[AI]从零开始的SDXL LORA训练进阶教程
讲解了SDXL LORA训练底模的选择与数据集、训练参数的优化与训练模型质量验证!
一、前言
在上一篇教程中,教了大家如何通过少量的图片从零训练一个LORA,其中的步骤可以说是非常简单,但是我们训练出来的LORA可能具有一些问题。比如我们基于SDXL底模训练出来的LORA可能在为我们画图时难以被控制,总会画出崩坏的身体或者多余的手或者脚,又或者是我们需要加特定的某个提示词LORA才会触发。上面这些问题的根本原因就是我们选择的底模针对性不强,以及我们的数据集质量不高再加上我们几乎没有调整过训练的参数,也就导致训练出来的LORA质量不高。所以,本次教程就来教大家如何选择训练的底模以及如何进行数据集优化和训练参数调整,如果你准备好了,就让我们开始吧!
二、声明
在开始之前同样在此声明,我并不是专业的SD模型工程师,不具备非常专业的知识,文章中的模型,参数,概念某些来自网络某些源于我自己摸索,如果有不正确的地方,欢迎指正!
三、SDXL训练模型选择
在开始训练之前,我们首先应该着重于去选择一款与我们训练内容相符合的底模。这里有人可能就要问了,什么是与我们训练内容相符合的底模呢?这里我们拿“sd_xl_base”来举例,这就是我们在上一篇教程中使用到的SDXL底模,它是由SD官方训练出来的,包含了生活中常见的事物以及人物形象等,实际使用中大家可能会发现,在这个模型上训练的LORA在搭配其底模出图时效果并不好,就是因为这个SD训练的SDXL底模包含了太多内容,所以在画二次元图片时的表现就没那么好。针对这种情况我们应该怎么办呢?当然是去找针对我们训练内容的底模,如果想训练动漫角色就应该使用专为动漫角色优化过的SDXL底模,如果想画真人,那就使用专为真人优化的底模,在底模的选择上很关键。
既然说了这么多,我们究竟应该怎么选择模型呢?其实非常简单,我们只需要去寻找基于“sd_xl_base”基础模型进行专业微调的模型即可。这里我仍然使用动漫人物模型进行举例,像“Illustrious-XL”与“Pony_Diffusion_V6_XL”这两款模型都在“sd_xl_base”底模的基础上进行了动漫人物的微调,也就是说,这两款模型在画动漫人物时表现会更好。这里有的小伙伴可能有疑问,既然这些模型都是基于“sd_xl_base”的基础模型,那我们在“sd_xl_base”上训练出来的LORA能不能运行在这两款模型上呢?答案是肯定的,因为他们都基于“sd_xl_base”。并且因为“Illustrious-XL”与“Pony_Diffusion_V6_XL”专门针对动漫人物进行了优化,所以我们的LORA甚至在这两款模型上表现更好。其实到了这里我们就可以得出一个结论,基于“sd_xl_base”直接训练出效果相对差,但是兼容性最好,它几乎可以兼容所有基于“sd_xl_base”训练的模型。
理解了上面的概念以后,让我们继续,如果我们基于“Illustrious-XL”与“Pony_Diffusion_V6_XL”训练LORA,那么这个LORA能够互相兼容吗?当然可以,因为他们都基于“sd_xl_base”训练。但是在实际操作中,并不推荐你这么做,实际测试下来这样做的效果可能并不好。这两个模型某种意义上属于不同的分支。那我们基于“Illustrious-XL”与“Pony_Diffusion_V6_XL”训练的LORA模型能放在“sd_xl_base”上运行吗,当然答案也是肯定的,但是,LORA几乎不起任何作用,无法还原角色了。所以,这里我们又可以得出一个结论,基于上层模型训练LORA不能放到底层模型上运行,同层模型训练的LORA兼容性较差,不推荐将LORA交叉使用。
我们继续,大家如果经常看C站,可能会发现这样一个模型,它叫“WAI-NSFW-illustrious-SDXL”,在模型主页我们可以发现这款模型是基于“Illustrious”训练的:
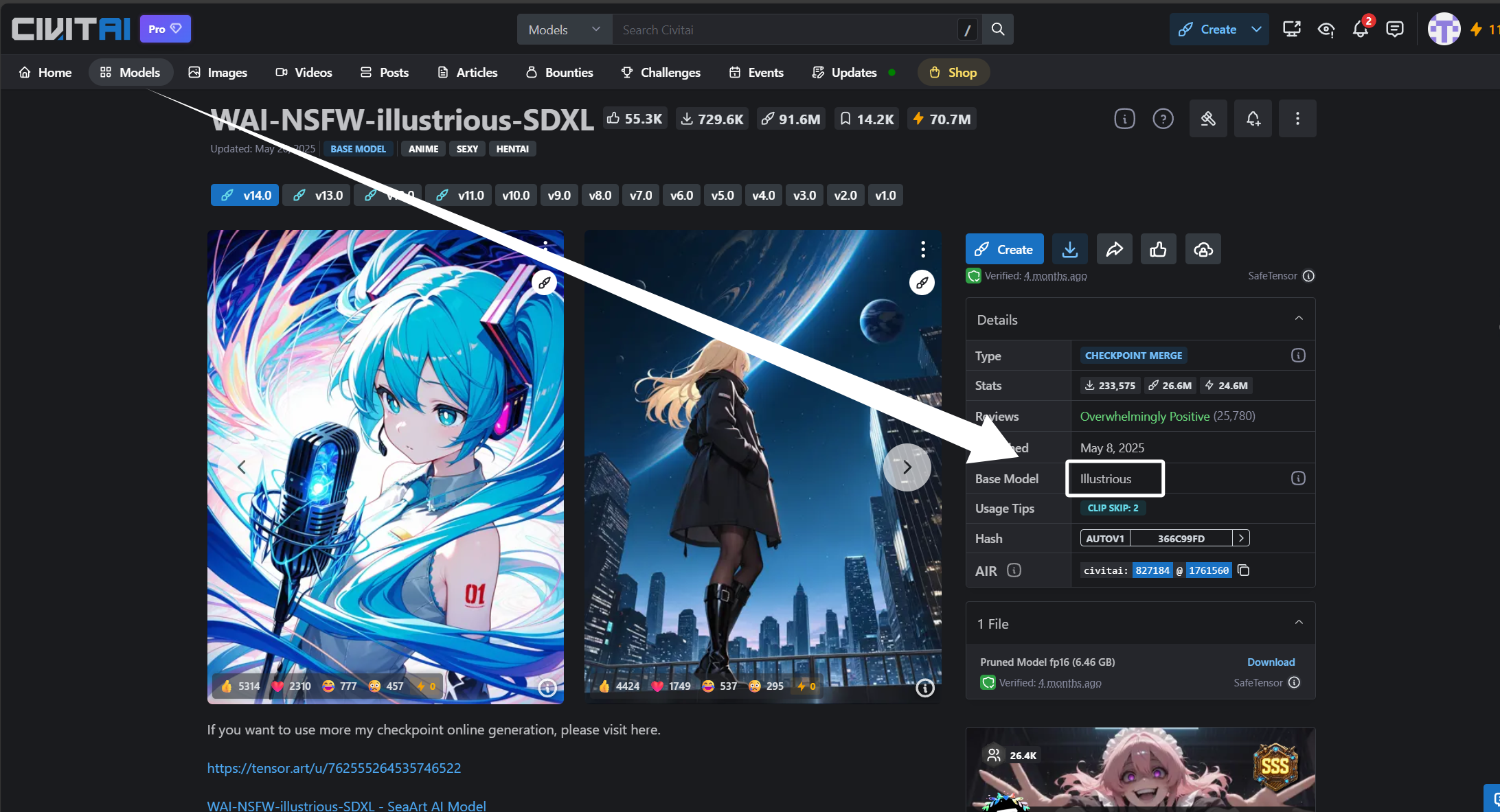
如果我们基于“Illustrious-XL”训练LORA,那么可以放在这款模型上运行吗?当然可以,并且效果较好甚至因为优化出图效果可能比“Illustrious-XL”更好。至此我们又可以得出一个结论,基于“sd_xl_base”训练得到“Illustrious-XL”,再基于“Illustrious-XL”训练得到的“WAI-NSFW-illustrious-SDXL”可以运行我们基于“Illustrious-XL”训练的LORA,也可以运行我们基于“sd_xl_base”训练的LORA。基于底层模型训练的LORA可以直接在上层模型使用,但是不建议嵌套太多层,比如我们将“sd_xl_base”训练得到的LORA放到“WAI-NSFW-illustrious-SDXL”上,效果就没有将基于“Illustrious-XL”训练得到的LORA放到“WAI-NSFW-illustrious-SDXL”上好,当然这其中的原因也有很多,其中最主要的还是底层模型的内容太多,没有进行专业方面的微调,训练的LORA不尽人意。
听了上面的内容,我相信你应该知道怎么去选择模型了,目前,市面上发布的大多数模型都是基于像“Illustrious-XL”这样的底模训练的,比如“WAI-NSFW-illustrious-SDXL”,“Illustrious_miaomiaoHarem_vPredDogma10”,“Illustrious_Anime_5.0”等等......那么,如果我们像训练一个LORA在这些基于“Illustrious-XL”的模型上都能用,我们应该选择哪个底模开始训练呢?当然是“Illustrious-XL”,因为它是后面所有模型的祖先。还记得我上面说的吗?如果同级模型之间交叉使用LORA效果并不好,所以,为了保证我们的LORA在这些同级模型的上一级进行训练,这样我们的模型就兼容了从这一层模型开始的所有下级模型,画个图你就明白了:
这里可以看到我们的“Illustrious-XL”属于二级模型,所有基于“Illustrious-XL”训练的模型都叫三级模型,我们如果想训练一个LORA在所有三级模型上都能使用,就只有选择这些模型共同的上级模型,那就是“Illustrious-XL”。
如果要下载“Illustrious-XL”的话,可以直接在C站或者hf-mirror中搜索“Illustrious”,直接就可以搜索到:
至此,我们训练模型的选择就完成了,相信大家应该也知道怎么选择训练LORA的底模了。
四、数据集优化
针对数据集的优化是SDXL LORA训练中一个非常重要的步骤,可以说数据集的好坏直接决定了模型的质量。在前面的教程中,我们只是将图片裁剪,然后使用SD WebUi里的自动裁剪将其裁剪到我们理想的大小,然后使用标签器为其打上标签。这样制作出来的数据集其实是非常低质量的,自动裁剪并不准确会丢失许多细节,标签的混乱会让模型学习一些非常奇怪的内容,比如背景,和周围环境,而不专注与角色。这样训练出来的LORA虽说是可以画图的,但是整体来说非常低质量出来的图会让我们觉得不尽人意。所以,在开始训练之前,我们一定要优化自己的数据集。这里数据集创建的细节就不多说了,在上一篇教程中已经讲得很详细了。如果你还不知道怎么构建SDXL训练使用的数据集,可以看下面的教程:
SDXL LORA训练教程:https://blog.csdn.net/c858845275/article/details/149898230
这里我使用星穹铁道中的海瑟音来举例,这里我们还是先新建一个与角色名字相关的文件夹,我这里就叫“Helektra”:
然后收集与角色相关的图片,我这里从网络上收集了一些角色的图片,然后也在游戏中直接截取了一些角色的图片,格式与通道转换完以后,如图:
下面我们来构建数据集,首先在“Helektra”文件夹下新建一个名为“image_cut”的文件夹:
这个文件夹用来存我们被我们裁剪好的图片,这次,我们不用后期处理中的自动裁剪功能,我们手动将图片裁剪为1:1,分辨率可以先不管,这里只需要保证我们的图片比例为1:1即可,大家自己使用熟悉的工具裁剪。这里需要注意的是,我们自己裁剪时,尽量保证角色居中,尽量保证角色特征都在图中。裁剪完成以后,如图所示:
当我们裁剪好图片以后,就可以来处理图片的分辨率了,现在我们的图片比例虽然都是1:1了但是分辨率还是参差不齐,这个时候就需要用到WebUI中的后期处理工具了,我们启动WebUI然后点击后期处理:
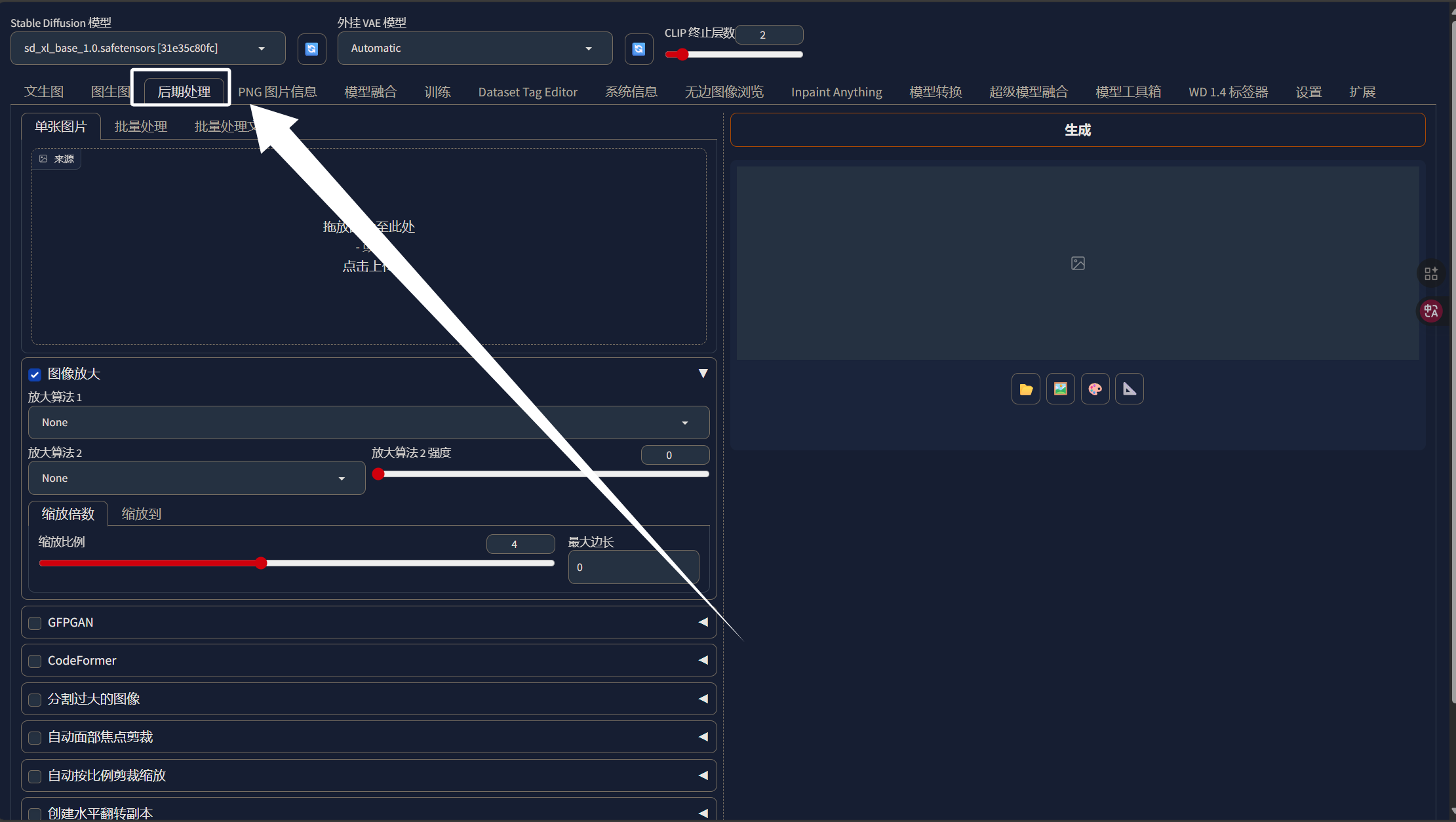
同样选择“批量处理文件夹”把我们裁剪完的文件夹路径写进来:
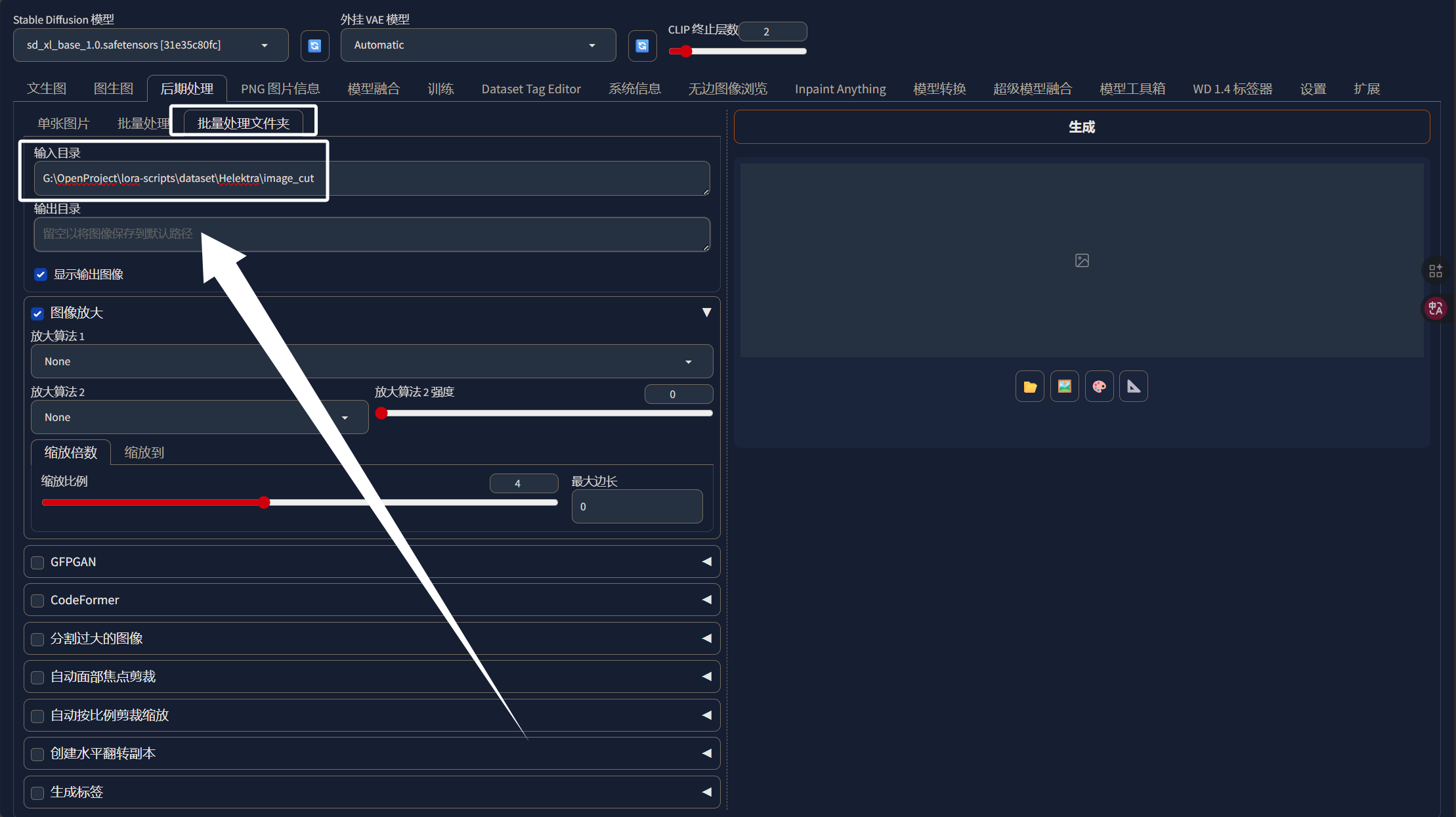
输出目我们用“image_cut_分辨率”的形式,假如我想将图片分辨率调整到1024x1024那么我输出目录就叫“image_cut_1024”,大家根据自己的情况写路径即可:
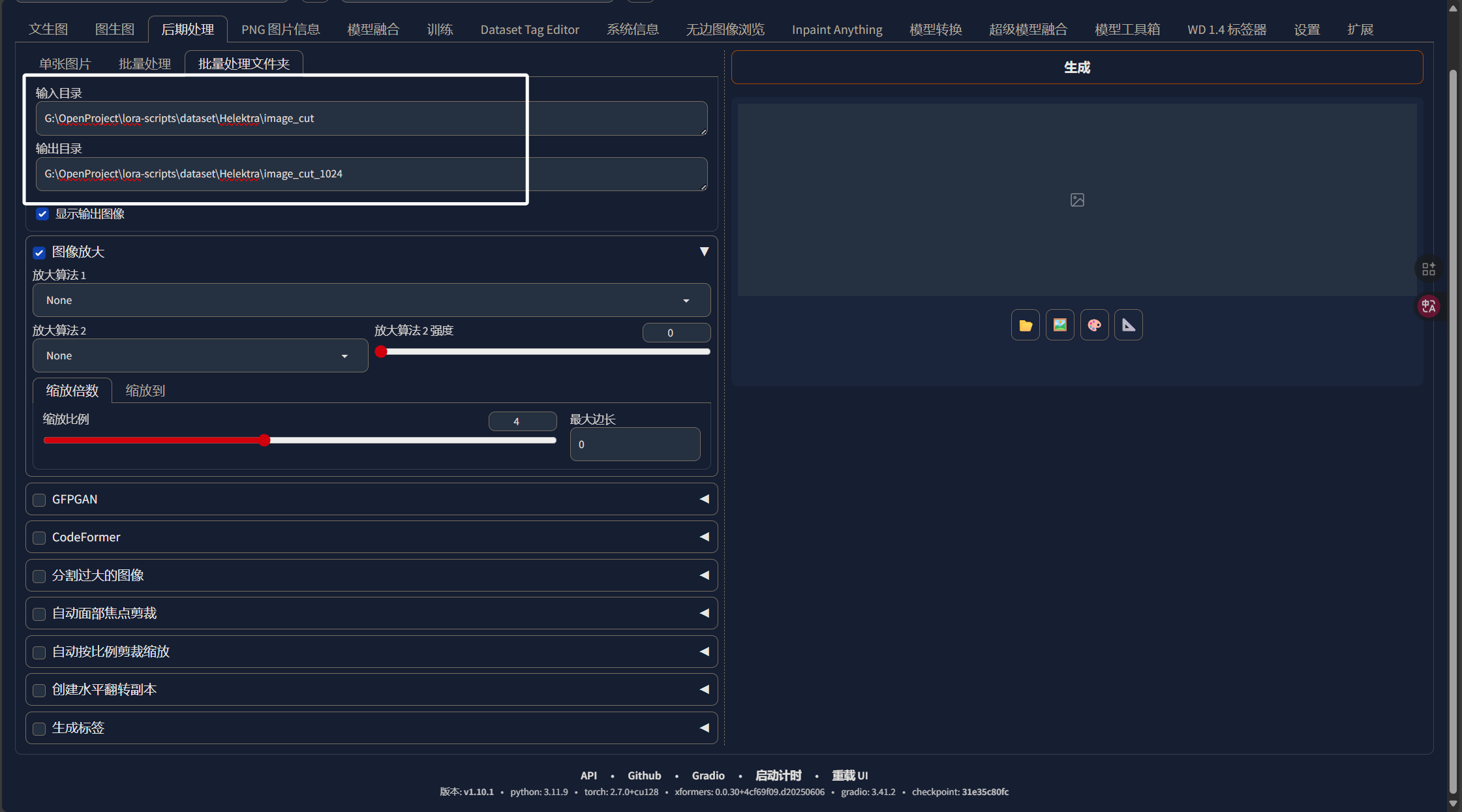
填写好输入输出目录以后,我们选择“图像放大”,选择下面的“缩放到”,大家根据自己的情况选择分辨率:
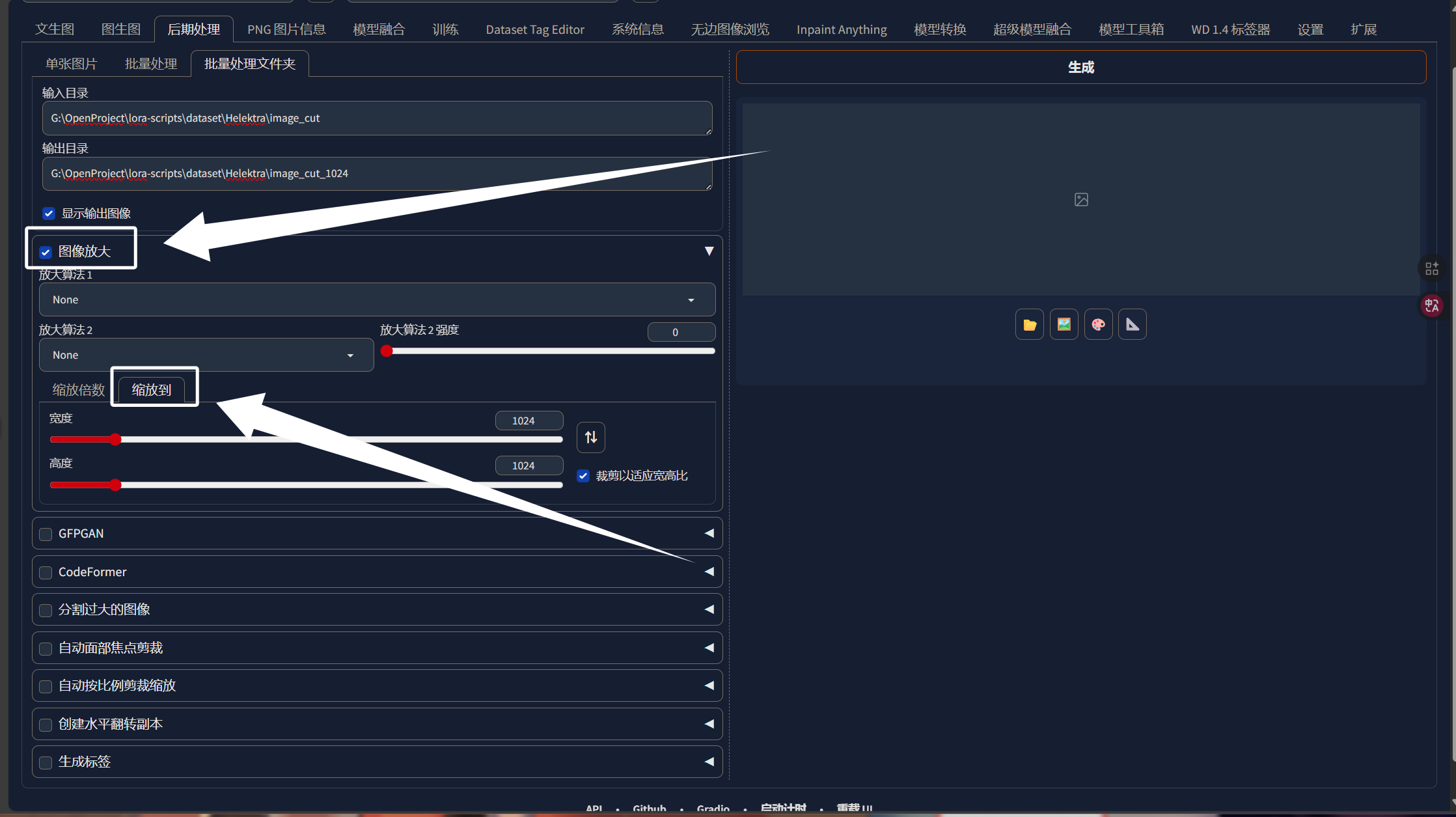
放大算法我们选择“4x-AnimeSharp”即可:
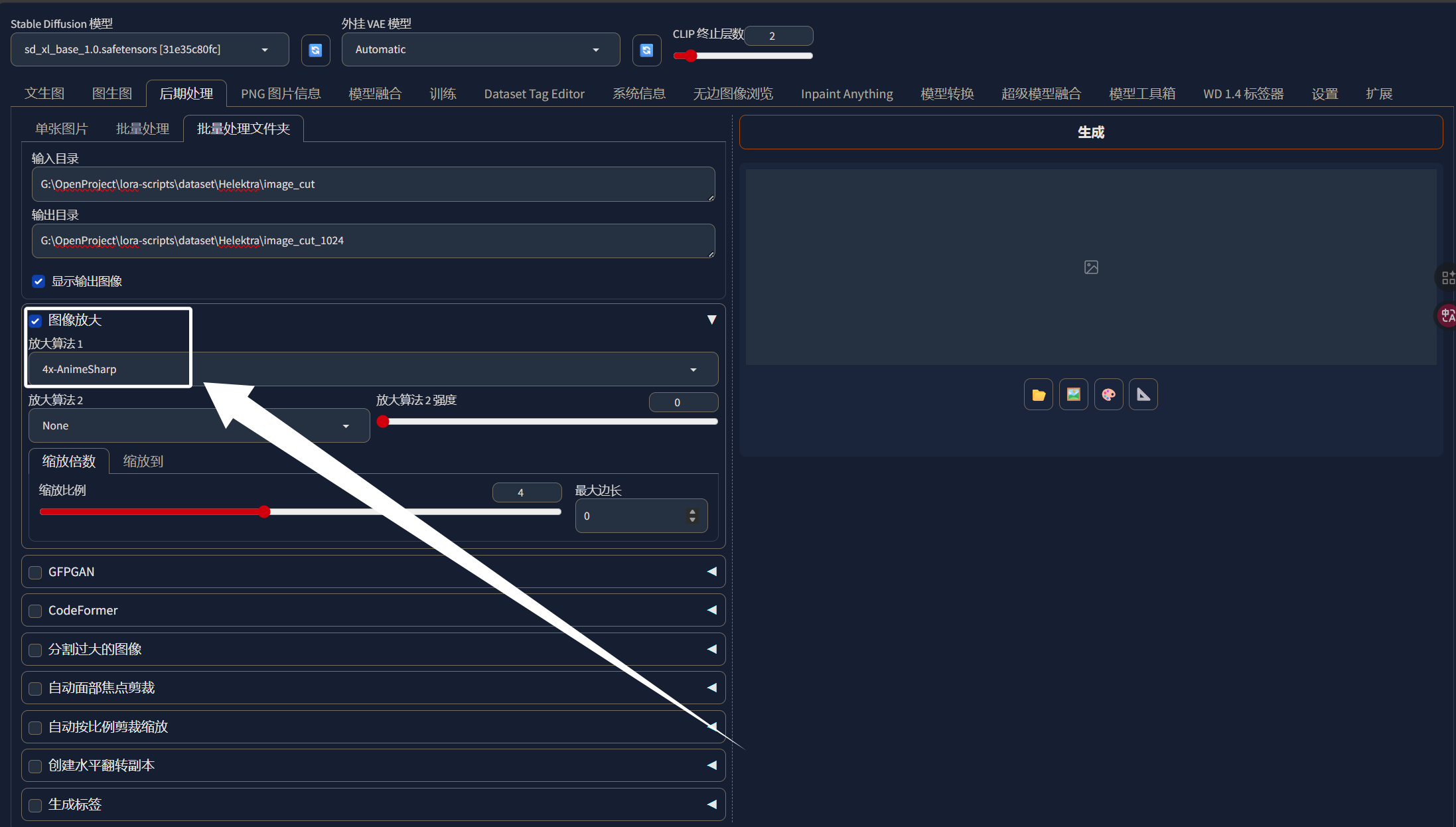
完成上面的步骤以后,我们点击生成即可:
生成完以后,如图所示:
我们的图片分辨率被缩放到了我们指定的分辨率,因为比例是1:1所以整体还是被我裁剪出来的样子:
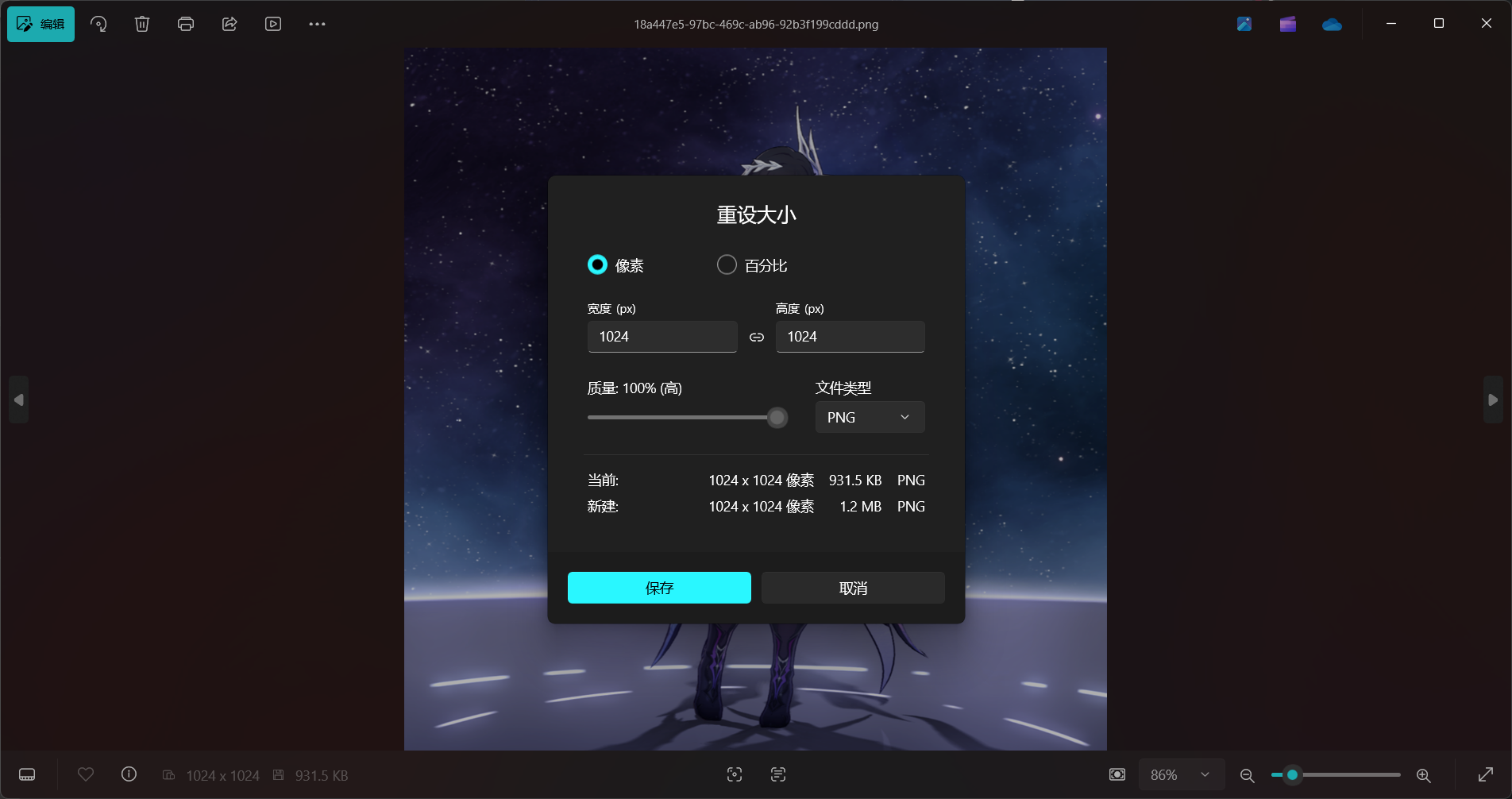
这样,我们数据集的裁剪就完成了。下面我们还是使用“WD 1.4标签器”为我们的数据集生成标签,生成标签后的txt文件要和图像在同一个文件夹中,如图所示:
完成上面的步骤以后,我们的数据集就做好了,到目前位置,我们通过自己裁剪图像解决了自动裁剪不准确的问题,现在我们数据集的标签还是非常混乱的,我们需要整理数据集的标签,这里需要我们在webUI中安装一个名为“Dataset Tag Editor”的插件,github主页如下:
Dataset Tag Editor GitHub:toshiaki1729/stable-diffusion-webui-dataset-tag-editor: Extension to edit dataset captions for SD web UI by AUTOMATIC1111
我们直接在WebUI的主目录下执行下面的克隆命令,将插件克隆到相关目录:
git clone https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor.git extensions/dataset-tag-editor完成以后,我们直接重启WebUi即可,相关依赖会自动安装,WebUI启动以后,我们就可以看到这个插件了:
我们在WebUI中点击这个插件,即可来到插件页面:
将我们制作好的数据集的路径添加进来,然后点击加载:
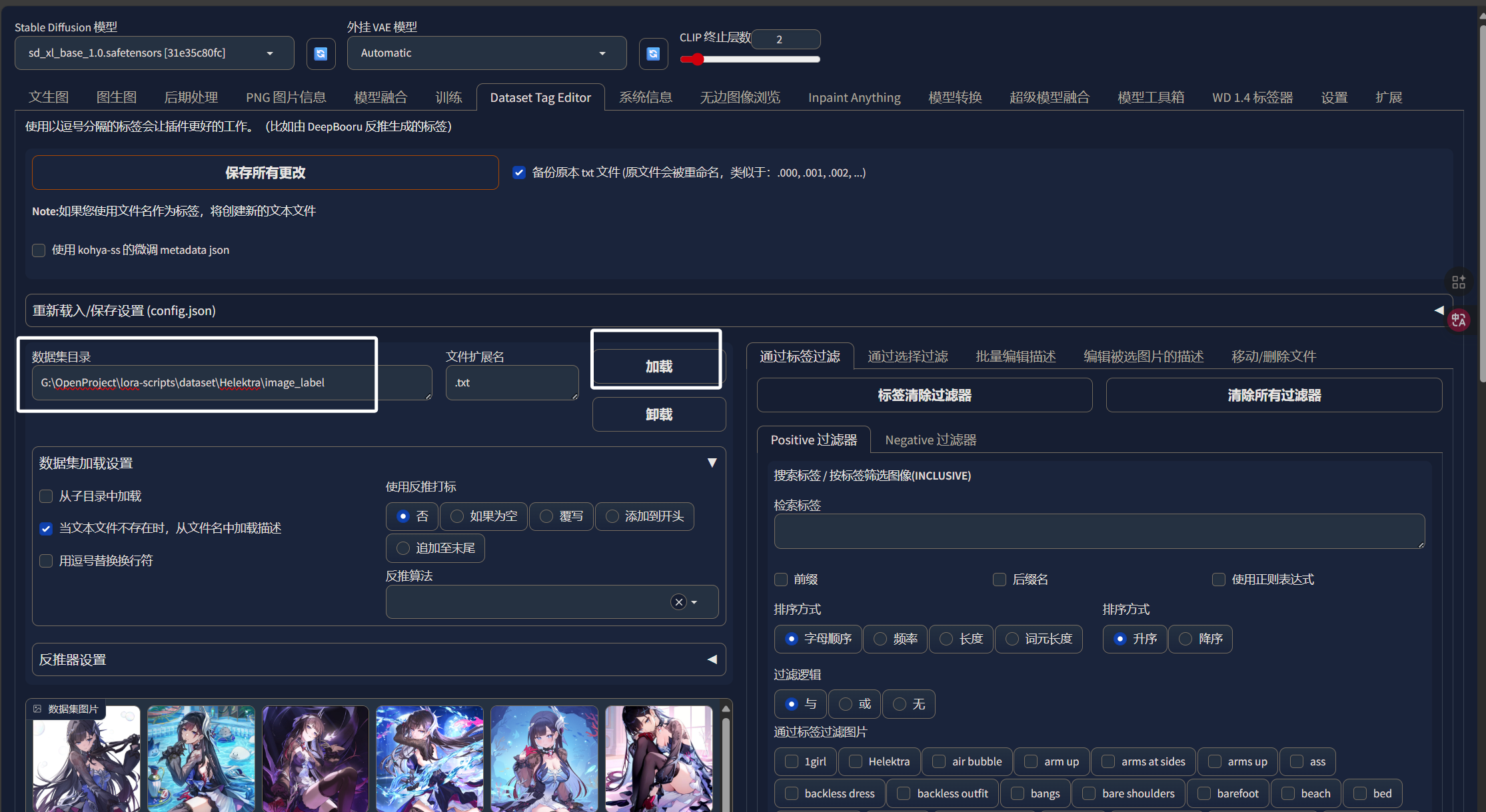
加载完成以后,我们数据集的图片就出现在了左边,数据集中所有标签就出现在了右边:
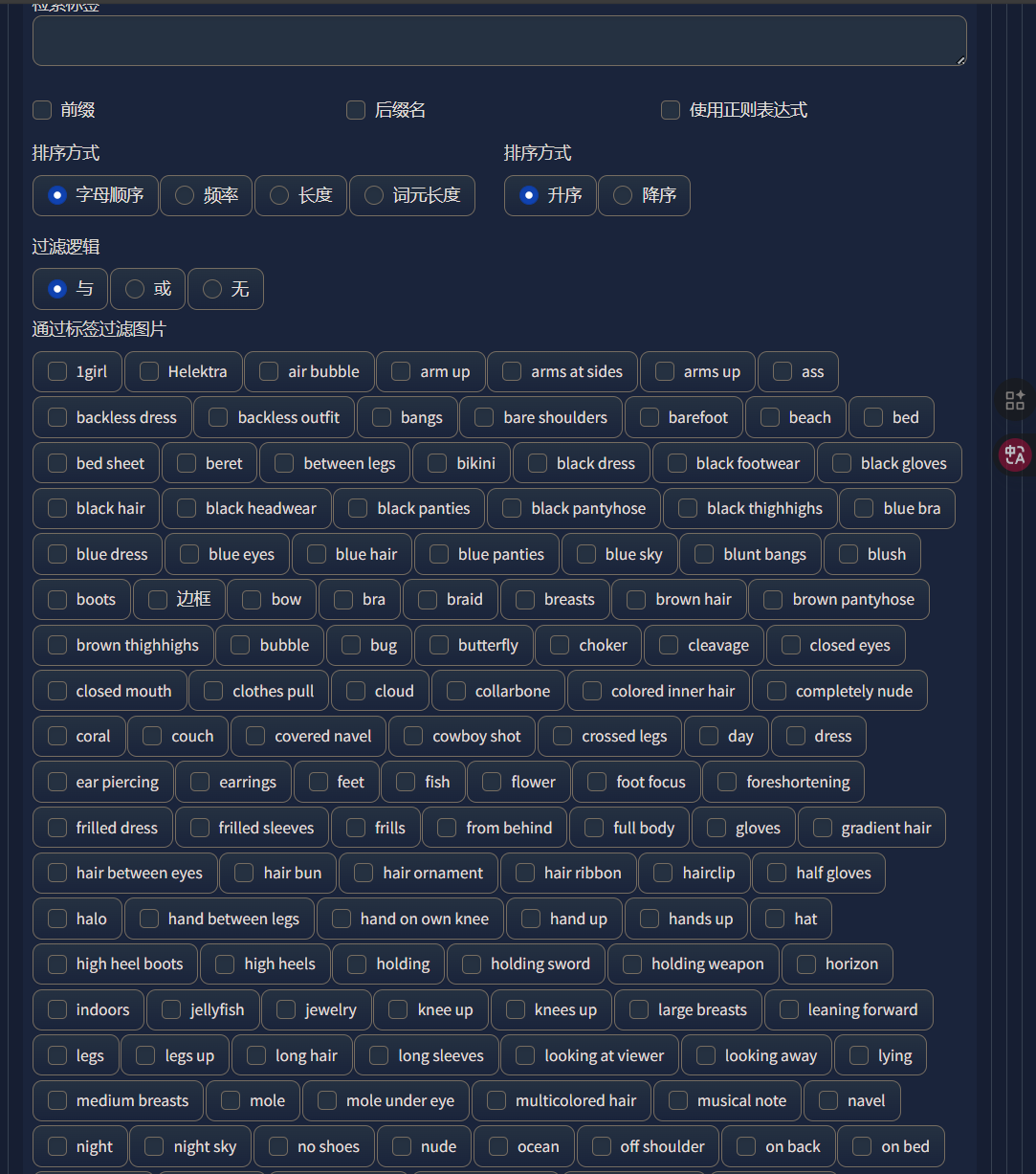
可以看到,这里我们数据集的标签非常多,我们要怎么判断哪些可以用,哪些不能用呢?
