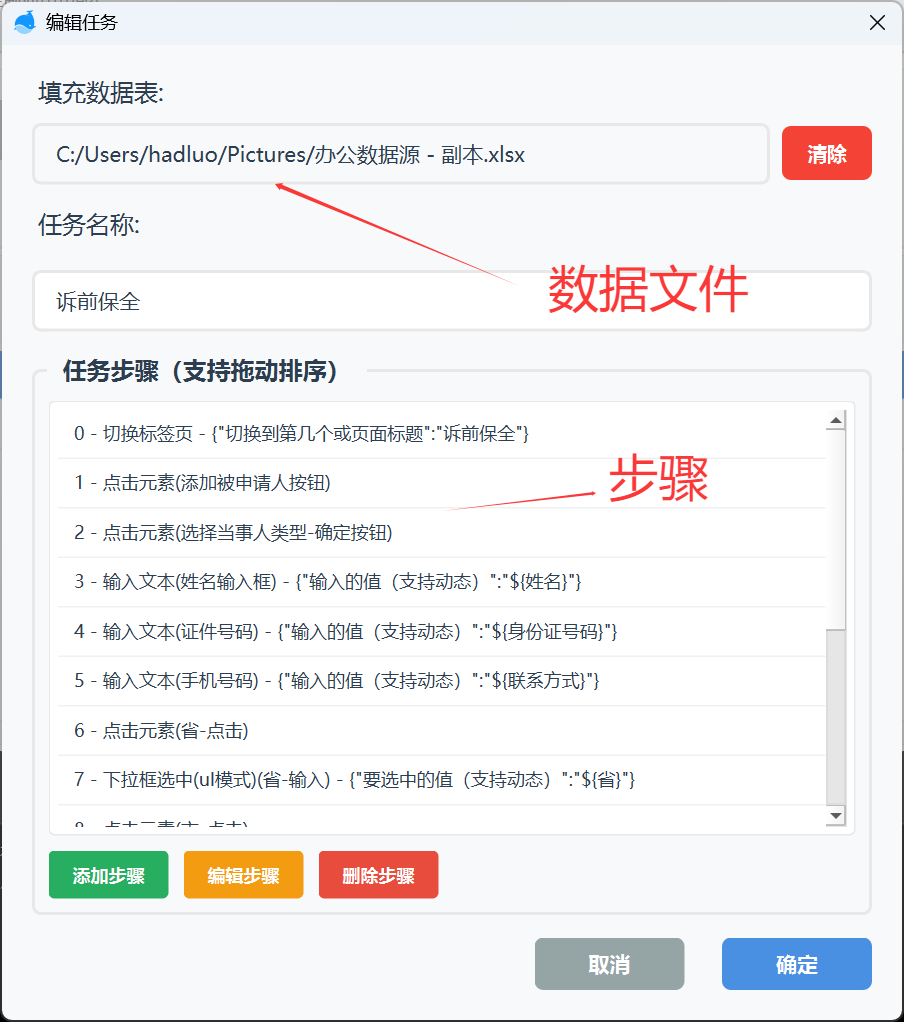
那么还有一个问题,数据源哪里来?
你录入浏览器页面的数据一般都是从excel或者word里面来, 我们可以给任务指定一个数据文件,就可以读取文件,填充到浏览器。
如果您有疑问可以一起来探讨,功能就介绍到 这里 ,希望能帮助大家,感谢!!!
如果您有疑问可以一起来探讨,功能就介绍到 这里 ,希望能帮助大家,感谢!!!
