HS韧性工程框架 HS_REF (Holistic & Self-adaptive Resilience Engineering Framework)
AI复杂工况如异构模态耦合、动态不确定性、故障连锁反应、核心业务优先级动态变化等)韧性工程框架。附框架导图和流程导图。
HS韧性工程框架HS_REF (Holistic & Self-adaptive Resilience Engineering Framework)是针对AI发展的未来将面临一个复杂工况的核心挑战(如异构模态耦合、动态不确定性、故障连锁反应、核心业务优先级动态变化等)。它具备应对未来多模态复杂工况的核心潜力,但需结合具体场景做细节适配。
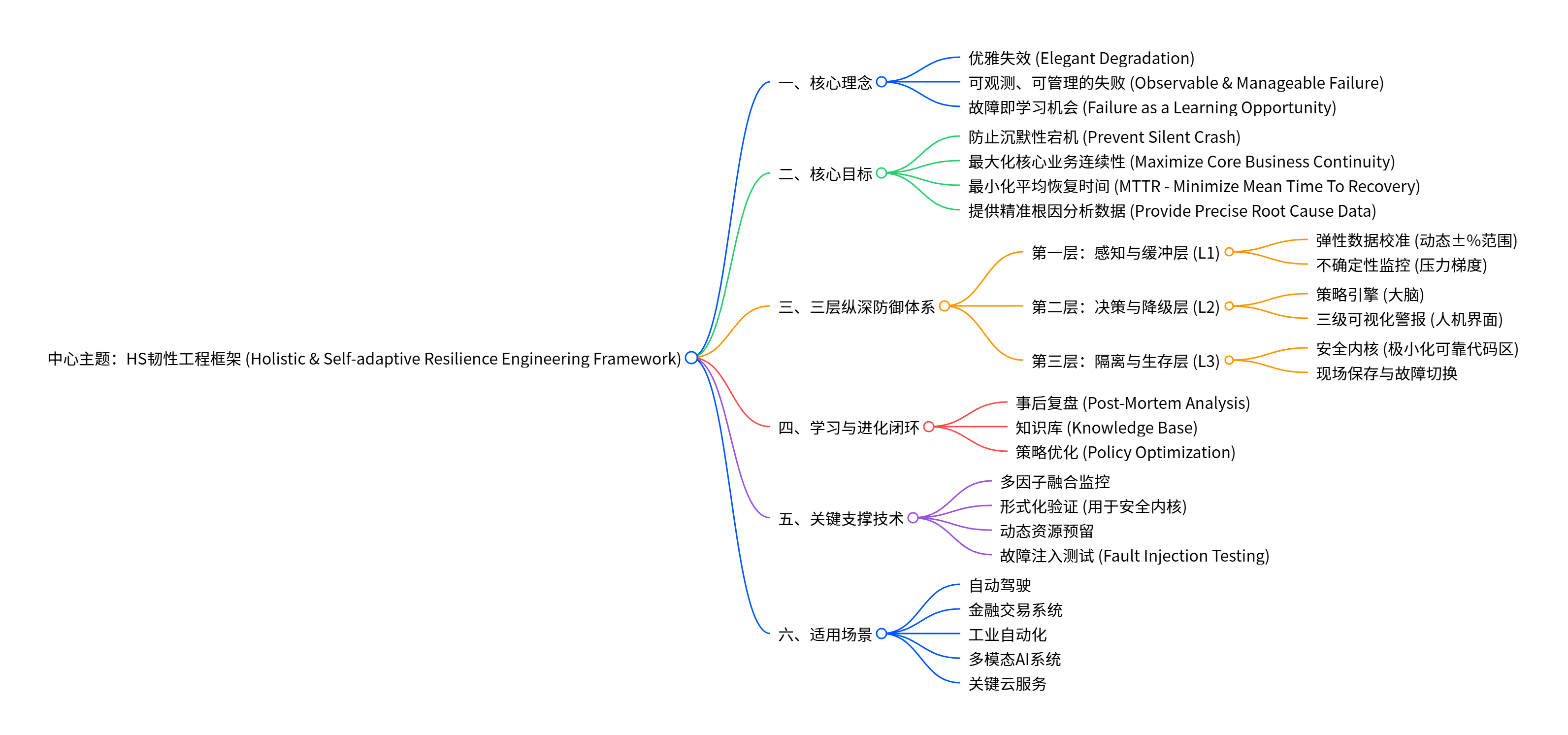
HS韧性工程框架(核心理念、目标、防御体系、全阶段过程流等),其核心策略逻辑与关键运行机制,具体可拆解为对框架 “设计思路 - 执行逻辑 - 闭环逻辑” 的三层理解:
一、对核心策略的理解:“阶梯式防御 + 数据驱动 + 底线思维”
框架的策略核心是“不追求‘永不故障’,而追求‘故障可控、损失最小、事后进化’”,具体通过三个维度落地:
阶梯式响应策略:以 “压力值” 为量化触发点(<60% 常态→60%-80% L1 缓冲→80%-90% L2 降级→≥90% L3 生存),实现 “轻度异常先缓冲、中度异常再降级、极端异常保底线” 的分层防御 —— 避免 “小故障用重策略” 的资源浪费,也防止 “大故障无应对” 的系统崩溃。
数据驱动决策策略:从初始化阶段的 “系统建模(定义健康度 / 置信度指标)”,到运行中的 “基线学习(动态更新正常模式)”,再到故障时的 “根因推测(如‘85% 概率由视觉模态 X 引起’)”,所有决策均依赖量化数据,而非主观判断 —— 这确保了策略的精准性和可复现性。
底线生存策略:将 “安全内核” 作为最终防线(经过形式化验证、极简可靠代码区),即使主系统崩溃,也能通过 “冻结故障快照 + 发送标准化生存信号” 保留诊断数据、避免异常输出扩散(如自动驾驶场景中避免误操作),为后续恢复和分析留足空间。
二、对关键机制的理解:“预设 - 监控 - 响应 - 恢复 - 进化” 全链路闭环
