【Datawhale之Happy-LLM】T5 encoder-decoder——Github最火大模型原理与实践教程task06
T5(Text-To-Text Transfer Transformer)是Google提出的预训练语言模型,其核心思想是实现NLP任务的大一统处理方式。T5将所有NLP任务视为文本到文本的转换问题,通过预训练+微调范式实现。模型采用Encoder-Decoder架构,主要改进包括:1)使用编码器自注意力和解码器自注意力+编解码注意力;2)采用RMSNorm归一化方法稳定训练;3)基于大规模清洗的
Task06
:第三章 预训练语言模型PLM
3.2 Encoder-Decoder(以T5为代表)
(这是笔者自己的学习记录,仅供参考,原始学习链接,愿 LLM 越来越好❤)
T5是什么
T5 = 5个T:Text-To-Text Transfer Transformer 文生文转化变换器
是Google的PLM,是模型。
T5的核心思想——大一统再分而治之
其实也就还是之前章节提到的思想,
预训练+微调+所有NLP都T2T
-
大一统:认为所有的NLP都是文2文,简化忽略不同任务的差异,所以搞一个通用泛化好的模型。- 如之前task中章节提到的NLP任务,翻译、问答、给句子定性等,退退退抛去很多任务差异,底层都是输入文本经过模型之后输出文本。
- NLP任务的差异,问答可能输出就比输入长,定性输出可能就比输入短。
-
分而治之:再根据具体任务微调,所以T5是一个泛化能力强的模型,基于T5微调后的模型就是更专精。
T5模型的伪解释图
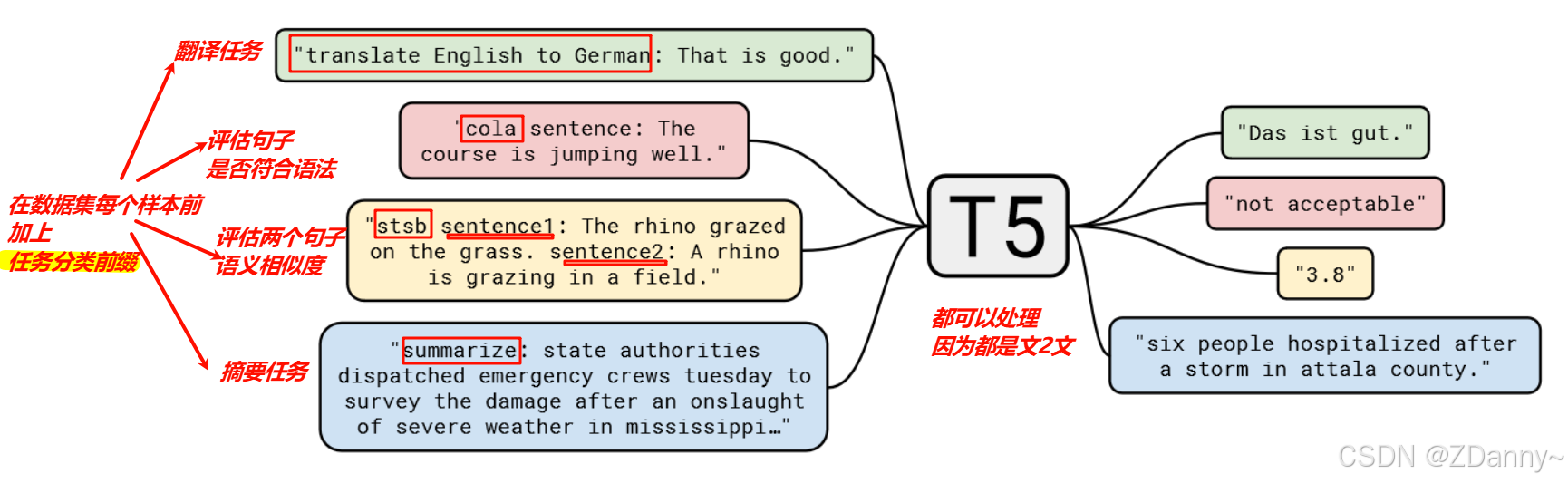
T5的结构
从大往小看:
还是tokenizer+Transformer架构;
Transformer 用了编、解码器;
每个编、解码层有attention、fnn、norm;
attention是捕(一个序列内部全局、输入输出序列之间)的关系。fnn是处理特征的非线性变换。
