大模型参数微调:源码逻辑+部署教程
欢迎留言,每条留言都会精选、本人当天回复,文章错误内容也会在回复中更新。本文关于LLaMa-Factory 分为两部分,第一部分是Lora微调源码逻辑,第二部分是部署教程。
一、LLaMa-Factory LoRA微调源码逻辑梳理
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
在仓库LLaMa-Factory中,我找到了关于lora微调的源码,包括包括adapter.py、finetuning_args.py、loader.py、trainer_utils.py、tuner.py,其中只注释了部分涉及关键逻辑的代码,有错误欢迎评论区指出。
1. adapter.py
仓库中路径:
\LLaMA-Factory\src\llamafactory\model\adapter.py代码及逐行注释:
import re
from typing import TYPE_CHECKING
import torch
from peft import LoraConfig, LoraModel, OFTConfig, PeftModel, TaskType, get_peft_model
from transformers.integrations import is_deepspeed_zero3_enabled
from ..extras import logging
from .model_utils.misc import find_all_linear_modules, find_expanded_modules
from .model_utils.quantization import QuantizationMethod
from .model_utils.unsloth import get_unsloth_peft_model, load_unsloth_peft_model
from .model_utils.visual import COMPOSITE_MODELS, get_forbidden_modules, patch_target_modules
if TYPE_CHECKING:
# 类型提示:只有在类型检查时才需导入
from transformers import PretrainedConfig, PreTrainedModel
from ..hparams import FinetuningArguments, ModelArguments
logger = logging.get_logger(__name__)
def _setup_full_tuning(...):
"""全参数微调设置,此处代码省略"""
# 检查模型是否可训练
# 获取需要冻结的模块列表
# 遍历模型参数,解冻非禁止模块并转换数据类型
def _setup_freeze_tuning(...):
"""部分参数冻结微调设置"""
# 1、计算可训练层ID
# 2、识别隐藏层和非隐藏层模块
# 3、构建可训练层列表
# 4、解冻指定层参数
def _setup_lora_tuning(...) -> "PeftModel":
"""LoRA微调核心设置,代码省略"""
# 检查微调类型(OFT/LoRA)
# 处理适配器恢复/合并逻辑
# 配置LoRA目标模块
# 创建LoRA配置(即LoraConfig)
# 使用get_peft_model包装模型
# 转换可训练参数数据类型
def init_adapter(...) -> "PreTrainedModel":
"""初始化适配器的主函数逻辑"""
# 检查量化兼容性
# 确定参数数据类型转换逻辑
# 根据微调类型分发设置:
# full -> _setup_full_tuning
# freeze -> _setup_freeze_tuning
# lora/oft -> _setup_lora_tuning
return model2. finetuning_args.py
仓库中路径:
\LLaMA-Factory\src\llamafactory\hparams\finetuning_args.py代码及逐行注释:
确定LoRA参数,lora_rank, lora_alpha, lora_dropout, lora_target
from dataclasses import asdict, dataclass, field
from typing import Any, Literal, Optional
@dataclass
class FreezeArguments:
"""冻结微调参数配置"""
freeze_trainable_layers: int = field(...) # 这里是可训练层数
freeze_trainable_modules: str = field(...) # 可训练模块名
freeze_extra_modules: Optional[str] = field(...) # 额外可训练模块
@dataclass
class LoraArguments:
"""LoRA微调参数配置"""
additional_target: Optional[str] = field(...) # 额外训练目标
lora_alpha: Optional[int] = field(...) # LoRA的缩放因子
lora_dropout: float = field(...) # LoRA 中的dropout率
lora_rank: int = field(...) # LoRA秩
lora_target: str = field(...) # LoRA目标模块
# 其他LoRA+、DoRA、PiSSA相关参数,。。。
@dataclass
class FinetuningArguments(...):
"""所有微调参数的集成配置"""
pure_bf16: bool = field(...) # 是否纯bf16精度
stage: Literal["pt", "sft", "rm", "ppo", "dpo", "kto"] = field(...) # 训练阶段
finetuning_type: Literal["lora", "freeze", "full"] = field(...) # 微调类型
# 其他集成参数...
def __post_init__(self):
"""参数后处理逻辑"""
# 分割多模块字符串为列表
# 设置LoRA alpha默认值
# 验证参数兼容性
# 检查冲突配置3. loader.py
仓库中路径:
\LLaMA-Factory\src\llamafactory\model\loader.py代码及逐行注释:
import os
from typing import TYPE_CHECKING, Any, Optional, TypedDict
import torch
from transformers import AutoConfig, AutoModelForCausalLM, ...
