Python的Excel表格处理——软测日常【章节二】
本文分享了作者利用AI工具快速开发办公自动化程序的经验。面对不熟悉的公司任务,作者通过Python和AI生成代码,开发出测试用例分类工具和Word文档内容提取工具。文章详细介绍了如何向AI提出清晰需求(如表格数据分类规则),并展示了生成的GUI程序代码。作者发现AI生成的代码逻辑清晰但略显冗长,包含大量错误处理机制。最终总结认为:合理使用AI辅助编程能显著提升开发效率,但需注意需求表述准确性和AI
前言
同样也是公司任务,不清楚同事是如何弄这个任务的,还不是特别熟悉,毕竟公司也没有所谓的聚餐和郊游活动,所以目前来说,照着自己的个人性格,也不好意思去问,所以,现在给我安排的任务,同样打算用Python代码大法,一键式处理,繁琐的文件信息。
一、照样是AI代码生成
在这之前,先弄明白,自己处理文档的需求,要处理哪些内容,要处理什么东西等,明白了自己的需求后,才好给AI提要求,生成的代码才能是向着自己想要的写。例如,我是这么提要求的
帮我写一个代码,我要你帮我把表格的数据分类,要求:1、根据测试用例标识分类,例如:WSYWDTAPP_XXXS_YWJS_GN01_UC01是一个用例标识,只需要把这个部分相同的:WSYWDTAPP_XXXS_YWJS_GN01归为一类,就可以了。2、归类后放一个表格,如果有多个比如:WSYWDTAPP_XXXS_YWJS_GN01_UC01、WSYWDTAPP_XXXS_YWJS_GN01_UC02、WSYWDTAPP_XXXS_YWJS_GN01_UC03这些,那么用例最后展示为这样WSYWDTAPP_XXXS_YWJS_GN01_UC01~UC03,因为这部分WSYWDTAPP_XXXS_YWJS_GN01_是相同的,但是后面的标号UC01到UC03不一样,他们直接记得用符号“~”连接。3、测试项名称,测试用例名称就只显示一条即可,因为分类后,一个WSYWDTAPP_XXXS_YWJS_GN01_UC01~UC03这种的测试用例标识对应一条测试项名称。4、你给我一个界面让我操作,这样方便我工作。5、记得在界面上补上日志展示,这样方便我纠错和优化代码
之后生成的代码是这样的
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
import pandas as pd
import re
from collections import defaultdict
class TestCaseClassifier:
def __init__(self, root):
self.root = root
self.root.title("测试用例分类工具")
self.root.geometry("900x700")
self.create_widgets()
self.log_messages = []
def create_widgets(self):
# 文件选择区域
file_frame = tk.Frame(self.root)
file_frame.pack(pady=10, padx=10, fill=tk.X)
tk.Label(file_frame, text="选择Excel文件:").pack(side=tk.LEFT)
self.file_path_var = tk.StringVar()