总体结构图
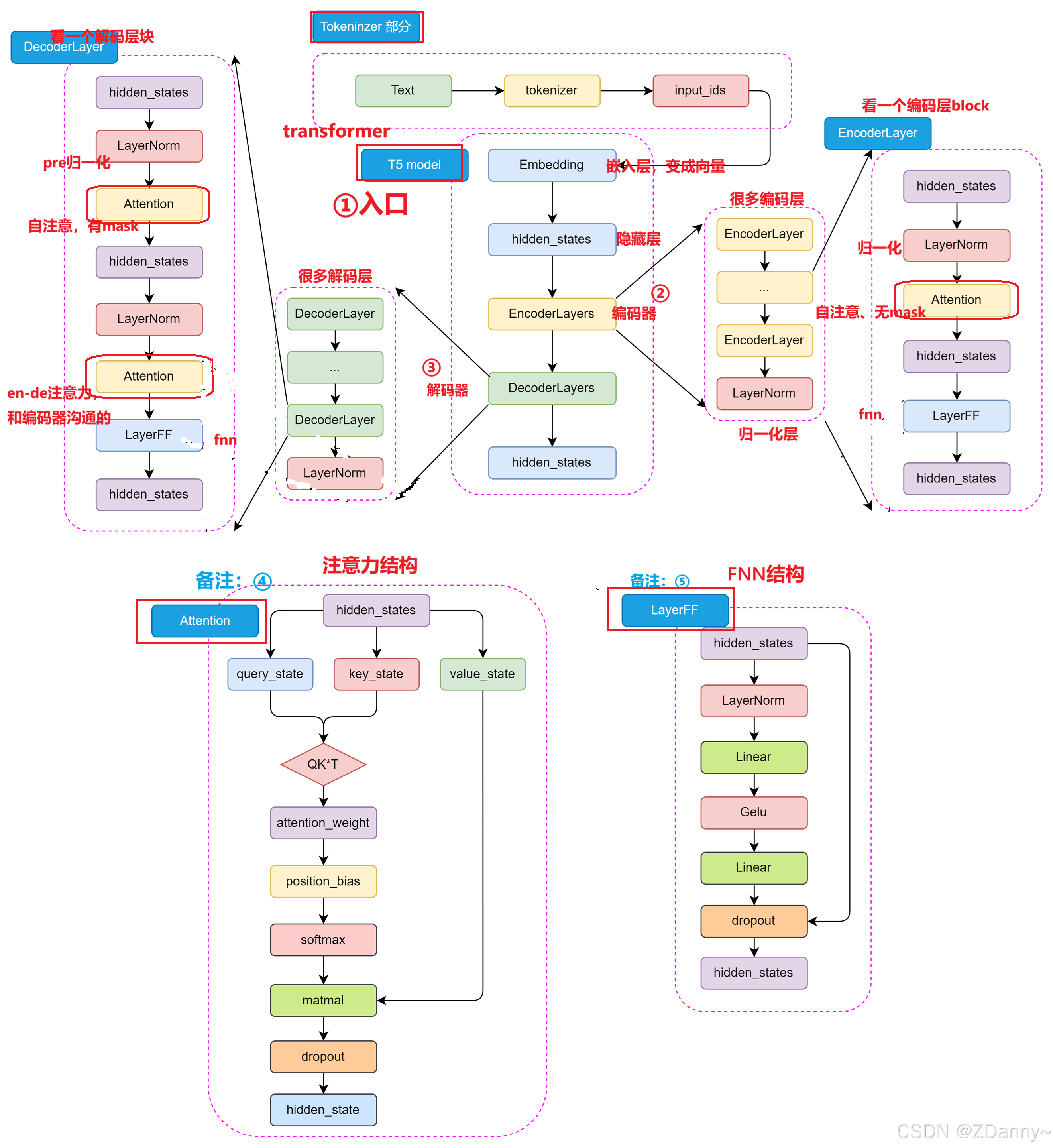
修改一:T5的attention
encoder 1️⃣个attention:encoder-self-attention
decoder 2️⃣个attention:decoder-self-attention、encoder-decoder-attention
自注意 vs 编解码注意力 vs 多头注意力的区别
| 类型 | Q、K、V 来源 | 出现位置 | 作用 | 举例 |
|---|---|---|---|---|
| 自注意力(Self-Attention) | Q、K、V 来自同一个序列 | 编码器 & 解码器 | 全局依赖关系建模方法 通过计算 QK 相似度来捕捉输入序列内部的依赖关系 |
翻译“我爱你”时,模型要理解“我”和“你”的关系 |
| 编解码注意力(Encoder-Decoder Attention) | Q 来自解码器当前步骤;K、V 来自编码器输出 | 解码器 | 让解码的输出关注到编码的输出内容 | 翻译“Grilled Salmon with Lemon Butter Sauce”中的“Grilled Salmon”时,解码器回看英文句子中的“Grilled”、“Salmon”、“Lemon Butter Sauce”,决定中文可能是“柠檬黄油烤三文鱼” |
| 多头注意力(Multi-Head Attention) | 它是一种策略,自注意或者编解码注意力的并行版本 | 编码器 & 解码器 & 编解码层都可用 | 并行关注不同的语义子空间,同一句从不同角度(头)关注,增强模型的表达能力 | 翻译“爱”时,同时从多个角度理解“爱”,不同头分别从情感、语法、语境等角度理解 |
补充说明:编码器 vs 解码器 中的自注意力
- encoder-self-attention 没有 mask,所有位置互相关注
- decoder-self-attention 有mask,防止偷看未来