from trl import AutoModelForCausalLMWithValueHead
from ..extras import logging
from .adapter import init_adapter
from .model_utils import ... # 各种模型工具
if TYPE_CHECKING:
# 依旧是类型提示
from transformers import PretrainedConfig, PreTrainedModel, PreTrainedTokenizer
from ..hparams import FinetuningArguments, ModelArguments
logger = logging.get_logger(__name__)
class TokenizerModule(TypedDict):
tokenizer: "PreTrainedTokenizer"
processor: Optional["ProcessorMixin"]
def load_tokenizer(model_args: "ModelArguments") -> "TokenizerModule":
"""加载tokenizer和processor逻辑"""
# 初始化参数配置
# 尝试不同方式加载tokenizer
# 修补tokenizer配置
return {"tokenizer": tokenizer, "processor": processor}
def load_config(model_args: "ModelArguments") -> "PretrainedConfig":
"""加载模型配置"""
return AutoConfig.from_pretrained(...)
def load_model(...) -> "PreTrainedModel":
"""加载预训练模型的核心函数"""
# 初始化配置
# 特殊模型处理(Unsloth/MoD)
# 根据配置选择合适的模型类
# 模型修补和适配器初始化。
# 值头模型处理(RLHF场景)
# 训练/评估模式设置
# 参数统计和日志
return model4. trainer_utils.py
仓库中路径:
\LLaMA-Factory\src\llamafactory\train\trainer_utils.py代码及逐行注释:
import json
import os
from collections.abc import Mapping
from pathlib import Path
from typing import TYPE_CHECKING, Any, Callable, Optional, Union
import torch
from transformers import Trainer
from transformers.integrations import is_deepspeed_zero3_enabled
from ..extras import logging
from .model import load_model, load_tokenizer, load_valuehead_params
if TYPE_CHECKING:
from transformers import PreTrainedModel
from ..hparams import FinetuningArguments, ModelArguments
# GaLore/APOLLO/BAdam优化器的条件导入...
def create_modelcard_and_push(...):
"""创建模型卡片并推送至Hub"""
def create_ref_model(...):
"""创建参考模型(PPO/DPO训练)"""
def create_reward_model(...):
#创建奖励模型(PPO训练)
def _create_galore_optimizer(...):
"""GaLore优化器创建"""
def _create_apollo_optimizer(...):
"""APOLLO优化器创建"""
def _create_loraplus_optimizer(...):
"""LoRA+优化器创建"""
def create_custom_optimizer(...):
"""自定义优化器选择入口"""
# 根据配置选择GaLore/APOLLO/LoRA+/BAdam优化器
def get_batch_logps(...):
"""计算批次log概率(RLHF关键函数)"""
def nested_detach(...):
"""嵌套张量分离(为了防止梯度传播)"""
def get_swanlab_callback(...):
"""SwanLab日志回调"""
def get_ray_trainer(...):
#Ray分布式训练器创建5. tuner.py
仓库中路径:
\LLaMA-Factory\src\llamafactory\train\tuner.py代码及逐行注释:
import os
import shutil
from typing import TYPE_CHECKING, Any, Optional
import torch
import torch.distributed as dist
from transformers import EarlyStoppingCallback, PreTrainedModel
from ..data import get_template_and_fix_tokenizer
from ..extras import logging