其实有个最简单的办法,我们直接复制全部标签,然后问AI应该怎么处理,我是这样问的:
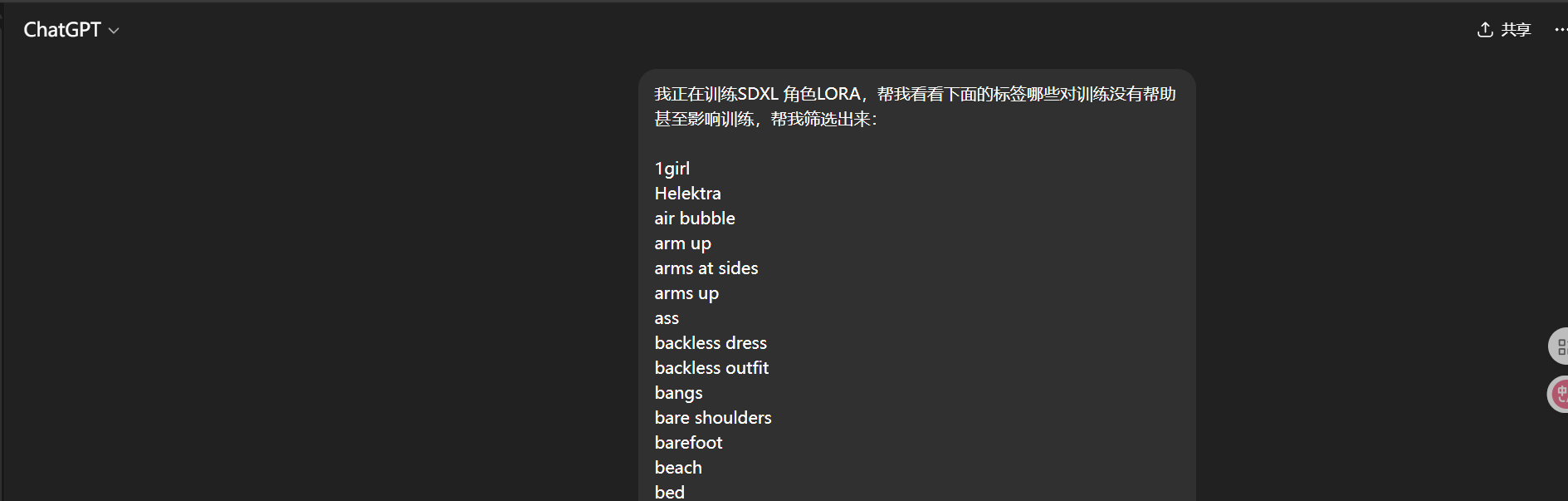
在问之前,一定要告诉AI你训练的是什么类型的LORA,这样AI才能更准确的帮我们筛选提示词。
可以看到AI已经帮我们将那些影响训练的标签给筛选出来了:
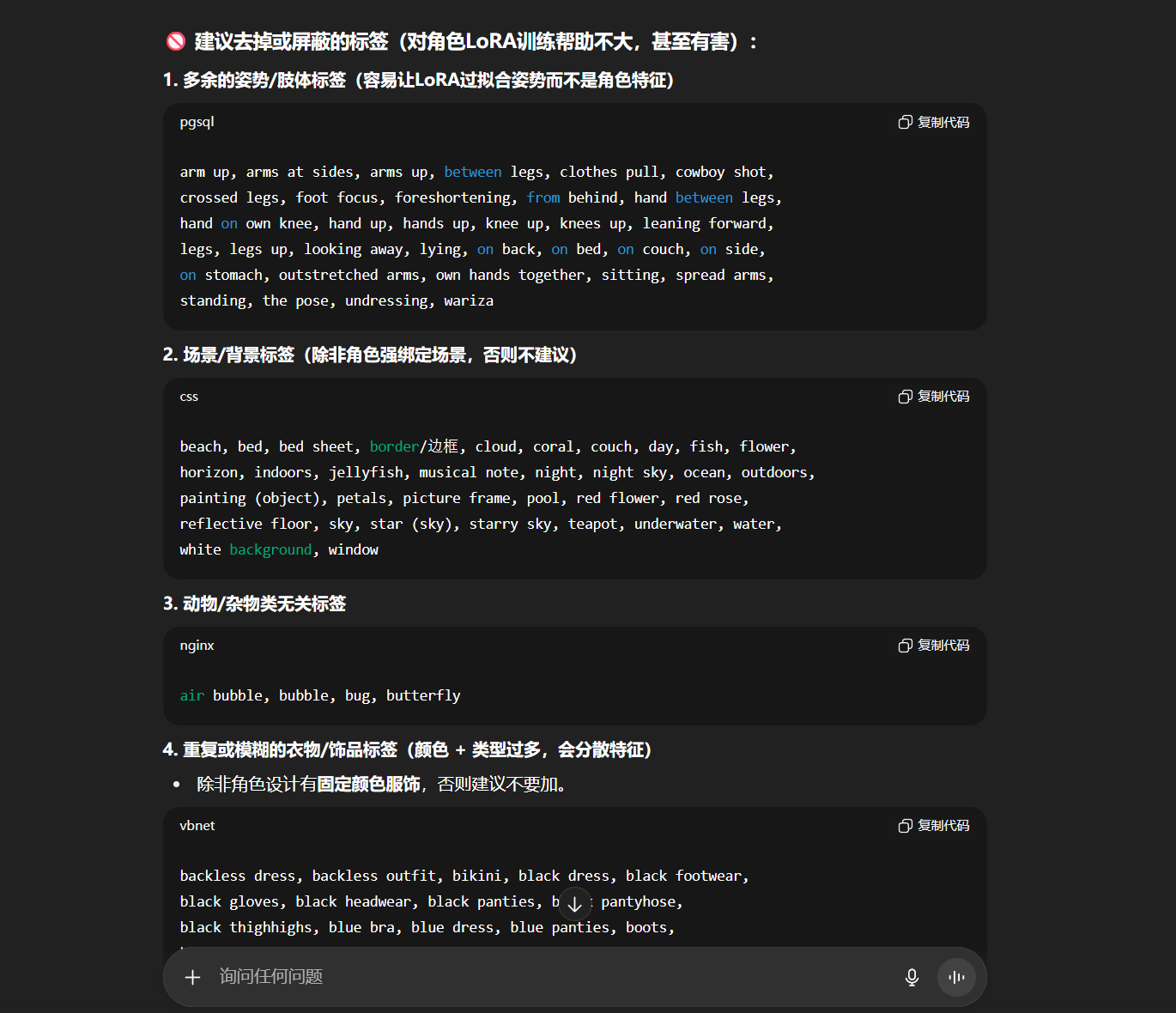
我们可以让AI帮我们列举全部可能影响训练的标签,并且用“|”分隔:
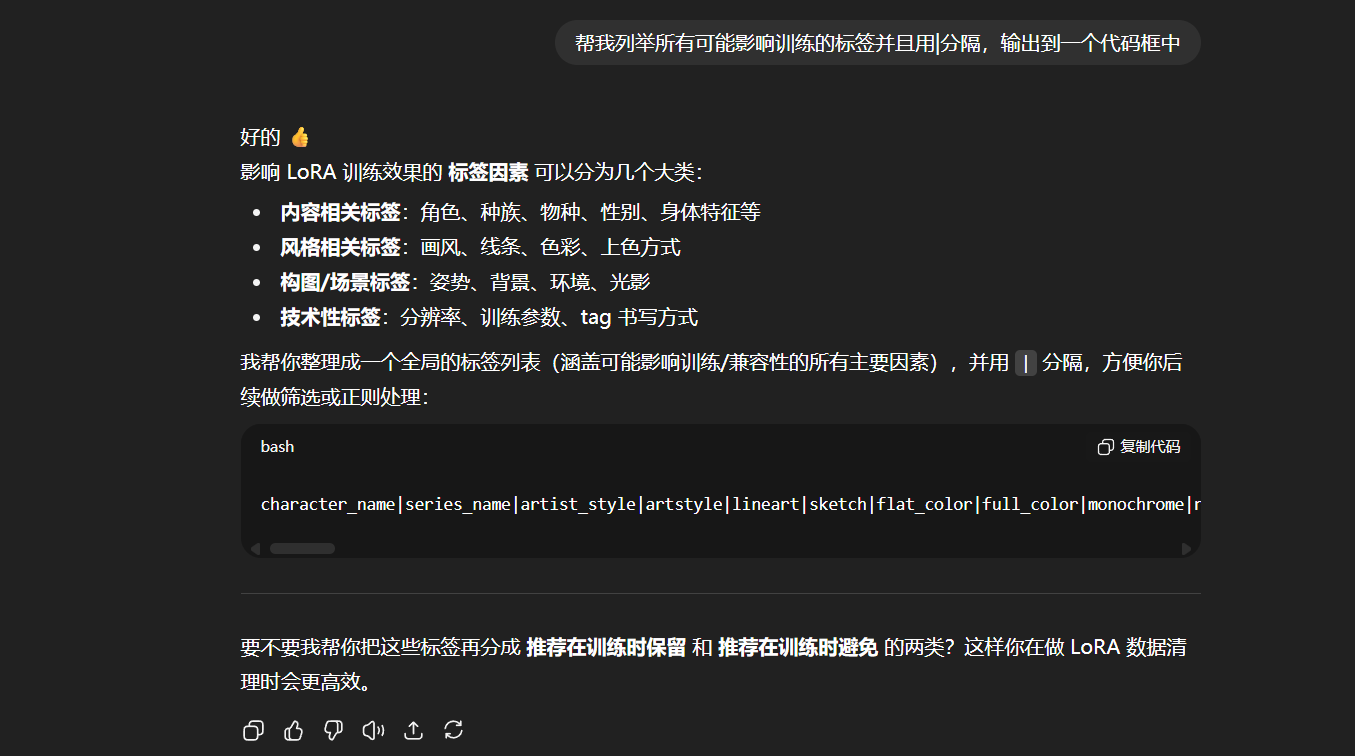
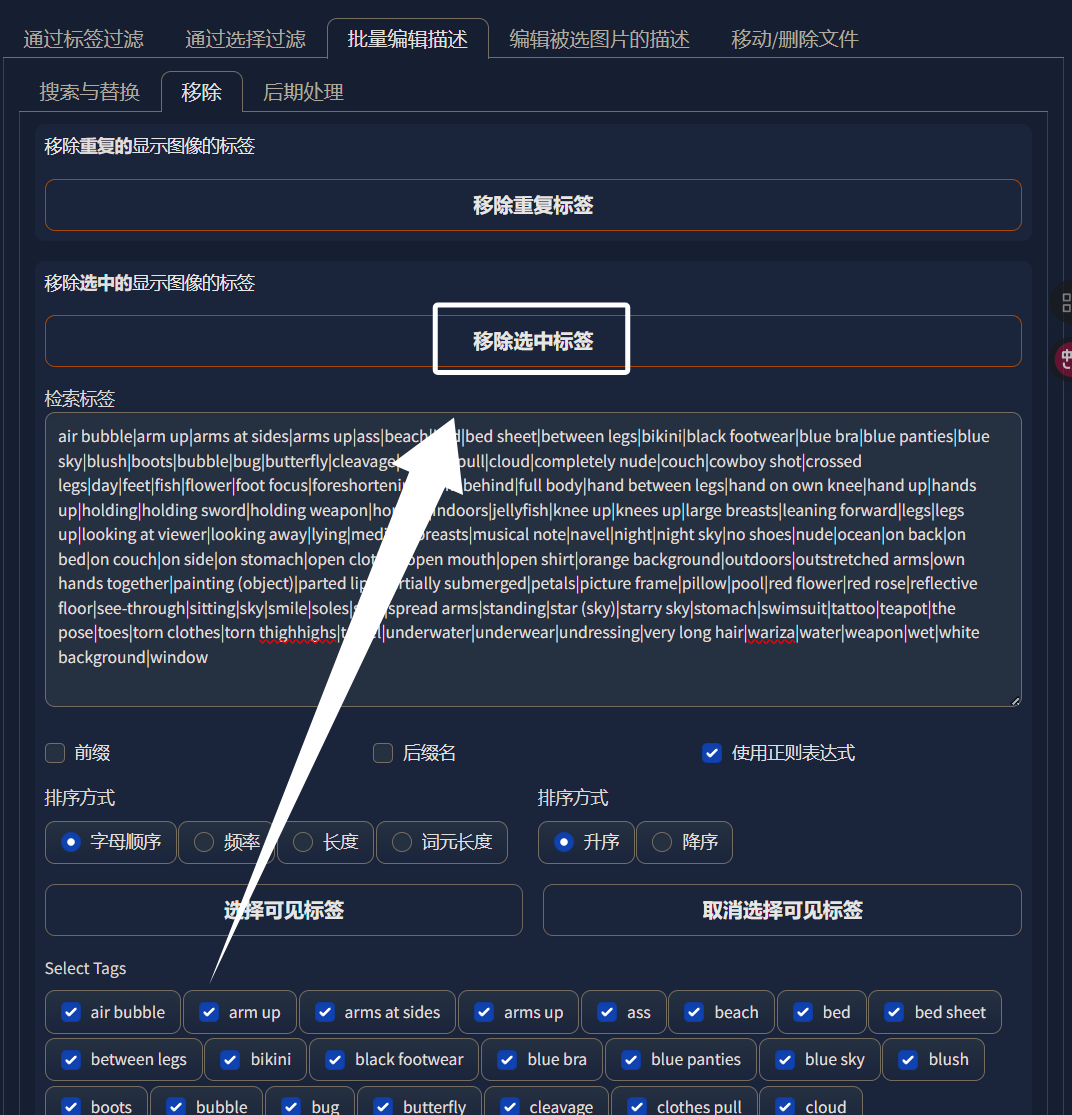
用“|”分隔后面我们可以直接做正则化处理。我们将AI输出的可能影响训练的标签都复制下来,然后我们在WebUI中点击“Dataset Tag Editor”的“批量编辑标签”:
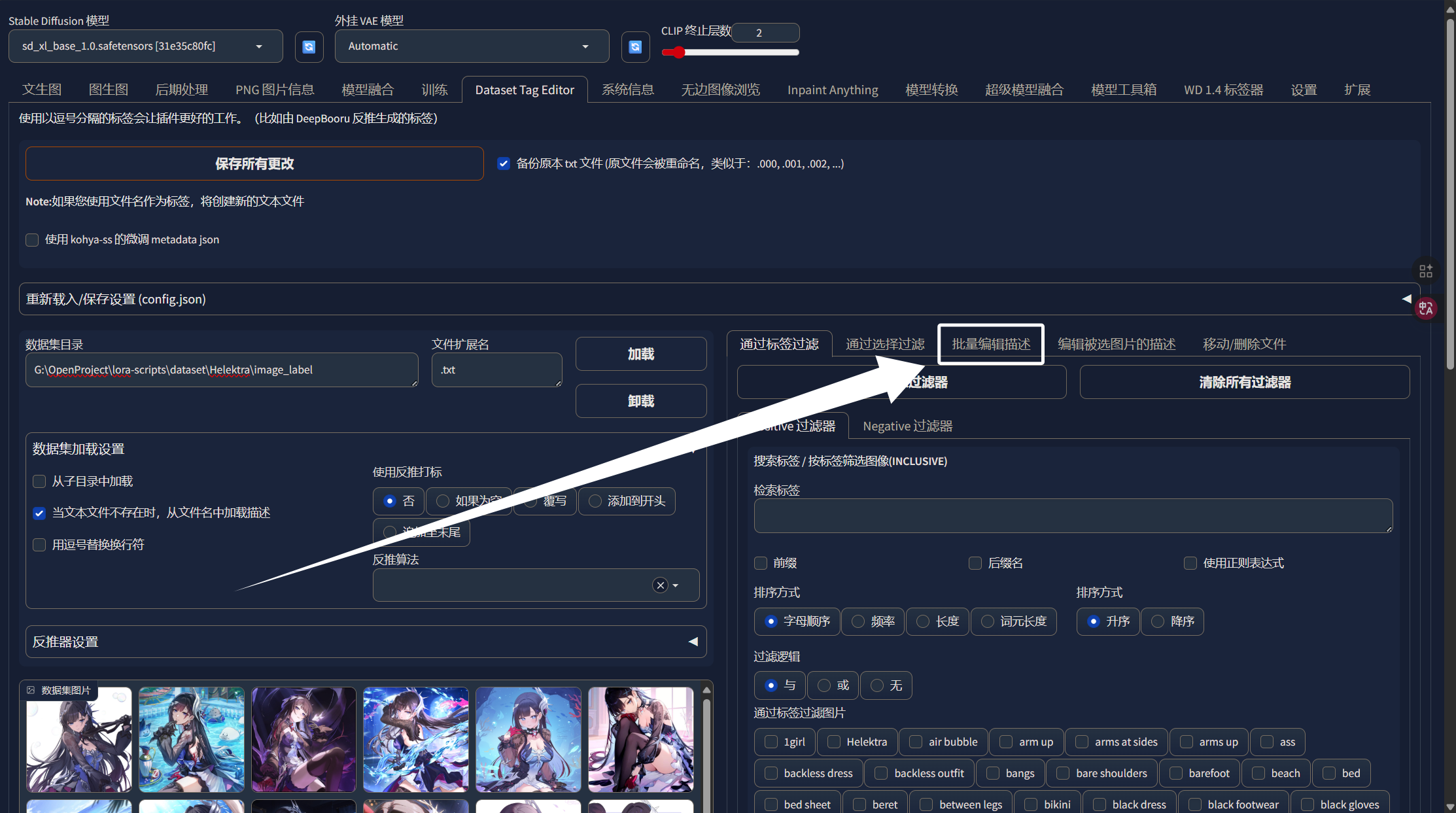
然后点击“移除”:
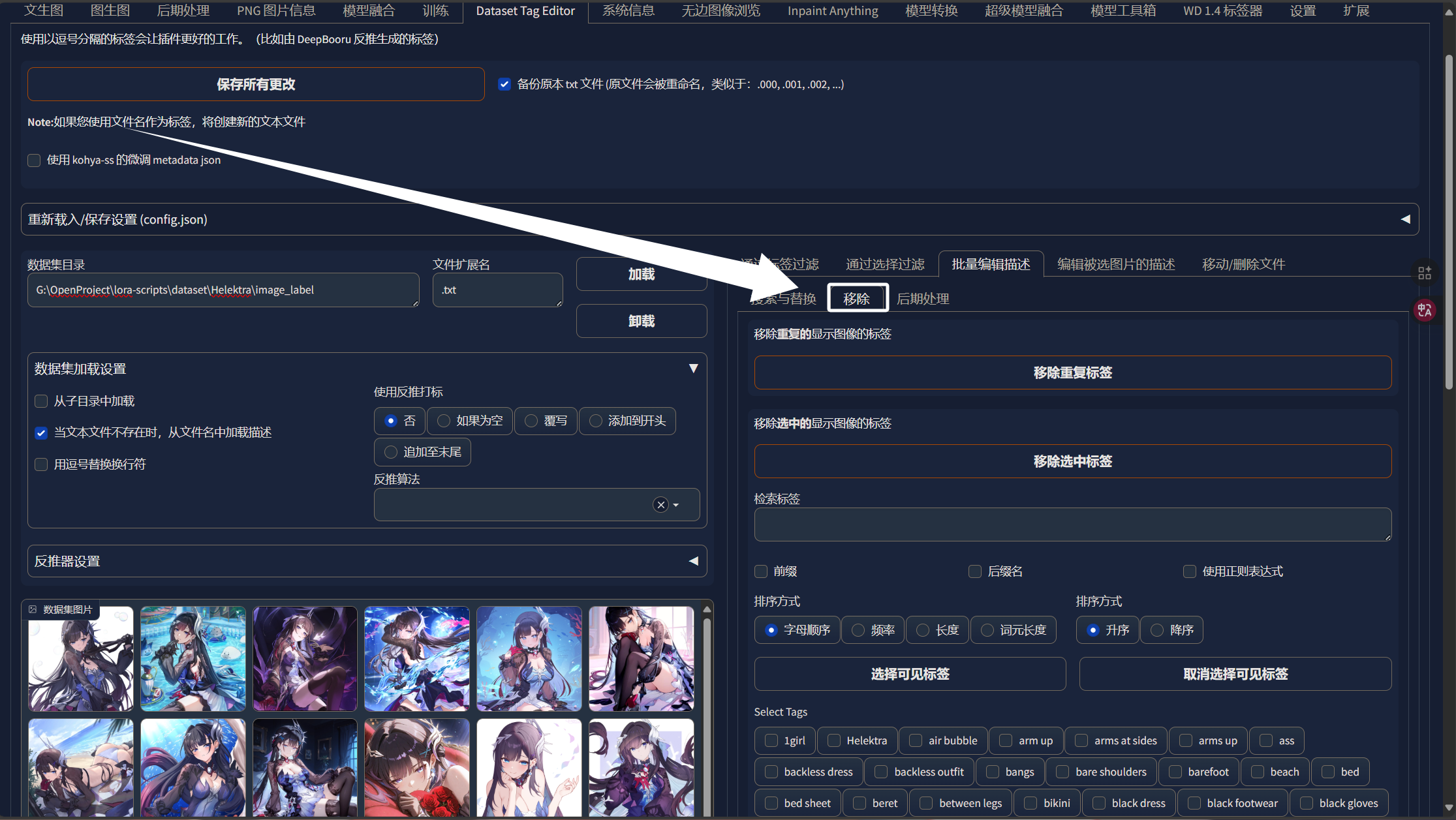
然后把我们从AI那儿复制到的tag复制过来:
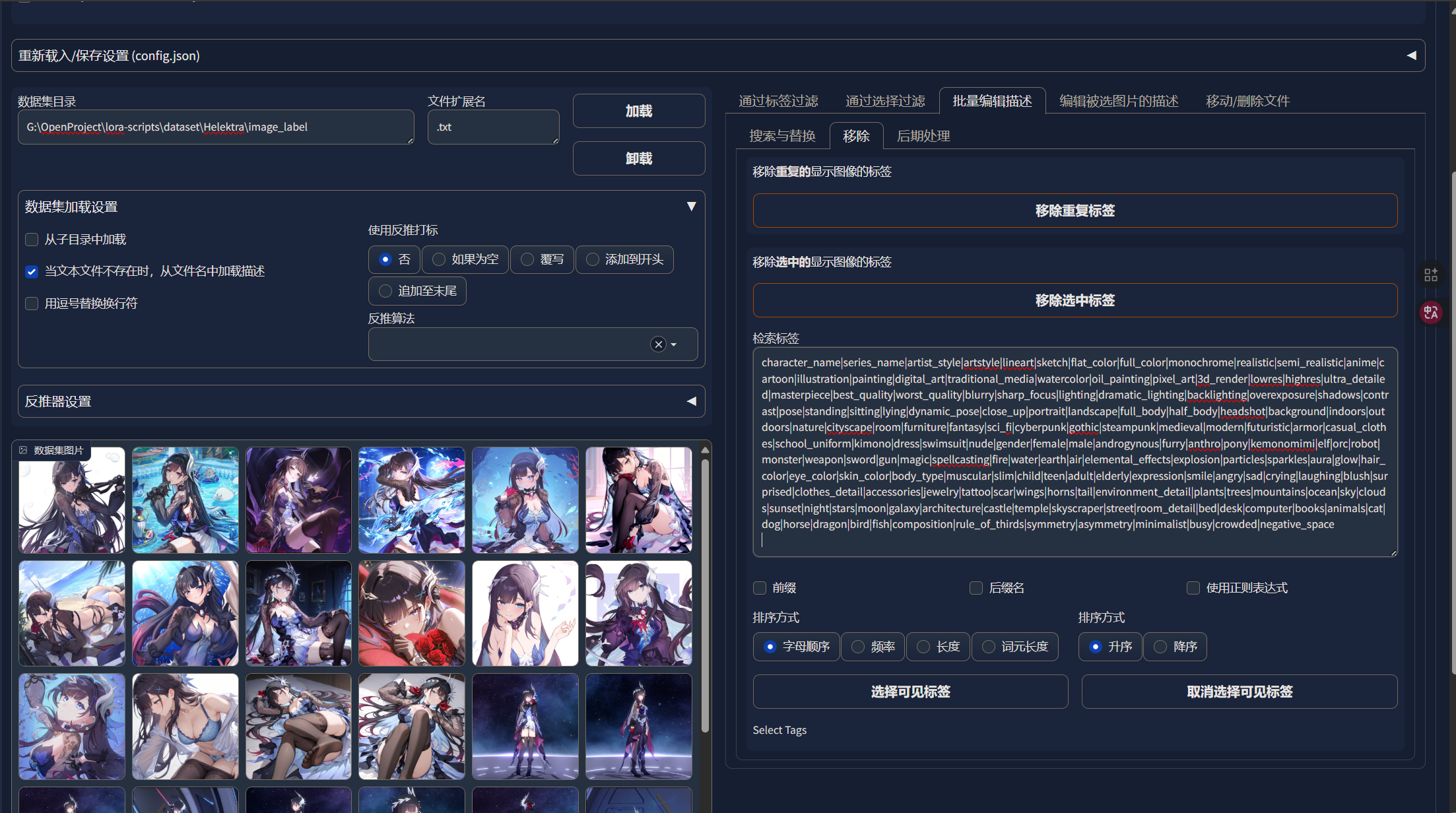
然后勾选“使用正则表达式”:
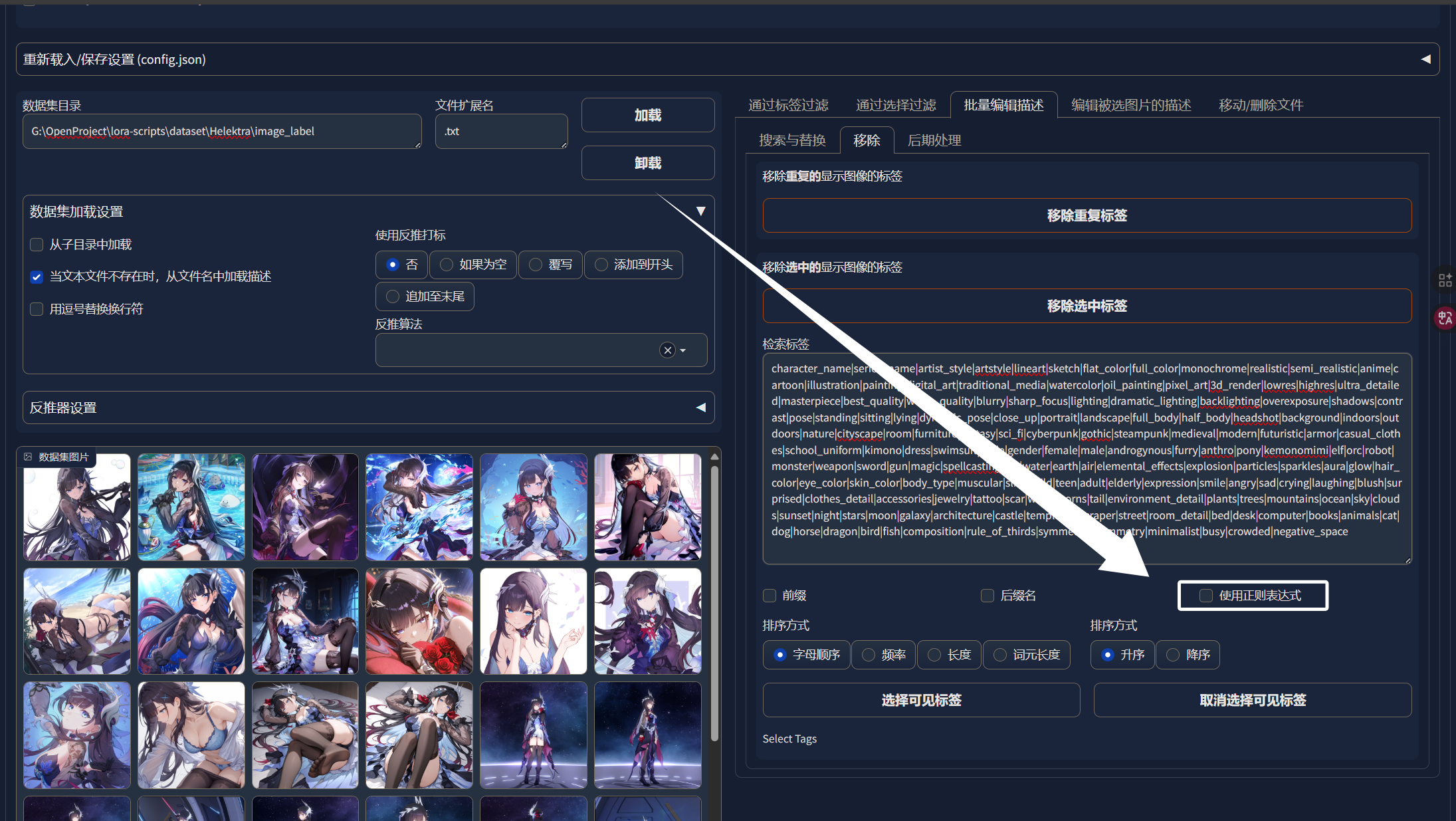
我们可以看到出现了非常多的标签:
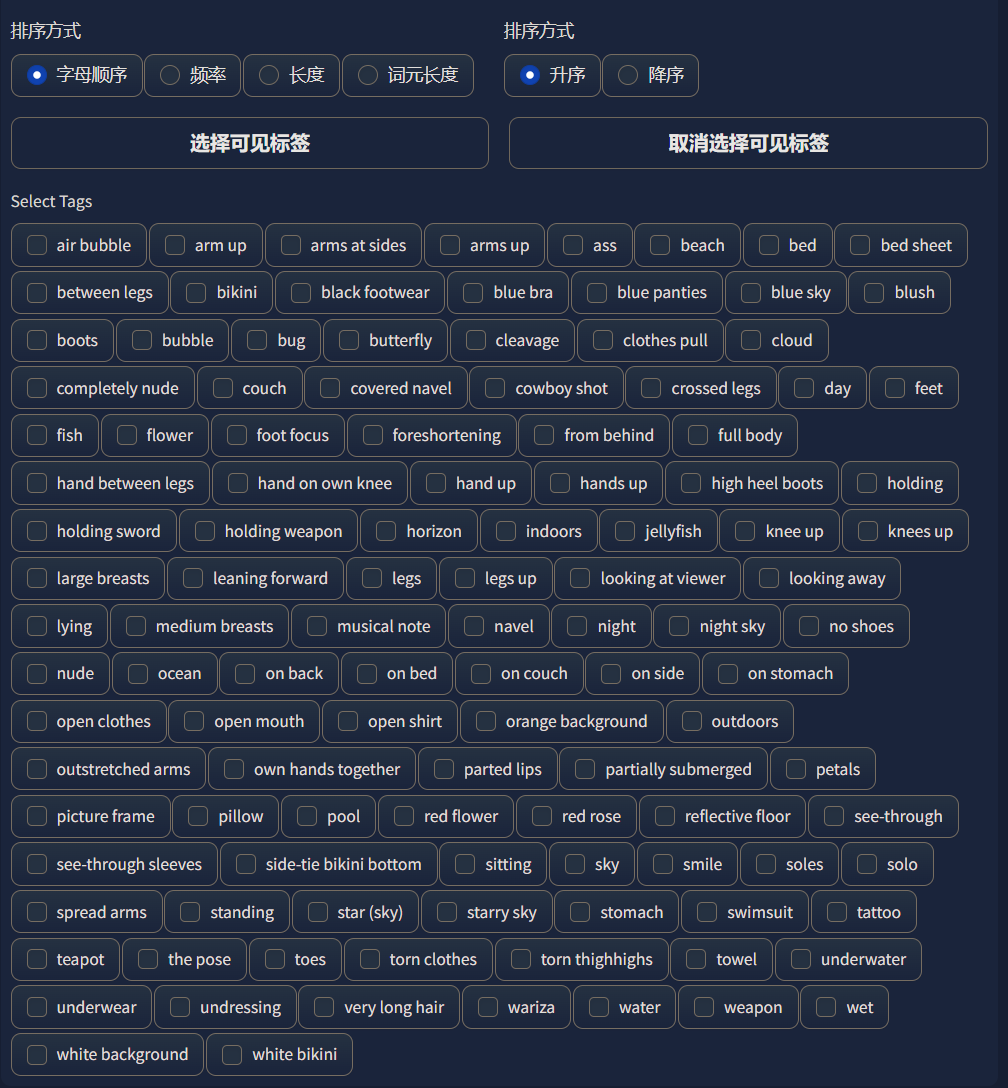
这里我们手动选中所有被列举出来的标签:
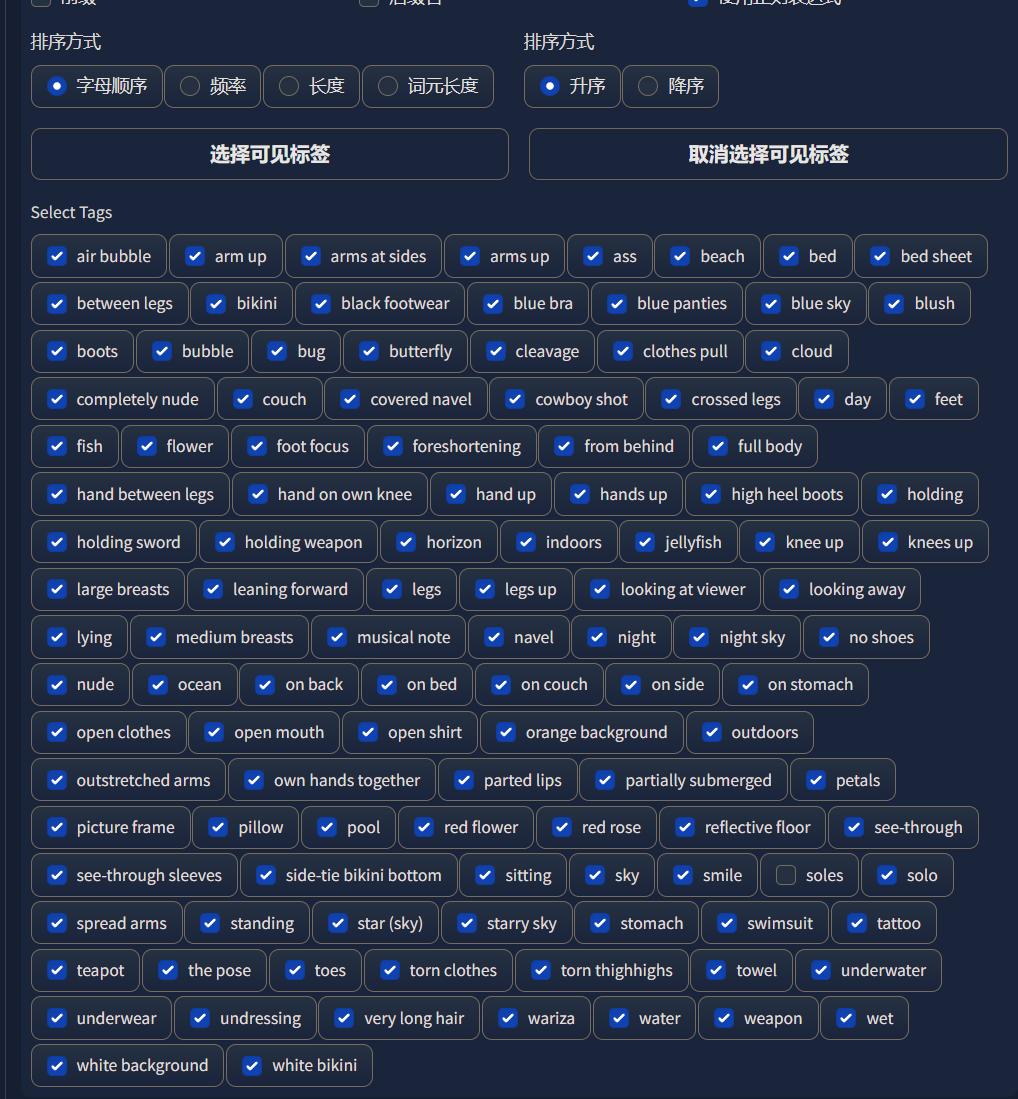
然后我们点击“移除选中标签”即可:
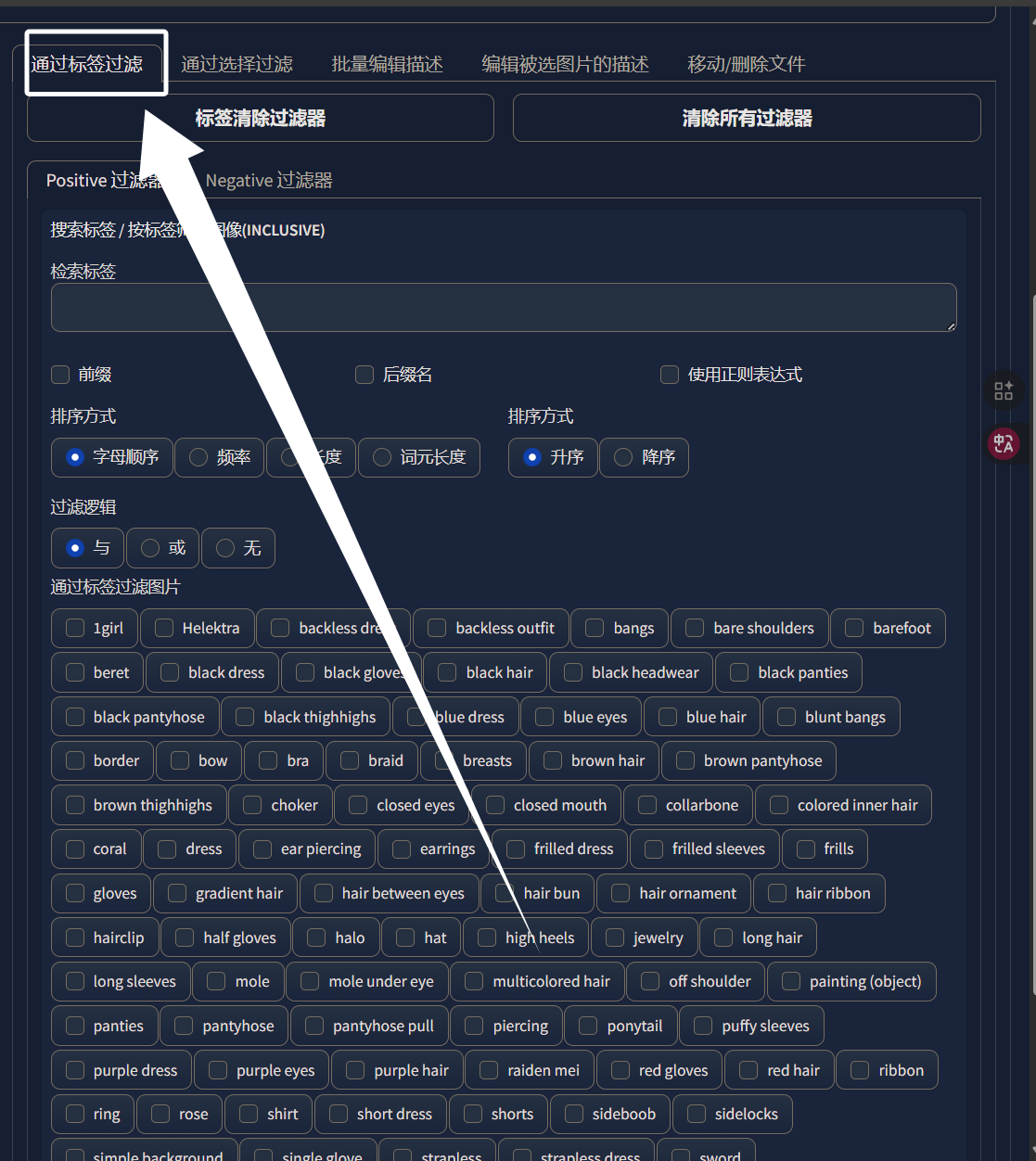
最后,回到“通用标签过滤”,就能发现我们的标签整体少了很多:
完成这些步骤以后,我们来到页面最上方,点击“保存所有更改”,旁边有一个备份选项,大家根据自己的情况勾选即可:
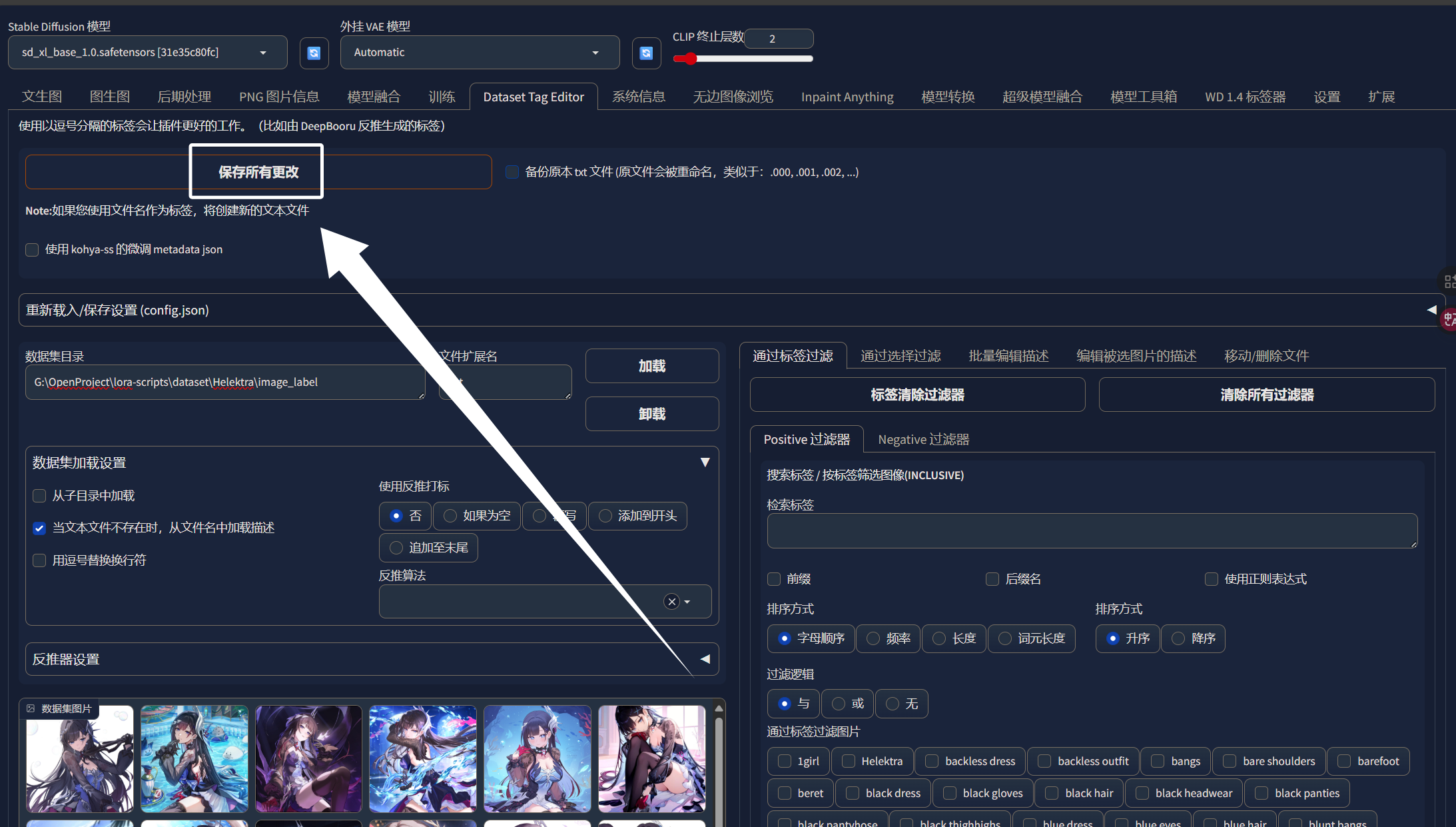
保存以后,我们随便打开一个标签文件,就可以发现,标签少了许多:
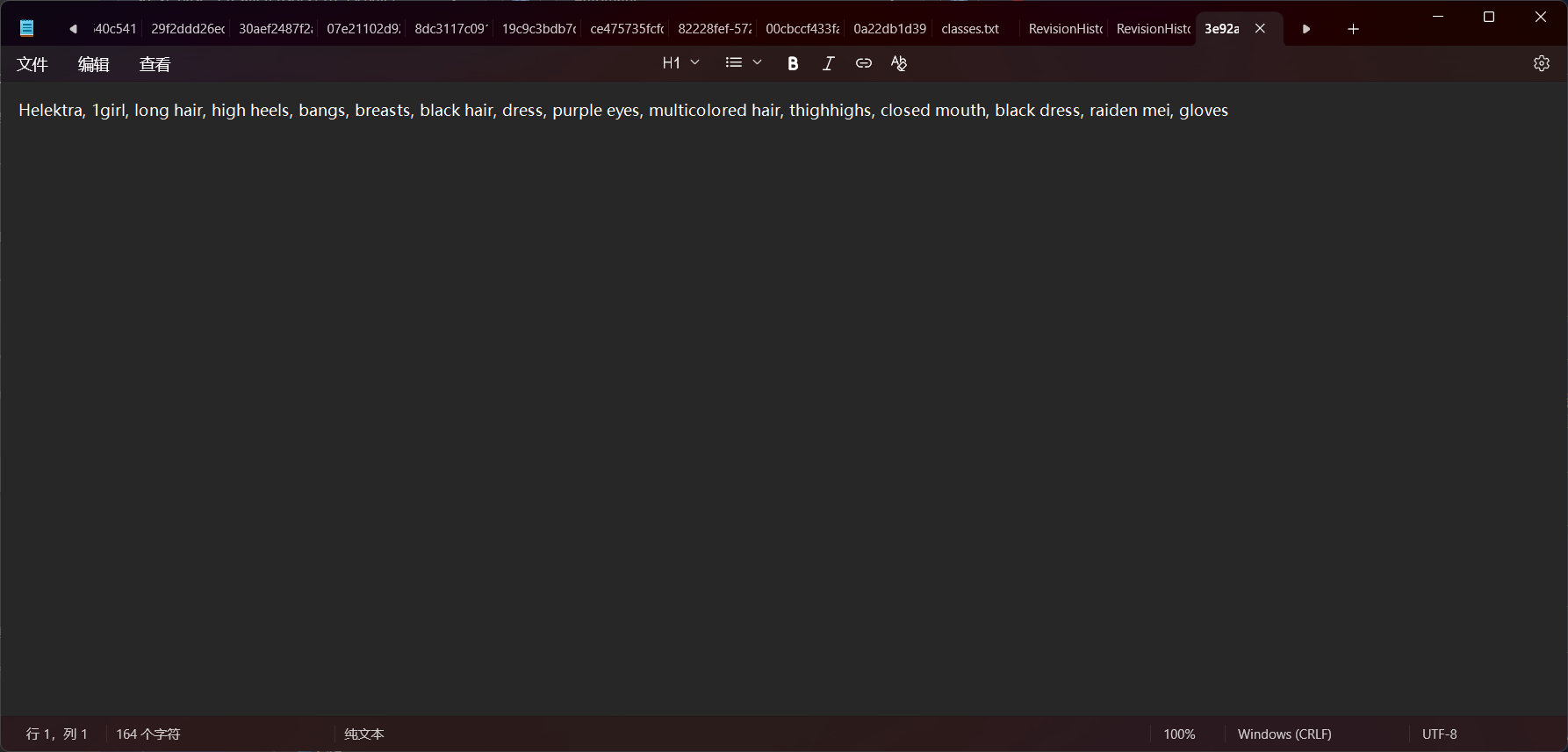
这样,我们的数据集优化就完成了。当然,你还可以进行更为细致的优化,自己一个一个筛选提示词,甚至可以将图像背景替换为空白的,这也有助于模型只学习人物特征。
五、训练参数调整及对训练模型的影响
训练参数同样是能够直接影响模型质量的。一套好的训练参数搭配优质的数据集训练出来的LORA才能符合我们的预期。现在我们就来学习如何调整训练器的参数从而产出相对优质的模型吧!