修改二:T5用的归一化RMSNorm
Transformer中的神经元是什么?
一个隐藏层输出是向量,向量有很多维度,比如768或者1024。这每一维度就是一个神经元,维度的值就叫神经元的激活值。所以神经元就是维度、也是特征。
隐藏层输出向量(假设维度为 4):
[0.5, -1.2, 0.3, 0.8]
#这 4 个数值就可以看作是 4 个“神经元”的激活值。
RMS是什么?
root mean square= 均方根,顾名思义:平方的均值开根号。
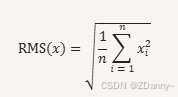
RMSNorm是什么?
是个函数,也是归一化层用的方法
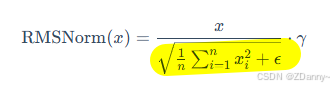
- 做法:如公式展示的,每个神经元的激活值➗他们的均方根进行放缩,从而实现归一化
- 好处:相比于layerNorm,它只需要学一个参数 γ \gamma γ(缩放因子),而 ε \varepsilon ε就是为了放置除以0的小常数
- 用RMSNorm的目的:确保权重的规模不会太大或太小(否则容易训着训着模型就梯度爆炸或者消失),稳定神经元的数值来稳定梯度。(尤其是层多了就要很注意)
修改三:T5的预训练任务
| 修改点 | 具体内容 |
|---|---|
| 数据集扩大 | - 数据集:Google 自建 C4 数据集(Colossal Clean Crawled Corpus) - 规模:约 750GB,已在 TensorFlow Datasets 开源 - 来源:从 Common Crawl 中提取大量英文文本 + 清洗去除了无意义文本、重复文本 |
| 训练任务增多 | - 主要还是 BERT-style 的 MLM(掩码语言建模) - 同时尝试 多任务混合训练(Multi-task Learning)(具体怎么个混合法就不知道了) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)