数字拼接的艺术与字符独舞的追寻:两道算法题背后的思维盛宴
从实现难度看,拼接最大数明显更加复杂,需要考虑多种边界情况和算法细节,而第一个唯一字符则相对 straightforward,但两者都体现了算法设计的核心思想:选择合适的数据结构和算法策略来高效解决问题。核心思路是:枚举所有可能从nums1中取i个数字、从nums2中取k-i个数字的情况,对每种情况分别求出两个数组能形成的最大子序列,然后合并这些子序列,最后选择所有合并结果中最大的那个。亲爱的读者
亲爱的算法爱好者们,欢迎来到今天的算法奇幻世界!在这个数字统治的时代,算法不仅是程序员手中的利器,更是思维训练的绝佳工具。今天,我们将一起探索两个看似不同却同样精彩的算法问题:拼接最大数和字符串中的第一个唯一字符。
想象一下,你手中握着两组数字卡片,如何从中挑选出k张卡片,排列成最大的数字?又或者,你面对一串神秘的字符,如何快速找到那个只出现一次的"独行侠"?这两个问题分别代表了算法设计中的两个重要范式:贪心算法与哈希映射的完美应用。
让我们一起深入这两个问题的核心,揭开它们的神秘面纱,感受算法设计的艺术与科学。无需编写代码,我们将聚焦于思维过程和分析方法,相信读完本文,你会对算法设计有更深刻的理解。
第一部分:拼接最大数——贪心算法的精致舞蹈
问题描述:
给你两个整数数组 nums1 和 nums2,它们的长度分别为 m 和 n。数组 nums1 和 nums2 分别代表两个数各位上的数字。同时你也会得到一个整数 k。
请你利用这两个数组中的数字创建一个长度为 k <= m + n 的最大数。同一数组中数字的相对顺序必须保持不变。
返回代表答案的长度为 k 的数组。
问题深度解析
拼接最大数问题要求我们从两个数组中保持原有顺序选择数字,组成最大的k位数。这看似简单的问题背后隐藏着深刻的算法设计思想。
问题特征分析:
-
顺序约束:必须保持每个数组中数字的原始顺序
-
组合优化:需要从两个数组中选择数字组合成最大数
-
全局最优:要求结果数字最大,而非局部最优
算法思维框架:
这个问题可以采用分治+贪心的策略解决。核心思路是:枚举所有可能从nums1中取i个数字、从nums2中取k-i个数字的情况,对每种情况分别求出两个数组能形成的最大子序列,然后合并这些子序列,最后选择所有合并结果中最大的那个。
具体而言,算法分为三个关键步骤:
-
单个数组的最大子序列提取:对于给定数组和指定长度,提取保持顺序的最大子序列。这里使用单调栈的思想,维护一个栈,保证栈中的数字尽可能大且保持顺序。
-
双序列合并:将两个子序列合并成一个最大序列。这需要比较两个序列的字典序,选择当前更大的数字。
-
结果比较:遍历所有可能的i值(从max(0, k-n)到min(k, m)),找出最大的合并结果。
时间复杂度分析:虽然题目要求O(n)空间复杂度,但实际最优解法的时间复杂度为O(k*(m+n)),空间复杂度为O(k)。
示例 1:
输入:nums1 = [3,4,6,5], nums2 = [9,1,2,5,8,3], k = 5
输出:[9,8,6,5,3]
示例 2:
输入:nums1 = [6,7], nums2 = [6,0,4], k = 5
输出:[6,7,6,0,4]
示例 3:
输入:nums1 = [3,9], nums2 = [8,9], k = 3
输出:[9,8,9]
题目程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 函数声明
int* maxSubsequence(int* nums, int numsSize, int k);
int* merge(int* nums1, int nums1Size, int* nums2, int nums2Size);
int compareSequence(int* nums1, int nums1Size, int index1, int* nums2, int nums2Size, int index2);
int isGreater(int* nums1, int size1, int* nums2, int size2);