tk.Entry(file_frame, textvariable=self.file_path_var, width=50).pack(side=tk.LEFT, padx=5)
tk.Button(file_frame, text="浏览", command=self.browse_file).pack(side=tk.LEFT, padx=5)
tk.Button(file_frame, text="处理", command=self.process_data).pack(side=tk.LEFT, padx=5)
# 数据展示区域
data_frame = tk.Frame(self.root)
data_frame.pack(pady=10, padx=10, fill=tk.BOTH, expand=True)
tk.Label(data_frame, text="处理结果:").pack(anchor=tk.W)
# 创建Treeview来展示结果
columns = ("测试用例标识", "测试项名称", "测试用例名称")
self.tree = ttk.Treeview(data_frame, columns=columns, show="headings", height=15)
# 定义列标题
for col in columns:
self.tree.heading(col, text=col)
self.tree.column(col, width=250)
# 添加滚动条
scrollbar_y = tk.Scrollbar(data_frame, orient=tk.VERTICAL, command=self.tree.yview)
scrollbar_x = tk.Scrollbar(data_frame, orient=tk.HORIZONTAL, command=self.tree.xview)
self.tree.configure(yscrollcommand=scrollbar_y.set, xscrollcommand=scrollbar_x.set)
# 布局
self.tree.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar_y.pack(side=tk.RIGHT, fill=tk.Y)
scrollbar_x.pack(side=tk.BOTTOM, fill=tk.X)
# 日志区域
log_frame = tk.Frame(self.root)
log_frame.pack(pady=10, padx=10, fill=tk.BOTH, expand=True)
tk.Label(log_frame, text="日志信息:").pack(anchor=tk.W)
self.log_text = scrolledtext.ScrolledText(log_frame, height=8)
self.log_text.pack(fill=tk.BOTH, expand=True)
# 底部按钮
button_frame = tk.Frame(self.root)
button_frame.pack(pady=10, padx=10, fill=tk.X)