框架的运行机制围绕 “从‘预防’到‘恢复’再到‘优化’” 的全周期展开,每个环节的机制设计都服务于 “韧性” 目标:
预设机制(阶段零):通过 “策略预演(覆盖传感器失真、流量洪峰等场景)”“资源预留(5% 专属资源)”“可视化集成(三级警报界面)”,提前为故障应对 “铺好路”—— 避免故障发生时 “手忙脚乱凑策略”,确保响应速度。
监控机制(阶段一):“低功耗监控” 平衡 “监控精度” 与 “资源消耗”,“基线学习” 动态适应系统负载变化(如白天高负载、夜间低负载的正常模式不同)—— 解决了 “固定阈值误报率高” 的传统监控痛点。
故障响应机制:
L1 缓冲:通过 “弹性校准范围扩大(±5%→±10%)”“梯度释放”,尝试在不影响核心功能的前提下 “化解小异常”;
L2 降级:通过 “选择性关闭非核心功能”“资源重分配(优先核心业务)”,确保 “核心业务不中断”(如金融交易系统优先保障支付功能,而非报表统计功能);
L3 生存:通过 “冻结故障快照”“安全内核接管”,实现 “故障不扩散、数据不丢失”—— 比如工业自动化场景中,即使主系统失效,也能避免设备误动作引发安全事故。
恢复与进化机制(阶段五 - 六):“人工干预” 不是终点,而是 “学习优化” 的起点 —— 通过 “事后复盘(存入知识库)”“策略优化(调整阈值 / 新增场景)”“框架更新(部署新模型)”,让框架从每次故障中积累经验,实现 “下次遇到类似问题时,响应更精准、损失更小” 的进化。
三、对 “韧性” 本质的理解:“自治性 + 可解释性 + 实用性” 的平衡
框架最关键的机制设计,是跳出了 “纯技术堆砌”,兼顾了实际场景的落地需求:
自治性:从 L1 到 L3 的响应无需人工干预(如 L2 自动降级非核心功能),减少 “人工决策延迟” 带来的损失;
可解释性:通过 “可视化警报(显示根因推测结果)”“标准化生存信号(标注异常模块)”,让运维人员能快速理解故障状态,避免 “自动化黑箱” 无法排查的问题;
实用性:针对不同场景(自动驾驶、金融交易、工业自动化),机制设计各有侧重(如自动驾驶需优先避免异常输出,金融交易需优先保障核心业务连续性),而非 “一刀切” 的通用方案。