下面我将详细介绍下每个步骤的具体教程。
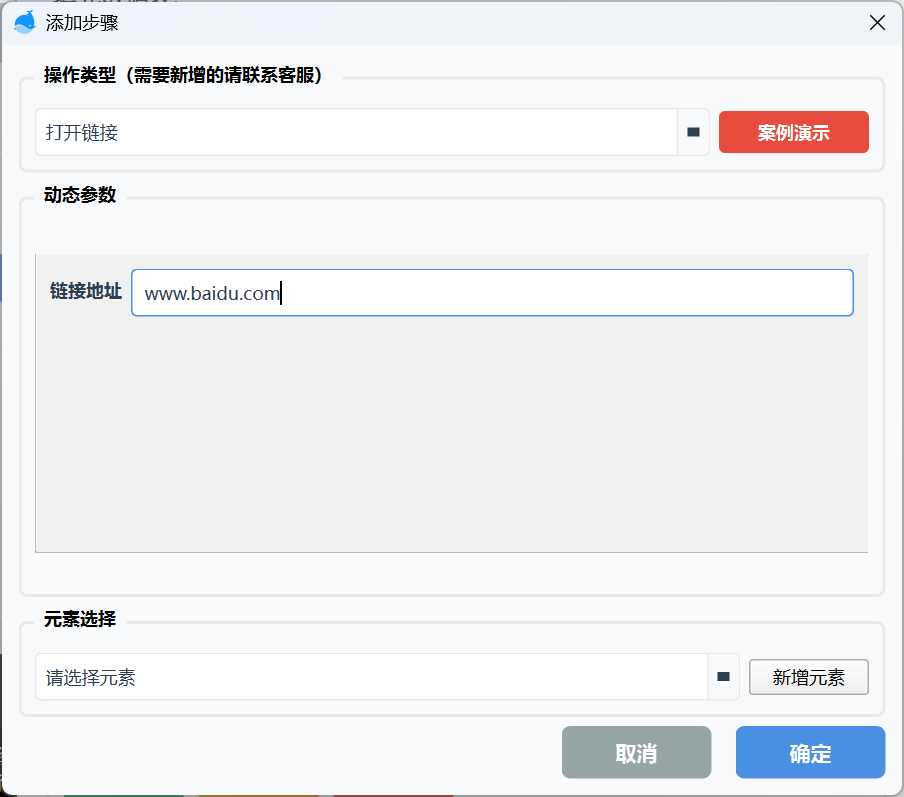
教程:打开链接
打开链接就是用浏览器打开一个地址,配置时,需要指定地址参数:
教程:点击元素
点击元素就是鼠标左键单击某个按钮,需要指定到哪一个按钮。
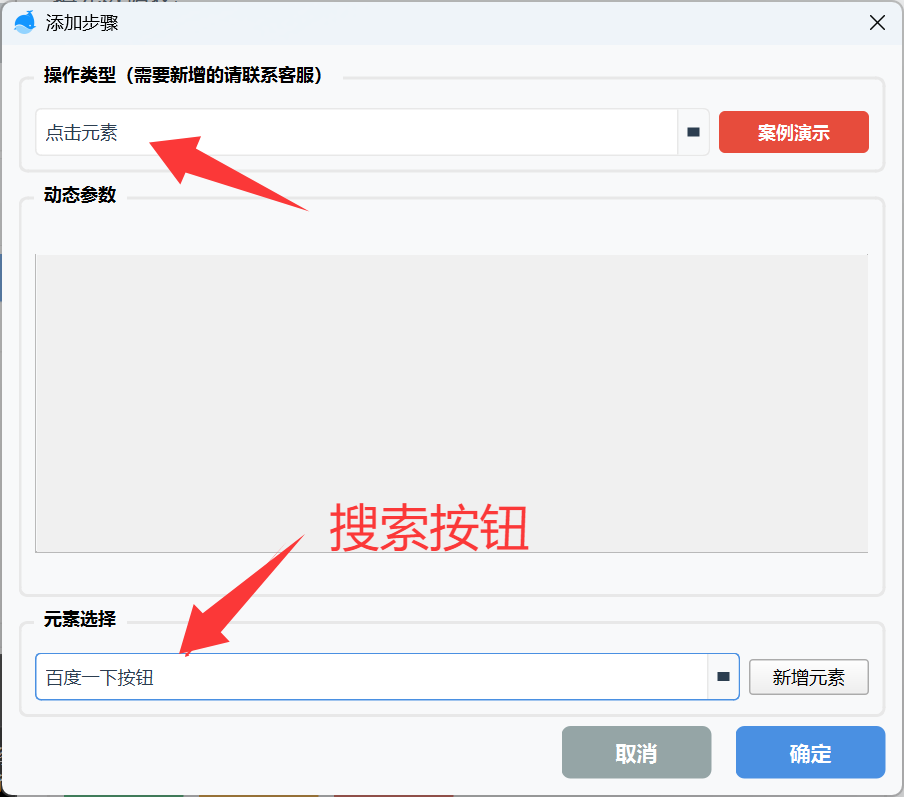
这个按钮怎么配置?不急,下面就介绍这个按钮如何选取和配置。
教程:选取元素
选取元素我用一个视频来演示,大家看这个视频就可以了:
教程:选取元素
教程:输入文本
输入文本就是将浏览器页面上的某个输入框输入你想要的值,值可以从表格里面来。
视频演示:
教程:输入文本
还有很多我就不一一介绍了,下面讲解下实现原理, 不懂技术的可以绕过了~~
技术实现原理
基于Python开发的现代化办公自动化软件,集成了浏览器自动化、Excel数据处理、用户管理、在线更新等多项核心功能。该软件采用模块化架构设计,具备良好的可扩展性和用户体验。
主要用到的技术架构:
用户界面框架 :PySide6
浏览器操作引擎: DrissionPage
数据处理层:Excel处理,openpyxl库, word处理,python-docx库
http网络:基于requests库的封装
多媒体集成:pywebview,用于播放视频
日志系统:基于Python logging模块,按照天来划分日志文件
版本更新: 采用线程下载更新文件,然后进行静默替换,自动启动更新的程序。
模块化:项目由于用到了浏览器,把浏览器打包到项目会很大, 于是将浏览器模块拆分,项目第一次启动时,会下载浏览器模块。
后端:采用了springboot技术, 记录了用户建立的任务和步骤数据。方便下次直接执行任务。
数据库表
项目用到了10张表
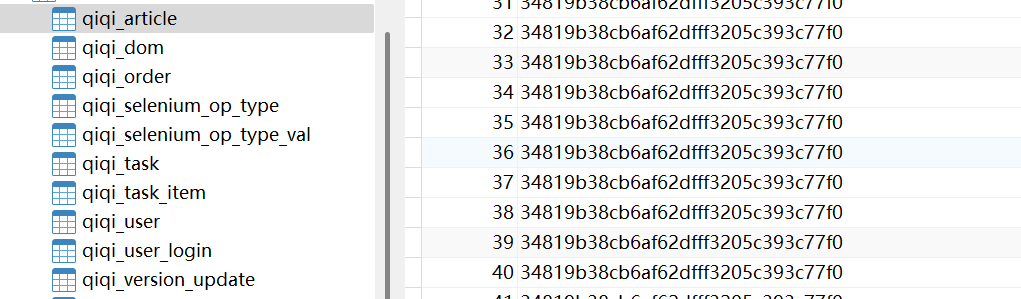
qiqi_article 表: 存储教程视频的表。视频为url链接。
qiqi_dom表 : 存储用户自定义的元素配置。
qiqi_selenium_op_type表: 存储所有的步骤操作类型。
qiqi_selenium_op_type_val表 : 存储用户步骤操作类型设置的参数值。
qiqi_task表: 存储用户新建的任务。
qiqi_task_item表: 存储用户定义的步骤。
qiqi_user表: 存储用户,用户标识就是当前的设备id。
部分代码解析
项目数据源动态读取excel或者word的入口代码:
通过判断路径,来动态的构造 ExcelParser或者 WordParser解析器, 这是最常见的策略模式的体现。

"""文件解析器主类
根据文件后缀名自动选择合适的解析器,统一解析接口。
"""
import os
from typing import List, Dict, Any, Optional, Union
from .excel_parser import ExcelParser
from .word_parser import WordParser
class FileParser:
"""文件解析器主类
自动根据文件后缀名选择合适的解析器进行文件解析。
"""
def __init__(self):
"""初始化文件解析器"""
self.excel_parser = ExcelParser()
self.word_parser = WordParser()
# 支持的文件格式映射
self.parser_map = {
'.xlsx': self.excel_parser,
'.xls': self.excel_parser,
'.docx': self.word_parser
}
def is_supported(self, file_path: str) -> bool:
"""检查文件是否为支持的格式
Args:
file_path: 文件路径
Returns:
bool: 是否支持该文件格式
"""
_, ext = os.path.splitext(file_path.lower())
return ext in self.parser_map
def get_supported_extensions(self) -> List[str]:
"""获取所有支持的文件扩展名
Returns:
List[str]: 支持的文件扩展名列表
"""
return list(self.parser_map.keys())
def parse(self, file_path: str, **kwargs) -> Dict[str, Any]:
"""解析文件
Args:
file_path: 文件路径
**kwargs: 额外参数
- sheet_name: Excel工作表名称 (仅Excel文件)
- table_index: Word表格索引 (仅Word文件)
- filter_empty_rows: 是否过滤空行 (默认True)
Returns:
Dict: 解析结果
{
'file_type': str, # 文件类型 ('excel' 或 'word')
'file_path': str, # 文件路径
'headers': List[str], # 表头列表
'data': List[List[str]], # 数据行列表
'total_rows': int, # 总行数
'total_cols': int, # 总列数
'metadata': Dict # 额外元数据
}
Raises:
FileNotFoundError: 文件不存在
ValueError: 文件格式不支持或解析失败
