SQLAlchemy 2.0数据库操作学习记录
·
目录
7、使用connection完成增删查改(利用text包住sql语句)
学习来源:
SQLAlchemy 2.0 教程 - Yifei's Notes
使用 INSERT 语句 — SQLAlchemy 2.0 文档 - SQLAlchemy 中文
1、链接数据库
from sqlalchemy import Column, String, create_engine, Integer, text, DateTime, select,UniqueConstraint, and_, ForeignKey, inspect, Numeric, func
from sqlalchemy.orm import sessionmaker, mapped_column, Mapped, relationship
from sqlalchemy.ext.declarative import declarative_base
db_path = r"C:\Users\xxx\AppData\Roaming\DBeaverData\workspace6\.metadata\sample-database-sqlite-1\Chinook.db" # 我找了一个dbeaver生成的示例数据库
engine = create_engine(f"sqlite:///{db_path}", echo=True)
sessionLocal = sessionmaker(engine)
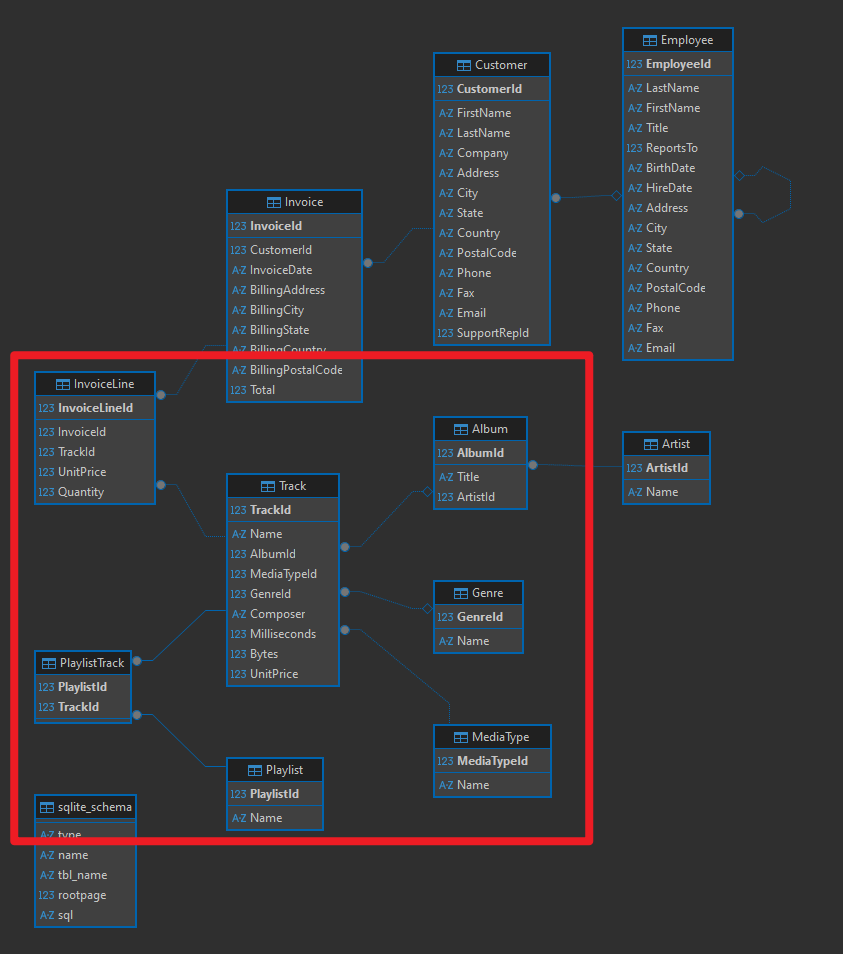
2、对应的表创建对应的class(表之间的关系图如下)
# 基类
Base = declarative_base()
# 不同的表不同的class,这里放几个表,关系图如上图。其中,track是比较中心的表,通过不同id链接了多个表格,其次,playlisttrack是一个记录了两个外键的表,链接了playlist和track的多对多关系
class MediaType(Base):
__tablename__ = "MediaType"
MediaTypeId: Mapped[int] = mapped_column(Integer, primary_key= True)
Name: Mapped[str] = mapped_column(String(120))
# relationship
track = relationship("Track", back_populates="media_type") # 第一个变量是索引的另一个类名,第二个变量是类里面对应的变量属性
class Genre(Base):
__tablename__ = "Genre"
GenreId: Mapped[int] = mapped_column(Integer, primary_key= True)
Name: Mapped[str] = mapped_column(String(120))
# relationship
track = relationship("Track", back_populates="genre")
class Album(Base):
__tablename__ = "Album"
AlbumId: Mapped[int] = mapped_column(Integer, primary_key= True)
Title: Mapped[str] = mapped_column(String(160))
ArtistId: Mapped[int] = mapped_column(Integer)
# relationship
track = relationship("Track", back_populates="album")
class InvoiceLine(Base):
__tablename__ = "InvoiceLine"
InvoiceLineId: Mapped[int] = mapped_column(Integer, primary_key= True)
InvoiceId: Mapped[int] = mapped_column(Integer)
TrackId: Mapped[int] = mapped_column(Integer, ForeignKey("Track.TrackId"))
UnitPrice: Mapped[float] = mapped_column(Numeric(precision=10, scale=2))
Quantity: Mapped[int] = mapped_column(Integer)
# relationship
track = relationship("Track", back_populates="invoice_line")
class Playlist(Base):
__tablename__ = "Playlist"
PlaylistId: Mapped[int] = mapped_column(Integer, primary_key= True)
Name: Mapped[str] = mapped_column(String(160))
# relationship
track = relationship("Track", secondary= 'PlaylistTrack', back_populates="play_list")
class Track(Base):
__tablename__ = "Track"
TrackId: Mapped[int] = mapped_column(Integer, primary_key= True)
Name: Mapped[str] = mapped_column(String(200))
AlbumId: Mapped[int] = mapped_column(Integer, ForeignKey("Album.AlbumId"))
MediaTypeId: Mapped[int] = mapped_column(Integer, ForeignKey("MediaType.MediaTypeId"))
GenreId: Mapped[int] = mapped_column(Integer, ForeignKey("Genre.GenreId"))
Composer: Mapped[str] = mapped_column(String(220))
Milliseconds: Mapped[int] = mapped_column(Integer)
Bytes: Mapped[int] = mapped_column(Integer)
UnitPrice: Mapped[float] = mapped_column(Numeric(precision=10, scale=2))