// 从数组中提取长度为k的最大子序列(保持原始顺序)
int* maxSubsequence(int* nums, int numsSize, int k) {
// 如果k为0,直接返回空数组
if (k == 0) {
return NULL;
}
// 分配栈空间,用于存储最大子序列
int* stack = (int*)malloc(k * sizeof(int));
// 初始化栈顶指针
int top = -1;
// 遍历输入数组的所有元素
for (int i = 0; i < numsSize; i++) {
// 当栈不为空,且当前元素大于栈顶元素,且剩余元素数量足够形成k长度的序列时
while (top >= 0 && stack[top] < nums[i] && top + numsSize - i >= k) {
top--; // 弹出栈顶元素
}
// 如果栈中元素数量小于k,将当前元素入栈
if (top < k - 1) {
stack[++top] = nums[i];
}
}
// 返回提取的最大子序列
return stack;
}
// 合并两个数组,形成最大的序列
int* merge(int* nums1, int nums1Size, int* nums2, int nums2Size) {
// 如果第一个数组为空,直接返回第二个数组的副本
if (nums1Size == 0) {
int* result = (int*)malloc(nums2Size * sizeof(int));
memcpy(result, nums2, nums2Size * sizeof(int));
return result;
}
// 如果第二个数组为空,直接返回第一个数组的副本
if (nums2Size == 0) {
int* result = (int*)malloc(nums1Size * sizeof(int));
memcpy(result, nums1, nums1Size * sizeof(int));
return result;
}
// 分配合并后的数组空间
int* result = (int*)malloc((nums1Size + nums2Size) * sizeof(int));
// 初始化两个数组的索引
int i = 0, j = 0;
// 遍历合并后的数组长度
for (int idx = 0; idx < nums1Size + nums2Size; idx++) {
// 比较两个数组从当前索引开始的字典序
if (compareSequence(nums1, nums1Size, i, nums2, nums2Size, j) > 0) {
// 如果第一个数组的字典序更大,取第一个数组的元素
result[idx] = nums1[i++];
} else {
// 否则取第二个数组的元素
result[idx] = nums2[j++];
}
}
// 返回合并后的数组
return result;
}
// 比较两个数组从指定索引开始的字典序
int compareSequence(int* nums1, int nums1Size, int index1, int* nums2, int nums2Size, int index2) {
// 遍历直到其中一个数组结束
while (index1 < nums1Size && index2 < nums2Size) {
// 比较当前元素
int diff = nums1[index1] - nums2[index2];
// 如果元素不同,返回差值
if (diff != 0) {
return diff;
}
// 移动索引
index1++;
index2++;
}
// 如果一个数组先结束,比较剩余长度
return (nums1Size - index1) - (nums2Size - index2);
}
// 比较两个数组的字典序大小