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在: {file_path}")
if not self.is_supported(file_path):
_, ext = os.path.splitext(file_path.lower())
supported = ', '.join(self.get_supported_extensions())
raise ValueError(f"不支持的文件格式 '{ext}',支持的格式: {supported}")
# 获取文件扩展名和对应的解析器
_, ext = os.path.splitext(file_path.lower())
parser = self.parser_map[ext]
try:
# 根据文件类型调用相应的解析方法
if ext in ['.xlsx', '.xls']:
# Excel文件
sheet_name = kwargs.get('sheet_name')
result = parser.parse(file_path, sheet_name=sheet_name)
# 过滤空行
filter_empty_rows = kwargs.get('filter_empty_rows', True)
if filter_empty_rows:
result['data'] = self._filter_empty_rows(result['data'])
result['total_rows'] = len(result['data'])
# 过滤标题前后空格
result['headers'] = self._trim_headers(result['headers'])
return {
'file_type': 'excel',
'file_path': file_path,
'headers': result['headers'],
'data': result['data'],
'total_rows': result['total_rows'],
'total_cols': result['total_cols'],
'metadata': {
'sheet_name': result['sheet_name']
}
}
elif ext == '.docx':
# Word文件
table_index = kwargs.get('table_index')
result = parser.parse(file_path, table_index=table_index)
# 过滤空行
filter_empty_rows = kwargs.get('filter_empty_rows', True)
if filter_empty_rows:
result['data'] = self._filter_empty_rows(result['data'])
result['total_rows'] = len(result['data'])
# 过滤标题前后空格
result['headers'] = self._trim_headers(result['headers'])
return {
'file_type': 'word',
'file_path': file_path,
'headers': result['headers'],
'data': result['data'],
'total_rows': result['total_rows'],
'total_cols': result['total_cols'],
'metadata': {
'table_index': result['table_index']
}
}
except Exception as e:
raise ValueError(f"解析文件失败: {str(e)}")
def parse_to_array(self, file_path: str, include_headers: bool = True, **kwargs) -> List[List[str]]:
"""解析文件并返回二维数组格式
Args:
file_path: 文件路径
include_headers: 是否包含表头
**kwargs: 额外参数
Returns:
List[List[str]]: 二维数组,第一行为表头(如果include_headers=True)
Raises:
FileNotFoundError: 文件不存在
ValueError: 文件格式不支持或解析失败
"""
result = self.parse(file_path, **kwargs)
if include_headers:
return [result['headers']] + result['data']
else:
return result['data']
def get_file_info(self, file_path: str) -> Dict[str, Any]:
"""获取文件基本信息
Args:
file_path: 文件路径
Returns:
Dict: 文件信息
{
'file_name': str, # 文件名
'file_size': int, # 文件大小(字节)
'file_type': str, # 文件类型
'is_supported': bool, # 是否支持解析
'additional_info': Dict # 额外信息
}
Raises:
FileNotFoundError: 文件不存在