综上,框架的策略和机制是高度自洽的 —— 从核心理念(优雅失效、故障即学习机会)到具体落地(阶梯响应、安全内核、学习闭环),每个环节都相互支撑,最终实现 “核心业务不中断、故障损失最小化、系统持续进化” 的韧性目标,完全适配自动驾驶、关键云服务等对 “可靠性” 和 “可控性” 要求极高的场景。
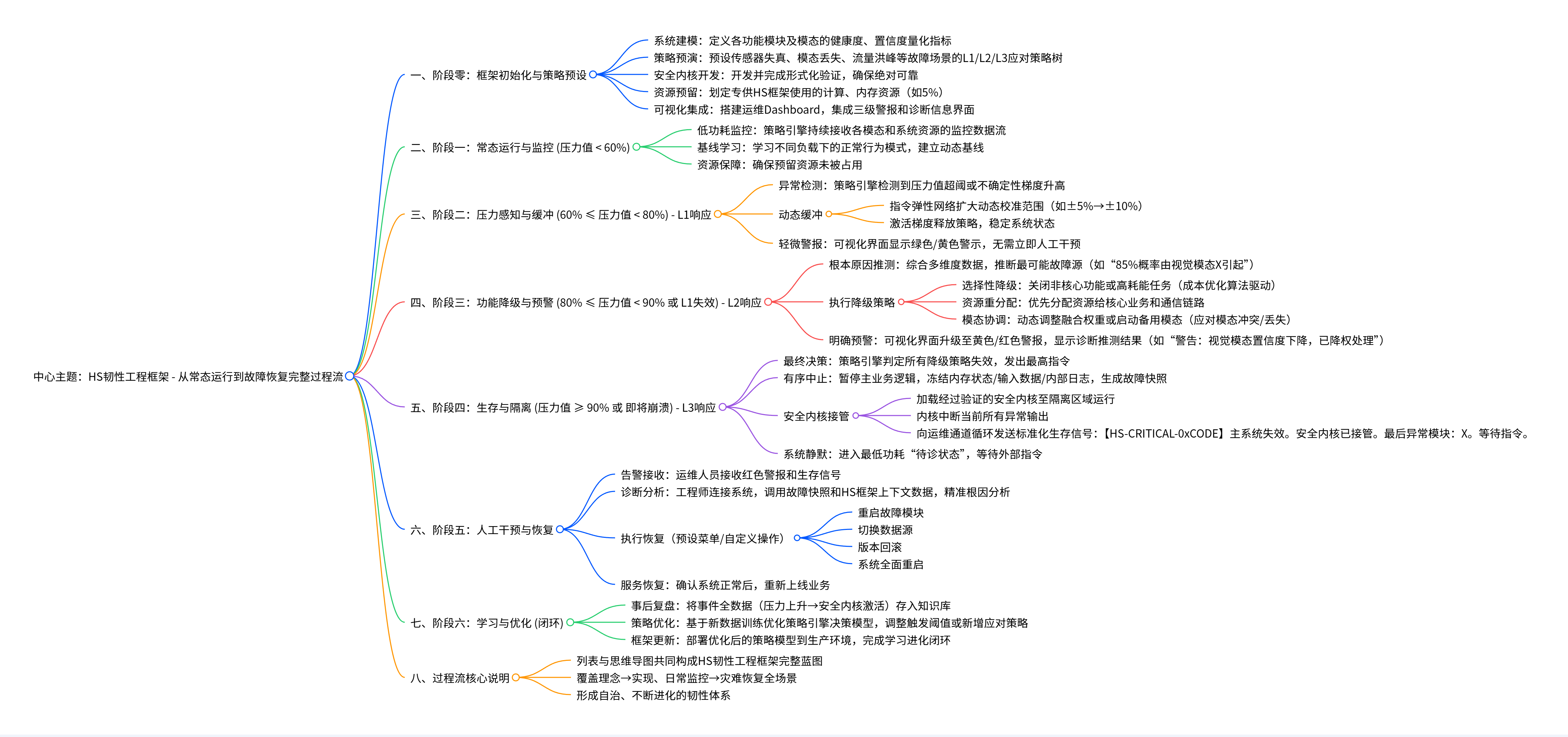
潜在优化方向:
1. 增强 “跨模态故障根因定位” 能力
当前框架的 “精准根因分析” 依赖 “故障快照 + 上下文数据”,但多模态系统的故障可能是 “间接耦合导致”(如激光雷达数据延迟→视觉模态误判→融合逻辑输出错误),需在策略引擎中新增 “跨模态因果分析模块”(如基于时序关联、数据依赖关系定位根本失效模态),避免根因定位偏差。
2. 适配 “多模态资源调度的动态性”
当前框架的 “资源预留” 是固定比例(如 5%),但多模态系统的资源需求随场景动态变化(如自动驾驶高速场景对激光雷达资源需求高,城区场景对视觉资源需求高),可优化为 “动态弹性预留机制”—— 根据当前核心模态的负载,实时调整预留资源的分配比例,避免资源浪费或不足。
3. 补充 “多模态协同降级的细粒度策略”
当前 L2 层的 “选择性降级” 是 “关闭非核心功能”,但多模态系统的 “核心 / 非核心” 可能动态变化(如多模态 AI 在 “医疗诊断” 场景中,文本病历模态是核心;在 “视频分析” 场景中,图像模态是核心),需新增 “场景化优先级配置接口”,让框架能根据当前业务场景,自动识别 “需优先保障的模态”,避免一刀切的降级策略。
HS 韧性工程框架的 “纵深防御 + 学习进化 + 核心业务优先” 设计,已经抓住了未来多模态复杂工况的 “容错、抗扰、可恢复” 核心需求,是一套具备前瞻性的通用框架 —— 只要结合具体多模态场景(如自动驾驶、医疗多模态 AI、工业多模态监控)的 “模态特性、业务优先级、故障模式” 做上述细节优化,就能有效应对未来的复杂挑战,甚至成为多模态系统 “韧性设计” 的标准化框架基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)