int isGreater(int* nums1, int size1, int* nums2, int size2) {
// 遍历两个数组的所有元素
for (int i = 0; i < size1 && i < size2; i++) {
// 如果当前元素不同,返回比较结果
if (nums1[i] != nums2[i]) {
return nums1[i] > nums2[i];
}
}
// 如果所有元素相同,返回长度更长的数组更大
return size1 > size2;
}
// 主函数
int* maxNumber(int* nums1, int nums1Size, int* nums2, int nums2Size, int k) {
// 初始化结果数组为NULL
int* result = NULL;
// 计算从第一个数组可取元素数量的起始值
int start = k - nums2Size > 0 ? k - nums2Size : 0;
// 计算从第一个数组可取元素数量的结束值
int end = nums1Size < k ? nums1Size : k;
// 遍历所有可能的取元素组合
for (int i = start; i <= end; i++) {
// 从第一个数组提取长度为i的最大子序列
int* sub1 = maxSubsequence(nums1, nums1Size, i);
// 从第二个数组提取长度为k-i的最大子序列
int* sub2 = maxSubsequence(nums2, nums2Size, k - i);
// 合并两个子序列
int* merged = merge(sub1, i, sub2, k - i);
// 如果结果数组为空或当前合并序列更大,更新结果
if (result == NULL || isGreater(merged, k, result, k)) {
// 释放原有结果数组
free(result);
// 更新结果数组
result = merged;
} else {
// 释放当前合并序列
free(merged);
}
// 释放子序列数组
free(sub1);
free(sub2);
}
// 返回结果数组
return result;
}
// 示例测试函数
int main() {
// 示例1
int nums1[] = {3,4,6,5};
int nums2[] = {9,1,2,5,8,3};
int k = 5;
int* result = maxNumber(nums1, 4, nums2, 6, k);
printf("Example 1: [");
for (int i = 0; i < k; i++) {
printf("%d", result[i]);
if (i < k - 1) printf(",");
}
printf("]\n");
free(result);
// 示例2
int nums3[] = {6,7};
int nums4[] = {6,0,4};
k = 5;
result = maxNumber(nums3, 2, nums4, 3, k);
printf("Example 2: [");
for (int i = 0; i < k; i++) {
printf("%d", result[i]);
if (i < k - 1) printf(",");
}
printf("]\n");
free(result);
// 示例3
int nums5[] = {3,9};
int nums6[] = {8,9};
k = 3;
result = maxNumber(nums5, 2, nums6, 2, k);
printf("Example 3: [");
for (int i = 0; i < k; i++) {
printf("%d", result[i]);
if (i < k - 1) printf(",");
}
printf("]\n");
free(result);