# relationship
media_type = relationship("MediaType", back_populates= "track")
genre = relationship("Genre", back_populates= "track")
album = relationship("Album", back_populates= "track")
invoice_line = relationship("InvoiceLine", back_populates= "track")
play_list = relationship("Playlist", secondary= 'PlaylistTrack', back_populates= "track")
class PlaylistTrack(Base):
__tablename__ = "PlaylistTrack"
PlaylistId: Mapped[int] = mapped_column(Integer, ForeignKey(Playlist.PlaylistId), primary_key= True)
TrackId: Mapped[int] = mapped_column(Integer, ForeignKey(Track.TrackId), primary_key= True)3、增insert
a1 = Album()
a1.Title = 'soul'
a1.AlbumId = 1
a1.ArtistId = 12
with sessionLocal() as s1:
s1.add(a1)
s1.commit()4、查select
# 简单查询
stmt = select(Album).where(Album.AlbumId == 66)
with sessionLocal() as s1:
result = s1.execute(stmt).scalars().all()# 注意scalars不要写成scalar
for r in result:
print(r.Title, r.AlbumId, r.ArtistId)
# 复杂一点的连带着其他表的查询
stmt = (select(Genre.Name, func.count(Track.TrackId)).join(Track, Track.GenreId == Genre.GenreId)
.group_by(Genre.GenreId).having(func.count(Track.TrackId) > 100))
# 查找track数大于100的音乐类型以及对应的track总数
# group用having,select对象用where
with sessionLocal() as session1:
result = session1.execute(stmt)
for r in result:
print(r)5、改update
# 先筛选出对象然后进行修改
stmt = select(Album).where(Album.AlbumId == 66)
with sessionLocal() as s1:
result = s1.execute(stmt).scalars().all()
for r in result:
r.Title = 'change 66'
s1.commit() # 需要手动提交
# 或者使用update语句
stmt = update(Album).where(Album.AlbumId == 66).values(Title = 'change 66')
with sessionLocal() as s1:
s1.execute(stmt)
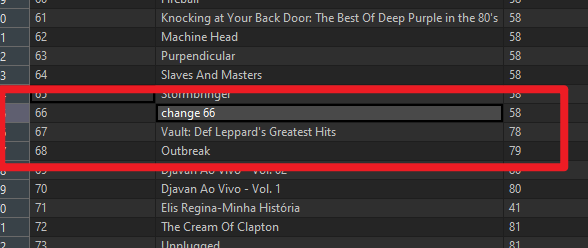
s1.commit()回到数据库看,albumid为66的title已经被修改
6、删除delete
stmt = select(Album).where(Album.AlbumId == 88)
with sessionLocal() as s1:
result = s1.execute(stmt).scalars().all()
for r in result:
s1.delete(r)
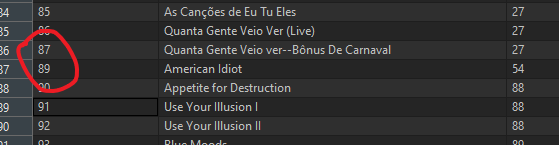
s1.commit()可以看到albumid为88的记录已经被删除
7、使用connection完成增删查改(利用text包住sql语句)
- 查询
# conn
with engine.connect() as conn:
result = conn.execute(text('select * from album where albumid = 66'))
for r in result:
print(r)查询结果
![]()
- 插入
with engine.connect() as conn:
conn.execute(text("insert into album values (88, 'insert 88', 89)"))
conn.commit() # 提交
- 修改
with engine.connect() as conn:
conn.execute(text("update album set title = 'update 33' where albumid = 33"))
conn.commit()
- 删除
with engine.connect() as conn:
conn.execute(text("delete from album where albumid = 45"))
conn.commit()
8、批量插入(利用字典格式
with sessionLocal() as s1:
albums = [
{"Title": "jjlu", "AlbumId": 888, "ArtistId": 99},
{"Title": "listen", "AlbumId": 987, "ArtistId": 929},
{"Title": "how", "AlbumId": 792, "ArtistId": 100}
]
s1.bulk_insert_mappings(Album, albums)
s1.commit()
9、批量修改
with sessionLocal() as s1:
albums = [
{"Title": "hello1", "AlbumId": 888, "ArtistId": 89757},
{"Title": "bulk", "AlbumId": 987, "ArtistId": 29873},
{"Title": "update111", "AlbumId": 792, "ArtistId": 23411}
]
s1.bulk_update_mappings(Album, albums)
s1.commit()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)