这里我们还是先启动训练器,训练器的环境安装以及基础使用都在上期教程中说了,这里就不多说了,我们直接启动训练器即可,启动以后如图所示:
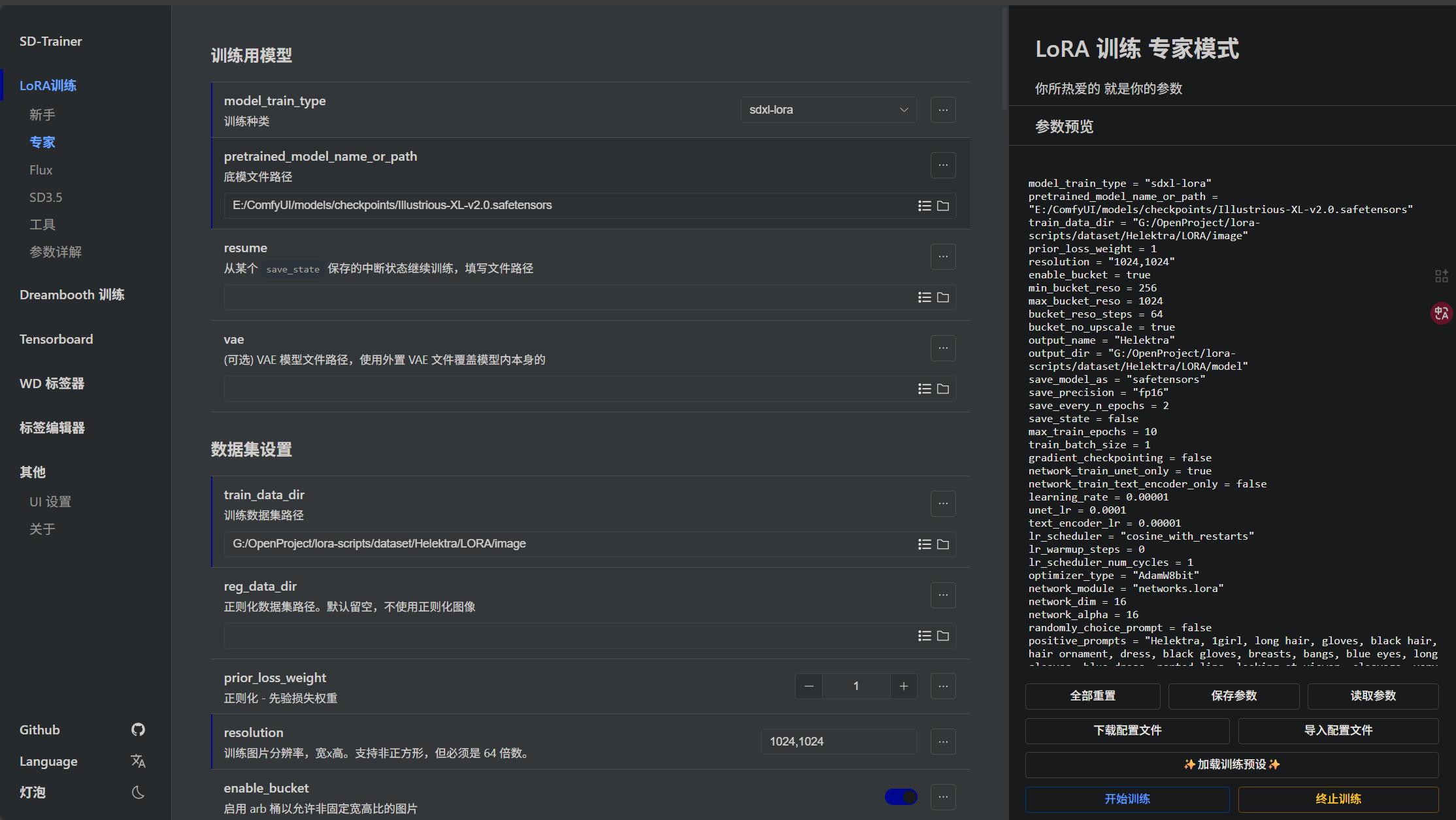
下面我将为大家介绍,哪些参数会对训练产生影响以及应该如何调整。
首先会影响训练质量的第一个参数就是我们训练时设置的训练图片的分辨率,即“resolution”:
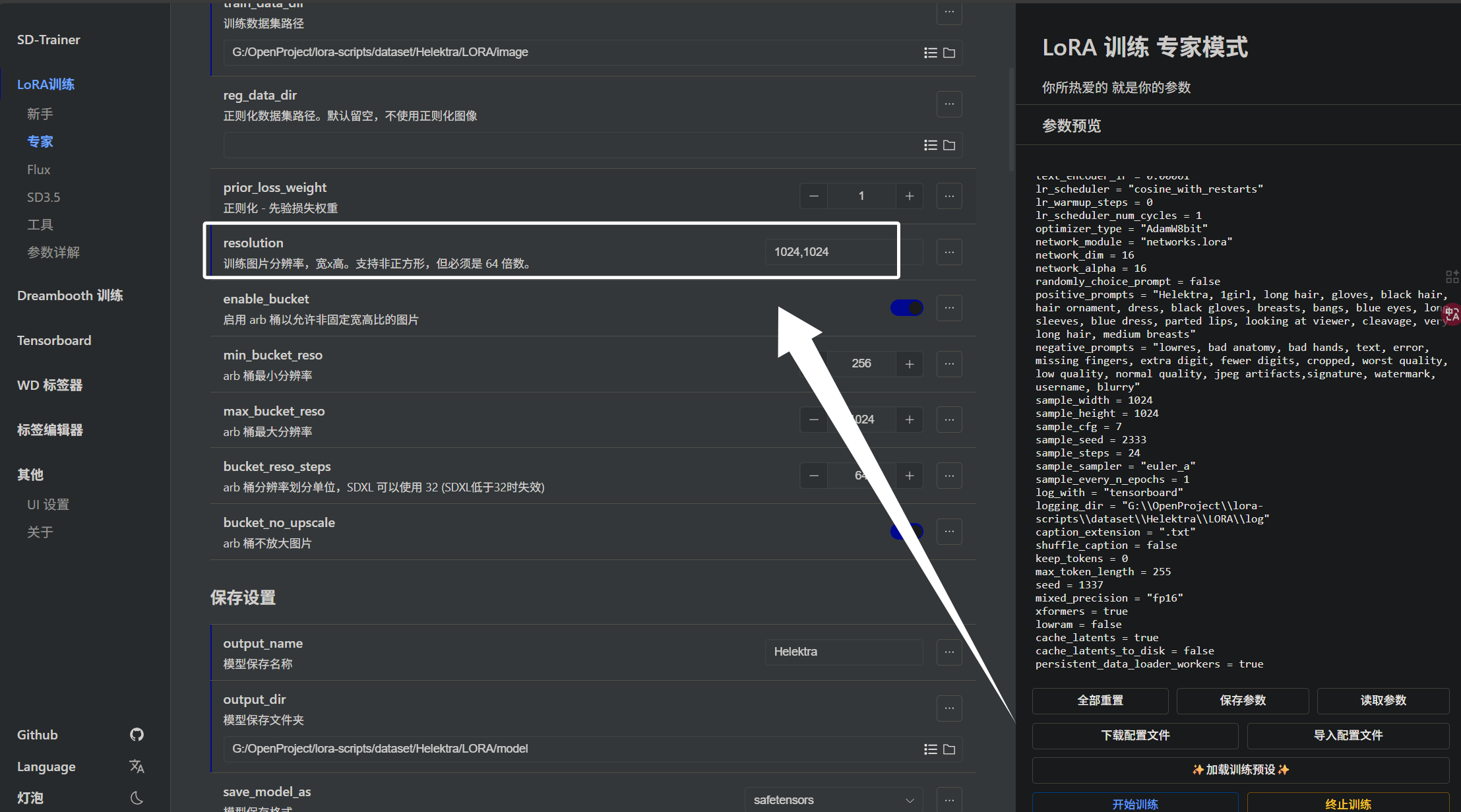
这个参数是根据我们图片的分辨率来确定的,就像我们前面把图片都裁剪为了1024x1024,这里就同样设置1024x1024,如果设置太小,模型学不到角色细节,如果设置太大,显存可能会炸,大家需要根据自己的数据集情况与硬件情况来权衡这个参数。当然,针对不同分辨率的图片也有解决办法,在下面会讲到。
下面是“enable_bucket”,才训练器中被叫做“arb桶”:
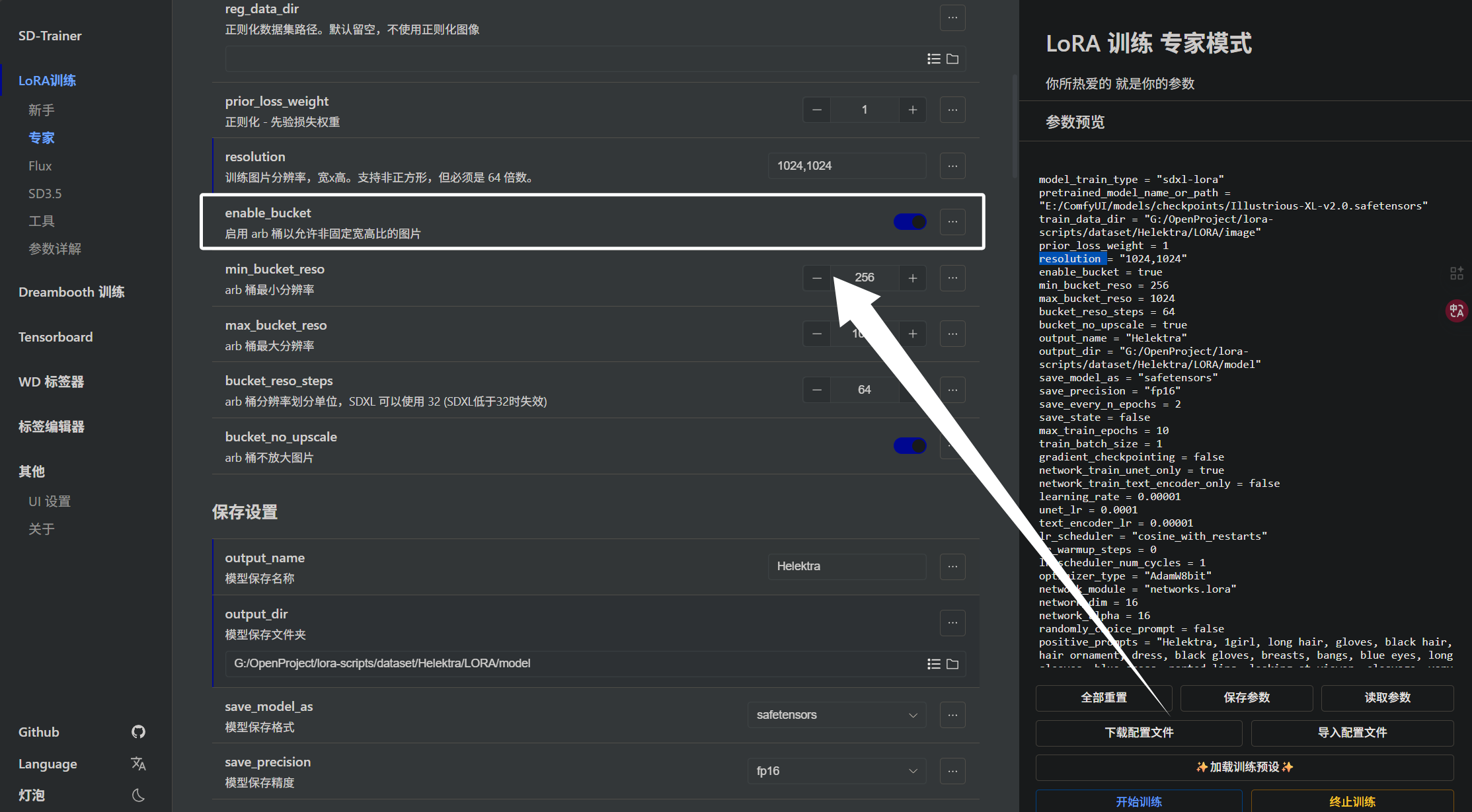
当我们将“enable_bucket”设置为开时,脚本会根据图像的长宽比,把图片归到不同的 bucket 分辨率里训练。
每个 “arb桶”的长边 ≤ max_bucket_reso,短边 ≥ min_bucket_reso也就是下面两个参数:
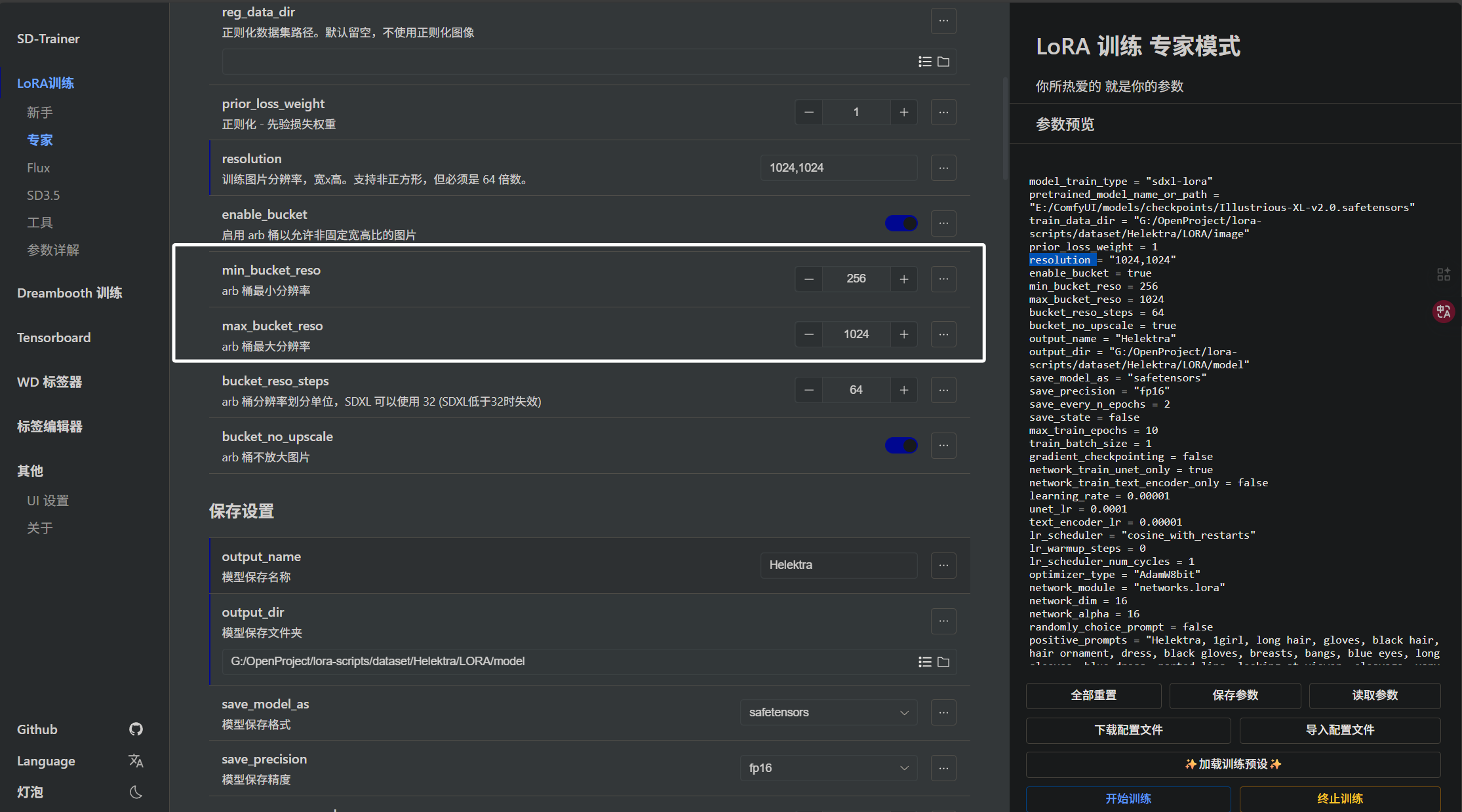
如果图片分辨率小于 min_bucket_reso,就会被丢到更低分辨率的 “arb桶” 里。
下面是“bucket_reso_steps”参数,它决定了我们“arb”桶的分辨率:
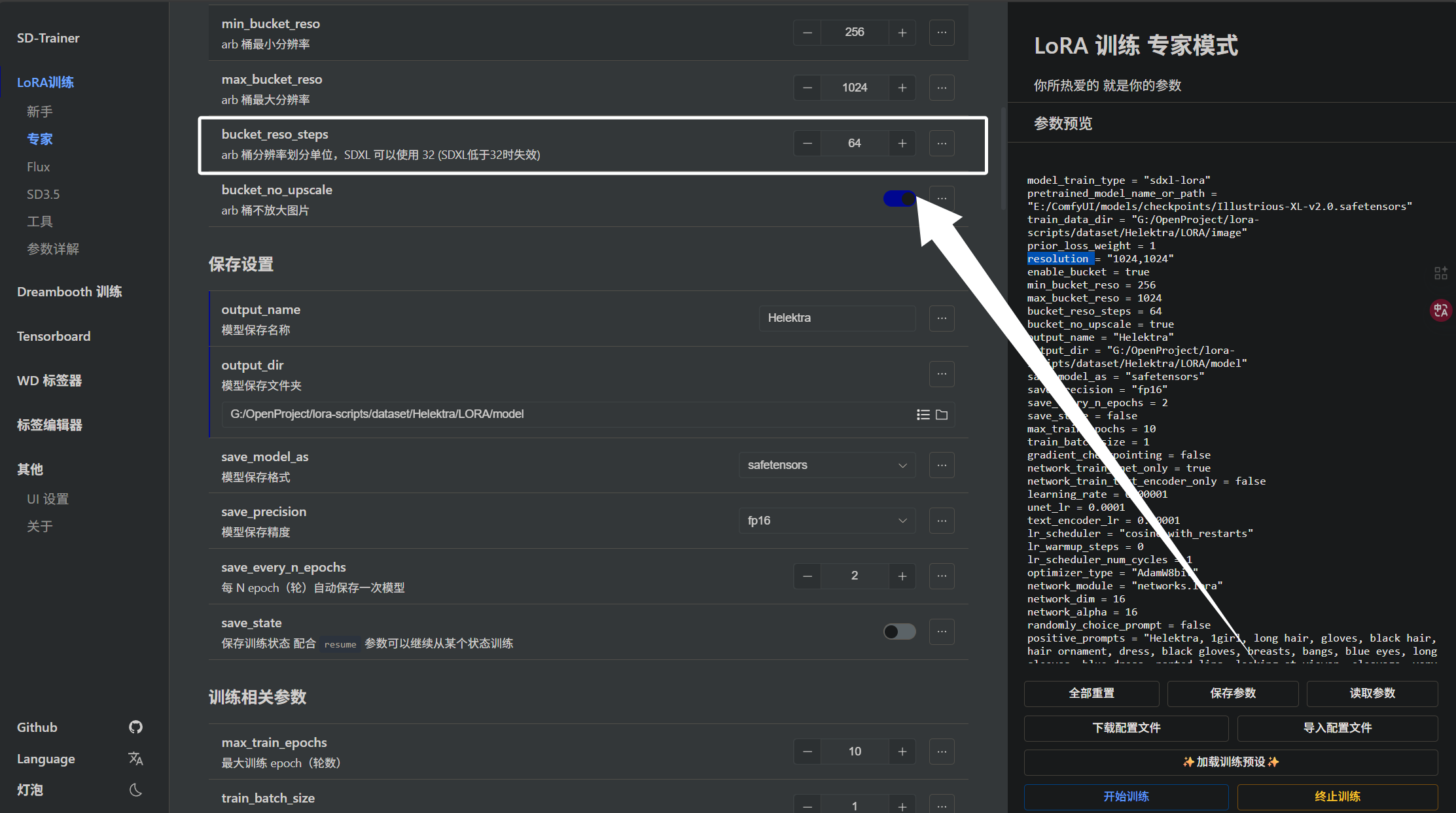
假如我们设置的“min_bucket_reso”为256,那么就会有“256,320,384,448,512,576,640,704,768,832,896,960,1024”这些桶。
下面是“bucket_no_upscale”参数,是是否禁止“arb桶”放大图片,我们将其开启就表示禁止:
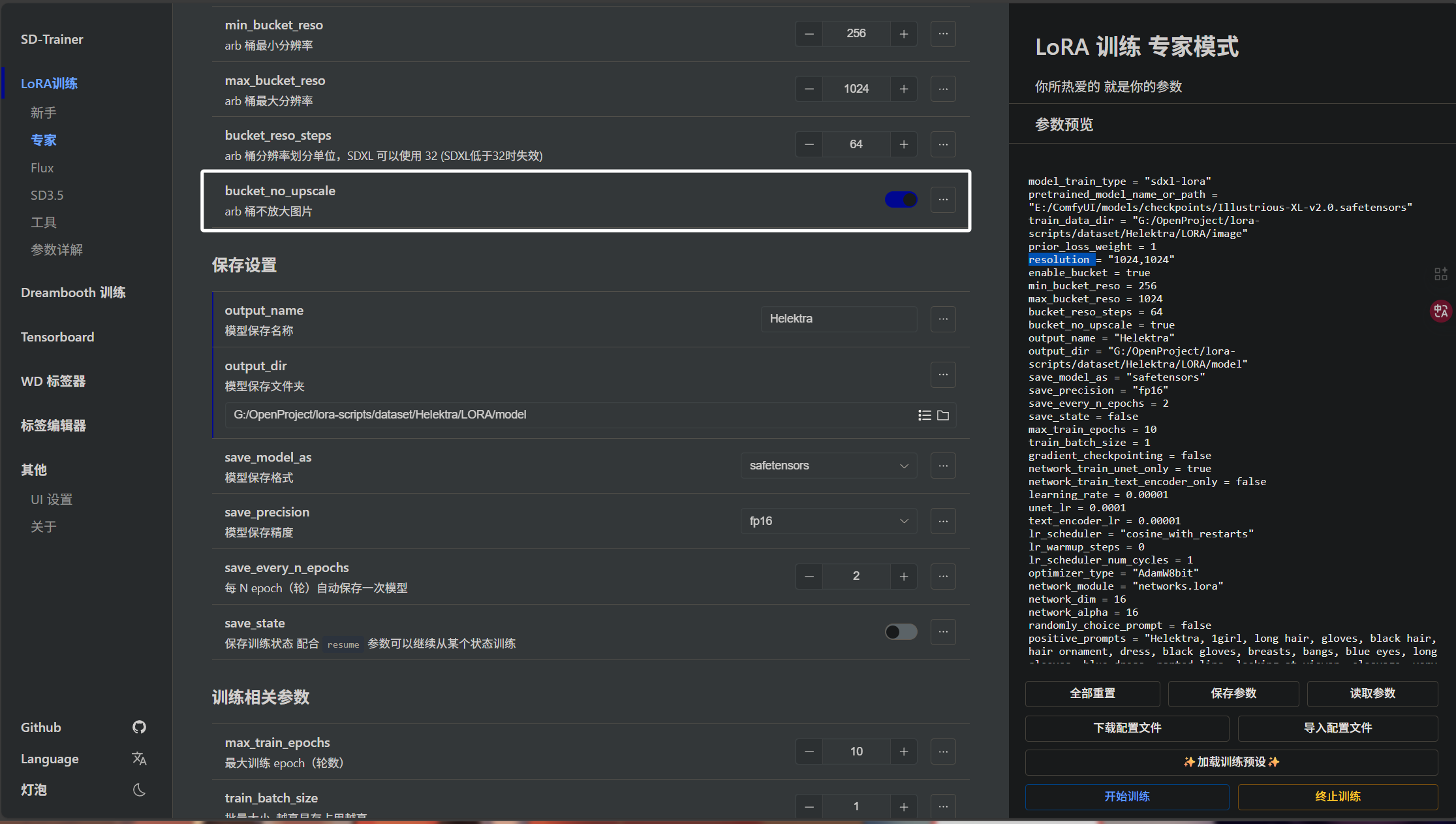
因为我们的图片都是统一的分辨率,所以“arb桶”对我们的数据集而言意义不大。
下面我们来介绍模型保存精度的参数,即模型训练完以后,以什么精度保存,即“save_precision”参数:
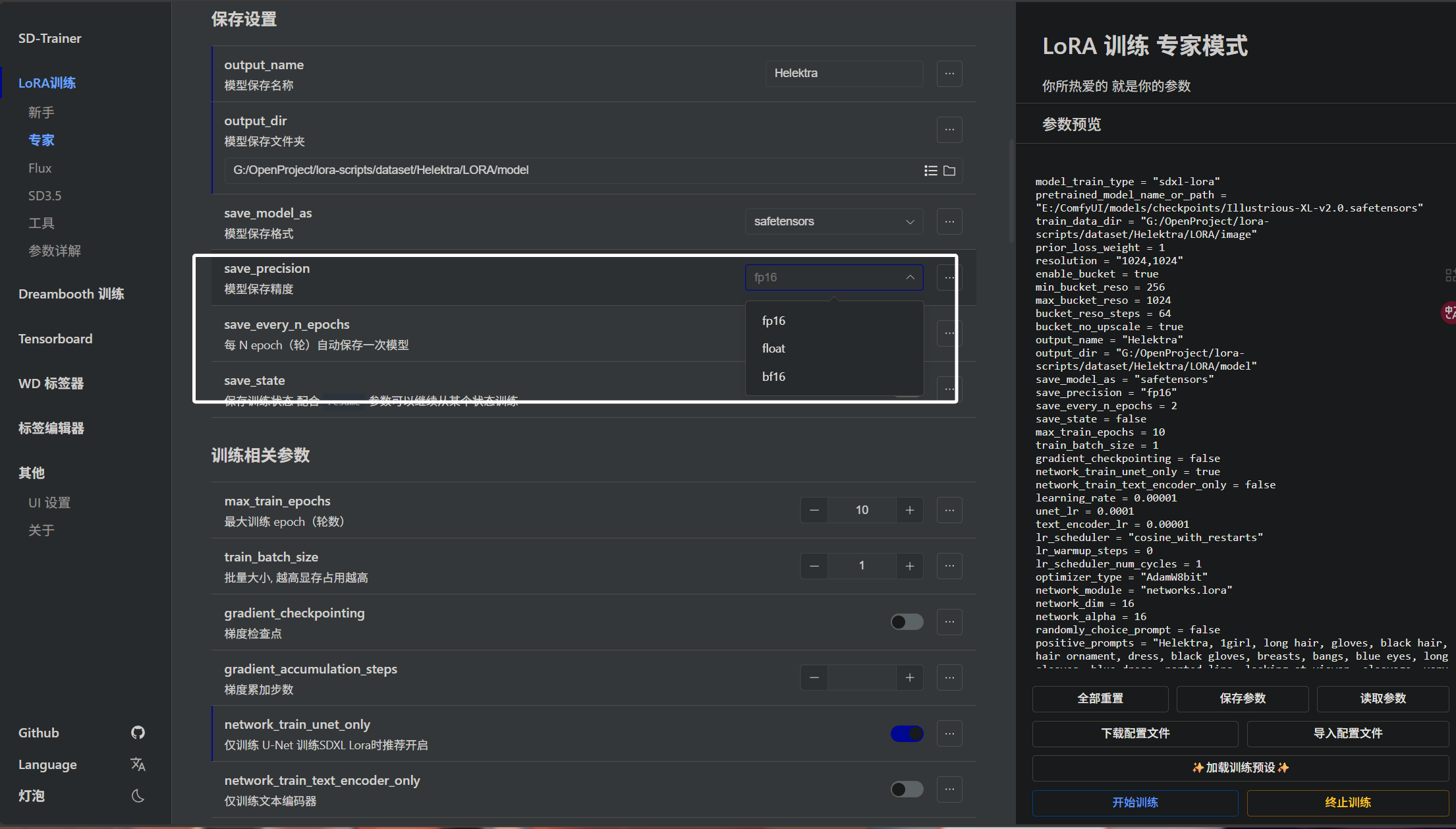
这里我们可以看到有3个选项,首先来讲讲float,完整的应该叫float32,即以32位精度保存模型。后面的fp16即float32的一半,以半精度保存的模型,精度更低但是推理速度快。然后是bf16全称“Brain Float 16”和fp16一样是float精度的一半,但是更稳定。在下方的训练精度中,我们也可以选择fp16或者bf16。
下面我们来看“save_every_n_epochs”参数,表示训练几个“epoch”保存一次模型:
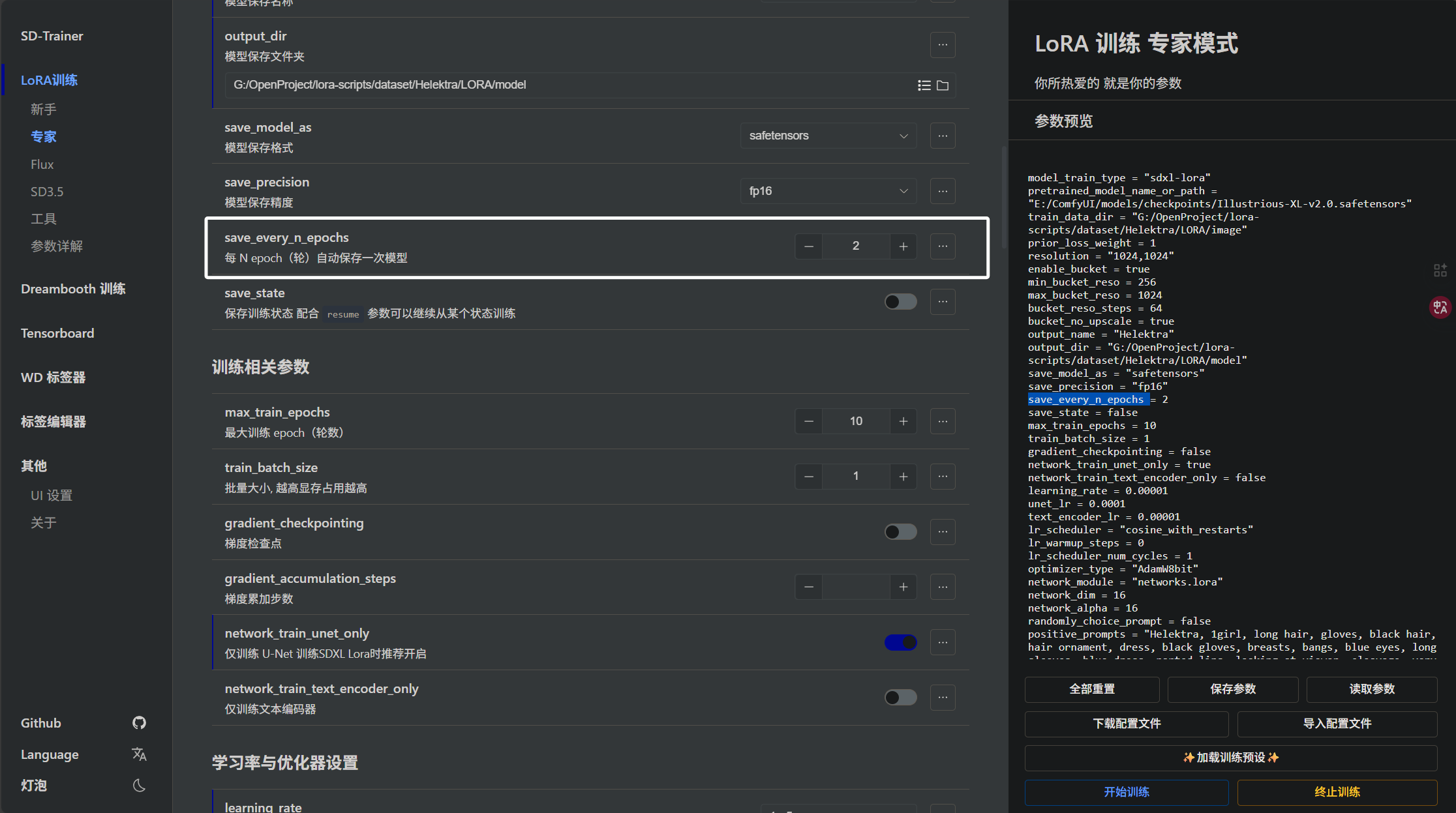
假如我们将“save_every_n_epochs”设置为2,总“epoch”设置为10,那么就会保存五个模型,每训练两轮就保存一次。
下面我们来看“max_train_epochs”参数,它关系到我们训练的步数:
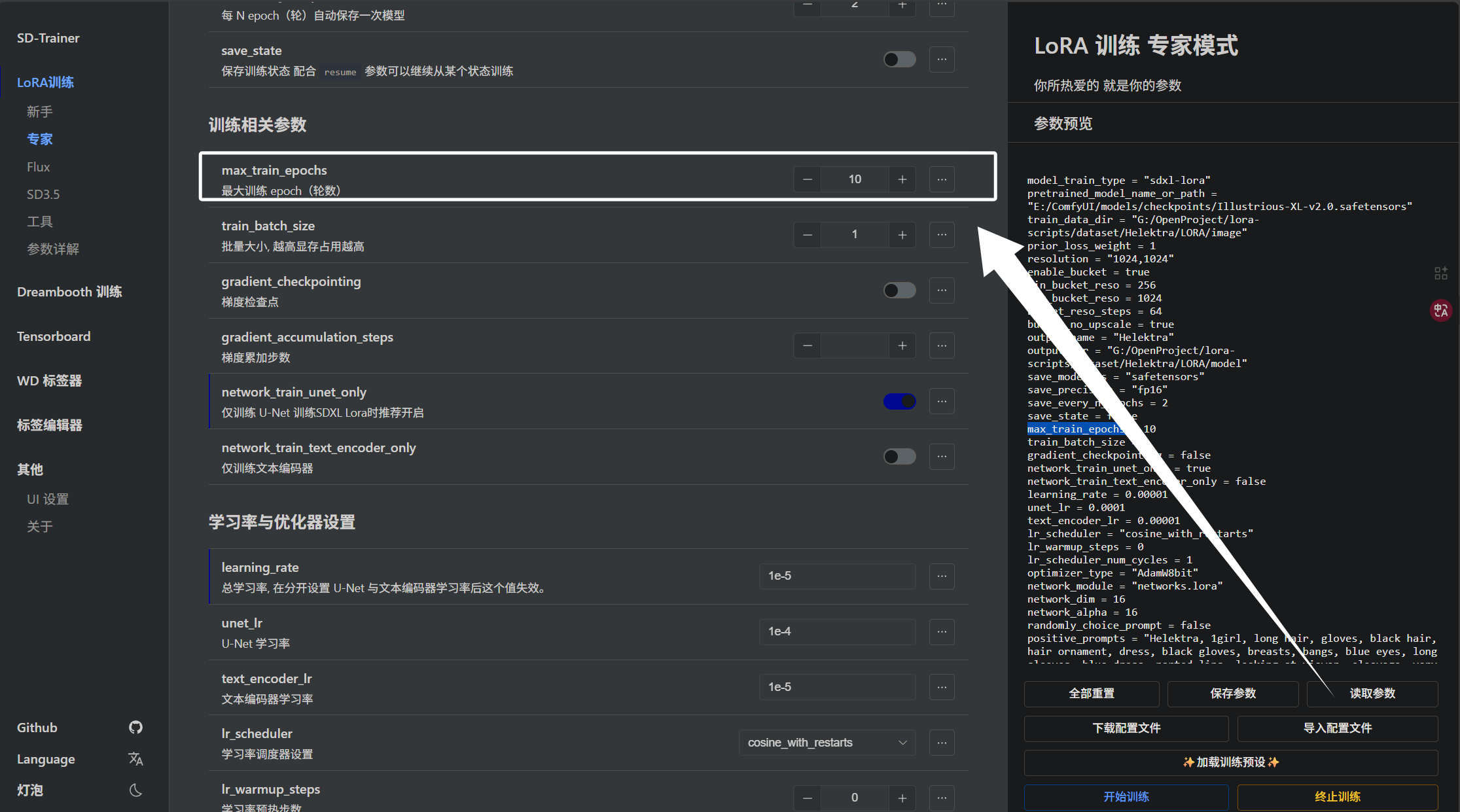
下面我来教大家如何计算步数,步数的计算对于训练而言是非常关键的,如果步数太多容易过拟合模型会去死记硬背,如果步数太少会欠拟合,模型没有学会特征。计算步数还需要结合下面的一个参数,即“train_batch_size”:
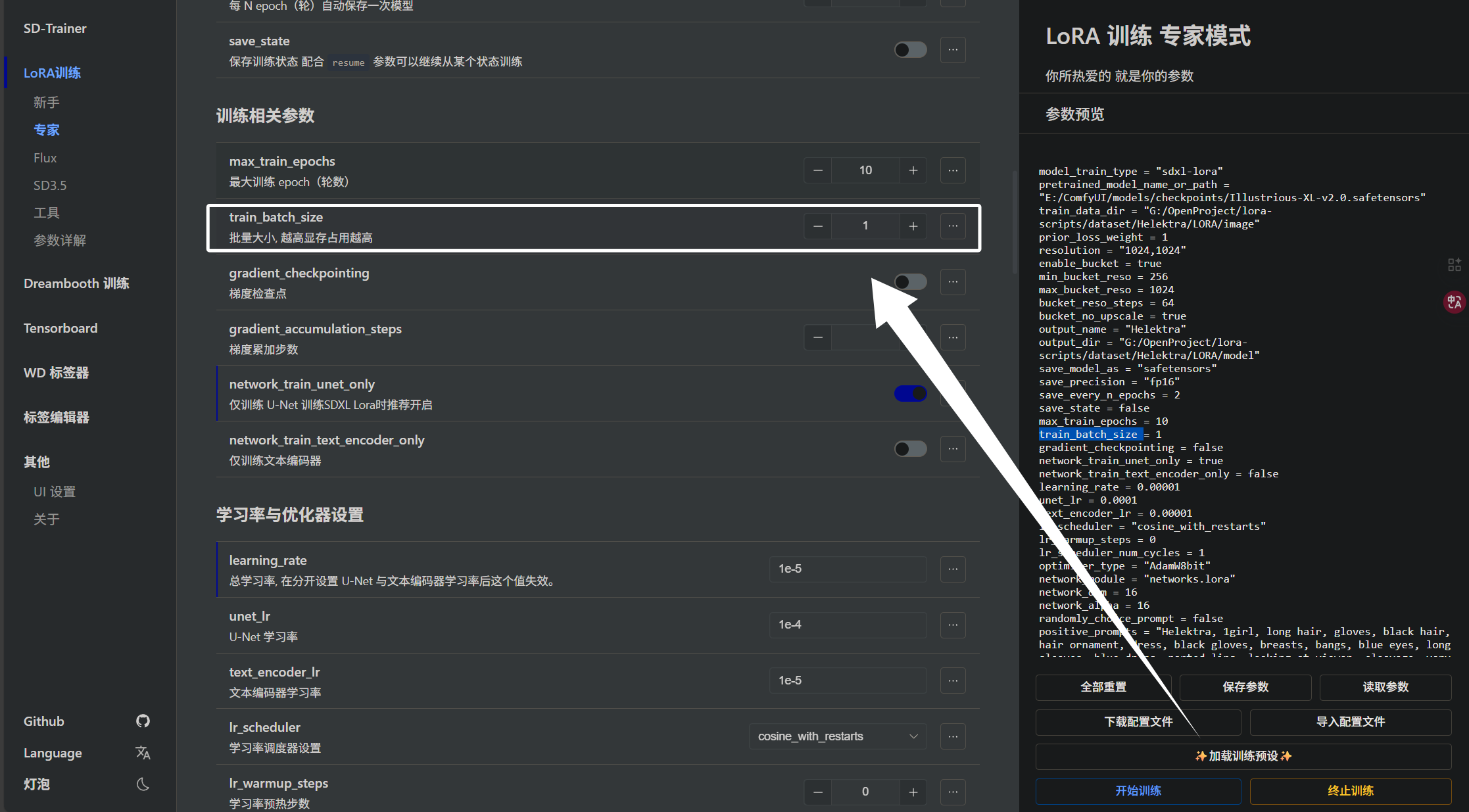
这个参数决定了每次喂给模型多少张图片,太小训练步数会很长,太大训练会炸显存或者训练慢,大家需要根据自己的硬件情况进行调整。
了解了上面这些参数以后,我们就可以来算训练的步长了,还记得我们在训练之前,需要新建一个“images”文件夹吗?然后在文件夹下新建一个“数字_角色名字”的文件夹,就类似下面这种:
那么这个数字是什么意思呢?其实这个数字是在一个“epoch”中将文件夹中的图片喂给模型的轮数,假如我这里是4,文件夹中的图片数量为32,就表示在一个“epoch”中,将这个文件夹中的32张图片喂给模型4次,这样就可以轻松算出,模型会看到4x32=128张图片,如果我们在耆那买呢设置了“train_batch_size”为1,模型每次看一张图片,那么这128张图片模型需要128步才能看完。如果我们设置了“train_batch_size”为2,那么这128张图片模型每次看两张图片,只需要64步就能看完。这里要知道,我们上面计算的是一个“epoch”下的。假如我们文件夹中图片为32张,文件夹开头数字为4,“train_batch_size”为1,“max_train_epochs”设置为10,那么模型要看多少步才能看完呢?其实很好算,因为我们已经将一个“epoch”的步数算出来了,针对我们列举的情况,模型一个“epoch”需要看128步才能看完,那么我们的总“epoch”为10,直接乘以10不就好了嘛。现在我们就知道了,当我们文件夹中图片为32张,文件夹开头数字为4,“train_batch_size”为1模型需要训练1280步,“train_batch_size”为2时模型需要训练640步。
上面就是训练步长的计算,我们通过调整合理的参数即可控制步长,一般的训练“train_batch_size”为1时建议步长控制在1200~1500步。
下面是“network_train_unet_only”参数与“network_train_text_encoder_only ”参数:
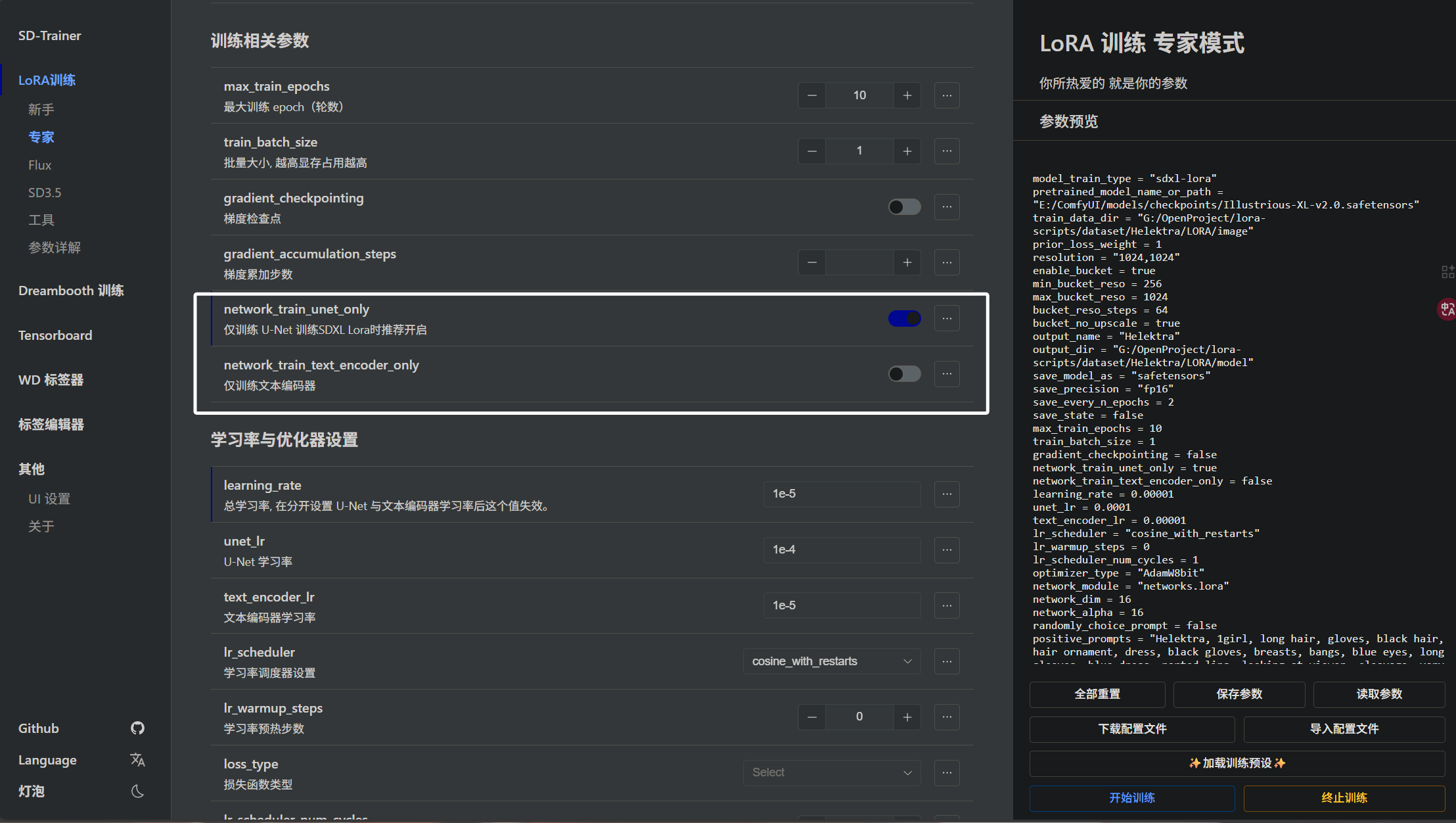
这里我们可以指定只训练“unet”或者“encoder”,只训练“unet”会提高训练效率,但是模型可能对触发词不是很敏感,模型会只关注角色特征。如果两者都训练,会加长训练时间,但是模型不仅会关注角色特征,还能通过关键词稳定触发。
下面我们来看看学习率调整的参数,即“learning_rate”,“unet_lr”,“text_encoder_lr”:
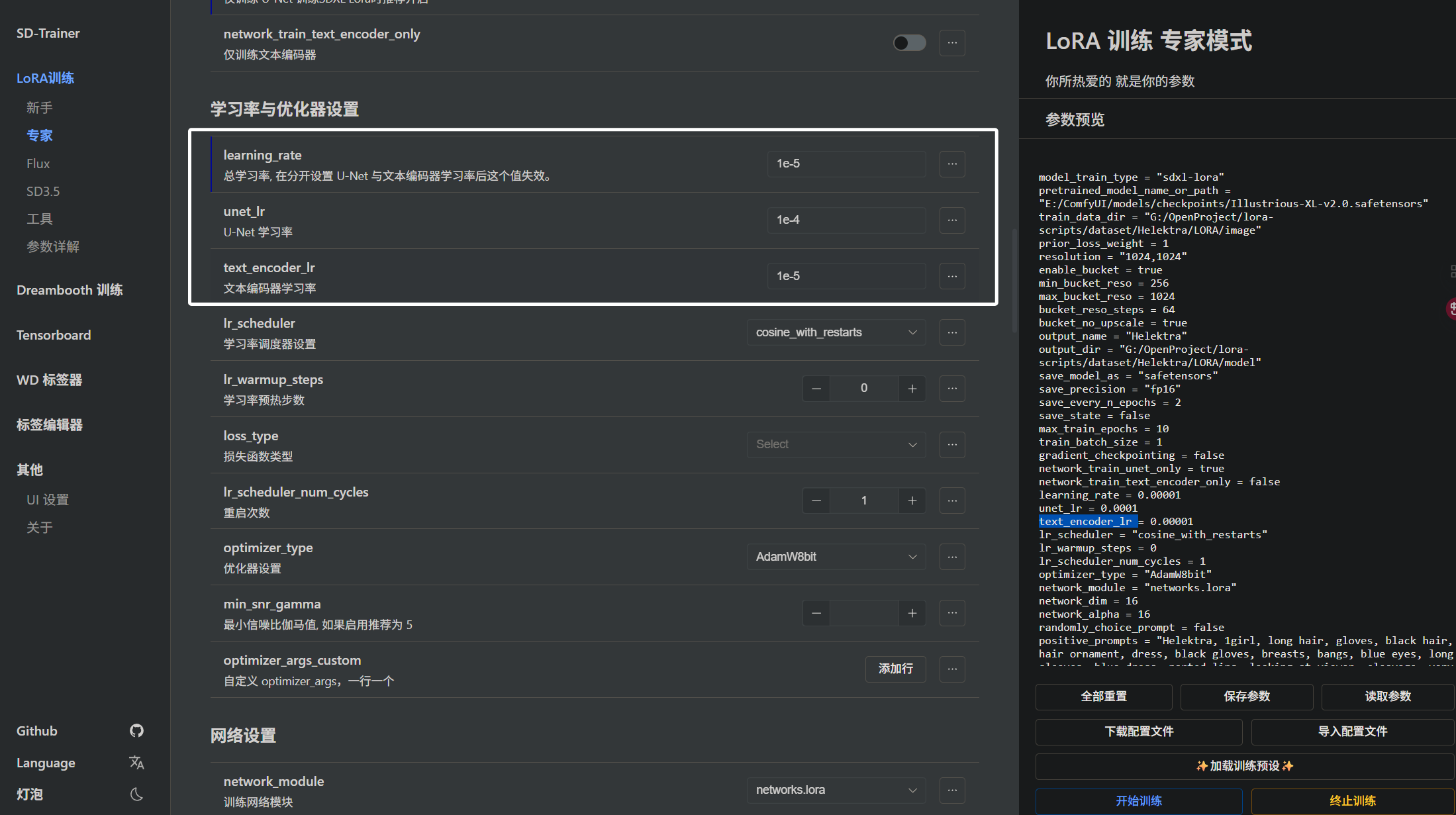 他们分别是“总学习率”,“unet学习率”,“text_encoder”学习率。在讲学习率之前,我们需要先理解这里的“1e-4”,“1e-5”是什么意思,这里很简单,需要一点中学数学知识即可。首先就是“1e-4”这就表示1x10^(-4),被我们读作“一乘十的负四次方”即0.0001,“1e-5”也很简单,表示1x10^(-5),被我们读作“一乘十的负五次方”即0.00001。下面来举个栗子,如果有一个“2e-6”,这是什么?很简单嘛,就是2x10^(-6),被我们读作“二乘十的负六次方”即0.000006,理解了学习率的参数以后我们现在来看看应该怎么调整学习率。首先就是总学习率,当我们不设置“unet学习率”,“text_encoder”学习率的值时,总学习率对这两个参数生效。当我们单独设置“unet学习率”,“text_encoder”学习率时,我们设置的值生效。“unet学习率”是学习的主力我们需要将学习率设置大一点,这里我这是的是1e-4,通常我们都设置在“1e-4 ~ 1e-5”之间。“text_encoder学习率”一般设置在“1e-5 ~ 1e-6”之间,尽可能小于“unet学习率”,当我们不训练“encoder”时,这个参数自然不生效。