tk.Button(button_frame, text="导出结果", command=self.export_result).pack(side=tk.RIGHT, padx=5)
tk.Button(button_frame, text="清空日志", command=self.clear_log).pack(side=tk.RIGHT, padx=5)
def browse_file(self):
file_path = filedialog.askopenfilename(
title="选择Excel文件",
filetypes=[("Excel files", "*.xlsx *.xls")]
)
if file_path:
self.file_path_var.set(file_path)
self.log(f"已选择文件: {file_path}")
def log(self, message):
self.log_messages.append(message)
self.log_text.insert(tk.END, message + "\n")
self.log_text.see(tk.END)
self.root.update_idletasks()
def process_data(self):
file_path = self.file_path_var.get()
if not file_path:
messagebox.showerror("错误", "请先选择文件")
return
try:
# 读取Excel文件
df = pd.read_excel(file_path)
self.log(f"成功读取文件,共 {len(df)} 行数据")
# 清空之前的结果
for item in self.tree.get_children():
self.tree.delete(item)
# 按测试用例标识分类
classified_data = self.classify_test_cases(df)
# 显示结果
for key, cases in classified_data.items():
# 构造合并后的测试用例标识
if len(cases) > 1:
# 提取UC编号并排序
uc_numbers = []
for case in cases:
match = re.search(r'_UC(\d+)$', case['测试用例标识'])
if match:
uc_numbers.append(int(match.group(1)))
if uc_numbers:
uc_numbers.sort()
first_uc = f"UC{uc_numbers[0]:02d}"
last_uc = f"UC{uc_numbers[-1]:02d}"
if first_uc == last_uc:
merged_id = f"{key}_{first_uc}"
else:
merged_id = f"{key}_{first_uc}~{last_uc}"
else:
merged_id = key
else:
merged_id = cases[0]['测试用例标识']
# 只显示第一条记录的测试项名称和测试用例名称
first_case = cases[0]
self.tree.insert("", tk.END, values=(
