强化学习基础概念介绍
强化学习的训练样本(这里指的是智能体与环境交互产生的数据)没有任何标记,即强化学习的训练样本并不是一开始就给好的“输入-标签对”,而是智能体与环境交互过程中自己收集的经验轨迹。强化学习的训练样本不是“数据集中已有的标签”,而是:智能体在环境中探索时所收集的(状态, 动作, 奖励, 下一个状态)的交互记录。它们是强化学习“自学能力”的体现,智能体通过这些数据不断改进自己的策略。在强化学习中,训练样本
强化学习介绍
智能体与环境
- 强化学习方法通过与环境交互,学习状态到行为的映射关系。它包括智能体和环境两大对象。智能体也称为学习者和玩家,环境是指与智能体交互的外部
- 通常情况下,智能体是指存在于环境中,能够与环境进行交互,自主采取行动以完成任务的强化学习系统。系统之外的部分称之为环境。
- 不能被智能体随意改变的东西都被认为是该智能体的外部环境。
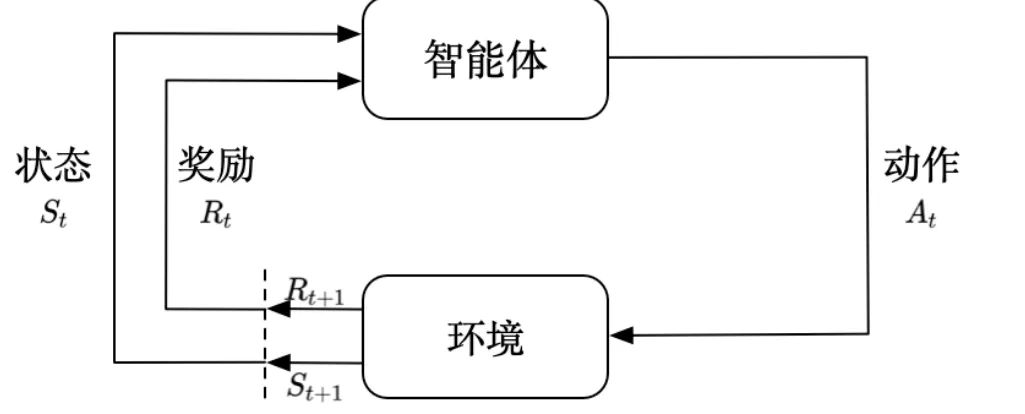
智能体主要组成
策略
- 策略是决定智能体行为的机制,是状态到行为的映射,定义了智能体在各个状态下的各种可能的行为及概率
- 策略分为确定性策略和随机性策略
- 确定性策略:根据具体状态输出一个动作
- 随机性策略:根据状态输出每个动作的概率,输出值为一个概率分布
- 策略仅和当前的状态有关,与历史信息无关
值函数
-
值函数表示智能体在给定状态下的表现,或者给定状态下采取某个行为的好坏程度。这里的好坏用未来的期望回报表示,而回报和采取的策略相关,所有值函数的估计都是基于给定的策略进行的。
-
值函数表示在给定策略下,智能体从某个状态(或状态-动作对)出发,未来期望能获得多少总回报。
-
值函数本身不是表示“某个动作获得的奖励”,而是表示“从当前状态(或状态+动作)出发,未来累积奖励的期望”,它关注的是**“长期回报”**,而不只是眼前那一步的奖励。
Gt=Rt+1+γRt+2+...=∑k=0∞γkRt+k+1 G_t = R_{t+1} + \gamma R_{t+2}+...=\sum_{k=0}^\infty \gamma^kR_{t+k+1} Gt=Rt+1+γRt+2+...=k=0∑∞γkRt+k+1 -
回报GtG_tGt为从t时刻开始往后所有的回报的有衰减的总和,γ\gammaγ表示衰减系数。接近1,表明会考虑长期的利益。
-
状态值函数Vπ(s)V_{\pi}(s)Vπ(s)表示从状态sss开始,遵循当前策略π\piπ所获得期望回报。这个值可用来评价一个状态的好坏,指导智能体选择动作。行为值函数类似,表示针对当前状态sss执行某一具体的行为aaa后,继续执行策略π\piπ所获得的期望回报。
-
Vπ(s)V_{\pi}(s)Vπ(s)**:是在“从状态 s 出发,按照策略 π 来行动”**的前提下,去计算未来的期望总奖励。
-
如果换一套策略$ π’,那,那,那V_{\pi}^{'}(s)$也会不同。
-
状态的好坏会因未来动作而不同,这体现在 QQQ 函数中;而 Vπ(s)V_{\pi}(s)Vπ(s)是“状态的好坏”,前提是它在一个策略 π 下定义,是对所有可能动作的加权平均。
模型
-
在强化学习任务中,模型MMM是智能体对环境的一个建模。给定一个状态和行为,改环境模型能够预测下一个状态和立即回报
-
模型指的是智能体用来预测环境反应的一种机制。它能回答两个关键问题:
- 如果我在某个状态下执行一个动作,会转移到哪个状态?