return 0;
}输出结果: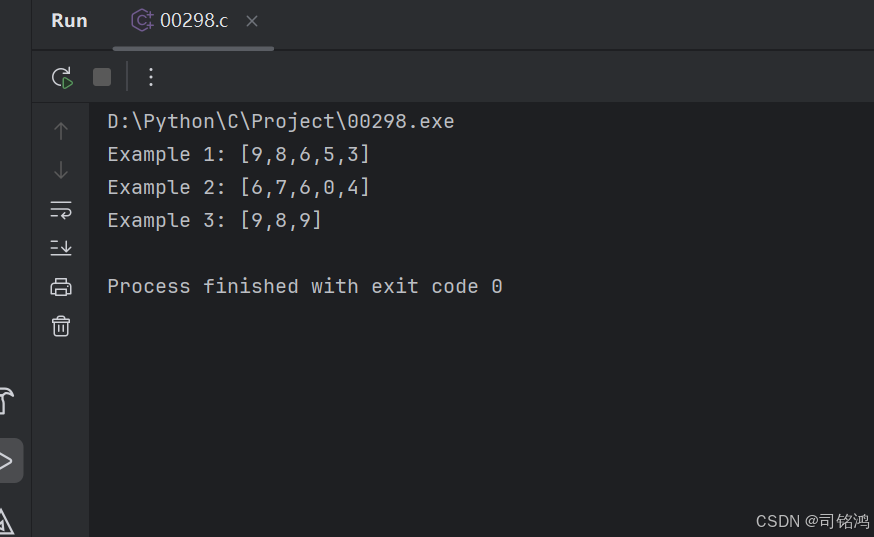
算法精妙之处
这个问题的解法展现了算法设计中多个重要概念的融合:
-
贪心选择性质:在每个步骤中选择当前最大的可用数字,虽然局部最优不一定保证全局最优,但结合适当的回溯(枚举所有可能的i值),最终能得到全局最优解。
-
单调栈的巧妙应用:在提取单个数组的最大子序列时,使用单调栈思想可以在O(n)时间内解决问题,这是算法效率的关键。
-
字典序比较的智慧:合并两个序列时,需要比较两个序列的字典序,这要求我们不仅看当前数字,还要看后续数字的潜在影响。
第二部分:字符串中的第一个唯一字符——哈希映射的高效追踪
问题描述:
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
问题本质探索
寻找字符串中第一个不重复字符是一个经典的字符串处理问题,它考察的是如何高效地统计和处理字符出现频率。
问题特征分析:
-
顺序重要性:需要找到第一个满足条件的字符,而不仅仅是判断是否存在
-
频率统计:需要准确记录每个字符的出现次数
-
效率要求:字符串长度可能达到10^5,需要线性时间解法
算法思维框架:
这个问题的最优解法使用哈希映射(或称为字典)来记录每个字符的出现频率,然后再次遍历字符串找到第一个频率为1的字符。
具体步骤如下:
-
频率统计:遍历字符串,使用哈希表记录每个字符出现的次数
-
顺序查找:再次遍历字符串,对于每个字符,检查其在哈希表中的频率值,找到第一个频率为1的字符
复杂度分析:时间复杂度为O(n),空间复杂度为O(1)(因为字符集大小固定,如小写字母只有26个)
示例 1:
输入: s = "leetcode"
输出: 0
示例 2:
输入: s = "loveleetcode"
输出: 2
示例 3:
输入: s = "aabb"
输出: -1
题目程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 函数声明:查找字符串中第一个不重复字符的索引
int firstUniqChar(char* s);
// 主函数:程序入口点
int main() {
// 示例测试1
char s1[] = "leetcode";
// 调用函数并打印结果
int result1 = firstUniqChar(s1);
printf("Example 1: %d\n", result1);
// 示例测试2
char s2[] = "loveleetcode";
// 调用函数并打印结果
int result2 = firstUniqChar(s2);
printf("Example 2: %d\n", result2);
// 示例测试3
char s3[] = "aabb";
// 调用函数并打印结果
int result3 = firstUniqChar(s3);
printf("Example 3: %d\n", result3);
return 0;
}
// 函数定义:查找字符串中第一个不重复字符的索引
int firstUniqChar(char* s) {
// 创建哈希表,用于存储每个字符的出现次数
// 使用256大小的数组以覆盖所有ASCII字符
int hash[256] = {0};
// 第一次遍历:统计每个字符的出现次数
// 使用指针遍历字符串,直到遇到空字符('\0')
char* p = s;
while (*p != '\0') {
// 将字符转换为无符号字符以确保正确的数组索引
// 增加对应字符的计数
hash[(unsigned char)*p]++;
// 移动指针到下一个字符
p++;
}
// 第二次遍历:查找第一个出现次数为1的字符
// 重置指针到字符串开头
p = s;
// 初始化索引计数器
int index = 0;
while (*p != '\0') {
// 检查当前字符的出现次数是否为1
if (hash[(unsigned char)*p] == 1) {