他们分别是“总学习率”,“unet学习率”,“text_encoder”学习率。在讲学习率之前,我们需要先理解这里的“1e-4”,“1e-5”是什么意思,这里很简单,需要一点中学数学知识即可。首先就是“1e-4”这就表示1x10^(-4),被我们读作“一乘十的负四次方”即0.0001,“1e-5”也很简单,表示1x10^(-5),被我们读作“一乘十的负五次方”即0.00001。下面来举个栗子,如果有一个“2e-6”,这是什么?很简单嘛,就是2x10^(-6),被我们读作“二乘十的负六次方”即0.000006,理解了学习率的参数以后我们现在来看看应该怎么调整学习率。首先就是总学习率,当我们不设置“unet学习率”,“text_encoder”学习率的值时,总学习率对这两个参数生效。当我们单独设置“unet学习率”,“text_encoder”学习率时,我们设置的值生效。“unet学习率”是学习的主力我们需要将学习率设置大一点,这里我这是的是1e-4,通常我们都设置在“1e-4 ~ 1e-5”之间。“text_encoder学习率”一般设置在“1e-5 ~ 1e-6”之间,尽可能小于“unet学习率”,当我们不训练“encoder”时,这个参数自然不生效。
下面我们来看“学习调度器”也就是“lr_scheduler”参数:
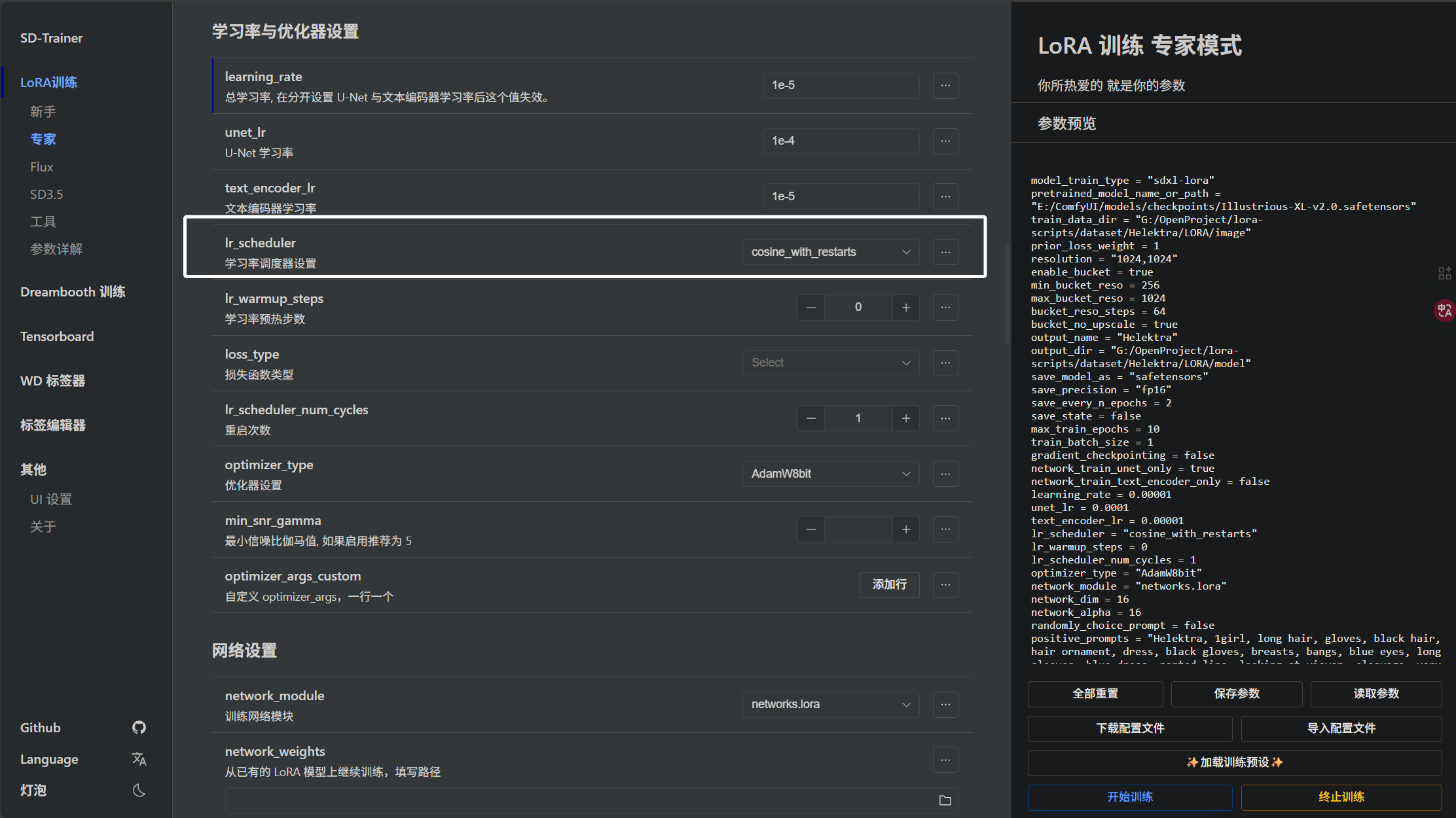
我们一般将其设置为"cosine_with_restarts",这也常被我们叫做余弦重启或者叫做余弦退火,
当一个周期结束时,学习率“重启”回到较高的值(通常是 ηmax\eta_{max}ηmax),然后再用余弦下降。使用余弦退火我们可以观察到,学习率曲线是一个余弦曲线:
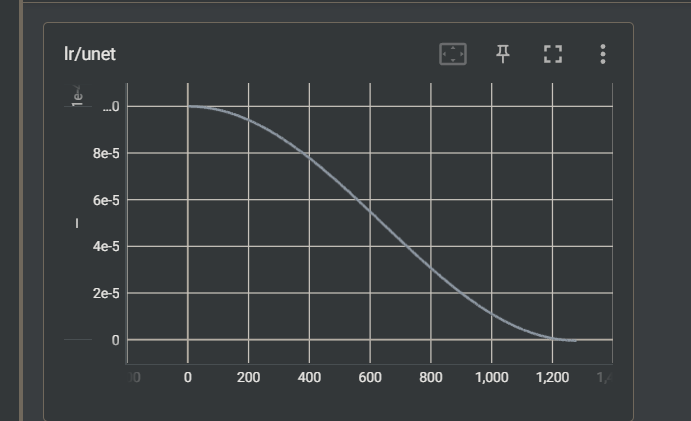
我们还可以通过设置“lr_scheduler_num_cycles”参数来设置余弦退火的重启次数:
关于更详细的“lr_scheduler”参数可以看下面的文章:
深度学习中的学习率调度器:深度学习中的学习率调度器(lr_scheduler)详解:以 Cosine 余弦衰减为例(中英双语)_cosinelrscheduler-CSDN博客
下面是优化器相关配置,即“optimizer_type”参数:
我们一般将其设置为“AdamW8bit”更节省显存,效果在大部分情况下与“AdamW”相近。
下面我们来看看网络维度参数,即“network_dim”:
它表示LORA 的秩,数值越大,模型能够学会的东西越多,同样模型也越大。16可能是一个比较适中的参数,大家可以根据自己的情况调整。
然后是“network_alpha”参数,即LORA的缩放系数,通常我们设置为与“network_dim”一样:
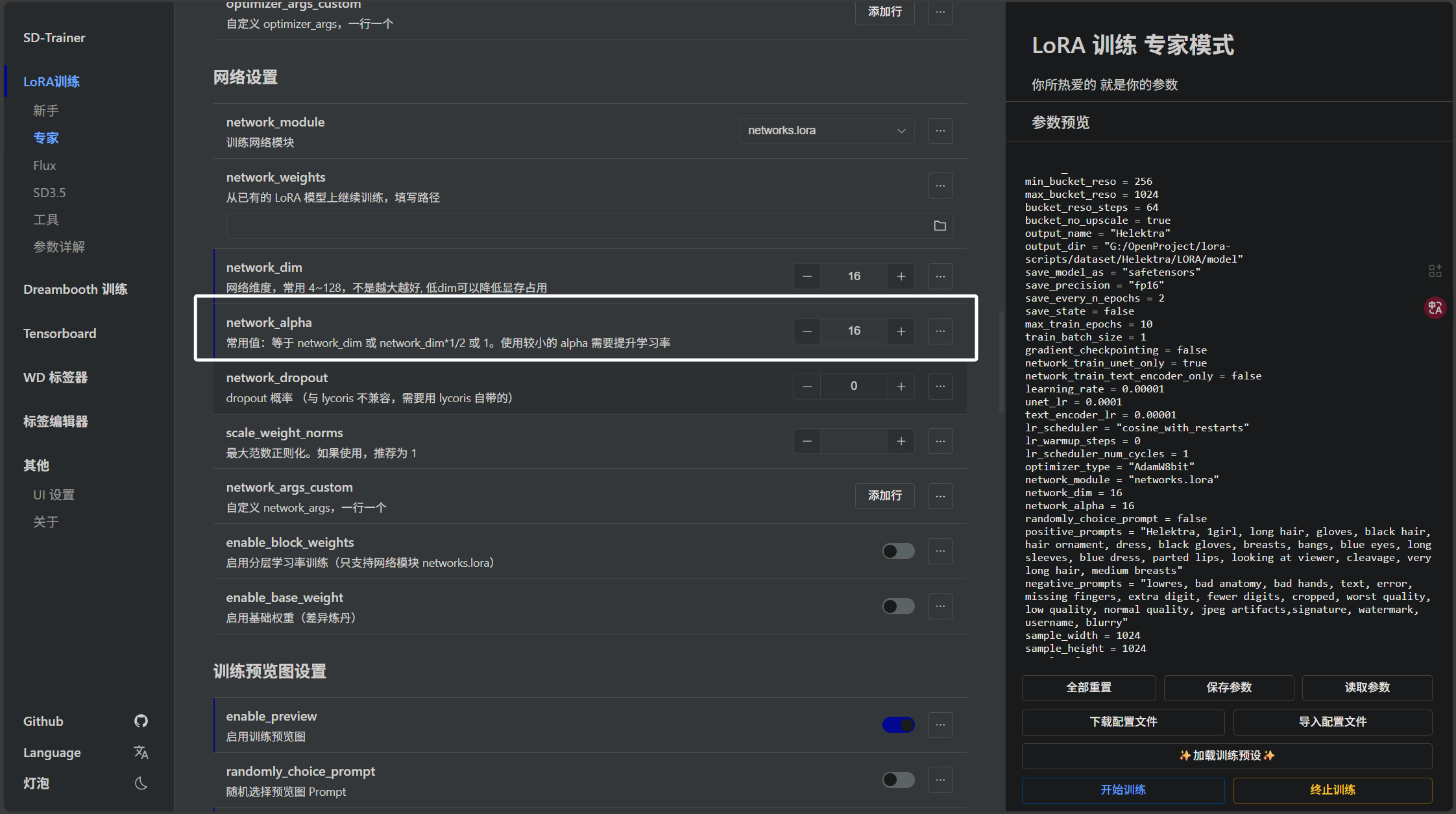
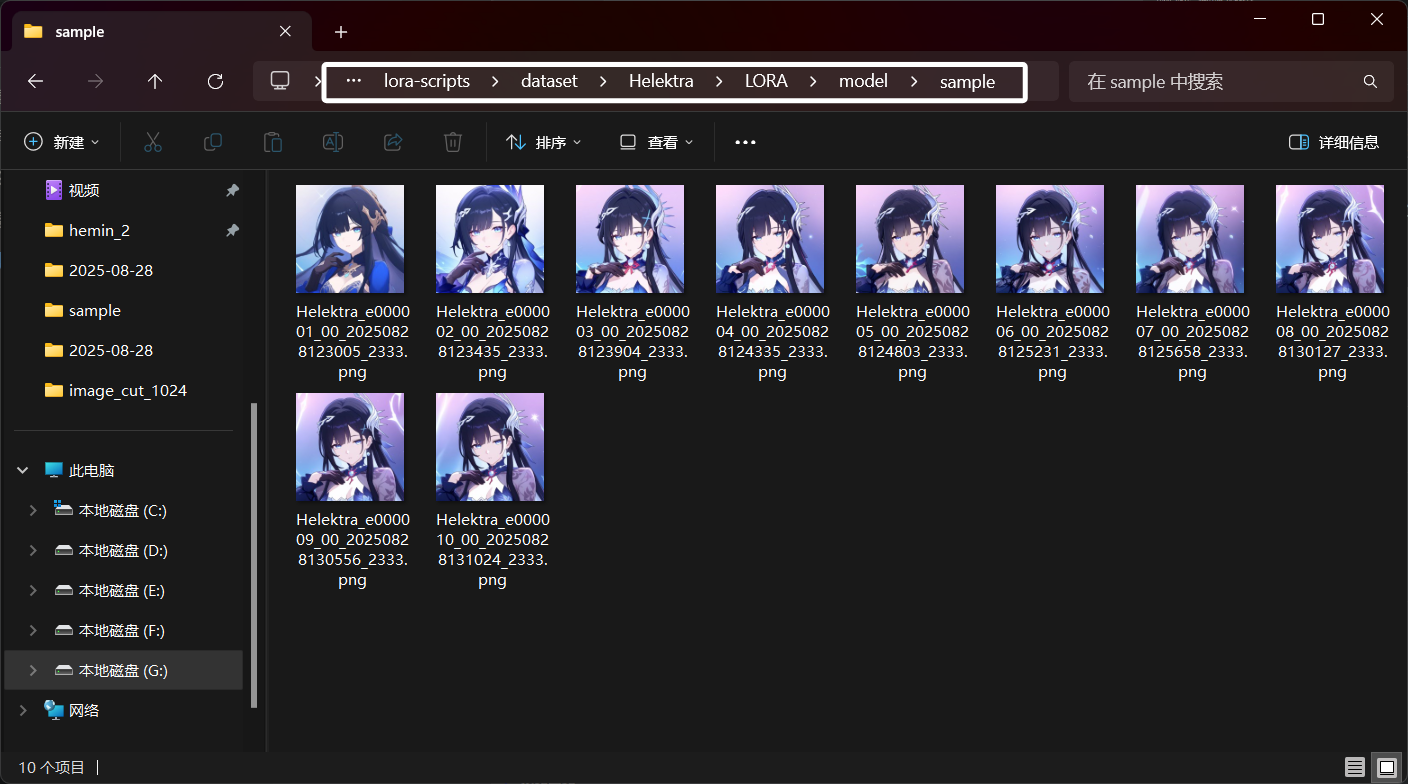
下面是关于预览图设置,我们可与填入相关参数,训练器会根据我们的参数就目前训练的LORA生成预览图,并且存放在模型文件夹下的“sample”目录中:
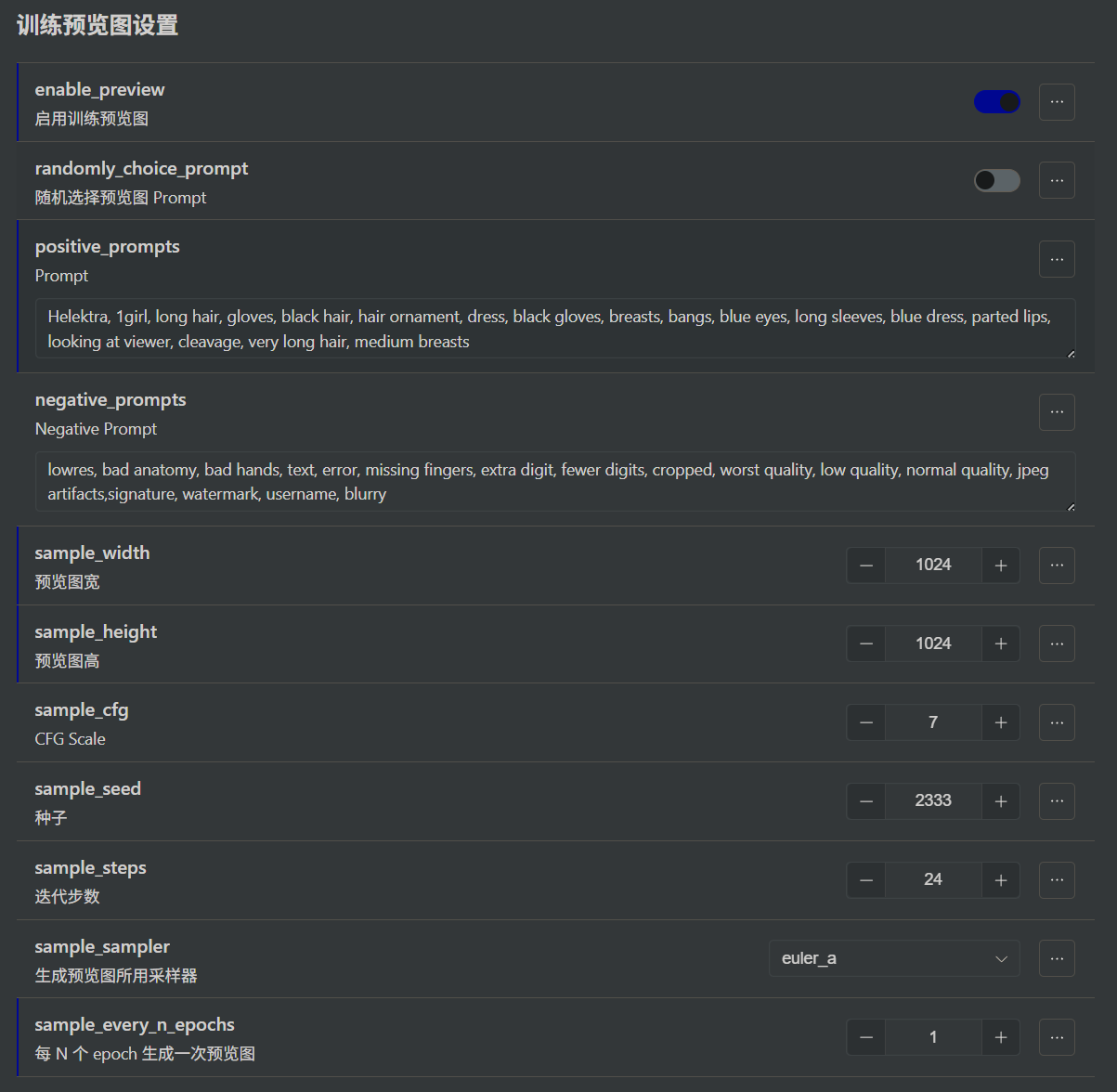