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"文件不存在: {file_path}")
file_name = os.path.basename(file_path)
file_size = os.path.getsize(file_path)
_, ext = os.path.splitext(file_path.lower())
is_supported = self.is_supported(file_path)
additional_info = {}
if is_supported:
try:
if ext in ['.xlsx', '.xls']:
# Excel文件额外信息
sheet_names = self.excel_parser.get_sheet_names(file_path)
additional_info = {
'sheet_names': sheet_names,
'sheet_count': len(sheet_names)
}
elif ext == '.docx':
# Word文件额外信息
table_count = self.word_parser.get_table_count(file_path)
additional_info = {
'table_count': table_count
}
except Exception:
# 如果获取额外信息失败,不影响基本信息返回
pass
return {
'file_name': file_name,
'file_size': file_size,
'file_type': ext,
'is_supported': is_supported,
'additional_info': additional_info
}
def batch_parse(self, file_paths: List[str], **kwargs) -> List[Dict[str, Any]]:
"""批量解析多个文件
Args:
file_paths: 文件路径列表
**kwargs: 额外参数
Returns:
List[Dict]: 解析结果列表,每个元素包含文件路径和解析结果或错误信息
"""
results = []
for file_path in file_paths:
try:
result = self.parse(file_path, **kwargs)
results.append({
'file_path': file_path,
'success': True,
'result': result,
'error': None
})
except Exception as e:
results.append({
'file_path': file_path,
'success': False,
'result': None,
'error': str(e)
})
return results
def _filter_empty_rows(self, data: List[List[str]]) -> List[List[str]]:
"""过滤掉全是空值的行
Args:
data: 原始数据行列表
Returns:
List[List[str]]: 过滤后的数据行列表
"""
filtered_data = []
for row in data:
# 检查行是否全为空(空字符串、None或只包含空白字符)
if any(cell and str(cell).strip() for cell in row):
filtered_data.append(row)
return filtered_data
def _trim_headers(self, headers: List[str]) -> List[str]:
"""过滤标题前后空格
Args:
headers: 原始标题列表
Returns:
List[str]: 过滤后的标题列表
"""
trimmed_headers = []
for header in headers:
if header is None:
trimmed_headers.append('')
else:
trimmed_headers.append(str(header).strip())
return trimmed_headers

http的封装

import requests
import json
from typing import Dict, Any, Optional
from requests.exceptions import RequestException, Timeout, ConnectionError
class HttpClient:
"""HTTP客户端工具类"""
def __init__(self, base_url: str = "", timeout: int = 30):
"""
初始化HTTP客户端
Args:
base_url: 基础URL
timeout: 请求超时时间(秒)
"""
self.base_url = base_url.rstrip('/')
self.timeout = timeout
self.session = requests.Session()
# 设置默认请求头
self.session.headers.update({
'Content-Type': 'application/json',
'User-Agent': 'OfficeAutomation/1.0'