- 执行这个动作后,我会得到多少奖励?
这两个问题合起来就是所谓的“环境动态”,模型就是在模拟或学习这个动态过程。
-
环境模型至少要解决两个问题:一是状态转换概率Pss′aP_{ss^{'}}^aPss′a,预测下一个可能状态发生的概率;二是预测可能获得的立即回报RsaR^a_{s}Rsa。
-
Pss′aP_{ss^{'}}^aPss′a表示环境的动态特征,用以预测在状态sss上采取行为aaa后,下一个状态s′s^{'}s′的概率分布。RsaR^{a}_sRsa表示在状态sss上采取行动aaa后得到的回报。
-
同一个动作,在同一个状态下执行多次,可能导致不同的结果,这是由环境的不确定性带来的。不确定性是不可避免的,例如:
- 物理世界中的机器人:会有感应误差、动作执行误差
- 博弈游戏中的对手反应:你做一个动作,对手的反应无法预测
- 自然环境的不稳定性:天气、时间、光照等影响环境反馈
- 噪声:传感器数据、输入状态不精确
-
一般来说,模型已知指的是获得了状态转移概率Pss′aP_{ss^{'}}^aPss′a和回报RsaR^{a}_sRsa。模型针对智能体而言是环境实际运行机制的近似。
强化学习概述
-
强化学习的训练样本(这里指的是智能体与环境交互产生的数据)没有任何标记,即强化学习的训练样本并不是一开始就给好的“输入-标签对”,而是智能体与环境交互过程中自己收集的经验轨迹。
-
强化学习的训练样本不是“数据集中已有的标签”,而是:智能体在环境中探索时所收集的
(状态, 动作, 奖励, 下一个状态)的交互记录。它们是强化学习“自学能力”的体现,智能体通过这些数据不断改进自己的策略。 -
在强化学习中,训练样本通常是通过智能体与环境的交互过程收集到的“经验”(也叫“转移”或“轨迹”),一个基本的训练样本单位是一个四元组或五元组:
-
标准的训练样本结构如下:
(st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1}) \quad(st,at,rt,st+1)或$ \quad (s_t, a_t, r_t, s_{t+1}, done)$
含义如下:
- sts_tst:当前状态
- ata_tat:在状态 sts_tst 下采取的动作
- rtr_trt:执行动作 ata_tat 后获得的奖励
- st+1s_{t+1}st+1:环境反馈的下一个状态
- donedonedone(可选):是否为终止状态(episode 是否结束)
-
强化学习不像监督学习那样拥有“老师给的答案”,它的训练样本来自:
- 智能体观察当前状态 sts_tst
- 根据策略 π\piπ 选择动作 ata_tat
- 环境给出奖励 rtr_trt 和新状态 st+1s_{t+1}st+1
- 智能体记录下这一条经验 (st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st,at,rt,st+1)
- 重复多次,收集大量轨迹,用于学习
这些经验可以被存入**经验回放池(Replay Buffer)**中,供后续训练使用。
-
强化学习是一个序贯决策的过程,需要在与环境不断交互的过程中动态学习,该方法所需要的数据也是通过与环境不断交互动态产生的,并且所产生的数据之间存在高度的相关关系。
-
深度强化学习同时结合了深度学习的感知和强化学习的决策。
强化学习分类
- 根据智能体在解决强化学习问题时是否建立环境动力学模型,将其分为有模型方法和无模型方法
有模型方法
- 有模型方法会显式或隐式地学习或使用环境的动态特征,也就是状态转移概率分布 P(s′∣s,a)P(s' \mid s, a)P(s′∣s,a) 和奖励函数 R(s,a)R(s, a)R(s,a)。这样,智能体可以在内部模拟环境,提前“计划”未来的动作选择,而不必完全依赖实际与环境的交互。