下面我们来看看“shuffle_caption”参数:
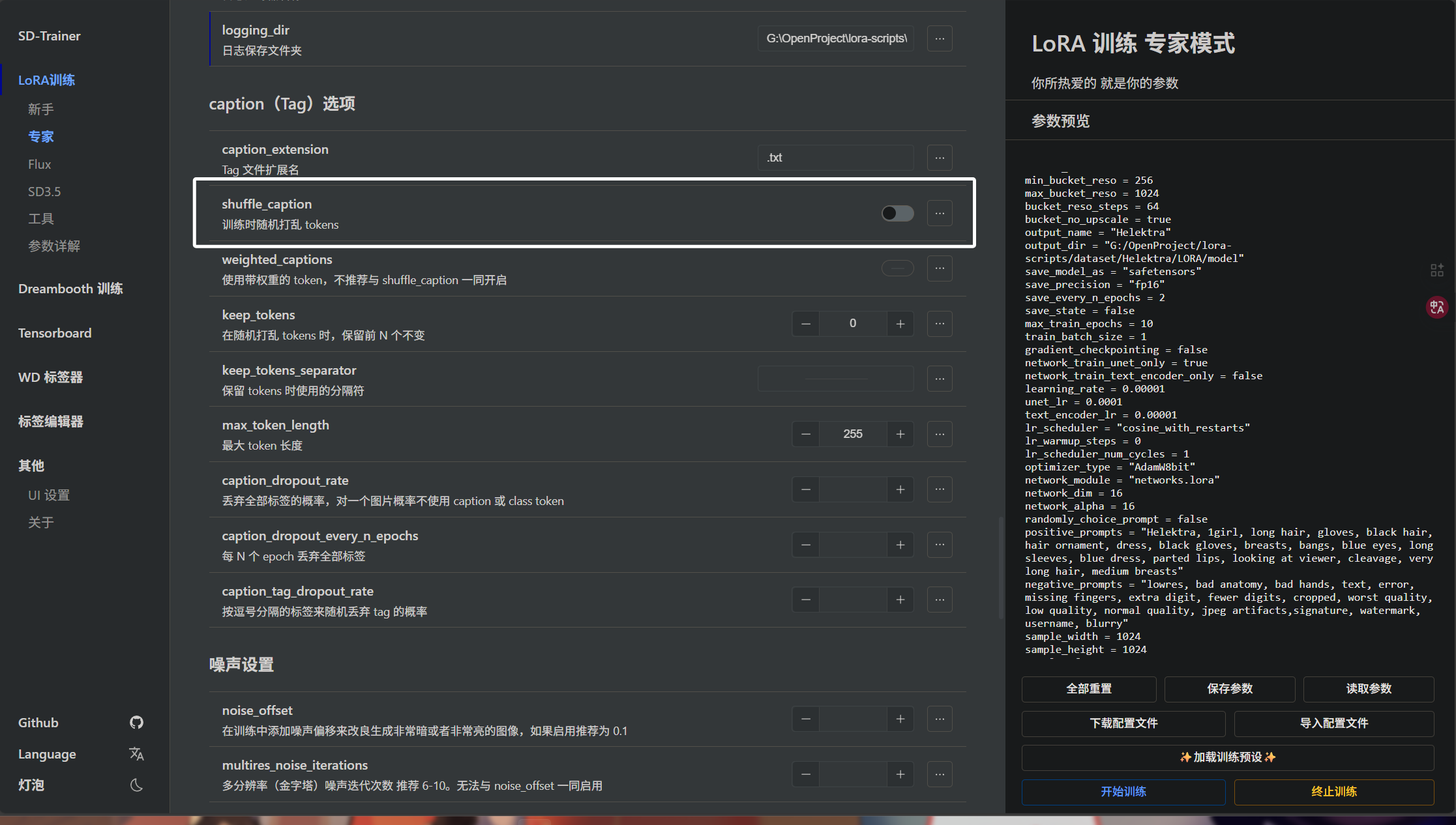
开启后,训练时会随机排列我们的标签,这样模型不会过度依赖标签的顺序。训练时建议开启。
上面的这些训练参数,就是我们在SDXL LORA训练中常用的一些参数,我们可以通过反复尝试这些参数,训练出效果符合预期的LORA。
大家应该能够注意到,我在文章中使用到了大量的“应该”,“可能”等字样,因为模型训练参数没有标准答案,我们需要自己不断地尝试,摸索出一套符合预期地参数。
六、测试训练的
当我们训练好一个LORA以后,我们应该怎样测试呢?当然,最简单的办法就是使用我们训练LORA推理一张图片,我们直接看效果,那我们怎么知道我们的模型在哪个“epoch”或者在哪个权重下效果最好呢?这里我们就要用到WebUI中的一个脚本了——“X/Y/Z plot”,它可以帮我们批量推理图片,让我们观察我们的LORA在不同的步数,不同的权重下的表现。
还记得我们一开始设置的“save_every_n_epochs”参数吗?它决定了每多少个epoch保存一次模型,我这里保存了五个模型:
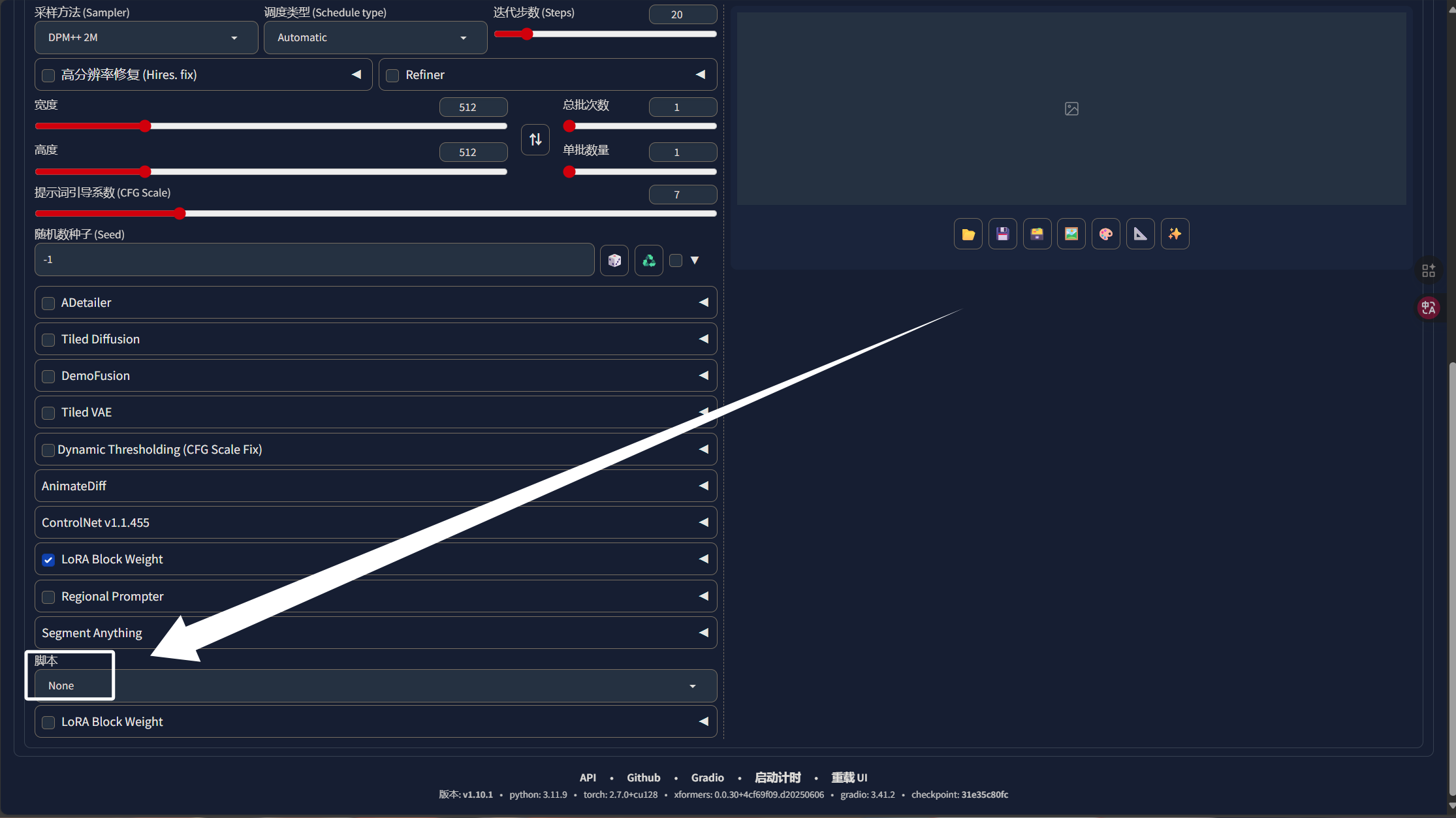
下面就来教大家如何使用“X/Y/Z plot”来批量推理图片,启动WebUI后,我们往下拉到最底下,找到“脚本”:
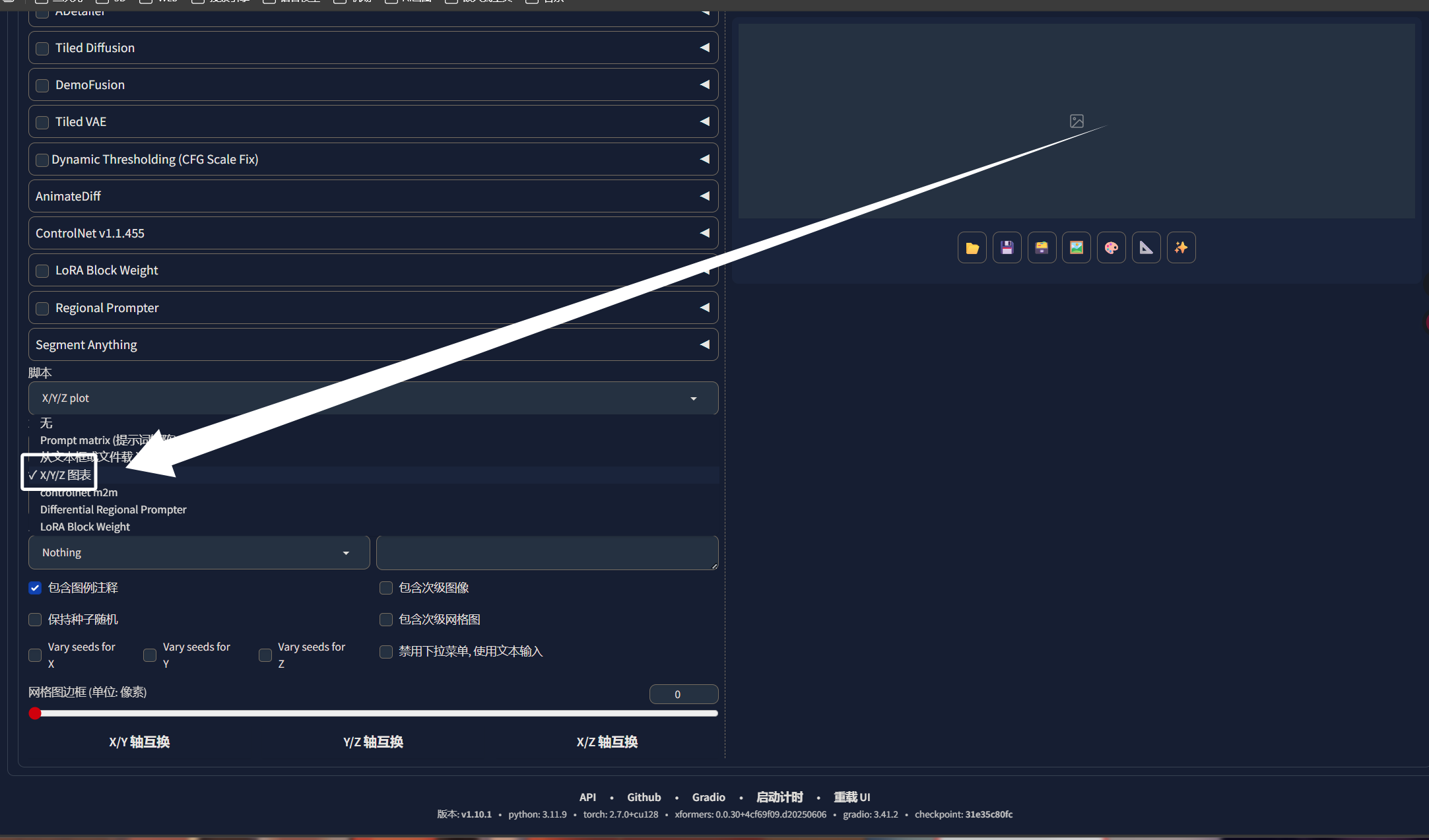
然后选择“XYZ图片”:
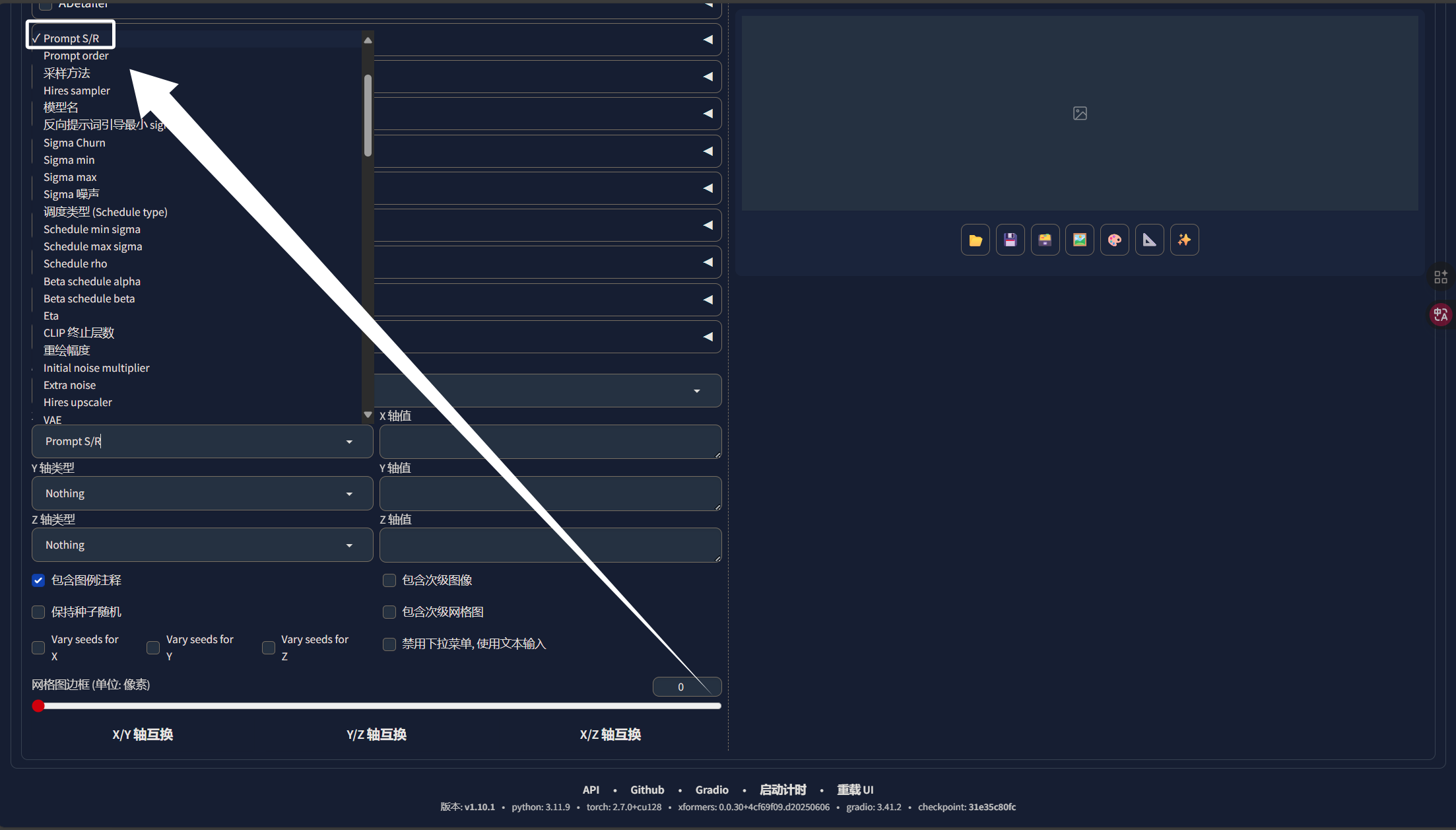
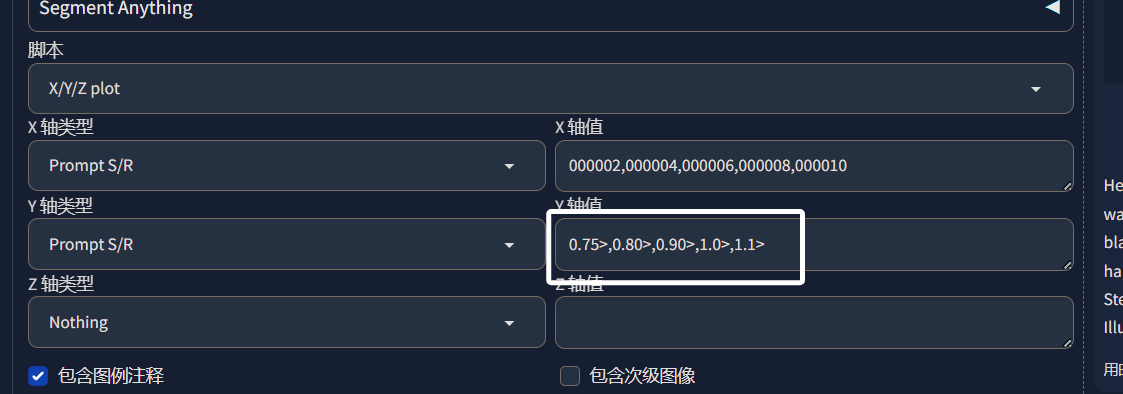
这里我们X轴选择“Prompt S/R”,即提示词替换:
我们再回到上面的提示词选项中,我们将推理图片要用的提示词填进来,然后把LORA也填进来:
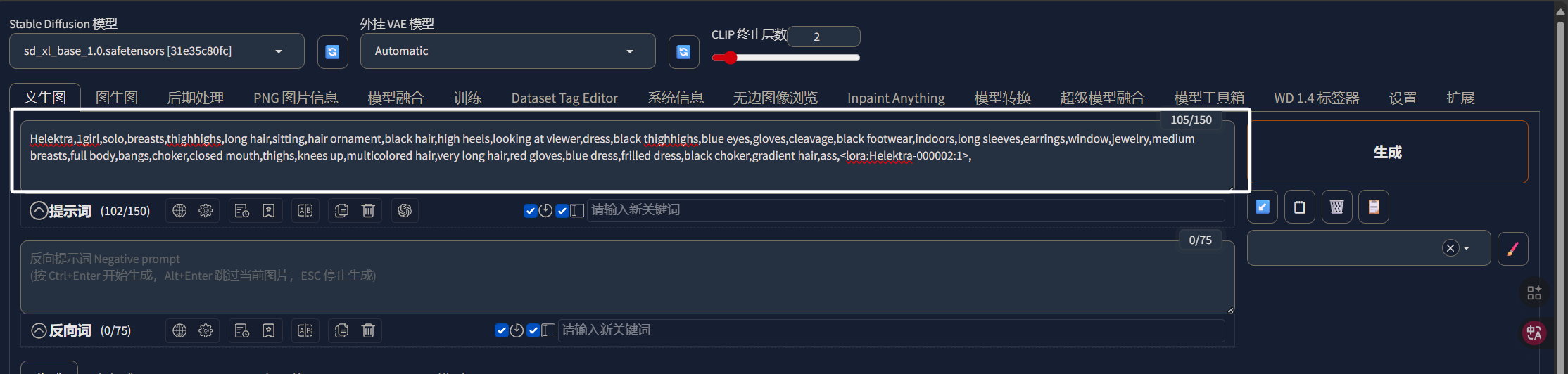
这里的LORA我们选择最小的那一个,也就是保存出来的第一个,我们从第一个开始,看哪个LORA的效果最好。我们再次来到XYZ图表中,在X轴值处填入我们要替换的内容:
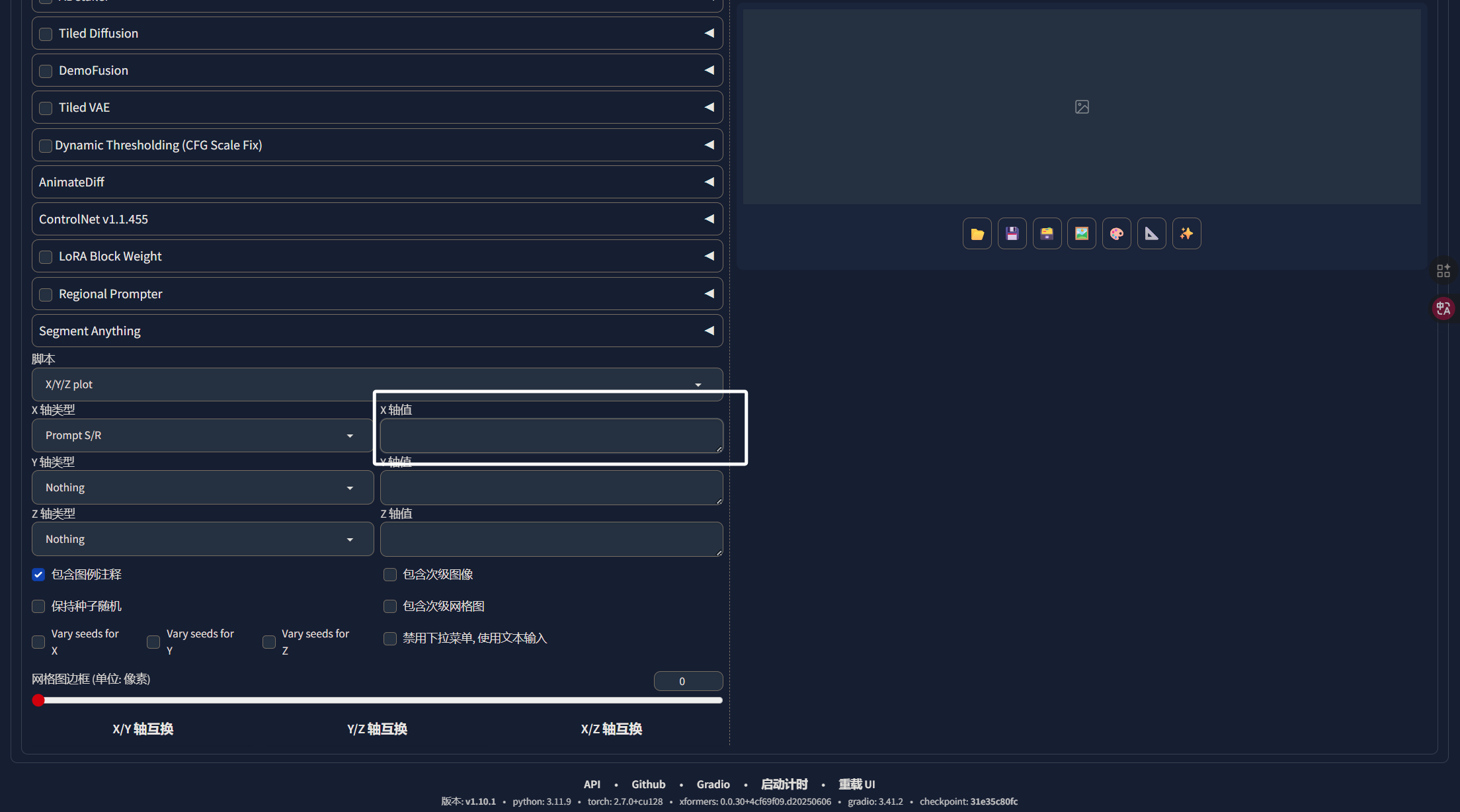
这里模型与模型之间,就只是模型名字后面的数字不同,我们每次替换模型名字的数字即可:
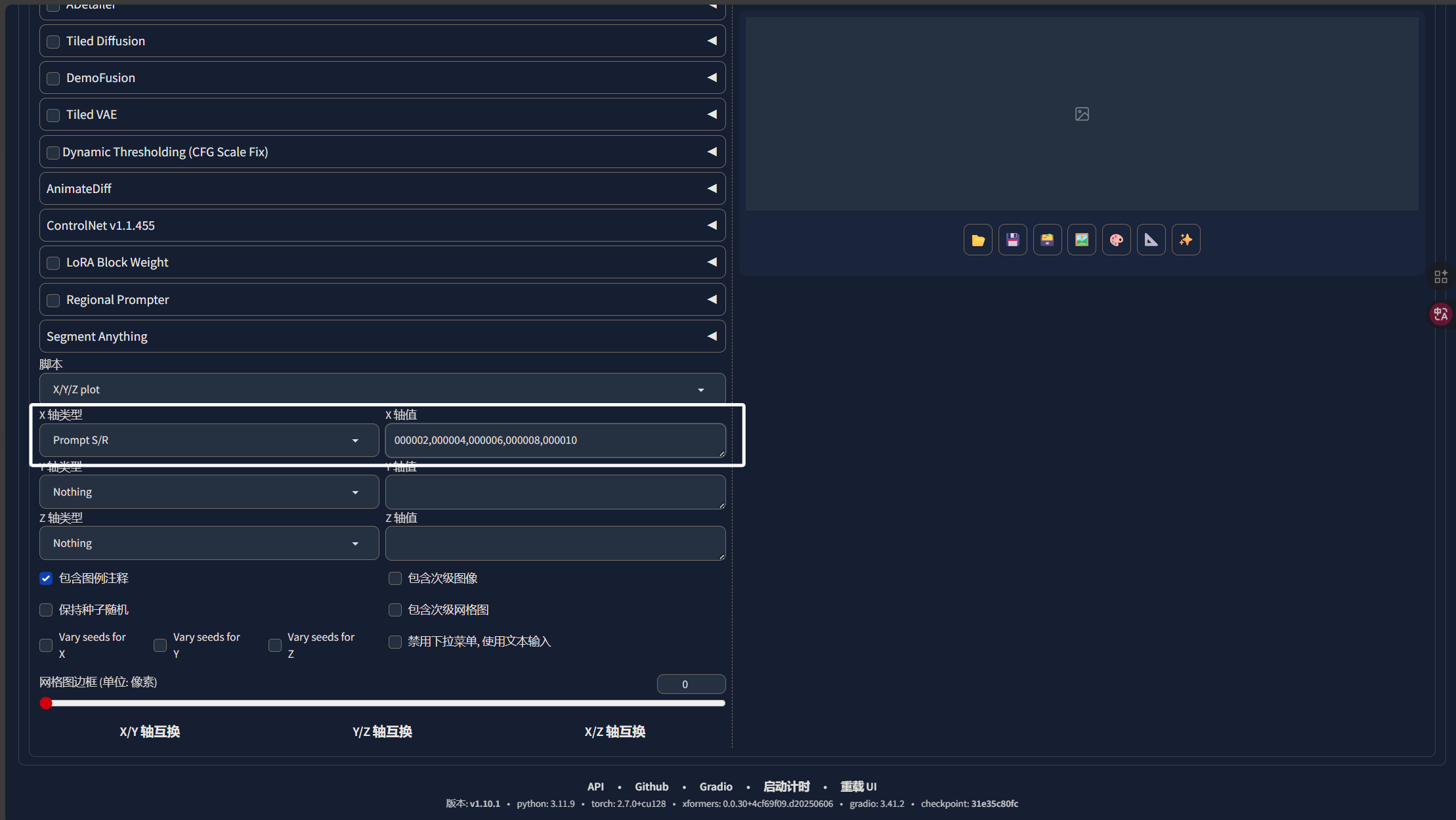
注意,第一个数字一定是我们提示词中LORA的,完成以后,我们点击生成即可,生成完成以后,我们就可以看到不同步数的模型在同一套参数下的生图效果,我们就可以选出相对较好的模型:
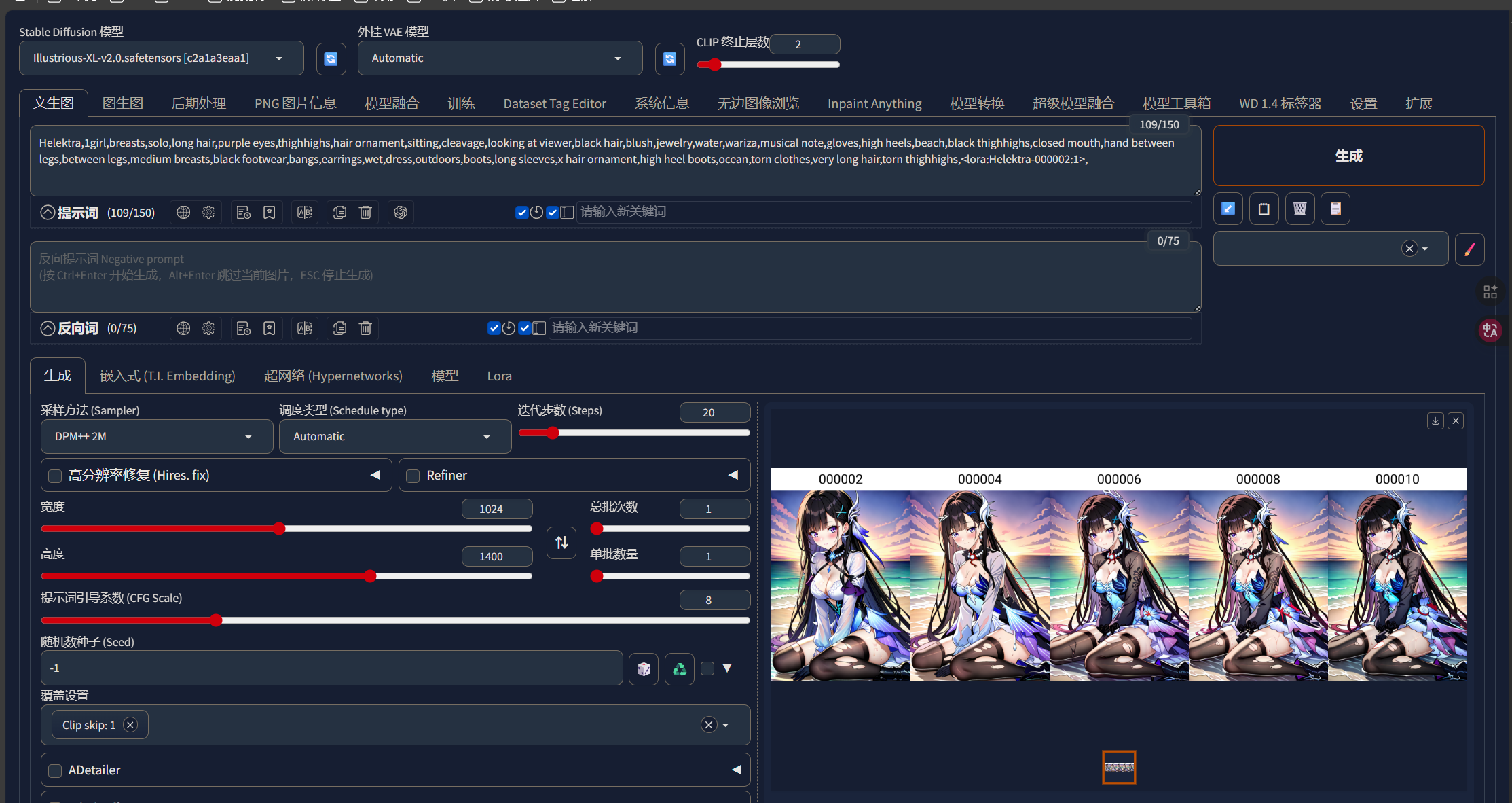
我们还可以在XYZ图表中加入Y参数来调整模型的权重,从而知道模型在哪个权重下表现最好:
我们再次推理:
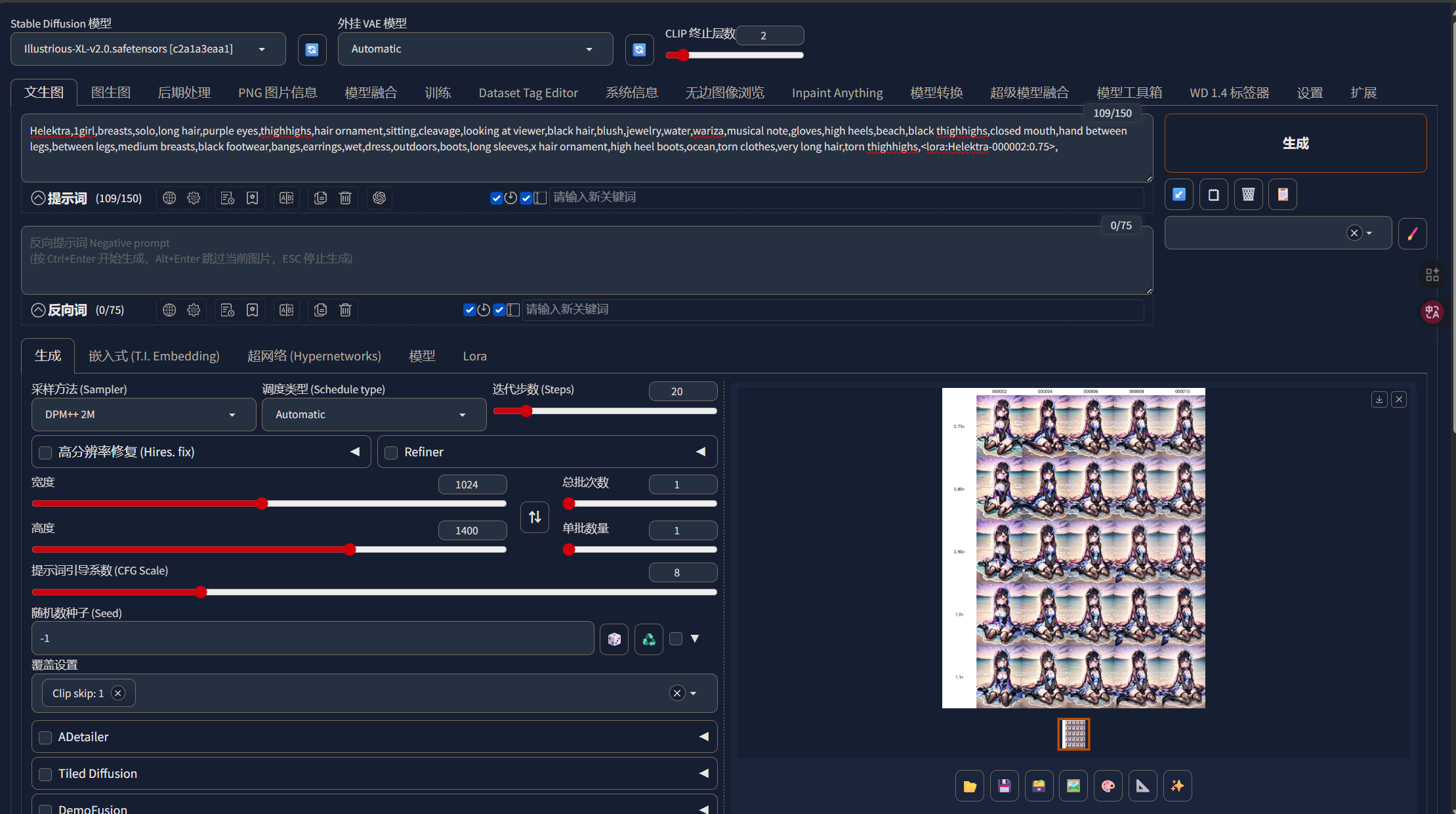
这样,我们就能看到我们的模型在不同步数与不同权重下的表现了,我们在未来可以使用那个最好的参数来进行推理。
七、结语
在本次教程中,教了大家如何挑选训练时使用的底模,也教了大家如何优化自己的数据集与训练参数,最后还讲了如何判断自己的模型在哪个步数与权重效果最好。LORA的训练有非常多的不确定性,我们需要在LORA训练中坦然接受失败,不断尝试,不断优化数据集与参数,这样才能训练出理想的模型,最后,感谢大家的观看!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)