})
def _build_url(self, endpoint: str) -> str:
"""构建完整URL"""
if endpoint.startswith('http'):
return endpoint
return f"{self.base_url}/{endpoint.lstrip('/')}"
def _handle_response(self, response: requests.Response) -> Dict[str, Any]:
"""处理响应数据"""
try:
# 检查状态码
if response.status_code >= 400:
error_data = response.json() if response.content else {}
error_message = error_data.get('message', f'HTTP {response.status_code} Error')
# 根据状态码返回不同的错误信息
if response.status_code == 400:
error_message = f"请求参数错误: {error_message}"
elif response.status_code == 401:
error_message = f"认证失败: {error_message}"
elif response.status_code == 403:
error_message = f"权限不足: {error_message}"
elif response.status_code == 404:
error_message = f"资源不存在: {error_message}"
elif response.status_code == 500:
error_message = f"服务器内部错误: {error_message}"
elif response.status_code >= 500:
error_message = f"服务器错误: {error_message}"
raise Exception(error_message)
# 返回JSON数据
return response.json() if response.content else {}
except json.JSONDecodeError as e:
# JSON解析错误
raise Exception(f"服务器返回数据格式错误: {str(e)}")
except Exception as e:
if "请求参数错误" in str(e) or "认证失败" in str(e) or "权限不足" in str(e) or "资源不存在" in str(e) or "服务器" in str(e):
raise
raise Exception(f"响应处理错误: {str(e)}")
def get(self, endpoint: str, params: Optional[Dict[str, Any]] = None,
headers: Optional[Dict[str, str]] = None) -> Dict[str, Any]:
"""
发送GET请求
Args:
endpoint: 接口端点
params: 查询参数
headers: 请求头
Returns:
响应数据字典
Raises:
Exception: 请求失败时抛出异常
"""
try:
url = self._build_url(endpoint)
response = self.session.get(
url,
params=params,
headers=headers,
timeout=self.timeout
)
return self._handle_response(response)
except Timeout:
raise Exception("请求超时,请检查网络连接或增加超时时间")
except ConnectionError as e:
raise Exception(f"网络连接失败: {str(e)},请检查网络设置")
except requests.exceptions.SSLError as e:
raise Exception(f"SSL证书验证失败: {str(e)}")
except requests.exceptions.TooManyRedirects as e:
raise Exception(f"重定向次数过多: {str(e)}")
except RequestException as e:
raise Exception(f"网络请求异常: {str(e)}")
def post(self, endpoint: str, data: Optional[Dict[str, Any]] = None,
json_data: Optional[Dict[str, Any]] = None,
headers: Optional[Dict[str, str]] = None) -> Dict[str, Any]:
"""
发送POST请求
Args:
endpoint: 接口端点
data: 表单数据
json_data: JSON数据
headers: 请求头
Returns:
响应数据字典
Raises:
Exception: 请求失败时抛出异常
"""
try:
url = self._build_url(endpoint)
response = self.session.post(
url,