// 如果是,返回当前索引
return index;
}
// 移动指针到下一个字符
p++;
// 增加索引计数器
index++;
}
// 如果没有找到不重复字符,返回-1
return -1;
}输出结果: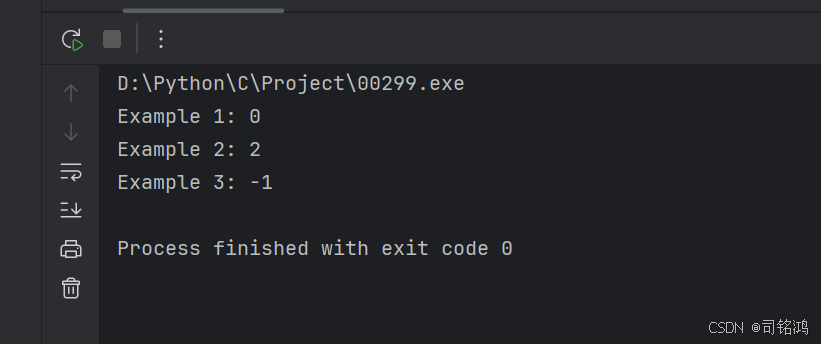
算法精妙之处
这个问题的解法虽然简单,但体现了算法设计中的重要原则:
-
空间换时间:通过使用额外的哈希表空间,将时间复杂度从朴素的O(n^2)降低到O(n)
-
两次遍历的分离:将统计频率和查找第一个唯一字符分离,使每个步骤专注解决一个子问题
-
固定空间复杂度:由于字符集大小固定(如小写字母只有26个),空间复杂度是O(1),
第三部分:双题对比分析——算法思维的两种范式
为了更清晰地展示两个问题的异同,我们通过以下对比图表进行分析:
| 特征维度 | 拼接最大数 | 第一个唯一字符 |
|---|---|---|
| 问题类型 | 组合优化问题 | 搜索查找问题 |
| 核心算法 | 贪心算法+分治 | 哈希映射 |
| 时间复杂度 | O(k*(m+n)) | O(n) |
| 空间复杂度 | O(k) | O(1) |
| 关键数据结构 | 栈(用于单调序列) | 哈希表 |
| 算法难点 | 双序列合并的字典序比较 | 频率统计与顺序查找的结合 |
| 实际应用 | 数据合并、资源分配 | 文本处理、编译器设计 |
| 思维模式 | 分解-解决-合并 | 统计-检索 |
深度对比解析
从算法范式角度看,这两个问题代表了两种不同的算法设计思想:
-
贪心与分治的融合(拼接最大数):这个问题需要将大问题分解为小问题(枚举所有可能的i值),对每个小问题采用贪心策略解决(提取最大子序列和合并序列),最后合并结果。这种分治+贪心的组合是解决复杂优化问题的强大工具。
-
简单而高效的映射(第一个唯一字符):这个问题展示了如何通过合适的数据结构(哈希表)将复杂问题简化。哈希表的使用使得原本需要嵌套循环的问题变得简单高效。
从实现难度看,拼接最大数明显更加复杂,需要考虑多种边界情况和算法细节,而第一个唯一字符则相对 straightforward,但两者都体现了算法设计的核心思想:选择合适的数据结构和算法策略来高效解决问题。
第四部分:算法思维的实际应用与拓展
这两个算法问题不仅仅是学术练习,它们有广泛的实际应用:
拼接最大数的应用场景:
-
金融领域:多个账户余额合并形成最大金额
-
资源分配:从多个资源池中选择资源形成最优配置
-
数据融合:多个数据源的信息合并为最完整版本
第一个唯一字符的应用场景:
-
编译器设计:识别标识符的第一次出现
-
文本处理:查找文档中第一次出现的特殊字符
-
数据清洗:识别数据集中的异常值或唯一值
算法思维拓展
通过这两个问题,我们可以提炼出以下算法设计原则:
-
分解复杂问题:像拼接最大数一样,将复杂问题分解为可管理的子问题
-
选择合适数据结构:如第一个唯一字符中哈希表的选择直接影响算法效率
-
空间换时间权衡:在两个问题中,我们都使用额外空间来提升时间效率
-
注意边界条件:特别是在拼接最大数中,需要仔细处理各种边界情况
算法世界犹如一个充满谜题的乐园,每一个问题都是对思维的一次挑战和锻炼。拼接最大数问题教会我们如何通过分治和贪心策略解决复杂优化问题,而第一个唯一字符问题则展示了哈希映射在高效搜索中的强大能力。
希望今天的分享能够让你感受到算法设计的艺术与科学,体会到不同算法策略的独特魅力。记住,掌握算法不仅仅是学习编写代码,更是培养一种解决问题的思维方式。
亲爱的读者,如果你对这两个问题有独到的见解,或者在实际工作中遇到过类似的应用场景,欢迎在评论区分享你的经验。让我们共同探索算法的无限可能!
互动环节:你在学习算法的过程中遇到过哪些令人印象深刻的问题?它们是如何改变你的思维方式的?分享你的故事,我们一起进步!
明日预告:明天我们将探讨「二叉树中的最大路径和」与「岛屿数量」问题,带你继续算法奇妙之旅。敬请期待!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)