merged_id,
first_case.get('测试项名称', ''),
first_case.get('测试用例名称', '')
))
self.log(f"数据处理完成,共生成 {len(classified_data)} 个分类")
except Exception as e:
messagebox.showerror("错误", f"处理数据时出错: {str(e)}")
self.log(f"错误: {str(e)}")
def classify_test_cases(self, df):
# 按测试用例标识前缀分类
classified = defaultdict(list)
for index, row in df.iterrows():
test_case_id = row.get('测试用例标识', '')
if not test_case_id:
continue
# 提取前缀部分(去掉_UCXX部分)
prefix = re.sub(r'_UC\d+$', '', test_case_id)
classified[prefix].append(dict(row))
return classified
def export_result(self):
if not self.tree.get_children():
messagebox.showwarning("警告", "没有可导出的数据")
return
file_path = filedialog.asksaveasfilename(
title="保存结果",
defaultextension=".xlsx",
filetypes=[("Excel files", "*.xlsx"), ("CSV files", "*.csv")]
)
if not file_path:
return
try:
# 收集Treeview中的数据
data = []
for item in self.tree.get_children():
values = self.tree.item(item, 'values')
data.append({
'测试用例标识': values[0],
'测试项名称': values[1],
'测试用例名称': values[2]
})
# 导出到文件
df = pd.DataFrame(data)
if file_path.endswith('.xlsx'):
df.to_excel(file_path, index=False)
else:
df.to_csv(file_path, index=False, encoding='utf-8-sig')
self.log(f"结果已导出至: {file_path}")
messagebox.showinfo("成功", f"结果已导出至:\n{file_path}")
except Exception as e:
messagebox.showerror("错误", f"导出文件时出错: {str(e)}")
self.log(f"导出错误: {str(e)}")
def clear_log(self):
self.log_text.delete(1.0, tk.END)
self.log_messages = []
self.log("日志已清空")