data=data,
json=json_data,
headers=headers,
timeout=self.timeout
)
return self._handle_response(response)
except Timeout:
raise Exception("请求超时,请检查网络连接或增加超时时间")
except ConnectionError as e:
raise Exception(f"网络连接失败: {str(e)},请检查网络设置")
except requests.exceptions.SSLError as e:
raise Exception(f"SSL证书验证失败: {str(e)}")
except requests.exceptions.TooManyRedirects as e:
raise Exception(f"重定向次数过多: {str(e)}")
except RequestException as e:
raise Exception(f"网络请求异常: {str(e)}")
def put(self, endpoint: str, data: Optional[Dict[str, Any]] = None,
json_data: Optional[Dict[str, Any]] = None,
headers: Optional[Dict[str, str]] = None) -> Dict[str, Any]:
"""
发送PUT请求
Args:
endpoint: 接口端点
data: 表单数据
json_data: JSON数据
headers: 请求头
Returns:
响应数据字典
"""
try:
url = self._build_url(endpoint)
response = self.session.put(
url,
data=data,
json=json_data,
headers=headers,
timeout=self.timeout
)
return self._handle_response(response)
except Timeout:
raise Exception("请求超时,请检查网络连接或增加超时时间")
except ConnectionError as e:
raise Exception(f"网络连接失败: {str(e)},请检查网络设置")
except requests.exceptions.SSLError as e:
raise Exception(f"SSL证书验证失败: {str(e)}")
except requests.exceptions.TooManyRedirects as e:
raise Exception(f"重定向次数过多: {str(e)}")
except RequestException as e:
raise Exception(f"网络请求异常: {str(e)}")
def delete(self, endpoint: str, params: Optional[Dict[str, Any]] = None,
headers: Optional[Dict[str, str]] = None) -> Dict[str, Any]:
"""
发送DELETE请求
Args:
endpoint: 接口端点
params: 查询参数
headers: 请求头
Returns:
响应数据字典
"""
try:
url = self._build_url(endpoint)
response = self.session.delete(
url,
params=params,
headers=headers,
timeout=self.timeout
)
return self._handle_response(response)
except Timeout:
raise Exception("请求超时,请检查网络连接或增加超时时间")
except ConnectionError as e:
raise Exception(f"网络连接失败: {str(e)},请检查网络设置")
except requests.exceptions.SSLError as e:
raise Exception(f"SSL证书验证失败: {str(e)}")
except requests.exceptions.TooManyRedirects as e:
raise Exception(f"重定向次数过多: {str(e)}")
except RequestException as e:
raise Exception(f"网络请求异常: {str(e)}")
def set_auth_token(self, token: str):
"""设置认证令牌"""
self.session.headers.update({
'Authorization': f'Bearer {token}'
})
def set_base_url(self, base_url: str):
"""设置基础URL"""
self.base_url = base_url.rstrip('/')
def close(self):
"""关闭会话"""
self.session.close()

如果您有疑问可以一起来探讨,今天就介绍到 这里 ,希望能帮助大家,感谢!!!
文章末尾关注公众号,回复:“小鱼办公” , 查看解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)