- 在已知模型的情况下,可以使用**动态规划(Dynamic Programming)**类方法,例如值迭代(Value Iteration)和策略迭代(Policy Iteration)。当模型未知时,可以通过交互数据估计模型,并基于该模型进行模拟和规划。
无模型方法
- 在实际的强化学习任务中,很难知道环境的反馈机制,如状态转移的概率,环境反馈的回报等。这时候只能使用不依赖环境模型的方法,叫做无模型的方法,如蒙特卡罗、时序差分法都属于此类方法。
强化学习解决方法
- 可以通过建立状态值估计来解决强化学习问题,也可以通过直接建立策略的估计来解决强化学习问题
- 基于值函数的方法:求解时仅估计状态值函数,不去估计策略函数,最优策略在对值函数进行迭代求解时间接得到。动态规划、蒙特卡罗、时序差分、值函数逼近都属于值函数的办法
- 基于策略的方法:最优行为或策略直接通过求解策略函数产生,不去求解各状态值的估计函数。所有策略函数逼近方法都属于基于策略的方法,包括蒙特卡罗策略梯度、时序差分策略梯度等。
- 行动者-评论家方法:求解方法中既有值函数估计又有策略函数估计。两者相互结合解决问题,如典型的行动者-评论家方法、优势行动者-评论家方法、异步优势行动者-评论家方法等
强化学习研究方法
- 求解强化学习问题的目标时求解每个状态下的最优策略。策略是指在每一时刻,某个状态下智能体采取所有行为的概率分布,策略的目标是在长期运行过程中接受的累积回报最大。为了获取更高的回报,智能体在决策时不仅要考虑立即回报,还需要考虑后续状态的回报。
- 解决强化学习问题一般需要两步,将实际场景抽象成一个数学模型,然后去求解这个数学模型,找到累积回报最大的解
- 第一步:构建强化学习的数学模型–马尔可夫决策模型
- 第二部:求解马尔可夫决策模型的最优解
强化学习的三大概念
学习与规划
- 学习与规划是强化学习的两大类方法,适用不同的情形。学习针对的是环境模型未知的情况,智能体不知道环境如何工作,状态如何转变,以及每一步的回报是多少,仅通过与环境交互,采用试错法逐渐改善其策略
- 当智能体已经知道或近似知道环境如何工作时,可以考虑使用规划方法。此时,智能体并不直接与环境发生实际的交互,而是利用其拟合的环境模型获得状态转换概率和回报,在此基础上改善其策略
- 实际应用中,采取如下思路解决问题:
- 首先与环境交互,了解环境的工作方式,借助实际交互数据构建环境模型;
- 然后把这个习得的环境模型当作智能体的外部环境,并利用这个环境模型进行规划;
- 在实际经历发生之前,通盘考虑未来可能的所有情况来决定行动方案。
- 因此,基于模型进行规划是有模型方法,而不依赖模型的试错学习法是无模型方法。
探索与利用
-
强化学习是一种试错性质的学习,智能体需要从其环境的交互中找到一个最优的策略,同时在试错的过程中不能丢失太多的回报。因此,智能体在决策时需要平衡探索与利用两个方面
-
探索是指智能体在某个状态下试图去尝试一个新的行为,以图挖掘更多的关于环境的信息。而利用则是智能体根据已知信息,选取当下最优行为来最大化回报
-
探索和利用是一对矛盾,需要好好平衡
预测与控制
- 预测与控制也要评估与改善
- 在解决一个具体的马尔可夫决策问题时,首先需要解决关于预测的问题,即评估当前这个策略有多好,具体的做法是求解在既定策略下的状态值函数。而后在此基础上解决关于控制的问题,即对当前策略的不断优化,直到找到一个足够好的策略能够最大化未来的回报
- 实际上解决强化学习问题时,一般是先预测后控制,循环迭代直至收敛到最优解

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)