def main():
root = tk.Tk()
app = TestCaseClassifier(root)
root.mainloop()
if __name__ == "__main__":
main()
运行一下试试看,测试一下,能不能完成我们的工作
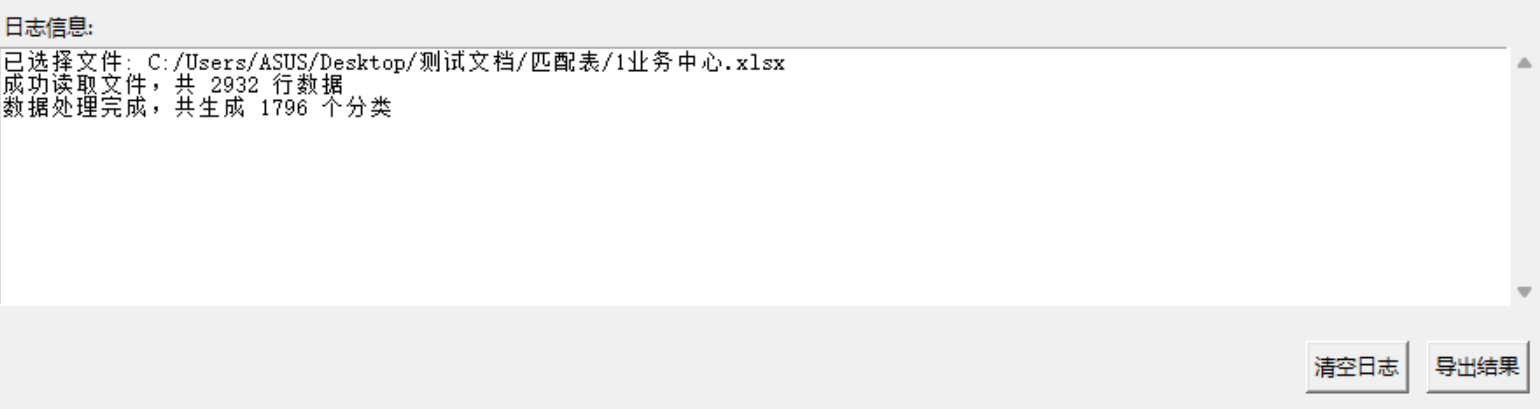
成功处理,得到我想要的结果。
二、生成后,不断调整
后面呢,就是根据自己的需要,不断去添加修改需求,然后让AI改代码了,最后得出自己的想要的结果,我现在还需要一个可以提取word文档中的内容的工具,然后让AI 不断帮忙修改,结果如下:
也是成功,搞出了2坨能用的工具,反正也就是处理一下小问题。尝试一下,看看结果:
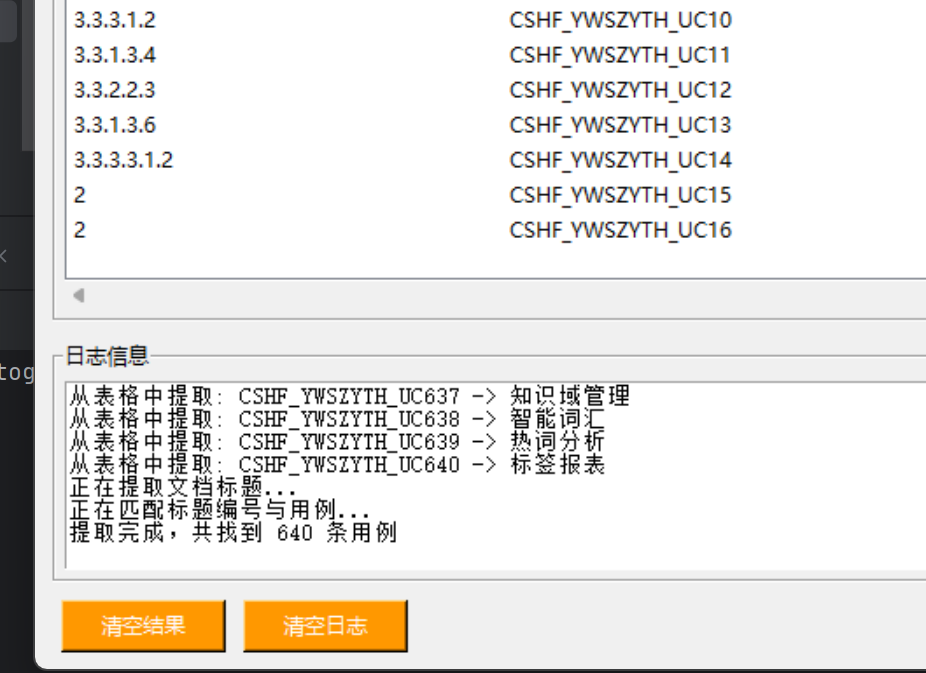
也是成功得到想要的。
三、总结
最后,总结呢,就是AI写的代码,逻辑清楚,结构清晰,但是有一种很多的感觉(屎山)(不是?】!),【AI:先不管理,来个一千行代码再说】,AI的代码,看了之后,感觉里面有很多的备案,类似的try except Exception as e 用的比较多,算是为了反正代码卡死的一种手段吧,反正处理的是比我好很多,但是,就目前来看,我自己使用的感觉是,学会使用AI帮助我编程作用很大,而且可以很快的开发完我想要的东西,真的快很多,而且,对应个人的辅助真的是很好,当然,自身能力也不能落下(哦,还得注意AI的记忆能力,反正他来来回回的给你改代码,或者混淆东西)
四、最近补充
最近这两天文档需要修改,给我临时安排了任务,然后发现当前的文档处理脚本并没有达到我的要求,旧版本的问题是实在一言难尽,所以,我觉得优化当前问题,几经周折,最后还是放弃AI写代码(😭哭),【实在是问AI问到恼火,已经开骂AI了,希望AI大人以后觉醒,不要第一个干我😯】(再次声明目前我的使用感觉来说AI并不是万能的,希望合理的使用它,虽然它有许许多多的小问题,但是希望AI的发展再接再厉,加油程序员们,加油各位大佬,下面慢慢给大家展示我的优化历程,我和AI不得不说的俩三事🐶)
补充1
AI目前对一些东西的处理记忆容易混乱。次数较多情况,或者,如果不断上传之前的资料啥的,这样的话,AI的每次修改或者给出的东西,可以是重复的,没有修改的,感觉可以试试自己调配的,按照自己的心意去调教的符合自己工作习惯的AI可能情况会好一些。下图是实在没有办法,重新开启新的窗口,防止AI老是给我搞混东西,推荐是核心部分代码,可以直接给出一部分逻辑,或者直接的需求很明确,一步一步的讲得非常清楚。
补充2
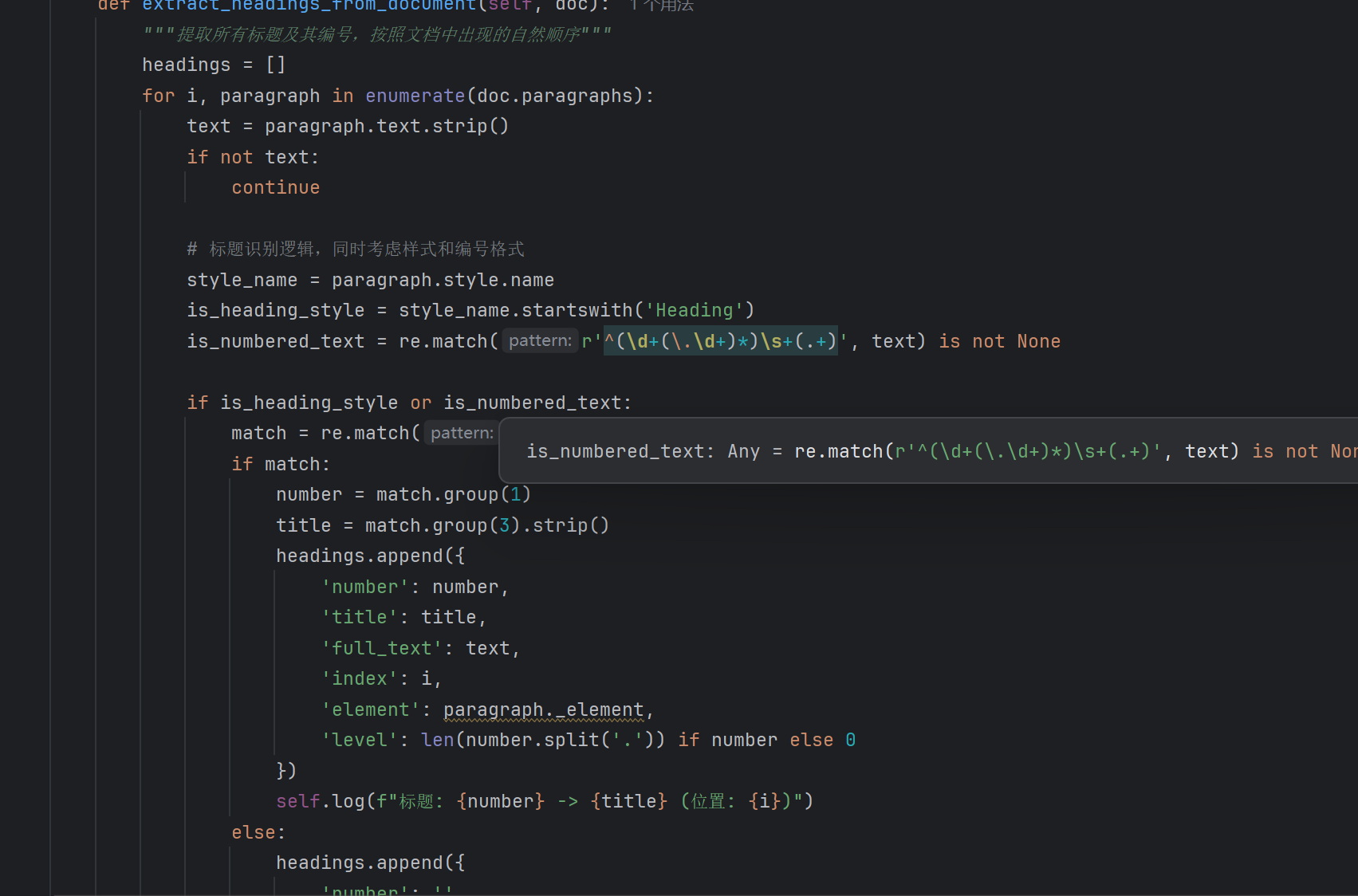
最新的修改后的的效果展示,效果比以前的好很多,同时也达到了我的需求,很快的帮我处理完成将近几千条数据,让我省去了很多的人工时间。(事实上,核心部分代码还是自己写完逻辑后,丢给AI帮忙,就一个标题的顺序提取,因为当时可以给AI提需求时,讲得不够明确,让AI理解错误,AI提取的标题,按照了父子层级树的关系进行存储,但是这不是我想要的,后面这部分手动来完成【哭笑】)最后说,打铁还得自身硬,目前来说AI是一个很好的辅助工具,遇到问题多思考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)