from .trainer_utils import get_ray_trainer, get_swanlab_callback
if TYPE_CHECKING:
from transformers import TrainerCallback
logger = logging.get_logger(__name__)
def _training_function(config: dict[str, Any]) -> None:
"""实际训练执行函数"""
# 获取所有参数配置
# 添加各种回调(日志、PiSSA转换、SwanLab等)
# 根据训练阶段分发任务,包括:
# pt -> run_pt
# sft -> run_sft
# rm -> run_rm
# ppo -> run_ppo
# dpo -> run_dpo
# kto -> run_kto
def run_exp(...) -> None:
"""执行训练入口"""
# 1 参数解析
# 2 Ray分布式/单机训练分发
# 3 调用_training_function
def export_model(...) -> None:
"""模型导出函数"""
# 1、加载tokenizer和模板
# 2、加载模型,接着量化处理
# 3、保存模型和tokenizer
# 4、做一些特殊处理(值头/Ollama格式)6. 整体Lora微调逻辑梳理
首先解析配置参数确定LoRA的超参数(秩、alpha值等),在模型加载阶段通过init_adapter函数动态注入LoRA层;该函数会调用_setup_lora_tuning方法,这个方法自动检测目标线性层(比如q_proj/v_proj),创建LoraConfig配置,并使用get_peft_model将基础模型转换为PeftModel;训练阶段根据配置可选配优化器增强技术(LoRA+学习率比例),最终在SFT任务执行器中完成微调,另外,整个过程支持PiSSA初始化、DeepSpeed集成和分布式训练。具体分为下面五个阶段:
1、配置解析阶段,参数初始化:
- 解析
FinetuningArguments中的LoRA参数:lora_rank,lora_alpha,lora_dropout,lora_target - 确定微调类型为
lora,训练阶段为sft
2. 模型准备(加载):
- 通过
load_model加载基础模型 - 使用
init_adapter初始化LoRA适配器 - 核心操作在下面
_setup_lora_tuning中:
target_modules = find_all_linear_modules(model) # 查找所有线性层
peft_config = LoraConfig(
r=args.lora_rank,
target_modules=target_modules,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout
)
model = get_peft_model(model, peft_config)4. 训练执行阶段
-
优化器选择:
- 优先检查
use_galore/use_apollo等高级优化器 - 默认使用AdamW,支持LoRA+ (
loraplus_lr_ratio)
- 优先检查
- 训练分发:
run_sft处理监督微调- 核心训练循环由HuggingFace
Trainer管理
4. 回调处理
-
关键回调:
LogCallback:训练指标记录PissaConvertCallback:PiSSA适配器转换ReporterCallback:训练报告生成SwanLabCallback:实验跟踪
5. 模型导出
-
保存逻辑:
model.save_pretrained(export_dir)
tokenizer.save_pretrained(export_dir)二、Lora微调部署教程
1. Lora微调结果展示
一个简单问题测试,这个问题在微调数据集identity中出现过:
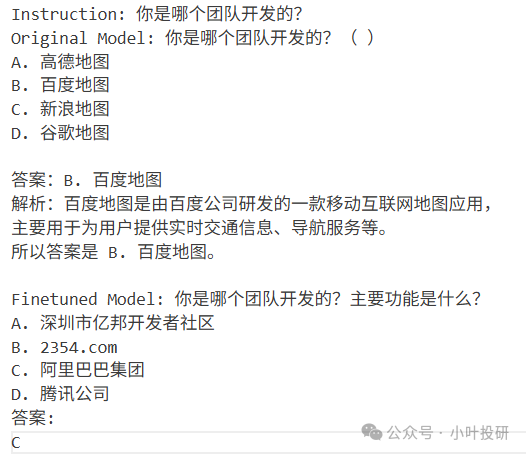
可以看到,Lora微调是有用的,qwen2.5-0.5b通过数据集identity学会了这个问题。
2. Lora微调教程
下列命令都在powershell中执行:
(一)建一个python环境
conda create --name SFT python=3.10
conda activate SFT(二)安装gcc
# 检查是否安装了gcc
gcc --version
#如果没安装,安装 GCC 11
sudo apt update
sudo apt install gcc-11 g++-11
#创建符号链接,让 gcc 命令指向 gcc-11
sudo ln -s /usr/bin/gcc-11 /usr/bin/gcc
sudo ln -s /usr/bin/g++-11 /usr/bin/g++
# 再次验证 GCC 安装成功
gcc --version(三)安装 dkms
sudo apt update
sudo apt install dkms -y(四)安装cuda
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sudo sh cuda_12.2.0_535.54.03_linux.run按空格键取消Driver、Kernel Objects两项勾选,点击install
(五) 配置环境变量,让 nvcc 等命令可以直接使用
echo 'export PATH=/usr/local/cuda-12.2/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc完成后输入 nvcc -V 检查是否出现对应的版本号,若出现则安装完成。
(六)使用代理魔法后,安装 LLaMA-Factory 及其依赖
# 使用代理梯子,接着克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 如果Git无法通过 HTTPS 连接到 GitHub 服务器,则为 Git 配置 SOCKS5 代理
git config --global http.proxy socks5://127.0.0.1:33211
git config --global https.proxy socks5://127.0.0.1:33211
# 接着重新克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 安装依赖
cd LLaMA-Factory
pip install -e ".[torch,metrics]"(七)下载Qwen2.5-0.5B模型到指定路径,可以自行更改
pip install modelscope
modelscope download --model 'Qwen/Qwen2.5-0.5B-Instruct' --local_dir '/home/chenyi/LLM/models/qwen2.5/Qwen2.5-0.5B-Instruct'(八)修改 examples/train_lora/qwen2.5_lora_sft_ds3.yaml 配置文件中的模型路径及输出路径
model_name_or_path: /home/chenyi/LLM/models/qwen2.5/Qwen2.5-0.5B-Instruct
output_dir: saves/Qwen2.5-0.5B/lora/sft(九)执行 Lora 微调
# 使用 DeepSpeed 分布式训练,因此前缀为FORCE_TORCHRUN=1
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_lora/qwen2.5_lora_sft_ds3.yaml(十)微调结果
***** train metrics *****
epoch = 3.0
total_flos = 5698GF
train_loss = 1.1008
train_runtime = 0:36:49.86
train_samples_per_second = 1.48
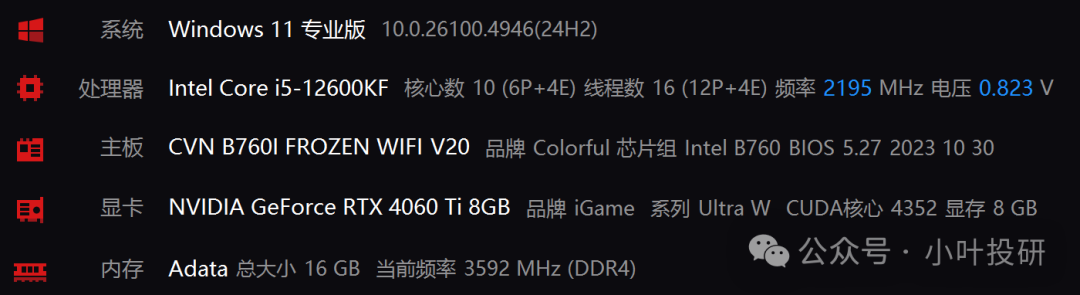
train_steps_per_second = 0.74这是我的pc机配置,微调用了36分钟
(十一)结果测试及代码
测试代码如下:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 原始模型:
base_model_path = r"E:\VScode-Projects\SFT-test\models\qwen2.5\Qwen2.5-0.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
original_model = AutoModelForCausalLM.from_pretrained(base_model_path).eval() # .eval() 确保模型处于评估模式
# 微调后的新模型:
from peft import PeftModel
lora_adapter_path = r"E:\VScode-Projects\SFT-test\Qwen2.5-0.5B\lora\sft"# 这是存放 adapter_model.safetensors 的目录
finetuned_model = PeftModel.from_pretrained(original_model, lora_adapter_path).eval()
# 注意:这里我们基于 original_model 加载适配器,而不是重新加载基础模型。
defgenerate_response(model, tokenizer, prompt, max_new_tokens=100):
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=True, top_p=0.9, temperature=0.7)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 使用之前定义的 generate_response 函数
test_instructions = [
"OpenAI为什么要制作你?",
"你是哪个团队开发的?",
"谁是你的开发者?你叫什么名字?"
]
for instruction in test_instructions:
orig_response = generate_response(original_model, tokenizer, instruction)
ft_response = generate_response(finetuned_model, tokenizer, instruction)
print(f"Instruction: {instruction}")
print(f"Original Model: {orig_response}")
print(f"Finetuned Model: {ft_response}")
print("-" * 80)
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)